프로그램 = 자료구조 + 알고리즘
알고리즘
: 컴퓨터로 문제를 풀기 위한 단계적인 절차
알고리즘의 조건
- 입력 : 0개 이상의 입력이 존재하여야 한다.
- 출력 : 1개 이상의 출력이 존재하여야 한다.
- 명백성 : 각 명령어의 의미는 모호하지 않고 명확해야 한다.
- 유한성 : 한정된 수의 단계 후에는 반드시 종료되어야 한다.
- 유효성 : 각 명령어들은 실행 가능한 연산이여야 한다.
알고리즘의 기술 방법
- 영어나 한국어와 같은 자연어
- 흐름도(flow chart)
- 의사 코드(pseudo-code)
- 프로그래밍 언어
1. 자연어로 표기 된 알고리즘
- 인간이 읽기 쉽다.
- 자연어의 단어들을 정확하게 정의하지 않으면 의미전달이 모호해질 우려가 있다.
2. 흐름도로 표기된 알고리즘
- 직관적, 이해하기 쉬움
- 복잡한 알고리즘의 경우 상당히 복잡해짐
3. 유사코드로 표현된 알고리즘
- 알고리즘 기술에 가장 많이 사용
- 프로그램을 구현할 때의 여러 가지 문제들을 감출 수 있다.
- 즉 알고리즘의 핵심적인 내용에만 집중할 수 있다.
4. c로 표현된 알고리즘
- 가장 정확한 기술이 가능
- 실제 구현 시, 많은 구체적인 사항들이 알고리즘의 핵심적인 내용에 대한 이해를 방해할 수 있다.
자료형
데이터의 종류
데이터의 집합과 연산의 집합 (각 자료형마다 연산이 정의되어있다.)
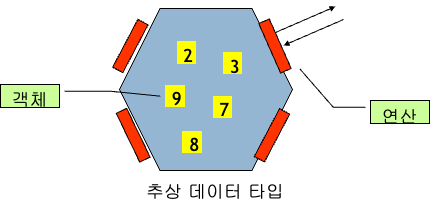
추상 데이터 타입 (ADT: Abstract Data Type)
기능(function)들만 기술해놓고, 그것의 내부적 표현이나 구현은 안해놓은 것을 의미
데이터나 연산이 무엇(what)인가는 정의되지만 데이터나 연산을 어떻게(how) 컴퓨터 상에서 구현할 것인지는 정의되지 않는다.
사용자 입장에서의 ADT는
'이 데이터 타입은 이러이러한 객체들(objects)과 이러이러한 함수들(functions)로 구성되어있다'
라는 것을 명시해 놓은것이고
'사용설명서' 같은것이기 때문에 외부에 공개적(public) 입니다.
그렇지만 구현 부분을 나타내지 않기 때문에 내부는 비공개적(private)입니다. (-> 정보 은닉)
이말인 즉슨, 사용자는 사용법만 알면, 내부는 몰라도 그 데이터 타입을 쉽게 쓸 수 있다는 말이 됩니다.
[출처] [자료구조 3강] 추상 데이터 타입(Abstract Data Type)|작성자 서천마을4단지
추상화(abstraction)-> 정보은닉기법(information hiding)-> 추상 자료형(ADT)
추상화란 사용자에게 중요한 정보는 강조되고 반면 중요하지 않은 구현 세부 사항은 제거하는 것
- 객체: 추상 데이터 타입에 속하는 객체가 정의된다.
- 연산: 이들 객체들 사이의 연산이 정의된다. 이 연산은 추상 데이터 타입과 외부를 연결하는 인터페이스의 역할을 한다.
