애플리케이션 계층
2.2 웹과 HTTP
2.2.1 HTTP 개요
웹의 애플리케이션 계층 프로토콜인 HTTP(HyperText Transfer Protocol) 는 웹의 중심이다. HTTP는 클라이언트 프로그램과 서버 프로그램 2가지로 구현된다. 각기 다른 종단 시스템에서 수행되는 클라이언트 프로그램과 서버 프로그램은 서로 HTTP 메시지를 교환하여 통신한다. HTTP는 메시지의 구조 및 클라이언트와 서버가 메시지를 어떻게 교환하는지에 대해 정의하고 있다. HTTP를 자세히 설명하기 전에 몇 가지 웹 전문용어를 살펴보는 것도 좋다.
웹 페이지는 객체들로 구성된다. 객체(object) 는 단순히 단일 URL로 지정할 수 있는 하나의 파일(HTML파일, JPEG이미지, 자바스크립트, CSS스타일시트파일 등)이다. 대부분의 웹 페이지는 기본 HTML 파일과 여러 참조 객체로 구성된다. 예를 들어, 웹 페이지가 HTML 텍스트와 5개의 JPEG 이미지로 구성되어 있으면, 이 웹 페이지는 6개의 객체를 갖고 있는 것이다. 기본 HTML 파일은 페이지 내부의 다른 객체를 그 객체의 URL로 참조한다. 각 URL은 2개의 요소, 즉 객체를 갖고 있는 서버의 호스트 이름과 객체의 경로 이름을 갖고 있다. 다음 URL을 예로 살펴보자.
http://www.someSchool.edu/someDepartment/picture.gif
{kind=link}
www.someSchool.edu는 호스트 이름이고, /someDepartment/picture.gif는 경로 이름이다. 웹 브라우저(Web browser) 는 HTTP의 클라이언트 측을 구현하기 때문에 웹의 관점에서 브라우저와 클라이언트라는 용어를 혼용하여 사용할 것이다. 브라우저는 요구한 웹 페이지를 보여주고 여러가지 인터넷 항해와 구성 특성을 제공한다. HTTP의 서버측을 구현하는 웹 서버는 URL로 각각을 지정할 수 있는 웹 객체를 갖고 있다. 인기 있는 웹 서버로는 아파치(Apache), 마이크로소프트 인터넷 인포메이션 서버(Internet Information Server) 등이 있다.
HTTP는 다음 그림처럼 웹 클라이언트가 웹 서버에게 웹 페이지를 어떻게 요청하는지와 서버가 클라이언트로 어떻게 웹 페이지를 전송하는지를 정의한다

사용자가 웹 페이지를 요청할 때, 브라우저는 페이지 내부의 객체에 대한 HTTP요청 메시지를 서버에게 보낸다. 서버는 요청을 수신하고 객체를 포함하는 HTTP 응답 메시지로 응답한다.
HTTP는 TCP를 전송 프로토콜로 사용한다. HTTP 클라이언트는 먼저 서버에 TCP 연결을 시작한다. 일단 연결이 이루어지면, 브라우저와 서버 프로세스는 그들의 소켓 인터페이스를 통해 TCP로 접속한다. 2.1절에서 기술한 대로, 클라이언트 측에서 보면 소켓 인터페이스는 클라이언트 프로세스와 TCP 연결 사이에서의 출입구다. 클라이언트는 HTTP 요청 메시지를 소켓 인터페이스로 보내고 소켓 인터페이스로부터 HTTP 응답 메시지를 받는다. 마찬가지로 HTTP 서버는 소켓 인터페이스로부터 요청 메시지를 받고 응답 메시지를 소켓 인터페이스로 보낸다. 일단 클라이언트가 메시지를 소켓 인터페이스로 보내면, 메시지는 클라이언트의 손을 떠난 것이고 TCP의 손에 쥐어진 것이다. 2.1절에서 배운 TCP가 HTTP에게 신뢰적인 데이터 전송 서비스를 제공한다는 것을 기억하자. 이것은 클라이언트 프로세스가 발생시킨 모든 HTTP 요청 메시지가 궁극적으로 서버에 잘 도착한다는 것을 의미한다. 마찬가지로, 서버 프로세스가 발생시킨 각 HTTP 응답 메시지도 클라이언트에 잘 도착한다는 것을 의미한다. 여기서 계층구조의 중요한 장점 중 하나를 보게 된다. HTTP는 데이터의 손실 또는 TCP가 어떻게 손실 데이터를 복구하고 네트워크 내부에서 데이터를 올바른 순서로 배열하는지 걱정할 필요가 없다. 이것은 TCP와 프로토콜 스택의 하위 계층들이 하는 일이다.
서버가 클라이언트에게 요청 파일을 보낼 때, 서버는 클라이언트에 관한 어떠한 상태 정보도 저장하지 않는다. 만약 특정 클라이언트가 몇 초 후에 같은 객체를 두 번 요청한다면, 잠시 전에 이미 그 객체를 보냈다고 서버가 알려주면 좋겠지만 서버는 이전에 한 일을 기억하지 않으므로 그 객체를 또 보낸다.HTTP 서버는 클라이언트에 대한 정보를 유지하지 않으므로, HTTP를 비상태 프로토콜(stateless protocol) 이라고 한다. 2.1절에서 설명한 것처럼 웹은 클라이언트-서버 애플리케이션 구조를 사용한다. 웹 서버는 항상 켜져 있고, 고정 IP주소를 가지며, 다른 잠재적인 수백만 브라우저로부터의 요청을 서비스한다.
첫 번째 HTTP 버전은 HTTP/1.0이며 1990년대 초에 등장했다. 2020년 현재 HTTP 트랜잭션의 대부분은 HTTP/1.1을 사용하고 있지만, 점차 많은 브라우저와 웹 서버가 새로운 HTTP 버전인 HTTP/2를 지원하고 있다.
