[C] 알고리즘
1.자료구조와 알고리즘

프로그램 = 자료구조 + 알고리즘: 컴퓨터로 문제를 풀기 위한 단계적인 절차입력 : 0개 이상의 입력이 존재하여야 한다. 출력 : 1개 이상의 출력이 존재하여야 한다. 명백성 : 각 명령어의 의미는 모호하지 않고 명확해야 한다.유한성 : 한정된 수의 단계 후에는 반드시
2.[c] 메모리 구조와 동적 객체 생성
데이터스택힙할당시기 : 프로그램이 실행될 때마다 할당 (실행될 때마다 주소값이 바뀜)할당장소 : 메인메모리 (RAM): 전역변수와 정적변수가 할당: 함수호출 시에 생성되는 지역변수와 매개변수가 저장됨 (함수호출이 완료되면 사라짐): 필요에 따라 동적으로 메모리 할당할당
3.[c] 포인터

: 메모리 주소를 가리키는 것, 변수의 주소값을 저장: \*(참조 연산자)를 붙여서 선언int형 변수의 주소를 담고 싶으면 int \* -> 가리킬 주소가 어떤 자료형을 갖는지 알려주고 위해서ex) int형이면 4바이트만큼 읽어들이기 위해포인터 변수의 크기는 모두 동일
4.[c] 알고리즘 - 배열과 구조체
소수의 정의1과 자기 자신만으로 나누어 떨어지는 1보다 큰 양의 정수윤년이란? : 4년에 한 번씩 2월 29일이 생김, 실제로 지구가 태양을 한 바퀴 도는데 정확히 365.2422일이 걸리기 때문.윤년의 주기연수가 4로 나누어 떨어지는 해는 윤년연수가 100으로 나누어
5.[c] 알고리즘 - 선형검색, 이진검색
선형 검색(순차 검색): 원하는 키 값을 갖는 요소를 만날 때까지 맨 앞부터 순서대로 요소를 검섹선형 검색 종료 조건검색할 값을 발견하지 못하고 배열의 끝을 지나간 경우검색할 값과 같은 요소를 발견한 경우while문보다 짧고 간결함.선형 검색은 반복할 때마다 종료조건
6.[c] 알고리즘 - 스택과 큐
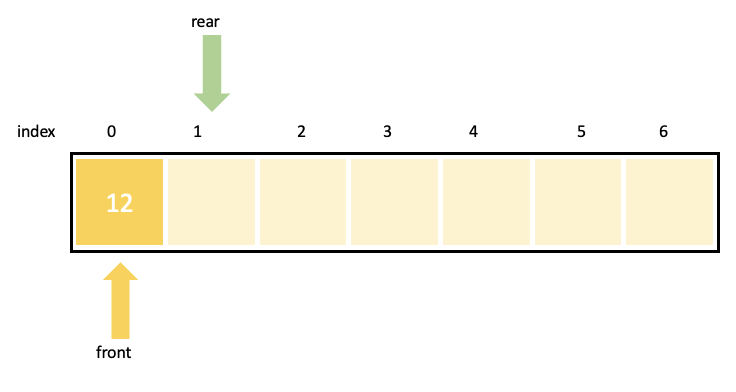
LIFO(Last In First Out)구조를 가진 자료구조IntStack.hIntStack.cIntStackTest.cFIFO(First In First Out)구조를 가진 자료구조rear : 다음 데이터를 넣을 위치front : 데이터가 빠져나갈 위치IntQueu
7.[c] 재귀 알고리즘

재귀란? : 어떤 사건이 자기 자신을 포함하고 다시 자기 자신을 사용하여 정의하는 것이처럼 가장 위쪽에 위치한 함수 호출부터 시작해 계단식으로 자세히 조사해 가는 분석 기법을 하향식 분석(top-down analysis)이라고 합니다.하향식 분석과는 반대로 아래쪽부터
8.[c] 소수 구하기 알고리즘
1에서 30만까지의 범위 중 소수를 구해 출력하세요.1과 자기 자신만으로 나누어 떨어지는 1보다 큰 양의 정수ex) 2, 3, 4, 5, 7, 11, 13, 17, 23...소수이기 위해서는 내가 구하고자 하는 수(n)가 1보다 크고 n보다 작은 수로 나눠지지 않으면
9.[c] 알고리즘 - 버블 정렬
1. 정렬 오름차순 정렬(ascending order sort) 내림차순 정렬(descending order sort) 내부 정렬(internal sorting) : 정렬할 모든 데이터를 하나의 배열에 저장할 수 있는 경우에 사용하는 알고리즘 외부 정렬(externa
10.[c] 알고리즘 - 단순 선택 정렬

