파이프라인 구조 - 산술&명령어 파이프 라인
현실적 파이프라인 구조
파이프라인 구조 VS 병렬적 다중 기능 장치
-
실제 파이프라인 구조가 이론적인 최대 속도를 구현하지 못하는 이유
- 각 세그먼트들이 부연산을 수행하는 시간이 서로 다르다.
- 또한 각 레지스터를 제어하는 클럭 사이클은 최대 전파 시간을 갖는 세그먼트의 지연 시간과 싱크를 맞추어야 한다. (제일 느린 시간에 맞춰야한다. 싱크를 맞추지 않을 경우 수행되지 않은 작업의 결과를 가져와야 하는 경우가 생김)
-
다음 그림과 같이 병렬적인 다중 기능 장치(파이프라인 처리 속도와 같다고 가정)를 고려할 수 있다.
- 각 P회로는 전체 파이프라인 회로에서와 동일하게 태스크를 수행한다.
- 그러나 이 구조는 순차적 처리가 아니라 모든 회로가 동시에 데이터를 입력받아 네 태스크를 한꺼번에 수행한다. - SIMD(Single Instruction Multi Data) 구조일 뿐
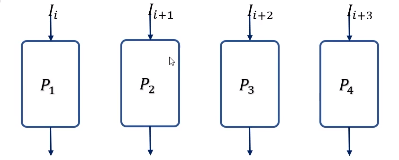
파이프라인 구조가 적용되는 컴퓨터 설계
- 산술(arithmetic) 파이프라인
- 산술 연산들을 부연산으로 나누어 파이프라인의 세그먼트에서 수행
- 고속 컴퓨터에서 부동 소수점 연산, 고정 소수점 수의 곱셈, 과학 계산용으로 활용
- 파이프라인 승산기(배열 승산기 - 부분 곱 사이의 캐리(carry)전파시간의 최소화를 위한 가산기 보유)
- 명령어(instruction) 파이프라인
- 명령어 사이클의 fetch, 디코드, 실행 단계를 중첩 시킴으로 명령어 흐름에 동작
산술 파이프라인
부동 소수점 덧셈과 뺄셈을 위한 파이프라인
정규화 (Normalize) - 가수 부분은 항상 0으로 시작하게 맞춰주는 작업
- 입력: 두 개의 정규화된 부동 소수점 이진수
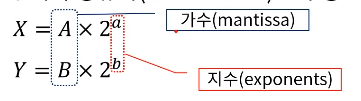
- 각 세그먼트에서 수행되는 부연산
- 지수의 비교
- 가수의 정렬
- 가수의 덧셈이나 뺄셈
- 결과의 정규화
예시
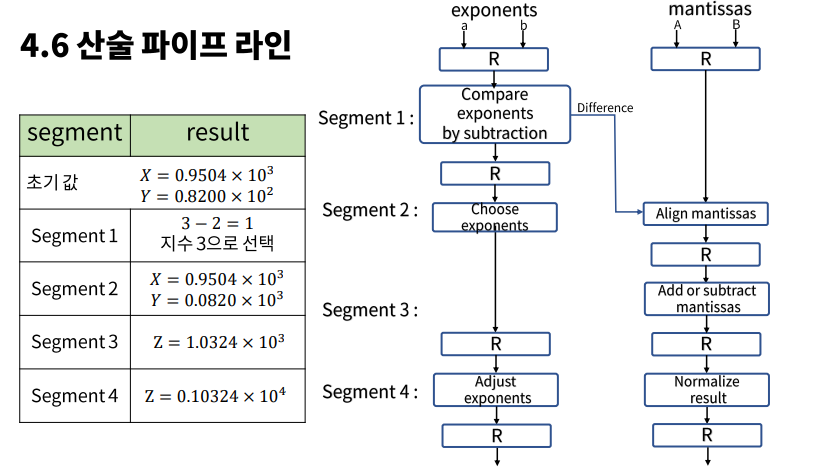
산술 파이프라인의 효율성
- 부동 소수점 파이프라인의 구성 요소
- 비교기, 시프터, 가산-감산기, 인크리멘터, 디크리멘터 -> 조합회로
명령어 파이프라인
명령어 실행과 파이프라인 구조
- 명령어 파이프라인은 이전 명령어가 다른 세그먼트에서 실행되고 있는 동안 메모리에 연속적으로 저장되어 있는 다음 명령어를 읽어옴으로써 fetch와 실행이 중첩되어 동시에 수행되는 구조
- 분기가 발생할 경우 (가장 큰 취약점)
현재의 파이프라인은 모두 비워져야 하고, 분기 명령 이후에 메모리에서 읽어온 명령어는 모두 무시되어야한다.
