
Computer Networking: A Top-Down Approach, 7th Edition의 번역 및 정리입니다.
요즘에는 넷플릭스나 유튜브 등의 영상 스트리밍 서비스가 인터넷 트래픽의 대부분을 잡아먹는다. 이 섹션에서는 비디오 스트리밍 서비스가 어떻게 구현되는지에 대해 간략하게 알아보자.
1. Internet Video
영상 스트리밍 애플리케이션의 비디오는 서버에 저장되어있고, 사용자는 자신이 원할 때 서버에 해당 비디오를 보기 위한 요청을 보낸다.
이 비디오 매체는 어떤 것일까? 비디오는 특정 속도로 보여지는 이미지의 시퀀스다. 압축되지 않은, 디지털로 인코딩된 이미지는 픽셀의 배열로 이루어져 있으며, 각 픽셀은 휘도와 색을 표현하기 위해 비트 숫자로 인코딩 된다. 비디오의 중요한 특징 중 하나는 압축을 할 수 있다는 것, 따라서 비디오의 퀄리티와 비트 전송률(bit rate)을 바꿀 수도 있다는 점이다. 요즘 쓰이고 있는 압축 알고리즘은 비디오를 원하는 비트 전송률에 맞춰 압축할 수 있고, 비디오 압축을 이용하면 같은 비디오의 퀄리티에 따른 여러 버전을 만들 수도 있다.
네트워크의 관점에서 볼 때, 비디오의 가장 두드러진 특징은 높은 비트 전송률을 가진다는 것이다. 압축된 인터넷 비디오는 100kbps(저퀄리티 비디오)에서 3Mbps(고해상도 영화)의 비트 전송률을 가지며, 4K 영상의 경우 10Mbps가 넘는 비트 전송률을 가진다. 때문에 비디오는 많은 트래픽을 유발시키고, 저장 공간도 많이 필요로 한다.
비디오 스트리밍의 가장 중요한 성능 척도는 평균 end-to-end 스루풋이다. 연속 재생을 가능케하려면 네트워크는 적어도 압축된 비디오의 비트 전송률만큼의 평균 스루풋을 스트리밍 애플리케이션에 제공할 수 있어야 하기 때문이다.
2. HTTP Streaming and DASH
HTTP 스트리밍에서 비디오는 여느 파일들과 마찬가지로 특정한 URL을 가지고 HTTP 서버에 저장된다. 사용자가 비디오를 보고 싶을 때 클라이언트는 서버와 TCP 연결을 맺고, 해당 영상의 URL로 서버에 HTTP GET 요청을 보낸다. 요청을 받은 서버는 HTTP 응답 메시지로 비디오 파일을 보낸다.
클라이언트 쪽에서 데이터들은 클라이언트 애플리케이션 버퍼에 모이고, 이 버퍼의 데이터량이 기정된 크기를 넘을 때 애플리케이션은 재생을 시작한다. 구체적으로 말하면, 비디오 스트리밍 애플리케이션은 주기적으로 클라이언트 애플리케이션의 버퍼로부터 비디오 프레임을 가져오고, 가져온 프레임들의 압축을 풀고, 이를 사용자의 스크린에 보여준다.
HTTP 스트리밍은 오랫동안 쓰여오긴 했지만, 큰 단점을 하나 가지고 있다. 클라이언트의 가용 대역폭에 변화가 생길 수 있음에도 모든 클라이언트가 동일한 비디오 인코딩을 받는다는 것이다. 이로 인해 새로 개발된 것이 DASH(Dynammic Adaptive Streaming over HTTP)다. DASH에서 비디오는 서로 다른 비트 전송률, 비디오 품질을 가지고 있는 여러 버전으로 인코딩될 수 있다. 클라이언트는 수 초 길이의 비디오 청크를 동적으로 요청할 수 있다. 가능 대역폭이 높은 경우 클라이언트는 높은 전송률의 버전을, 그렇지 않은 경우에는 낮은 전송률의 버전을 선택하고 HTTP GET 요청 메시지를 통해 청크를 한 번에 하나씩 가져게오게 된다.
