Original Link: https://www.assemblyai.com/blog/pytorch-vs-tensorflow-in-2022/
이 포스트는 위 원문을 번역한것 입니다. 번역문이 이해가 안될경우 원문을 참조 하시기 바랍니다.
PyTorch vs TensorFlow in 2022
2022년에 PyTorch와 TensorFlow중 어떤것을 사용해야 합니까? 이 가이드는 PyTorch와 TensorFlow의 주요 장단점과 올바른 프레임워크를 선택하는 방법을 안내합니다.
PyTorch와 TensorFlow는 오늘날 가장 인기 있는 두 가지 딥 러닝 프레임워크입니다. 어떤 프레임워크가 더 우월한가에 대한것은 오랜 논쟁거리이며, 각 진영에는 열렬한 지지자들이 있습니다.
PyTorch와 TensorFlow는 상대적으로 짧은 수명 동안 너무 빠르게 발전하여 논쟁 환경이 계속 진화하고 있습니다. 오래되거나 불완전한 정보가 풍부하고 주어진 영역에서 어떤 프레임워크가 우위에 있는지에 대한 복잡한 논의를 더욱 어렵게 만듭니다.
TensorFlow는 산업 중심 프레임워크로, PyTorch는 연구 중심 프레임워크로 유명하지만 이러한 개념은 부분적으로 오래된 정보에서 비롯된 것입니다. 어떤 프레임워크가 최고를 지배하는지에 대한 대화는 2022년으로 갈수록 훨씬 더 미묘해집니다. 이제 이러한 차이점을 살펴보겠습니다.
실용적인 고려 사항
PyTorch와 TensorFlow는 모두 고유한 개발 스토리와 복잡한 설계-결정 이력을 가지고 있습니다. 이전에는 이로 인해 현재 기능과 예상되는 미래 기능에 대한 복잡한 기술 논의로 둘을 비교했습니다. 두 프레임워크가 시작된 이후 기하급수적으로 성숙했다는 점을 감안할 때 이러한 기술적 차이점중 많은 부분이 이 시점에서 흔적이 남아 있습니다.
다행스럽게도 눈이 번쩍 뜨이는 것을 원하지 않는 사람들을 위해 PyTorch 대 TensorFlow 논쟁은 현재 세 가지 실용적인 고려 사항으로 귀결됩니다:
-
모델 가용성: 딥 러닝의 영역이 매년 확장되고 모델이 차례로 커지면서 처음부터 최첨단(SOTA, State-of-the-Art) 모델을 훈련하는 것은 더 이상 실현 가능하지 않습니다. 다행히 공개적으로 사용할 수 있는 SOTA 모델이 많이 있으며 가능한 한 이를 활용하는 것이 중요합니다.
-
배포 인프라: 성능이 좋은 모델을 훈련하는 것은 사용할 수 없다면 무의미합니다. 특히 마이크로서비스 비즈니스 모델의 인기가 높아짐에 따라 배포 시간을 줄이는 것이 무엇보다 중요합니다. 효율적인 배포는 기계 학습을 중심으로 하는 많은 비즈니스를 성패할 수 있는 잠재력을 가지고 있습니다.
-
생태계: 딥 러닝은 더 이상 고도로 통제된 환경의 특정 사용 사례에 국한되지 않습니다. AI는 수많은 산업에 새로운 힘을 불어넣고 있으므로 모바일, 로컬 및 서버 애플리케이션 개발을 용이하게 하는 더 큰 생태계 내에 있는 프레임워크가 중요합니다. 또한 Google의 Edge TPU와 같은 특수 기계 학습 하드웨어의 등장으로 성공적인 실무자는 이 하드웨어와 잘 통합될 수 있는 프레임워크로 작업해야 합니다. .
이제 이 세 가지 실용적인 고려 사항을 차례로 살펴보고 다른 영역에서 사용할 프레임워크에 대한 권장 사항을 제공합니다.
PyTorch 대 TensorFlow - 모델 가용성
성공적인 딥 러닝 모델을 처음부터 구현하는 것은 특히 엔지니어링 및 최적화가 어려운 NLP와 같은 애플리케이션의 경우 매우 까다로운 작업이 될 수 있습니다. SOTA 모델의 복잡성이 증가함에 따라 소규모 기업에서는 교육 및 조정이 비현실적이고 거의 불가능에 가까운 작업이 되었습니다. OpenAI의 GPT-3에는 1750억 개 이상의 매개변수가 있고 GPT-4에는 100조 개 이상의 매개변수가 있습니다. 스타트업과 연구원은 모두 이러한 모델을 자체적으로 활용하고 탐색할 수 있는 컴퓨팅 리소스가 없으므로 미세 조정된 전이 학습 또는 즉시 사용 가능한 추론을 위해 사전 훈련된 모델에 대한 액세스가 매우 중요합니다.
모델 가용성의 영역에서 PyTorch와 TensorFlow는 크게 다릅니다. PyTorch와 TensorFlow에는 모두 자체 공식 모델 리포지토리가 있습니다. 아래 생태계 섹션에서 살펴보겠습니다. 그러나 실무자는 다른 소스의 모델을 활용하고자 할 수 있습니다. 각 프레임워크에 대한 모델 가용성을 정량적으로 살펴보겠습니다.
허깅페이스(HuggingFace)
HuggingFace를 사용하면 몇 줄의 코드로 훈련되고 조정된 SOTA 모델을 파이프라인에 통합할 수 있습니다.
주: 허깅페이스는 트랜스포머를 기반으로 하는 다양한 모델(transformer.models)과 학습 스크립트(transformer.Trainer)를 구현해 놓은 모듈이다. 원래는 파이토치로 layer, model 등을 선언해주고 학습 스크립트도 전부 구현해야 하지만, 허깅 페이스를 사용하면 이런 수고를 덜 수 있다. 정리하면 '허깅 페이스'라는 회사가 만든 'transformers' 패키지가 있고, 일반적인 파이토치 구현체의 layer.py, model.py이 transformer.models에, train.py 가 transformer.Trainer에 대응된다
(출처: https://hyunlee103.tistory.com/118)
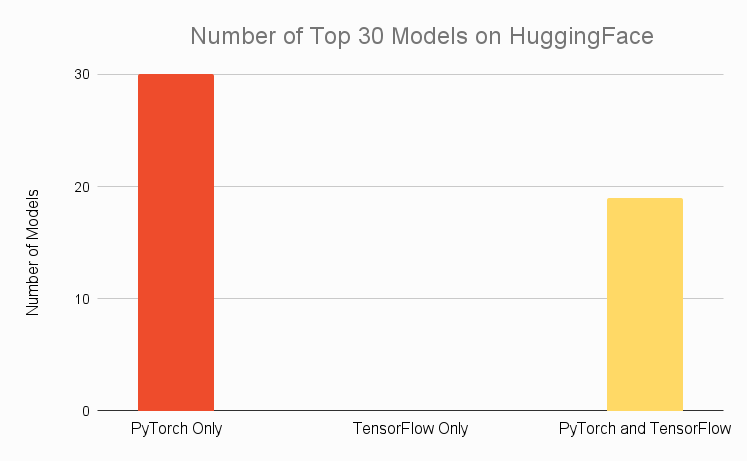
PyTorch와 TensorFlow에 대한 HuggingFace 모델 가용성을 비교할 때 결과는 놀랍습니다. 아래에서 PyTorch 또는 TensorFlow 독점 또는 두 프레임워크 모두에서 사용할 수 있는 HuggingFace에서 사용할 수 있는 총 모델 수에 대한 차트를 볼 수 있습니다. 우리가 볼 수 있듯이 PyTorch에서만 사용할 수 있는 모델의 수는 경쟁을 완전히 압도합니다. 거의 85%의 모델이 PyTorch 독점적이며, 독점이 아닌 모델도 PyTorch에서 사용할 수 있는 확률이 약 50%입니다. 대조적으로 모든 모델의 약 16%만 TensorFlow에서 사용할 수 있으며 약 8%만 TensorFlow 전용입니다.
