시스템 BUS 구성 및 제어
시스템 버스의 필요성
버스와 메모리 전송
- 전형적인 디지털 컴퓨터는 많은 레지스터와 레지스터들 사이의 정보 전송을 위한 경로를 가져야 한다.
시스템은 이를 위해 각 레지스터들 사이를 연결하는 번거로움 대신 공통의 버스(bus: 한 번에 하나의 전송만이 이루어지도록 제어 신호를 이용하여 해당 레지스터를 선별)시스템이라는 효율적인 방법을 사용한다. - CPU가 행하는 중요한 기능 중 하나는 외부 주변 장치(입출력 장치) 및 통신(network)의 주체로서
정보의 입출력을 관장하는 일이다.- Bus Adapter -> 입출력 버스를 시스템 버스 라인에 연결
- 입출력 제어기(I/O controller: 입출력 인터페이스) -> 입출력 속도 및 유사한 동작 특성 단위로
입출력 장치들을 제어 관리하는 장치
시스템 버스와 I/O 버스
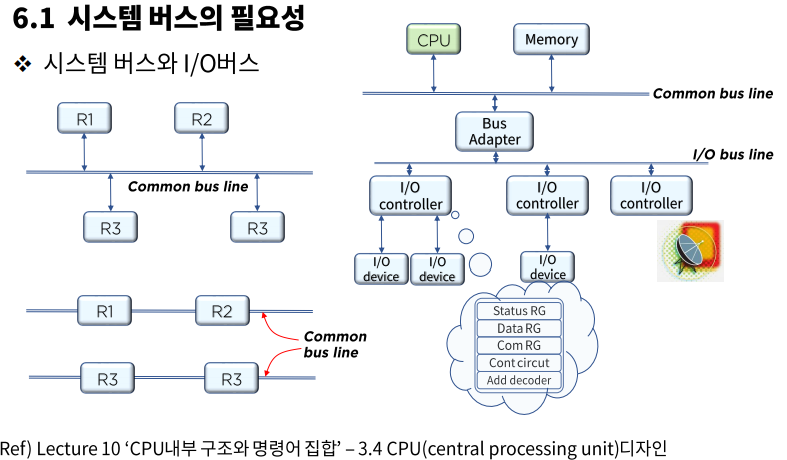
- Status RG: 상태 레지스터
- Data RG: 데이터 레지스터
- Com RG: 명령어 레지스터(Command RG)
- Cont circut: 제어 회로(Controll circuit)
- Add decoder: 주소 디코더(Address decoder)
시스템 버스의 제어
시스템 버스와 I/O 버스 간 상호 중재
- 컴퓨터 시스템에는 각 요소들 사이의 정보 전송을 위한 다양한 단계의 여러 버스가 존재한다.
ex)
CPU내에서도 레지스터와 ALU사이의 정보 전송을 위한 여러 내부 버스가 존재한다.
마더 보드의 회로들이 다 버스다.- 메모리 버스 -> 데이터, 주소, 읽기/쓰기 정보 전송
- I/O 버스 -> 입출력 장치로 정보를 주고 받는데 사용
- 공유 메모리 멀티 프로세서 시스템에서 프로세서는 시스템 버스를 통하여
공유 자원에 대한 접근을 요구한다.- 공유 자원이 사용되고 있지 않을 경우 -> 바로 사용 승인
- 공유 자원이 사용되고 있을 경우 -> 선점 프로세스의 종료까지 대기 상태 유지(인터럽트는 예외)
- 동시에 시스템 버스를 요구하는 경우 -> 공유 자원에 대한 충돌을 해결하기 위한 중재(arbitration)동작이 수행되어야 한다.
버스 중재 요소
- 버스 마스터(Bus Master) - 버스 사용의 주체(장치)
- 일반적인 컴퓨터 시스템에서는 CPU와 I/O 제어기 등이 버스 마스터이다.
- 동기식 버스 시스템에서는 기억장치 모듈도 버스 마스터가 될 수 있다.
- 버스 중재기(Bus Arbiter) - 두 개 이상의 마스터들이 동시에 버스를 요구할 때
순서를 결정하는 하드웨어 모듈- 버스 우선 순위: 높은 우선 순위의 장치가 먼저 서비스 받는다.
- 공평성: 가장 낮은 우선 순위의 장치라도 언젠가 버스를 사용할 수 있어야 한다.
시스템 버스의 기본 동작
- 쓰기 동작 순서
- 버스 마스터가 버스 사용권 획득
- 버스를 통하여 주소와 데이터 및 쓰기 신호 전송
- 읽기 동작 순서
- 버스 마스터가 버스 사용권 획득
- 주소와 읽기 신호를 보내고, 데이터가 수신될 때까지 대기
- 버스 동작의 타이밍에 따른 버스의 분류
- 동기: 전체 장치가 공통 클럭 펄스가 진동할 때만 작업이 진행된다.
- 회로가 간단하다.
- 클럭의 주기를 가장 늦게 끝나는 장비에 맞춰야해서 시간 낭비가 있다.
- 중형급 이상의 시스템에서 사용
- 비동기: 동기식과는 다르게 시간을 따로 정하지 않고 각 장치들을 독립적 클럭으로 동기화한다.
- 낭비되는 시간이 상대적으로 적지만 회로가 복잡하다.
- 서로 데이터를 주고 받을 준비가 되어있는지 핸드 쉐이킹 프로토콜(hand shaking)을 사용하여 바로바로 전송한다.
- 소규모 시스템에서 사용
- 동기: 전체 장치가 공통 클럭 펄스가 진동할 때만 작업이 진행된다.
버스 중재 신호
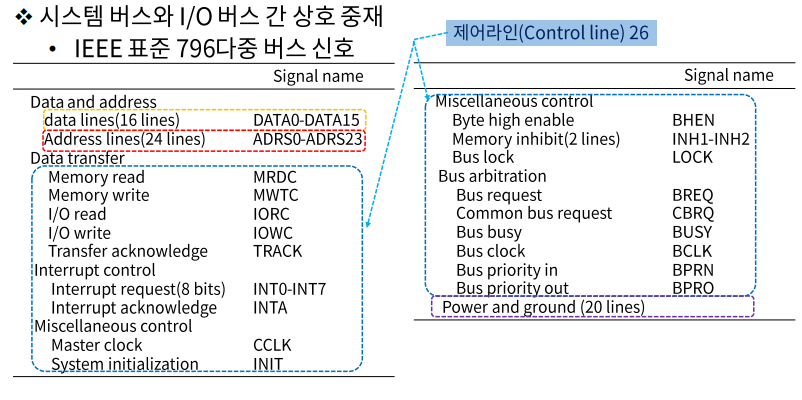
- 데이터 라인: 프로세서와 공통 메모리 사이의 데이터 전송 경로 제공
- 데이터는 CPU<->기억장치, CPU<->I/O 장치, 기억장치<->I/O장치 사이에
양방향으로 전송되기 때문에 양방향 전송 기능을 지원해야 한다.
- 데이터는 CPU<->기억장치, CPU<->I/O 장치, 기억장치<->I/O장치 사이에
- 주소 라인: 메모리 주소와 입출력 포트 식별에 활용
- 주소는 CPU에 의해서만 발생하기 때문에 단방향 전송 기능만 있으면 된다.
- 제어 라인: 장치들 간의 정보 전송을 제어하는 신호를 제공
- 기억장치 쓰기(MRDC) - 버스에 실린 데이터를 주소가 지정하는 기억장소에 저장되도록 하는 신호
- 기억장치 읽기(MWTC) - 주소가 지정하는 기억 장소의 내용을 읽어서 버스에 실리게 하는 신호
- 입출력 읽기(IORC) - 지정된 I/O 장치로부터 데이터를 읽어서 데이터 버스에 실리게 하는 제어 신호
- 입출력 쓰기(IOWC) - 버스에 실린 데이터를 지정된 I/O 장치로 출력되게 하는 제어 신호
- 전송 확인(TRACK) - 데이터 전송 동작이 완료되었음을 알려주는 신호
- 버스 요구 신호(BREQ) - 버스 마스터가 버스 사용을 요구했음을 알리는 신호
- 버스 승인 신호(BGNT) - 버스 사용을 요구한 마스터에게 사용을 허가하는 신호
- 버스 사용중 신호(BUSY) - 현재 버스가 사용되고 있는 중임을 나타내는 신호
- 인터럽트 요구 신호(INT0-INT7) - I/O 장치가 인터럽트를 요구했음을 알리는 신호
- 인터럽트 확인 신호(INTA) - CPU가 인터럽트 요구를 인식했음을 알리는 신호
버스 중재 방식의 분류
연결 구조에 따른 분류
- 직렬 중재 방식 - 버스 요구와 승인 신호 선이 각각 한 개씩만 존재하며, 각 신호선을 버스 마스터들 간에 직렬로 접속하는 방식
- 병렬 중재 방식 - 각 버스 마스터들이 독립적인 버스 요구 신호와 버스 승인 신호를 발생
-> 버스 마스터들의 수와 같은 수의 버스 요구선 및 승인 신호선이 필요
버스 중재기의 위치에 따른 분류
- 중앙 집중식 중재 방식
- 시스템 내에 버스 중재기가 한 개만 존재
- 각 버스 마스터는 버스 요구(BREQ)선을 가짐
- 버스 마스터들이 발생하는 버스 요구 신호들은 하나의 중재기로 보내지고,
중재기는 정해진 중재 원칙에 따라 선택한 버스 마스터에게 승인 신호(BGNT) 발생
- 분산식 중재 방식
- 모든 버스 마스터들이 중재기를 한 개씩 가지고 있고,
버스 중재 동작이 각 마스터의 중재기에 의하여 이루어지는 방식 - 중앙 집중식에 비해 중재 회로가 간단하여 동작 속도가 더 빠름
- 고장을 일으킨 중재기를 찾기 힘들고, 한 중재기의 고장이 전체 시스템에 영향을 준다.