효율적 명령어 실행을 위한 파이프라인 구조
- 명령어 fetch장치와 명령어 실행 장치로서 두 세그먼트 파이프라인을 구성하는 컴퓨터를 고려
- 명령어 fetch 장치 -> FIFO에 의한 Queue로 구성 되어 queuing기법에 의한 메모리 참조에 의해 평균 메모리 접근 시간을 효과적으로 줄여줌
- 명령어 파이프라인이 수행되는데 있어 발생하는 애로사항
- 세그먼트의 수행시간이 서로 다름
- 두 개 이상의 세그먼트에 의해 동일한 주소 공간이 참조되는 경우(충돌, Dead lock)
네 세그먼트 명령어 파이프라인의 플로우
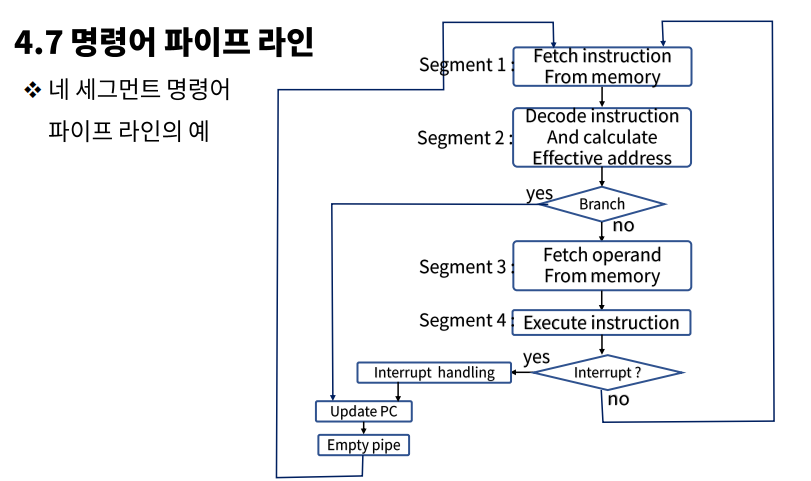
명령어 파이프라인의 시간 관계
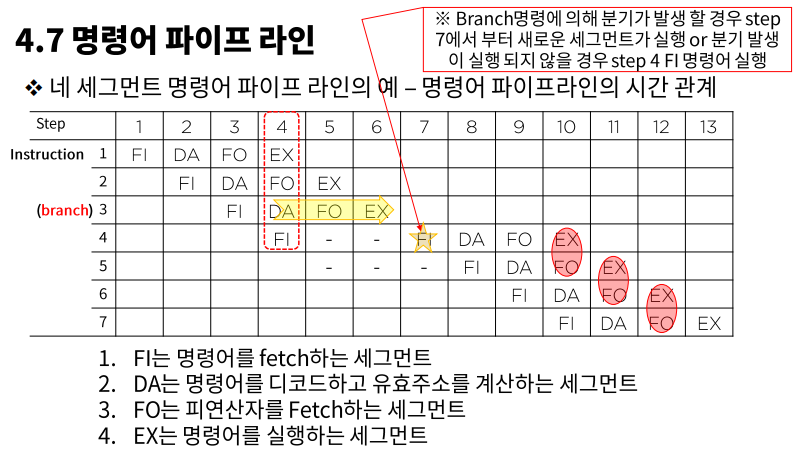
- 분기가 발생할 경우 아무 일도 하지 않는 시간이 생긴다.
- 10번째 step에서부터 FO는 이전 세그먼트의 EX의 결과값에 의존한다.
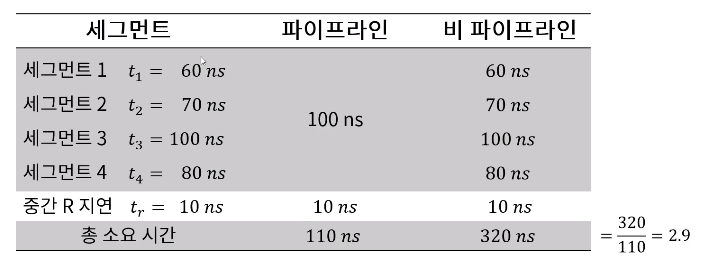
파이프라인 CPU의 성능 분석
파이프라인 분기 예측
명령어 파이프라인이 정상적인 동작에서 벗어나게 되는 요인
-
자원 충돌(Resource conflict)
두 세그먼트가 동시에 메모리에 접근하려고 하는데서 기인하는데,
명령어 메모리와 데이터 메모리를 분리함으로써 대부분 해결할 수 있다. -
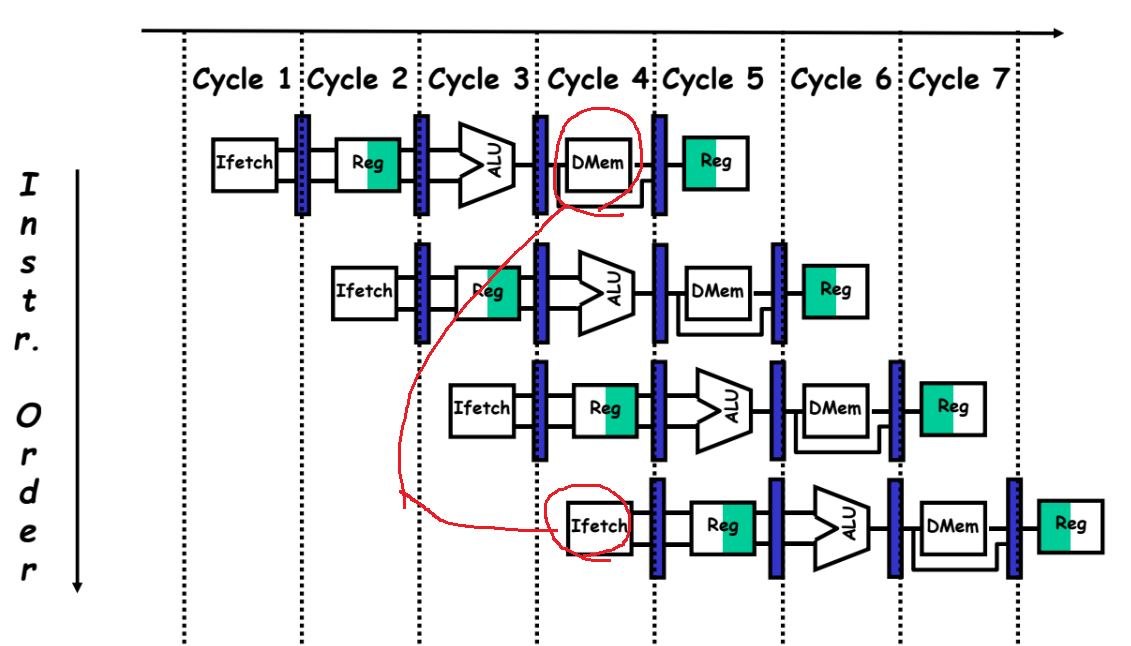
데이터 의존성(data dependency)
어떤 명령어가 이전 명령어의 결과에 의존하여 수행되는데,
그 값이 아직 준비되지 않은 경우에 발생한다. -
분기 곤란(branch difficulty)
분기 명령어같이 PC의 값을 변경시키려는 명령어에 의해 발생한다.
인터럽트도 이에 포함된다.