2.2.2 비지속 연결과 지속 연결
많은 인터넷 애플리케이션에서 클라이언트와 서버는 클라이언트라 일련의 요구를 하고 서버가 각 요구에 응답하면서 상당한 기간 동안 통신한다. 애플리케이션과 그 애플리케이션이 어떻게 이용되는지에 따라 일련의 요구가 계속해서, 일정한 간격으로 주기적으로 혹은 간헐적으로 만들어질 수 있다. 이 클라이언트-서버 상호작용이 TCP상에서 발생할 때 애플리케이션 개발자는 중요한 결정을 할 필요가 있다. 각 요구/응답 쌍이 분리된 TCP 연결을 통해 보내져야 하는지 혹은 모든 요구와 해당하는 응답들이 같은 TCP 연결상으로 보내져야 하는지. 전자의 경우 애플리케이션은 비지속 연결(non-persistent connection) 이라고 하고, 후자의 경우 지속 연결(persistent connection) 이라고 한다. 이 설계 쟁점을 자세히 이해하기 위해서는 특정 애플리케이션, 즉 HTTP(이는 비지속 연결과 지속 연결 모두를 사용할 수 있음)의 관점에서 지속 연결의 장점과 단점을 살펴보자. 비록 HTTP가 디폴트 모드로 지속 연결을 사용하지만 HTTP 클라이언트와 서버는 비지속 연결을 사용하도록 설정될 수 있다.
비지속 연결 HTTP
웹 페이지를 서버에서 클라이언트로 전송하는 단계를 살펴보자. 페이지가 기본 HTML파일과 10개의 JPEG 이미지로 구성되고, 이 11개의 객체가 같은 서버에 있다고 가정하자. 기본 HTML 파일의 URL은 다음과 같다.
http://www.someSchool.edu/someDepartment/home.index
연결 수행 과정은 다음과 같다.
-
HTTP 클라이언트는 HTTP의 기본 포트 번호 80을 통해 www.someSchool.edu 서버로 TCP 연결을 시도한다. TCP 연결과 관련하여 클라이언트와 서버에 각각 소켓이 있게 된다.
-
HTTP 클라이언트는 1단계에서 설정된 TCP 연결 소켓을 통해 서버로 HTTP 요청 메시지를 보낸다. 이 요청 메시지는 /someDepartment/home.index 경로 이름을 포함한다.
-
HTTP 서버는 1단계에서 설정된 연결 소켓을 통해 요청 메시지를 받는다.저장장치로부터 /someDepartment/home.index 객체를 추출한다. HTTP 응답 메시지에 그 객체를 캡슐화한다. 그리고 응답 메시지를 소켓을 통해 클라이언트로 보낸다.
-
HTTP 서버는 TCP에게 TCP 연결을 끊으라고 한다(그러나 실제로 TCP 클라이언트가 응답 메시지를 올바로 받을 때까지 연결을 끊지 않는다)
-
HTTP 클라이언트가 응답 메시지를 받으면, TCP 연결이 중단된다. 메시지는 캡슐화된 객체가 HTML 파일인 것을 나타낸다. 클라이언트는 응답 메시지로부터 파일을 추출하고 HTML 파일을 조사하고 10개의 JPEG 객체에 대한 참조를 찾는다.
-
그 이후에 참조되는 각 JPEG 객체에 대해 처음 네 단계를 반복한다.
브라우저는 웹 페이지를 수신하면서, 사용자에게 그 페이지를 보여준다. 2개의 다른 브라우저는 웹 페이지를 각기 다른 방식으로 해석할 수 있다. HTTP는 클라이언트가 웹 페이지를 어떻게 해석하는지는 관심이 없다. HTTP 명세서는 클라이언트 HTTP 프로그램과 서버 HTTP 프로그램 사이의 통신 프로토콜만 정의한다.
앞 단계는 서버가 객체를 보낸 후에 각 TCP 연결이 끊어지므로 비지속 연결을 사용하고 있다. HTTP./1.0은 비지속 연결을 지원한다. 각 TCP 연결은 하나의 요청 메시지와 하나의 응답 메시지만 전송한다. 그래서 이예에서는 사용자가 웹 페이지를 요청할 때 11개의 TCP 연결이 만들어진다.
앞에 설명한 단계에서는 의도적으로 클라이언트가 10개의 순차적 TCP 연결을 통해 10개의 JPEG 파일을 얻는지 아니면 동시에 TCP 연결을 만들어 JPEG를 얻는지 언급하지 않았다. 사실 사용자가 동시성 정도를 조절할 수 있도록 브라우저를 구성할 수 있다. 브라우저는 여러개의 TCP 연결을 설정하며 다중 연결상에서 웹 페이지의 각기 다른 원하는 부분을 요청할 수도 있다. 다음 장에서 보겠지만, 동시 연결을 사용하면 응답 시간을 줄일 수 있다.
계속 진행하기 전에 클라이언트가 기본 HTML 파일을 요청하고 그 파일이 클라이언트로 수신될 때까지의 시간을 측정해보자. 이를 위해 작은 패킷이 클라이언트로부터 서버까지 가고, 다시 클라이언트로 되돌아오는 데 걸리는 시간인 RTT(rount-trip time) 를 정의한다. RTT는 패킷 전파 지연, 중간 라우터와 스위치에서의 패킷 큐잉 지연, 패킷 처리 지연 등을 포함한다. 이제 사용자가 하이퍼링크를 클릭하면 어떤 일이 발생하는지 생각해보자. 다음 그림처럼 이 클릭은 브라우저가 브라우저와 웹 서버 사이에서 TCP 연결을 시도하게 한다.