- 모든 버스 마스터들이 중재기를 한 개씩 가지고 있고,
우선 순위의 결정 방식에 따른 분류
- 고정 우선 순위 방식 - 각 버스 마스터에 지정된 우선 순위가 고정되어 있는 방식
- 가변 우선 순위 방식 - 우선 순위를 변경할 수 있는 방식
직렬 중재 방식
중앙 집중식 직렬 중재 방식
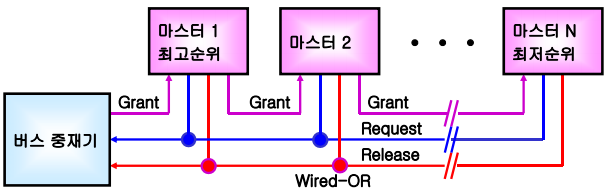
- 하나의 중재 신호선(BGNT)이 데이지-체인(daisy-chain)형태로 모든 버스 마스터들을 직렬로 연결
- 마스터들의 우선 순위는 버스 중재기를 시작점으로 하여 승인 신호선이 연결된 순서대로 정해짐
(중재기에 가까운 순서) - 어떤 마스터도 버스를 사용하지 않을 때만 버스 중재기가 승인 신호를 발생하도록 설계해야 한다.
- BUSY 신호가 해제될 때까지 버스 마스터들이 요구 신호를 보낼 수 없게 하는 설계
- 버스 요구 신호는 항상 발생시킬 수 있지만,
승인 신호를 받은 후에도 BUSY신호가 해제될 때까지는 버스를 사용할 수 없게 하는 설계
- 동작 원리
- 한 개 이상의 버스 마스터가 버스 사용을 요구하면 공통의 BREQ 신호 세트
- 버스 중재기는 데이지-체인의 첫 번째에 접속된 마스터로 BGNT 신호 전송
- 신호를 받은 마스터는 만약 버스 사용을 요구한 상태라면 사용권을 가지고,
아니라면 버스 사용을 요구한 마스터에게 도달할 때까지 다음에 연결된 마스터로 통과 - 사용권을 가진 마스터는 Bus busy line(Wired-OR)을 확인한다.
- Bus busy line이 비활성 상태 -> 마스터는 버스를 할당 받고 Bus busy line을 활성 상태로 변경
- Bus busy line이 활성 상태 -> 비활성 상태가 될 때까지 대기
분산식 직렬 중재 방식
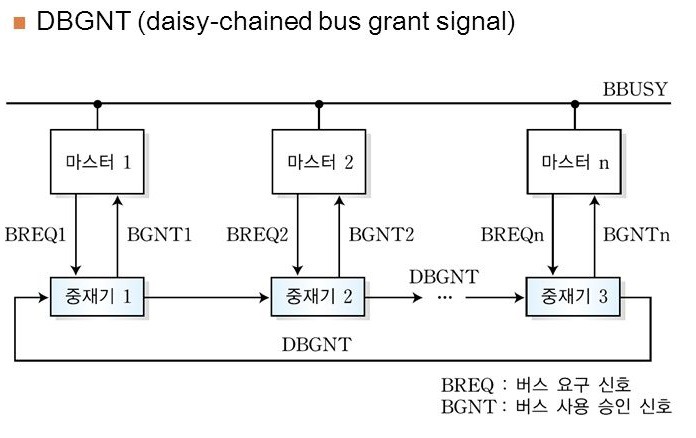
- 구성 - DBGNT(데이지 체인 버스 승인 신호)가 버스 중재기들을 순환형(circular)으로 접속
- 동작 원리
- 버스 사용권을 부여 받은 마스터가 버스 사용을 시작하는 순간 그 마스터의 중재기가
DBGNT 신호를 세트하여 자신의 바로 우측에 연결된 마스터의 중재기로 전송 - 신호를 받은 중재기의 마스터가 버스 사용을 신청한 상태였다면 BGNT 신호를 발생시켜
마스터에게 보내고, 아니라면 다음 중재기로 넘긴다.
- 버스 사용권을 부여 받은 마스터가 버스 사용을 시작하는 순간 그 마스터의 중재기가
- 특징 - 각 마스터의 우선 순위가 계속 변한다.
- 즉, 어떤 마스터가 버스 사용 승인을 받으면
그 마스터는 다음 중재 동작에서는 최하위 우선순위를 가지게 되고,
그 마스터의 바로 우측에 위치한 마스터가 최상위 우선순위를 가진다.
- 즉, 어떤 마스터가 버스 사용 승인을 받으면
- 단점 - 어떤 한 중재기에 결함이 발생하면 DBGNT 신호를 통과시킬 수 없기에
전체 시스템의 동작이 중단된다.
병렬 중재 방식
중앙 집중식 고정 우선 순위 방식
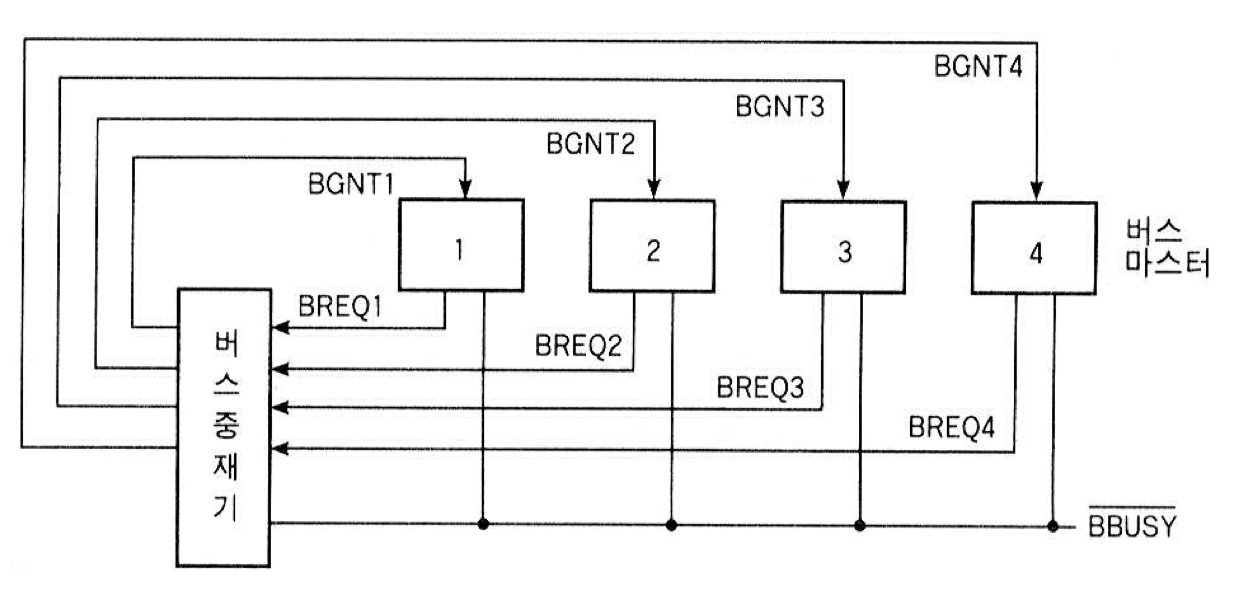
- 각 버스 마스터는 자신의 버스 요구(BREQ)선을 가지며, 이들은 모두 하나의 버스 중재기로 연결됨
- 버스 중재기는 한 개 이상의 BREQ를 받아서, 그중 우선 순위가 가장 높은 마스터에게 BGNT 신호 셋
- 동작 원리
버스 마스터 1이 버스 사용중일 때, 버스 마스터 3이 버스 사용을 요구한다고 가정- 마스터 3이 BREQ3 신호 세트
- 버스 중재기가 마스터 3에게 BGNT3 신호를 세트하여 버스 사용을 허가
- 마스터 1이 버스 사용을 끝내고 BBUSY 신호를 해제
- 마스터 3이 BBUSY 신호를 다시 세트하고 버스 사용
분산식 고정 우선 순위 방식
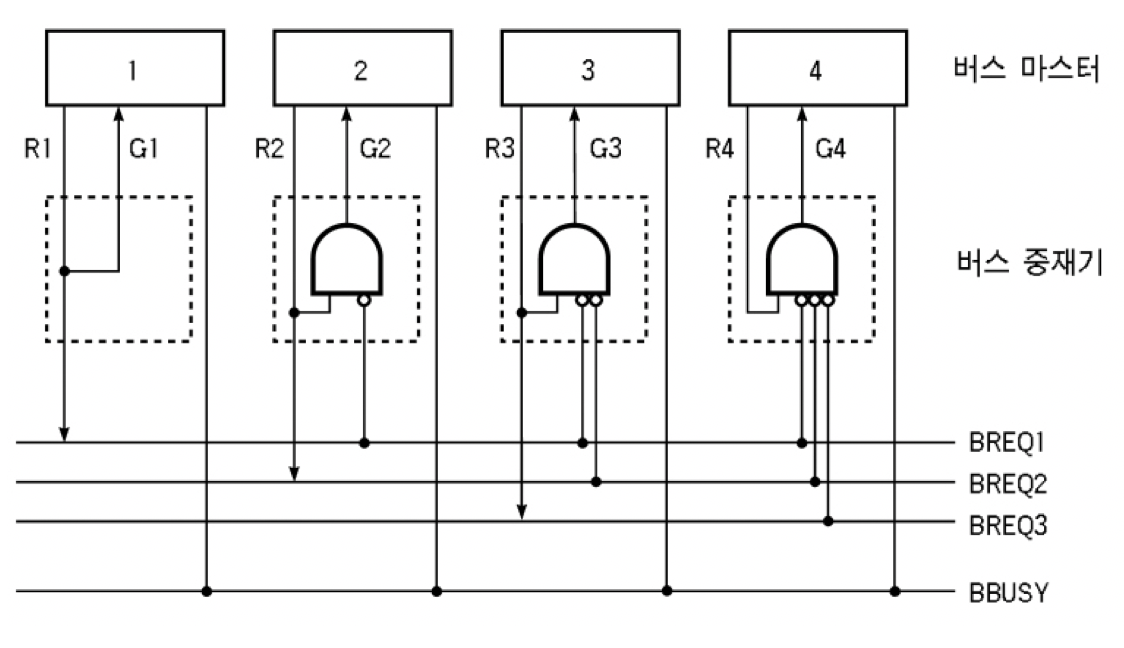
- 동작 원리
- 각 중재기는 자신보다 더 높은 우선 순위를 가진 마스터들의 버스 요구 신호들을 받아 검사하여,
그들이 버스 사용 요구를 하지 않은 경우에만 자신의 버스 마스터로 버스 승인 신호 발생 - 승인 신호를 받은 버스 마스터는 BBUSY 신호를 검사하여 활성화되지 않았을 때 버스 사용
- 각 중재기는 자신보다 더 높은 우선 순위를 가진 마스터들의 버스 요구 신호들을 받아 검사하여,
- 장점 - 중앙 집중식에 비해 중재 회로가 간단하여 동작 속도가 더 빠르다.
