
Day 1🏄🏻♀️
08-05-MONDay 1🏄🏻♀️✨ Overview, 01. PyTorch 기초 ✨
TIL
1) PyTorch란
- PyTorch는 FaceBook AI 연구소에서 개발된 오픈소스 프레임워크이다. (2016년)
사용자 친화성을 강조함. 복잡한 작업도 쉽게 처리함. 학계, 산업계 연구자, 실무자에게 유용했음
사용하고 있는 기업-테슬라(자율주행 Autopilot에서), 우버(택시, Pyro 확률), 허깅페이스(최신 딥러닝 모델 무료 제공하는 곳, Transformers 라이브러리-BERT,gpt시리즈 +구글-Tensorflow를 사용)
허깅페이스 모델 92%가 PyTorch
학계 연구 논문 꾸준히 증가, 거의 모두가 PyTorch
언제 이 통계가 바뀔지 모름. 여러가지 프레임워크를 공부하는 것은 중요함 - 간편한 딥러닝 API를 제공함
API란 응용프로그램이 서로 상호작용하는데 사용하는 명령어, 함수, 프로토콜의 집합을 의미한다
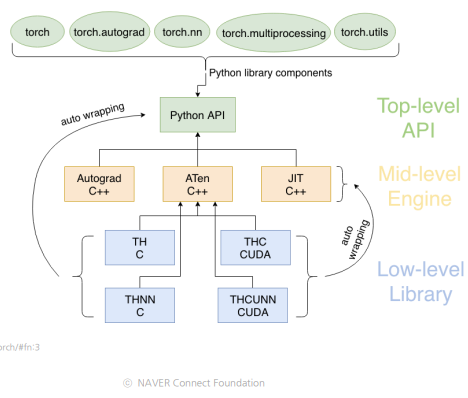
사용자는 많은 API level로 pytorch를 이용할 수 있다 :torch,torch.autograd(자동미분),torch.nn(Neural network),torch.multiprocessing,torch.utils(utility)
PyTorch API는 두번째 레벨인 Engine level과, Python API로 연결되어
텐서 연산을 처리하고 자동미분을 담당하는 역할을 한다.
마지막 레벨인 Library level에서는 사용자의 텐서연산을 담당하는 C, GPU를 담당하는 CUDA 등 실제 하드웨어와 연동해서 텐서들의 연산을 수행하고 있다. - 확장성이 뛰어난 멀티플랫폼이다
다양한 규모의 프로젝트에 적응할 수 있음-작업량을 처리할 수 있음, 멀티플랫폼=Window, macOS등 다양한 환경에서 사용할 수 있음 - 동적 계산 그래프를 사용한다
= 연산을 평가하고, 계산을 실행하고, 구체적인 값을 즉시 반환하는 명령형 프로그래밍 환경을 제공한다
계산 그래프를 사전에 구성한 후 실행하는 tensorflow 초기와 차이가 있음 -파이토치로 넘어옴 - 고성능과 효율성(Nvidia, GPU 지원-대규모병렬연산을 효율적으로 수행-학습/추론속도를 매우 높임), 풍부한 모델 구현체(허깅페이스, PyTorch Hub에서 쉽게 가져와 사용-연구/개발의 시작점을 빠르게 잡을 수 있음)
2) Tensor란
Tensor는 파이토치의 핵심 데이터 구조이다.
Numpy의 다차원 배열과 유사한 형태로 표현할 수 있다. 데이터를.
tensor의 언어적-대수적-공간-코드 표현
-
0-D Tensor 란
= 0차원 텐서
= Scalar라고 부르던 개념
0차원 텐서의 언어적 표현 : 하나의 숫자로 표현되는 양
0차원 텐서의 대수적 표현(=수식) :
0차원 텐서 공간에서 표현 : 한점
0차원 텐서의 코드 표현 :a = torch.tesor(36.5) -
colab 실습
클라우드 기반 - 로컬 컴퓨터의 자원을 쓰지 않고도 인터넷만 연결할 수 있는 어디서든지 접근할 수 있음import torch # 0-D Tensor(=Scalar)의 코드 표현 실습 a = torch.tensor(36.5) print('a =', a) -
1-D Tensor 란
= 1차원 텐서
= Vector로 부르던 개념
1차원 텐서의 언어적 표현 : 순서가 지정된 여러 개의 숫자들이 일렬로 나열된 구조
1차원 텐서의 대수적 표현(=수식) :
1차원 텐서 공간에서 표현 : 5개의 항목의 값들을 일렬로 나열한 것,dim-0-나열 축, 차원이 늘어날 때마다 이 축의 위치가 변경됨. (2차원, 3차원 텐서에서 축의 위치는 어떻게 바뀌는가?)
1차원 텐서의 코드 표현 :b = torch.tesor(36.5) -
colab 실습
import torch # 1-D Tensor(=Vector)의 코드 표현 실습 b = torch.tensor([175, 60, 81, 0.8, 0.9]) print('b =', b) -
2-D Tensor 란
= 2차원 텐서
= Matrix로 부르던 개념
2차원 텐서의 언어적 표현 : 동일한 크기를 가진 1D Tensor들이 모여서 형성한, 행과 열로 구성된 사각형 구조
2차원 텐서의 대수적 표현(=수식) :
2차원 텐서 공간에서 표현 : 3행 4열 12개,dim-0-행차원 축 +dim-1-기존축 변화. 차원이 늘어날 때마다 이 축의 위치가 변경됨. (3차원 텐서에서 축의 위치는 어떻게 바뀌는가?), 그레이 스케일. 공간에서의 값들이 그레이 스케일의 밝기 정도로 바뀜, 이미지로 표현
2차원 텐서의 코드 표현 :c = torch.tensor([[77, 114, 140, 191], [39, 56, 46, 119], [61, 29, 20, 33]]) -
colab 실습
import torch # 2-D Tensor(=Matrix)의 코드 표현 실습 c = torch.tensor([[77, 114, 140, 191], [39, 56, 46, 119], [61, 29, 20, 33]]) print('c =', c) # 그레이스케일 이미지의 코드 표현 실습 import matplotlib.pyplot as plt plt.xticks([]), plt.yticks([]) ptl.imshow(c, cmap='gray', vmin=0, vmax=255) plt.show() -
3-D Tensor 란
= 3차원 텐서
= Matrix로 부르던 개념
3차원 텐서의 언어적 표현 : 동일한 크기를 가진 1D Tensor들이 모여서 형성한, 행과 열로 구성된 사각형 구조
3차원 텐서의 대수적 표현(=수식) :
3차원 텐서 공간에서 표현 : 3행 4열 12개,dim-0-행차원 축 +dim-1-기존축 변화. 차원이 늘어날 때마다 이 축의 위치가 변경됨. (3차원 텐서에서 축의 위치는 어떻게 바뀌는가?), 그레이스케일. 공간에서의 값들이 그레이 스케일의 밝기 정도로 바뀜, 이미지로 표현
3차원 텐서의 코드 표현 :c = torch.tensor([[77, 114, 140, 191], [39, 56, 46, 119], [61, 29, 20, 33]]) -
colab 실습
import torch # 3-D Tensor(=Matrix)의 코드 표현 실습 d = torch.tensor([[77, 114, 140, 191], [39, 56, 46, 119], [61, 29, 20, 33]]) print('d =', d) # 그레이스케일 이미지의 코드 표현 실습 import matplotlib.pyplot as plt plt.xticks([]), plt.yticks([]) ptl.imshow(c, cmap='gray', vmin=0, vmax=255) plt.show() -
정리
- Tensor란 PyTorch의 핵심 데이터 구조로서, Numpy의 다차원 배열과 유사한 형태로 데이터를 표현한다.