데이터 의존성
데이터나 주소의 충돌은 명령어 파이프라인의 성능을 저하시키는 요인
- 데이터 의존성
아직 준비되지 않은 데이터를 기다리는 경우에 발생한다고 할 수 있다.
ex) FO에 의해 피연산자를 fetch하려고 하는데
아직 EX세그먼트에 의해 데이터가 만들어지지 않은 경우 - 주소 의존성
마이크로 연산 시 레지스터 간접 모드를 사용하는 명령어는
이전 명령어가 주소값을 메모리로부터 로드하는 명령이라면 곧바로 피 연산자를 fetch하지 못하고 기다리게 된다. (데이터 의존성에 주소만 추가된 상황이다.)
데이터 의존성 해결 방법
-
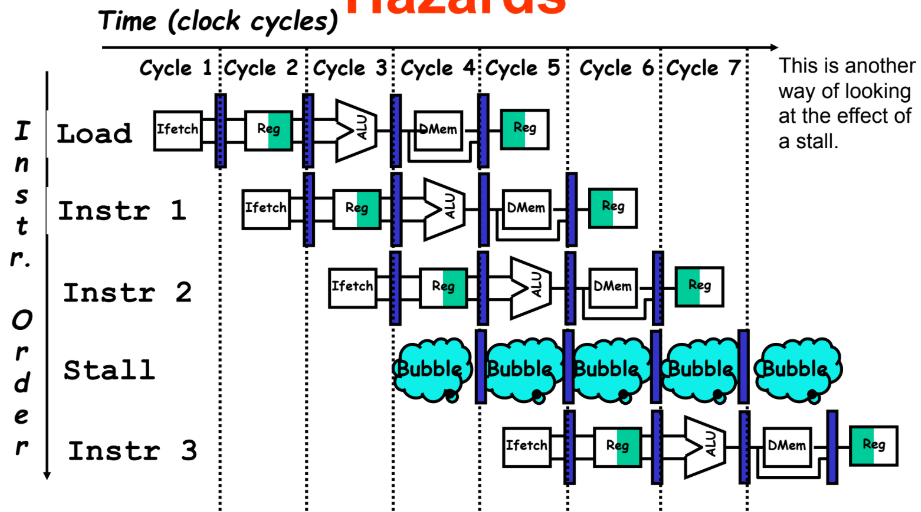
하드웨어 인터락 (hardware interlock)
어떤 명령어의 피연산자가 파이프라인에 앞서간 명령어의 목적지와 일치하는지 검사한다.
이러한 상황이 감지되면 피연산자가 준비되지 않은 명령어는 충돌을 피할 수 있을 만큼
충분한 클럭 사이클을 두어 지연시킨다.
-
오퍼랜드 포워딩 (operand forwarding)
데이터를 동시에 사용할 때 발생
존재 가능한 모든 충돌을 색인으로 체크해놓고 감지될 경우 정해진 경로로 처리한다.
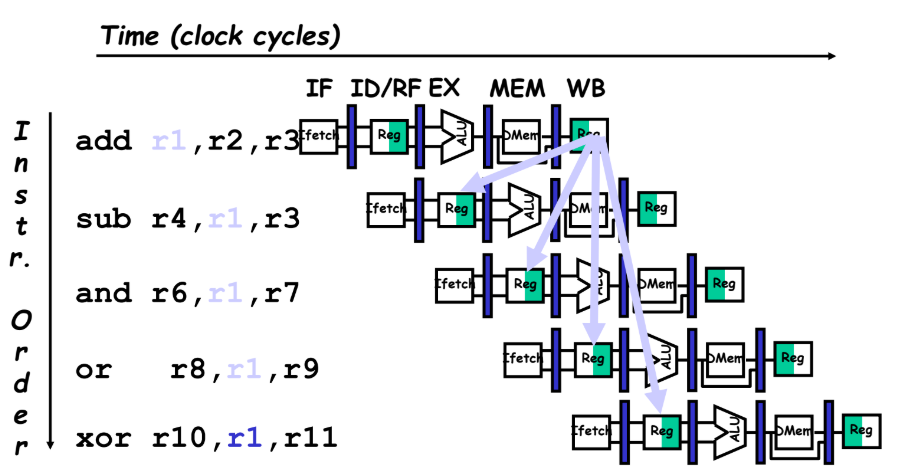
add 명령어의 수행이 끝난 후, r1 오퍼랜드를 다음 명령어가 쓸 수 있는데
sub, and, or 명령어는 add의 수행이 끝나기 전에 r1을 요구하는 상황
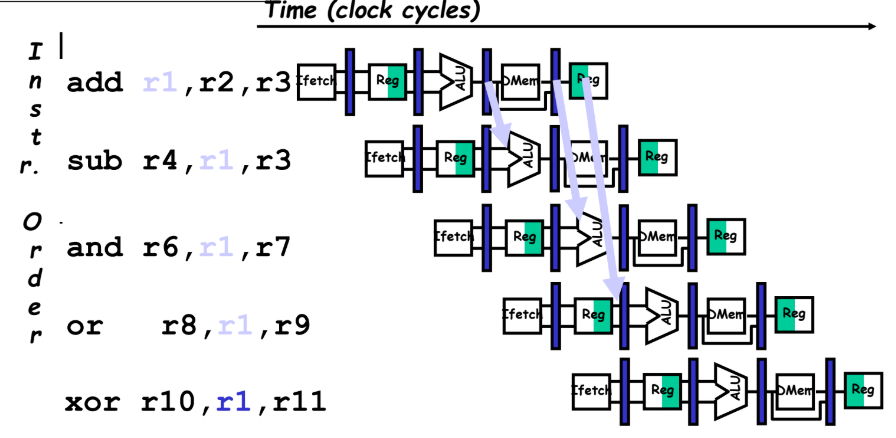
r1을 필요한 명령어에게 바로바로 쏴준다.
분기 명령어의 처리
분기 명령어를 만나면 fetch한 명령어들을 다 버리고 파이프라인을 비워주고 다시 시작해야한다.
그래서 나온 해결 방안이다.
- 순차적으로 처리될 명령어를 분기의 목표가 되는 명령어와 함께 저장하는 방법을 사용한다.
- 분기 예측(branch prediction)
분기 명령어의 주소를 BTB (branch target buffer)에 저장하거나 참조하는 기법
저장된 주소가 있다면 그 주소로 이동한다.