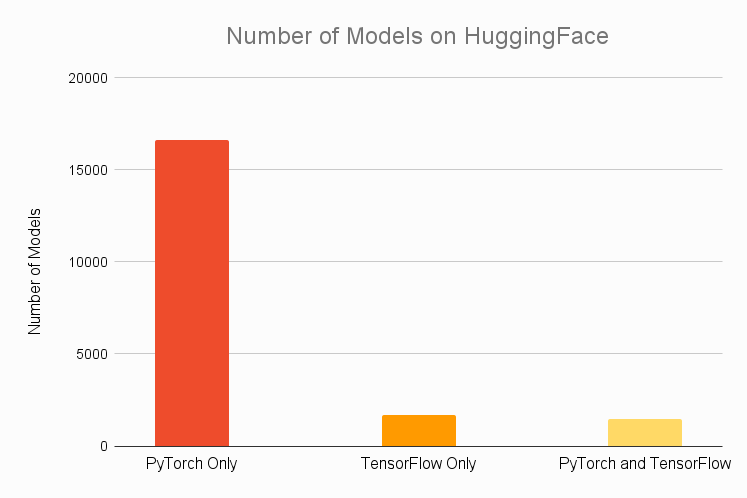
HuggingFace에서 가장 인기 있는 모델 30가지로만 범위를 분류하면 비슷한 결과가 나타납니다. 상위 30개 모델 중 2/3도 TensorFlow에서 사용할 수 없지만 모두 PyTorch에서 사용할 수 있습니다. TensorFlow 독점인 상위 30개 모델은 없습니다.
연구 논문
특히 연구 종사자의 경우 최근에 발표된 논문의 모델에 액세스하는 것이 중요합니다. 다른 프레임워크에서 탐색하려는 새 모델을 다시 만들려는 시도는 귀중한 시간을 낭비하므로 저장소를 복제하고 즉시 실험을 시작할 수 있다는 것은 중요한 작업에 집중할 수 있다는 것을 의미합니다.
PyTorch가 사실상의 연구 프레임워크라는 점을 감안할 때 HuggingFace에서 관찰한 추세가 연구 커뮤니티 전체로 계속 이어질 것으로 예상합니다. 그리고 우리의 직감은 정확합니다.
PyTorch 또는 TensorFlow를 사용하는 출판물의 상대적 비율을 보여주는 아래 그래프는 지난 몇 년 동안 8개의 상위 연구 저널의 데이터를 집계했습니다. 보시다시피 PyTorch의 채택은 매우 빨랐으며 불과 몇 년 만에 PyTorch 또는 TensorFlow를 사용하는 논문의 거의 80%에서 사용하는 비율이 약 7%에서 성장했습니다.
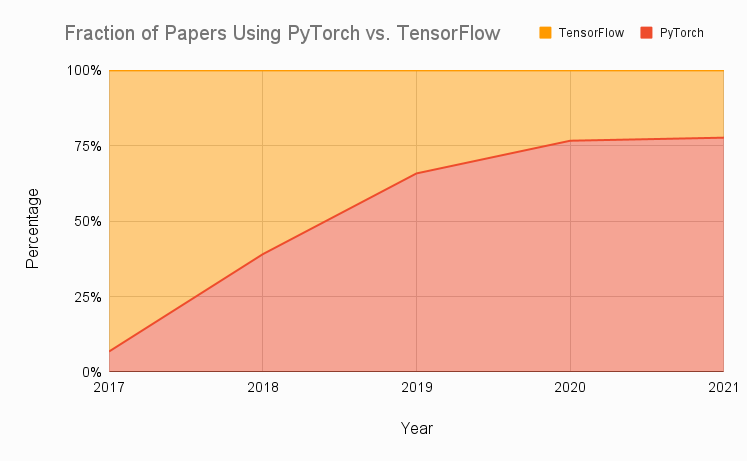
이러한 빠른 채택의 대부분은 연구의 맥락에서 악화된 TensorFlow 1의 어려움으로 인해 연구자가 새로운 대안 PyTorch를 찾게 되었습니다. TensorFlow의 많은 문제가 2019년 TensorFlow 2의 출시로 해결되었지만 PyTorch의 추진력은 최소한 커뮤니티 관점에서 확립된 연구 중심 프레임워크로 유지될 만큼 충분히 컸습니다.
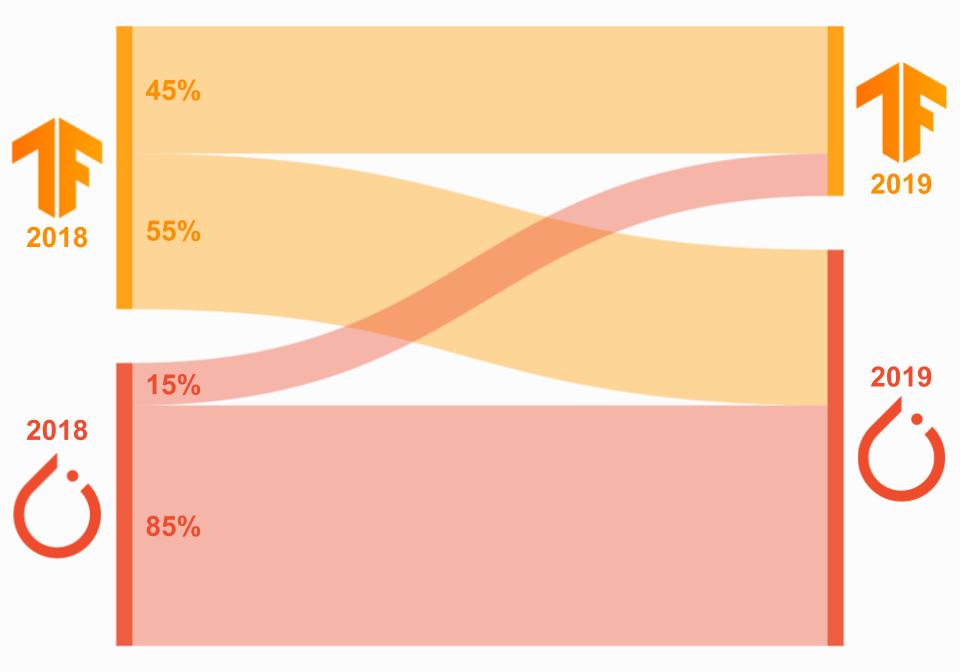
프레임워크를 마이그레이션한 연구자의 비율을 보면 동일한 패턴을 볼 수 있습니다. 2018년과 2019년에 PyTorch 또는 TensorFlow를 사용했던 저자의 출판물을 보면 2018년에 TensorFlow를 사용한 저자의 대다수가 2019년에 PyTorch로 마이그레이션한 반면(55%) PyTorch를 사용한 저자의 대다수는 2018년에는 PyTorch 2019(85%)를 유지했습니다. 이 데이터는 아래 Sankey 다이어그램에 시각화되어 있습니다. 여기서 왼쪽은 2018년, 오른쪽은 2019년에 해당합니다. 데이터는 총 수가 아닌 2018년 각 프레임워크의 사용자 비율을 나타냅니다.
주의 깊은 독자는 이 데이터가 TensorFlow 2 릴리스 이전의 데이터임을 알 수 있지만 다음 섹션에서 볼 수 있듯이 이 사실은 연구 커뮤니티와 관련이 없습니다.