알고리즘의 성능 분석 기법
1. 수행 시간 측정
- 두개의 알고리즘의 실제 수행 시간을 측정하는 것
- 실제로 구현하는 것이 필요
- 동일한 하드웨어를 사용하여야 함
수행시간 측정 2가지 방법

#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(void)
{
clock_t start, stop;
double duration;
start = clock(); // 측정 시작
for (int i = 0; i < 1000000; i++) // 의미 없는 반복 루프
;
stop = clock(); // 측정 종료
duration = (double)(stop - start) / CLOCKS_PER_SEC;
printf("수행시간은 %f초입니다.\n", duration);
return 0;
}
2. 알고리즘의 복잡도 분석
- 직접 구현하지 않고서도 수행 시간을 분석하는 것
- 알고리즘이 수행하는 연산의 횟수를 측정하여 비교
- 일반적으로 연산의 횟수는 n의 함수
시간 복잡도는 알고리즘을 이루고 있는 연산들이 몇 번이나 수행되는지를 숫자로 표시
- 시간 복잡도(time complexity)
- 공간 복잡도(space complexity)
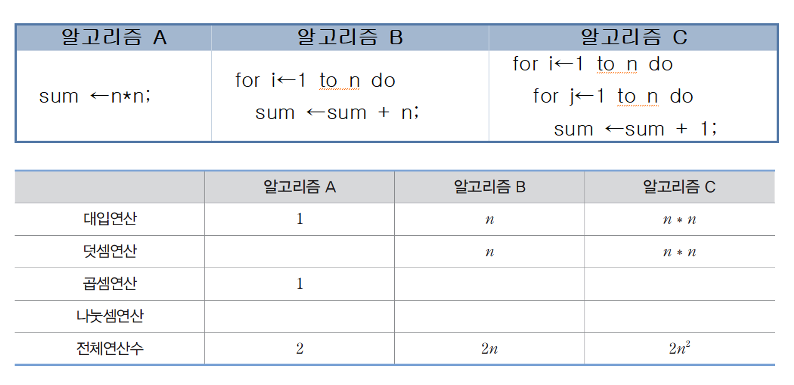
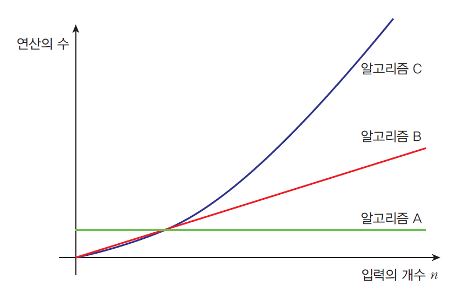
알고리즘A의 연산 횟수가 가장 적음.
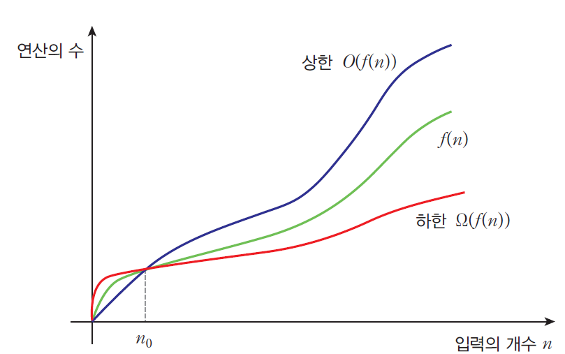
빅오 표기법
연산의 횟수를 대략적(점근적)으로 표기한 것
함수의 상한을 표시한다.(최악의 경우)
빅오 표기법의 종류

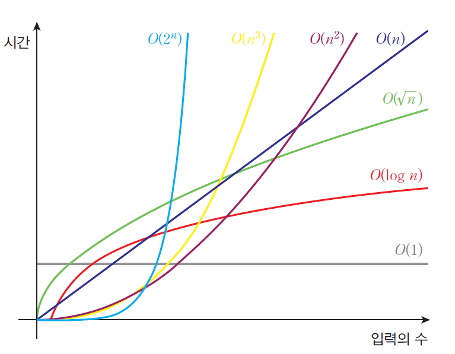
빅오메가 표기법
함수의 하한을 표시한다.(최선의 경우)
빅세타 표기법
함수의 하한인 동시에 상한을 표시한다. (평균적인 경우)
- 최선의 경우(best case): 수행 시간이 가장 빠른 경우
- 평균의 경우(average case): 수행시간이 평균적인 경우
- 최악의 경우(worst case): 수행 시간이 가장 늦은 경우
참고)