- 단점 - 고장을 일으킨 중재기를 찾아내기 힘들며, 한 중재기의 고장이 전체 시스템에 영향을 미친다.
가변 우선 순위 방식
- 시스템의 상태에 따라 각 버스 마스터들의 우선 순위를 계속 변화시키는 방식
- 장점 - 모든 마스터들이 공정하게 버스를 사용할 수 있다.
- 단점 - 중재 회로가 복잡하다.
- 가변 우선 순위 알고리즘
- 회전 우선 순위
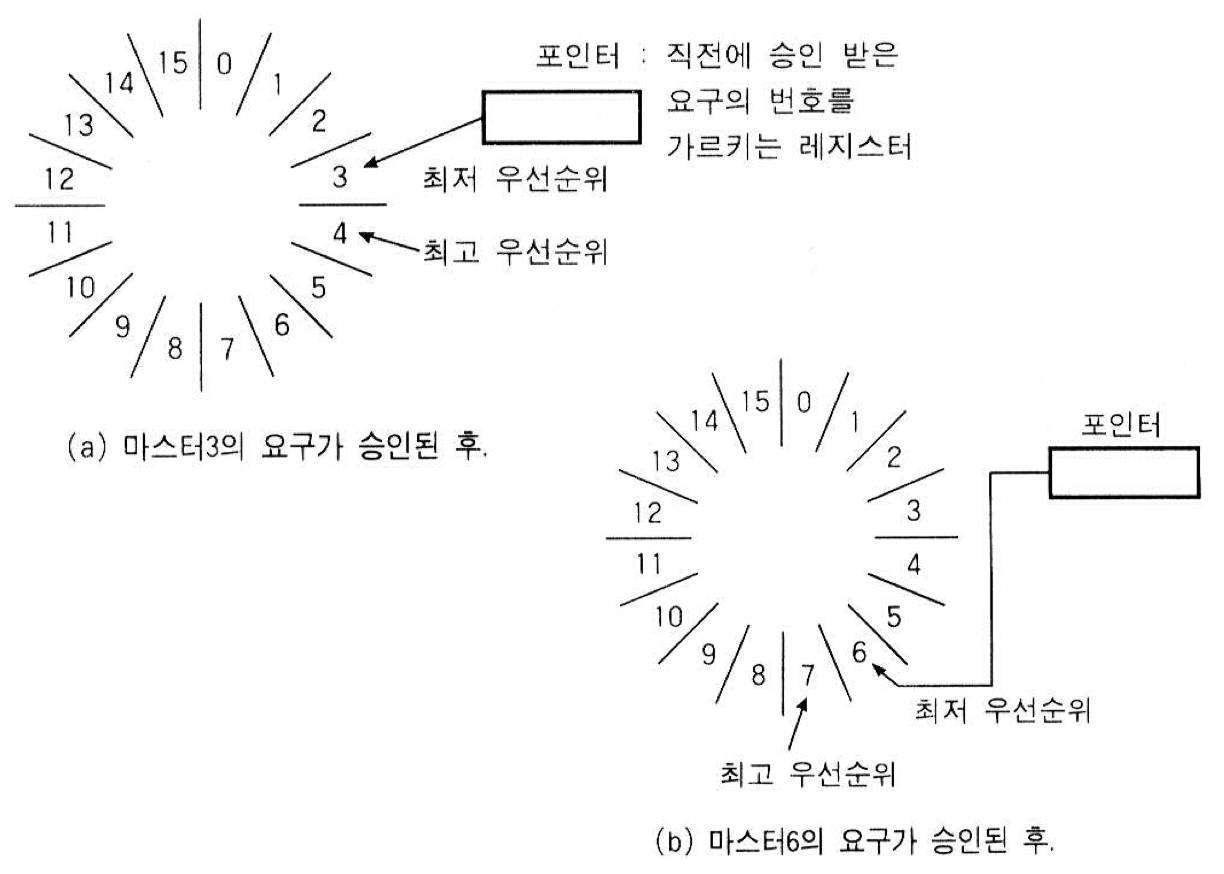
1. 중재 동작이 끝날 때마다 모든 마스터들의 우선 순위가 한 단계씩 낮아지고,
가장 우선 순위가 낮았던 마스터가 최상위 우선 순위를 가지도록 하는 방법
2. 버스 사용 승인을 받은 마스터는 최하위 우선 순위를 가지며,
바로 다음에 위치한 마스터가 최상위 우선 순위를 가지도록 하는 방법 - 임의 우선 순위 방식
- 각 중재 동작이 끝날 때마다 우선 순위를 임의(랜덤)로 결정
- 동등 우선 순위 방식
- 모든 마스터들의 동등한 우선 순위를 가지며, FIFO 알고리즘 사용
- 최소-최근 사용(Least-Recently Used: LRU) 방식
- 최근 가장 오랫동안 버스를 사용하지 않은 버스 마스터에게 최상위 우선 순위 할당
- 단점 - 회로가 매우 복잡
- 회전 우선 순위
폴링 방식
버스 중재기가 각 마스터들이 버스 사용을 원하는지를 주기적으로 검사하여 버스 승인 여부를 결정
하드웨어 폴링 방식
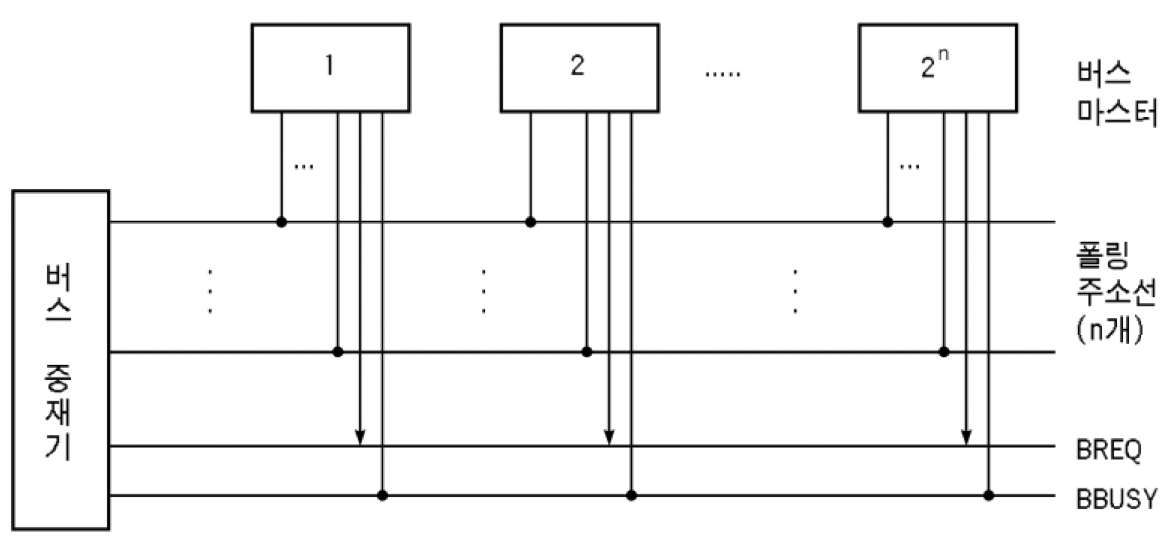
- 중재기 내의 고정된 하드웨어를 이용한 주기적 검사를 통해 중재 기능을 수행하는 방식
- 버스 중재기와 각 버스 마스터 간에 폴링 동작을 위한 폴링 선이 존재함
- 이진 코드화된 폴링 주소를 사용 -> 폴링 선의 수는
logN개 (N은 마스터의 개수) - 공통의 BREQ 선과 BBUSY 선이 각각 한 개씩 존재
- 동작 원리
- 중재기는 폴링 주소를 발생하여 검사할 마스터를 지정한 다음,
마스터가 버스 사용을 원하는지 묻는다. - 지정된 마스터가 버스 사용을 원하면 BREQ 신호를 세트하고, 중재기는 현재 검사 중인 마스터에게 버스 사용을 허가한다.
- 지정된 마스터가 버스 사용을 원하지 않으면 다음 마스터들에 대한 검사를 순서대로 진행한다.
- 중재기는 폴링 주소를 발생하여 검사할 마스터를 지정한 다음,
- 우선 순위 결정 방법
- 중재기가 마스터를 검사하는 순서에 의해 결정
- 검사할 마스터의 번호는 2진 카운터(binary counter)를 이용하여 발생
소프트웨어 폴링 방식
- 구성은 하드웨어 폴링 방식과 동일하지만
중재 동작이 고정된 하드웨어에 의해 이루어지는 게 아니라
프로그램을 실행할 수 있는 프로세서에 의해 조정되는 방식이다.- 하드웨어 방식에 비하여 속도는 느리지만, 우선 순위(폴링 순서)의 변경이 용이하다.
- 결함이 있는 마스터를 폴링에서 제외함으로써 시스템 결함 허용도를 높임
입출력(I/O)연결과 주소 지정
입출력 주소 지정
- 컴퓨터 시스템에는 다양한 입출력(I/O)장치 및 통신 포트 등이 연결된다.