이는 '세 방향 핸드셰이크(three-way handshake)'를 포함한다. 즉, 클라이언트가 작은 TCP 메시지를 서버로 보내고, 서버는 작은 메시지로 응답하고, 마지막으로 클라이언트가 다시서버에게 응답한다. 세 방향 핸드셰이크 중 처음 두 부분이 경과하면 한 RTT가 계산된다. 핸드셰이크의 처음 두 과정이 끝난 후에 클라이언트는 HTTP 요청 메시지를 TCP 연결로 보내면서 핸드세이크의 세 번쨰 부분(응답)을 함께 보낸다. 일단 요청 메시지가 서버에 도착하면 서버는 HTML 파일을 TCP 연결로 보낸다. 이 HTTP 요청/응답은 또 하나의 RTT를 필요로 한다. 따라서 대략 총 응답 시간은 2 RTT와 HTML 파일을 서버가 전송하는 데 걸리는 시간을 더한것이다.
지속 연결 HTTP
비지속 연결은 몇 가지 단점이 있다. 첫째, 각 요청 객체에 대한 새로운 연결이 설정되고 유지되어야 한다. TCP 버퍼가 할당되어야 하고 TCP 변수들이 클라이언트와 서버 양쪽에 유지되어야 한다. 이는 수많은 클라이언트들의 요청을 동시에 서비스하는 웹 서버에게 심각한 부담을 줄 수 있다. 둘째, 앞서 언급한 대로 각 객체는 2 RTT를 필요로 한다(TCP 연결 설정에서 1 RTT, 객체를 요청하고 받는데 1 RTT)
HTTP/1.1 지속 연결에서 서버는 응답을 보낸 후에 TCP 연결을 그대로 유지한다. 같은 클라이언트와 서버 간의 이후 요청과 응답은 같은 연결을 통해 보내진다. 특히, 전체 웹 페이지(앞 예에서 기본 HTML 파일과 10개 이미지)를 하나의 지속 TCP 연결을 통해 보낼 수 있다. 또한 같은 서버에 있는 여러 웹 페이즈들을 하나의 지속 TCP 연결을 통해 보낼 수 있다. 이들 객체에 대한 요구는 진행 중인 요구에 대한 응답을 기다리지 않고 연속해서 만들어질 수 있다(파이프라이닝(pipelining)). 일반적으로 HTTP 서버는 일정 기간(타임아웃 기간) 사용되지 않으면 연결을 닫는다. 서버가 연속된 요구를 수신할 때, 서버는 객체를 연속해서 보낸다. HTTP의 디폴트 모드는 파이프라이닝을 이용한 지속 연결을 사용한다.
2.2.3 HTTP 메시지 포맷
HTTP 명세서는 HTTP 메시지 포맷을 정의한다. 두가지 HTTP 메시지, 즉 '요청메시지'와 '응답메시지'가 있으며, 아래에서 이 두 가지 타입을 살펴본다.
HTTP 요청 메시지
다음은 전형적인 HTTP 요청메시지다.
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/5.0
Accept-language: fr
간단한 요청메시지이지만 잘 분석하면 많은 것을 배울 수 있다. 첫째, 메시지가 일반 ASCII 텍스트로 쓰여 있어 사람들이 읽을 수 있다. 둘째, 메시지가 다섯줄로 되어있고 각 줄은 CR(carriage return)과 LF(line feed)로 구별된다. 마지막 줄에 이어서 추가 CR과 LF가 따른다. 비록 이 특정 요청메시지가 다섯 줄이지만, 요청메시지는 더 많은 줄로 구성되거나 하나의 줄이 될 수도 있다. HTTP 요청메시지의 첫 줄은 요청라인(request line) 이라 부르고, 이후의 줄들은 헤더라인(header line) 이라고 부른다. 요청라인은 3개의 필드, 즉 방식(method) 필드, URL 필드, HTTP 버전 필드를 갖는다. 방식필드는 GET, POST, HEAD, PUT, DELETE를 포함하는 여러가지 값을 가질 수 있다. HTTP 메시지의 대부분은 GET 방식을 사용한다. GET 방식은 브라우저가 URL 필드로 식별되는 객체를 요청할 떄 사용된다. 이 예에서 브라우저는 /somedir/page.html 객체를 요청하고 있다. 버전은 특별한 설명이 필요하지 않다. 이 예에서 브라우저는 HTTP/1.1 버전을 구현하고 있다.
이제 예에서 헤더라인을 살펴보자. 헤더라인 Host: www.someschool.edu는 객체가 존재하는 호스트를 명시하고 있다. 이미 호스트까지 TCP 연결이 맺어져 있기 때문에 이 헤더라인이 불필요하다고 여겨질 수도 있다. 그러나 호스트 헤더라인이 제공하는 정보는 웹 프록시 캐시에서 필요로 한다. Connection: close 헤더라인을 포함함으로써, 브라우저는 서버에게 지속 연결 사용을 원하지 않는다는 것을 말하고 있다(브라우저는 서버가 요청객체를 보낸 후에 연결을 닫기를 원한다). User-agent: 헤더라인은 사용자 에이전트, 즉 서버에게 요청을 하는 브라우저타입을 명시하고 있다. 여기서 사용자 에이전트는 Mozilla/5.0, 파이어 폭스 브라우저다. 이 헤더라인은 서버가 같은 객체에 대한 다른 버전을 다른 타입의 사용자 에이전트에게 보낼 수 있으므로 유용하다(각 버전은 같은 URL을 갖는다). 마지막으로, Accept-language: 헤더는 사용자가 객체의 프랑스어 버전(서버에 존재한다면)을 원하고 있음을 나타낸다. 이것이 존재하지 않으면 서버는 기본 버전을 보낸다. Accept-language: 헤더는 HTTP에서 사용가능한 많은 콘텐츠 협상헤더 중 하나다.

위 그림에 보이는 요청메시지의 일반포맷을 살펴보자. 요청메시지의 일반포맷이 앞서의 예제를 잘 따르고 있음을 볼 수 있다. 그러나 헤더라인(그리고 추가 CR, LF) 이후에 '개체몸체(entity body)'가 있음을 발견할 것이다. 개체몸체는 GET 방식에서는 비어있고(empty) POST 방식에서 사용된다. HTTP 클라이언트는 사용자가 폼을 채워 넣을 때 POST 방식을 사용한다. POST 메시지로 사용자는 서버에 웹페이지를 요청하고 있으나, 웹페이지의 특정 내용은 사용자가 폼필드에 무엇을 입력하는가에 달려 있다. 만약 방식필드의 값이 POST이면, 개체몸체는 사용자가 폼필드에 입력한 것을 포함한다.