0 int i = 0;
1 do {
2 statement;
3 statement;
4 } while (i++ < 10);위와 같은 코드가 있을 때
1. 4번지에서 ID가 분기 명령어라는 사실을 알아내면 BTB에 현재 PC값에 대응되는 branch값이 있는지 확인한다.
2. EX단계에서 i < 10을 만족하는지 확인 후, BTB는 아직 비어있으므로 PC: 4, NextPC: 1을 저장한다. (miss)
3. i가 9가 될 때까지 BTB에 저장된 주소로 바로 점프한다. (HIT)
4. i가 10이 되면 EX단계에서 i < 10이 불만족함을 확인 후, BTB에서 PC: 4, NextPC: 1를 삭제한다. (miss)
RIRC(Reduce Instruction Set Computer) Processor
- 축소 명령어 세트 컴퓨터
- 핵심적인 명령어를 기반으로 최소한의 명령어 세트를 구성함으로써
파이프라인에 접목시키기 용이하다.
RISC 프로세서의 설계 목표
- 실행 명령어 수는 증가하더라도 작업 처리 시간은 감소시킬 수 있다. (파이프라인 기법)
- 명령어당 실행 클록 수(CPI)와 클록 주기를 파이프라인 구조를 이용하여 감소시킬 수 있다.
RISC 프로세서의 구조적 특징
- 명령어의 1사이클 실행을 위한 파이프라인 구조이다.
- 메모리 참조를 위한 온칩 캐쉬(CPU에 저장 공간 생성)로 더 빠르다.
- 간단한 명령 코드와 주소 지정 모드 및 하드웨어적 제어장치 (축소된 명령어)
- 신속한 오퍼랜드 참조/문맥 전환을 위한 레지스터 집합(중첩된 레지스터 윈도우)
파이프라인의 명령어가 중첩돼서 실행되기 때문에 궁합이 잘 맞는다. - 실수 연산의 별도 처리를 위한 코프로세서(co-processor)
RISC 파이프라인
- I: 명령어의 fetch
- A: ALU 동작
- E: 명령어의 실행
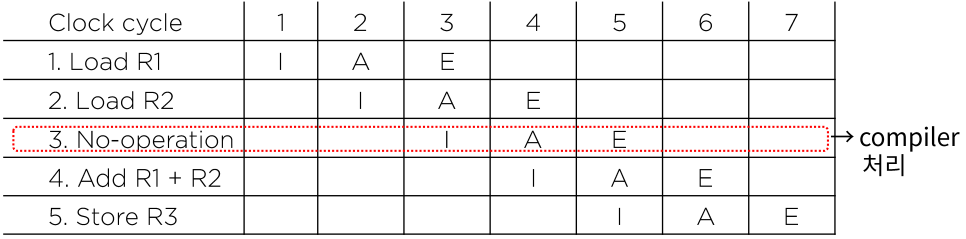
No-operation
4번째 클럭 사이클에서 이전 E명령의 결과를 현재 A명령이 의존하고 있다.
이러한 충돌이나, 데이터 의존성 문제가 발생할 부분을 프로그램이 아니라 컴파일러단에서 처리한다.
(명령어의 개수가 적어서 컴파일러가 단순하게 구현)
파이프라인 CPU 성능 분석
이론적으로는 명령어 세그먼트의 횟수가 많아질수록 파이프라인의 최대 속도가 증가하는 것으로 분석되었으나, 이를 구현하기 위해서는 까다로운 조건이 필요하다.
- 모든 명령어는 동일한 처리 과정(세그먼트의 적용, 세탁 -> 건조 -> 다림질)으로 처리되어야한다.
- 모든 단계는 '클럭 사이클'을 기준으로 처리되게 설계되어야 한다.
- 모든 명령어는 작성된 순서에 따라 순차적으로 실행되어야 한다. (분기 명령, 함수 호출, 반환 명령 등에 의해 순차성이 깨지지 않아야함)
- 사용 명령어들 사이에는 상호 의존성이 없어야 한다.
- 명령어들 처리 시 공유 자원의 충돌이 없어야 한다.
이 부분은 명령어를 저장하는 공간과 자료를 저장하는 공간을 분리함으로써 해결할 수 있다.
Memory system의 이해
메모리 계층
기억장치는 CPU에 의해 시행될 프로그램이 저장되는 곳으로
- 주 기억장치(main memory unit)
- 보조 기억장치(auxiliary memory unit)
- 캐쉬 메모리(cache memory)
로 분류된다.
주 기억장치(Main memory unit)
- 마더보드(motherboard)에 장착된다.
- RAM, ROM이 주 기억장치로 분류된다.
보조 기억장치(Auxiliary Memory Unit)
- 비교적 저속이고 대용량의 자료 보관이 가능하다.
- 보조 기억장치 내의 자료는 필요한 경우 주 기억장치로 옮겨져야 한다. (ROM의 역할)
캐쉬 메모리(Cache memory, buffer)
- 주 기억장치에 접근하는 시간은 프로세스의 논리 회로의 속도보다 느리기 때문에
현재 진행되고 있는 프로그램의 일부 또는 사용 빈도가 높은 임시 데이터를 저장한다. - 프로세스 논리 회로의 속도는 보통 1나노세컨드의 시간이 소요되는데
바꿔 말하면 1기가헤르츠 만큼의 시그널을 보내거나 받아들일 수 있다.
무슨 뜻이냐면 프로세스 논리 회로의 속도가 빠른 만큼 클럭 펄스가 발생하고
클럭 펄스가 발생한 만큼 컴퓨터는 일을 처리할 수 있다.
