지난 포스팅에서 ...
앞선 포스팅에서 우린 명암과 밝기 조절을 (나름 극단적으로) 해봄으로써 얼굴 인식이 과연 어디까지 되는가에 관해 알아보았다. 그러한 과정을 토대로 어느 정도의 밝기와 어느 정도의 명암 비에선 인식에 어려움을 겪는 것 또한 직접 확인해 볼 수 있었다.
자연에서 그러한 극단적 밝기와 명암비 상태에서 얼굴을 인식하는 일은 없겠지만 항상 이러한 것에 대해 공부할 땐 "극단적"상황을 가정하고 최대한 그것을 해결하는 방안으로 진행해야한다 생각한다.
이번 포스팅에선 "histogram stretching"과 "histogram equalization"이란 개념에 대해 알아보며 이를 통해 문제점을 해결할 수 있는지 알아보려 한다.
Histogram Anaylysis (히스토그램 분석)
히스토그램을 이용하면 주어진 영상의 픽셀 밝기 분포를 조사하여 밝기 및 명암비를 조절할 수 있다.
히스토그램이란?
히스토그램은 간단히 말해서 도수분포표를 그래프로 나타낸 것이다. 영상 처리 측면에서 보면 영상의 픽셀 값 분포를 그래프 형태로 표현한 것이다. 모든 픽셀의 밝기 값들을 구한 후 밝기 값 마다의 픽셀 개수를 세어서 그래프를 구성한다.
히스토그램에서 가로축을 히스토그램의 빈(bin) 이라고 하며 그레이스케일 영상의 경우 256개의 빈을 가진 히스토그램을 구하는 것이 일반적이지만 경우에 따라서 빈 개수를 다르게 할 수도 있다.
히스토그램을 만드는 함수는 다음과 같다.
cv2.calcHist([img], channel, mask, histSize, range)img: 이미지 배열
channel: 분석할 색상 채널
mask: 분석할 영역. None이면 이미지 전체를 의미
histSize: 히스토그램의 크기 = 빈의 개수
range: x축 값의 범위
실제로 우리 코드를 통해 히스토그램을 나타내 보자.
히스토그램을 만드는 로직 추가와 이전 포스팅에서 다뤘던 명암을 조절하는 값인 saturate_contrast()함수의 num값만 조절만 진행 할 것이다.
전체 코드는 이전 포스팅과 동일하다.
코드에 적용시켜 보기
def saturate_contrast(p, num):
pic = p.copy()
pic = pic.astype('int32')
pic = np.clip(pic+(pic-128)*num, 0, 255)
pic = pic.astype('uint8')
return pic
#명암의 num값을 -0.8로 두면서 명암을 극도로 낮춘 케이스이다.
img = saturate_contrast(img, -0.8)
# cv2의 calcHist() 메서드를 통해 히스토그램 호출
hist = cv2.calcHist([img], [0], None, [256], [0, 256])
plt.subplot(2, 1, 1), plt.imshow(img, 'gray')
plt.subplot(2, 1, 2), plt.plot(hist, color='r')
plt.xlim([0, 255])
plt.show()위와 같이 명암 조절과정에서 num값을 -0.8로 두고 명암을 크게 낯춘 경우 픽셀의 분포는 어떻게 될까? 히스토그램 결과를 확인해보자.