DASH를 이용하는 경우, 각 비디오의 버전들은 서로 다른 URL로 HTTP 서버에 저장된다. HTTP 서버에는 매니페스트 파일(manifest file)이 있는데, 이는 각 비트 전송률에 해당하는 버전의 URL을 제공하는 역할을 한다. 클라이언트는 우선 매니페스트 파일을 요청하고 어떤 버전이 있는지를 확인한다. 이후 클라이언트는 각 시간마다 HTTP GET 요청 메시지에 매니페스트 파일에 있는 URL과 바이트-레인지를 담아 보내 청크를 선택한다. 클라이언트는 청크를 다운로드 하면서 수신 대역폭을 측정하고 전송률 결정 알고리즘을 실행해 다음으로 요청할 청크를 선택한다. 만약 클라이언트에 버퍼링된 비디오가 많고, 측정된 수신 대역폭도 높다면 클라이언트는 고-전송률 버전을 요청할 것이고, 반대의 경우에는 저-전송률 버전을 요청하게 될 것이다.
3. Content Distribution Networks
오늘날 인터넷 비디오 회사들은 매일 수억개의 비디오 스트림을 전세계의 사용자들에게 보내고 있다. 이 모든 트래픽을 전세계의 사용자들이 끊기지 않고 재생할 수 있도록 스트리밍하는 일은 어려운 일이다.
물론 비디오 스트리밍 서비스를 제공하는 가장 쉬운 방법은, 하나의 거대한 데이터 센터를 두고 모든 비디오를 저장해 전세계로 스트리밍하는 것이다. 하지만 이 방식에는 세 가지 큰 문제가 있다.
- 클라이언트가 데이터 센터에서 멀리에 있으면, 서버에서 클라이언트로의 패킷은 많은 통신 링크, 많은 ISP들을 거치게 될 것이다. 이 링크들 중 하나가 비디오 재생에 필요한 최소 스루풋을 제공하지 못하면 사용자는 심한 딜레이를 겪게 된다. 패킷이 거치는 통신 링크의 수가 많아지면 많아질 수록 그럴 가능성은 커진다.
- 유명한 비디오 하나가 같은 통신 링크를 통해 여러 번 보내지게 된다. 이는 네트워크 대역폭의 낭비를 일으키며, 비디오 회사가 ISP에 많은 비용을 지불해야만 하도록 만든다.
- 단일 데이터 센터는 단일 실패 지점이라는 말이다. 데이터 센터, 혹은 데이터 센터에서 인터넷으로의 링크에 장애가 발생하면 어떤 비디오 스트림도 전달되지 못한다.
이러한 문제들로 인해, 거의 대부분의 메이저 비디오 스트리밍 회사들은 컨텐츠 분산 네트워크(Content Distribution Networks)를 이용한다. CDN은 여러 지리적으로 분산된 위치의 서버들을 관리하고, 비디오의 사본들을 그 서버들에 저장하고, 또한 각 사용자의 요청을 최고의 사용자 경험을 제공할 수 있는 CDN 위치로 연결시키는 일을 한다.
CDN은 프라이빗 CDN일 수도, 서드파티 CDN일 수도 있다.
- 프라이빗 CDN: 컨텐츠 제공자가 소유하는 CDN. 예를 들면 구글 CDN과 유튜브.
- 서드파티 CDN: 여러 컨텐츠 제공자들을 대신해 컨텐츠를 분산시키는 네트워크
CDN은 서버 클러스터들을 위치시키기 위해 다음의 두 방식 중 하나를 이용한다.
- Enter Deep: 많은 수의 작은 서버 클러스터들을 전세계에 있는 액세스 ISP에 배포한다. 이 방식의 목표는 최종 사용자에게 최대한 가까이 서버를 위치 시켜, CDN 서버와 최종 사용자 사이의 링크 & 라우터의 수를 줄임으로써 사용자가 인식할 수 있는 딜레이를 최소화하고 스루풋을 높이는 데 있다. 이 경우 극도로 분산된 설계로 인해 클러스터를 유지 관리하는 일이 어려워진다.
