
Computer Networking: A Top-Down Approach, 7th Edition의 번역 및 정리입니다.
이 섹션에서는 UDP가 무엇을 어떻게 하는지 자세히 알아본다.
RFC 768에 정의된 UDP는 전송 프로토콜이 할 수 있는 최소한의 서비스만을, 그러니까 멀티플렉싱/디멀티플렉싱, 간단한 에러 확인 서비스만을 제공한다. 사실 애플리케이션 개발자가 TCP 대신 UDP를 선택하는 경우, 애플리케이션은 거의 IP와 직접 이야기하는 것이나 다름없다.
UDP는 애플리케이션 프로세스로부터 메시지를 받아 소스/목적지 포트 번호 필드를 채우고, 또 다른 두 가지 작은 필드를 추가해 결과 세그먼트를 네트워크 계층으로 보낸다. 네트워크 계층은세그먼트를 IP 데이터그램으로 만들고, 이를 수신 호스트로 보내기 위해 최선을 다한다.
수신 호스트에 세그먼트가 도착하면, UDP는 목적지 포트 번호를 이용해 세그먼트의 데이터를 적절한 애플리케이션 프로세스로 전달한다. UDP에는 세그먼트 전송 전 송수신 전송 계층 엔티티 간 핸드 셰이크 과정이 없고, 그렇기 때문에 UDP는 비연결(connectionless) 프로토콜이라 불린다.
UDP를 사용하는 대표적인 애플리케이션 계층 프로토콜에는 DNS가 있다. 호스트의 DNS 애플리케이션이 쿼리를 만들 때, 이는 DNS 쿼리 메시지를 만들고 이를 UDP로 전달한다. 목적지 종단 시스템에서 실행되는 UDP 엔티티와 따로 핸드셰이킹을 하는 일 없이, 호스트 측 UDP는 메시지에 헤더 필드를 추가하고 이를 네트워크 계층으로 보낸다. 네트워크 계층은 UDP 세그먼트를 데이터그램으로 캡슐화하고 데이터그램을 네임 서버로 보낸다. 쿼리를 날리는 호스트의 DNS 애플리케이션은 해당 쿼리에 응답이 오기를 기다린다. 만약 응답을 받지 못하면 이는 쿼리를 재전송하거나, 다른 네임 서버로 쿼리를 보내거나, 혹은 애플리케이션에 응답을 받지 못했다고 알려준다.
그렇다면 애플리케이션 개발자는 어떤 경우에 TCP 대신 UDP를 선택할까? 신뢰성 있는 데이터 전송 서비스를 제공하는 TCP를 사용하는 게 항상 더 좋지 않을까? 그렇지는 않다. 다음의 이유로, 어떤 애플리케이션은 UDP를 사용하는 게 더 적절할 수도 있다.
- 언제, 어떤 데이터를 보낼지에 대한 애플리케이션-계층 제어에 유리
+ UDP의 경우, 애플리케이션 프로세스가 데이터를 UDP로 전달하고 나서, 바로 이를 UDP 세그먼트로 패키징하고 네트워크 계층으로 전달한다.
+ 이와 달리 TCP의 경우 혼잡 제어, 패킷 재전송들을 전송 계층에서 알아서 해주며, 때문에 전송률이 UDP보다는 낮아지게 된다.
+ 어느 정도의 데이터 손실을 감내할 수 있고 세그먼트 전송에 과한 지연이 일어나기를 원하지 않는 실시간 애플리케이션들의 경우, TCP보다는 UDP가 더 어울린다.
+ 이러한 애플리케이션은 UDP를 사용하면서, 애플리케이션 계층에서 추가적인 기능들을 구현해 이용한다. - 연결 수립 없음
+ TCP는 데이터 전송을 시작하기 전에 3-way 핸드셰이크를 하지만, UDP는 사전 작업 없이 그냥 데이터를 보낸다. 따라서 UDP에서는 연결 수립으로 인한 지연이 발생하지 않는다.
+ DNS가 TCP 대신 UDP를 쓰는 이유다. TCP를 쓴다면 DNS는 훨씬 더 느려질 것이다.
+ HTTP의 경우, 웹 페이지의 신뢰성 있는 전송이 중요하기 때문에 UDP보다는 TCP를 사용한다. 하지만 HTTP의 TCP 연결 수립으로 인한 지연은 웹 문서 다운로드 속도에 큰 영향을 미친다.