Papers with Code (코드가 있는 논문)
마지막으로 Papers with Code의 데이터를 살펴봅니다. 이 웹사이트는 Machine Learning 논문, 코드, 데이터세트 등을 사용하여 무료로 공개된 리소스를 만드는 것이 목표입니다. 2017년 말부터 현재 분기까지 분기별로 집계된 데이터와 함께 시간 경과에 따라 PyTorch, TensorFlow 또는 다른 프레임워크를 활용하는 논문의 비율을 표시했습니다. 우리는 PyTorch를 활용하는 논문의 꾸준한 성장을 보고 있습니다. 이번 분기에 생성된 4,500개의 리포지토리 중 60%는 PyTorch에서 구현되고 11%는 TensorFlow에서 구현됩니다.
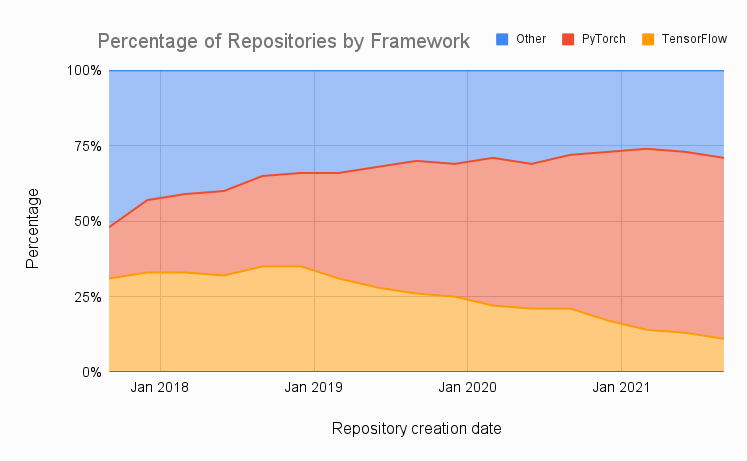
반대로 TensorFlow의 사용은 꾸준히 감소하고 있습니다. 2019년 TensorFlow 1을 사용하여 연구를 어렵게 만든 많은 문제를 해결한 TensorFlow 2의 출시조차도 이러한 추세를 뒤집기에 충분하지 않았습니다. TensorFlow 2가 출시된 후에도 TensorFlow의 인기가 거의 단조로운 감소를 보입니다.
모델 가용성 - 정리
위의 데이터에서 PyTorch가 현재 연구 환경을 지배하고 있음이 분명합니다. TensorFlow 2는 연구를 위해 TensorFlow를 훨씬 쉽게 활용할 수 있게 해주었지만, PyTorch는 연구자들이 TensorFlow로 돌아가서 다시 시도해 볼 이유가 없습니다. 또한 TensorFlow 1의 이전 연구와 TensorFlow 2의 새로운 연구 사이의 이전 버전과의 호환성 문제는 이 문제를 악화시킬 뿐입니다.
현재로서는 PyTorch가 커뮤니티에서 널리 채택되고 대부분의 출판물/사용 가능한 모델이 PyTorch를 사용하기 때문에 연구 영역에서 확실한 승자입니다.
몇 가지 주목할만한 예외/참고 사항이 있습니다:
-
Google AI: 분명히 Google에서 발표한 연구는 주로 TensorFlow를 사용합니다. Google이 Facebook보다 훨씬 더 많다는 점을 감안할 때 (2020년 NeurIPS 또는 ICML에 게시된 기사 292개 대 92개), 일부 연구원은 TensorFlow를 사용하는 것이 유용하거나 최소한 TensorFlow에 능숙할 수 있습니다. Google Brain은 또한 Flax - Google의 JAX용 신경망 라이브러리와 함께 JAX를 사용합니다.
-
DeepMind: DeepMind는 2016년에 TensorFlow의 사용을 표준화했지만 2020년에 발표된 JAX를 사용하여 연구를 가속화합니다. 이 발표에서 그들은 또한 JAX 에코시스템, 특히 JAX 기반 신경망 라이브러리인 Haiku에 대한 개요도 제공합니다.
DeepMind는 또한 Facebook보다 다작입니다(2020년 NeurIPS 또는 ICML에 게시된 기사 110개 대 92개). DeepMind는 Sonnet을 만들었습니다. 이 API는 TensorFlow를 위한 고수준 API로 연구에 적합하며 때때로 "Keras의 연구 버전"이라고 불리며 이러한 사용자에게 유용할 수 있습니다. 연구에 TensorFlow 사용을 고려 중입니다. 또한 Deepmind의 Acme 프레임워크는 강화 학습 실무자에게 필수적일 수 있습니다.
-
OpenAI: 반면에 OpenAI는 2020년에 내부적으로 PyTorch의 사용을 표준화했습니다. 그러나 다시 한 번 강화 학습에 있는 사람들을 위해 이전 기준점(baselines) 저장소가 TensorFlow에서 구현됩니다. Baselines는 강화 학습 알고리즘의 고품질 구현을 제공하므로 TensorFlow는 강화 학습 실무자에게 최상의 선택이 될 수 있습니다.
-
JAX: Google에는 연구 커뮤니티에서 인기를 얻고 있는 JAX라는 또 다른 프레임워크가 있습니다. 어떤 의미에서는 PyTorch 또는 TensorFlow에 비해 JAX의 오버헤드가 훨씬 적습니다. 그러나 기본 철학은 PyTorch 및 TensorFlow와 다르며 이러한 이유로 JAX로 마이그레이션하는 것은 대부분의 경우 좋은 선택이 아닐 수 있습니다. JAX를 활용하는 모델/논문이 증가하고 있지만 현재로서는 PyTorch 및 TensorFlow와 관련하여 향후 연구 커뮤니티에서 JAX가 얼마나 널리 퍼질지 확실하지 않습니다.
TensorFlow가 지배적인 연구 프레임워크로 재건되기를 원한다면 불가능하지는 않더라도 길고 험난한 여정을 거쳐야 합니다.
PyTorch 대 TensorFlow 논쟁의 라운드 1은 PyTorch가 우세합니다.
PyTorch 대 TensorFlow - 배포
최첨단 결과를 위해 SOTA 모델을 사용하는 것이 추론 관점에서 딥 러닝 애플리케이션의 성배이지만, 이 이상은 항상 실용적이거나 산업 환경에서 달성할 수 있는 것은 아닙니다. SOTA 모델에 대한 액세스는 지능을 실행 가능하게 만드는 힘들고 오류가 발생하기 쉬운 프로세스가 있는 경우 무의미합니다. 따라서 가장 빛나는 모델에 액세스할 수 있는 프레임워크를 고려하는 것 외에도 각 프레임워크에서 종단 간 딥 러닝 프로세스를 고려하는 것이 중요합니다.
TensorFlow는 처음부터 배포 지향 애플리케이션을 위한 필수 프레임워크였으며 그럴만한 이유가 있습니다. TensorFlow에는 종단 간 딥 러닝 프로세스를 쉽고 효율적으로 만드는 수많은 관련 도구가 있습니다. 특히 배포의 경우 TensorFlow Serving 및 TensorFlow Lite를 사용하면 클라우드, 서버, 모바일 및 IoT 장치에 간편하게 배포할 수 있습니다.
PyTorch는 배포 관점에서 극도로 부진했지만 최근 몇 년 동안 이 격차를 좁히기 위해 노력했습니다. 작년 TorchServe와 PyTorch Live의 도입으로 불과 몇 주 전에 매우 필요한 기본 배포 도구가 제공되었지만 PyTorch가 업계 환경에서 사용할 가치가 있을 만큼 배포 격차를 좁혔습니까? 한 번 보겠습니다..
TensorFlow
TensorFlow는 추론 성능에 최적화된 정적 그래프로 확장 가능한 생산을 제공합니다. TensorFlow로 모델을 배포할 때 애플리케이션에 따라 TensorFlow Serving 또는 TensorFlow Lite를 사용합니다.