- Tensor는 언어적, 대수적, 공간에서, 코드로 표현이 가능하다.
1) PyTorch의 데이터 타입
-
데이터 타입 (dtype)
= Tensor가 저장하는 값의 데이터 유형
정수형, 실수형 -
정수형 데이터
= 소수 부분이 있는 숫자를 저장하는 데 사용되는 데이터 타입
= 8비트 부호 없는 정수, 8비트 부호 있는 정수, 16비트 부호 있는 정수, 32비트 부호 있는 정수, 64비트 부호 있는 정수-
8비트 부호 없는 정수의 언어적 표현: 8개의 이진 자리수(비트)를 사용하여 0부터 255까지의 정수를 표현할 수 있는 데이터 형식, 사실상 자연수
8비트 부호 없는 정수의 공간에서 표현: 0부터 255까지만 표현이 가능(2^0 + ... + 2^7 = 255)
8비트 부호 없는 정수의 코드 표현:dtype=torch.uint8unsigned integer 8 비트 -
8비트 부호 있는 정수의 언어적 표현: 8개의 이진 자리수(비트)를 사용하여 -128부터 127까지의 정수를 표현할 수 있는 데이터 형식
8비트 부호 있는 정수의 공간에서 표현: 0이면 +(양), 1이면 -(음), 숫자는 2^0 ~ 2^6 음수는 왜 -128까지? 양수는 0을 포함한 1부터 127까지 음수는 0을 제외하고 나타내기에 -1~-128까지
8비트 부호 있는 정수의 코드 표현:dtype=torch.int8, torch tensor의 함수의 매개변수로 사용 -
16비트 부호 있는 정수의 언어적 표현: 16개 이진 자리수(비트)를 사용하여 -32,768부터 32,767까지의 정수를 표현할 수 있는 데이터 형식- 부호 1비트를 제외한 15비트를 숫자에 할당
16비트 부호 있는 정수의 코드 표현 :dtype = torch.int16또는dtype=torch.short -
32비트 부호 있는 정수의 언어적 표현 : 32개의 이진 자리수(비트)를 사용하여 -2,147,483,648부터 2,147,483,647까지의 정수를 표현할 수 있는 데이터 형식, 대부분의 프로그래밍에서 표준적인 정수 크기로 사용
32비트 부호 있는 정수의 코드 표현:dtype=torch.int32또는dtype=torch.int -
64비트 부호 있는 정수의 언어적 표현 : 64개의 이진 자리수(비트)를 사용하여 -9,223,372,036,854,775,808부터 9,223,372,036,854,775,807까지의 정수를 표현할 수 있는 데이터 형식
64비트 부호 있는 정수의 코드 표현 :dtype=torch.int64또는dtype=torch.long
-
- 실수형 데이터
= 실수형 데이터 타입은 32비트 부동 소수점 수와 64비트 부동 소수점 수의 유형 등으로 구분함
= 실수형 데이터 타입들은 신경망의 수치 계산에서 사용됨, 가장 중요한 데이터 타입- 16비트 고정 소수점 수의 언어적 표현
16개의 이진 자리수(비트)를 사용하여 정수부와 소수부로 표현하는 데이터 형식 - 16비트 고정 소수점 수의 공간에서 표현
- 부동 소수점 수의 등장
고정 소수점 수의 방식의 문제점을 해결하기 위해 부동 소수점 수가 등장함
부동 소수점 수는 숫자를 정규화하여 가수부와 자수부로 나누어 표현하는 방식
- 32비트 부동 소수점 수의 언어적 표현
32개의 이진 자리수(비트)를 사용하여 가수부와 지수부로 표현하는 데이터 형식
32비트 부동 소수점 수의 공간에서 표현
부호는 1bit 지수부는 8bit 가수부는 23bit
32비트 부동 소수점 수의 코드 표현:dtype = torch.float32또는dtype=torch.float - 64비트 부동 소수점 수의 언어적 표현
64개의 이진 자리수(비트)를 사용하여 지수부와 가수부로 표현하는 데이터 형식
공간에서 표현 1bit 부호 11bit 지수부 52bit 가수부
코드 표현 :dtype=torch.float64또는dtype=torch.double
- 16비트 고정 소수점 수의 언어적 표현
- 타입 캐스팅이란
= PyTorch에서 타입 캐스팅은 한 데이터 타입을 다른 데이터 타입으로 변환하는 것을 의미함
딥러닝에서 모델의 매개변수, gradient를 저장할 때 메모리를 줄여줌- 타입 캐스팅의 코드 표현
i = torch.tensor([2,3,4], dtype = torch.int8)과 같이 Tensor를 생성했을 때,
32비트 부동 소수점 수로 변환하는 코드 표현
j = i.float()
64비트 부동 소수점 수로 변환하는 코드 표현
k = i. double()
- 타입 캐스팅의 코드 표현
- 정리
PyTorch의 데이터 타입- PyTorch에서 데이터 타입(dtype)은 Tensor가 저장하는 값의 데이터 유형을 의미한다. (정수형, 실수형)
- PyTorch에서 타입 캐스팅은 한 데이터 타입을 다른 데이터 타입으로 변환하는 것을 의미한다.
2) Tensor의 기초 함수 및 메서드
- Tensor의 요소를 반환하거나 계산하는 함수
min()함수의 언어적 표현
PyTorch의 min() 함수는 Tensor의 모든 요소들 중 최소값을 반환하는 함수min()함수의 공간에서 표현
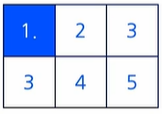
max()함수의 언어적 표현
PyTorch의 max() 함수는 Tensor의 모든 요소들 중 최대값을 반환하는 함수max()함수의 공간에서 표현
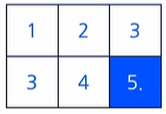
sum()함수 : Tensor의 모든 요소들의 합prod()함수 : Tensor의 모든 요소들의 곱mean()함수 : Tensor의 모든 요소들의 평균var()함수 : Tensor의 모든 요소들의 표본분산 (variance)std()함수 : Tensor의 모든 요소들의 표본표준편차 (standard division)
- 표본분산이란
- 표본이란
= 과학적인 방법으로 모집단에서 추출한 일부 데이터의 집합
모집단이란
= 연구 또는 조사에서 관심의 대상이 되는 전체 집단을 의미함 - 표본분산이란
데이터의 분포 정도를 나타내는 통계량
데이터가 평균값을 중심으로 얼마나 퍼져 있는지를 묘사함 - 표본표준편차 = 루트 포본분산값
제곱근 (분산을 계산할 때 제곱을 하는데 이를 상쇄하기 위함) - 표본분산의 수식 표현
데이터 변동성을 측정하는 중요한 지표
전체 표본의 개수에서 1을 뺐을 때 더 정확한 분산이 도출됨 이를 자유도라고 함
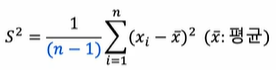
- 표본분산 계산의 예(1,3,5,7,9 -> 포본분산 = 10)
I = torch.tensor([[1,2,3], [4,5,6]]) torch.min(I) torch.max(I) torch.sum(I) torch.prod(I) torch.mean(I) torch.var(I) torch.std(I) - 표본이란
- Tensor의 특성을 확인하는 메서드의 코드 표현
- Tensor 'I'의 차원의 수 확인
I.dim() - Tensor의 크기(모양)를 확인
I.size()또는I.shape(메서드가 아닌 속성) - Tensor 'I'에 있는 요소의 총 개수를 확인
I.numel()number of element의 약자. 요소의 총 개수 (6개)
- Tensor 'I'의 차원의 수 확인
- 정리
- Tensor의 요소를 반환하거나 계산하는 함수의 코드 표현으로
torch.min(),torch.max(),torch.sum(),torch.prod(),torch.mean(),torch.var(),torch.std() - Tensor의 특성을 확인하는 메서드의 코드 표현으로
dim(),size(),shape(속성),numel()등이 있다.
