Neural Networks
뇌 신경망을 모방하고자 하는 시스템
꼭 뇌를 따라했다고 볼 수 없다
이유: 역전파 back propagation는 인간의 뇌에서 일어나지 않는다.
사람의 뉴런, 지능을 모방하는 방법론으로 굳이 설명할 필요가 없다
날고자하는 욕망 박쥐의 날개를 모방, 1900년대 라이트 형제 비행기, 새를 모방했다고
볼 수 있지만 사실은 그렇지 않음 프로펠러, 최근에 나온 발전된 비행기는 새처럼 생기지 않음
우리가 하늘을 날고 싶다고 해서 새와 같이 움직일 수 없음
AI를 만들고 싶다고 해서 인간의 뇌를 모방할 필요는 없다
시작했을지는 모르지만 딥러닝, 뉴럴 네트워크 트렌드가 인간의 뇌와 많이 달라짐
수학적으로 분석하는 방법이 더 옳다
애매하게 사람의 뇌를 모방하는 시스템이라는 정의보다는,
"Neural networks are function approximators that stack affine
transformations followed by nonlinear transformations."
affine transformation, nonlinear transformation
이 반복적으로 일어남
담백하고 오해를 덜 살 수 있는 정의
Linear Neural Networks
- 1차원
라인에 대한 slope=기울기, y절편이 있다.
- Data:
- Model:
- Loss:
-
가장 간단한 회귀 문제 loss function은 squared loss function을 사용한다.
-
는 번째 데이터의 출력값이고
는 를 집어넣었을 때 나의 현재 모델에서 나오는 출력값이다 -
결국 나의목표는 나의 개의 데이터를 잘 설명하거나 표현할 수 있는 모델을 찾는 거니까
Neural Network의 출력값과 나의 데이터 사이의 차이를 줄이는 게 중요하다.
그 차이를 보통 라고 부른다.
어떻게 를 찾을까?
- 가 최소화되는 와 를 찾을 수 있다.
(제약조건: 데이터가 작고, 우리모델이 linear하고, 가 confex일때)
결국 사용할 전략은
- back propagation
-
loss function이 주어졌을 때, 결국 loss function을 줄이는 것이 나의 목표이기 때문에 나의 파라미터가 어느 방향으로 움직였을 때 loss function이 줄어드는지를 찾고 그 방향으로 파라미터를 바꾸는 게 우리의 목적
-
그래서 loss function의 파라미터를 미분하게 되는 방향을 역수(음수) 방향으로 파라미터를 업데이트하면
loss가 최소화되는 지점에 이르게 되겠죠 이걸 optimal parameter라고 부른다.
(이건 아직도 무슨 말인지 모르겠다) -
위 수식은 N개의 데이터에 대한 출력값 학습데이터의 타겟데이터와 나의 모델의 아웃풋 사이의 제곱을 minimize하는 loss function에 대한 w에 대한 편미분
(.. 왓.....그냥 몰겠다 이젠) -
b 로 partial derivative 편미분
-
w, b 만큼의 편미분한만큼을 빼면서 w, b를 계속 업데이트함
-
줄이고자 하는 loss function 편미분을 빼줌
= gradient descent = 업데이트 -
선형으로 이쁘지 않음
- linear한 변환 + nonlinear 포함
- deep learning(nn): layer 여러개
-
마지막 최종단에서 나오는 loss function 값을 전체 파라미터로 편미분하는 것이 back propagation이다
-
back propagation에서 나오는 각 파라미터만의 편미분을 업데이트시키는 게 gradient descent이다.
-
η : 에타, Stepsize
너무 크게되면 학습이 안됨. gradient 정보는 굉장히 local한 정보. 그 위치에서 조금밖에 유효하지 않기 때문에 stepsize가 너무 크게 되면 학습이 아예 되지 않고 너무 작으면 학습이 안됨
"Of course, we can handle multi dimensional input and output"
예)
100차원 입력 -> 20차원 출력
모델일 경우
→ 행렬을 사용한다!
x : ->
= affine transform 이라고 함
-
와 가 행렬과 벡터고,
-
행렬곱이란?
두 개의 사이의 변환
선형대수) linear 선형성을 가지는 변환 = 행렬로 표현된다
행렬을 찾겠다 = 두개의 vector space, 차원 사이의 선형 변환을 찾겠다는 것
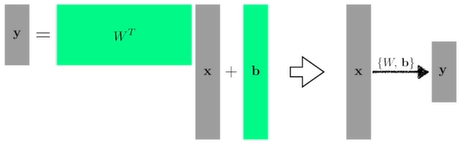
"What if we stack more?"
-
: hidden layer
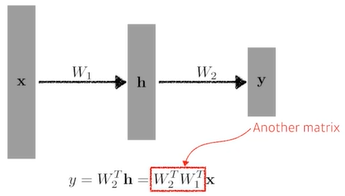
한 단짜리 NN(Neural Network)와 다를 게 없다. -
: 가 중간에 필요함
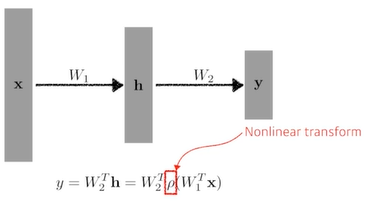
한번 선형결합을 한 후에는 activation function을 곱해서(sigmoid, tanh, relu)
그렇게 얻어지는 feature 벡터를 다시 선형변환하고, nonlinear transform을 거치고.. 그게 n번 반복되고.. 더 많은 표현력을 갖게 되는 것이다.
그게 보통 Neural Network이고.
Beyond Linear Neural Networks
- 어떤 nonlinear function을 사용해야 되냐.
1) ReLU (Rectified Linear Unit)
어떤
- 한 문장 한 문장이 멈춰서 써보고 곱씹어야만 이해됐고, 잘 모르는 내용이 담겨 있기도 했다. 필기해두고 다시 읽어보면서 복습할 기회를 만들어야겠다.
- 공부할 내용 : 선형대수학
