
🎯 SVM이란?
Support Vector Machine(SVM : 서포트 벡터 머신)은 분류 과제에 사용할 수 있는
머신러닝 지도학습 모델 중 하나로,
Decision Boundary(결정 경계), 즉 분류를 위한 기준 선을 정의하는 분류 모델이다.
그래서 분류되지 않은 새로운 점이 경계를 기준으로 어느쪽에 속하는지 분류할 수 있게 된다. 결국 Decision Boundary를 어떻게 정의할지와 그것을 계산하는 것이 중요해진다.
두 가지 데이터를 분류해보자.(Playoff Teams, Non-Playoff Teams)
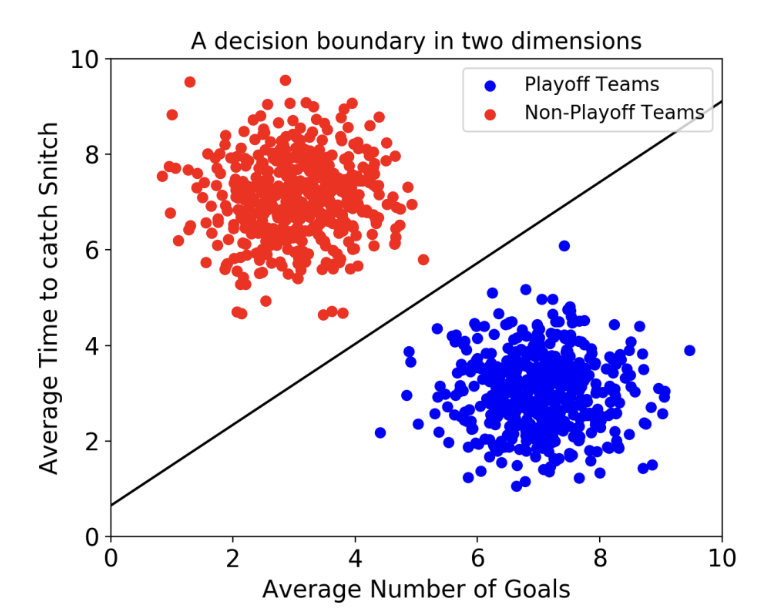 위 그림처럼 데이터의 속성이 2가지라면, Decision Boundary는 선으로 나타나게 된다.
위 그림처럼 데이터의 속성이 2가지라면, Decision Boundary는 선으로 나타나게 된다.
다음 그림을 보면,
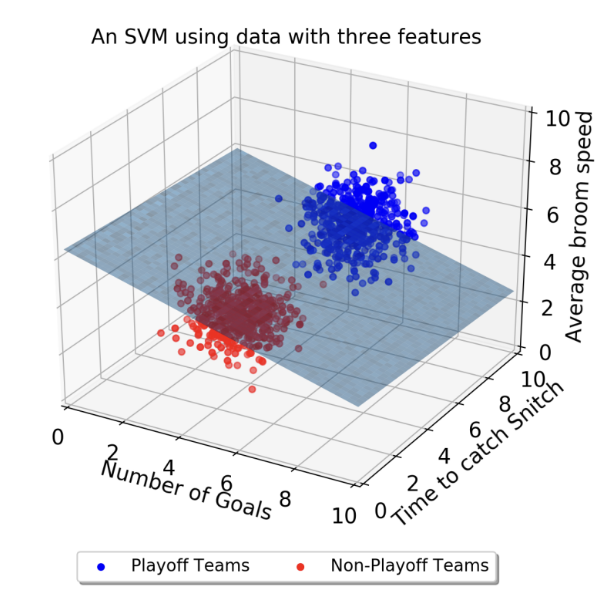
속성이 3가지로 늘어났을 때는 Decision Boundary가 면이 된다. 여기까지는 눈으로 확인할 수 있다. 속성이 여러개로 늘어나게 되면 초평면이 된다.
🏓 Decision Boundary
결정 경계는 무수히 많이 그을 수 있다. 그중 가장 최적의 결정 경계는 어떻게 결정할 수 있을까?