- Tensor의 요소를 반환하거나 계산하는 함수의 코드 표현으로
Future Action
- ☑️ 온보딩 클래스 파이썬 강의, 프리코스 선형대수학, 부스트코스 확률론을 수강해야된다.
- ☑️ 온보딩 클래스 DL 강의를 좀 더 꼼꼼히 들어야겠다.
- ☑️ 논문 리뷰: RNN-Seq2seq-Attention-transformer-LLM 순으로 된 논문/논문리뷰를 찾아봐야겠다.
- ☑️ 주말에 복습할 수 있도록 TIL WIL을 잘 정리해두어야겠다.
- ☑️ 이전 기수의 캠퍼들의 회고를 꼼꼼히 찾아봐야겠다.
- ☑️ PyTorch Github, Twitter, Tutorials 방문/조사하기
- ☑️ 기초다지기 강의 3. 기초수학첫걸음 (전체) 공부하기
Day 2✍️
08-06-TUEDay 2✍️✨ Tensor 생성과 조작 ✨
TIL
Creating Tensors
- 키워드 :
연속균등분포,표준정규분포,CPU Tensor,GPU/CUDA
Tensor의 생성
-
1) 특정한 값으로 초기화된 Tensor 생성
- 0으로 초기화된 Tensor를 생성하는 표현

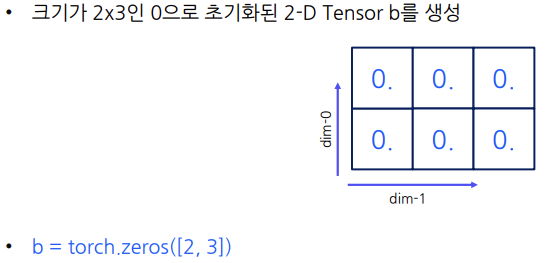 (
(dim-0은 행차원,dim-1은 열차원)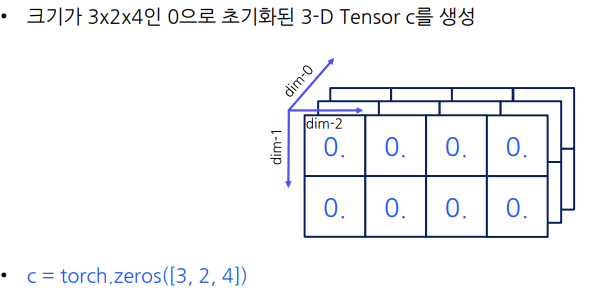 (
(dim-0은 depth차원,dim-1은 행차원,dim-2은 열차원) - 1로 초기화된 Tensor를 생성하는 표현
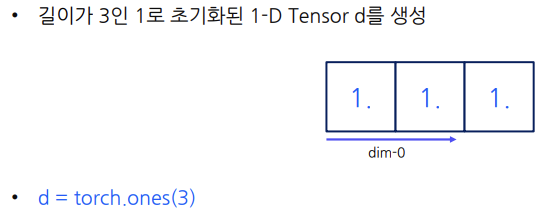
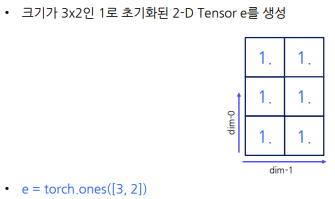
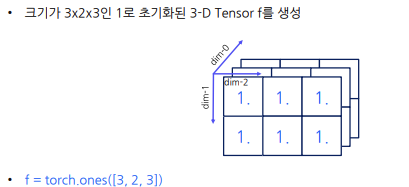
- 0으로 초기화된 Tensor를 생성하는 표현
-
2) 특정한 값으로 초기화된 Tensor 변환
- 크기와 자료형이 같은 0으로 초기화된 Tensor로 변환하는 표현
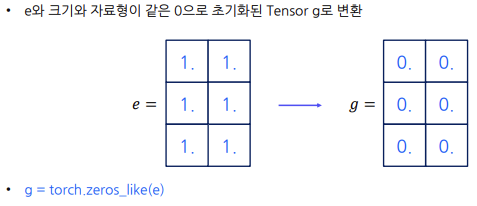 (! 메모리 주소는 변화하지 않는다/AI에서 메모리는 모델의 성능과도 연결이 됨)
(! 메모리 주소는 변화하지 않는다/AI에서 메모리는 모델의 성능과도 연결이 됨) - 크기와 자료형이 같은 1로 초기화된 Tensor로 변환하는 표현
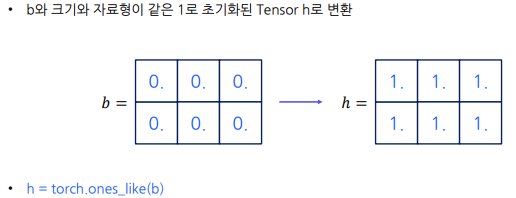
- 크기와 자료형이 같은 0으로 초기화된 Tensor로 변환하는 표현
-
3) 난수로 초기화된 Tensor 생성
-
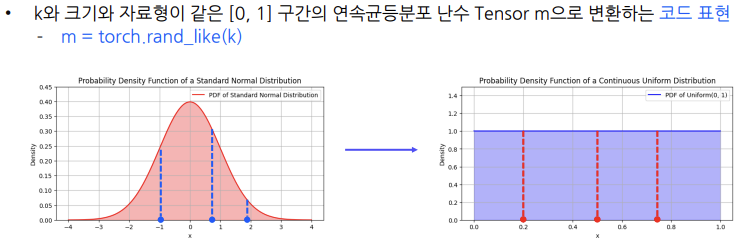
[0,1] 구간의 연속균등분포 난수 Tensor 생성
0~1 사이의 연속균등분포에서 추출한 난수로 채워진 특정 크기의 Tensor를 생성하는 코드 표현i = torch.rand(3) j = torch.rand([2, 3]) -
[0,1] 구간의 연속균등분포란?
