
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
UNIX 운영체제가 처음 도입되었을 때 만들어진 파일 시스템이 있다. 이것을 "오래된 UNIX 파일 시스템"이라 부르자. 이 시스템은 아주 단순했다. 기본적으로 그 자료 구조는 디스크 상에서 다음과 같았다.

슈퍼블럭은 전체 파일 시스템에 대한 정보를 가지고 있다. 볼륨이 얼마나 큰지, 얼마나 많은 아이노드들이 있는지, 가용 블럭 리스트의 헤드를 가리키는 포인터 등등의 정보들이다. 디스크의 아이노드 영역은 파일 시스템의 모든 아이노드들을 포함하고 있고, 대부분의 디스크는 데이터 블럭들이 쓰고 있다.
오래된 파일 시스템의 좋은 점은 이것이 단순하고, 파일 시스템이 제공하고자 하는, 파일 및 디렉토리 계층과 같은 기본적인 추상화들을 지원한다는 것이다. 이 사용하기 쉬운 시스템은 과거의 서투른, 레코드 기반 저장 시스템에서 발전한 것이고, 디렉토리 계층은 초기 시스템들이 제공했던, 단순한 1레벨 계층으로부터 진일보한 것이었다.
1. The Problem: Poor Performance
문제는 성능이 끔찍했다는 것이다. 버클리의 Kirk McKusick과 그 동료들이 측정한 바로는, 성능은 시작부터 좋지 않았고, 시간이 지나면서 더 나빠졌다. 파일 시스템이 전체 디스크 대역폭의 2%만을 사용하지 못할 정도까지였다.
주된 이슈는 오래된 UNIX 파일 시스템이 디스크를 RAM과 같은 것으로 다뤘다는 데 있다. 데이터는 데이터를 담고 있는 매체가 디스크라는 사실을 생각지 않고 여기 저기에 흩뿌려져 있었고, 따라서 접근 비용은 너무 많이 들었다. 예를 들어 파일의 데이터 블럭은 그 아이노드로부터 멀리 떨어져 있었기 때문에, 아이노드를 읽고나서 파일의 데이터 블럭을 읽기 위해서는 탐색 시간이 많이 걸렸다.
더 나쁜 것은 가용 공간이 주의깊게 관리되지 않아, 파일 시스템이 상당히 단편화(fragmented)되어 버리고 만다는 것이었다. 가용 리스트는 디스크에 퍼져있는 블럭 뭉치들을 가리키고, 파일은 할당될 때 그저 다음 가용 블럭을 취할 뿐이다. 그 결과로, 논리적으로는 연속적인 파일에 접근하기 위해 디스크를 이리 저리 돌아다니게 됐고, 이는 성능을 극적으로 저하시킨다.
예를 들어, 다음의 데이터 블럭 영역을 생각해보자. 여기에는 각각 사이즈가 2블럭인 네 개의 파일들(A, B, C, D)이 있다.

만약 B, D가 삭제되면 결과 레이아웃은 다음과 같다.

여기서 볼 수 있듯, 가용 공간은 연속적인 네 블럭의 청크가 아니라, 두 블럭의 두 청크로 단편화되어 있다. 4블럭 사이즈의 파일 E를 할당하고자 한다 해보자.

여기서 무슨 일이 일어나는지를 볼 수 있다. E는 디스크에 퍼져있고, 그 결과로 E에 접근할 때에는 디스크에서 얻을 수 있는 최고 성능을 얻을 수 없게 된다. E1, E2를 읽고, 탐색한 후, E3, E4를 읽게 되는 것이다. 이 단편화 문제는 오래된 UNIX파일 시스템에서 항상 일어나, 그 성능을 저하시켰다. 이 문제가 바로 디스크의 단편화 제거(defragmentation) 도구가 다루는 것이다.이 도구는 파일들을 연속적으로 위치시키기 위해 디스크 상 데이터를 재조직하고, 데이터를 이리저리로 움직이고, 아이노드를 다시 쓰고, 변화들을 반영하기 위한 여러 작업들을 수행함으로써 가용 공간을 하나, 혹은 적은 수의 연속된 영역으로 만든다.