- Bring Home: 적은 수의 큰 클러스터들을 이용한다. 보통은 액세스 ISP 내부로까지 들어가지 않고, IXP에 서버 클러스터들을 위치 시킨다. 유지 관리 오버헤드가 작아지는 대신, 사용자 딜레이가 커지고 스루풋이 낮아질 수 있다.
서버 클러스터가 위치하고 나면, CDN은 컨텐츠를 각 클러스터들에 복사한다. 다만 모든 비디오들을 모든 클러스터들에 복사하는 것은 아니다. 조회수가 적은 비디오도 있을 수 있고, 특정 국가에서만 많이 보는 비디오도 있을 수 있기 때문이다.
사실 많은 CDN들은 비디오를 클러스터에 푸시하는 전략보다는, 간단한 풀 전략을 사용한다. 만약 클라이언트가 어떤 비디오를 요청했는데 그 비디오가 클러스터에 있지 않다면, 클러스터는 중앙 리포지토리, 혹은 다른 클러스터에서 해당 비디오를 찾고, 그 복사본을 로컬에 저장하면서 클라이언트에게 그 비디오를 스트리밍한다. 이전에 봤던 웹 캐싱과 유사하다.
CDN Operation
이제 CDN이 어떻게 동작하는지에 대해 조금 더 자세하게 살펴보자. 사용자 호스트의 브라우저가 특정 비디오를 검색하면 CDN은 이 요청을 인터셉트해 (1) 그때 클라이언트에게 적절한 CDN 서버를 결정하고 (2) 클라이언트의 요청을 해당 클러스터로 리다이렉트한다.
그렇다면 CDN은 어떻게 적절한 클러스터를 결정할 수 있을까? 일단은 요청의 인터셉트와 리다이렉트가 어떻게 이뤄지는지 알아보자.
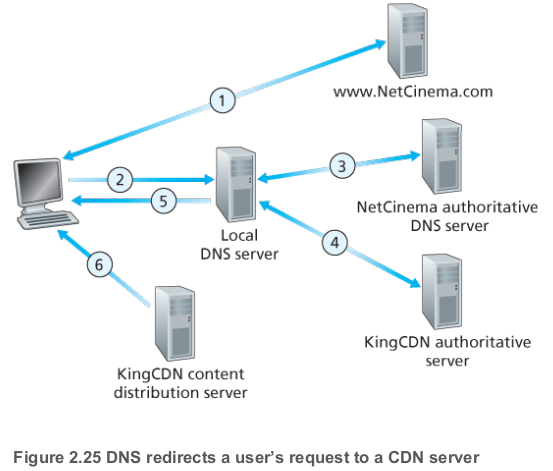
대부분의 CDN은 DNS를 통해 요청을 인터셉트 및 리다이렉트한다. 예를 들어, 컨텐츠 제공자 NetCinema가 서드파티 CDN 회사 KingCDN을 이용한다고 해보자. NetCinema의 웹 페이지에는 각 비디오를 고유하게 식별할 수 있는 URL이 있을 것이다.
- 사용자가 NetCinema의 웹 페이지(예:
http://video.netcinema.com)에 방문한다. - 사용자가 비디오 링크를 누르면, 사용자 호스트는
video.netcinema.com에 대한 DNS 쿼리를 보낸다. - 사용자의 로컬 DNS 서버는 이 DNS 쿼리를 NetCinema의 권한형 DNS로 중계한다. DNS 쿼리를 KingCDN으로 넘기기 위해, NetCinema의 권한형 DNS 서버는 IP주소를 반환하는 대신 KingCDN 도메인의 호스트명, 예를 들면
a1105.kingcdn.com을 반환한다. - 사용자의 로컬 DNS 서버는 반환받은
a1105.kingcdn.com에 대한 쿼리를 보내고, KingCDN의 DNS는 KingCDN의 컨텐츠 서버의 IP 주소를 로컬 DNS 서버로 보낸다. - 로컬 DNS 서버는 해당 컨텐츠를 제공하는 CDN 노드의 IP 주소를 사용자 호스트에게 넘겨준다.