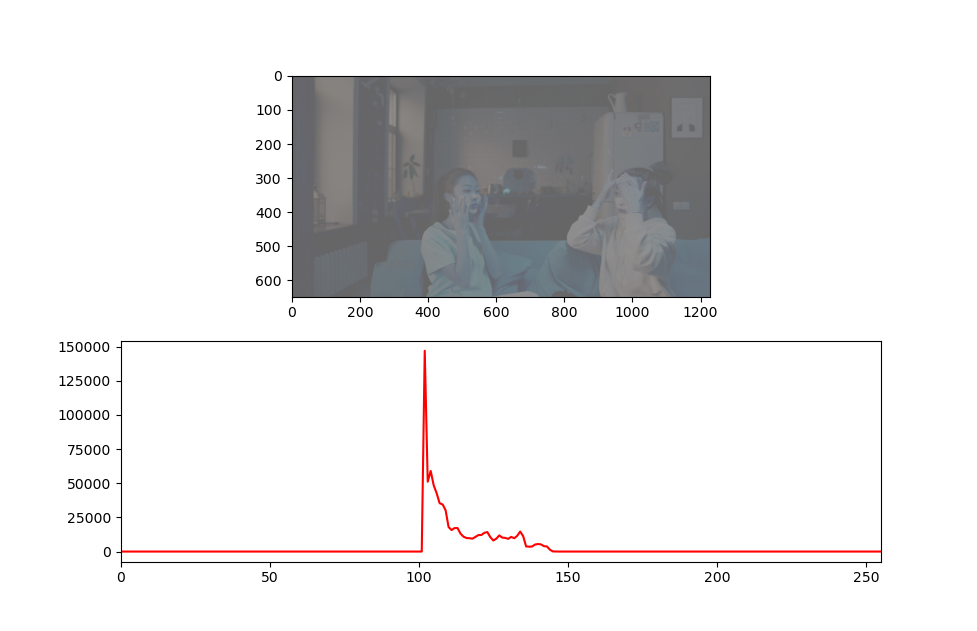
위와 같이 분포 영역이 한 곳에 몰리게 되고 전체적 분포 영역이 굉장히 작아짐을 확인할 수 있다. 이는 이미지 색상이 대부분 비슷한 값에 몰려있다는 사실인데 이미지가 선명하지 않다는 것을 의미한다.
그렇다면 만약 명암을 키운다면 어떻게 될까?
saturate_contrast()함수의 num값을 이번엔 5로 높여보자.
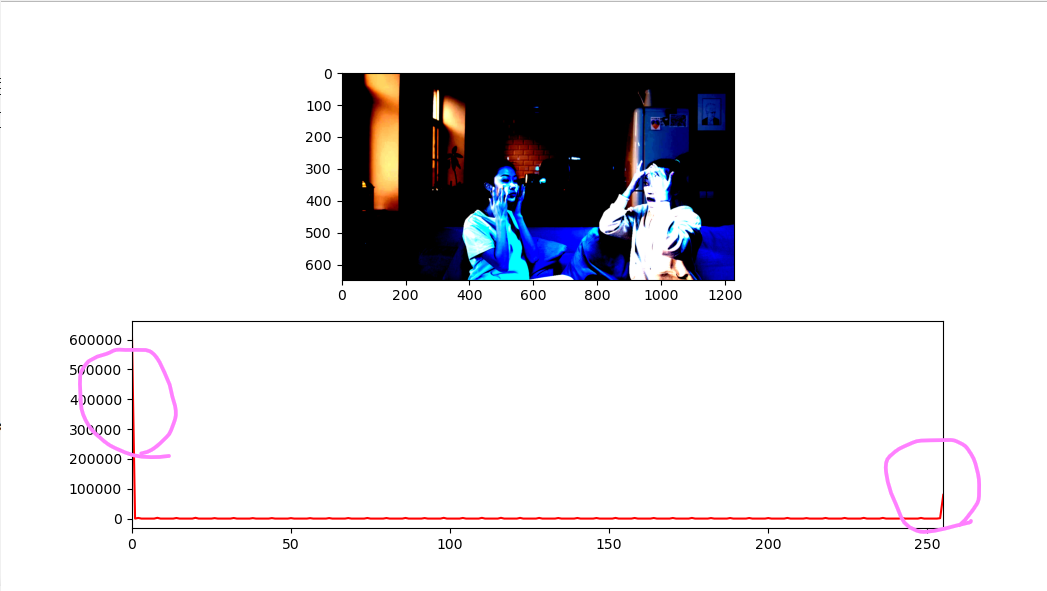
위와 같이 명암비를 크게 줬을 경우 픽셀의 분포가 아주 밝은 쪽과 아주 어두운 쪽으로 나누어진다.
즉, 우리는 명암비가 작은 이미지가 input으로 들어왔을 경우 명암비를 높여주는 작업을 해야할 것이고, 반대로 명암비가 큰 이미지가 input으로 들어왔을 경우 명암비를 낮추어주는 작업을 수행해야 할 것이다.
그럼 아래의 단계를 통해 수행해보자.