한 가지 다른 문제도 있다. 원래 사용하던 블럭이 너무 작다는 것이다(512 bytes). 그러므로 데이터를 디스크로부터 불러오는 작업은 본질적으로 비효율적일 수 밖에 없었다. 작은 크기의 블럭은 내부 단편화를 최소화하는 데에는 좋지만 데이터 전송에는 불리하다. 왜냐하면 각 블럭에 도달하기 위해서는 접근 시간 오버헤드가 발생하기 때문이다.
어떻게 성능을 향상시킬 수 있는 파일 시스템 자료 구조를 조직할 수 있을까? 그런 자료 구조에 필요한 할당 정책에는 어떤 종류가 있을까?
2. FFS: Disk Awareness Is The Solution
버클리의 연구자들은 그들이 FFS(Fast File System)이라 이름 지은, 더 낫고 빠른 파일 시스템을 만들기로 했다. 아이디어는 파일 시스템 자료 구조와 할당 정책이 디스크적 특성을 반영하도록 설계함으로써 성능을 향상시키는 것이었다. FFS는 파일 시스템 연구의 새 시대를 열었다. 그들은 파일 시스템의 인터페이스는 같은 것으로 유지하면서 내부 구현을 바꿈으로써, 오늘날에도 여전히 쓸 수 있는, 새로운 파일 시스템 제작을 위한 길을 닦았다. 거의 모든 현대 파일 시스템들도 그 인터페이스는 따르면서, 성능, 신뢰성, 혹은 다른 이유들을 위해 내부 구조는 바꾸고 있다.
3. Organizing Structure: The Cylinder Group
첫 번째 단계는 디스크 상 구조를 바꾸는 것이다. FFS는 디스크를 여러 개의 실린더 그룹으로 나눈다. 하나의 실린더는 하드 드라이브의 여러 표면들에 있는, 드라이브 중심으로부터 같은 거리에 있는 트랙들의 집합이다. FFS는 N개의 연속적인 실린더들을 하나의 그룹으로 묶으며, 따라서 전체 디스크는 실린더 그룹의 모음으로도 볼 수 있다. 아래의 그림은 6개의 플래터로 이루어진 드라이브의 가장 바깥쪽 네 트랙들과, 세 개의 실린더들을 포함하는 하나의 실린더 그룹을 보여주고 있다.
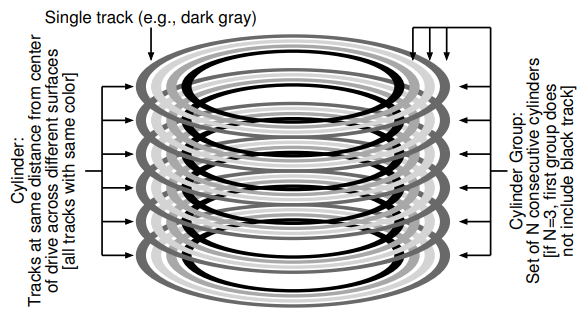
현대 드라이브들이 파일 시스템이 어떤 특정 실린더가 사용중인지 알 수 있기 위한 충분한 정보를 노출시키지는 않는다는 것에 유의하자. 앞서 논의된 것처럼, 디스크는 블럭들의 논리 주소 공간만을 노출시키며, 그 기하학적 특성은 사용자에게 보여주지 않는다. 그러므로 Linux ext2, ext3, ext4와 같은 현대 파일 시스템들은 드라이브를 블럭 그룹(block group)들로 조직한다. 이 각각은 디스크 주소 공간의 연속적인 부분일 뿐이다. 아래의 그림은 각각 8개의 연속적인 블럭들로 이루어진 블럭 그룹들을 보여주고 있다.
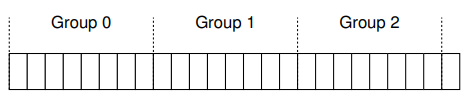
실린더 그룹이든, 블럭 그룹이든, 이 그룹들이 FFS가 성능을 향상시키기 위해 사용하는 핵심 메커니즘이다. 서로 다른 두 파일들을 하나의 그룹에 넣음으로써, 하나에 접근하고 나서 다른 것에 접근하는 일이 디스크 탐색 시간을 너무 오래 걸리지 않게 만든다.