폼으로 생성한 요구가 반드시 POST 방식을 사용할 필요는 없다. 대신에 HTML 폼은 흔히 GET 방식을 사용하고 요청된 URL의 입력데이터(폼 필드들)를 전송한다. 예를 들어, 만약 폼에 GET 방식을 사용하고 2개의 필드를 가지며 두 필드의 입력값이 monkeys와 bananas라면 URL은 www.somesite.com/animalsearch?monkeys&bananas 구조를 가질것이다.
HEAD 방식은 GET 방식과 유사하다. 서버가 HEAD 방식을 가진 요청을 받으면 HTTP 메시지로 응답하는데, 요청객체는 보내지 않는다. 애플리케이션 개발자는 흔히 디버깅을 위해 HEAD 방식을 많이 사용한다. PUT 방식은 또한 웹 서버에 업로드할 객체를 필요로 하는 애플리케이션에 의해 사용된다. DELETE 방식은 사용자 또는 애플리케이션이 웹 서버에 있는 객체를 지우는 것을 허용한다.
HTTP 응답 메시지
다음은 전형적인 HTTP 응답메시지를 보여주고 있다. 이 응답메시지는 앞서 살펴본 예제의 요청메시지에 대한 응답일 수 있다.
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(데이터 데이터 데이터 데이터 데이터 ...)
이 응답메시지는 3개의 섹션, 즉 초기 상태라인(status line), 6개의 헤더라인, 개체몸체로 이루어졌다. 이 개체몸체는 요청객체(데이터 데이터 데이터 데이터 데이터 ...로 표현된 부분)를 포함한다. 상태 라인은 3개의 필드, 즉 프로토콜 '버전 필드', '상태 코드', '해당 상태메시지'를 갖는다. 이 예에서 상태라인은 서버가 HTTP/1.1을 사용하고 있고, 모든것이 양호함(OK)을 나타낸다(즉, 서버가 요청객체를 찾아서 보내고 있음을 알려준다).
이제 서버가 사용하는 헤더라인들을 살펴보자.
- Connection: close: 클라이언트에게 메시지를 보낸 후 TCP 연결을 닫는 데 사용한다.
- Date: 응답이 서버에 의해 생성되고 보낸 날짜와 시간을 나타낸다. 이 시간이 객체가 생성되거나 마지막으로 수정된 시간을 의미하는 것이 아님을 유의하라. 서버가 파일시스템으로부터 객체를 추출하고 응답메시지에 그 객체를 삽입하여 응답메시지를 보낸 시간을 의미한다.
- Server: 메시지가 아차피 웹 서버에 의해 만들어졌음을 나타낸다. HTTP 요청 메시지의 User-agent: 헤더라인과 비슷하다.
- Last-Modified: 객체가 생성되거나 마지막으로 수정된 시간과 날짜를 나타낸다. 이 헤더는 객체를 로컬 클라이언트와 네트워크 캐시 서버(프록시 서버로도 알려짐) 캐싱에 매우 중요하다.
- Content-Length: 송신되는 객체의 바이트 수를 나타낸다.
- Content-Type: 개체몸체 내부의 객체가 HTML 텍스트인것을 나타낸다. 객체타입은 파일확장자로 나타내는 것이 아니라 공식적으로 Content-Type: 헤더로 나타낸다.
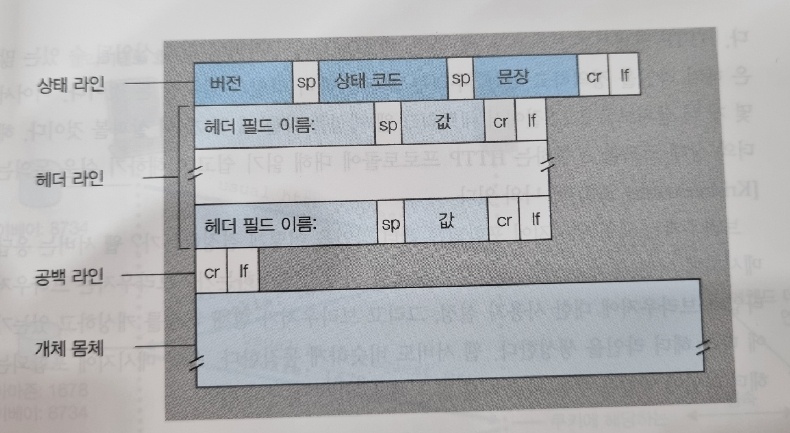
위 그림에 있는 응답메시지의 일반포맷을 살펴보자. 이 응답메시지의 일반 포맷은 응답 메시지의 이전 예와 일치한다. 상태코드와 그들 문장에 대한 추가설명을 하겠다. 상태코드와 연관문장은 요청 결과를 나타낸다. 일반적인 상태코드와 연관문장은 다음과 같다.
- 200 OK: 요청이 성공했고, 정보가 응답으로 보내졌다.
- 301 Moved permanently: 요청 객체가 영원히 이동되었다. 새로운 URL은 응답 메시지의 Location: 헤더에 나와 있다. 클라이언트 소프트웨어는 자동으로 이 새로운 URL을 추출한다.
- 400 Bad Request: 서버가 요청을 이해할 수 없다는 일반 오류코드다.
- 404 Not Fount: 요청 문서가 서버에 존재하지 않는다.
- 505 HTTP Version Not Supported: 요청 HTTp 프로토콜 버전을 서버가 지원하지 않는다.
