
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
이 장에서는 vsfs(Very Simple File System)이라 불리는 간단한 파일 시스템 구현을 소개한다. 이 파일 시스템은 전형적인 UNIX 파일 시스템을 단순화 시킨 버전으로, 여기서는 기본적인 디스크 상 구조, 접근 방법, 그리고 오늘날의 많은 파일 시스템들에서 찾을 수 있는 다양한 정책들을 볼 수 있다.
파일 시스템은 순수 소프트웨어다. CPU나 메모리의 가상화 개발과 달리, 파일 시스템이 좀 더 잘 작동하게 하기 위한 하드웨어를 추가하지는 않는다. 파일 시스템을 만드는 데에는 많은 방법이 있기 때문에 AFS에서 ZFS까지 수많은 파일 시스템들이 만들어져왔다. 이 모든 파일 시스템들은 다른 자료 구조를 가지고 있고, 서로 장단점을 가지고 있다. 그러므로 파일 시스템들에 대해 공부하기 위해서는 많은 사례들에 대해 연구하게 될 것이다. 우선은 vsfs를 통해 대부분의 컨셉들을 소개하고, 이후 실제 파일 시스템들에 대한 연구로 그것들이 실제로는 어떻게 다른지 공부해본다.
어떻게 간단한 파일 시스템을 만들 수 있을까? 디스크에는 어떤 구조가 필요할까? 이들이 추적해야하는 정보에는 어떤 게 있을까? 이것들에 접근하기 위해서는 어떻게 해야할가?
1. The Way To Think
파일 시스템에 대해서는 보통 두 가지 다른 측면에서 생각한다. 만약 이 두 측면들 모두에 대해서 이해한다면, 파일 시스템이 기본적으로 어떻게 동작하는지를 이해할 수 있을 것이다.
첫 번째는 파일 시스템의 자료 구조다. 다시 말해 파일 시스템의 데이터와 메타데이터를 조직하기 위해서는 어떤 종류의 디스크 상 구조를 활용해야하는지에 대한 것이다. 우리가 볼 첫 번째 파일 시스템은 블럭의 배열이나 다른 객체들과 같은 간단한 구조를 사용한다. 한편 SGI의 XFS와 같은 좀 더 세련된 파일 시스템들은 더 복잡한 트리 기반의 구조를 사용한다.
두 번째는 파일 시스템의 접근 방법이다. 어떻게 파일 시스템은 프로세스가 호출하는 open(), read(), write() 등등과 같은 시스템콜들을 그 파일 시스템의 구조에 매핑할까? 특정 시스템 콜을 실행할 때에는 어떤 구조가 읽어지고 쓰일까? 이 과정들 전체들은 얼마나 효율적으로 수행될까?
만약 파일 시스템의 자료 구조와 접근 방법에 대해 이해한다면, 이 파일 시스템이 실제로 어떻게 동작하는지에 대한 이해도 곧잘 할 수 있게 될 것이다.
2. Overall Organization
이제는 vsfs 파일 시스템의 전반적인 디스크 상 자료 구조 조직을 개발해보자. 가장 먼저 해야할 것은 디스크를 블럭들로 나누는 것이다. 간단한 파일 시스템은 딱 하나의 블럭 크기만을 사용하며, 여기서도 그렇다. 여기서는 가장 널리 쓰이는 4KB의 사이즈를 사용한다.
우리가 만드는 파일 시스템을 만드는 디스크 파티션은 단순하다. 4KB 블럭들의 나열일 뿐이다. N개의 4KB 블럭들로 이루어진 이 디스크 파티션의 각 블럭들은 0에서 N-1의 주소를 가지고 있다. 64개 블럭들로 이루어진 아주 작은 디스크를 가지고 있다고 해보자.
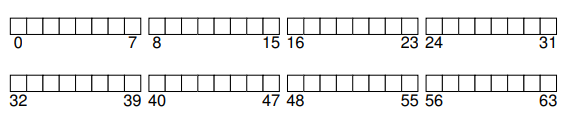
그렇다면 이제는 파일 시스템을 만들기 위해 이 블럭들에 무엇을 저장해야하는지에 대해 생각해보자. 물론 가장 먼저 생각나는 것은 사용자의 데이터다. 사실 어떤 파일 시스템이든지, 대부분의 공간은 사용자 데이터로 이루어져있다. 이렇게 사용자 데이터를 위해 쓰이는 디스크 영역을 데이터 영역(data region)이라 부른다. 단순화를 위해 이 영역의 블럭들을 위해 디스크의 고정 부분을 예약해놓도록 하자. 예에서는 뒤쪽 56개 블럭들을 사용하도록 한다.