이 그룹을 파일과 디렉토리 저장에 사용하기 위해, FFS는 파일과 디렉토리를 그룹에 위치시킬 수 있어야 하고, 또한 그것들에 대한 모든 필요한 정보들도 추적할 수 있어야 한다. 이를 위해 FFS는 파일 시스템이 각 그룹에 대해 가져야할 모든 자료 구조를 가지고 있다. 예를 들면 아이노드, 데이터 블럭 등등에 대한 공간 말이다. 하나의 실린더 그룹에 대한 FFS의 자료구조는 다음과 같이 그릴 수 있다.

이제는 이 실린더 그룹의 구성 요소들에 대해 좀 더 자세히 알아보자. 신뢰성의 이유로, FFS는 슈퍼블럭의 복사본을 각 그룹 내에 보관한다. 슈퍼블럭은 파일 시스템을 마운트하기 위해 필요하다. 복수의 복사본들을 보관함으로써, 만약 한 복사본이 오염되더라도, 다른 작동하는 복사본을 이용해 파일 시스템을 마운트하고 그것에 접근할 수 있게 된다.
FFS는 각 그룹 내에서 해당 그룹의 아이노드들과 데이트 블럭들이 할당됐는지를 추적할 수 있어야 한다. 그룹 별 아이노드 비트맵과 데이터 비트맵이 이 역할을 맡고 있다. 비트맵은 파일 시스템 내에서 가용 공간을 관리하기 위한 훌륭한 방법인데, 이를 이용하면 오래된 파일 시스템에서 일어났던 가용 리스트 단편화 문제를 피하면서도, 파일에 할당하기 위한 커다란 가용 공간 청크를 쉽게 찾을 수 있기 때문이다.
마지막으로 아이노드와 데이터 블럭 영역은 이전 vsfs에서와 같다. 각 실린더 그룹의 대부분은 보통 데이터 블럭이 차지한다.
4. Policies: How To Allocate Files and Directories
이러한 그룹 구조를 통해 FFS는 어떻게 파일, 디렉토리, 그리고 관련된 메타데이터를 디스크에 위치시킬지를 결정해야한다. 기본적인 방법은 간단하다. 관련된 것들을 가까이에 모아두는 것이다.
이를 위해 FFS는 어떤 것들이 관련되어 있는지를 결정해야 하고, 이것들을 같은 블럭 그룹 안에 위치시켜야 한다. 반대로, 관련이 없는 아이템들은 다른 블럭 그룹에 위치시켜야 한다. 이 목적을 위해 FFS는 여러 가지 간단한 배치 휴리스틱들을 사용한다.
첫 번째는 디렉토리의 배치에 대한 것이다. FFS는 간단한 방법을 취한다. 할당된 디렉토리를 위해서는 낮은 번호의 실린더 그룹을 이용하고, 가용 아이노드를 위해서는 높은 번호를 이용한다. 디렉토리 데이터와 아이노드들은 해당 그룹에 집어넣는다. 물론 다른 휴리스틱들도 사용될 수 있다.
파일들을 위해서는 두 가지를 진행한다. 첫 번째로 FFS는 파일의 데이터 블럭들을 아이노드와 같은 그룹에 넣어, 아이노드와 데이터 사이의 긴 탐색을 방지한다. 두 번째로, 같은 디렉토리에 있는 모든 파일들은 해당 디렉토리가 있는 같은 실린더 그룹에 집어넣는다. 이로써 만약 사용자가 네 개의 파일 /a/b, /a/c, /a/d, /b/f를 만들면, FFS는 앞의 세 파일들을 서로 가까이에 위치시키고, 마지막 네 번째 파일은 좀 더 먼 곳에 위치 시킨다.
이러한 할당에 대한 예를 하나 살펴보자. 이 예에서는 각 그룹에 10개의 아이노드와 10개의 데이터 블럭들이 있다고 가정한다. 또한 세 개의 디렉토리(/, /a, /b)와 네 개의 파일(/a/c, /a/d, /a/e, /b/f)들이 있다고 가정한다. 이때 정규 파일들은 각각 2블럭의 사이즈를 가지고, 디렉토리는 한 데이터 블럭만을 차지한다고 하자. 아래에서 '/'는 루트 디렉토리, 'a'는 /a, 'f'는 /b/f를 가리킨다.