실제로 HTTP 응답메시지를 어떻게 볼 수 있을까? 먼저 원하는 웹 서버에 텔넷으로 접속한다. 그 서버에 있는 객체에 대해 한 줄로 된 요청 메시지를 입력한다. 유닉스 컴퓨터에 로그인할 수 있다면 다음과 같이 입력하라(마지막 줄을 입력한 후에 엔터를 두 번 쳐라)
telnet gaia.cs.umass.edu 80
GET /kurose_rose/interactive/index.php HTTP/1.1
Host: gaia.cs.umass.edu
이는 gaia.cs.umass.edu 호스트의 80번 포트로 TCP 연결을 설정하고 다음에 HTTP 요청메시지를 보낸다. 단지 HTTP 메시지 줄만 보이고 객체 자체는 받지 않으려면 GET을 EHAD로 바꾸어 시도한다.
이 절에서는 HTTP 요청/응답 메시지에 사용할 수 있는 여러 헤더라인을 살펴봤다. HTTP 명세서는 브라우저, 웹 서버, 네트워크 캐시 서버에 의해 삽입될 수 있는 많은 헤더라인을 정의하고 있다.
브라우저는 요청메시지에 포함되는 헤더라인을 어떻게 결정하는가? 웹 서버는 응답메시지에 어떤 헤더라인을 포함할 것인지를 어떻게 결정하는가? 브라우저는 브라우저타입과 브라우저에 대한 사용자설정, 그리고 브라우저가 현재 객체를 캐싱하고 있는가에 따라 헤더라인을 생성한다. 웹 서버도 비슷하게 동작한다. 응답메시지에 포함되는 헤더라인에 영향을 주는 서로 다른 많은 제품, 버전, 설정이 있다.
사용자와 서버간의 상호작용: 쿠키
앞에서 HTTP 서버는 상태를 유지하지 않는다고 했다. 이것은 서버 설계를 간편하게 하고 동시에 수천개의 TCP 연결을 다룰 수 있는 고성능의 웹 서버를 개발하게 해주었다. 그러나 서버가 사용자 접속을 제한하거나 사용자에 따라 콘텐츠를 제공하지 원하므로 웹사이트가 사용자를 확인하는 것이 바람직할 때가 있다. 이 목적으로 HTTP는 쿠키(cookie)를 사용한다. 쿠키는 사이트가 사용자를 추적하게 해준다. 대부분의 주요 상용 웹사이트는 쿠키를 사용하고 있다.

위 그림에서처럼 쿠키 기술은 네 가지 요소, 즉 (1) HTTP 응답메시지 쿠키 헤더라인, (2) HTTP 요청메시지 쿠키 헤더라인, (3) 사용자의 브라우저에 사용자 종단시스템과 관리를 지속시키는 쿠키파일, (4) 웹 사이트의 백엔드(back-end) 데이터베이스를 갖고 있다. 위 그림을 이용하여 쿠키가 어떻게 동작하는지를 알아보자. 집에 있는 PC로 인터넷 익스플로러를 통해 항상 웹 접속을 하는 수잔이 처음으로 아마존닷컴에 접속했다고 가정하자. 과거에 그녀는 이미 이베이 사이트를 방문한 적이 있다고 가정한다. 아마존 웹 서버에 요청이 들어올 때 그 서버는 유일한 식별번호를 만들고 이 식별번호로 인덱싱되는 백엔드 데이터베이스 안에 엔트리를 만든다. 그런 후 아마존 웹 서버는 수잔의 브라우저에 응답하는데, 이 HTTP 응답에 식별번호를 담고 있는 Set-cookie: 헤더가 포함된다. 예로 그 헤더라인은 다음과 같다.
Set-cookie: 1678
수잔의 브라우저가 HTTP 응답 메시지를 받았을 때 그 Set-cookie: 헤더를 볼 수 있다. 그런 다음 브라우저는 관리하는 특정한 쿠키파일에 그 라인을 덧붙이게 된다. 이 라인은 서버의 호스트이름과 Set-cookie: 헤더와 식별번호를 포함한다. 수잔이 과거에 이베이 사이트를 방문했기 때문에 쿠키파일은 이베이ㅔ 대한 엔트리를 갖고 있음에 유의하라. 수잔이 곗고해서 아마존 사이트를 살펴봄에 따라, 그녀가 웹페이즈를 요청할 때 그녀의 브라우저는 쿠키파일을 참조하고 이 사이트에 대한 그녀의 식별번호를 발췌하고, HTTP 요청에 식별번호를 포함하는 쿠키헤더파일을 너허는다. 특히, 아마존서버로의 각 HTTP 요청은 다음과 같은 헤더라인을 포함한다.
Cookie: 1678
이러한 방식으로 아마존서버는 수잔의 아마존 사이트에서의 활동을 추적할 수 있다. 비록 아마존 웹사이트는 수잔의 이름을 알 필요는 없지만 1678 사용자가 어느 페이지를, 어떤 순서로, 몇 시에 방문했는지 정확히 알 수 있다. 아마존은 '쇼핑카트' 서비스를 제공하기 위해 쿠키를 사용한다. 아마존은 수잔의 모든 원하는 구매목록을 유지할 수 있어서 그녀는 그 세션이 끝날 때 그것들을 총괄하여 지불할 수 있다.
만약 수잔이 사이트를 일주일 후에 다시 접속하면 그녀의 브라우저는 Cookie: 1678을 헤더라인에 넣어 요청메시지를 보낼 것이다. 아마존은 또한 그녀가 과거에 아마존에서 방문한 웹페이지에 기초하여 제품을 추천한다. 만약 수잔이 자신을 아마존에 등록한다면(이름 전체, 전자메일, 우편번호, 신용카드 정보를 제공) 아마존은 이 정보를 데이터베이스에 추가하고, 그것에 의해 그녀의 식별번호(그리고 예전에 사이트에 그녀가 방문한 페이지 모두)를 수잔의 이름과 연관시킨다. 이것이 아마존을 비롯한 전자상거래 사이트가 '원 클릭 쇼팡'을 제공하는 방식이다. 수잔이 다음에 방문에서 구매할 물건을 선택하면 그녀의 이름, 신용카드번호, 주소를 재입력할 필요가 없다.