즉, 1나노세컨드 == 1기가헤르츠, 0.5나노세컨드 == 2기가헤르츠, 2나노세컨드 == 0.5기가헤르츠
컴퓨터 시스템의 메모리 계층
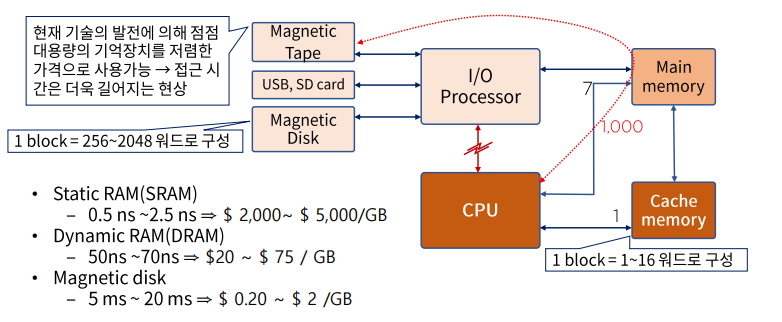
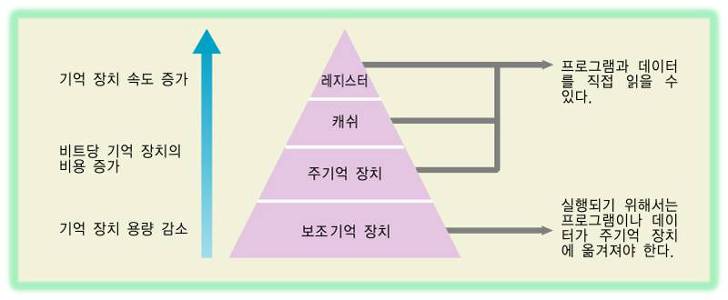
- CPU는 캐쉬 메모리와 주 기억장치만 관리 및 참조한다.
보조 기억 장치까지 참조하면 속도가 매우 느리기 때문에
현재 작업할 내용은 I/O Processor가 보조기억장치에서 주 기억장치로 로드 시켜준다. - 캐쉬 메모리는 CPU와 주 기억장치 사이에 위치하며 CPU는 캐쉬 메모리를 먼저 확인 후 주 기억장치를 확인한다.
- SRAM은 속도가 빠른 대신 비싸고 용량이 적기 때문에 캐쉬 메모리로 사용이 되고
DRAM은 속도가 느린 대신 싸고 용량이 많기 때문에 메인 메모리로 사용이 된다.
주 기억장치
주 기억장치의 종류
-
RAM(Ramdom Access Memory)
-
SRAM(Static RAM)
- 플리플롭(Flip-Flop)으로 작동한다.
플리플롭은 전류 신호가 오기 전에는 상태가 변화하지 않는 소자이기 때문에
가만히 냅두면 변하지 않는(Static) 안정적인 메모리다.
(전원이 연결되어 있는 동안만 정보를 유지한다) - 메모리만 기억하면 돼서 속도가 빠르므로 Cache Memory로 사용된다.
- 플리플롭(Flip-Flop)으로 작동한다.
-
DRAM(Dynamic RAM)
- 축전기(Capacitor)로 작동한다.
축전기는 시간이 지나면 스스로 방전이 되기 때문에
시간이 지나면 메모리가 변화(Dynamic)한다.
이러한 이유로 주기적으로 재충전을 해주어야 정보가 유지되는데
DRAM 자체적으로 Refresh회로가 달려있고 주기적으로 Referesh 신호를 보낸다. - 전력 소비가 적고, 대량의 정보를 저장할 수 있다.
- 축전기(Capacitor)로 작동한다.
-
-
ROM(Read Only Memory)
- 부트스트랩 로더(bootstrap loader)라고도 한다.
보조 기억장치의 OS를 RAM으로 끌어올리는(부팅) 기능을 수행한다. - 전원의 on/off와 무관하게 작동되기 때문에 불변하는 상수의 표 등이 저장된다.
- 부트스트랩 로더(bootstrap loader)라고도 한다.
RAM의 동작 원리
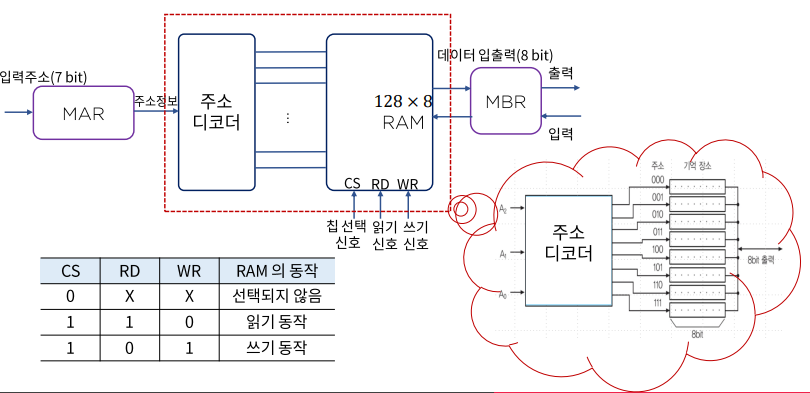
- CS (Clock Signal)
- 빨간 점선으로 표시된 부분이 RAM이다.
- 주소 디코더 - 주소 정보를 해석해서 해당 주소의 메모리의 기억 장소를 가져온다.
- 클럭 펄스(CS)가 1일 때만 동작한다.
- 읽기 요청 - MAR의 주소 정보를 주소 디코더가 해석하고 그 주소의 데이터를 MBR에 전송한다.
- 쓰기 요청 - MAR의 주소 정보를 주소 디코더가 해석하고
그 주소의 기억 장소에 MBR에 있는 데이터를 저장한다.
보조 기억장치
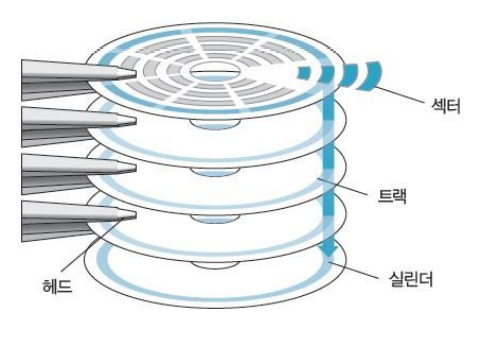
- 접근 시간
메모리 내의 기억 장소에 도달하여 그 내용을 얻는데 요구되는 평균시간- 시크 타임(Seek time)
read/write head가 지정된 기억 장소(특정 트랙의 섹터)에 도달하는 시간 - 트렌스퍼 타임(Transfer Time)
추출된 데이터를 장치 내 또는 장치 밖으로 전송하는 시간 - 레코드(Record)
일반적으로 데이터가 기록되는 단위, 시크 타임을 체크하게 되는 기준(일정한 길이의 수치 또는 문자 집합) - 전송률
장치가 레코드의 시작점에 위치한 다음 단위 시간 당(보통 minute) 전송할 수 있는 문자나 워드의 수
- 시크 타임(Seek time)
효율적 메모리 관리 정책
Associative memory
- 내용에 의해 접근하는 메모리 장치
- CPU는 메모리 장치에 탐색(Search)를 하게 될 수밖에 없고,
더 효율적인 탐색이 가능할 수 있는 저장 공간의 필요성에 의해 만들어졌다. - 내용 지정 메모리(content addressable memory, CAM)이라고도 한다.