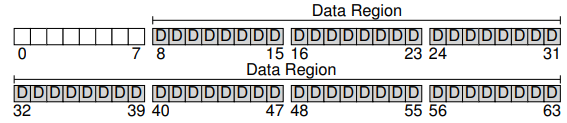
지난 챕터에서 배웠던 것처럼, 파일 시스템의 각 파일의 정보를 추적해야한다. 이 정보가 메타데이터의 핵심이며, 이는 어떤 데이터 블럭이 파일을 이루는지, 파일의 크기, 그 소유자와 접근 권한, 접근 및 수정 시간, 이외의 여러 비슷한 종류의 정보들을 추적하는 데 쓰인다. 이러한 정보를 저장하기 위해서 파일 시스템은 주로 아이노드(inode)라 불리는 구조를 사용한다.
아이노드를 수용하기 위해서도 마찬가지로 디스크의 일정 공간을 예약해놓도록 한다. 이 부분을 아이노드 테이블(inode table)이라 부르도록 하자. 여기에는 디스크 상의 아이노드들의 배열이 담겨있다. 그러므로 다섯 블럭을 아이노드를 위해 쓴다고 가정할 때, 우리의 디스크 상 이미지는 다음 그림과 같다.
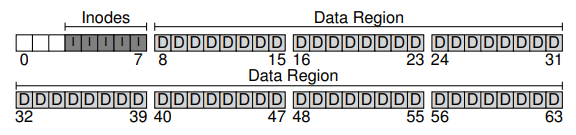
여기서 아이노드가 보통은 127~256 바이트로 그렇게 크지는 않다는 것을 염두에 두자. 아이노드마다 256 바이트를 가정하면, 4KB 블럭은 16개의 아이노드를 가질 수 있고, 따라서 위의 파일 시스템은 총 80개의 아이노드를 담을 수 있다. 이는 우리가 파일 시스템 내에서 가질 수 있는 파일의 최대 수를 나타낸다. 다만 같은 시스템이라 하더라도 좀 더 큰 디스크를 사용한다면 아이노드 테이블을 위한 공간을 더 할당해 더 많은 파일들을 수용할 수도 있다.
이제 우리의 파일 시스템은 데이터 블럭들과 아이노드들을 가지고 있다. 하지만 아직 몇 가지 추가할 것들이 있다. 필요한 구성 요소 중 하나는 이 아이노드 및 데이터 블럭들이 할당된 상태인지 사용 가능한 상태인지를 추적하기 위한 것이다. 따라서 그런 할당 구조(allocation structure)는 어떤 파일 시스템에서든 반드시 필요하다.
물론 다양한 할당-추적 방법들이 가능하다. 예를 들어 첫 번째 가용 블럭, 그 다음의 가용 블럭, 그리고 그다음 ...을 가리키는 가용 리스트(free list)를 사용할 수 있다. 또는 데이터 영역과 아이노드 테이블 각각에 대해 비트맵(bitmap)이라 불리는 간단하고 유명한 구조를 이용할 수도 있다. 비트맵은 간단한 구조다. 각 비트는 그에 해당하는 객체나 블럭이 사용 가능(0)한지, 사용 중인지(1)를 가리킨다. 그러므로 우리의 디스크 상 자료구조의 레이아웃에서는 다음과 같은 아이노드 비트맵(i)과 데이터 비트맵(d)를 사용한다.
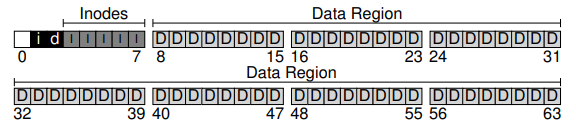
비트맵을 위해 이 4KB 블럭 하나를 통으로 사용하는 게 너무 과하다고 생각될 수도 있다. 4KB 비트맵은 총 32K(4K * 8bit)개의 객체를 구분하는 데 쓰일 수 있지만, 우리는 고작 80개의 아이노드와 56개의 데이터 블럭 밖에 가지고 있지 않기 때문이다. 하지만 여기서는 단순함을 위해 한 블럭을 모두 사용한다.
이제 마지막 한 블럭이 남아있다. 이 블럭은 슈퍼블럭(superblock)을 위해 예약해둔다. 슈퍼블럭은 이 특정 파일 시스템에 대한 정보들을 담고 있는 것으로, 예를 들면 얼마나 많은 아이노드와 데이터 블럭들이 파일 시스템에 있는지, 아이노드 테이블이 어디서부터 시작하는지 등의 정보들을 포함한다. 이는 또한 파일 시스템의 타입을 나타내기 위한 매직 넘버도 포함할 것이다.

파일 시스템을 마운트할 때 OS는 슈퍼블럭을 우선 읽고, 여러 파라미터들을 초기화하고 나서 이 볼륨을 파일 시스템 트리에 갖다 붙인다. 이로써 볼륨 내의 파일에 대한 접근이 일어났을 때, 시스템은 요구되는 디스크 상 자료 구조를 찾으려면 정확히 어디를 봐야할지 알 수 있게 된다.