FFS의 정책이 가져다 주는 두 이점에 대해 유의하자. 각 파일의 데이터 블럭은 그 아이노드와 근접해있고, 같은 디렉토리의 파일들은 서로 근접해있다.
이와 달리, 이번에는 단순하게 아이노드를 그룹들에 흩뿌려놓는 아이노드 할당 정책을 살펴보자. 어떤 그룹의 아이노드 테이블도 빨리 채워지지 않게 해본다. 최종 할당 결과는 다음과 같을 것이다.

여기서 볼 수 있듯, 이 정책은 파일과 디렉토리 데이터들을 그 각각의 아이노드와는 근접하게 위치시키지만, 같은 디렉토리에 있는 파일들은 디스크에 임의로 흩어져있고, 따라서 이름 기반의 지역성은 유지되지 않는다. 파일 /a/c, /a/d, /a/e에의 접근은 FFS 방식에서와 달리 세 개의 그룹에 걸쳐있다.
FFS 정책 휴리스틱이 파일 시스템 트래픽과 같은 것에 대한 연구에 기반한 것은 아니다. 그보다 이는 오래된 상식에 기반해 있다. 디렉토리에 있는 파일들은 주로 함께 접근된다. 여러 파일들을 컴파일하고 하나의 실행 파일로 링크시키는 경우를 생각해보라. 이러한 네임스페이스 기반의 지역성이 존재하기 때문에, FFS는 관련된 파일 사이의 탐색 시간을 줄이며 성능을 향상시킬 수 있는 것이다.
5. Measuring File Locality
이러한 휴리스틱이 그럴싸한 것인지를 알아보기 위해, 이번에는 파일 시스템 접근을 따라 분석해보며 정말로 네임스페이스 지역성이 있는지를 확인해보자.
구체적으로는 SEER 트레이스를 이용해 디렉토리 트리 내에서의 파일 접근이 얼마나 멀리 다른 것들과 떨어져있는지를 분석해본다. 예를 들어 만약 파일 f가 열려있고, 다른 파일이 열리기 전에 해당 파일을 얼마 후에 다시 열면, 두 파일 접근 사이의 거리는 0이다. 만약 디렉토리 dir 안의 파일 f가 열리고, 같은 디렉토리 내의 파일 g를 열게 되면, 두 파일 접근 사이의 거리는 1이다. 같은 디렉토리 내에는 있지만 서로 같은 파일은 아니기 떄문이다. 다시 말해, 여기서 측정되는 거리의 기준은 두 파일의 공통 조상을 찾기 위해 얼마나 디렉토리 트리를 올라가야 하는지를 말한다. 트리 내에서 가까울수록 거리는 짧아진다.
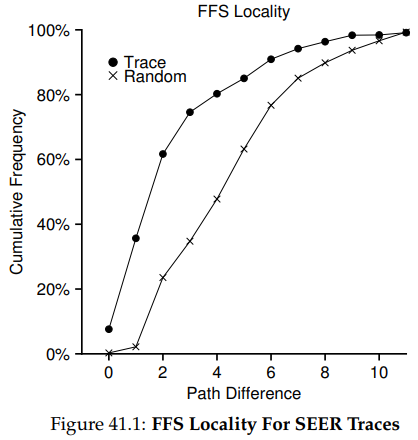
위 그림은 SEER 클러스터의 모든 워크스테이션의 모든 트레이스 총합에 대한 SEER 트레이스의 지역성을 보여준다. 그래프의 x축은 거리(경로 차이), y축은 해당 거리에 따른 파일 열기의 누적 빈도다. 구체적으로 SEER 트레이스에 대해, 7%의 파일 접근은 이전에 열린 파일들에 대한 것이고, 약 40%의 파일 접근은 같은 파일, 또는 같은 디렉토리 내에 있는 파일임을 볼 수 있다. 따라서 FFS의 지역성 가정은 그럴 듯해보인다.