히스토그램 스트레칭(normalized histogram)
'normalized'란 영어 뜻에서도 알 수 있듯이 히스토그램 스트레칭은 일종의 "정규화"와 같다. 앞서 우리는 명암이 낮은 경우 픽셀의 분포가 한 쪽으로 몰려있는 것을 히스토그램을 통해 확인할 수 있었다.
그러한 치우친 분포를 "히스토그램 스트레칭"을 통해 넓게, 고르게 펴주는 작업이 필요하다. 만약 명암이 낮은 경우, 해당 작업을 거치면 명암비가 증가하며 얼굴 인식에 있어서 좀 더 명확한 인식이 가능케 될 것이다.
히스토그램 스트레칭은 어떤 방식으로 이루어질까? 사실 깊게 파고들자면 복잡하다. 일단 알아가는 단계이므로 간단히 이해해보기로 하였다.
우린 cv2의 normalize()라는 메서드를 통해 진행한다. 사실 해당 제공되는 메서드가 아닌 손수 구하는 방법또한 존재한다. 본인은 그러한 방법에서 무수히 많은 에러를 마주하게 되어, 일단 해당 제공되는 normalize()메서드로써 대체한다.
간단히 해당 메서드의 작업을 설명하자면 영상(혹은 이미지) 내 픽셀의 최소, 최대값의 비율을 이용하여 고정된 비율로 영상을 낮은 밝기와 높은 밝기로 당겨주는 처리를 진행한다.
코드를 통해 확인해보자.
def saturate_contrast(p, num):
pic = p.copy()
pic = pic.astype('int32')
pic = np.clip(pic+(pic-128)*num, 0, 255)
pic = pic.astype('uint8')
return pic
var_img = saturate_contrast(img, -0.8)
# normalized histogram --> 히스토그램 스트레칭 시키기 (추가 !)
dst = cv2.normalize(img, None, 0, 255, cv2.NORM_MINMAX)
hist = cv2.calcHist([dst], [0], None, [256], [0, 256])
plt.subplot(2, 1, 1), plt.imshow(dst)
plt.subplot(2, 1, 2), plt.plot(hist, color='r')
plt.xlim([0, 256])
plt.show()전체 코드는 동일하고 명암 조절을 하는 함수와 히스토그램 띄우는 코드에 normalize()메서드만 추가한 것이다.
한 가지 주의할 점은 기존에
img = saturate_contrast(img, -0.8)
와 같이 적었던 코드를 변수명 img에서 --> var_img로 변경시킨 것이다. 이러한 작업엔 이유가 있다.
우리가 normalize()메서드를 이용해 진행할 스트레칭 작업에서 첫 번째 매개변수는 "원본" 이미지이어야 한다. 즉, 원본 이미지를 기존에 지정한 img변수로 그대로 설정한 뒤, saturate_contrast()함수를 통해 명암을 조절(변경)한 이미지를 var_img로 둔다. 그 뒤 진행되는 코드에서 img를 var_img로 변경시키는 것 또한 잊지말자.
이러한 변수명 변경 후, 히스토그램을 그리는
hist = cv2.calcHist([dst], [0], None, [256], [0, 256])다음의 코드에 첫 번째 매개변수에 (기존엔 variable_img였을 것이다.) 정규화 작업을 통해 만들어 준 결과물인 dst를 주입시켜준다.
한 번 결과를 알아보자. 히스토그램의 변화가 있을까?

놀랍게도 변화가 생겼다 !!
우리는 스트레칭 작업을 하기 전, 명암을 낮춘상태로 설정함으로써 픽셀의 분포가 한 곳으로 모여있는 경우를 확인 할 수 있었다. 하지만 스트레칭 작업 후 명암의 분포를 고르게 만들 수 있게 되었고, 영상 이미지의 명암 또한 커진 것을 확연히 볼 수 있게 되었다.
하지만 위와 같은 경우도 완벽한 문제 해결이라 보긴 어렵다.
우리가 명암을 높여줌으로써 분포를 나름 고르게 할 순 있었지만 아직도 여전히 낮은 픽셀에 분포 값들이 모여 있는 것을 확인할 수 있다.
조금 더 쉽게 말하자면, 히스토그램 스트레칭을 통해 분포도는 넓혀주었지만 특정 그레이 스케일 값에 픽셀 분포가 뭉쳐있는 문제는 해결할 수 없는 것이다.