3. File Organization: The Inode
파일 시스템에서 가장 중요한 디스크 상 자료 구조중 하나는 아이노드다. 사실상 거의 모든 파일 시스템이 이와 유사한 자료 구조를 가지고 있다. 아이노드라는 이름은 인덱스 노드(index node)의 준말이다. 이 이름은 UNIX 및 그보다 초기의 시스템들로부터 유래한 것으로, 이 노드들은 원래는 배열에 배치되어 있었고, 이 배열은 특정 아이노드에 접근하기 위해 쓰인다.
각 아이노드는 암묵적으로 번호로 표현되는데, 이는 앞서 파일의 낮은 수준 이름이라 불렸던 것이다. vsfs에서는 i-number를 가지고서 직접적으로 해당 아이노드가 디스크의 어디에 위치해있는지를 계산할 수 있다. 예를 들어 위의 아이노드 테이블을 보자. 이 아이노드 테이블은 총 20KB의 크기를 가지며, 80개의 256KB 아이노드들을 가지고 있다. 또한 아이노드 영역이 12KB에서 시작한다고 가정한다. vsfs에서 파일 시스템 파티션의 시작 부분은 다음의 레이아웃을 가진다.
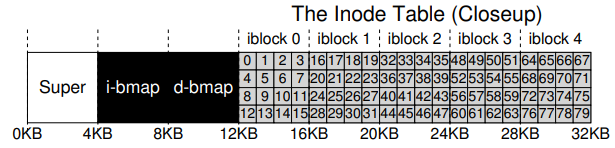
32번 아이노드를 읽기 위해서는, 파일 시스템은 우선 아이노드 영역에서의 오프셋을 계산하고 이를 디스크 상 아이노드 테이블의 시작 주소에 더해, 원하는 아이노드 블럭의 정확한 바이트 주소에 도달한다. 디스크 자체는 바이트 주소로 접근할 수 없으며, 보통 512 바이트의, 주소로 접근할 수 있는 많은 섹터들을 포함함에 유의하자. 그러므로 아이노드 32번이 있는 아이노드 블럭을 가져오기 위해서 파일 시스템은 40(= )번 섹터를 가져와야한다. 일반적으로 아이노드 블럭의 섹터 주소 sector 는 다음과 같이 계산된다.
blk = (inumber * sizeof(inode_t)) / blockSize;
sector = ((blk * blockSize) + inodeStartAddr) / sectorSize;각 아이노드의 내부에는 파일에 대해 필요한 거의 모든 정보들이 있다. 그 정보에는 파일의 사이즈, 파일에 할당된 블럭의 수, 보호 정보, 파일이 언제 만들어졌고 수정됐고 가장 최근에 접근됐는지 등의 시간 정보, 데이터 블럭이 디스크의 어디에 위치해있는지 등이 있다. 파일에 대한 이러한 정보들을 메타데이터라 부른다. 사실 사용자 데이터가 아닌 파일 시스템 내의 정보는 무엇이든지 메타데이터라 부른다. ext2의 아이노드에 대한 예는 다음과 같다.

아이노드 설계에서 가장 중요한 결정 중 하나는 이것이 어떻게 데이터 블럭이 어디에 있는지를 나타내는지에 대한 것이다. 한 가지 단순한 접근법은 하나 이상의 직접 포인터(direct pointer)를 아이노드 내부에 두는 것이다. 각 포인터들은 파일에 속하는 디스크 블럭 하나를 가리킨다. 다만 이런 방법은 제한적이다. 예를 들어 파일이 아주 커서 그에 속하는 블럭들을 아이노드 내에 있는 직접 포인터들로 다 가리킬 수 없는 경우에는 사용할 수 없다.
The Multi-Level Index
더 큰 파일을 지원하기 위해 파일 시스템 설계자들은 아이노드 내에 다른 자료 구조를 도입해야만 했다. 한 가지 일반적인 아이디어는 간접 포인터(indirect pointer)라 불리는 특수한 포인터를 사용하는 것이다. 이는 사용자 데이터를 직접 가리키지 않고, 사용자 데이터를 가리키는 포인터들을 포함하고 있는 블럭을 가리킨다. 이렇게 하면 아이노드는 고정된 수의 직접 포인터(12개라 하자)와 하나의 간접 포인터만 가져도 된다. 만약 파일이 충분히 커지면 포인터들을 담은 간접 블럭이 할당되고, 아이노드의 간접 포인터는 이 블럭을 가리키게 된다. 4KB 블럭과 4바이트 디스크 주소를 가정하면, 블럭에는 1024개의 포인터가 들어갈 수 있고, 파일은 (12+1024) 4K = 4144KB의 크기를 가질 수 있게 된다.
