Distinguish images of dogs from cats
[kaggle 링크]
https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/overview
Data Description
The train folder contains 25,000 images of dogs and cats. Each image in this folder has the label as part of the filename. The test folder contains 12,500 images, named according to a numeric id. For each image in the test set, you should predict a probability that the image is a dog (1 = dog, 0 = cat).
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))

test.zip 와 train.zip 압축파일을 풀어줍니다.
!unzip -q -o /kaggle/input/dogs-vs-cats-redux-kernels-edition/train.zip
!unzip -q -o /kaggle/input/dogs-vs-cats-redux-kernels-edition/test.zip import glob
glob.glob("train/*")[:5] python glob 모듈의 glob 함수를 이용해
정답 파일이 들어있는 train/..~ 파일명들을 리스트로 변환할 수 있다.
아래는 돌려본 결과값이다.
from PIL import Image
Image.open("train/cat.5978.jpg")python 이미지 라이브러리인 pillow(PIL) 을 이용해 해당 경로의 이미지를 열어 볼 수 있습니다.

데이터 프레임 만들기
판다스(Pandas) DataFrame 을 이용해 데이터 리스트를 표(Table) 형태로 만들어 줍니다.
Pandas (Python Data Analysis Library)
python을 활용해 데이터 분석을 하기위해서 사용하는 필수적인 패키지
통계 분석을 위해 많이 사용되는 R의 Dataframe을 벤치마킹하여 Python에서 사용할 수 있는 형태의 Dataframe을 제공해주는 라이브러리이다.
Pandas DataFrame
list, dictionary, series, ndarray 등 다양한 데이터 타입을 이용하여 표의 형태로 처리하는 자료구조이다. 보통 RDB 환경에서 SQL로 테이블을 컨트롤할 수 있는 수준의 기능들이 상당 부분 데이터프레임에 구현되어있다.
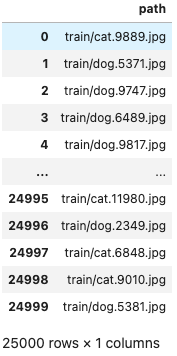
train = pd.DataFrame({"path": glob.glob("train/*")})
train코드 실행 결과
path 값을 보면 cat 혹은 dog 로 이미지의 정답 값이 path값 안에 포함되어있는 것을 알 수 있다. 이 값을 편집하여 추출해 라벨링을 한다.
train['label'] = train['path'].apply(lambda x:x.split('/')[-1].split('.')[0])
train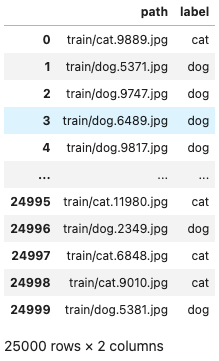
이미지 제네레이터
많은 이미지를 전부다 돌리고 늘리고 한 결과들을 램에 캐시할 수가 없을 것이다.
메모리상엔 기본 이미지만 올려놓고 학습시 배치단위로 입력될 때 살짝 변조해서 데이터를 입력해주는 방식으로 큰 메모리 손실없이 데이터를 학습하게 하는 생성기이다.
karas 에서 제공하는 이미지 제네레이터를 이용한다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
idg = ImageDataGenerator()
train_generator = idg.flow_from_dataframe(train, x_col='path', y_col='label', batch_size=64, target_size=(100,100)) # batch 단위로 나눠서 함 - arguments

모델 정의
from tensorflow.keras import *
from tensorflow.keras.layers import *
from tensorflow.keras.applications.inception_v3 import InceptionV3
model = Sequential()
iv = InceptionV3(include_top=False, pooling='avg')
model.add(iv)
model.add(Dense(2, activation='softmax')) InceptionV3
48개 계층으로 구성된 CNN(Convolutional Neural Network, 컨벌루션 신경망, 합성곱 신경망) 이다.
https://norman3.github.io/papers/docs/google_inception.html
https://runebook.dev/ko/docs/tensorflow/keras/applications/inceptionv3
include_top 네트워크의 마지막 계층으로 맨 위에 완전 연결 계층을 포함할지 여부를 나타내는 부울입니다. 기본값은 True 입니다.
pooling include_top 이 False 인 경우 기능 추출을 위한 선택적 풀링 모드
- None (기본값)은 모델의 출력이 마지막 컨벌루션 블록의 4D 텐서 출력이됨을 의미합니다.
- avg 는 글로벌 평균 풀링이 마지막 컨볼 루션 블록의 출력에 적용되므로 모델의 출력이 2D 텐서가됨을 의미합니다.
max 는 글로벌 최대 풀링이 적용됨을 의미합니다.
Dense
https://runebook.dev/ko/docs/tensorflow/keras/layers/dense
units 양의 정수, 출력 공간의 차원. activation 사용할 활성화 기능. 아무것도 지정하지 않으면 활성화가 적용되지 않습니다 (예 : "선형"활성화 : a(x) = x ).
softmax
입력받은 값을 출력으로 0~1 사이의 값으로 모두 정규화하며, 출력 값들의 총합은 항상 1이 되는 특성을 가진 함수다.
Keras Sequential model
레이어를 선형으로 연결하여 구성합니다. 레이어 인스턴스를 생성자에게 넘겨줌으로써 Sequential 모델을 구성할 수 있습니다.
https://keras.io/ko/getting-started/sequential-model-guide/
model.compile(metrics='acc', loss='categorical_crossentropy', optimizer='adam')
model.fit(train_generator)categorical crossentropy(Multi-class classification에 사용) loss로 지정하여 컴파일 하고, fit() 함수를 사용하여 모델 학습을 합니다.
fit()
- X : 입력 데이터
- Y : 결과(Label 값) 데이터
- batch_size : 한 번에 학습할 때 사용하는 데이터 개수
- epochs : 학습 데이터 반복 횟수
RESULT
GPU로 돌린 결과는 다음과 같다.
391/391 [==============================] - 81s 173ms/step - loss: 0.4716 - acc: 0.7968
학습할수록 정확도가 올라가고 있으며, loss 는 줄어들고 있다.
391 은 25000/64 으로, 2만5천장의 이미지를 64 배치의 크기로 돌렸을 때라는걸 알 수 있다.