우리는 이와 같은 문제를 아래서 보게 될 "히스토그램 평활화(histogram equalization)"을 통해 해결할 수 있다.
히스토그램 평활화 (Histogram Equalization)
히스토그램 평활화를 하는 방법은 여러가지가 있지만, 이번 포스팅에선 위의 스트레칭 방법과 마찬가지로 cv2에서 제공하는 메서드를 사용할 것이다.
해당 메서드는 equalizeHist()이다. 인자로는 원본 이미지를 받을 것이므로 우리는 img를 주입해준다.
전체 코드를 알아보자. 스트레칭 작업과 크게 다를 건 없다.
dst = cv2.equalizeHist(img)
hist = cv2.calcHist([dst], [0], None, [256], [0, 256])
plt.subplot(3, 1, 2), plt.imshow(dst)
plt.subplot(3, 1, 3), plt.plot(hist, color='r')
plt.xlim([0, 256])
plt.show()히스토그램 평활화는 뭉쳐져있는 픽셀 부분은 펼쳐주고, 빈도가 적은 부분은 오히려 뭉쳐지게끔 해준다. 해당 코드는 "Gray_Scale"에 해당하는 코드이다.
히스토그램의 분포가 달라졌는지 확인해 보자
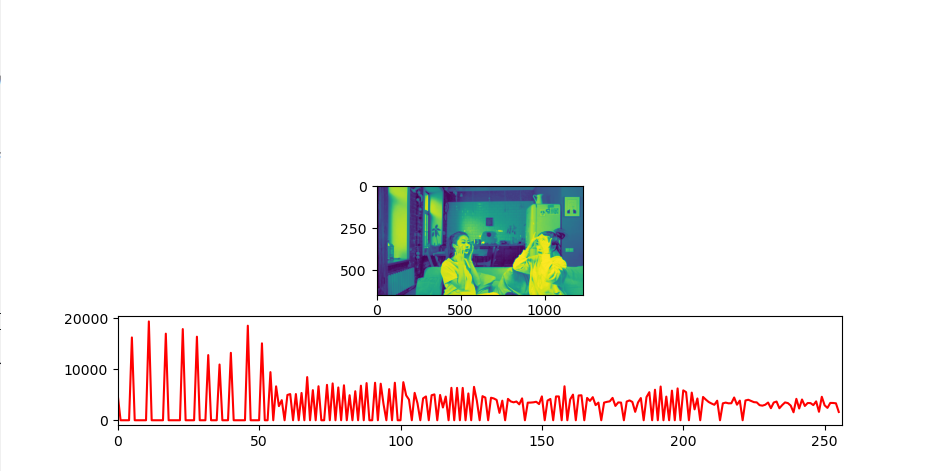
확연히 분포가 고르게 나타난 것을 확인할 수 있다. 하지만 생각보다 이미지가 깔끔해지지 않았다.
아직 해당 문제에 대한 해답을 찾진 못하였다. 아마 Gray_Scale 지정과 관련된 문제인 것 같고, 해결 중에 있다.
생각정리
이번 포스팅에선 지난 포스팅에서 명암과 밝기 조절에 따른 얼굴 인식 문제를 "히스토그램"이란 방식과 함께 해결하는 것은 중점으로 진행하였다.
그러한 방법으로 "히스토그램 스트레칭"과 "히스토그램 평활화"란 것이 있다는 것을 알게 되었고, 간단히 cv2의 내장 메서드들을 이용해 진행해보았다. 하지만 메서드들을 통해 사용하다보니 전체적 원리를 알기엔 부족하였다. 또한, 마지막 평활화 작업에선 픽셀의 분포는 고르게 되었지만, 이미지의 뚜렷함은 이루어지지 않는 등의 오류는 여전히 존재하였다. 더 정확한 얼굴 인식을 위해선 해당 문제또한 해결해야 할 것이다.
다음 주차 포스팅에선 "히스토그램 스트레칭"과 "히스토그램 평활화"를 cv2의 내장 메서드가 아닌 원천적인 방법으로 접근해볼 것이고, 위의 오류들을 잡아봄으로써 모든 작업 후, 극단적 밝기 혹은 명암을 input으로 주었을때 최대한 얼굴 인식을 가능케 하는 방향으로 진행해 볼 예정이다.