물론 이보다도 더 큰 파일을 원할 수도 있다. 이러한 파일을 가능케 하려면 아이노드에 다른 포인터를 추가하기만 하면된다. 바로 이중 간접 포인터(double indirect pointer)다. 이 포인터는 데이터 블럭을 가리키는 포인터들을 포함하는 간접 블럭을 가리키는 포인터들을 포함하는 블럭을 가리킨다. 이중 간접 블럭은 4GB가 넘는 크기의 파일을 지원한다. 만약 더 원한다면, 삼중으로도 쓸 수 있을 것이다.
종합적으로, 이 불균형 트리는 파일 블럭을 가리키기 위한 멀티-레벨 인덱스(multi-level index) 방식이라 불린다. 이제 12개의 직접 포인터, 하나의 간접 포인터, 하나의 이중 간접 포인터를 가지는 경우를 생각해보자. 블럭 사이즈를 4KB라 가정하고, 포인터의 크기를 4바이트라 가정하면, 이 구조는 크기가 4GB를 넘는 파일을 수용할 수 있다.
널리 쓰이는 리눅스 ext2, ext3 파일 시스템이나 UNIX의 원래 파일 시스템 등, 많은 파일 시스템들은 멀티-레벨 인덱스를 사용한다. SGI XFS, 리눅스 ext4등의 파일 시스템은 간단한 포인터가 아닌 익스텐트(extent)를 사용하기도 한다.
익스텐트는 디스크 포인터에 길이를 더한 것이다. 파일의 디스크 상 위치를 찾기 위해 파일을 이루는 모든 블럭에 대한 포인터가 아니라, 포인터 하나와 길이만을 이용하는 것이다. 하나의 익스텐트만으로는 제한적일 수 있는데, 파일에 공간을 할당할 때, 디스크 상의 연속적인 가용 공간 청크를 찾지 못할 수도 있기 때문이다. 그러므로 익스텐트 기반의 파일 시스템은 하나 이상의 익스텐트를 허용함으로써 파일 시스템에 파일 할당에 있어서의 높은 자유도를 허용한다.
두 접근법을 비교하면, 포인터 기반 방식은 더 유연하지만 파일 당 많은 양의 메타데이터를 필요로 하고, 익스텐트 긱반 방식은 덜 유연하지만 압축적이다. 특히 익스텐트 기반 방식은 디스크에 가용 공간이 충분하고 파일이 연속적으로 배치될 수 있을 때 잘 동작한다.
다음과 같은 사실에 의문이 들 수도 있다. 왜 이런 불균형 트리를 사용하는 걸까? 왜 다른 방법을 쓰지 않는 걸까? 많은 연구자들이 파일 시스템과 그것들이 어떻게 쓰이는지에 대해 연구해왔지만, 그들은 거의 항상 하나의 진실에 도달했다. 바로 대부분의 파일들은 작다는 것이다. 이 불균형 설계는 그런 사실을 반영하고 있다. 만약 대부분의 파일들이 실제로는 작다면, 그런 경우에 최적화하는 것이 이치에 맞을 것이다. 그러므로 적은 수의 직접 포인터를 통해 아이노드는 직접 최대 48KB 데이터를 가리킨다. 더 큰 파일들에 대해서는 하나 이상의 간접 블럭들을 사용하면서 말이다.
물론 아이노드 설계에 있어서는 많은 다른 방법들도 있을 수 있다. 어찌됐든 아이노드는 그저 자료 구조로서, 관련 정보들을 담고 효율적으로 조회할 수만 있으면 되기 때문이다. 파일 시스템 소프트웨어가 쉽게 바뀔 수 있으므로, 항상 워크로드와 기술 변화에 따라 다른 디자인들을 탐구할 수 있어야 한다.
4. Directory Organization
vsfs에서 디렉토리는 간단하다. 디렉토리는 기본적으로 (엔트리 이름, 아이노드 번호) 쌍의 리스트를 가지고 있다. 주어진 디렉토리 내의 각 파일과 디렉토리를 위해, 디렉토리의 데이터 블럭 안에는 문자열과 번호가 저장되어야 한다. 각 문자열을 위해서는 그 길이도 함께 저장된다.
예를 들어 디렉토리 dir(i-number 5) 안에 세 개의 파일(foo, bar, foobar_is_a_pretty_longname)이 있다고 하자. 파일 각각의 아이노드 번호는 12, 13, 14라 하자. dir의 디스크 상 데이터는 다음과 같을 것이다.

이 예에서 각 엔트리에는 아이노드 번호, 레코드 길이(이름 + 남은 공간들의 바이트 총합), 문자열 길이, 그리고 엔트리의 이름이 있다. 여기서 각 디렉토리가 두 개의 추가 엔트리, "."과 ".."을 가진다는 것에 유의하자. 전자는 현재 디렉토리, 후자는 부모 디렉토리다.