이 논의로부터 쿠키는 사용자 식별에 사용할 수 있음을 알 수 있다. 사용자가 사이트를 처음 방문하면 사용자는 사용자 확인(이름)을 제공한다. 다음 세션 동안에, 브라우저는 서버에 쿠키헤더를 전달하여 서버에게 사용자를 확인한다. 따라서 쿠키는 비상태 HTTP 위에서 사용자 세션 계층을 생성하는 데 이용될 수 있다. 예로 사용자가 웹 기반 전자메일 애플리케이션으로 로그인했을 때 브라우저는 서버에 쿠키정보를 보내고 그 애플리케이션에서 사용자 세션시간동안 사용자를 식별하게 한다.
비록 쿠키가 사용자를 위해 인터넷 쇼핑경험을 간소화하지만, 사용자 사생활에 대한 침해로 보일 수 있음에 따라 커다란 논쟁거리다.
2.2.5 웹 캐싱
웹 캐시(Web cache, 프록시 서버(proxy server)라고도 함) 는 기점 웹 서버(origin Web server)를 대신하여 HTTP 요구를 충족시키는 네트워크 개체다. 웹 캐시는 자체의 저장디스크를 갖고 있어 최근 호출된 객체의 사본을 저장 및 보존한다. 아래 그림처럼 브라우저는 사용자의 모든 HTTP 요구가 웹 캐시에 가장 먼저 보내지도록 구성될 수 있다.

일단 브라우저가 설정되면 객체에 대한 각각의 브라우저 요청은 웹 캐시가 가장 먼저 보내진다. 예를 들어, http://www.someschool.edu/campus.gif 라는 객체를 요구한다고 생각해보자. 이때 어떤 일이 발생하는지 알아보면 다음과 같다.
{kind=link}
- 브라우저는 웹 캐시와 TCP 연결을 설정하고 웹 캐시에 있는 객체에 대한 HTTP 요청을 보낸다.
- 웹 캐시는 객체의 사본이 자기에게 저장되어 있는지 확인한다. 만일 저장되어 있다면 웹 캐시는 클라이언트 브라우저로 HTTP 응답메시지와 함께 객체를 전송한다.
- 만약 웹 캐시가 객체를 갖고 있지 않다면, 웹 캐시는 기점 서버인 www.someschool.edu로 TCP 연결을 설정한다. 그리고 나서 웹 캐시는 캐시와 서버 간의 TCP 연결로 객체에 대한 HTTP 요청을 보낸다. 이러한 요청을 받은 후에 기점 서버는 웹 캐시로 HTTP 응답메시지와 함께 객체를 보낸다.
- 웹 캐시의 객체를 수신할 때, 객체를 지역 저장장치에 복사하고 클라이언트 브라우저에 HTTP 응답메시지와 함께 객체의 사본을(클라이언트 브라우저와 웹 캐시 사이에 이미 설정된 TCP 연결을 통해) 보낸다.
캐시는 서버이면서 클라이언트라는 점을 유의해야 한다. 브라우저로부터 요구를 받고 응답을 보내는 것은 서버이고, 출처 서버에게 요구를 보내거나 응답을 받는것이 클라이언트다.
일반적으로 웹 캐시는 ISP가 구입하고 설치한다. 에를들어, 대학교는 캠퍼스 네트워크에 웹 캐시를 설치하고 모든 캠퍼스의 브라우저가 이 캐시로 요청을 보내도록 설정한다. 또한 컴캐스트(Comcast) 같은 주요 가정 ISP는 하나 이상의 캐시를 네트워크상에 설치하고 설치된 캐시를 가리키도록 브라우저를 미리 설정한다.
웹 캐싱은 인터넷상에서 다음과 같은 이유로 즐겨 사용되어왔다. 첫째, 웹 캐시는 클라이언트의 요구에 대한 응답 시간을 줄일 수 있다. 특히 클라이언트와 기점 서버 사이의 병목 대역폭이 클라이언트와 캐시 사이의 병목 대역폭에 비해 매우 작을 때 더욱 효과적이다. 클라이언트와 캐시 사이에 높은 속도의 연결이 설정되어 있고 캐시가 요청된 객체를 갖고 있다면, 캐시는 그 객체를 클라이언트로 매우 신속하게 전달할 수 있다. 둘째, 웹 캐시는 한 기관에서 인터넷으로의 접속하는 링크상의 웹 트래픽을 대폭으로 줄일 수 있다. 트래픽을 줄여주면, 기관(회사나 대학)은 자주 대역폭을 개선할 필요가 없어져 비용을 줄일 수 있다. 더욱이 웹 캐시는 인터넷 전체의 웹 트래픽을 실질적으로 줄임으로써 모든 애플리케이션을 위한 성능을 개선한다.
캐시의 장점을 더 깊이 이해하기 위해 다음 그림을 살펴보자.

이 그림은 두 네트워크(기관 네트워크와 그 외의 공중 인터넷)를 보여준다. 그림에서 기관 네트워크는 고속의 LAN이며 기관 네트워크에 있는 라우터와 인터넷에 있는 라우터는 15 Mbps 회선에 연결되어 있다. 기점 서버는 인터넷에 연결되어 있지만 전역에 걸쳐 위치하게 된다. 평균 객체의 크기가 1Mb이고 기관 브라우저로부터 기점 서버에 대한 평균 요청 비율이 초당 15요청이라고 가정하자. 그리고 HTTP 메시지요청이 무시할 만큼 작으므로 네트워크나 접속회선(기관라우터에서 인터넷라우터 사이의 접속회선)에 어떤 트래픽도 발생시키지 않는다고 가정하자. 또한 위 그림에서 접속 회선의 인터넷부분 라우터가 HTTP 요청(IP 데이터그램을 통해)을 전달하고 응답(일반적으로 많은 IP 데이터그램을 통해)을 받을 때까지 평균소요시간은 2초라 가정하자. 통상 이러한 지연을 '인터넷지연'이라 한다. 총 응답시간(브라우저의 요청으로부터 객체 수신까지 걸리는 시간)은 LAN지연과 접속지연(라우터간의 지연), 인터넷지연의 합과 같다. 이제 이 지연을 알아보기 위해 대략적인 계산을 해보자. LAN의 트래픽강도는 다음과 같다.