- 이 방식은 데이터의 내용을 병렬 탐색을 하기에 적합하도록 구성되어 있고,
탐색은 전체 워드 또는 한 워드의 일부만을 가지고 실행할 수 있다. - 각 셀이 저장 능력 뿐 아니라 외부의 인자와 내용을 비교하기 위한 논리 회로를 갖고 있기 때문에 RAM보다 값이 비싸다. 따라서 탐색 시간이 짧아야 하는 중요한 이슈일 경우에 활용한다.
Associative memory의 하드웨어 구성과 메모리
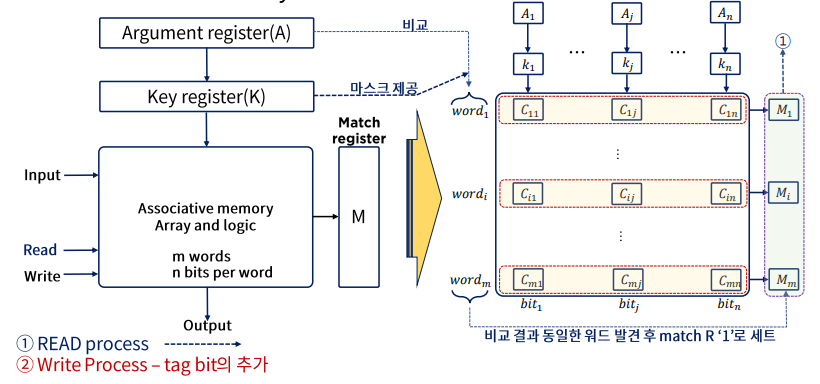
- m개의 word는 각각 n개의 bits로 이루어져있음
- Match register - 일치하는 단어가 있으면 레지스터의 값을 1로 바꾸고
비교가 끝난 후에는 m개의 레지스터 중에서 1로 세팅된 값을 읽는다.
- A에 K의 마스킹을 통해 특정 필드(키)만 뽑아낸다.
- m개의 각 word마다 병렬적으로 비교한다.
- 일치하면 Mi를 1로 설정한다.
key register의 역할
- 인자 워드(argument register)의 특정 영역이나 키를 선택하기 위한 마스크(mask)를 제공한다.

Cache 메모리
참조의 국한성(locality of reference)
프로그램이 수행되는 동안 메모리 참조는 국한된 영역에서만 이루어지는 경향이 있음을 확인할 수 있다.
- 프로그램 루프와 서브 루틴의 빈번한 활용
- 순차적 프로그램의 실행
- 데이터 메모리 참조에서도 동일한 경향이 있음을 확인할 수 있다.
- 테이블-룩업(loop-up) 절차
- 공통 메모리와 배열 사용 예
캐시 메모리는 참조의 국한성(locality of reference)을 이용하여
- 속도는 빠르고 (CPU와 거의 동일)
- 조그마한 메모리(고비용)
를 이용하여 프로그램을 수행시킨다.
Cache 메모리의 동작과 성능
Cache의 기본 동작(CPU가 메모리에 접근할 필요가 있는 경우)
- Cache를 체크
- 워드가 Cache에서 발견되면(hit) 읽어들이고 아닐 경우(miss) 주 기억장치에 접근한다.
- 이 워드를 포함한 블록(1~16워드, 환경에 따라 다름)을 Cache로 전송한다.
히트율, hit ratio

효율적 메모리 관리를 위해서는 효과적으로 cache를 구성하는 방법이
현존하는 메모리 관리 방법 중 최고의 방법이다.
컴퓨터 성능 개선을 위한 메모리 관리
cache 메모리 전송을 위한 다양한 매핑 기법
cache 메모리의 매핑 프로세스
- associative mapping
- Direct mapping
- Set-associative mapping
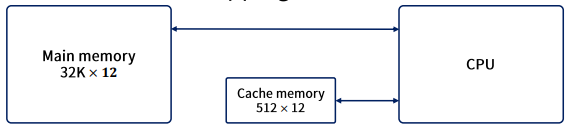
다음과 같은 설정을 가정해보자.
- 우선 15bit의 주소를 cache로 보내어 hit가 발생하면 cache로부터 12bit의 데이터를 받아들인다.
- 만약 miss가 발생하면 주 기억장치로부터 워드를 읽고, 이를 cache로 이동, 저장한다.
associative mapping
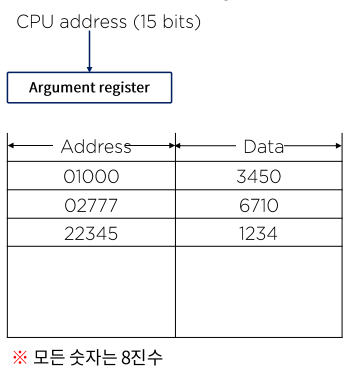
- CAM에 캐싱된다.
- 가장 빠르고 융통성 있는 cache 구조
- CPU의 15bit 주소는 인자 레지스터에 놓여지며, associative memory 내 주소와 같은 12bit의 데이터를 읽어 CPU로 보낸다.
- miss인 경우 CPU는 주 기억장치에서 해당 자료를 찾아 cache로 옮긴다.
- 만약 cache에 여유 공간이 있다면 그 공간에 주소와 데이터를 저장한다.