- KingCDN 컨텐츠 서버의 IP 주소를 받은 클라이언트는, 해당 IP 주소의 서버와 직접 TCP 연결을 맺고 HTTP
GET요청을 보낸다. DASH를 사용하는 경우 서버는 클라이언트에게 매니페스트 파일을 보내줄 것이고, 클라이언트는 동적으로 비디오의 여러 버전들 중 하나의 청크를 선택하게 된다.
Cluster Selection Strategies
CDN 배포의 핵심은 동적으로 클라이언트를 CDN의 서버 클러스터나 데이터 센터로 다이렉트하는 클러스터 선택 전략(cluster selection strategy)이다. 앞서 봤듯 CDN은 클라이언트의 로컬 DNS 서버의 IP 주소를 클라이언트의 DNS 검색을 통해 알 수 있다. CDN은 이 IP 주소를 통해 적절한 클러스터를 선택해야 한다. CDN들은 각자 자기만의 클러스터 선택 전략을 사용하는데, 여기서는 간단하게 몇 가지 방식들과 그 장단점들에 대해 알아보자.
한 가지 간단한 방법은 클라이언트에게 지리적으로 가장 가까이 있는 클러스터를 할당하는 것이다. Quova나 Max-Mind와 같은 지리적 위치 데이터베이스를 이용하면 각 로컬 DNS를 특정 위치와 매핑할 수 있다. 특정 로컬 DNS로부터 DNS 요청이 들어오면, CDN은 이를 가지고 지리적으로 가장 가까운 클러스터를 고를 수 있다.
하지만 어떤 클라이언트들에게 위 방식은 제대로 작동하지 않을 수 있는데, 지리적으로 가장 가까운 클러스터라고 해서 꼭 네트워크 경로의 길이가 짧다거나 홉(hop)의 수가 적은 것만은 아니기 때문이다. 또한 최종 사용자가 멀리 떨어진 로컬 DNS를 사용하는 경우, 위 방식은 실제 사용자에게 가장 가까운 서버 클러스터를 제공하지 못한다. 마지막으로 이 방식은 특정 클라이언트에게 항상 같은 크러스터를 할당하기 때문에, 시간에 따라 변하는 네트워크 지연 및 가용 대욕폭의 변화를 반영하지 못한다.
현재 트래픽 상태에 기반해 클라이언트에게 최고의 클러스터를 제공하기 위해, CDN은 주기적으로 클러스터와 클라이언트 사이의 딜레이 및 손실 성능을 실시간 측정하기도 한다. 예를 들어 CDN은 각 클러스터가 주기적으로 전세계의 로컬 DNS에 probe(핑 메시지, DNS 쿼리 등)를 보내게 할 수 있다. 다만 이 방식의 문제는 많은 로컬 DNS가 그런 probe에 응답하도록 설정되어 있지는 않다는 것이다.
4. Case Studies: Netflix, YouTube, and Kankan
NetFlix
넷플릭스 비디오 배포는 아마존 클라우드와 넷플릭스 CDN 인프라를 이용한다. 넷플릭스에는 회원가입, 로그인, 요금 청구, 영화 카탈로그, 영화 추천 시스템 등의 많은 기능들을 처리하는 웹 사이트가 있다.
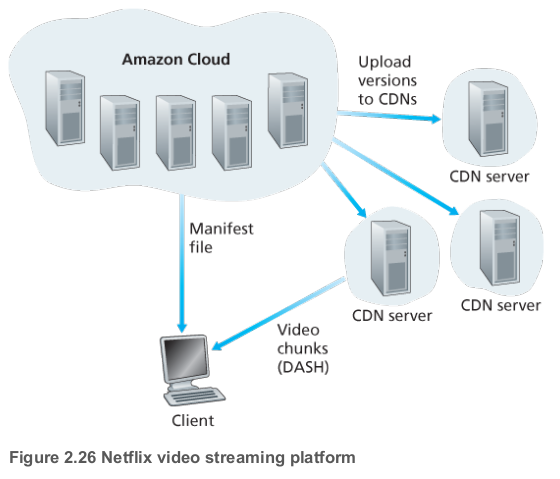
이 웹 사이트는 모두 아마존 클라우드의 아마존 서버에서 돌아간다. 아마존 클라우드는 다음과 같은 주요 기능들을 제공한다.
