
정의
대규모 데이터 처리용 통합 분석 엔진
- 오픈소스이며 범용적인 목적을 지닌 분산 클러스터 컴퓨팅 프레임워크
- SQL, 스트리밍, 머신러닝 및 그래프 처리를 위한 기본 제공 모듈 존재
- 클라우드의 Apache Hadoop, Apache Mesos, Kubernetes에서 자체적으로 실행될 수 있음
- 다양한 데이터 소스에 대해 실행될 수 있음
등장 배경
-
MapReduce 형태의 클러스터 컴퓨팅 패러다임의 한계를 극복하고자 등장 (Hadoop의 단점을 보완하기 위해)
→ In-memory 연산을 통해 처리 성능을 향상시키고자 -
Map Reduce
- 디스크로부터 데이터를 읽은 후 Map을 통해 흩어져 있는 데이터를 Key-Value 형태로 연관성 있는 데이터끼리 묶은 후에 Reduce를 하여 중복된 데이터를 제거하고 원하는 데이터로 가공하여 다시 Disk에 저장
- 이러한 파일 기반의 Disk I/O는 성능이 좋지 못했음
Apache Spark & Hadoop
- 유사성 높은 Apache 최상위 프로젝트로서 함께 사용되는 경우가 많음
Spark 생태계 주요 구성 요소
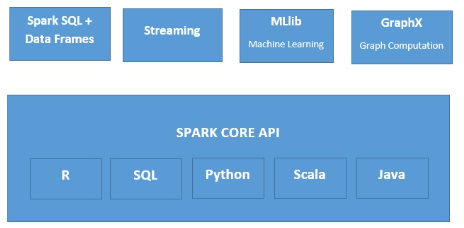
1) Spark Core
- 범용 분산 데이터 처리 엔진
- SQL, 스트림 처리, 머신러닝, 그래프 계산을 위한 라이브러리가 있고 이 모든 것을 애플리케이션에서 함께 사용할 수 있음
- 전체 프로젝트의 기반으로서 분산된 작업 디스패치, 예약, 기본 I/O 기능을 제공
2) Spark SQL
- 구조화된 데이터를 사용하는 작업을 위한 Spark 모듈
- 다양한 데이터 소스에 액세스하는 일반적인 방법 지원
- SQL이나 친숙한 DataFrame API를 사용하여 Spark 프로그램 내의 구조화된 데이터를 쿼리할 수 있음
- HiveQL 구문을 지원하며 기존 Apache Hive 웨어하우스에 대한 액세스를 허용
- 서버 모드에서는 자바 데이터베이스 또는 개방형 데이터베이스를 통해 표준 연결을 제공
3) Spark Streaming
- 확장 가능하고 내결함성 있는 스트리밍 솔루션을 쉽게 빌드할 수 있게 해줌
- 스트림 처리에 Spark 언어 통합 API를 활용하므로 일괄 작업과 동일한 방식으로 스트리밍 작업을 작성할 수 있음
- Java, Scala, Python을 지원
- 즉시 사용 가능한 Stateful, Exactly-Once 시맨틱스를 갖추고 있음
4) MLlib
- 실용적인 ML을 확장 가능하고 쉽게 만드는 도구를 갖춘 Spark 확장형 머신러닝 라이브러리
- 분류, 회귀분석, 추천 및 클러스터링 등 일반적인 학습 알고리즘이 많이 포함되어 있음
- 기능 변환, ML 파이프라인 구성, 모델 평가, 분산 선형 대수, 통계를 포함한 워크플로와 기타 유틸리티도 포함
5) GraphX
- 그래프와 그래프 병렬 계산을 위한 Spark API
- 유연성이 뛰어나며 그래프와 컬렉션 모두에서 원활하게 작동함
- 추출/변환/로드와 탐색 분석, 반복적 그래프 계산이 한 시스템 내에 통합되어 있음
- 매우 유연한 API 외에도 다양한 그래프 알고리즘이 포함되어 있음
- Spark의 유연성, 내결함성, 사용 편의성 유지
기본 동작 원리 및 아키텍처
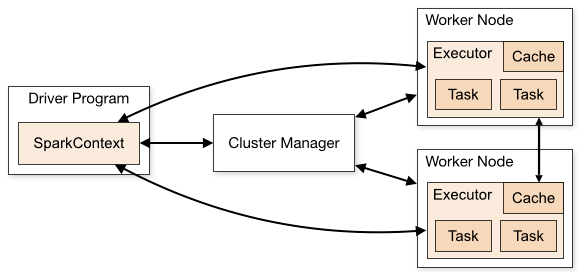
- Spark Application: Spark 실행 프로그램. Driver와 Executor 프로세스로 실행되는 Master-Slave 구조
1) Driver
- Spark Application을 실행하는 프로세스
- Main 함수를 실행하고 SparkContext 객체 생성
- Spark Application의 라이프 사이클을 관리하고 사용자로부터 입력을 받아 애플리케이션에 전달
2) Spark Context
- Cluster Manager와 연결되는 객체
3) Cluster Manger
- Spark Application의 리소스를 효율적으로 배분
4) Executor
- Task의 실행을 담당하는 에이전트. 실제 작업을 진행하는 프로세스
- Task 단위로 작업을 실행하고 결과를 Driver에 알려줌
5) Task
- Executor에서 실행되는 실제 작업
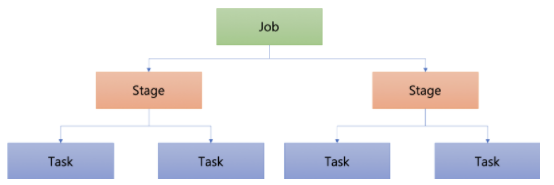
- Job: Spark Application에 전달한 작업
- Stage: 단위에 따라 구분한 작업
- Task: Executor에서 실행되는 실제 작업
특징
- Spark는 다음 사항들이 필요
- Cluster들을 관리하는 Cluster Manager
- 자주 사용되는 Cluster Manager Hadoop의 YARN, Standalone, SIMR (Spark in MR), Apache Mesos, Kubenetes 등
- 데이터를 분산 저장하는 Distributed Storage System
- 자주 사용되는 Distributed Storage System HDFS, Map-FS, Cassandra, OpenStack Swift, Amazon S3, Kudu, Custom Solution, HBase 등 가장 많이 사용되는 것은 Hadoop → 압축 알고리즘을 지원하며 Spark와 같은 머신에서 구동 가능하기 때문에
API
1) RDD (Resilient Distributed Dataset)
- Resilient Distributed Dataset ?
