
Computer Networking: A Top-Down Approach, 7th Edition의 번역 및 정리입니다.
이상적으로는 두 종단 시스템 사이에서 원하는 만큼의 데이터를 지연없이 전송할 수 있다면 좋겠지만, 실제로는 그럴 수 없다.
1.4.1 Overview of Delay in Packet-Switched Networks
패킷이 소스를 출발해, 여러 개의 라우터를 지나, 목적지까지 간다고 하자. 이렇게 패킷이 이동하는 경로 위의 모든 노드에서는 반드시 어떤 종류든 지연이 발생하게 된다. 많은 인터넷 애플리케이션의 성능은 이 네트워크 지연에 크게 영향을 받는다. 패킷 스위칭과 컴퓨터 네트워크에 대해 더 잘 이해하기 위해서는, 이러한 지연들이 갖는 성질과 그 중요성에 대해 잘 알아야 한다.
Types of Delay
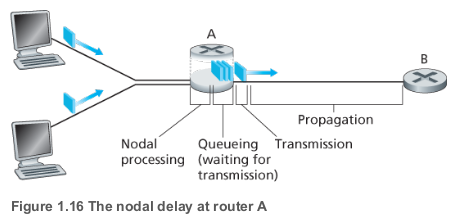
라우터 A에는 라우터 B로 향하는 아웃바운드 링크가 있고, 이 링크 앞에는 큐(버퍼)가 있다. 패킷이 라우터 A에 도착하면, A는 패킷의 헤더를 검사해 적절한 아웃바운드 링크로 보낸다. 패킷은 큐의 맨 앞에 있을 때 B로의 링크를 타서 이동하고, 만약 아직 자기 앞에 다른 패킷이 남아있으면 큐에서 대기하게 된다
Processing Delay
패킷의 헤더를 검사하고 어디로 보낼지 결정하는 등의 처리를 하는 데 걸리는 시간이다. 고속 라우터의 processing delay는 수 마이크로초, 혹은 그 이하로 아주 짧다. 라우터는 프로세싱이 끝나면 보낼 다음으로 보낼 라우터와 연결된 링크 앞의 큐로 해당 패킷을 보낸다.
Queuing Delay
큐에 있는 패킷들은 링크로 전송될 때까지 대기한다. 이 queuing delay의 길이는 먼저 도착해 전송을 기다리고 있는 패킷의 수에 따라 달라진다. 큐가 비어있어 대기 중인 패킷이 없다면 queuing delay는 0이 될 것이고, 트래픽이 많아 대기 중인 패킷들이 많다면 queuing delay는 길어질 것이다. 실제 queuing delay는 수 마이크로초에서 수 밀리초 정도다.
Transmission Delay
Transmission delay는 한 패킷의 모든 비트를 링크로 밀어넣는 데 걸리는 시간이다. 패킷의 길이를 비트, 라우터 A에서 라우터 B로 연결된 링크의 전송 속도를 bits/sec이라 하자. 이때 transmission delay는 이 된다. Transmission delay도 실제로 수 마이크로초에서 수 밀리초 정도가 된다.
Propagation Delay
비트를 링크로 밀어넣으면, 이제는 라우터 B로 전파를 해줘야 한다. 패킷을 링크의 시작점에서 라우터 B로 전파하는 데 걸리는 시간이 propagation delay다. 비트는 링크의 전파 속도를 따라 전파되며, 그 전파 속도는 링크의 물리 매체에 따라 달라진다. Propagation delay는 두 라우터 사이의 거리를 propagation speed로 나눠 구할 수 있다. WAN에서 propagation delay는 보통 수 밀리초 정도다.
Transmission Delay vs. Propagation Delay
- Transmission delay는 라우터가 패킷을 링크로 밀어넣는 데 필요한 시간으로, 두 라우터 사이의 거리와는 상관이 없다.
- Propagation delay는 하나의 비트를 한 라우터에서 다른 라우터로 전파하는 데 걸리는 시간으로, 패킷 길이나 링크의 전송 속도와는 관련이 없다.
이 각각 processing, queuing, transmission, propagation delay라 하자. 전체 nodal delay 이다.
1.4.2 Queuing Delay and Packet Loss
다른 지연 과 달리, 는 패킷마다 달라진다. 그렇기 때문에 queuing delay를 기술할 때는 보통 queuing delay의 평균, 분산 등의 통계적인 방법을 사용한다.
queuing delay는 언제 커지고, 또 언제 작아질까? 이 질문에 대한 답은 큐에 도달하는 트래픽의 속도, 링크의 전송 속도, 도달 트래픽의 성질(주기적으로 오는지, 한 번에 갑자기 많이 오는지 등)에 따라 달라진다.
를 큐에 도달하는 패킷들의 평균 속도(단위는 packets/sec), 을 전송 속도라 하자. 편의상 모든 패킷들이 비트의 길이라고 하면, 패킷들이 큐에 도달하는 평균 속도는 bits/sec이 된다. 큐가 아주 커서 무한히 많은 비트들을 담을 수 있다고 하자.
이때 트래픽 강도(traffic intensity) 은 queuing delay가 얼마나 될지 가늠하는 데 유용하게 쓰일 수 있다.
+ 큐에서 전송될 수 있는 비트보다 큐로 들어오는 비트가 더 많은 경우
+ 큐에 계속해서 패킷이 차고, queuing delay도 무한히 커지게 될 것
+ 도달하는 트래픽의 특성이 queuing delay에 영향을 준다.