TensorFlow Serving:
TensorFlow Serving은 TensorFlow 모델을 사내 또는 클라우드에 배포할 때 사용되며 TensorFlow Extended(TFX)는 종단 간 기계 학습 플랫폼 내에서 사용됩니다. 서빙을 사용하면 모델 태그가 있는 잘 정의된 디렉터리로 모델을 쉽게 직렬화하고 서버 아키텍처와 API를 정적으로 유지하면서 추론 요청을 만드는 데 사용할 모델을 선택할 수 있습니다.
Serving을 사용하면 고성능 RPC를 위한 Google의 오픈 소스 프레임워크를 실행하는 특수 gRPC 서버에 모델을 쉽게 배포할 수 있습니다. gRPC는 다양한 마이크로서비스 생태계를 연결하기 위해 설계되었으므로 이러한 서버는 모델 배포에 적합합니다. 전체적으로 Vertex AI를 통해 Google Cloud와 긴밀하게 통합되고 Kubernetes 및 Docker와 통합됩니다.
TensorFlow Lite:
TensorFlow Lite(TFLite)는 TensorFlow 모델을 모바일 또는 IoT/임베디드 기기에 배포할 때 사용합니다. TFLite는 이러한 장치에 대한 모델을 압축 및 최적화하고 온디바이스 인공 지능에 대한 5가지 제약 조건(대기 시간, 연결, 개인 정보 보호, 크기 및 전력 소비)을 보다 광범위하게 해결합니다. 동일한 파이프라인을 사용하여 표준 Keras 기반 SavedModels(Serving과 함께 사용) 및 TFLite 모델을 동시에 내보내므로 모델 품질을 비교할 수 있습니다.
TFLite는 마이크로컨트롤러(Bazel 또는 CMake가 있는 ARM) 및 임베디드 Linux(예: [Coral](https://coral.ai/ 장치) 에 사용할 수 있습니다. Python, Java, C++, JavaScript, Swift용 TensorFlow API(올해 보관됨)는 개발자에게 다양한 언어 옵션을 제공합니다.
PyTorch
PyTorch는 이전에 이 분야에서 악명 높았던 배포를 보다 쉽게 만드는 데 투자했습니다. 이전에는 PyTorch 사용자가 Flask 또는 Django를 사용하여 모델 위에 REST API를 빌드해야 했지만 이제는 TorchServe 및 PyTorch Live 형식의 기본 배포 옵션이 있습니다.
TorchServe
TorchServe는 AWS와 Facebook(현재 Meta)의 협업으로 탄생한 오픈 소스 배포 프레임워크로 2020년에 출시되었습니다. 엔드포인트 사양, 모델 아카이빙(보관) 및 메트릭스(항목) 관찰 등의 기본 기능을 가지고 있습니다만 TensorFlow 대안보다 열등합니다. REST 및 gRPC API는 모두 TorchServe에서 지원됩니다.
PyTorch Live
PyTorch는 2019년 PyTorch Mobile에 처음 출시되었으며, Android, iOS 및 Linux용으로 최적화된 기계 학습 모델 배포를 위한 종단 간 워크플로를 생성하도록 설계되었습니다.
PyTorch Live는 모바일 기반으로 12월 초에 출시되었습니다. JavaScript 및 React Native를 사용하여 관련 UI가 있는 크로스 플랫폼 iOS 및 Android AI 기반 앱을 만듭니다. 기기 내 추론은 여전히 PyTorch Mobile에서 수행됩니다. Live는 부트스트랩할 예제 프로젝트와 함께 제공되며 향후 오디오 및 비디오 입력을 지원할 계획입니다.
배포 - 정리
현재 TensorFlow는 여전히 배포 측면에서 우위를 점하고 있습니다. Serving 및 TFLite는 PyTorch 경쟁자보다 훨씬 강력하며 Google의 Coral 장치와 함께 로컬 AI에 TFLite를 사용하는 기능은 많은 산업 분야에서 필수 요소입니다. 대조적으로 PyTorch Live는 모바일에만 초점을 맞추고 TorchServe는 아직 초기 단계입니다. 향후 몇 년 동안 배포 영역이 어떻게 변경되는지 보는 것은 흥미로울 것이지만 현재로서는 PyTorch 대 TensorFlow 논쟁의 2차 라운드는 TensorFlow가 우세합니다.
모델 가용성 및 배포 문제에 대한 최종 참고 사항: TensorFlow 배포 인프라를 사용하고 싶지만 PyTorch에서만 사용할 수 있는 모델에 액세스하려는 경우 ONNX를 사용하여 PyTorch에서 TensorFlow로 모델 이식
PyTorch 대 TensorFlow - 생태계
2022년에 PyTorch와 TensorFlow를 구분하는 마지막 중요한 고려 사항은 이들이 위치한 생태계입니다. PyTorch와 TensorFlow는 모두 모델링 관점에서 볼 때 유능한 프레임워크이며, 이 시점에서의 기술적 차이점은 쉬운 배포, 관리, 분산 교육 등을 위한 도구를 제공하는 주변 생태계보다 덜 중요합니다. 이제 각 프레임워크의 생태계를 살펴보겠습니다.
PyTorch
Hub
HuggingFace와 같은 플랫폼 외에도 사전 훈련된 모델과 리포지토리를 공유하기 위한 연구 중심 플랫폼인 공식 PyTorch Hub도 있습니다. Hub에는 오디오, 비전 및 NLP용 모델을 포함하여 다양한 모델이 있습니다. 또한 유명인 얼굴의 고품질 이미지를 생성하기 위한 GAN을 포함한 생성 모델도 있습니다.

SpeechBrain
SpeechBrain은 PyTorch의 공식 오픈 소스 음성 툴킷입니다. SpeechBrain은 ASR, 화자 인식, 확인 및 분할 등을 지원합니다! 모델을 만들고 싶지 않고 대신 Auto Chapters, 감정 분석, 엔티티 감지 등 등과 같은 기능을 갖춘 플러그 앤 플레이 도구를 원한다면 AssemblyAI의 자체 Speech-to-Text API를 확인하십시오.
생태계 도구(Ecosystem Tools)
Computer Vision 또는 자연어 처리(NLP, Natural Language Processing)에 맞게 조정된 라이브러리와 같이 유용할 수 있는 다른 라이브러리에 대해서는 PyTorch의 도구 페이지를 확인하세요. 여기에는 fast.ai가 포함됩니다. - 최신 모범 사례를 사용하여 신경망을 생성하는 데 널리 사용되는 라이브러리입니다.
TorchElastic
TorchElastic은 2020년에 출시되었으며 AWS와 Facebook의 협업 결과입니다. 훈련에 영향을 주지 않고 동적으로 변경될 수 있는 컴퓨팅 노드 클러스터에서 모델을 훈련할 수 있도록 작업자 프로세스를 관리하고 재시작 동작을 조정하는 분산 훈련용 도구입니다. 따라서 TorchElastic은 서버 유지 관리 이벤트 또는 네트워크 문제와 같은 문제로 인한 치명적인 오류를 방지하여 교육 진행 상황을 잃지 않도록 합니다. TorchElastic은 Kubernetes와의 통합 기능을 제공하며 PyTorch 1.9+에 통합되었습니다.
TorchX
TorchX는 머신 러닝 애플리케이션의 빠른 구축 및 배포를 위한 SDK입니다. TorchX에는 지원되는 스케줄러에서 분산 PyTorch 애플리케이션을 시작하기 위한 교육 세션 관리자(Training Session Manager) API가 포함되어 있습니다. TorchElastic에서 로컬로 관리하는 작업을 기본적으로 지원하면서 분산 작업을 시작하는 역할을 합니다.
Lightning
PyTorch Lightning은 PyTorch의 Keras라고도 합니다. 이 비교가 약간 오해의 소지가 있지만 Lightning은 PyTorch의 모델 엔지니어링 및 교육 프로세스를 단순화하는데 유용한 도구이며 2019년 초기 릴리스 이후 상당히 발전했습니다. Lightning은 객체 지향 방식으로 모델링 프로세스에 접근하여 재사용 가능하고 프로젝트 전체에서 활용할 수 있는 공유 가능한 구성 요소. Lightning에 대한 자세한 정보와 그 워크플로를 바닐라 PyTorch와 비교하는 방법에 대한 비교는 여기 자습서를 참조하세요.