= 연속균등분포란 특정한 두 경계값 사이의 모든 값에 대해 동일한
확률을 가지는 확률분포
= [0,1] 구간의 연속균등분포에서 특정한 두 경계값은 0과 1
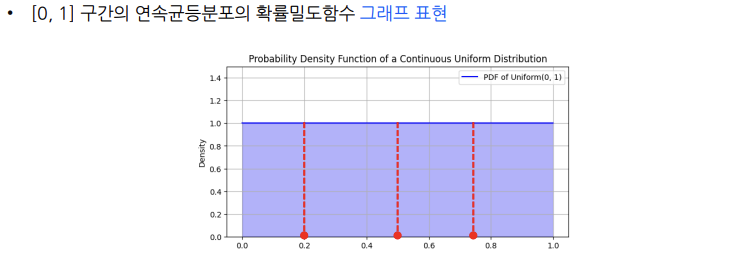
-
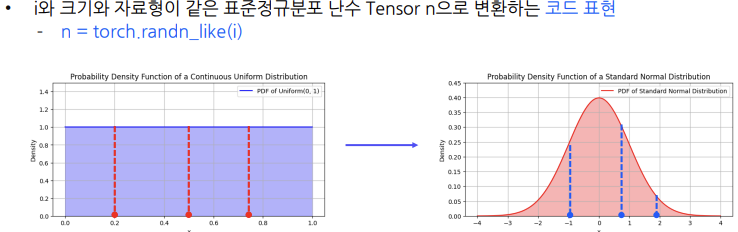
표준정규분포 난수 Tensor 생성
표준정규분포에서 추출한 난수로 채워진 특정 크기의 Tensor를 생성하는 코드 표현
randn()(random normal함수)k = torch.randn(3) l = torch.randn([2, 3]) -
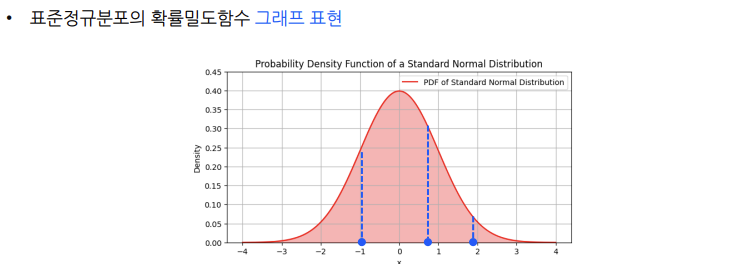
표준정규분포란?
= 표준정규분포란 평균이 0이고 표준편차가 1인 종 모양의 곡선
= 표준정규분포는 평균 0을 중심으로 좌우 대칭인 종모양을 가지기 때문에,
평균, 중앙값, 최빈값이 모두 0
-
크기와 자료형이 같은 [0, 1] 구간의 연속균등분포 난수 Tensor로 변환
-
-
4) 지정된 범위 내에서 초기화된 Tensor 생성
 (
(arange()= array range의 약자)
start: tensor의 시작값, end: tensor의 끝값, step: tensor의 간격
dtype = int64 dtype = float32
dtype = float32
-
5) 초기화 되지 않은 Tensor 생성
‘초기화 되지 않았다’는 것은 생성된 Tensor의 각 요소가 명시적으로
0, 1, 2 등과 같은 다른 특정 값으로 설정되지 않았음을 의미함
초기화 되지 않은 Tensor를 생성할 때, 해당 Tensor는 메모리에 이미
존재하는 임의의 값들로 채워짐- 초기화 되지 않은 Tensor를 사용하는 이유
• 성능 향상: Tensor를 생성하고 곧바로 다른 값들로 덮어쓸 예정인 경우라면,
초기 값을 설정하는 단계는 불필요한 자원을 소모하는 것임
• 메모리 사용 최적화: 큰 Tensor를 다룰 때, 불필요한 초기화는 메모리 사용량을 증가시킴
초기화되지 않은 Tensor를 사용함으로써 메모리 할당 후 즉시
필요한 계산에 사용하여 메모리 효율성을 높일 수 있음 - 초기화 되지 않은 Tensor를 생성하는 표현

- 초기화 되지 않은 Tensor에 다른 데이터로 수정하는 표현

- 초기화 되지 않은 Tensor를 사용하는 이유
-
6) list, Numpy 데이터로부터 Tensor 생성
-
list 데이터로부터 Tensor를 생성하는 코드 표현
• Python의 list는 여러 값을 순차적으로 저장할 수 있는 가변적인 컨테이너 데이터타입
• list는 대괄호 ‘[ ]’ 안에 쉼표로 구분한 요소들을 채워 생성할 수 있음
• s = [1, 2, 3, 4, 5, 6]의 list를 생성했을 때, s를 Tensor t로 생성하는 코드 표현t = torch.tensor(s) -
Numpy 데이터로부터 Tensor를 생성하는 코드 표현
• Numpy는 C언어로 구현된 Python 핵심 과학 컴퓨팅 라이브러리
– 대규모 다차원 배열 연산을 지원
– 배열을 효율적으로 조작할 수 있는 높은 수준의 수학 함수를 제공
• Numpy와 list의 코드 표현은 외형적으로 비슷해 보이나, Numpy는 대규모 수치 데이터 연산 또는 조작에 있어 적합한 반면, list는 그렇지 못함u = np.array([[0, 1], [2, 3]])/u = [[0, 1], [2, 3]]
• u = [[0, 1], [2, 3]]의 Numpy 2-D Matrix를 생성했을 때, u를 Tensor v로 생성하는 코드 표현v = torch.from_Numpy(u)
• Numpy로부터 생성된 Tensor는 기본적으로 정수형이므로 실수형으로 타입 캐스팅이 필요함v = torch.from_Numpy(u).float()
-
-
7) CPU Tensor 생성
w = torch.IntTensor([1, 2, 3, 4, 5]) A, B, C, D, E = 1, 2, 3, 4, 5 w = torch.IntTensor([A, B, C, D, E]) x = torch.FloatTensor([A, B, C, D, E]) torch.ByteTensor # 8비트 부호 없는 정수형 CPU Tensor 생성 torch.CharTensor # 8비트 부호 있는 정수형 CPU Tensor 생성 torch.ShortTensor # 16비트 부호 있는 정수형 CPU Tensor 생성 torch.LongTensor # 64비트 부호 있는 정수형 CPU Tensor 생성 torch.DoubleTensor # 64비트 부호 있는 실수형 CPU Tensor 생성 -
Tensor를 복제하는 코드 표현
x = torch.tensor([1, 2, 3, 4, 5, 6])와 같이 Tensor를 생성했을 때,
y = x.clone()또 다른 Tensor를 복제하는 코드 표현
x = torch.tensor([1, 2, 3, 4, 5, 6])와 같이 Tensor를 생성했을 때,
z = x.detach()
• x.clone() 메서드와 다른 점은 x를 계산그래프에서 분리하여 새로운 Tensor z에 저장한다는 것 (detach()자동미분을 배울 때 중요한 함수) -
8) CUDA Tenor 생성과 변환
Pytorch의 가장 큰 장점- GPU란
GPU(Graphics Processing Unit) 그래픽 처리 장치
원래는 컴퓨터 그래픽스를 렌더링하는데 사용되도록 설계되었음
컴퓨터 그래픽스 렌더링이란 컴퓨터를 사용하여 이미지를 생성하는 과정
• 현재는 AI 연구 및 개발에 있어 대규모 데이터 처리와 복잡한 계산을 위해 사용 - AI 분야에서 GPU를 사용해야하는 이유
• 병렬 처리 능력: GPU는 수 천 개의 작은 코어를 가지고 있어 병렬 데이터 처리에 매우 효율적임. 즉, 대량의 연산을 동시에 수행할 수 있게 함
• 속도: GPU의 병렬 처리 능력은 AI 모델의 훈련과 추론 속도를 크게 향상시킴(T4-8Q: 엔비디아의 테슬라T4 GPU의 하나의 설정이다. 구글 코랩에서 제공하는 GPU 환경중 하나. 빠른 처리속도. 뛰어난 성능)
• 경제적 이점: 초기에는 높은 비용이 들 수 있으나, GPU를 사용하면 시간 단축과 에너지 절약으로 인해 장기적인 투자 대비 높은 수익을 얻을 수 있음 - 디바이스를 확인하기
CUDA란 Nvidia가 개발한 병렬 컴퓨팅 플랫폼과 프로그래밍 모델로서, 개발자가 Nvidia의 GPU를 활용하여 고도의 계산 처리를 수행할 수 있게 도와준다. 이를 통해 우리는 복잡한 과학적 계산이나 엔지니어링 문제를 효율적으로 해결할 수 있다.