(15요청/초) X (1 Mb/요청)/(100 Mbps) = 0.15
접속회선(인터넷라우터에서 기관라우터사이)의 트래픽강도는 다음과 같다.
(15요청/초) X (1 Mb/요청)/(15 Mbps) = 1
일반적으로 LAN의 트래픽강도 0.15는 많아야 수십 ms의 지연을 야기하므로 LAN지연을 무시할 수 있다. 그러나 1.4.2절에서 언급한 것처럼 트래픽강도가 1에 가까워지면 접속회선의 경우와 같이 회선의 지연은 매우 커지고 한없이 증가한다. 따라서 요청을 만족시키기 위한 평균응답시간은 대략 몇 분이 걸리므로 기관 사용자에게 적합하지 않다. 어떻게든 이것은 분명히 해결되어야 한다.
한 가지 가능한 방법은 접속률을 15 Mbps에서 100 Mbps로 늘리는 것이다. 이 방법은 두 라우터간의 전송지연을 무시할 수 있는 수준인 0.15까지 접속회선의 트래픽강도를 낮추게 된다. 이 경우에 총 응답지연(즉, 인터넷 지연)은 대략 2초다. 그러나 이러한 해결책은 기관이 접속회선을 15 Mbps에서 100 Mbps로 개선해야 하므로 많은 비용이 들어간다.

그렇다면 다른 해결방법, 즉 접속회선을 증설하지 않고 기관 네트워크에 웹캐시를 설치하는 방법을 생각해보자. 이 방법은 위 그림에 설명되어 있다. 적중률(캐시가 만족시킨 요청 비율)은 일반적으로 0.2~0.7이다. 설명을 위해 이 기관에서는 캐시가 0.4의 적중률을 제공한다고 가정하자. 캐시와 클라이언트가 고속 LAN에 연결되어 있으므로 요청의 40%는 캐시에 의해 즉시(10ms) 만족된다. 하지만 여전히 60%의 요청은 기점 서버에 의해 만족되어야 한다. 그러나 요청된 객체의 60%만 접속회선을 통과하므로 트래픽강도는 1.0에서 0.6으로 감소된다. 일반적으로 0.8 미만의 트래픽가아도는 작은지연(15 Mbps 회선에서 수십 ms 정도)에 속한다. 이 지연은 2초의 인터넷지연에 비하면 무시할 수 있다. 그러므로 이들을 고려한 평균지연은 다음과 같다.
0.4 X (0.01초) + 0.6 X (2.01초)
이것은 1.2초가 조금 넘는 지연이다. 따라서 이 두 번째 해결방법은 첫 번째 방법보다 낮은 응답시간을 가지며 기관이 인터넷을 위힌 회선을 증설할 필요가 없다. 물론 기관은 웹캐시를 구입하고 설치해야 하겠지만, 캐시 가격은 저렵하다. 많은 캐시가 저렴한 PC에서 실행되는 공개 소프트웨어를 사용한다.
콘텐츠 전송 네트워크(Content Distribution Network, CDN) 의 사용을 통해, 웹캐시는 인터넷에서 점진적으로 중요한 역할을 하고 있다. CDN 회사는 인터넷 전역을 통해 많은 지역적으로 분산된 캐시를 설치하고 있으며, 이를 통해 많은 트래픽을 지역화하고 있다. 그 종류로는 공유 CDN(예: 아카마이, 라임라이트)과 전용 CDN(예: 구글, 마이크로소프트)이 있다.
조건부 GET
웹캐싱이 사용자가 느끼는 응답시간을 줄일 수 있지만, 새로운 문제를 야기한다. 즉, 캐시 내부에 있는 객체의 복사본이 새것이 아닐 수 있다는 점이다. 다시 말해, 복사본이 클라이언트에 캐싱된 이휑 웹서버에 있는 객체가 갱신되었을 수도 있다. 다행히도, HTTP는 클라이언트가 브라우저로 전달되는 모든 객체가 최신의 것임을 확인하면서 캐싱을 하게 해주는 방식을 갖고 있다. 이러한 방식은 조건부 GET(conditional GET) 이라고 한다. HTTP 요청메시지가 (1) GET 방식을 사용하고, (2) If-Midified-Since: 헤더라인을 포함하고 있다면, 그것이 조건부 GET 메시지다.
조건부 GET이 어떻게 동작하는지를 설명하기 위해 예를 들어 살펴보자. 첫째, 브라우저의 요청을 대신해 프록시 캐시는 요청메시지를 웹서버로 보낸다.
GET /fruit/kiwi.gif. HTTP/1.1
Host: www.exotiquecuisine.com
둘째, 웹서버는 캐시에게 객체를 가진 응답메시지를 보낸다.
HTTP/1.1 200 OK
Date: Sat, 3 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
Last-Modified: Wed, 9 Sep 2015 09:23:24
Content-Type: image/gif
(데이터 데이터 데이터 데이터 데이터 ...)
캐시는 요청하는 브라우저에게 객체를 보내주고 자신에게도 객체를 저장한다. 중요한것은 캐시가 객체와 더불어 마지막으로 수정된 날짜를 함께 저장한다는 점이다. 셋째, 일주일 후에 다른 부라우저가 같은 객체를 캐시에게 요청하면 객체는 여전히 저장되어 있다. 이 객체는 지난주에 웹서버에서 수정되었으므로 부라우저는 조건부 GET으로 갱신조사를 수행한다. 특히, 브라우저는 다음과 같은 내용을 보낸다.