흥미롭게도, 다른 25%의 파일 접근은 거리가 2인 파일들에 대한 것이었다. 이러한 종류의 지역성은 사용자가 다층적인 방식으로 관련된 디렉토리 집합을 구성하고 계속해서 그것들 사이를 번갈아 접근할 때 일어난다. 예를 들어 만약 사용자가 src 디렉토리를 가지고 있고, 오브젝트 파일을 obj 디렉토리에 만들었다고 하자. 이 두 디렉토리는 proj 디렉토리의 하위 디렉토리들이다. 이때의 흔한 접근 패턴은 proj/src/foo.c에 이어 proj/obj.foo.o에 접근하는 것이다. 두 접근 사이의 거리는 2인데, proj가 공통 조상이기 때문이다. FFS는 이러한 종류의 지역성을 정책에서 포착하고 있지 않고, 따라서 두 접근 사이에서는 더 많은 탐색이 일어나게 될 것이다.
비교를 위해 그래프는 랜덤 트레이스의 지역성도 보여주고 있다. 랜덤 트레이스는 SEER 트레이스에 있는 파일들을 임의의 순서로 고르고, 이 접근들 사이의 거리를 계산함으로써 만들어진다. 여기서 볼 수 있듯, 랜덤 접근에는 적은 네임스페이스 지역성이 나타난다. 하지만 모든 파일들이 결국에는 공통 조상(즉 루트 디렉토리)을 가지므로, 지역성이 나타나기는 한다. 랜덤 트레이스가 비교에 유용한 이유다.
6. The Large-File Exception
FFS의 일반적인 파일 배치 정책에는 한 가지 중요한 예외가 있는데, 이는 큰 파일들에 대한 것이다. 이러한 예외 규칙이 없다면, 큰 파일들은 그것이 처음으로 들어가게 되는 블럭 그룹 전체를 채워버리게 될 것이다. 이와 같은 방식으로 하나의 블럭 그룹을 채우는 것은 원하던 것이 아니다. 왜냐하면 이는 그것과 관련된 파일들을 해당 블럭 그룹에 위치시키는 것을 막고, 파일 접근 지역성을 해치기 때문이다.
그러므로 큰 파일들에 대해서, FFS는 다음과 같이 한다. 첫 번째 블럭 그룹에 얼마간의 블럭들을 할당하고 나면, FFS는 파일의 다음 큰 청크를 다른 블럭 그룹에 놓는다. 그러고나면 또 다음의 파일 청크를 또 다른 블럭 그룹에 넣는다.
이 정책을 좀 더 잘 이해하기 위한 다이어그램을 보도록하자. 큰 파일에 대한 예외처리가 없으면, 하나의 큰 파일은 블럭의 한 부분에 모든 블럭을 놓게 될 것이다. 각 10개의 아이노드, 40개의 데이터 블럭으로 이루어진 그룹을 이용하는 FFS에 30블럭 짜리 파일 /a를 놓아보자.

그림에서 볼 수 있듯, /a는 그룹 0의 대부분의 데이터 블럭을 채우고, 다른 그룹들은 빈 채로 남는다. 만약 어떤 다른 파일들이 루트 디렉토리에 만들어진다고 하면, 해당 데이터를 그 그룹에 넣을 빈 공간은 남아있지 않다.
큰 파일에 대한 예외 처리를 이용한다면, FFS는 해당 파일을 여러 그룹에 흩어 놓아, 한 그룹만을 너무 많이 활용하지 않도록 만든다.

이렇게 파일 블럭들을 디스크에 흩어 놓는 것은, 특히 흔히 일어나는 순차적 접근의 경우, 성능을 저하시킨다. 하지만 이러한 문제는 청크의 크기를 세심하게 정함으로써 해결할 수 있다.
구체적으로, 만약 청크의 크기가 충분히 크다면 파일 시스템은 그 대부분의 시간을 디스크로부터 데이터를 전송해오는 데 쓰고, 블럭 청크들 사이에서 탐색하는 데에는 거의 쓰지 않는다. 이렇게 오버헤드 당 더 많은 작업들을 함으로써 전체 오버헤드를 줄이는 과정을 가리켜 amortization이라 부르며, 이는 컴퓨터 시스템에서 흔히 쓰이는 테크닉이다.
다른 예를 한번 보자. 디스크에의 평균 접근 시간이 10ms라 가정하자. 또한 디스크의 데이터 전송 속도는 40MB/s라 가정하자. 만약 전체 시간 중 절반은 청크 사이의 탐색, 그리고 나머지 절반은 데이터 전송을 위해 쓰고자 한다면, 각 10ms의 포지셔닝마다 10ms의 데이터 전송 시간을 써야할 것이다. 그렇다면 10ms의 시간을 데이터 전송에 쓰기 위한 청크의 크기는 얼마나 커야할까?