이를 서로 구분하기 위해 각각의 장치에 고유한 주소를 할당한다. - 하나의 입출력 장치에 그 상태나 데이터의 입출력등 용도에 따라 다수의 주소 할당이 가능하다.
(하나의 입출력 장치에 대해 입력, 출력할 때마다 주소가 달라질 수 있다.) - 주소 지정 방법
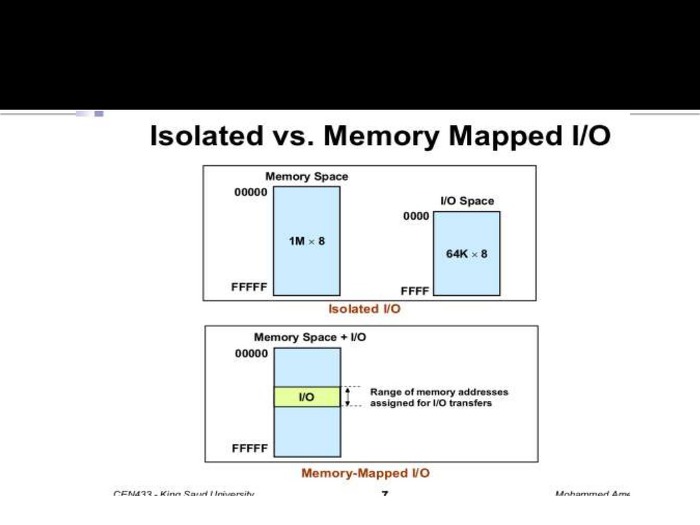
- 입출력 맵 입출력(I/O mapped I/O, isolated)
- 독립된 메모리 주소 공간과 입출력 주소 공간을 구분하여 할당한다.
- 메모리와 입출력 주소를 구분하는 제어선을 사용한다.
- 상호 구분되는 명령어가 필요하다.
(데이터에 적용되는 명령어와 입출력 장치에 적용되는 명령어는 달라야한다.) - 제어 신호를 통해 입출력에 대한 내용은 입출력 장치쪽으로,
메모리에 관한 내용은 메모리쪽으로 접근하도록 H/W적 구현이 필요하다. - I/O용 별도의 명령어와 제어선이 있는 CPU나 PC(Personal Computer, 노트북)에서 구현 가능
- 메모리 맵 입출력(memory mapped I/O)
- 메모리에 부여된 주소 공간의 일부를 입출력 주소 공간으로 활용
- 동일한 주소선과 제어선으로 입출력 관리 가능
- 시스템은 지정된 주소값에 의해 데이터 저장 공간과 I/O장치를 구분
- 모든 CPU에 대해 구현이 가능하나, 주소값에 따라 H/W적 분류 접근 구현이 필요하다.
- 입출력 맵 입출력(I/O mapped I/O, isolated)
입출력 버스 할당
- 중앙 제어 버스 시스템
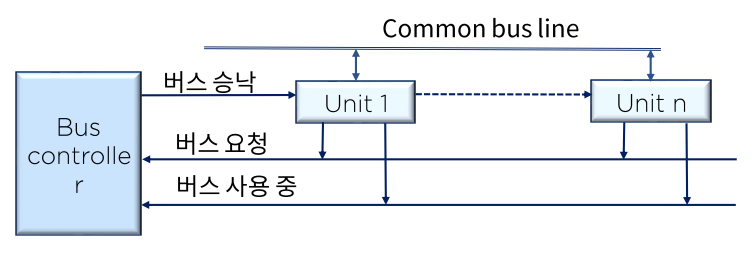
- 구현 및 관리가 용이하나 제어기의 이상시 시스템에 큰 영향을 미친다.
- I/O 버스로 활용
- 분산 제어 버스 시스템
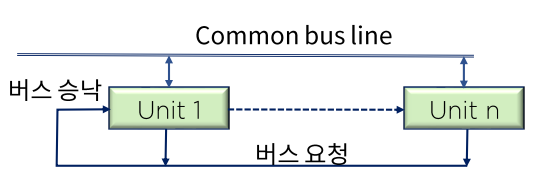
- 버스상의 모든 장치가 제어 기능을 나누어 실행한다.
- 시스템 버스로 활용
입출력 수행의 분류
- 동기 버스에 의한 수행
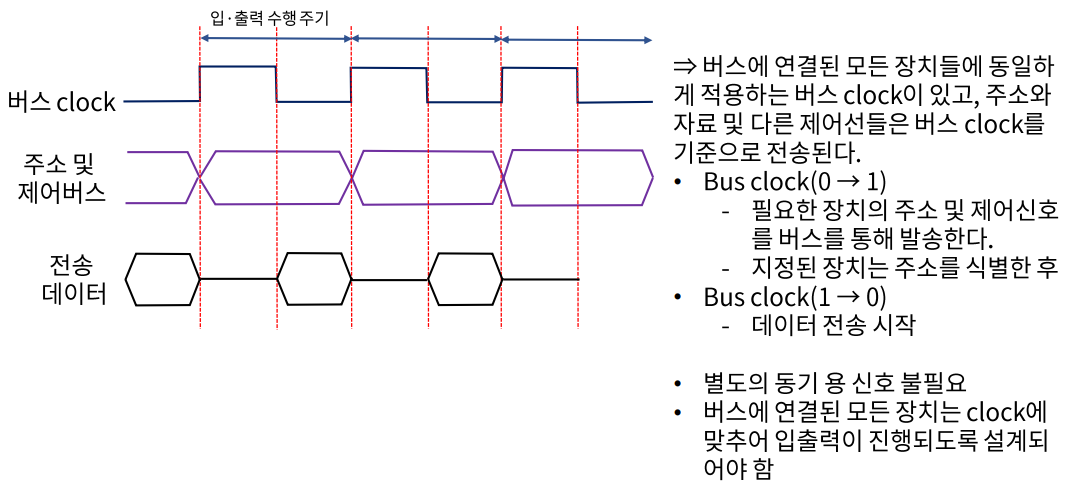
- 비동기 버스에 의한 수행
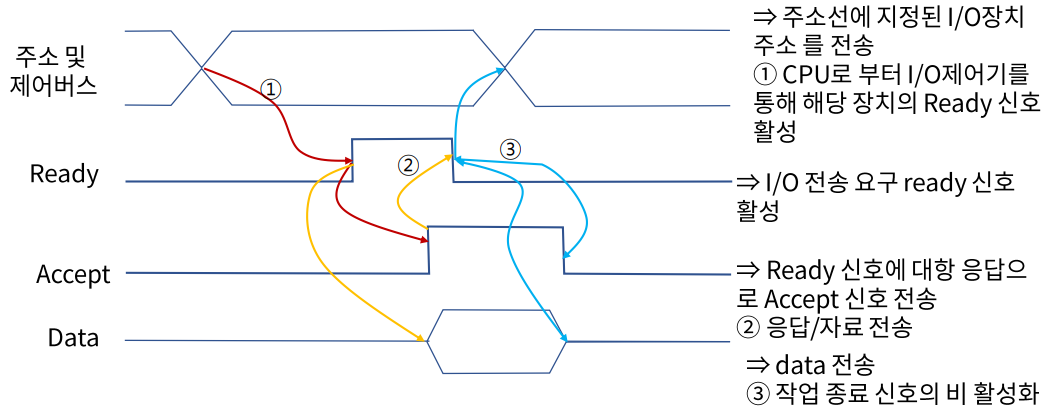
- 핸드 셰이킹 과정
- CPU가 버스 제어기(Ready)를 깨우면 버스 제어기는 데이터를 받을 장치(Accept)를 깨운다.
- Accept가 일어나서 Ready에게 준비됐다는 신호를 보내면
Ready는 Accept에게 데이터를 전송한다. - 전송이 완료되면 Ready는 CPU와 Accept에게 완료됐다는 신호를 보낸다.
입출력 수행과 인터럽트
DMA(Direct Memory Access)를 이용한 I/O
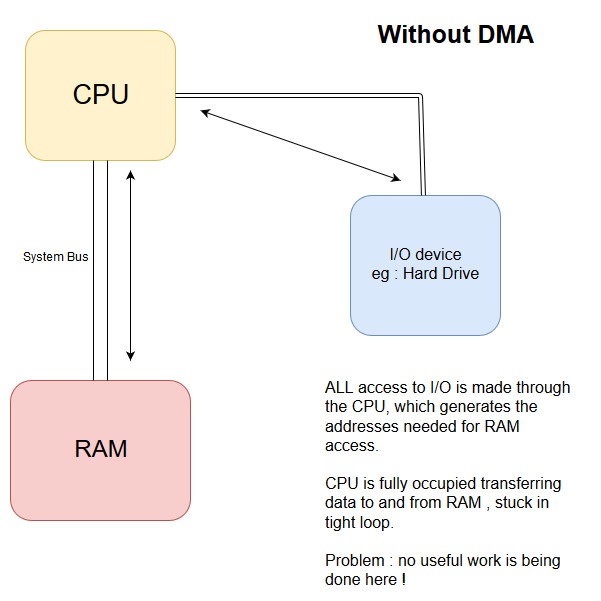
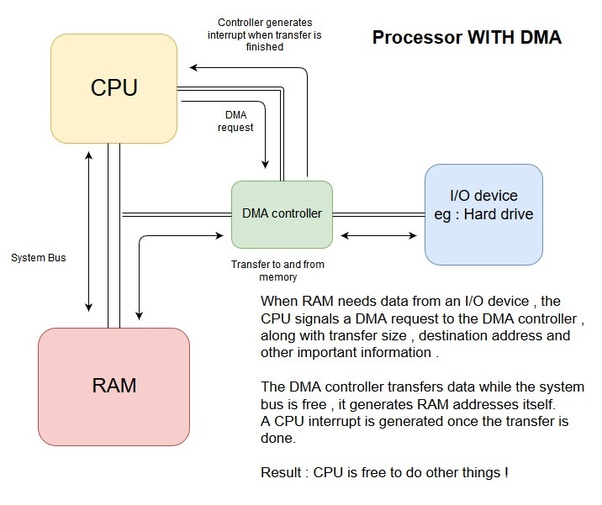
- I/O 장치가 CPU를 거치지 않고도 메인 메모리에 접근할 수 있는 메커니즘
- 동작 원리
- RAM이 I/O 장치로부터 데이터를 필요로 할 때,
CPU는 전송 크기, 목적지 주소 및 기타 중요한 정보와 함께
DMA request를 DMA controller에게 보낸다. - DMA contoller는 시스템 버스가 비어있는 동안 데이터를 전송하며,
자체적으로 램에 주소를 생성한다. - RAM에 전송이 완료되면 CPU에게 인터럽트를 보낸다.