파일을 삭제하는 것은 디렉토리 중간에 빈 공간을 남겨 둘 수 있으므로, 이를 표시하기 위한 방법도 있어야 한다(예를 들면 삭제된 파일을 위한 아이노드 번호 0을 배정해두는 것). 이러한 파일의 삭제가 레코드 길이가 사용되는 이유 중 하나다. a new entry may reuse an old, bigger entry and thus have extra space within.
디렉토리가 정확히 어디에 저장되는지가 궁금할 수도 있다. 파일 시스템들은 보통 디렉토리를 특수한 타입의 파일로 대한다. 그러므로 디렉토리는 아이노드를 가진다. 디렉토리는 이 아이노드가 가리키는 데이터 블럭을 가진다. 이 데이터 블럭은 데이터 블럭 영역에 위치한다. 파일에서의 디스크 상 자료 구조가 그대로 유지되는 것이다.
또한 이러한 간단한 디렉토리 엔트리의 선형 리스트가 그 정보들을 저장하기 위한 유일한 방법은 아님에 유의해야한다. 이전과 같이 어떤 자료 구조든지 사용될 수 있다. 예를 들어 XFS에서는 디렉토리를 B-트리 형태로 저장해, 파일 생성 작업을 그러기 위해 그 전체 리스트를 탐색해야하는 단순한 리스트보다 빠르게 수행될 수 있게 한다.
5. Free Space Management
파일 시스템은 새 파일이나 디렉토리가 할당되기 위한 공간을 찾기 위해, 아이노드와 데이터 블럭이 비어있는지, 그렇지 않은지를 추적해야 한다. 그러므로 가용 공간 관리(free space management)는 모든 파일 시스템들에 있어 중요한 문제다. vsfs에서는 이 작업을 위해 두 개의 단순한 비트맵을 사용한다.
예를 들어 파일을 만들 때에는 해당 파일에 아이노드를 할당해야 한다. 따라서 파일 시스템은 비트맵을 통해 사용 가능한 아이노드를 찾고, 디스크 상 비트맵을 올바른 정보로 갱신한다. 비슷한 활동이 데이터 블럭이 할당될 때도 일어난다.
데이터 블럭을 파일에 할당할 때 생각해야 할 다른 것들도 있다. 예를 들어 ext2나 ext3과 같은 몇몇 리눅스 파일 시스템에서는 새로운 파일이 만들어져 데이터 블럭이 필요해질 때, 블럭들의 시퀀스를(8이라 하자) 찾는다. 그런 가용 블럭 시퀀스를 찾고 그것들을 새로이 생성된 파일에 할당함으로써 파일 시스템은 파일의 부분들이 디스크 상에 연속적으로 있음을 보장하고 성능을 향상시키게 된다. 이러한 선할당(pre-allocation) 정책은 데이터 블럭에 공간을 할당할 때 자주 쓰이는 휴리스틱이다.
6. Access Paths: Reading and Writing
어떻게 파일과 디렉토리가 디스크에 저장되는지를 알게 됐으니, 이제는 파일의 읽기나 쓰기 활동이 일어날 때의 작업 플로우를 따라갈 수 있을 것이다. 이 접근 경로(access path)에서 어떤 일이 일어나는지를 이해하는 것은 어떻게 파일 시스템이 작동하는지 이해하기 위한 두 번째 핵심 요소다.
아래의 예에서는 파일 시스템이 마운트 되어 있고, 슈퍼블럭도 이미 메모리에 있다고 가정한다. 나머지는 아직 디스크에 있다.
Reading A File From Disk
이 간단한 예에서는 우선 단순히 파일(/foo/bar)을 열고, 읽고, 닫기를 원한다고 가정하자. 파일의 크기는 12KB라고 가정한다.
open("/foo/bar", O_RDONLY) 시스템 콜을 호출하면 파일 시스템은 우선 파일 bar의 기본 정보들을 얻기 위해 해당 파일의 아이노드를 찾아야 한다. 이를 위해서 파일 시스템은 아이노드를 찾을 수 있어야 하는데, 지금 당장 알고 있는 것은 전체 경로명 밖에 없다. 따라서 파일 시스템은 경로명을 순회하면서 원하는 아이노드를 찾아내야 한다.
모든 순회는 파일 시스템의 루트, "/"로 불리는 루트 디렉토리에서부터 시작한다. 파일 시스템이 디스크에서 가장 먼저 읽어야할 것은 루트 디렉토리의 아이노드다. 그런데 이 아이노드는 어디에 있을까? 아이노드를 찾으려면 그 번호를 알아야 한다. 일반적으로 파일이나 디렉토리의 아이노드 번호는 부모 디렉토리에서 찾는데, 루트는 정의상 부모가 없다. 그러므로 루트 아이노드 번호는 "잘 알려져" 있어야 한다. 파일 시스템은 파일 시스템이 마운트 되었을 때 해당 루트 아이노드 번호가 무엇인지를 알아야 한다. 대부분의 UNIX 파일 시스템에서 루트 아이노드 번호는 2다. 그러므로 위 과정을 시작하기 위해 파일 시스템은 아이노드 번호 2를 포함한 블럭을 읽는다.