- cache가 꽉 차 있을 경우 기존 cache의 주소와 데이터 쌍 중
주어진 알고리즘(random, 히트율이 낮은 데이터 삭제)에 의해
해당 주소 데이터 쌍이 새로운 쌍으로 대체된다.
Direct mapping
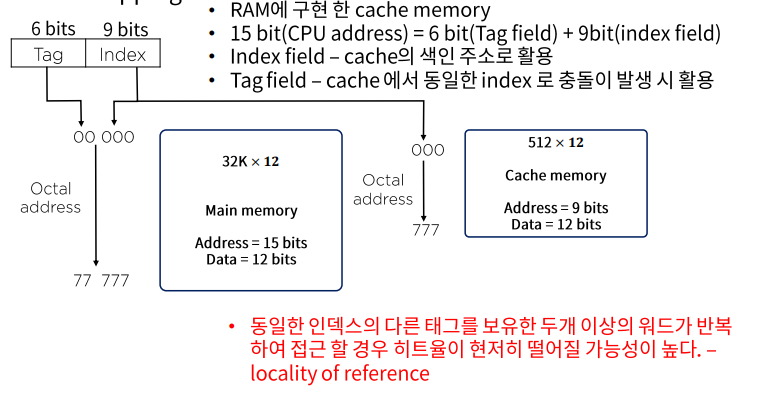
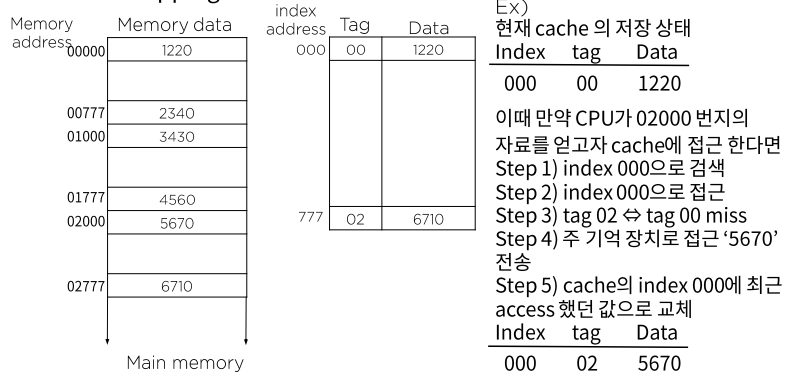
- SRAM에 캐싱
- 하나의 인덱스에 하나의 데이터 워드를 저장
Set-associative mapping
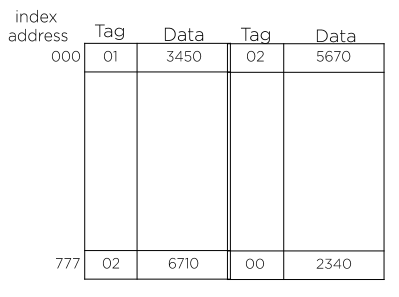
- SRAM에 캐싱
- 하나의 인덱스에 두 개 이상의 데이터 워드를 저장 (인접 리스트)
- 큰 규모의 cache는 히트율을 높일 수 있으나 좀 더 복잡한 비교 논리 회로를 필요로 한다.
- 기존 데이터의 대체 알고리즘이 복잡하다.
가상 메모리
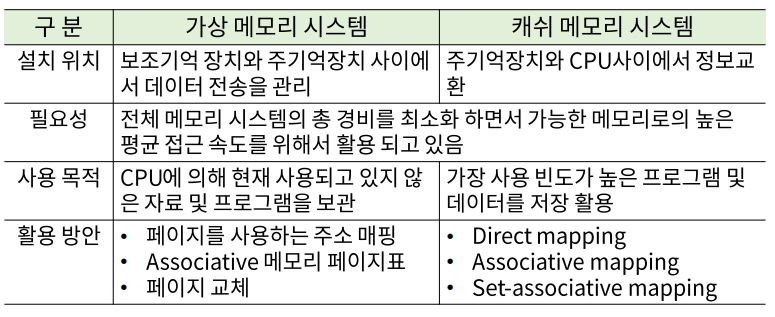
메모리 관리 하드웨어
메모리 관리 시스템
- 메모리의 광역화(가상 메모리 + 캐쉬 메모리)와 멀티 프로그램의 발달로 인한
시스템 내부의 상호 간섭도 증가 -> 시스템 기능 저하 요인 - 프로그램 사이의 데이터 흐름, 선후 데이터의 활용, 사용 메모리의 양 조절 등등을 담당
- 메모리 내의 여러 프로그램을 관리하기 위한 H/W와 S/W 절차의 집합체로
메모리 관리 소프트웨어는 운영체제의 일부이다.
메모리 관리 하드웨어
-
논리 메모리 참조를 물리 메모리 주소로 변환하는 동적 저장 장소 재배치를 위한 기능
ex) 파이프라인에서 데이터 의존성이 생길 때 operand forwarding 기법 사용 -
메모리 내에서 서로 다른 사용자가 하나의 프로그램을 같이 사용하기 위한 편의
-
사용자 간의 허락되지 않은 접근을 방지하고 사용자가 OS의 기능을 변경하지 못하도록 하는 정보의 보호의 역할
다양한 기억장치들에 대한 이해
클럭 펄스
0 -> 1 -> 0 ... 으로 변하는 계단식 주파수 형태
컴퓨터가 계속 구동할 수 있도록 끊임없이 발생한다. ex) CU, ALU, 입출력
사람으로 따지면 심장의 펌프질과 비유할 수 있다.
주 기억장치
SDRM(Synchronous Dynamic Random Access Memory)
- 동기식 DRAM으로서 DRAM의 발전된 형태이다.
- SDR(Single Data Rate)의 성질
클럭 펄스의 변이 (0 <-> 1)시 단 한 차례의 정보 전송만을 허용하는 구조
DDR(Double Data Rate)
- 클럭 신호의 상승 및 하강(0 -> 1 -> 0)에서 데이터를 전송함으로써 성능을 두 배로 향상시킬 수 있다.
이는 SDR 시절의 오버 클럭을 사용했을 때보다 더 빠른 성능으로 혁신적인 기술이다.