- RAM이 I/O 장치로부터 데이터를 필요로 할 때,
인터럽트를 이용한 I/O
-
프로그램을 이용한 I/O 방식은 CPU가 I/O 작업을 기다려야 하기 때문에 시간 낭비 초래 ->
인터럽트 메커니즘을 이용함으로써, I/O 동작이 진행되는 동안에 CPU가 다른 작업을 처리할 수 있도록 하는 방식 -
동작 원리
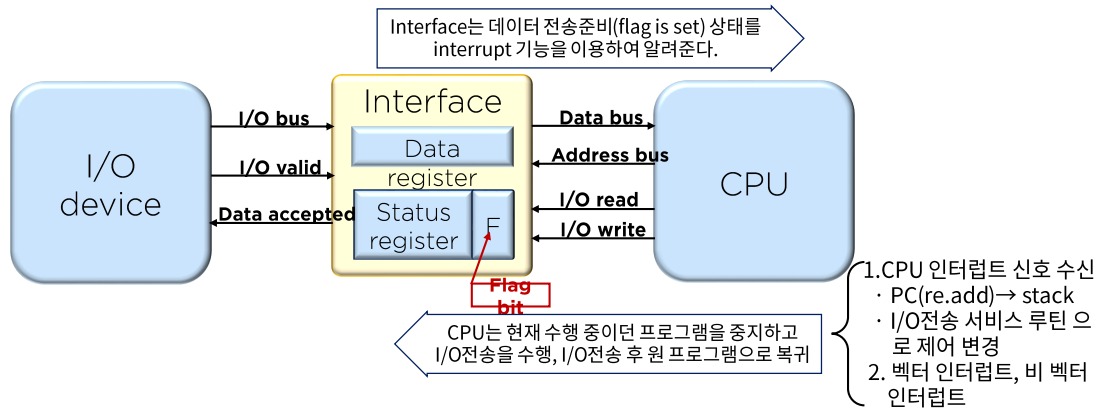
-
Interface - 입출력 통로 관리, CPU와 입출력 장치와의 매개체
- CPU가 I/O 제어기에게 명령을 전송하고, CPU는 다른 작업을 수행
- 제어기는 I/O 장치를 제어하여 I/O 명령을 수행
- I/O 명령 수행이 완료되면, 제어기는 CPU로 인터럽트 신호를 전송
- I/O bus -> data register 적재
- I/O valid -> data가 유효한지 판단한 정보
- status register가 세트 되면 Interrupt 발생 (cpu야 하던 일 멈추고 I/O부터 처리해줘)
- CPU는 인터럽트 신호를 수신하면 현재 작업하던 내용 (pc가 가리키는 주소)를
stack에 저장하고 I/O 전송 처리 - 원 프로그램 복귀
인터럽트 I/O 구현 방법
-
다중 인터럽트 방식
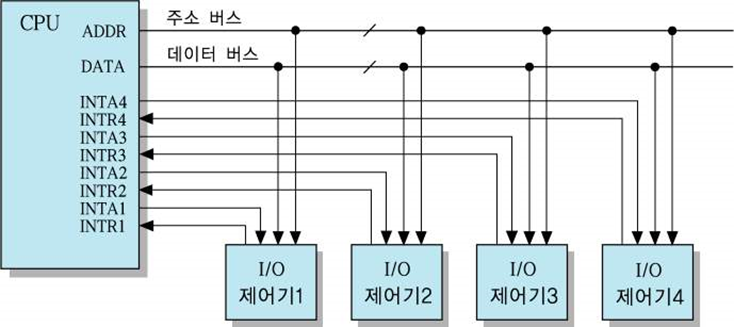
- 각 I/O 제어기와 CPU 사이에 별도의 인터럽트 요구(INTR)선과 인터럽트 확인(INTA)선을 접속하는 방법
- 두 개 이상의 I/O 장치들이 동시에 인터럽트 요구 신호를 보내는 경우,
각 I/O 장치에 대하여 우선 순위를 정하고, 더 높은 우선 순위를 가진 장치의 인터럽트 요구부터
INTA를 보내고 서비스한다. - 동작 원리
I/O 제어기2가 인터럽트를 요구하는 경우의 동작 순서
- I/O 제어기2가 INTR2 신호를 세트
- CPU는 INTA2 신호를 세트함으로써 그 제어기에게 인터럽트 요구를 인식하였음을 알리고,
인터럽트를 위한 서비스 시작 - I/O 제어기2는 INTR2 신호를 해제(0으로 리셋)
- CPU도 INTA2 신호를 해제
- 장점 - CPU가 인터럽트를 요구한 장치를 쉽게 찾아낼 수 있다.
- 단점 - 하드웨어가 복잡하다.
-
데이지-체인 방식
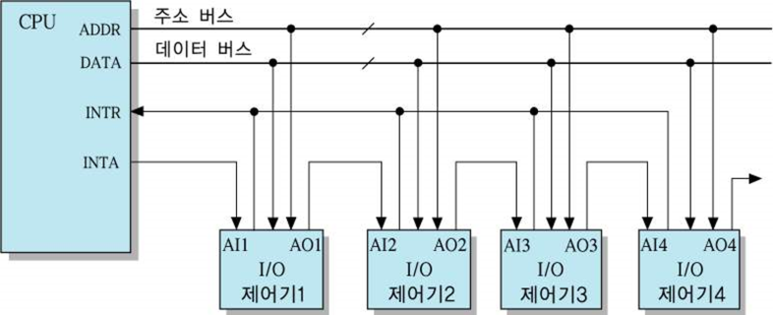
- CPU로부터 발생되는 INTA 출력 선을 I/O 제어기들에 직렬로 접속(데이지 체인)하는 방식
- INTA는 첫 번째 I/O 제어기로 보내진다.
- 만약 그 제어기가 인터럽트를 요구한 상태라면,
즉시 데이터 버스를 통해 자신의 ID(인터럽트 벡터)를 CPU에 보낸다. - 인터럽트를 요구한 상태가 아니라면, 확인 신호를 다음 제어기로 통과시킨다.
- 만약 그 제어기가 인터럽트를 요구한 상태라면,
- 장점 - 하드웨어가 간단하다.
- 단점 - 우선 순위가 낮은 장치들이 서비스를 받지 못하고
매우 오래 기다려야 하는 경우가 발생 가능
-
소프트웨어 폴링 방식
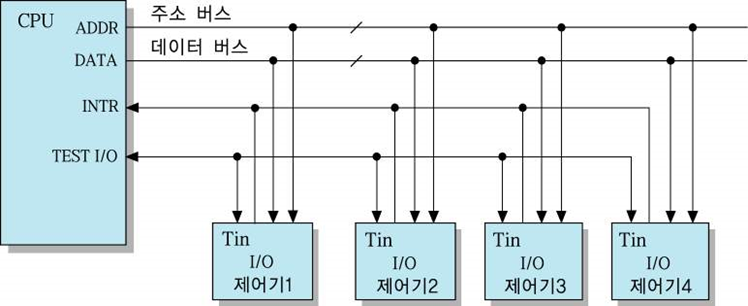
- CPU가 모든 I/O 제어기들에 접속된 TEST I/O 선을 이용하여
인터럽트를 요구한 장치를 검사하는 방식 - 데이지-체인 방식과 같은 방식이지만 그 역할을 소프트웨어가 수행한다는 점에 있어서 다르다.