• Tensor가 현재 어떤 디바이스에 있는지 확인하는 코드 표현a = torch.tensor([1, 2, 3]) a.device - CUDA 사용가능 환경 확인
• CUDA 기술을 사용할 수 있는 환경인지 확인하는 코드 표현
torch.cuda.is_available()
• CUDA device 이름을 확인하는 코드 표현
torch.cuda.get_device_name(device=0) - Tensor를 GPU에 할당
• Tensor를 GPU에 할당하는 코드 표현
b = torch.tensor([1, 2, 3, 4, 5]).to(‘cuda’)
b = torch.tensor([1, 2, 3, 4, 5]).cuda() - GPU에 할당된 Tensor를 CPU Tensor로 변환
• GPU에 할당된 Tensor를 CPU Tensor로 변환하는 코드 표현
c = b.to(device = ‘cpu’)
c = b.cpu()
- GPU란
정리 - Tensor의 생성
- 0, 1과 같은 특정한 값으로 초기화된 Tensor를 생성하는 함수로
torch.zeros(),torch.ones()가 있다 - [0,1] 구간의 연속균등분포, 표준정규분포에서 추출한 난수로 채워진 Tensor를 생성하는 함수로
torch.rand(),torch.randn()이 있다. - 지정된 범위 내에서 초기화된 Tensor를 생성하는 함수로
torch.arange(start, end,step)가 있다. - 초기화 되지 않은 Tensor를 생성하는 함수로
torch.empty()가 있으며,fill_()메서드로 데이터를 수정할 수 있다. - Numpy 데이터로부터 Tensor를 생성하는 함수로
torch.from_numpy()가 있다. - 정수형 및 실수형 CPU Tensor를 생성하는 함수로
torch.IntTensor(),torch.FloatTensor()가 있다. - Tensor를 복제하는 메서드로
clone(),detach()가 있다.
(참고)clone: Tensor의 복사본을 만듭니다. 원본과는 별도의 메모리를 사용하여 독립적으로 존재합니다.detach: Tensor를 연산 그래프에서 분리합니다. 원본 Tensor와 데이터를 공유하지만, 그래디언트 계산이 되지 않습니다.
t.clone()이 아니라t.detach()는 Tensor ‘t’를 복제하면서 계산그래프에서 분리된 새로운 Tensor를 반환합니다. - Tensor를 GPU에 할당하는 메서드로
to('cuda'),.cuda()가 있다.
Manipulation of Tensors
- 키워드 : Tensor의 indexing, slicing, 모양변경, 평탄화, 차원축소와 확장
Tensor의 인덱싱과 슬라이싱
- 1) Tensor의 indexing & slicing
- 1-D Tensor의 indexing 표현
- 1-D Tensor의 slicing 표현
정리 - Tensor의 인덱싱과 슬라이싱
- indexing이란 Tensor의 특정 위치의 요소에 접근하는 것을 의미한다.
- slicing란 부분집합을 선택하여 새로운 Sub Tensor 생성하는 과정을 의미한다.
Tensor의 모양변경1
-
2) view() 메서드를 활용한 Tensor의 모양변경
- 단, view() 메서드는 Tensor의 메모리가 연속적으로 할당된 경우에 사용이 가능함
- 연속적 메모리 할당의 예시
2-D Tensor를 생성했을 때
PyTorch는 해당 Tensor의 데이터 타입과 차원 정보에 기반하여, 컴퓨터 메모리에서 충분한 공간을 할당 받아 데이터를 저장함 - 연속적 메모리 할당의 시각적 표현
- 메모리 레이아웃의 변화로 인한 비연속적 메모리 할당
- Tensor의 메모리가 연속적 또는 비연속적으로 할당되었는지를 확인하는 코드 표현
c.is_contiguous()
d.is_contiguous()
True or False - view()
f.torch.arange(12)
g = f.view(4,3)org = f.view(4, -1)(- 열을 모를 때)
Q. 행을 모를 때?g = f.view(-1, 3)
h = f.view(3, 2, 2) h = f.view(3, 2, -1) (depth, 행, 열)
-
3) flatten() 함수를 활용한 Tensor의 평탄화
- Tensor를 평탄화하는 모양변경 방법으로 flatten() 함수를 활용할 수 있음
- 다차원 데이터를 처리할 때 유용하며, 데이터를 신경망 모델에 적합한 전처리하기 위해 많이 활용함
- 1-D Tensor로 평탄화 j = torch.flatten(i) or i.flatten()
-
4) reshape() 메서드를 활용한 Tensor의 모양변경
- view() 메서드와는 달리 메모리가 연속적이지 않아도 사용 가능함
reshape() 메서드는 안전하고 유연성이 좋다는 장점이 있으나 성능 저하의 단점 있음 메모리 연속성이 확실하고 성능이 중요한 경우 view() 메서드를 사용하는 것이 좋음
- view() 메서드와는 달리 메모리가 연속적이지 않아도 사용 가능함
-
5) transpose() 메서드를 활용한 Tensor의 모양변경

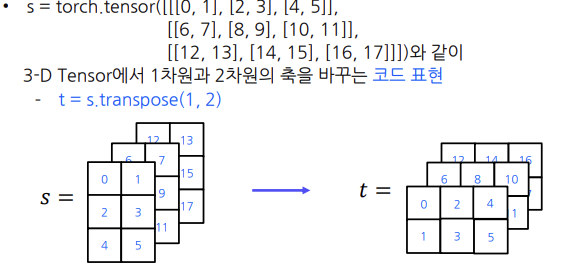
-
6) stack() 함수를 활용한 Tensor들 간의 결합
정리 - Tensor의 모양변경1
- Tensor의 모양을 변경하는 메서드
view()reshape() - 평탄화
flatten() - 두 차원의 축을 서로 바꿈
transpose() - 차원 축소
squeeze()차원 확장unsqueeze() - tensor들을 결합
stack()
Future Action
- ☑️ 수업을 더 빨리 듣자
- ☑️ 아침에 일찍 일어나서 기초다지기를 빨리 듣자
- ☑️ WIL 을 잘 작성할 수 있게 하자
- ☑️ 멘토님 조언에 따라 백엔드 스터디를 하면 좋겠다(js, spring)
- ☑️ 피어세션 때 가만히 있다가 뒷북치지 말자. 리액션 더 많이 하자. 그리고 미리 말할 걸 생각/정리해가자. 적극적으로 말하자. 어제보다는 그래도 조금 더 친해진 것 같다. 물론 내적 친밀감.. 근데 좀 더 정신차리고 적극적으로 편안한 마음가짐으로 임하자.