TensorFlow
Hub
TensorFlow Hub는 미세 조정할 준비가된 훈련된 머신 러닝 모델의 저장소로, 몇 줄의 코드로 BERT와 같은 모델을 사용할 수 있습니다. Hub에는 다양한 사용 사례를 위한 TensorFlow, TensorFlow Lite 및 TensorFlow.js 모델이 포함되어 있으며 이미지, 비디오, 오디오 및 텍스트 문제 도메인에 사용할 수 있는 모델이 있습니다. 여기 자습서를 시작하거나 여기 모델 목록을 참조하세요. .
Model Garden
바로 사용할 수 있는 사전 훈련된 모델이 애플리케이션에서 작동하지 않을 경우 TensorFlow의 Model Garden은 SOTA 모델용 소스 코드를 사용할 수 있도록 하는 저장소입니다. 모델이 작동하는 방식을 이해하기 위해 내부적으로 들어가거나 필요에 맞게 수정하려는 경우에 유용합니다. 이는 전이 학습 및 미세 조정을 넘어 직렬화된 사전 훈련된 모델로는 불가능한 일입니다.
Model Garden에는 Google에서 유지 관리하는 공식 모델, 연구원이 유지 관리하는 연구 모델 및 커뮤니티에서 유지 관리하는 선별된 커뮤니티 모델에 대한 디렉토리가 포함되어 있습니다. TensorFlow의 장기 목표는 Hub의 Model Garden에서 사전 훈련된 모델 버전을 제공하고 Hub의 사전 훈련된 모델이 Model Garden에서 사용 가능한 소스 코드를 갖도록 하는 것입니다.
Extended (TFX)
TensorFlow Extended는 모델 배포를 위한 TensorFlow의 종단간 플랫폼입니다. 데이터를 로드, 검증, 분석 및 변환할 수 있습니다. 모델 훈련 및 평가 Serving 또는 Lite를 사용하여 모델을 배포합니다. 그런 다음 아티팩트와 해당 종속성을 추적합니다. TFX는 Jupyter 또는 Colab과 함께 사용할 수 있으며 오케스트레이션(주: 조화롭게 어우러짐)을 위해 Apache Airflow/Beam 또는 Kubernetes를 사용할 수 있습니다. TFX는 Google Cloud와 긴밀하게 통합되며 Vertex AI Pipelines와 함께 사용할 수 있습니다.
Vertex AI
Vertex AI는 Google Cloud의 통합 머신러닝 플랫폼입니다. 올해 출시되어 GCP, AI Platform 및 AutoML을 하나의 플랫폼으로 통합합니다. Vertex AI는 서버리스 방식으로 워크플로를 오케스트레이션하여 기계 학습 시스템을 자동화, 모니터링 및 관리하는데 도움이 될 수 있습니다. Vertex AI는 또한 워크플로의 아티팩트를 저장할 수 있으므로 종속성과 모델의 교육 데이터, 하이퍼파라미터 및 소스 코드를 추적할 수 있습니다.
MediaPipe
MediaPipe는 얼굴 감지, 다중 손 추적, 객체 감지 등에 사용할 수 있는 다중 모드, 교차 플랫폼 적용 기계 학습 파이프라인을 구축하기 위한 프레임워크입니다. 프로젝트는 오픈 소스이며 Python, C++ 및 JavaScript를 비롯한 여러 언어로 바인딩됩니다. MediaPipe 및 즉시 사용 가능한 솔루션 시작에 대한 자세한 정보는 여기에서 찾을 수 있습니다.
Coral
클라우드 기반 AI에 의존하는 다양한 SaaS 회사가 있지만 많은 산업 분야에서 로컬 AI에 대한 수요가 증가하고 있습니다. Google Coral은 이러한 요구를 해결하기 위해 만들어졌으며 로컬 AI로 제품을 빌드하기 위한 완벽한 툴킷입니다. Coral은 2020년에 출시되었으며 개인 정보 보호 및 효율성을 포함하여 배포 섹션의 TFLite 부분에서 언급한 온보드 AI 구현의 어려움을 해결합니다.
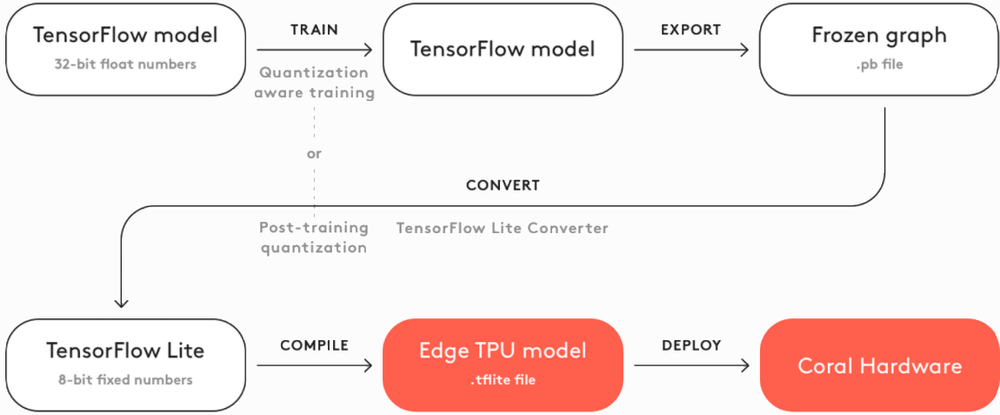
Coral은 프로토타이핑, 생산 및 감지를 위한 일련의 하드웨어 제품을 제공하며, 그 중 일부는 AI 애플리케이션을 위해 특별히 제작된 본질적으로 더 강력한 Raspberry Pi입니다. 그들의 제품은 저전력 장치에 대한 고성능 추론을 위해 Edge TPU를 활용합니다. Coral은 또한 이미지 분할, 포즈 추정, 음성 인식 등을 위해 미리 컴파일된 모델을 제공하여 자체 로컬 AI 시스템을 만들려는 개발자에게 스캐폴딩을 제공합니다. 모델을 만드는 필수 단계는 아래 순서도에서 볼 수 있습니다.
TensorFlow.js
TensorFlow.js는 Node.js를 사용하여 브라우저와 서버 측 모두에서 모델을 교육하고 배포할 수 있는 머신 러닝용 JavaScript 라이브러리입니다. Python 모델을 가져오는 방법에 대한 예제와 정보가 있는 문서, 즉시 사용할 수 있는 사전 훈련된 모델, 관련 코드와 함께 라이브 데모를 제공합니다.
Cloud
TensorFlow Cloud는 로컬 환경을 Google Cloud에 연결할 수 있는 라이브러리입니다. 제공된 API는 Cloud Console을 사용할 필요 없이 로컬 머신의 모델 빌드 및 디버깅부터 GCP의 분산 학습 및 초매개변수 조정까지의 격차를 해소하도록 설계되었습니다.
Colab
Google Colab은 Jupyter와 매우 유사한 클라우드 기반 노트북 환경입니다. GPU 또는 TPU 교육을 위해 Colab을 Google Cloud에 쉽게 연결할 수 있습니다. PyTorch는 Colab에서도 사용할 수 있습니다.