- 장점 - 우선 순위의 변경이 용이
- 단점 - 처리 시간이 오래 걸림
- CPU가 모든 I/O 제어기들에 접속된 TEST I/O 선을 이용하여
-
병렬 우선 순위 인터럽트
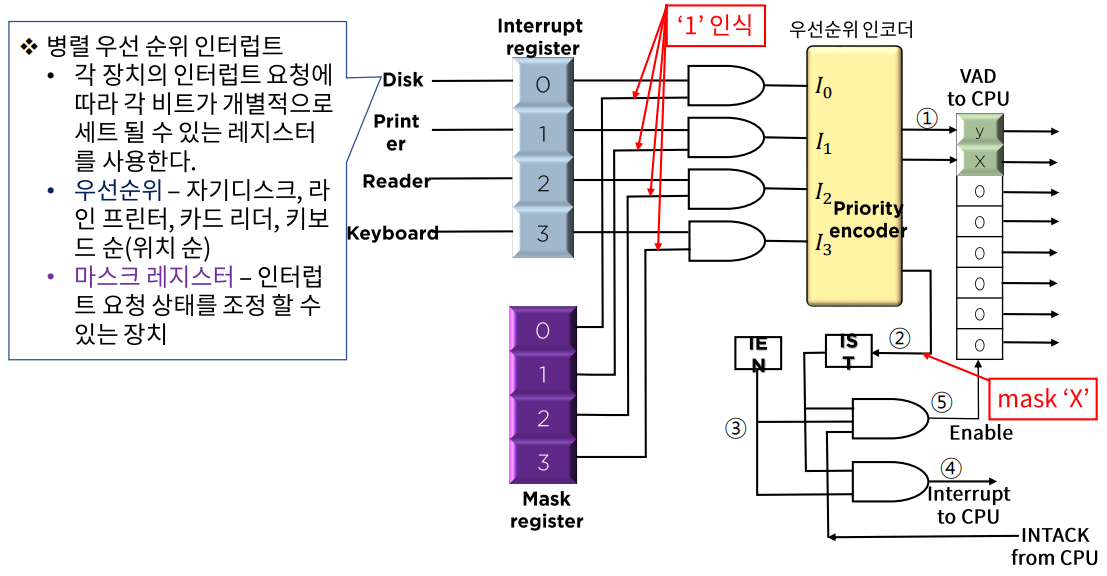
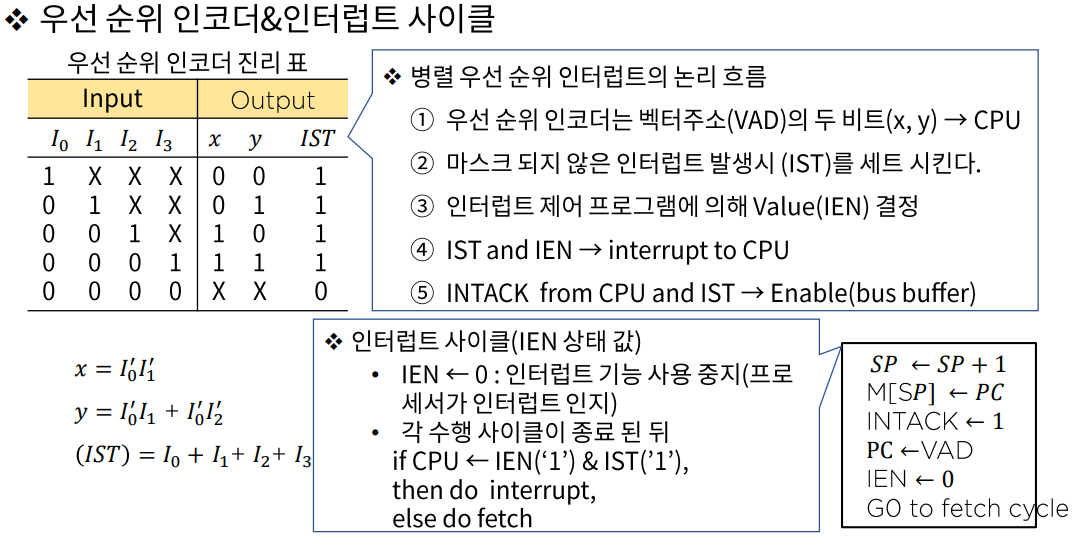
- 인터럽트 사이클
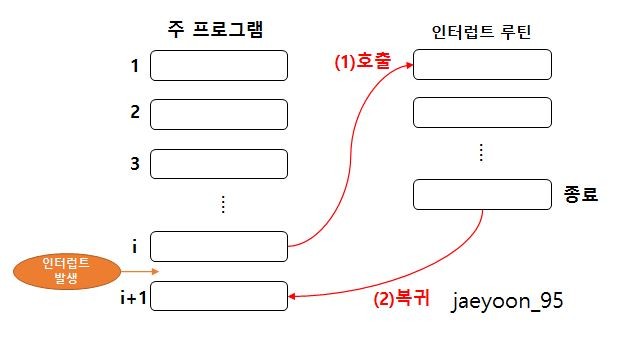
- 동작 원리
- 현재의 PC값을 스택에 저장(복귀할 주소 저장)
- 해당 인터럽트 루틴의 시작 주소를 PC에 적재
- 마이크로 연산
t0:MBR <-- PC
t1:MAR <-- SP, PC <-- ISR의 시작주소 (SP: Stack Pointer, ISR: Interrupt Service Routine)
t2:M[MAR] <-- MBR, SP <-- SP-1
출처 - https://m.blog.naver.com/jaeyoon_95/221054395900
- 동작 원리
- 인터럽트 사이클
입출력 장치와 CPU간 전송에 대한 소프트웨어적 고찰
- 컴퓨터는 주변 장치와의 인터페이스를 위한 H/W 못지 않게 S/W 루틴을 가져야 한다.
- 주변 장치 제어
- 입출력 장치, 메모리 장치, 네트워크 장치 등등
- 프로세서(CPU)와 주변 장치 사이에 데이터 전송
- 주변 장치의 주소값을 알아야 하고 그 주소값의 데이터를 stack에 저장하는 등의 로직
- 주변 장치 제어
- I/O routine은 주변 장치의 활성화를 위한 제어 커맨드(인터럽트)의 발송 및
데이터 전송을 위한 준비 상태(status register)체크 로직을 보유해야 한다. - 입출력 장치는 시스템에게 '나 입출력 할거야 준비해!' 라고 명령할 수 있어야하고(인터럽트)
명령을 실행할 주변 장치에 해당 로직(커맨드)이 있어야 한다. - DMA(Direct Memory Access)전송 시 I/O 소프트웨어는 DMA 채널을 개시시킬 수 있어야 한다.
입출력 장치와 CPU간 인터럽트 논리
- CPU와 I/O 장치 사이의 데이터 전송은 CPU에 의해 시작된다.(모든 논리는 CPU로부터 시작)
- 각 장치는 통신 준비 여부(I/O bus, I/O valid, Data accepted)에 따라 CPU와 통신이 가능
- 시스템 퍼포먼스를 위해 각 디바이스 인터페이스는
플래그가 enable 됐을 때 CPU에 인터럽트 요청
- 프로세서가 분기 주소를 선택하는 방법
- vectored interrupt
- 인터럽트를 내는 소스가 프로세서에게
분기에 대한 정보(인터럽트 벡터)를 제공한다.
- 인터럽트를 내는 소스가 프로세서에게
- Non-vectored interrupt
- 분기 주소는 메모리의 고정 위치에 저장되어 있다.
- vectored interrupt
- 수많은 장치 중 인터럽트가 발생한 장치 선별,
동시에 발생한 다수개의 인터럽트의 경우 우선 순위를 결정해야한다.(우선 순위 인터럽트)- 우선 순위 결정은 소프트웨어(운영체제) * 하드웨어(LRU)적으로 처리
- 소프트웨어적으로 인터럽트 우선 순위를 결정하는 방법 -> 폴링
- 각 장치의 인터럽트를 주기적으로 확인
- 소요 시간이 길다.
시스템의 병렬 처리와 멀티 프로세서
병렬 처리
Serial process system vs Parallel process system
- Serial Process system
- 현재까지 설명되고 논의 대상이던 CPU가 하나 뿐인 시스템
- 과학, 계산, 네트워크 등 컴퓨터 처리 전 분야에 걸쳐
더 나은 성능 개선 요구가 제기되고 있지만,
기계적, 논리적 프로세싱(사람의 사고 - 순차적인 생각, 융통성)으로는 가장 효율적이다.
- Parallel Process system
- 동시에 여러 명령 또는 여러 작업을 실행할 수 있는 시스템
- 병렬 처리 시스템이 가능한 시스템을 병렬 구조라 한다.
- 병렬 처리 시스템 구현 기술의 일환인
병렬 처리 소프트웨어(병렬 운영체제, 병렬 컴파일러, 메모리 공유 등)가 발전하고 있다. - 다중 장치 구조
- 다수의 CPU로 동시에 여러 개의 작업을 병렬로 처리할 수 있는 시스템
- MIMD
- 공간적 병렬성(spatial parallelism)
- 파이프라인 구조
- 한 개의 CPU로 다수의 작업을 각기 다른 실행 단계에서 병렬로 처리할 수 있도록 지원되는 구조
- 시간적 병렬성(temporal parallelism)
멀티 프로세서
멀티 프로세서의 특징
- 메모리와 I/O 장치를 공유하는 두 개 이상의 CPU를 갖는 시스템을 말한다.
- MIMD 시스템으로 분류
- 멀티 프로세서 시스템에서는 하나의 운영체제에 의해 프로세서들간의 상호 동작이 제어되며,
동일한 문제의 해결을 위해 모든 요소들이 협력한다. (!= 멀티 컴퓨터) - 시스템의 신뢰성 향상을 위한 멀티 프로세서의 동작 원리
- 다수의 독립적인 작업들이 병렬적으로 처리될 수 있다.
- 하나의 작업이 여러 부분으로 나뉘어 각각 병렬적으로 처리될 수 있다.
- 사용자가 명시적으로 병렬 실행이 가능한 작업을 선언(ex) 자바와 c#의 쓰레드)
- 컴파일러가 자동적으로 프로그램의 병렬성을 감지해 처리(RISC 컴파일)
멀티 프로세서의 분류
- 밀접 결합 시스템(tightly coupled multiprocessor) 또는 공유 메모리(shared-memory)
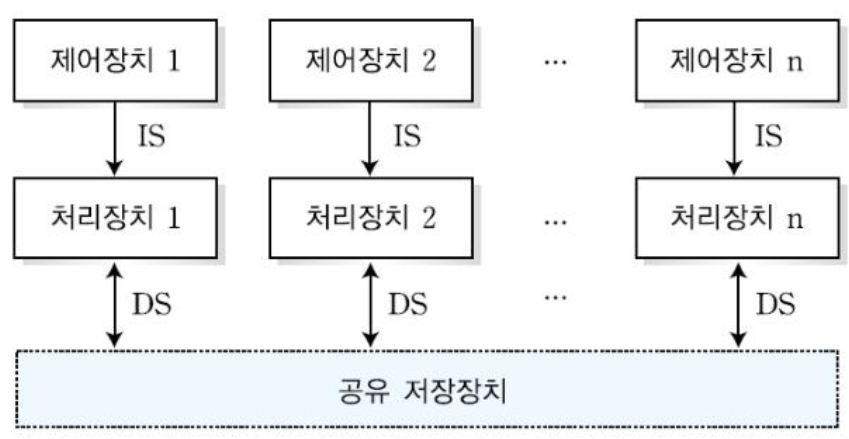
- 모든 처리 장치가 공유된 기억 장치를 이용하여 통신하는 다중 프로세서 시스템
- 느슨 결합 시스템(Loosely coupled multiprocessor)
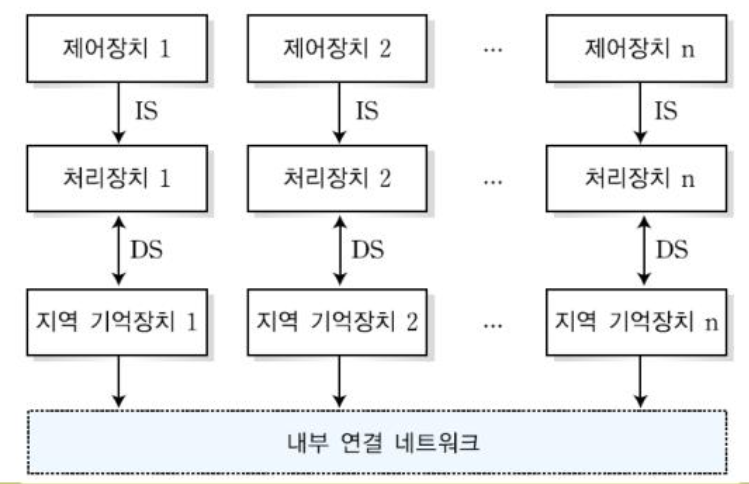
- 각 처리 장치는 지역 기억 장치를 가진 독립적인 컴퓨터 모듈로 구성되며,
처리 장치간의 통신은 내부 연결 네트워크를 통해서 메세지 전송 방식을 이용한다.