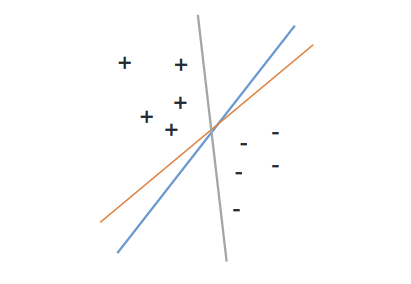
 Graph C를 보면 선이 파란색 그룹과 매우 가깝다. 별로 좋지 못한 기준선으로 보인다. 이 중 가장 좋은 선은 아마 Graph F의 선일 것이다. 파란색의 경향과 붉은 색의 경향을 가장 잘 구분한 선일 것이다. 그리고 이 선은 두 클래스(분류) 사이에서 거리가 가장 멀다.
Graph C를 보면 선이 파란색 그룹과 매우 가깝다. 별로 좋지 못한 기준선으로 보인다. 이 중 가장 좋은 선은 아마 Graph F의 선일 것이다. 파란색의 경향과 붉은 색의 경향을 가장 잘 구분한 선일 것이다. 그리고 이 선은 두 클래스(분류) 사이에서 거리가 가장 멀다.
결정 경계는 데이터 군으로부터 최대한 멀리 떨어지는 게 좋다
실제로 Support Vector Machine이라는 이름에서 Support Vectors는 Decision Boundary와 가까이 있는 데이터 포인트들을 의미한다. 이 데이터들이 경계를 정의하는 결정적인 역할을 하는 셈이다.
🥏 Margin이란?
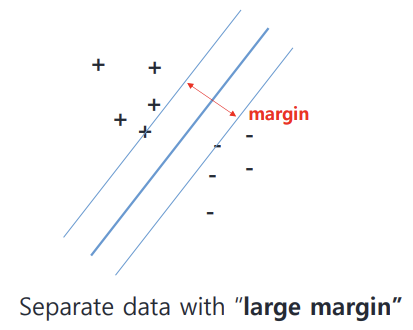
Margin(마진)이란 Decision Boundary와 Support Vector 사이의 거리를 말한다.
 실선이 Decision Boundary, 점선에 걸쳐져 있는 red dot 1개와 blue dot 2개가 Support Vector이다. 실선에서 점선까지의 거리가 바로 margin이다.
실선이 Decision Boundary, 점선에 걸쳐져 있는 red dot 1개와 blue dot 2개가 Support Vector이다. 실선에서 점선까지의 거리가 바로 margin이다.
최적의 Decision Boundary는 Margin을 최대화한다.
x축과 y축 2개의 속성을 가진 데이터로 Decision Boundary를 그었는데, 총 3개의 데이터 포인트(Support Vector)가 필요했다.
n개의 속성을 가진 데이터에는 최소 n+1개의 서포트 벡터가 존재한다
🎁 SVM 알고리즘의 장점
대부분의 머신러닝 지도 학습 알고리즘은 학습 데이터 모두를 사용하여 모델을 학습한다. 그런데 SVM에서는 결정 경계를 정의하는 게 결국 서포트 벡터이기 때문에 데이터 포인트 중에서 서포트 벡터만 잘 골라내면 나머지 쓸 데 없는 수많은 데이터 포인트들을 무시할 수 있다. 그래서 매우 빠르다.
🎊 SVM 구현
from sklearn.svm import SVC
classifier = SVC(kernel = 'linear')
training_points = [[1, 2], [1, 5], [2, 2], [7, 5], [9, 4], [8, 2]]
labels = [1, 1, 1, 0, 0, 0]
classifier.fit(training_points, labels)
print(classifier.predict([[3, 2]]))
print(classifier.support_vectors_)🎈 Outlier
SVM은 데이터 포인트들을 올바르게 분리하면서 마진의 크기를 최대화해야 하는데, 결국 이상치(outlier)를 잘 다루는 게 중요하다.
Reference
서포트 벡터 머신 쉽게 이해하기
ml_lec6