아이노드가 읽히고 나면, 파일 시스템은 그 안을 보고 데이터 블럭의 포인터를 찾는다. 이 데이터 블럭에는 루트 디렉토리의 내용들이 담겨 있다. 파일 시스템은 따라서 이 디스크 상의 포인터를 이용해 디렉토리를 읽고, foo에 해당하는 엔트리를 찾을 것이다. 하나 이상의 디렉토리 데이터 블럭을 읽음으로써 파일 시스템은 foo에 해당하는 엔트리를 찾는다. 이를 찾으면 파일 시스템은 foo의 아이노드 번호도 알게 될 것이다.
다음 단계는 원하는 아이노드를 찾을 때까지 재귀적으로 경로명을 순회하는 것이다. 이 예에서 파일 시스템은 foo의 아이노드를 담은 블럭을 읽고, 그 디렉토리 데이터를 읽고, 마지막으로 bar의 아이노드 번호를 찾게 될 것이다. open()의 마지막 단계는 bar의 아이노드를 메모리로 읽어오는 것이다. 그러고 나면 파일 시스템은 마지막으로 권한을 체크하고, 해당 프로세스의 open-file table에 파일 디스크립터를 할당해 사용자에게 반환할 것이다.
파일이 열리고 나면 프로그램은 read() 시스템 콜을 통해 파일을 읽는다. 첫 번째 읽기는 아이노드를 통해 파일의 첫 번째 블럭의 위치를 찾고, 해당 블럭을 읽을 것이다. 이때 아이노드에 저장되는 최근 접근 시간도 갱신된다. 이 읽기는 이 파일 디스크립터의, 메모리 상에 있는 open file table을 갱신한다. 다음 읽기를 위해서는 파일 오프셋을 업데이트해줘야 하기 때문이다.
언젠가 파일은 닫히게 될 것이다. 여기서는 크게 할 일이 없다. 파일 디스크립터를 할당 해제만 하면 된다. 파일 시스템이 더 할 일은 없고, 디스크 I/O도 일어나지 않는다.
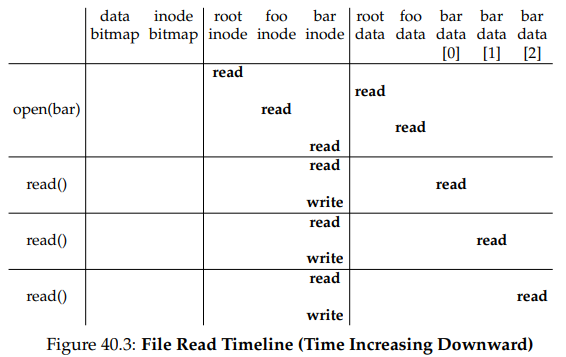
아래의 표는 위의 전체 프로세스를 보여준다. 여기서 열기는 파일의 아이노드를 찾기 위해 많은 읽기를 일으킨다. 이후 각 블럭을 읽기 위해서 파일 시스템은 우선 아이노드를 확인하고 해당 플럭을 읽고, 아이노드의 최근 접근 시간을 갱신해야한다.
열기에서 일어나는 I/O 작업의 양이 경로명의 길이에 비례한다는 점에 유의하라. 경로 상에 추가적인 디렉토리가 생긴다면, 그 아이노드와 데이터를 모두 읽어야 한다. 만약 큰 디렉토리가 있다면 더 안 좋아진다. 예에서는 디렉토리의 내용을 가져 오기 위해 하나의 블럭만 읽으면 됐지만, 큰 디렉토리의 경우, 원하는 엔트리를 찾기 위해 많은 수의 데이터 블럭을 읽어야 할 수도 있다.
Writing A File To Disk
파일 쓰기 작업도 비슷한 과정을 통해 이루어진다. 위와 마찬가지로 우선은 파일을 열어야 한다. 그러고 나면 프로그램은 write() 시스템 콜을 통해 파일을 새로운 내용으로 업데이트 한다. 마지막으로 파일은 닫힌다.
읽기와 달리, 파일 쓰기의 경우 새로운 블럭 할당을 필요로 할 수도 있다. 새 파일을 쓸 때, 각 쓰기 작업은 디스크에 데이터를 쓸 뿐만 아니라, 그보다 먼저 디스크의 자료 구조를 업데이트하기 위해 파일에 어떤 블럭을 할당할지를 정해야 한다. 따라서 파일에의 쓰기 작업은 논리적으로 5개의 I/O를 발생시킨다. 데이터 비트맵을 읽고, 비트맵에 쓰고, 아이노드를 읽고, 쓰고, 데이터 블럭에 쓰기 위해서다.