- Content ingestion: 넷플릭스는 영화를 고객에게 보내기 전에 우선 영화 정보를 수집하고 처리해야한다. 넷플릭스는 영화의 스튜디오 마스터 버전을 받아 아마존 클라우드의 호스트에 업로드한다.
- Content processing: 아마존 클라우드의 기기가 각 사용자 기기(데스크톱, 스마트폰 등등)에 맞는 영화 포맷을 만들어낸다. 각 포맷과 비트 전송률에 따라 영화의 여러 버전들이 만들어진다. 이것들은 DASH를 이용한 적응적 HTTP 스트리밍을 가능케 한다.
- Uploading versions to its CDN: 영화의 모든 버전들이 만들어지면, 아마존 클라우드의 호스트가 이 버전들을 CDN에 업로드한다.
넷플릭스는 비디오 스트리밍 서비스를 시작했던 2007년에는 세 개의 서드 파티 CDN 회사들을 통해 비디오 컨텐츠를 전달했지만, 지금은 자신의 프라이빗 CDN을 통해 모든 비디오를 송출하고 있다. CDN을 만들기 위해 넷플릭스는 IXP(50곳 이상)와 가정용 ISP(수백 곳) 모두에 서버 랙을 설치했다. 서버 랙의 각 서버들은 10Gbps의 이더넷 포트와 100 테라바이트가 넘는 저장 공간을 가지고 있다. 하나의 랙에 들어있는 서버의 수는 달라지는데, IXP의 경우에는 수십 개의 서버가 있어 모든 넷플릭스 스트리밍 비디오 라이브러리를 담을 수 있게 하고, 로컬 IXP의 경우에는 하나의 서버만 둬 가장 자주 보는 비디오들만 담는다.
넷플릭스의 경우 앞서 말한 풀 방식을 사용하지 않고, 사용자가 적은 시간대에 비디오들을 CDN 서버에 푸시하는 방식을 사용한다. 전체 라이브러리를 담을 수 없는 곳에는 그날 그날 자주 보는 비디오들만을 푸시한다.
이제는 클라이언트와 서버들 사이의 상호작용이 어떻게 이루어지는지에 대해 좀 더 자세히 살펴보자. 넷플릭스 비디오 라이브러리를 검색하기 위한 웹 페이지는 아마존 클라우드 서버가 제공한다. 사용자가 재생할 영화를 선택하면, 아마존 클라우드에서 돌아가는 넷플릭스 소프트웨어가 우선 어떤 CDN 서버에 영화의 복사본이 있는지를 확인한다. 그 영화를 가지고 있는 서버들 중, 서버는 클라이언트 요청을 가장 잘 처리할 수 있는 서버를 선택한다. 만약 클라이언트가 넷플릭스 CDN 서버 랙이 설치된 가정용 ISP를 사용하고, 그 서버 랙에 요청된 영화의 사본이 있다면 이 랙의 서버가 선택된다. 그렇지 않은 경우에는 보통 가까이 있는 IXP의 서버가 서택된다.
컨텐츠를 보낼 CDN 서버를 결정하고 나면, 넷플릭스는 클라이언트에게 해당 서버의 IP 주소와 매니페스트 파일을 보낸다. 클라이언트와 CDN 서버는 DASH를 이용해 직접 상호작용한다. 구체적으로, 클라이언트는 HTTP GET 메시지의 바이트 범위 헤더를 이용해 영화의 서로 다른 버전의 청크를 요청한다. 넷플릭스는 대략 4초 길이가 되는 청크를 사용하는데, 청크가 다운로드되고 있을 때 클라이언트는 받은 스루풋을 측정하고 전송률 결정 알고리즘을 이용해 다음으로 요청할 청크의 품질을 결정한다.