+ 때문에 구글 크롬 브라우저에서 쓰이는 QUIC(Quick UDP Internet Connection) 프로토콜의 경우 기저 전송 프로토콜로 UDP를 사용하고, 신뢰성은 UDP 위의 애플리케이션 계층에서 구현해 사용하고 있다. - 연결 상태 없음
+ TCP는 종단 시스템 간 연결 상태를 유지한다. 이 연결 상태에는 송수신 버퍼, 혼잡 제어 파라미터, 시퀀스, 애크놀로지먼트 번호 파라미터 등이 포함된다. 이러한 상태 정보는 TCP에서 신뢰할 수 있는 데이터 전송 서비스를 구현하고 혼잡 제어 서비스를 제공할 때 쓰인다.
+ 한편 UDP의 경우, 연결 상태를 유지하지 않으므로 이런 파라미터들을 추적 관리할 필요가 없다. 때문에 특정 애플리케이션의 서버들의 경우 TCP 대신 UDP를 사용해 더 많은 활동 클라이언트들을 지원할 수 있게 된다. - 패킷 오버헤드가 작음
+ TCP에는 매 세그먼트마다 20바이트의 헤더 오버헤드가 발생한다.
+ 반면 UDP의 헤더 오버헤드는 고작 8바이트 밖에 되지 않는다.
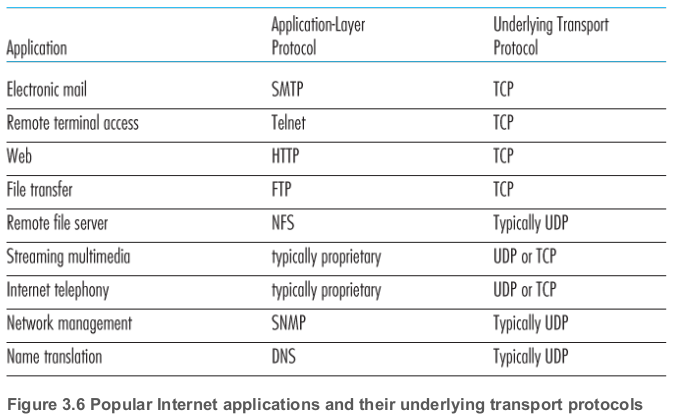
아래의 표는 자주 쓰이는 인터넷 애플리케이션과, 그것들이 사용하는 전송 프로토콜들이다. 이메일, 원격 터미널 액세스, 웹, 파일 전송 등은 TCP를 이용한다. TCP가 제공하는 신뢰할 수 있는 데이터 전송 서비스를 이용하기 위함이다.
UDP를 사용하는 애플리케이션들도 많다. 예를 들어 네트워크 관리 애플리케이션의 경우 TCP보다는 UDP를 많이 사용한다. 이러한 애플리케이션의 경우 네트워크가 스트레스 상태에 있어 신뢰성 있는 데이터 전송, 혼잡 제어 등이 이루어지기 힘들 때에도 잘 실행되어야 하기 때문이다. DNS도 UDP에서 실행된다. TCP의 연결 수립 지연을 피하기 위함이다.
오늘날의 멀티미디어 애플리케이션들(인터넷 전화, 실시간 화상 회의, 오디오/비디오 스트리밍 등)의 경우, UDP와 TCP를 모두 사용하기도 한다. 이 애플리케이션들의 경우, 어느 정도의 패킷 손실은 감내될 수 있기 때문에, 데이터 전송의 신뢰성이 애플리케이션의 성공적 동작에 큰 영향을 미치지는 않는다. 인터넷 전화, 화상 회의 등의 실시간 애플리케이션의 경우, TCP 혼잡 제어가 동작하는 경우 잘 실행되지 않는다. 이러한 이유로 멀티미디어 애플리케이션의 경우 TCP보다는 UDP를 사용한다. 단 패킷 손실률이 낮고, 보안의 이유로 UDP 트래픽을 차단되는 경우, TCP를 사용하기도 한다.
오늘날 많이 쓰이고 있기는 하지만, 멀티미디어 애플리케이션에 UDP를 사용하는 것은 논쟁적이다. 위에서 말했듯 UDP에는 혼잡 제어가 없다. 하지만 혼잡 제어는 네트워크가 아주 적은 일들만 할 수 있게 되는 혼잡 상태에 빠지지 않게 하기 위해 필요하다. 만약 모두가 어떤 혼잡 제어도 없이 고-비트 전송률 비디오를 스트리밍하고 싶어한다면, 라우터에는 엄청난 패킷 오버 플로우가 생길 것이고, 성공적으로 소스-목적지 경로를 순회할 수 있는 UDP는 극히 적어질 것이다. 게다가 제어되지 않는 UDP 송신자로 인한 높은 손실률은 다른 TCP 송신자의 전송률을 심하게 떨어트리게 될 수도 있다.따라서 혼잡 제어를 제공하지 않는 UDP를 사용하는 것은 송수신자 사이의 데이터 손실률을 높일 수 있고, 다른 TCP 세션들도 혼잡하게 만들 수 있다.