Feedback (피드백: 앞서 정한 향후 행동을 실천해본뒤, 이에 대해 어떤 피드백을 받았나?)
- ☑️ 온보딩 클래스 파이썬 강의
- ✅ 프리코스 선형대수학
- ☑️ 부스트코스 확률론 수강
- ☑️ 온보딩 클래스 DL 강의를 좀 더 꼼꼼히 들어야겠다.
- ☑️ 논문 리뷰: RNN-Seq2seq-Attention-transformer-LLM 순으로 된 논문/논문리뷰를 찾아봐야겠다.
- ✅ 주말에 복습할 수 있도록 TIL WIL을 잘 정리해두어야겠다.
- ☑️ 이전 기수의 캠퍼들의 회고를 꼼꼼히 찾아봐야겠다.
- ☑️ PyTorch Github, Twitter, Tutorials 방문/조사하기
- ✅ 기초다지기 강의 3. 기초수학첫걸음 (전체) 공부하기
Day 3🏄🏻♀️
08-07-WEDDay 3🏄🏻♀️✨ Tensor 연산 및 심화 ✨
- Basic Operations
- Tensor Operations
- (7강) Linear Regression1
TIL
(5강) Basic Operations
- in-place 방식의 연산은 어떻게 메모리를 절약할 수 있는 것일까요?
Tensor의 모양변경2
- cat() 함수를 활용한 Tensor들 간의 연결
stack() 함수는 새로운 차원을 생성해서 Tensor들을 결합하는데,
cat() 새로운 차원을 추가하는 것이 아닌 기존의 차원을 유지하면서 Tensor들을 연결한다.
텐서들은 차원이 같아야 함
dim=0 방향 연결
dim=1 방향 연결 : 두 텐서의 행의 개수가 다르면 에러 -> reshape() 메서드 사용하여 행의 개수를 같게 만들어준다. - expand() 메서드를 활용한 Tensor의 크기 확장
f = torch.tensor([[1,2,3]]) # 2차원 텐서
g = f.expand(4,3) - repeat() 메서드를 활용한 Tensor의 크기 확장
장점: 차원 중 일부의 크기가 1이어야 한다는 제약이 없음
단점: 추가 메모리를 할당하기 때문에 메모리를 할당하지 않는 expand() 메서드보다 메모리 효율성이 떨어짐
퀴즈! repeat 메서드는 view만을 생성하기 때문에 expand 메서드보다 메모리 효율성이 좋다> (X)
해설) repeat 메서드는 실제 복사본을 형성함. expand 메서드는 가상으로 view를 생성함. 따라서 repeat 메서드는 expand 메서드보다 메모리 효율성이 떨어짐기억할 것: expand 함수는 차원의 크기가 1인 차원에 대해서만 확장해주는 메서드
- 학습정리
• cat() 함수를 활용하면 차원의 축방향에 따라 Tensor들을 연결할 수 있다.
• expand() 메서드를 활용하면 주어진 Tensor의 차원 중 일부의 크기가 1일 때, 해당 차원의 크기를
확장할 수 있다.
• repeat() 메서드를 활용하면 Tensor의 요소들을 반복하는 방식으로 크기를 확장할 수 있다
Tensor의 기초 연산
-
Tensor의 산술연산
- 더하기 연산
torch.add(a,b)저장되는 메모리 공간이 다름 (a, b, a+b)
in-place 방식: 메모리 절약 a에 b를 in-place 방식으로 a를 수정a.add_(b)
추가적인 메모리 할당이 필요x but, 이후 autograd와의 호환성 측면에서 문제!! -> 신중히 사용
크기가 다른 Tensor의 더하기 연산torch.add(a,b). 프로그래밍에서는 브로드캐스팅에 의해 b가 자동으로 행 차원이 확장됨 - 빼기 연산
torch.sub(e,f)f.sub_(e)
크기가 다른 Tensor의 빼기 연산 크기가 작은 것이 확장된 후에 연산이 이루어짐
torch.sub(e,f) - 스칼라곱 연산
실수 곱하는 연산torch.mul(i, j)
요소별 곱하기 연산(Hadamard product, Element wise product)
torch.mul(k, l)ork.mul_(l)
크기가 다른 Tensor의 요소별 곱하기 연산torch.mul(m, n) - 요소별 나누기 연산
torch.div(o, p)o.div_(p) - 요소별 거듭제곱 연산 n제곱
torch.pow(s, n)t.pow_(u) - 요소별 거듭제곱근 연산 n제곱근
torch.pow(s, 1/n)
- 더하기 연산
-
Tensor의 비교연산
torch.eq(v, w): 두 텐서의 대응요소들이 같은가 결과는 boolean텐서(각 요소마다 출력됨)torch.ne(v, w): 두 텐서의 대응요소들이 다른지 (not equal)torch.gt(v, w): v의 요소들이 w의 대응요소보다 큰지 (greater than)torch.ge(v, w): 크거나 같은지 (greater or equal)torch.lt(v, w): 작은지 (less than)torch.le(v, w): 작거나 같은지 (less or equal)
-
Tensor의 논리연산
기초논리- 논리 연구란 타당하지 않은 논증으로부터 타당한 논증을 구별하는 데 사용되는 원리와
방법을 의미함(Lin & Lin, 1973)
• 이러한 논리는 전문적으로 사용되고 있는 용어 “명제”로부터 시작함
• 명제란 참, 거짓 중 어느 한 경우이되 동시에 양쪽은 아닌 서술문(주장)을 뜻함(Lin & Lin, 1973)
– 2+1은 3과 같다(참인 명제)
– 2>3(거짓인 명제)
– 새우버터구이는 맛있다(명제 X) - 논리곱, 논리합, 배타적 논리합
- 논리곱(AND) T & T = T 나머지는 F
torch.logical_and(x, y) - 논리곱(OR) 하나라도 T면 T
torch.logical_or(x, y) - 배타적 논리합(XOR) 둘 중 하나만 T일 때 T (T ⨁ T = F 이다)
torch.logical_xor(x, y)
- 논리 연구란 타당하지 않은 논증으로부터 타당한 논증을 구별하는 데 사용되는 원리와
-
학습정리
• Tensor들의 요소별 산술연산 방법에는 함수 방식과 in-place 방식이 있다.