- 각 처리 장치는 지역 기억 장치를 가진 독립적인 컴퓨터 모듈로 구성되며,
- Distributed memory
- 느슨 결합 구조로서 각 프로세서가 자신의 지역 기억 장치를 소유하고,
다른 프로세서들과의 통신은 메세지 전송을 이용한다. - 공유 자원의 경합이 감소하지만
메세지 전송을 위한 통신 프로토콜 때문에 지연 시간이 증가한다.
- 느슨 결합 구조로서 각 프로세서가 자신의 지역 기억 장치를 소유하고,
상호 연결 구조
- 멀티 프로세서 시스템은 CPU, IOP(I/O Processor) 그리고 여러 모듈로 분리된 메모리 장치에 의해 구성된다.
- 공유 메모리 시스템 - 프로세스와 메모리 사이의 경로 수에 따라 물리적으로 다른 특성을 보인다.
- 느슨히 결합된 시스템 - 프로세스 요소들 사이의 전송 경로 수에 따라 물리적으로 다른 특성을 보인다.
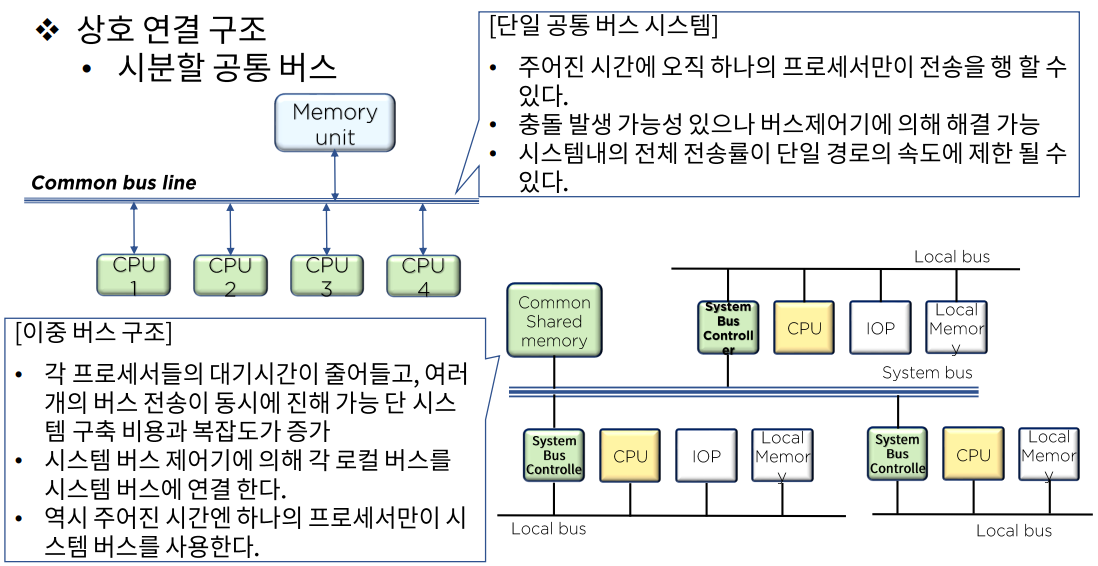
- 시분할 공통 버스
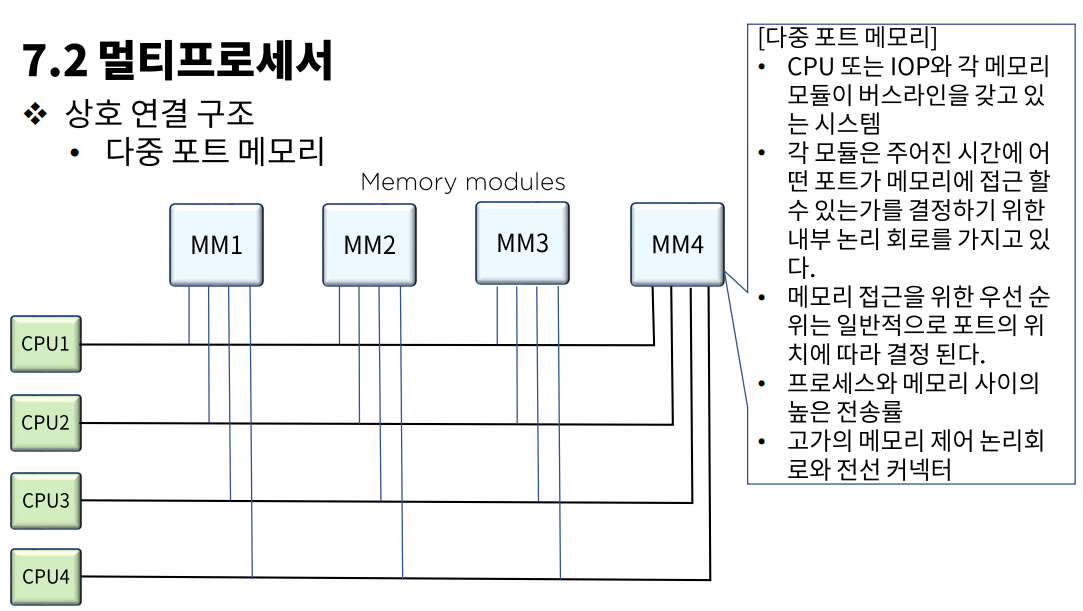
- 다중 포트 메모리
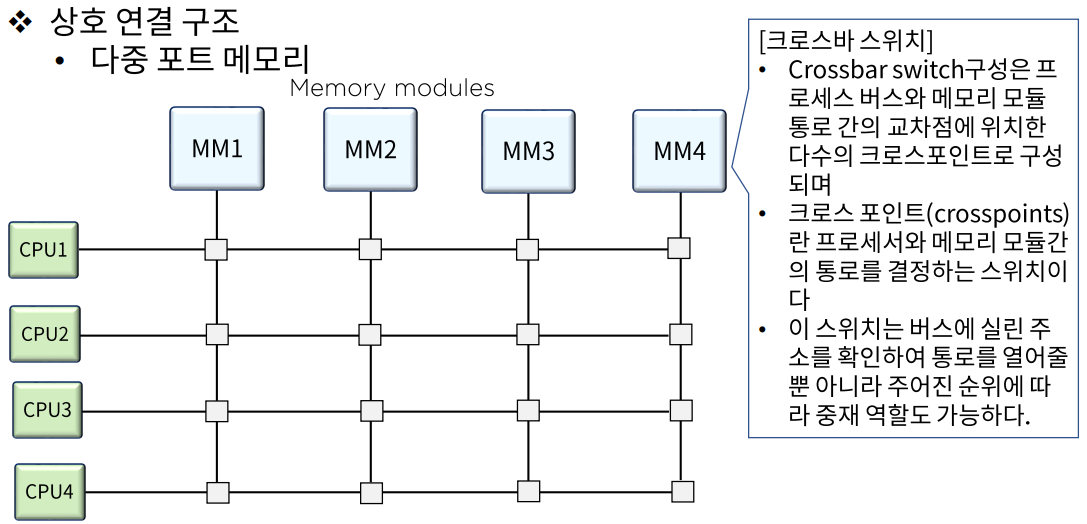
- 크로스바 스위치
- 다단 교환망
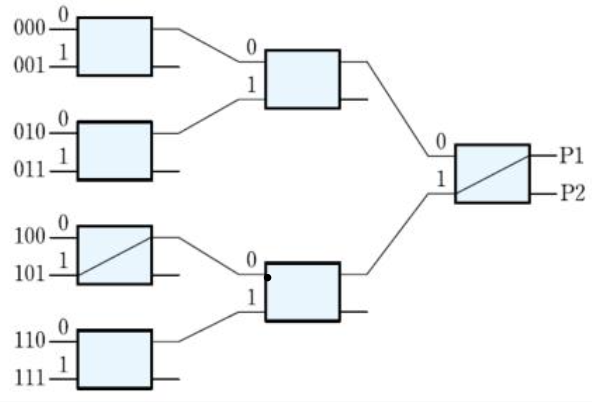
- 두 개의 입력과 두 개의 출력을 갖는 스위치를 이용하여,
단계별로 연결을 구성한 방식 - 다중 프로세서의 요소들이 다단 교환망에 상호 연결되어 통신을 수행하며,
통신 경로가 하나 이상 존재한다. - 그래서 한 경로가 블로킹되어 연결할 수 없더라도
다른 경로를 경유해 연결할 수 있다. - 전달되는 메세지가 여러 단계를 통해 전달되어 제어 체계가 복잡하다.
- 이 방식은 느슨 결합 형태에서 사용된다.