Playground
플레이그라운드는 신경망의 기본을 이해하기 위한 작지만 세련된 교육 도구입니다. 깔끔한 UI 내에서 시각화된 단순한 조밀한 네트워크를 제공합니다. 네트워크의 레이어 수와 크기를 변경하여 기능을 학습하는 방법을 실시간으로 확인할 수 있습니다. 학습률 및 정규화 강도와 같은 하이퍼파라미터 변경이 다른 데이터 세트의 학습 프로세스에 어떻게 영향을 미치는지 확인할 수도 있습니다. Playground를 사용하면 학습 과정을 실시간으로 재생하여 훈련 과정에서 입력이 어떻게 변환되는지 매우 시각적으로 볼 수 있습니다. Playground는 네트워크의 기본사항을 이해할 수 있도록 구축된 오픈 소스 소규모 신경망 라이브러리도 함께 제공됩니다.
Datasets
Google Research의 Datasets는 Google에서 주기적으로 데이터셋을 출시하는 데이터셋 리소스입니다. Google은 또한 더 광범위한 데이터세트 데이터베이스에 액세스할 수 있는 데이터세트 검색을 제공합니다. 물론 PyTorch 사용자도 이러한 데이터 세트를 활용할 수 있습니다.
생태계 - 정리
이 라운드는 세 가지 중 가장 가깝지만 궁극적으로 TensorFlow는 우수한 생태계를 가지고 있습니다. Google은 엔드 투 엔드 딥 러닝 워크플로의 각 관련 영역에서 사용 가능한 제품이 있는지 확인하는 데 많은 투자를 했지만 이러한 제품이 얼마나 잘 다듬어진지는 이 환경에 따라 다릅니다. 그럼에도 불구하고 TFX와 함께 Google Cloud와의 긴밀한 통합으로 종단간 개발 프로세스가 효율적이고 조직화되었으며 Google Coral 기기로 모델을 쉽게 이식할 수 있으며 일부 산업에서는 TensorFlow가 압도적인 승리를 거두었습니다.
PyTorch 대 TensorFlow 논쟁의 3 라운드는 TensorFlow가 우세합니다.
PyTorch 또는 TensorFlow를 사용해야 합니까?
예상대로 PyTorch 대 TensorFlow 논쟁에는 정답이 없습니다. 특정 사용 사례와 관련하여 한 프레임워크가 다른 프레임워크보다 우수하다고 말하는 것이 합리적입니다. 어떤 프레임워크가 가장 적합한지 결정하는데 도움이 되도록 권장 사항을 아래의 순서도에 정리했으며 각 차트는 서로 다른 관심 영역에 맞게 조정되었습니다.
내가 업계에 있으면 어떻게 됩니까?
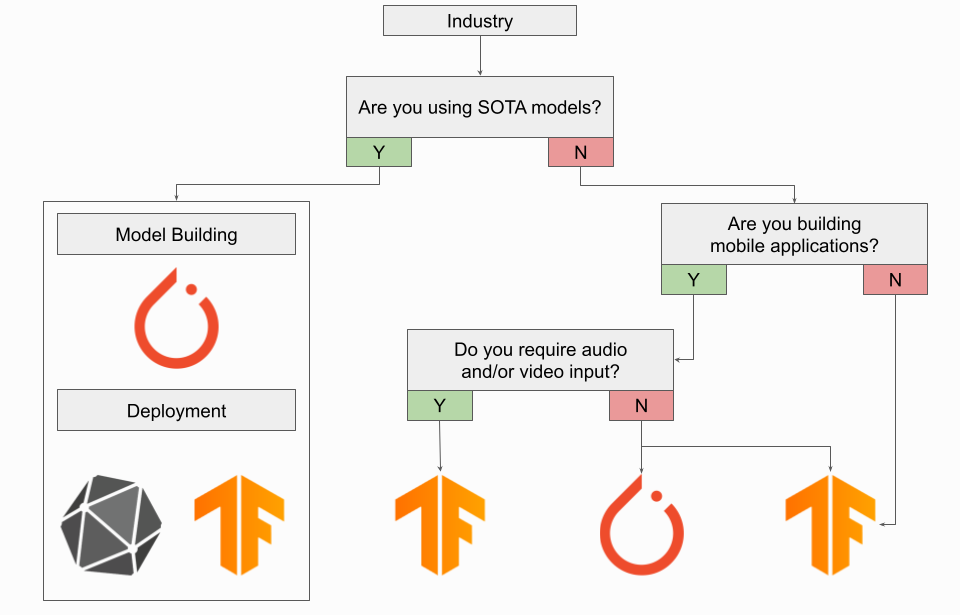
산업 환경에서 딥 러닝 엔지니어링을 수행하는 경우 TensorFlow를 사용하고 있을 가능성이 높으며 계속 사용해야 합니다. TensorFlow의 강력한 배포 프레임워크와 종단간 TensorFlow Extended 플랫폼은 모델을 생산해야 하는 사람들에게 매우 중요합니다. 모델 모니터링 및 아티팩트 추적과 함께 gRPC 서버에 쉽게 배포하는 것은 업계에서 사용하기 위한 중요한 도구입니다. TorchServe의 최근 릴리스에서는 PyTorch에서만 사용할 수 있는 SOTA 모델에 액세스해야 하는 경우와 같이 합당한 이유가 있는 경우 PyTorch 사용을 고려할 수 있습니다. 이 경우 ONNX를 사용하여 TensorFlow의 배포 워크플로 내에서 변환된 PyTorch 모델을 배포하는 것을 고려하십시오.
모바일 애플리케이션을 구축하는 경우 PyTorch Live의 최근 릴리스를 감안할 때 PyTorch 사용을 고려할 수 있습니다만 오디오 또는 비디오 입력이 필요하다면 TensorFlow를 사용해야 합니다. AI를 활용하는 임베디드 시스템 또는 IoT 장치를 구축하는 경우에도 여전히 주어진 TFLite + Coral 파이프라인을 사용하는 TensorFlow를 사용해야 합니다.
결론: 하나의 프레임워크를 선택해야 한다면 TensorFlow를 선택하세요.
내가 연구원이라면?
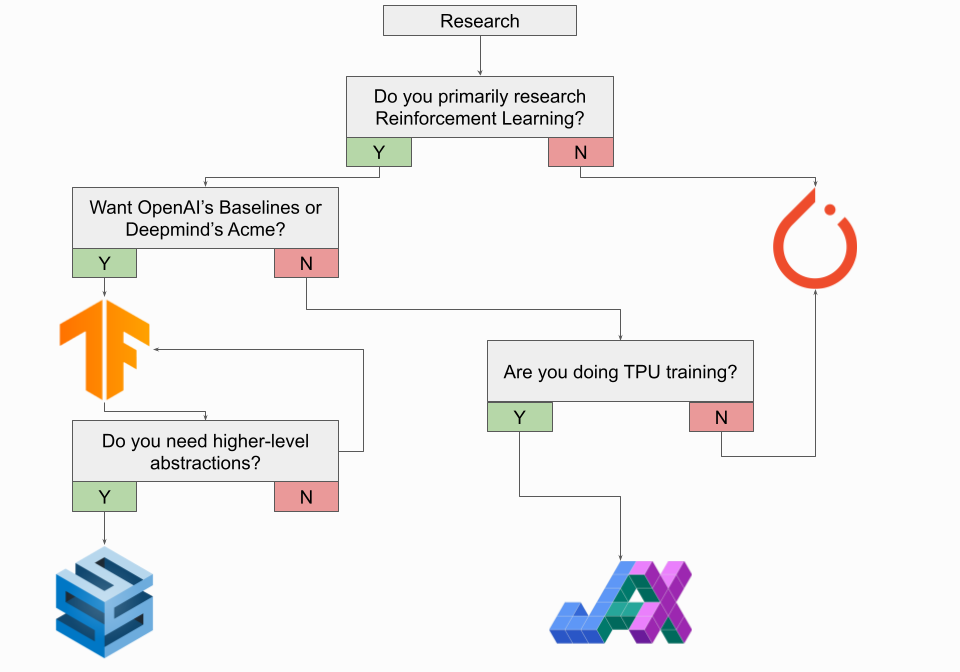
연구원이라면 거의 확실히 PyTorch를 사용하고 있으며 현재로서는 계속 사용하고 있을 것입니다. PyTorch는 사실상의 연구 프레임워크이므로 대부분의 SOTA 모델은 PyTorch에 있거나 PyTorch용입니다.