앞서 말한 구글 크롬의 QUIC 프로토콜처럼, UDP를 사용하면서도 애플리케이션 계층에서 신뢰성 있는 데이터 전송을 구현할 수는 있지만, 쉬운 일은 아니다.
1. UDP Segment Structure
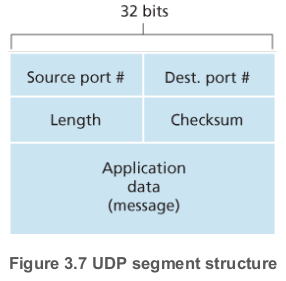
UDP 세그먼트 구조는 RFC 768에 정의되어 있다. UDP 세그먼트의 데이터 필드는 애플리케이션 데이터로 채워져있다. 예를 들어 DNS의 경우 데이터 필드는 쿼리 메시지 혹은 응답 메시지고, 스트리밍 오디오 애플리케이션의 경우에는 오디어 샘플들이 데이터 필드를 채운다
UDP 헤더에는 각 2바이트의 네 필드들이 있다. 이전 섹션에서 말한 것처럼, 목적지 호스트는 포트번호를 이용해 애플리케이션 데이터를 정확한 프로세스로 전달한다. 길이 필드는 UDP 세그먼트(헤더 + 데이터)의 길이를 명시한다. 각 UDP 세그먼트마다 데이터 필드의 크기가 달라질 수 있으므로, UDP 세그먼트의 바이트 수를 명시하는 일은 중요하다.
체크섬은 수신 호스트에서 세그먼트에 에러가 발생했는지를 확인하는 데 필요하다. 사실 체크섬은 UDP 뿐만 아니라 IP 헤더의 몇몇 헤더들에서도 계산되기는 한다.
2. UDP Checksum
UDP 체크섬은 에러 검출 기능을 제공한다. 즉 우리는 체크섬을 통해 소스에서 목적지로 이동하는 도중 UDP 세그먼트에 변조가 일어났는지를 확인할 수 있다.
송신측 UDP는 세그먼트 내 모든 16-bit 워드들의 합의 1의 보수를 계산해 UDP 세그먼트의 체크섬 필드에 넣는다.
예를 들어 3개의 16-bit 워드들이 있다고 하자.
0110_0110_0110_0000
0101_0101_0101_0101
1000_1111_0000_1100첫 번째 워드와 두 번째 워드의 합은 1011_1011_1011_0101이다. 여기에 세 번째 워드 1000_1111_0000_1100를 더하면 0100_1010_1100_0010가 된다(사실 1_0100_1010_1100_0010이지만 오버플로우는 무시된다). 0100_1010_1100_0010의 1의 보수는 1011_0101_0011_1101이고, 이 값이 UDP 세그먼트의 체크섬 필드에 들어간다.
수신 측은 체크섬을 포함해, 모든 16-bit 워드들을 더한다. 만약 전송 도중 패킷에 에러가 발생하지 않았다면 그 값은 반드시 1111_1111_1111_1111이 될 것이다. 만약 이 비트 중 하나라도 0이라면, 우리는 이를 통해 패킷에 에러가 생겼음을 확인할 수 있다.
많은 링크-계층 프로토콜들도 에러 확인 기능을 제공하는데, 왜 UDP에서 또 체크섬 기능을 제공하는 걸까? 그 이유는 소스와 목적지 사이의 모든 링크들이 이러한 에러 확인 서비스를 제공할 것이라는 보장이 없기 때문이다.
게다가 세그먼트가 링크를 거쳐 올바르게 전송되었다 하더라도, 세그먼트가 라우터의 메모리에 저장될 때 비트 에러가 발생할 수도 있다. 링크 간 전송 신뢰성이 보장되지 않고, 인 메모리 에러 검출도 보장되지 않기 때문에, UDP는 종단 전송 계층 에러 검출 서비스를 제공해야만 한다.
다만 UDP는 에러 검출을 할 뿐, 에러 복구를 위한 작업은 하지 않는다. 어떤 UDP 구현은 에러가 있는 세그먼트를 그냥 버리기도 하고, 혹은 손상된 세그먼트를 경고와 함께 애플리케이션으로 전달하기도 한다.