• Tensor들 간의 요소들을 비교할 수 있는 비교연산으로 torch.eq(), torch.ne(), torch.gt(), torch.ge(), torch.lt, torch.le() 등이 있다.
• 명제를 포함하고 있는 Tensor들의 논리를 연산할 수 있는 방법으로 논리곱, 논리합, 배타적 논리합 등이 있다.
Tensor Operations
- 키워드 : L1 노름, L2 노름, L∞ 노름, 맨해튼 유사도, 유클리드 유사도, 코사인 유사도
1) Tensor의 노름
-
1-D Tensor 복습
 텐서의 크기 = 요소의 개수 a.shape 또는 a.size()
텐서의 크기 = 요소의 개수 a.shape 또는 a.size()
?! 두 텐서를 비교할 때 요소의 개수가 더 많다고 해서 크기가 더 크다고 얘기할 수 없다 -
노름이란
= 1-D Tensor의 노름: Vector가 원점에서 얼마나 떨어져 있는지를 의미함
L1 노름, L2 노름, L∞ 노름 여러 노름 존재
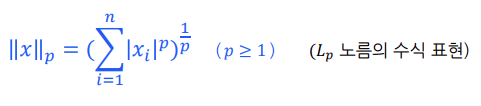
-
Ln 노름
L1 노름 : 요소의 절댓값의 합, 맨해튼 노름.torch.norm(a, p=1)(a는 Tensor)
L2 노름 : 요소의 제곱합의 제곱근, 유클리드 노름.torch.norm(a, p=2)
L∞ 노름 : [L infinity] 포함된 요소의 절댓값 중 최댓값. ,
torch.norm(a, p=float('inf'))ortorch.max(a.abs()) -
노름에 따른 기하학적 의미
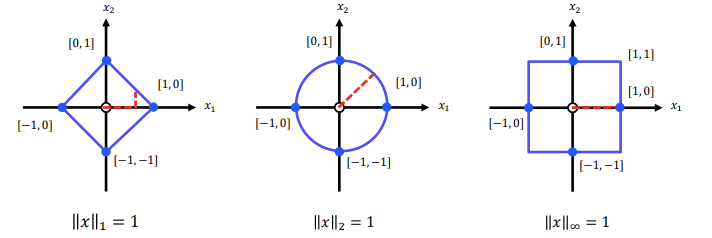
L1은 요소의 절댓값의 합, L2는 요소의 제곱합의 제곱근, L∞는 텐서의 요소 중 최댓값
나중에 성능을 평가할 때 사용됨 -
학습정리
• 1-D Tensor의 노름은 Vector가 원점에서 얼마나 떨어져 있는지를 의미한다.
• L1 노름은 1-D Tensor에 포함된 요소의 절대값의 합으로 정의할 수 있다.
• L2 노름은 1-D Tensor에 포함된 요소의 제곱합의 제곱근으로 정의할 수 있다.
• L∞ 노름은 1-D Tensor에 포함된 요소의 절대값 중 최대값으로 정의할 수 있다.
2) 유사도
- 유사도란
두 1-D Tensor가 얼마나 유사한지 측정값
군집화(비지도 학습) 알고리즘에서 데이터가 얼마나 유사한지의 기준으로 사용 - 맨해튼 유사도
두 1-D Tensor 사이의 멘해튼 거리를 역수로
거리 값이 작을 수록 유사도 값은 커짐
유사도가 1에 가까울 수록 두 텐서는 유사함
수식: 두 텐서가 일치할 경우 거리가 0이 되기 때문에 1을 더함
두 텐서가 일치할 경우 거리가 0이 되기 때문에 1을 더함
코드: 거리manhattan_distance = torch.norm(b-c, p=1)유사도1/(1+manhattan_distance) - 유클리드 유사도
두 1-D Tensor 사이의 유클리드 거리를 역수로 변환
유사도가 1에 가까울 수록 두 텐서는 유사함
수식:
코드:euclidean_distance=torch(b-c, p=2)유사도1/(1+euclidean_distance) - 코사인 유사도
두 텐서 사이의 각도를 측정한 값
how? 1차원 텐서의 내적을 활용
내적을 구하는 방법: 두 1-D 텐서의 각 요소를 곱해서 더하기/두 1-D 텐서의 길이를 곱한다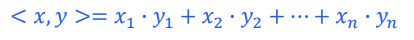
내적 코드: torch.dot(b, c)
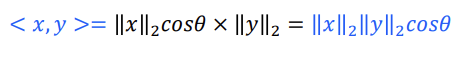
수식:
유사도 코드:cosine_similarity = torch.dot(b, c) / (torch.norm(b, p = 2) * (torch.norm(c, p = 2)) - 학습정리
유사도
• 유사도(Similarity)란 두 1-D Tensor(=Vector)가 얼마나 유사한지에 대한 측정값을 의미한다.
• 맨해튼 유사도는 두 1-D Tensor 사이의 맨해튼 거리를 역수로 변환하여 계산한 값이다.
• 유클리드 유사도는 두 1-D Tensor 사이의 유클리드 거리를 역수로 변환하여 계산한 값이다.
• 코사인 유사도는 두 1-D Tensor 사이의 각도를 측정하여 계산한 값이다
3) 2-D Tensor 행렬 연산
- 2-D Tensor 행렬 곱셈 연산
딥러닝에서 중요
대수적 표현: 두 행렬 사이의 행벡터 열벡터 사이의 내적
앞의 열, 뒤의 행의 개수가 같아야
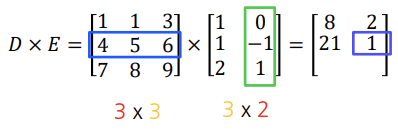
코드: D.matmul(E), D.mm(E), D @ E (matrix multiplication의 줄임) - 2-D Tensor 행렬 곱셈 연산 활용
흑백 이미지의 대칭 이동: 주어진 축을 기준으로 이미지를 뒤집는 변환을 의미함
• 그렇다면 흑백 이미지의 상하로 대칭 이동은 어떤 축을 기준으로 이미지를 뒤집는 변환일까요?
• 또한, 흑백 이미지를 상하로 대칭 이동시키기 위해서는 어떤 행렬을 어떻게 곱셈해야 할까요? - 학습정리
• 2-D Tensor(=Matrix)의 행렬 곱셈은 두 행렬을 결합하여 새로운 행렬을 생성하는 연산이다.
• 흑백 이미지 처리에서 행렬의 곱셈 연산을 사용하면 대칭 이동을 수행할 수 있다
- Further reading
Lp 노름에 대한 수학적 정의 중 The p-norm in finite dimensions 부분을 읽으면, Lp 노름에 대한 엄밀한 정의를 찾아보실 수 있다.