쓰기 작업의 트래픽 양은 파일 생성과 같은, 간단하고 흔한 작업에서 훨씬 더 크다. 파일을 생성하기 위해 파일 시스템은 아이노드를 할당해야 할 뿐만 아니라, 새 파일을 담고 있는 디렉토리에도 공간을 할당해야 한다. 이를 위한 전체 I/O 트래픽 양은 상당히 많다. 빈 아이노드를 찾기 위해 아이노드 비트맵을 읽고, 해당 자리가 할당되었음을 표시하기 위해 쓰고, 새 아이노드를 쓰고, 아이노드 번호와 이름을 링크하기 위해 디렉토리 데이터에 쓰고, 디렉토리 아이노드를 갱신하기 위해서도 한 번씩 읽고 써야 하기 때문이다. 만약 디렉토리가 새 엔트리를 수용하기 위해 더 커져야 한다면, 추가적인 I/O도 필요하다. 이것들이 전부 파일을 하나 만들기 위해서 필요한 작업들이다.
파일 /foo/bar가 만들어지고 세 블럭이 해당 파일에 쓰이는 구체적인 예를 한 번 살펴보자. 아래의 표가 open()과 세 번의 4KB 쓰기 작업 각각이 일어날 때 어떤 일이 일어나는지를 보여주고 있다.
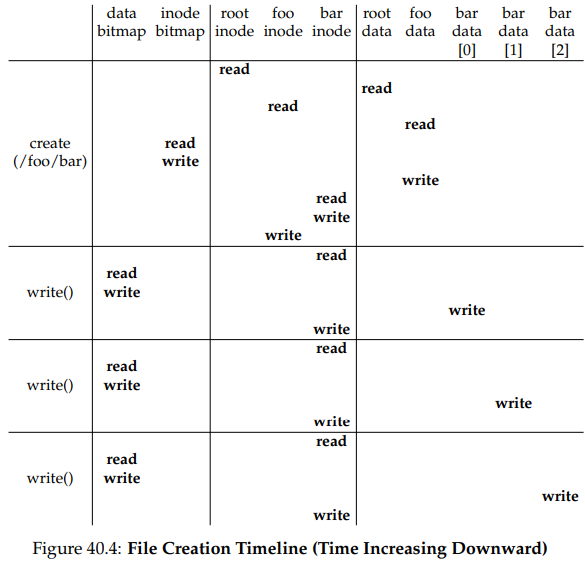
표에서 디스크에의 읽기와 쓰기 작업들은 어떤 시스템 콜에 의해 일어났는지에 따라 묶여 있다. 파일 생성에 얼마나 많은 작업이 필요한지를 볼 수 있다. 이 경우에는 경로명을 순회하고 파일을 만들기 위해서만 10번의 I/O가 일어난다. 또한 공간 할당이 필요한 쓰기 작업들 각각에 대해서도 5번의 I/O가 일어난다. 아이노드를 읽고 쓰기 위해, 데이터 비트맵을 읽고 갱신하기 위해, 그리고 마지막으로 데이터를 쓰게 위해서다. 어떻게 파일 시스템은 이러한 작업들을 효율적으로 달성할 수 있을까?
파일 열기, 읽기, 쓰기와 같은 가장 간단한 작업들도 많은 수의 I/O 작업을 필요로 한다. 파일 시스템은 이렇게 많은 I/O 작업 수행의 비용을 어떻게 줄일 수 있을까?
7. Caching and Buffering
위의 예가 보여주듯, 파일을 읽고 쓰는 것은 많은 디스크 I/O 작업을 일으키는 비싼 작업이 될 수 있다. 큰 성능 문제가 될 이러한 문제를 해결하기 위해, 대부분의 파일 시스템은 중요한 블럭들을 캐시하기 위해 적극적으로 시스템 메모리를 사용한다.
위 예에서의 open()을 보자. 캐싱이 없으면 모든 파일 열기는 디렉토리 계층마다 적어도 두 번의 읽기를 필요로 할 것이다. 만약 긴 경로명을 사용한다면, 파일 시스템은 말 그대로 파일을 열기 위해서만 수백 번의
읽기를 수행해야 할 수도 있다.
그래서 초기 파일 시스템들은 고정 크기 캐시(fixed-sized cache)를 도입해 자주 쓰이는 블럭들을 담았다. 가상 메모리에서의 논의와 마찬가지로, LRU나 그 변종들과 같은 전략들은 어떤 블럭들을 캐시에 담을지를 결정한다. 이 고정 사이즈 캐시는 부팅 시간에, 대충 전체 메모리의 10% 정도의 크기로 할당된다.
하지만 이러한 메모리의 정적 파티셔닝(static partitioning)에는 낭비가 많다. 파일 시스템이 특정 시점에 10%의 메모리를 필요로 하지 않는다면 어떨까? 위와 같은 고정 크기 방식에서 파일 캐시의 사용되지 않는 페이지들은 다른 용도로 재사용되지 못하고, 따라서 낭비가 된다.