이 규칙에는 몇 가지 주목할만한 예외가 있으며, 가장 주목할만한 것은 강화 학습에 있는 사람들이 TensorFlow 사용을 고려해야 한다는 것입니다. TensorFlow에는 강화 학습을 위한 기본 Agents 라이브러리가 있으며, Deepmind의 Acme 프레임워크는 TensorFlow에 구현되어 있습니다. OpenAI의 Baselines 모델 저장소도 TensorFlow에서 구현되지만 OpenAI의 Gym은 TensorFlow 또는 PyTorch와 함께 사용할 수 있습니다. 연구에 TensorFlow를 사용할 계획이라면 Deepmind의 Sonnet에서 더 높은 수준의 추상화도 확인해야 합니다.
TensorFlow를 사용하고 싶지 않다면 TPU 훈련을 하고 있다면 Google의 JAX 탐색을 고려해야 합니다. 신경망 프레임워크 자체는 아니지만 자동 분화 기능이 있는 G/TPU용 NumPy 구현에 더 가깝습니다. "Sonnet for JAX"라고 부르는 Deepmind의 Haiku는 JAX를 기반으로 구축된 신경망 라이브러리로, JAX를 고려하고 있다면 살펴볼 가치가 있습니다. 또는 Google의 Flax에서 확인할 수 있습니다. TPU 훈련을 하지 않는다면 지금은 PyTorch를 사용하는 것이 가장 좋습니다.
어떤 프레임워크를 선택하든 2022년 JAX를 주시해야 합니다. 특히 커뮤니티가 성장하고 더 많은 출판물에서 이를 활용하기 시작함에 따라 더욱 그렇습니다.
결론: 하나의 프레임워크를 선택해야 하는 경우 PyTorch를 선택하세요.
내가 교수라면?
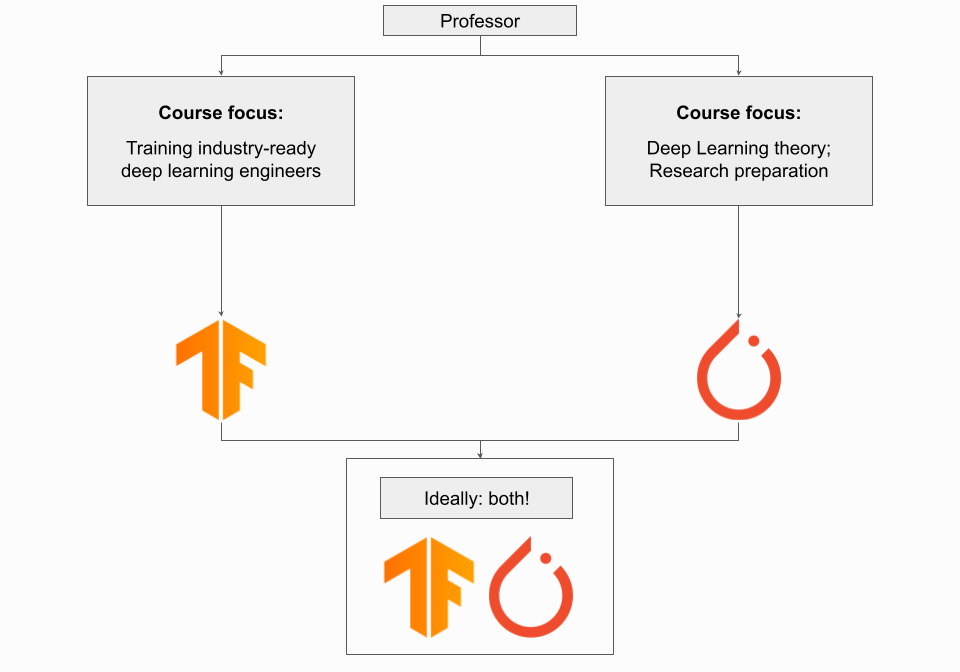
교수라면 딥 러닝 과정에 사용할 프레임워크는 과정의 목표에 따라 다릅니다. 교육 과정의 초점이 딥 러닝 이론뿐만 아니라 전체 딥 러닝 프로세스에서 역량을 발휘하여 기초를 다질 수 있는 업계 준비 딥 러닝 엔지니어를 양성하는 것이라면 TensorFlow를 사용해야 합니다. 이 경우 종단 간 실습 프로젝트와 함께 TensorFlow 생태계 및 도구에 대한 노출은 매우 유익하고 가치가 있습니다.
코스의 초점이 딥 러닝 이론과 딥 러닝 모델의 기본 이해에 있다면 PyTorch를 사용해야 합니다. 이는 딥 러닝 연구를 수행할 수 있도록 학생들을 준비시키기 위한 고급 학부 과정이나 초기 대학원 수준 과정을 가르치는 경우 특히 그렇습니다.
이상적으로는 학생들이 각 프레임워크에 노출되어야 하며, 프레임워크 간의 차이점을 이해하는데 시간을 할애하는 것은 한 학기의 시간 제약에도 불구하고 아마도 가치가 있을 것입니다. 코스가 다른 주제에 전념하는 많은 클래스가 있는 더 큰 기계 학습 프로그램의 일부인 경우 두 가지 모두에 노출하려고 하는 것보다 코스 자료에 가장 적합한 프레임워크를 고수하는 것이 더 나을 수 있습니다.
경력 변경을 원하고 있다면 어떻게 합니까?
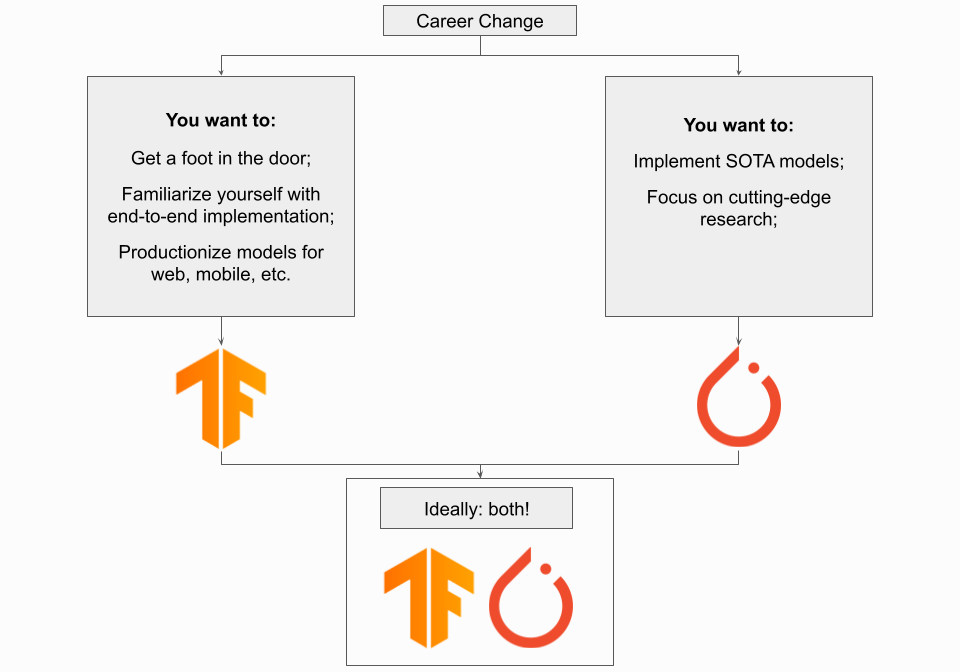
경력을 바꾸고 싶다면 PyTorch나 TensorFlow가 좋은 선택입니다. 이 경우에 할 수 있는 가장 중요한 것은 즉시 가치를 가져올 수 있다는 것을 입증하는 것이므로 프로젝트 포트폴리오를 보유하는 것이 중요합니다. 딥 러닝을 창의적인 사용 사례에 적용하거나 프로젝트를 끝까지 수행하여 업계 준비가 되었음을 보여줌으로써 평범한 것을 넘어 당신을 매우 유리한 위치에 놓을 것입니다.