위 등식이 말하는 것은 다음과 같다. 40MB/s의 속도로 데이터를 전송하는 경우, 절반의 시간을 탐색, 절반의 시간을 데이터 전송에 쓰고자 한다면, 탐색마다 409.6KB의 데이터를 전송해야한다는 것이다. 비슷하게 최대 대역폭의 90%를 달성하고자 하는 경우의 청크 크기도 계산할 수 있고, 99%인 경우에도 계산할 수 있다. 최대 대역폭에 가까워질수록 더 큰 청크를 사용할 수 있게 된다.
하지만 FFS가 큰 파일을 그룹에 분산시키기 위해 이와 같은 계산을 하는 것은 아니다. FFS는 그 대신 아이노드의 구조에 기반한 단순한 방식을 취한다. 첫 번째 열두 개 직접 블럭들은 아이노드와 같은 그룹에 위치한다. 후속 간접 블럭 각각과 그것이 가리키는 블럭들은 다른 그룹에 위치한다. 블럭 사이즈가 4KB이고 디스크 주소가 34-bit일 때, 이 전략은 파일을 1024 블럭(4MB) 단위로 별개의 그룹에 위치시킨다. 유일한
예외는 직접 포인터들이 가리키는 첫 번째 48KB가 된다.
디스크 제작사가 더 많은 비트들을 같은 표면에 집어넣게 되면서 데이터 전송률은 빠르게 증가하지만, 탐색과 관련한, 기계적인 측면은 보다 느리게 개선된다는 점에 유의하자. 즉 시간이 지날수록 기계적 비용은 상대적으로 비싸진다. 따라서 전체 비용을 줄이기 위해서는 비싼 탐색마다 최대한 많은 데이터 전송이 일어날 수 있게 해야한다.
7. A Few Other Things About FFS
FFS는 다른 혁신 기법들도 도입했다. 특히 설계자들은 작은 파일들을 수용하는 데에 많은 신경을 썼다. 왜냐하면 그때의 많은 파일들은 2KB였기 때문에, 4KB 블럭을 사용하는 것은 데이터 전송에는 좋았을지 몰라도 공간 효율성의 측면에서는 그리 좋지 않았기 때문이다. 이러한 내부 단편화는 거의 절반의 디스크가 낭비되도록 하는 결과로 이어질 수도 있다.
FFS 설계자들이 선택한 해법은 단순했다. 파일 시스템이 파일에 할당할 수 있는, 512바이트 크기의 작은 서브블럭(sub-block)을 도입한 것이다. 만약 작은 크기의 파일, 예를 들어 1KB의 파일을 만들면, 이는 2개의 서브블럭을 차지할 것이고, 4KB 블럭 전체를 낭비하는 일은 일어나지 않을 것이다. 파일이 더 커지면 파일 시스템은 해당 파일이 최대 4KB 데이터를 얻을 때까지 계속해서 512바이트의 블럭을 거기에 할당할 것이다. 이 시점에서 FFS는 4KB 블럭을 찾고, 그 안의 서브블럭을 복사하고, 나중에 쓸 수 있게 그 안의 서브블럭들의 할당을 해제할 것이다.
이러한 과정이 파일 시스템에 많은 추가적인 작업을 필요로 하기 때문에 비효율적으로 보일 수도 있다. 그러므로 FFS는 보통 libc 라이브러리를 수정해 이런 비효율적인 행동을 피한다. 이 라이브러리는 쓰기를 버퍼 처리하고, 4KB의 크기가 되면 파일 시스템에 요청을 보낸다. 이러한 방법으로 서브블럭을 사용하는 대부분의 특수한 경우를 피할 수 있게 된다.
FFS가 도입한 두 번째 기발한 것은 성능에 최적화된 디스크 레이아웃이다. 그때 디스크들은 그리 정교하지 않았고, 호스트 CPU가 그 연산들을 직접적인 방법으로 제어해야했다. 이 문제는 FFS에서, 하나의 파일이 디스크의 연속된 섹터에 위치될 때 발생한다.