- Resilient: 메모리에서 데이터 손실 시 파티션을 재연산해 복구 가능
- Distributed: 클러스터의 모든 머신의 메모리에 분산 저장
- Dataset: 외부 파일 시스템과의 연동
- 여러 클러스터에 분산되어 있으며 Fault-tolerant한 방식으로 유지되는 변경 불가능한 (Read-only) 형태의 데이터 모음
- Low-level Transformation & Control을 원하는 경우에 사용
- Schema를 포함하지 않아도 무관한 경우에 사용하는 것도 좋음
- 각 RDD는 연결되어 있으며, 하나의 RDD가 실패하는 경우 이전 단계로 Re-precessing을 수행하는 Lineage Graph
- 인메모리 컴퓨팅에서 Fault Tolerance를 보장하기 위함
2) Data Frame
- Spark 1.3x 부터 Named Column으로 구성된 데이터의 분산 집합인 Data Frame이 등장하게 됨
- Named Column 스키마를 가진 RDD로 관계형 데이터베이스의 테이블과 비슷
- Named Column 스키마를 가진 RDD로 관계형 데이터베이스의 테이블과 비슷
- Data Frame 부터는 Spark 내부에서 최적화를 할 수 있는 기능들이 추가됨
- 또한 기존 RDD에 스키마를 부여하고 질의나 API를 통해 데이터를 쉽게 처리할 수 있음
3) Dataset
- Spark 2.0부터는 Data Frame과 Dataset이 Dataset으로 병합되어 데이터 처리를 통합
- 내부 동작 방식에는 Catalyst Optimizer를 통해 실행 시점에 최적화된 코드를 제공하여 언어에 무관하게 동일한 성능을 보장
- 개념적으로 Data Frame은 Dataset의 부분집합
- Strongly-typed API / Untyped API라는 2가지 특성을 모두 사용
File Format
- Spark 데이터를 파일로 저장할 경우 여러 파일 포맷을 사용할 수 있음
대표적으로 사용되는 파일 포맷
-
CSV, JSON
- 일반적으로 사용하는 TEXT 기반의 파일 포맷
- 사람이 읽을 수 있지만 압축이 되지 않았기 때문에 용량이 큼
-
Parquet (Columa)
- Spark와 함께 가장 널리 사용되는 파일 포맷
- Binary 포맷 사용
- 데이터 뿐만 아니라 컬럼명, 데이터 타입, 기본적인 통계 데이터 등의 메타데이터를 포함
- CSV, JSON과 다르게 기본적인 압축 알고리즘을 사용
- WORM (Write Once Read Many) 특성으로 인해 쓰는 속도는 느리지만 읽는 속도는 빠름
- 컬럼 베이스 스토리지로 컬럼 단위로 저장을 하기 때문에, 전체 테이블에서 특정 컬럼만 쿼리할 때 빠른 성능을 보임
-
Avro (Row)
- Row에서 전체 컬럼을 리턴해야 하는 시나리오의 경우에는 Avro가 더 유리
- Parquet과 더불어 Spark와 함께 널리 사용되는 Binary 데이터 포맷
- 로우 베이스로 데이터를 저장
- Binary로 데이터를 저장하고 스키마는 JSON 파일에 별도로 저장 → 사용자가 Binary 파일을 이해할 필요 없이 JSON 만으로도 전체적인 데이터 포맷에 대한 이해가 가능
장점
1) 속도
- Hadoop 맵리듀스보다 100배 빠른 속도로 워크로드 실행
- 최첨단 DAG (Directed Acyclic Graph) 스케줄러, 쿼리 최적화 도구, 물리적 실행 엔진을 사용하여 일괄 처리 데이터와 스트리밍 데이터 모두에 대해 고성능 달성
2) 사용 편의성
- 병렬 앱을 쉽게 빌드할 수 있게 해주는 80개가 넘는 상위 수준 연산자 제공
- Scala, Python, R, SQL 셀에서 대화형으로 Spark를 사용하여 애플리케이션을 빠르게 작성할 수 있음
3) 보편성
- SQL, DataFrame, 머신러닝용 MLlib, GraphX, Spark Streaming을 비롯한 다양한 라이브러리 지원
- 이러한 라이브러리를 동일한 애플리케이션에서 원활하게 결합할 수 있음
4) 오픈소스 프레임워크 혁신
- 글로벌 커뮤니티 지원
- 오픈소스 커뮤니티의 집단적 힘으로 더 많은 아이디어 / 빠른 개발 가능
- TTM (Time To Market) 단축