YouTube
유튜브는 세계에서 가장 큰 비디오 공유 사이트인데, 넷플릭스와 마찬가지로 비디오를 제공하기 위하 CDN 기술을 사용한다. 넷플릭스와 유사하게 구글도 유튜브 비디오를 위해 프라이빗 CDN을 사용하며, 수백의 IXP와 ISP에 서버 클러스터들을 설치한다. 하지만 넷플릭스와는 달리, 구글을 풀 캐싱과 DNS 리다이렉트를 사용한다. 구글의 클러스터 선택 전략은 클라이언트를 RTT가 가장 낮은 클러스터로 다이렉트하지만, 가끔은 클러스터들의 부하 균형을 맞추기 위해 좀 더 먼 클러스터로 다이렉트 하기도 한다.
유튜브는 DASH 대신 HTTP 스트리밍을 사용하며, 사용자가 수동으로 버전을 선택하도록 한다. 기존의 HTTP 스트리밍에는 중간에 스트리밍을 그만둬도 비디오 전체를 받아와야 한다는 문제가 있고, 이는 대역폭과 서버 자원의 낭비로 이어진다. 유튜브는 대역폭과 서버 자원의 낭비를 막기 위해 HTTP 바이트 레인지 요청을 이용해 원하는 만큼의 비디오 이상의 데이터가 전송되는 일을 막는다.
수백만 개의 비디오가 매일 유튜브에 업로드되고 있는데, 비디오를 업로드 할 때에도 HTTP를 사용한다. 유튜브는 받은 비디오들을 처리하고, 유튜브 비디오 포맷으로 변환한 후 비트 전송률에 따라 여러 버전들을 만든다. 이 처리는 전적으로 구글 데이터 센터에서 이뤄진다.
Kankan
위에서는 프라이빗 CDN에서 사용하는 전용 서버들에 대해서 알아봤다. 전용 서버를 사용하는 넷플릭스와 유튜브는 서버 하드웨어는 물론, 서버들이 비디오를 전송하는 데 쓰는 대역폭에 대해서도 비용을 지불해야 한다. 서비스의 규모를 생각하면, 이는 너무 비싸다. 마지막으로 인터넷에 대량의 비디오를 제공하는 전혀 다른 방식을 하나만 보고 끝내자. 이 방식은 클라이언트-서버가 아니라 P2P 방식을 사용한다. Kankan이 이러한 P2P 비디오 스트리밍을 이용한다.
높은 수준에서, P2P 비디오 스트리밍은 BitTorrent의 파일 다운로드와 아주 비슷하다. 피어는 비디오를 보고 싶을 때, 트래커에 연결해 해당 비디오의 사본을 가지고 있는 시스템 내의 다른 피어를 찾는다. 요청 피어는 비디오를 가지고 있는 다른 피어들에게 비디오 청크를 병렬적으로 요청한다. BitTorrent의 경우 청크가 어떤 순서로 들어오든 파일만 제대로 만들 수 있으면 되지만, 비디오 스트리밍의 경우 되도록이면 재생이 끊기지 않도록 해야하므로 청크도 그렇게 할 수 있도록 요청해야 한다.
최근 Kankan은 CDN-P2P 혼합 스트리밍 시스템으로 전환하고 있다. 구체적으로 Kankan은 수백개의 서버를 중국에 두고 비디오 컨텐츠들을 이 서버들에 푸시한다. 이 Kankan CDN은 비디오 스트리밍의 시작 단계에서 중요한 역할을 한다. 대부분의 경우 클라이언트는 컨텐츠의 시작 부분은 CDN 서버에 요청하고, 병렬적으로 다른 피어들에게도 컨텐츠를 요청한다. 총 P2P 트래픽이 비디오 재생에 충분하다면, 클라이언트는 CDN 스트리밍을 멈추고 피어 스트리밍만을 받고, 그렇지 않은 경우에는 CDN 연결을 재시작하고 혼합 CDN-P2P 스트리밍 모드로 전환한다. 이러한 방식으로 Kankan은 시작 딜레이를 줄이면서도 비싼 인프라 서버와 대역폭에 최소한으로 의존할 수 있게 된다.