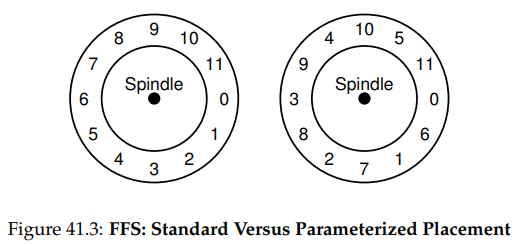
구체적으로, 이 문제는 순차적 읽기가 일어날 때 발생한다. FFS는 우선 블럭 0에 대한 읽기를 요청한다. 읽기가 완료되는 시점에 FFS는 블럭 1에 대한 읽기를 요청하는데, 이는 너무 늦다. 블럭 1은 이미 헤드를 지나갔고, 다시 1번 블럭을 읽기 위해서는 또 완전히 한 바퀴를 돌려야 하기 떄문이다.
FFS는 이 문제를 다른 레이아웃을 사용함으로써 해결한다. 위 그림의 오른쪽과 같다. 블럭들을 순서대로 하나 씩 띄워놓음으로써 FFS는 다음 블럭이 디스크 헤드를 지나가기 전에 해당 블럭을 요청할 충분한 시간을 가질 수 있게 된다. 사실 FFS는 특정 디스크에 대한 배치를 만들 때, 추가적인 회전을 피하기 위해서는 얼마나 많은 블럭들을 스킵해야하는지를 알아낼 수 있을 만큼 똑똑하다. 이러한 기법을 가리켜 매개화(parameterization)라 부른다. FFS가 디스크의 구체적인 성능 파라미터를 알아내고, 이를 이용한 정확한 시차 배치 기법을 결정하기 때문이다.
물론 이러한 방법이 항상 좋지만은 않다는 것도 알 수 있을 것이다. 사실 이러한 종류의 레이아웃을 사용하면 최대 대역폭의 50% 밖에 얻지 못한다. 왜냐하면 각 블럭을 한 번 읽기 위해서는 적어도 두 개의 트랙을 돌아야 하기 떄문이다. 다행스럽게도 현대 디스크들은 좀 더 똑똑하다. 그들은 내부적으로 전체 트랙을 읽어 들이고, 이를 내부 디스크 캐시에 버퍼링한다. 그러면 트랙에 대한 후속 읽기 작업에서 디스크는 원하던 데이터를 그 캐시에서 꺼내 반환할 것이다. 이로써 파일 시스템은 이러한 과하게 낮은 수준의 세부 사항들에 대해서는 신경 쓸 필요가 없게 된다. 추상화와 고수준 인터페이스만으로도 충분하다. 설계가 적절하게 됐다면 말이다.
사용성 향상을 위한 것들도 추가됐다. FFS는 긴 파일 이름을 허용한 첫 번째 파일 시스템이며, 이는 전통적인 고정 크기 방식보다 더 표현력 있는 이름을 가능하게 했다. 또한 심볼릭 링크라는 새로운 개념도 도입됐다. 이전 장에서 논의된 것과 같이, 하드 링크는 디렉토리를 가리킬 수 없고, 같은 볼륨 내의 파일만 가리킬 수 있다는 한계를 가진다. 심불릭 링크는 사용자가 시스템 상 어떠한 파일이나 디렉토리에 대해서도 별칭을 만들 수 있게 하며, 따라서 더 유연하다. FFS는 원자적 rename() 작업도 도입했다. 이러한 사용성의 개선은 FFS가 더 두터운 사용자층을 얻을 수 있게 했다.
8. Summary
FFS의 도입은 파일 시스템 역사에서의 분수령이다. 왜냐하면 이는 파일의 관리 문제가 운영체제 내에서 가장 흥미로운 이슈라는 것을 명확히 했고, 하드 디스크라는, 가장 중요한 장치를 어떻게 다룰 수 있는지를 보여줬기 때문이다. 그때부터 수 백개의 새로운 파일 시스템들이 개발되어 왔지만, 오늘날에도 많은 시스템들은 여전히 FFS의 영향을 받고 있다. 분명히, 모든 현대 시스템들은 디스크를 디스크로 다루라는 FFS의 핵심 교훈을 따르고 있다.