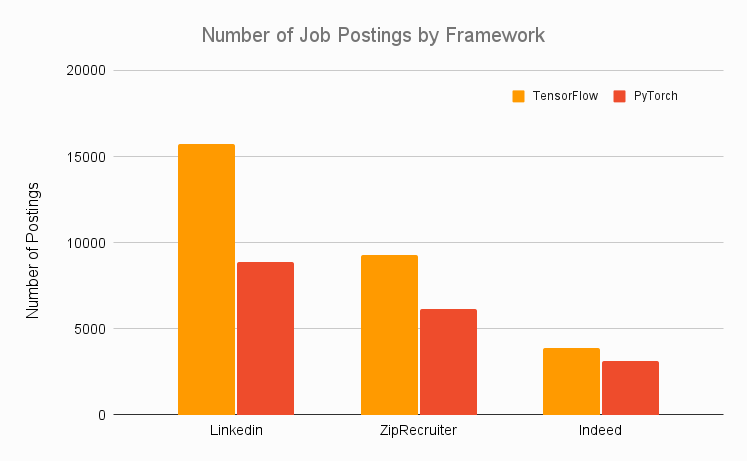
따라서 보다 쉽게 작업할 수 있는 프레임워크를 사용하십시오. 보다 직관적인 프레임워크를 사용하면 포트폴리오를 효율적으로 구축할 수 있습니다. 이는 특정 프레임워크의 API에 익숙해지는 것보다 훨씬 더 중요합니다. 즉, 완전히 프레임워크에 구애받지 않는 경우 선호되는 업계 프레임워크인 TensorFlow를 사용하십시오. 아래 그래프의 각 프레임워크에 대해 다양한 직업 웹사이트의 채용 공고 수를 집계했으며 TensorFlow가 PyTorch를 크게 압도했습니다.
결론: OpenAI 또는 TensorFlow에서 일하는 목표가 절망적으로 직관적이지 않은 경우와 같이 PyTorch를 사용해야 하는 특별한 이유가 있다면 자유롭게 사용하십시오. 하지만 TensorFlow에 집중하는 것이 좋습니다.
내가 취미생활을 한다면?
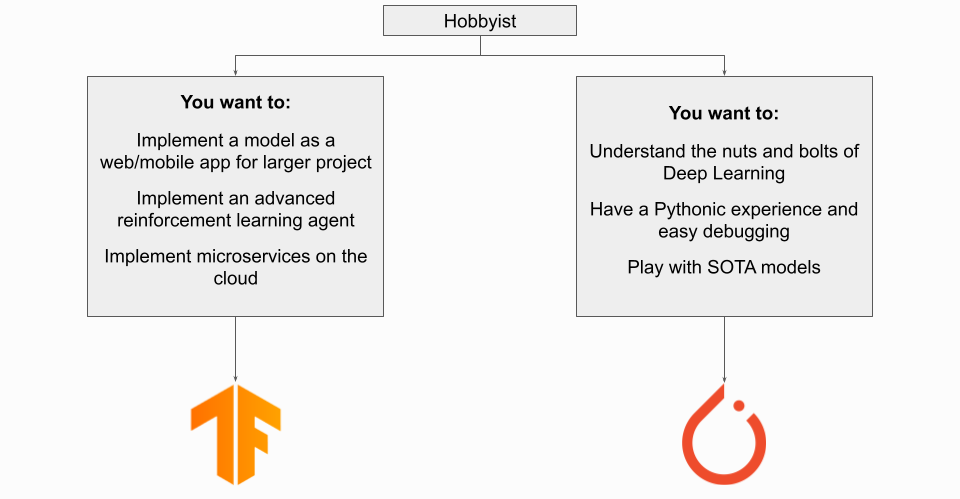
딥 러닝에 관심이 있는 취미 생활자라면 사용하는 프레임워크는 목표에 따라 다릅니다. 더 큰 프로젝트의 일부로 딥 러닝 모델을 구현하는 경우 특히 IoT/임베디드 장치에 배포하는 경우 TensorFlow를 사용하고 싶을 것입니다. PyTorch Live가 출시되면 모바일 애플리케이션에 PyTorch를 사용할 수 있지만 현재로서는 TensorFlow + TFLite가 여전히 선호되는 방법론입니다.
목표가 딥 러닝 자체를 배우는 것이라면 이 경우에 가장 적합한 프레임워크는 배경에 따라 다릅니다. 일반적으로 PyTorch는 아마도 여기서 더 나은 옵션일 것입니다. 특히 Python 작업에 익숙하다면 더욱 그렇습니다. 딥 러닝을 이제 막 배우기 시작한 완전 초보자라면 다음 섹션을 참조하세요.
내가 완전 초보자라면?
딥 러닝에 관심이 있고 이제 막 시작하려는 완전 초보자라면 Keras를 사용하는 것이 좋습니다. 높은 수준의 구성 요소를 사용하여 딥 러닝의 기본 이해를 쉽게 시작할 수 있습니다. 딥 러닝의 기본 사항을 더 철저히 이해하기 시작할 준비가 되면 다음과 같은 몇 가지 옵션이 있습니다:
새 프레임워크를 설치하고 싶지 않고 귀하의 역량이 새 API로 얼마나 잘 변환될지 걱정된다면 Keras에서 TensorFlow로 "드롭다운"을 시도할 수 있습니다. 배경에 따라 TensorFlow가 혼란스러울 수 있습니다. 이 경우 PyTorch로 이동해 보십시오.
기본적으로 Python처럼 느껴지는 프레임워크를 원한다면 PyTorch로 이동하는 것이 가장 좋은 방법일 수 있습니다. 이 경우 새 프레임워크를 설치하고 사용자 지정 스크립트를 잠재적으로 다시 작성해야 합니다. 또한 PyTorch가 다소 번거롭다면 PyTorch Lightning을 사용하여 코드를 구획화하고 일부 상용구를 제거할 수 있습니다. .
완전히 초보자라면 TensorFlow와 PyTorch 모두에서 YouTube 튜토리얼을 보고 어떤 프레임워크가 더 직관적으로 느껴지는지 결정하는 것이 좋습니다.
맺음말
보시다시피, PyTorch 대 TensorFlow 논쟁은 환경이 끊임없이 변화하는 미묘한 차이가 있으며 오래된 정보로 인해 이러한 환경을 이해하기가 훨씬 더 어렵습니다. 2022년에 PyTorch와 TensorFlow는 모두 매우 성숙한 프레임워크이며 핵심 딥 러닝 기능이 크게 겹칩니다. 오늘날에는 모델 가용성, 배포 시간, 관련 생태계와 같은 각 프레임워크의 실질적인 고려 사항이 기술적인 차이점을 대체합니다.
두 프레임 워크 모두 좋은 문서, 많은 학습 리소스 및 활성 커뮤니티를 가지고 있기 때문에 두 프레임 워크를 선택하는 데 실수가 없습니다. PyTorch는 연구 커뮤니티에서 폭발적으로 채택된 후 사실상의 연구 프레임워크가 되었고 TensorFlow는 레거시 산업 프레임워크로 남아 있지만 두 도메인 모두에서 각각에 대한 사용 사례가 확실히 있습니다.
우리의 권장 사항이 복잡한 PyTorch 대 TensorFlow 환경을 탐색하는 데 도움이 되었기를 바랍니다! 더 많은 도움이 되는 정보는 블로그에서 다른 콘텐츠를 확인하세요!


잘 읽었습니다. 감사합니다!!