현대 시스템에서는 이와 달리 동적 파티셔닝(dynamic partitioning) 방식을 사용한다. 구체적으로 많은 현대 운영체제는 가상 메모리 페이지와 파일 시스템 페이지를 일원화된 페이지 캐시(unified page cache)로 통합한다. 이러한 방식으로 메모리는 특정 시점에 어느 것이 더 많은 메모리를 필요로 하는지에 따라 가상 메모리와 파일 시스템 사이에서, 좀 더 유연하게 할당될 수 있게 된다.
이제는 캐싱을 이용한 파일 열기를 생각해보자. 첫 번째 열기는 디렉토리 아이노드와 데이터를 읽기 위해 많은 I/O 트래픽을 발생시킬 것이다. 하지만 같은 파일에 대한, 혹은 같은 디렉토리의 파일들에 대한 후속 파일 열기들은 대부분 캐시 히트될 것이고, 더 이상의 I/O를 필요로 하지 않는다.
쓰기 작업의 경우는 어떨까? 읽기 I/O의 경우는 충분히 큰 캐시를 사용하면 피할 수 있지만, 쓰기의 경우 데이터를 영구적으로 저장하기 위해서는 디스크에 접근해야 한다. 그렇기 때문에 캐시는 읽기에서와 마찬가지의 효과를 가져다 주지는 못한다. 그 대신, 쓰기 버퍼링(write buffering)이 많은 성능상 이점을 가져다 준다. 첫 번째로, 쓰기를 지연시킴으로써 파일 시스템은 작은 I/O 집합의 갱신을 일괄 처리할 수 있다. 예를 들어 만약 아이노드 비트맵이 파일이 생성되었을 때 갱신되고, 나중에 다른 파일이 만들어졌을 때 또 갱신된다면, 파일 시스템은 첫 번째 갱신 이후 쓰기를 지연시킴으로써 I/O 작업을 줄일 수 있다. 두 번째로, 여러 쓰기를 메모리에 버퍼링시킴으로써 시스템은 후속 I/O를 스케줄링해 성능을 향상시킬 수 있다. 마지막으로 어떤 쓰기 작업은 지연을 통해 아예 수행되지 않을 수도 있다. 예를 들어 만약 응용 프로그램이 파일을 만들고 지운다면, 쓰기 지연을 통해 이 작업은 전혀 이루어지지 않게 만들 수도 있다.
위와 같은 이유로 대부분의 현대 파일 시스템들은 쓰기 작업을 5-30초 정도 메모리에 버퍼링시킨다. 다만 여기에는 다른 트레이드 오프도 있다. 만약 시스템이 업데이트가 디스크로 이어지기 전에 크래시를 일으키면, 해당 업데이트는 손실된다. 하지만 쓰기를 좀 더 메모리에 오랫동안 둠으로써, 성능은 일괄 처리, 스케줄링, 회피 등을 통해 향상될 수 있다.
데이터베이스와 같은 어떤 애플리케이션들은 이런 트레이드 오프를 좋아하지 않는다. 쓰기 버퍼링을 통한 예상치 못한 데이터 손실을 피하기 위해, 이들은 간단히 강제로 디스크에 쓰는 방법을 택한다. 그 방법에는 fsync() 시스템 콜을 호출하는 방법, 캐시를 사용하지 않는 직접적인 I/O 인터페이스를 사용하는 방법, 또는 디스크 자체의 인터페이스를 사용해 파일 시스템을 사용을 피하는 방법 등이 있다. 대부분의 애플리케이션들이 파일 시스템로 인한 트레이드 오프를 감수하기를 선택하지만, 그런 작업이 마음에 들지 않는 경우 원하는 것을 할 수 있게 하기 위한 충분히 많은 제어들도 있다.
8. Summary
지금까지 파일 시스템을 만들기 위한 기본적인 기법들에 대해 알아봤다. 각 파일에 대해 필요한 정보들이 있으며, 이들은 보통 아이노드라 불리는 구조에 저장된다. 디렉토리는 이름과 아이노드 번호 매핑을 저장하는 특수한 타입의 파일일 뿐이다. 이외의 다른 자료 구조들도 필요하다. 예를 들어 파일 시스템은 비트맵과 같은 구조를 이용해 아이노드나 데이터 블럭 중 어느 것이 사용 가능한지, 혹은 할당됐는지를 추적한다.
파일 시스템 설계의 훌륭한 면모는 그 자유도다. 이후의 장들에서 만날 파일 시스템들은 각각 이러한 자유도의 이점을 살리고 있다. 아직 탐구하지 못한 많은 정책들도 있다. 예를 들어 새 파일이 만들어졌을 때, 이 파일은 디스크의 어디에 위치해야 할까? 이러한 정책들은 이후 장들에서 다루게 될 것이다.