참고)(내 손으로 직접 코딩하며 확인한다!) 자료구조와 함께 배우는 알고리즘 입문 - C 언어 편
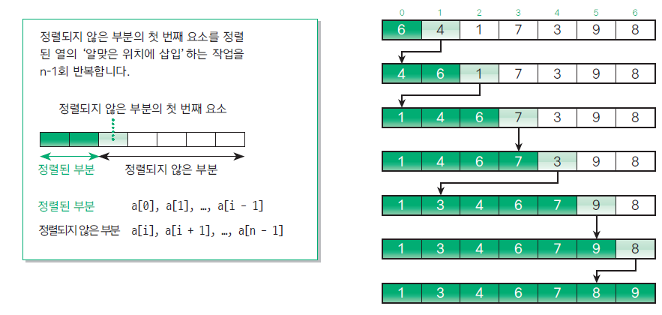
11.[c] 알고리즘 - 단순 삽입 정렬

단순 삽입 정렬: 정렬되지 않은 부분의 첫 번째 요소를 정렬된 열의 '알맞은 위치에 삽입'하는 작업을 n-1회 반복한다.\- 2번째 요소부터 선택하여 진행한다.\- n-1회를 반복하여 정렬\- 셔틀 정렬(shuttle sort)이라고도 한다.장점 :\- 정렬을 마친 상
12.[c] 알고리즘 - 8퀸 문제

각 행에 하나의 퀸각 열에 하나의 퀸대각선에 하나의 퀸64 X 63 X 62 X 61 X 60 X 59 X 58 X 57가지 뻗기로 8퀸 문제의 해답을 얻을 수 없다.규칙2 각 행에 퀸을 1개만 배치한다.규칙2를 적용해 다시 구현한다.한정 조작 : 필요하지 않은 분기를
13.[c] 퀵정렬
참고) https://hongku.tistory.com/149
14.[c] 셸 정렬
삽입 정렬을 보완한 알고리즘삽입 정렬이 어느 정도 정렬된 배열에 대해서는 대단히 빠른 것에 착안정렬을 마친 상태에 가까우면 정렬 속도가 매우 빨라진다. 삽입할 위치가 멀리 떨어져 있으면 이동(대입)해야 하는 횟수가 많아진다.\- 요소들이 삽입될 때, 이웃한 위치로만 이
15.[c] 퀵 정렬

가장 빠른 알고리즘 중 하나찰스 앤터니 리처드 호어(C.A.R. Hoare)가 명명각 그룹에 대해 피벗(pivot) 설정과 그룹 나눔을 반복하며 모든 그룹이 1명이 되면 정렬을 마침불안정 정렬에 속함피벗(pivot) : 그룹을 나누는 기준을 말하며, 피벗은 마음대로 선
16.[c] 병합 정렬

배열을 앞 부분과 뒷 부분으로 나누어 각각 정렬한 다음 병합하는 작업을 반복하여 정렬을 수행하는 알고리즘1945년 존 폰 노이만(John von Neumann)이 개발안정정렬에 속한다.분할 정복 알고리즘의 하나이다. (퀵 정렬도 분할정복알고리즘)배열 a에서 선택한 요소
17.[c] 힙 정렬 / 도수 정렬

https://gmlwjd9405.github.io/2018/05/10/algorithm-heap-sort.html'부모의 값이 자식의 값보다 항상 크다'는 조건을 만족하는 완전이진트리힙 정렬은 선택 정렬(가장 큰 요소 선택)을 응용한 알고리즘불안정 정렬힙 정
18.[c] 문자열의 기본

프로그램에서 문자의 '나열'을 표현한 것빈 문자열도 문자열이다.문자열 리터럴의 끝을 나타내기 위해 NULL 문자열을 자동으로 추가문자열 리터럴의 자료형은 char형 배열문자열 리터럴의 메모리 영역 기간 == 정적 메모리 영역의 기간프로그램의 시작부터 끝까지 메모리 영역
19.[c] 브루트-포스법 / KMP법 / Boyer-Moore법

선형 검색을 확장한 알고리즘이므로 단순법, 소박법이라고 한다.이미 검사를 진행한 위치를 기억하지 못하므로 효율은 떨어진다.(D.E. Knuth, V.R. Pratt, J.H. Morris)다른 문자를 만나면 패턴을 1칸씩 옮긴 다음 다시 패턴의 처음부터 검사하는 Bru
20.[c] 리스트 / 트리

커서 : 포인터 역할을 하는 인덱스를 커서라고 한다. 다음 노드가 들어있는 요소의 인덱스에 대한 값이다.마트에서 사용하지 않는 카트를 모아둔것 처럼사용하지 않는 빈 배열의 문제 해결, 삭제한 레코드를 관리하기 위해 사용하는 자료구조원형 리스트이중 연결 리스트원형 이중