Linear Regression 1
- 키워드: 선형 회귀 분석, 상관관계, 클래스와 인스턴스, 손실 오차
1) 선형 회귀 모델
- 선형 회귀의 의미
주어진 트레이닝 데이터를 사용하여 특징 변수와 목표 변수 사이의 선형 관계를 분석하고,- 주어진 트레이닝 데이터: YearsExperience(연차)에 따른 임금(Salary) 데이터셋
- 특징 변수: YearsExperience
- 목표 변수: Salary
- 트레이닝 데이터
트레이닝 데이터의 대응표
코드 표현 !kaggle datasets download -d abhishek14398/salary-dataset-simple-linear-regression
다운로드한 파일의 압축을 해제하는
!unzip salary-dataset-simple-linear-regression.zip
데이터 불러오기 data = pd.read_csv("Salary_dataset.csv", sep=',', header=0)
트레이닝 데이터의 특징 변수와 목표 변수를 분리하는 코드 표현
x = data.iloc[:, 1].values (-> Integer location의 약자)
t = data.iloc[:, 2].values - 상관 관계 분석
선형 관계를 파악하기 위해 상관 관계를 파악. 그 관계가 양의 관계인지 음의 관계인지.
높은 상관 관계를 가지는 특징 변수들을 파악(다중 선형 회귀 모델에서 필요)
np.corrcoef(x, t) - 선형 회귀 모델에서의 학습
• 선형 회귀란 ① 주어진 트레이닝 데이터를 사용하여 ② 특징 변수와 목표 변수 사이의 선형 관계를 분석하고, ③ 이를 바탕으로 모델을 학습시켜
• 선형 회귀 모델에서 학습이란 주어진 트레이닝 데이터의 특성을 가장 잘 표현할 수 있는 직선 𝑦 = 𝑤𝑥 + 𝑏의 기울기(가중치) 𝑤와 𝑦절편(바이어스) 𝑏를 찾는 과정을 의미함 - 신경망 관점에서의 선형 회귀 모델
신경망 관점에서 선형회귀 모델은 입력층의 특징 변수가 출력층의 예측 변수로 사상(mapping)되는 과정이라고 할 수 있음
입력층: 특징 변수들을 포함
Feedback
- 파이썬 공부 해야되는데.. 언제 하지? ㅜㅜ
- 말을 해야 하는데 말이 안나온다..
Day 4⛺
08-08-THUDay 4⛺✨ 04. 선형회귀, 05. 이진 분류✨
- Linear Regression 2
- Binary Classification
TIL
Linear Regression
[노션] 선형 회귀
Binary Classification
[노션] 이진 분류
FEEDBACK
- 과제가 남았다.. ㅡ.ㅡ
- 내일은 심화과제랑 Wrap-up 퀴즈 풀자.
- 예전보다 생각이 많~이 느려진 걸 느낀다.. 할말도 없고.. 아는게 없는 게 크다. 공부를 많이 하는 수밖에 없다… 근데 너무 어렵다..
- 아침에 공복 유산소 자세까지 정확하게 했다 굳
- 데일리 스크럼 때 늦을 뻔 했다.. 정신차리자
- 팀원들 덕분에 자극받아서 열심히 했다.
- 1년동안 못한걸 4일안에 할 수 있는 환경이라니.. 나한텐 정말 ㄹㅇ로 감사한 환경이다.
Day 5👩🏻💻
2024-08-09Day 5👩🏻💻
- 심화과제
- wrap-up 퀴즈
TIL
1) 심화과제하면서 배운 것
__init__함수는 인스턴스 초기화 함수__call__함수는 인스턴스가 호출됐을 때 실행되는 함수tensor.clamp()함수 : 입력으로 들어오는 모든 값들을 범위 안으로 조정해주는 역할- MLP 를 linear 레이어 2개와 활성화함수 Relu를 이용해 만들었다.
# MLP를 정의합니다. 이 모델은 선형 레이어와 ReLU 활성화 함수를 이용하여 구성됩니다.
class WithoutNNMLP:
def __init__(self, in_features, hidden_features, out_features):
self.linear1 = WithoutNNLinear(
in_features, hidden_features
) # 첫 번째 선형 레이어
self.relu = WithoutNNReLU() # ReLU 활성화 함수
self.linear2 = WithoutNNLinear(
hidden_features, out_features
) # 두 번째 선형 레이어
# 이 메소드는 입력 x를 받아서 모델을 통과시킨 후 출력을 반환합니다.
def __call__(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
return x
# 이 메소드는 모델을 특정 디바이스로 이동시킵니다.
def set_device(self, device):
self.linear1.set_divce(device)
self.linear2.set_divce(device)
# 이 메소드는 모델의 파라미터를 반환합니다.
def parameters(self) -> list:
"""
반환값:
list: 모델의 가중치와 편향 텐서를 포함하는 리스트.
"""
return self.linear1.parameters() + self.linear2.parameters()-
첫번째 선형 레이어는 in_features, hidden_features 두번째 선형 레이어는 hidden_features, out_features이다.
-
.set_device(device)함수는 모델을 특정 디바이스로 이동시킨다. -
def parameters(self) -> list:에서와 같이 화살표(->)의 경우, 해당 함수의 return 값의 형태에 대한 주석 -
CrossEntropyLoss
# Cross Entropy 손실 함수를 정의합니다. 이 함수는 출력과 타겟을 받아서 손실을 계산합니다.
class WithoutNNCrossEntropyLoss:
def __init__(self, reduce="mean"):
self.reduce = reduce
# 이 메소드는 출력과 타겟을 받아서 손실을 계산합니다.
def __call__(self, output, target):
return -torch.log_softmax(output, dim=1)[range(target.size(0)), target].mean()softmax이 함수는 입력을 확률 분포로 변환한다. 출력값이 0에서 1 사이의 값으로 변환되며, 모든 값의 합이 1이 되도록 한다.log-softmaxsoftmax 출력의 로그를 취한다. 로그를 취하는 이유는 손실 함수에서 곱셈을 덧셈으로 변환해 계산을 더 쉽게 하기 위함이다.range(target.size(0))배치 내 각 샘플의 인덱스를 의미한다.target.size(0)은 배치 크기를 의미한다. 예를 들어 배치 크기가 32이면,range(32)는[0, 1, 2, ..., 31]의 범위를 제공한다.
[range(target.size(0)), target] output출력값 중에서 정답 레이블target에 해당하는 값을 선택한다.
- output은 크기
(batch_size, num_classes)를 가지는 텐서인데,range(target.size(0))는 각 샘플의 인덱스를,target은 각 샘플의 정답 클래스 인덱스를 가리킵니다. .mean()여러 샘플에 대한 손실 값을 평균내는 역할을 합니다.
이 예제에서는 reduce="mean"로 설정되어 있으므로, 최종적으로 모든 샘플에 대한 손실의 평균을 반환합니다.
모델 학습
1. 학습, 테스트 데이터 셋과 데이터 로더를 선언합니다.
2. train함수를 이용하여 모델을 학습하고 학습 loss를 반환합니다.
3. test 함수를 이용하여 모델을 평가하고 평가 loss와 accuracy를 반환합니다.
- train 함수
.requires_grad=True는 autograd 에 모든 연산(operation)들을 추적해야 한다고 알려줍니다 .
optimizer.zero_grad() # 그래디언트를 초기화합니다.
output = model(X) # 모델의 출력을 계산합니다.
loss = criterion(output, y) # loss을 계산합니다.
loss.backward() # 그래디언트를 계산합니다.
optimizer.step() # 파라미터를 업데이트합니다.
running_loss += loss.item() # loss을 누적합니다.- criterion 뜻: 기준,표준
torch.no_grad(): 그래디언트를 계산하지 않게 설정한다.