+ 패킷이 주기적으로 온다고 해보자.
+ 매 초 마다 패킷이 도착하면, queuing delay가 발생하지 않는다.
+ 한 번에 많은 수의 패킷이 오면 평균 queuing delay도 커진다.
Packet Loss
위에서는 큐가 무한히 많은 패킷들을 담을 수 있다고 가정했지만, 실제로는 그렇지 않다.
실제로는 큐의 용량이 유한하기 때문에, packet delay는 무한히 커지지 않는데, 대신 큐가 꽉 차는 경우가 있을 수는 있다. 큐에 더 이상 패킷을 저장할 여유가 없으면, 라우터는 패킷을 삭제(drop)하고, 패킷은 손실(lost)된다.
종단 시스템의 관점에서 보자. 손실된 패킷은 소스에서는 보내지지만 목적지에는 도착하지 못한다. 패킷 손실의 비율은 트래픽 강도가 커짐에 따라 증가한다. 따라서 노드의 성능은 종종 지연뿐만 아니라 패킷 손실 확률을 통해서 측정하기도 한다.
1.4.3 End-to-End Delay
지금까지는 단일 노드에서 발생할 수 있는 지연에 대해서만 이야기했는데, 소스에서 목적지까지의 전체 지연에 대해서도 생각해보자. 소스에서 목적지까지의 경로 위에 개의 라우터가 있다고 하자. 단 queuing delay가 무시할 수 있을 만큼 충분히 작고, 각 노드에서의 processing, propagation delay가 으로 동일하고, 각 노드의 전송 속도도 bits/sec으로 동일하다고 가정한다.
이때 nodal delay의 합 이 end-to-end 딜레이 가 된다.
End System, Application, and Other Delays
processing, transmission, propagation delay 외에도, 종단 시스템에서 추가적인 지연이 발생할 수도 있다.
1.4.4 Throughput in Computer Networks
네트워크에는 지연, 패킷 손실 외에도 추가적인 성능 척도가 있는데 end-to-end 처리량(throughput)이다. 호스트 A에서 호스트 B로 큰 파일을 전송한다고 해보자. 특정 시점의 순간 처리량은 호스트 B가 파일을 받는 속도(bits/sec)이고, 비트 파일을 전송하는 데 초가 걸린다면 파일 전송의 평균 처리량은 bits/sec이 된다.
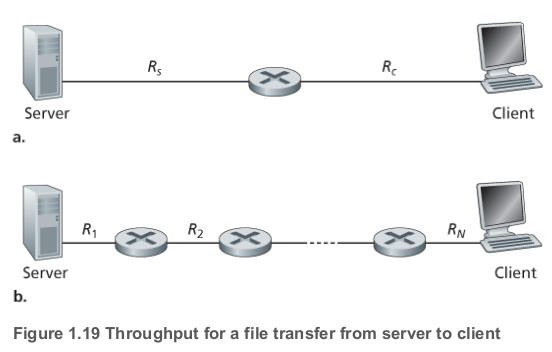
위와 같은 네트워크를 생각해보자. 서버는 보다 빠르게 데이터를 보낼 수 없고, 라우터는 보다 빠르게 데이터를 보낼 수 없다.
end-to-end 경로 상의 링크 중 가장 낮은 속도의 링크를 병목 링크(bottleneck link)라 부르고, 이때 end-to-end 처리량은 병목 링크의 전송 속도가 된다.
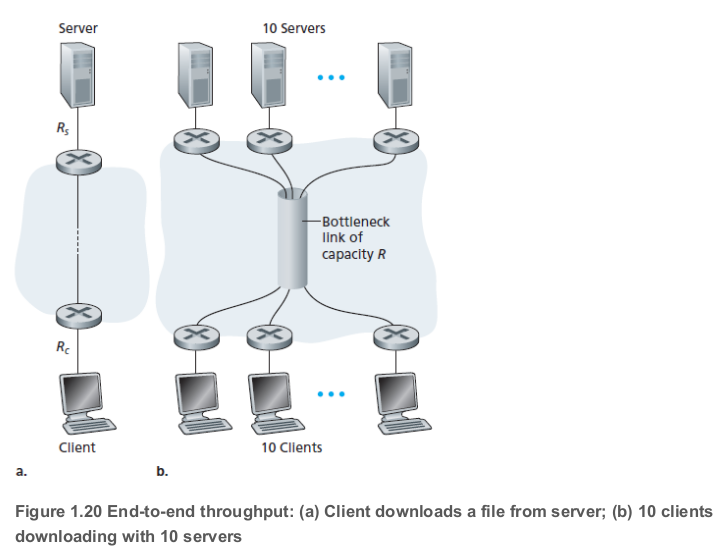
이번에는 위의 (b)를 생각해보자. 마찬가지로 서버들에서 바로 다음 라우터까지는 , 클라이언트에서 가장 가까운 라우터까지는 다. 만약 각 서버에서 클라이언트로의 모든 경로에서 공유되는, 보다 빠른 전송 속도 을 가지는 링크가 있다면 end-to-end 처리량은 어떻게 될까? Mbps, Mbps, Mbps라 하자. 이때 다운로드의 병목은 코어의 공유 링크가 되고, 그 처리량은 (각 다운로드 당) kbps가 되어, end-to-end 처리량도 kbps가 된다.
처