- 두 개의 입력과 두 개의 출력을 갖는 스위치를 이용하여,
- 하이퍼큐브 상호 연결
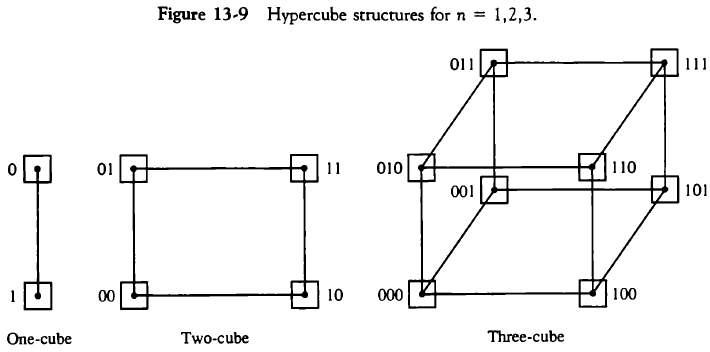
- 프로세서
2^N개가N차원 이진 큐브로 연결되고 느슨 결합 시스템에서 사용한다. - 각 프로세서는 큐브의 노드를 형성하는데
노드에는 CPU, 로컬 메모리, I/O 인터페이스 등등이 있다. - 다수의 프로세서를 효과적으로 연결시킬 수 있으며
인접한 번지는 한 비트만 차이가 나는 장점이 있다.
- 프로세서
시스템 성능 분석과 개선
프로세서간 중재
시스템 버스 vs 로컬 버스
- 컴퓨터 시스템에는 각 요소들 사이의 정보 전송을 위한 다양한 단계의 여러 버스가 존재하며
CPU내에서도 레지스터와 ALU사이의 정보 전송을 위한 여러 내부 버스가 존재한다. - 시스템 버스(System bus) -> CPU, IOP, Memory와 같은 주요 요소를 연결하는 연결 체계
- 로컬 버스(Local bus) -> 메모리 버스(데이터, 주소 그리고 읽기/쓰기 정보 전송),
I/O 버스(입출력 장치로 정보 전송),
통신 전용 버스(특정 포트 정보, 해당 프로토콜 정보 등을 송/수신) - 공유 메모리 프로세서 시스템에서 각 자원의 효율적 분배와 상호 충돌을 배제하는
중재 프로세스는 전체 시스템 성능 향상에 많은 영향을 미친다.
메모리 공유 멀티 프로세서를 위한 시스템 버스 구조
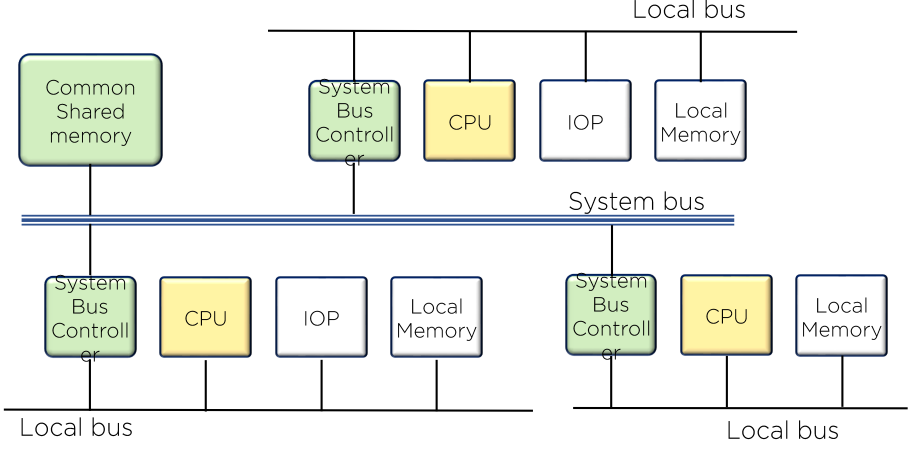
중재 알고리즘
- 일반적으로 시스템 버스는 100여개의 신호라인으로 구성되고
이 명령 라인에 의해 중재 논리가 성립된다. - 직렬(데이지 체인) 중재 절차
- 병렬 중재 논리
- 동적 중재 논리
프로세서간 통신과 동기화
프로세서 간 통신
- 멀티 프로세서 시스템에 있는 다양한 프로세서들은
공통의 입출력 채널을 통하여 서로 통신한다. - 공통 메모리의 역할
- 공유 메모리 멀티 프로세서 시스템에서
메모리의 일부를 모든 프로세서가 접근할 수 있도록 할당한 공간 - 수신 프로세서의 폴링 방식 -
프로세서의 나열된 순서대로 각 송신 프로세서를 주기적으로 점검(요구, 메세지) - 인터럽트 신호를 통한 송신 프로세서 <-> 수신 프로세서 방식이 더 효율적이다.
- 공유 메모리 멀티 프로세서 시스템에서
- 멀티 프로세서를 위한 운영체제의 종류
- 주종(master-slave) 모드
- 주(master)프로세서(OS 기능 수행) <- 종(slave)프로세서는 필요에 의한 인터럽트 요청
- 분리 운영체제(seperate operating system)
- 모든 프로세서가 자신의 운영체제를 가지고 운영된다.
이는 느슨한 결합 시스템에 적합한 형태이다.
- 모든 프로세서가 자신의 운영체제를 가지고 운영된다.
- 분산 운영체제(distributed operating system)
- OS의 특정 기능은 한 순간에 하나의 프로세서에서만 작동된다.
- 즉 운영체제가 여러 프로세서에 분산되어 있는 형태이다.
- 주종(master-slave) 모드
- 동기화의 필요성
- 처리될 작업들간의 정확한 순서 유지
- 공용의 기록 가능한 변수에 대해 상호 배제적 접근 보장
ex)B가 공용 변수일 때 P1이A + B를 연산하고 P2가++B + C를 연산하고
P3가B + D를 연산할 때 P2가 B변수를 증감시켰기 때문에 상호 배제가 깨져버림. - 하드웨어적 접근 방법인 이진 세마포(semaphore)를 이용해 동기화 하는 방법이 있다.
Cache 관련 정책
- Cache의 일관성(cache coherence)
- 공유 메모리 멀티 프로세서 시스템에서도 각 프로세서는 로컬 메모리를 운영한다.
- 이 때 여러 개의 동일한 내용이 주기억장치나 각 로컬 메모리에
복사본으로 중복되어 저장되는 경우가 발생할 수 있고 정확한 메모리 동작을 위해
이 내용들이 모두 동일하게 유지되어야 한다는 정책이다.
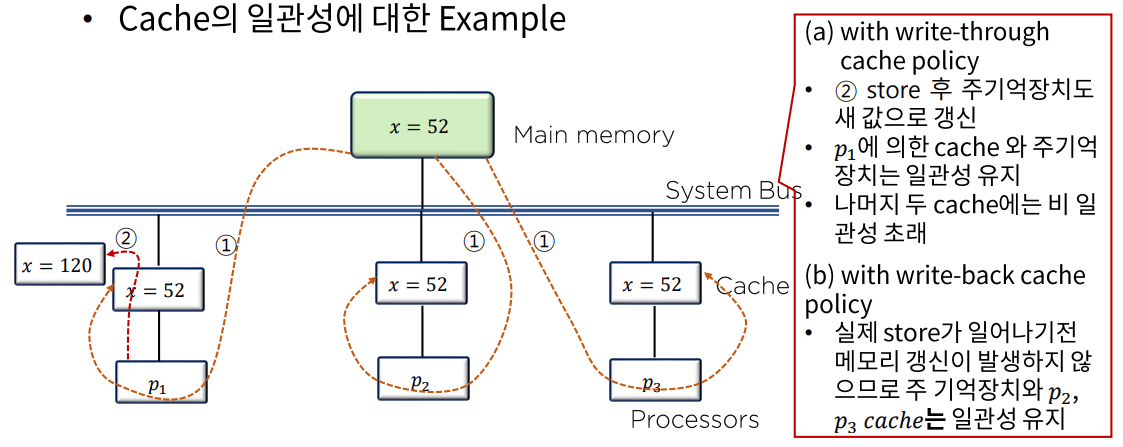
- 메모리에 쓰기 동작 시 메모리 갱신 정책
- write-throuth 정책
- 쓰기 동작의 발생 시 cache와 주 기억장치 모두 갱신
- write-back 정책
- Cache만 갱신하고 다음에 메모리로 전달할 수 있도록 데이터 위치를 표시
- write-throuth 정책
cache의 비 일관성에 대한 조건
- cache의 일관성 문제는 각 프로세스별로 개별적인 cache를 가진 멀티 프로세서에서
공통의 기록 가능한 데이터가 필요하기 때문에 발생
cache의 일관성 문제에 대한 해결책
- 각 프로세서에 개별적인 cache를 허용하지 않고
주 기억장치에 공용 cache 메모리를 두는 경우 - 근접성 원리에 위배, 평균 접근 시간을 증가시킨다. - 캐시 가능(cacheable)
- 읽기 전용 데이터에 한해서 cache에 저장되도록 하는 방안
- 스누피 캐시 제어기(snoopy cache controller)
- 기본적으로 버스에 부착된 모든 cache에 대해 버스-감시 기능을 유지하도록 설계된 H/W 장치
- 다른 캐시 쓰기 발생 시 자기 정보 무효화
- Write Through 캐시 수정 -> 메모리 갱신
- Write Back 캐시 수정 -> 메모리 갱신 x
일기
컴퓨터 구조 겨우 끝냈다...
강의 보는 시간보다 블로그로 output 하면서 정리하는 시간이 훨씬 많이 걸렸다.
이 글만 해도 10시간 쏟아낸 듯하다.
일단 패캠 강의가 너무 겉핥기 식으로 알려주기 때문에 이해가 잘 안 가고
더 궁금한 부분들은 구글링해서 채워 넣었다.
이 지식들이 앞으로 배울 운영체제와 추후에 컴퓨터 구조를 제대로 공부할 때 탄탄한 기반 지식이 되었으면 좋겠다.
계속 나아가자.

함수형 프로그래밍, 자바스크립트에 관심이 많습니다.