보조 기억장치
SSD(Solid State Drive)
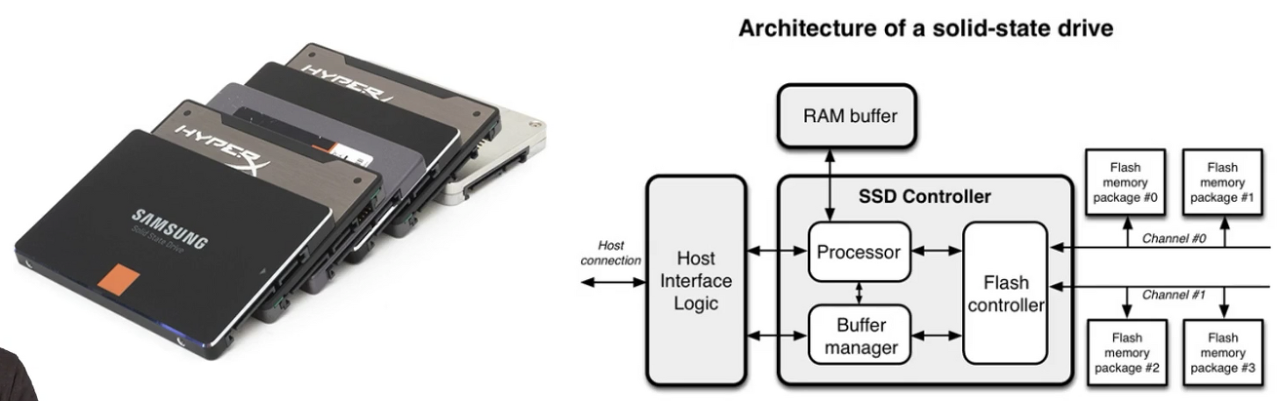
- 데이터를 저장, 접근할 때 플레시 메모리(논리 회로)를 이용하기 때문에
발열, 소음, 소모 전력량이 적다. - 이런 식으로 회전판이 제거된 시스템을 제로 스핀 시스템이라고 한다.
HDD
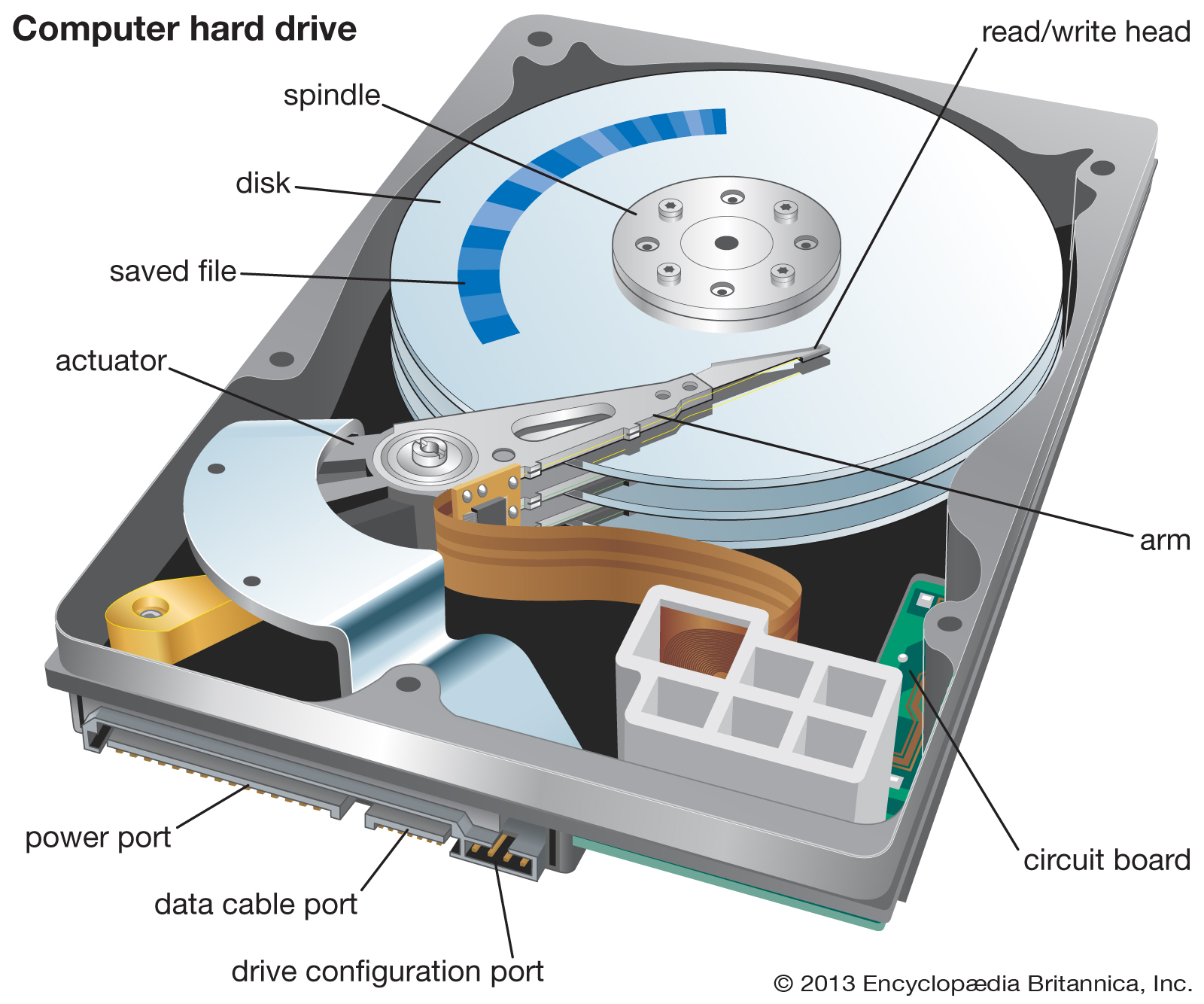
- HDD는 표면상의 스크래치를 이용해서 데이터를 저장, 접근하기 때문에
발열, 소음, 소모 전력량이 많다.