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
If-modified-since: Wed, 9 Sep 2015 09:23:24
If-modified-since: 헤더라인의 값이 일주일 전에 서버가 보낸 Last-Modified: 헤더라인의 값과 정확히 일치하는 것에 유의하라. 이 조건부 GET은 서버에게 그 객체가 명시된 날짜 이후 수정된 경우에만 그 객체를 보낼것을 말하고 있다. 그 객체가 9 Sep 2015 09:23:24 이후 변경되지 않았다고 가정하자. 넷째, 그러면 웹서버는 클라이언트에게 다음과 같은 응답메시지를 보낸다.
HTTP/1.1 304 Not Modified
Date: Sat, 10 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
(빈 객체 몸체)
조건부 GET에 대한 응답으로 웹서버가 여전히 응답메시지를 보내지만 응답메시지에 요청된 객체를 포함하지 않음을 볼 수 있다. 요청메시지를 포함하는것은 대역폭을 낭비하는 것이고, 특히 그 개체가 크다면 사용자가 느끼는 응답시간이 증가된다. 이 마지막 응답메시지는 304 not Modified 상태라인을 갖고 있으며, 이는 클라이언트에게 요청객체의 캐싱된 복사본을 사용하라는 것을 의미한다.
2.2.6 HTTP/2
2015년에 표준화된 HTTP/2는 1997년에 표준화된 HTTP/1.1 이후 새로운 첫 번째 HTTP 버전이다. HTTP/2가 발표된 이후 2020년 현재 주요 웹사이트 천만개의 40%가 HTTP/2를 지원하고 있다. 구글 크롬, 인터넷 익스플로러, 사파리, 오페라, 파이어폭스 등 대부분의 주요 브라우저도 HTTP/2를 지원하고 있다.
HTTP/2의 주요 목표는 하나의 TCP 연결상에서 멀티플렉싱 요청/응답 지연시간을 중이는데 있으며, 요청 우선순위화, 서버 푸시, HTTP 헤더 필드의 효율적인 압축 기능 등을 제공한다. HTTP/2는 상태코드, URL, 헤더필드 등 HTTP 메소드 자체는 변경하지 않았다. 대신에 HTTP/2는 클라이언트와 서버간의 데이터 포맷방법과 전송방법을 변경했다.
HTTP/2의 필요성을 강조하기 위해 HTTP/1.1을 상기해보자. HTTP/1.1은 지속적인 TCP 연결을 이용하여 하나의 TCP 연결상에서 서버로부터 클라이언트로 보내지는 웹페이지를 허용한다. 웹페이지당 오직 하나의 TCP 연결을 가짐으로써, 아래 설명하듯이 서버에서의 소켓 수를 줄이며 전송되는 각 웹페이지는 공정한 네트워크 대역폭을 가질 수 있다. 그러나 웹브라우저 개발자들은 하나의 TCP 상에서 웹페이지에 있는 모든 객체를 보내면 HOL(Head of Line) 블로킹 문제가 발생할 수 있다는 사실을 재빨리 발견했다. HOL 블로킹을 이해하기 위해 하나의 HTML 기반 페이지, 웹페이지 상단에 큰 비디오 클립이 위치하며 비디오 아래 많은 수의 작은객체들을 포함하는 하나의 웹페이지를 고려해보자. 또한 서버와 클라이언트 사이에는 저속에서 중간속도의 병목(예를 들어, 저속의 무선링크)링크가 있다. 하나의 TCP 연결을 이용하여 비디오 클립은 병목링크를 통과하는데 오랜 시간이 걸리는 반면, 작은 객체들은 비디오 클립 뒤에서 기다림이 길어진다. 즉, 앞쪽에 있는 비디오 클립은 뒤에 오는 작은 개체들을 블로킹하게 된다. HTTP/1.1 브라우저에서는 여러개의 병렬 TCP 연결을 열어서 HOL 블로킹 문제를 해결해왔다. 따라서 같은 웹페이지에 있는 객체들은 브라우저로 병렬적으로 전송되며, 이런 방법으로 작은 객체들도 브라우저를 통해 훨씬 빠르게 전달될 수 있으면 사용자가 느끼는 지연은 줄어들게 된다.
3장에서 논의할 TCP 혼잡 제어 또한 하나의 지속적인 연결 대신 여러개의 병렬 TCP 연결을 사용함으로써 브라우저에게 예상치 못한 혜택을 주게된다. TCP 혼잡제어는 각 TCP 연결이 공정하게 병목링크를 공유하여 같은 크기의 가용한 대역폭을 공평하게 나누게 해준다고 볼 수 있다. 만일 n개의 TCP 연결이 병목링크에서 작동하고 있다면 각 연결은 대략 대역폭의 1/n씩을 사용하게 된다. 하나의 웹페이지를 전송하기 위해 여러개의 병렬 TCP 연결을 열게 함으로써 브라우저는 일종의 속임수로 링크 대역폭의 많은 부분을 받게 된다. 많은 HTTP/1.1 브라우저들은 6개까지 병렬 TCP 연결을 열 수 있으며 HOL 블로킹을 막을 뿐만 아니라 더 많은 대역폭을 사용할 수 있게 해준다.
HTTP/2의 주요 목표 중 하나는 하나의 웹 페이지를 전송하기 위한 병렬 TCP 연결의 수를 줄이거나 제거하는 데 있다. 이는 서버에서 열고 유지되는 데 필요한 소켓의 수를 줄일 뿐만 아니라 목표한 대로 TCP 혼잡제어를 제어할 수 있게 하는 데 있다. 그러나 웹페이지를 전송하기 위해 오직 하나의 TCP 연결만을 사용하게 될 경우에 HTTP/2는 HOL 블로킹을 피하기 위해 신중하게 구현된 메커니즘이 필요하다.
HTTP/2 프레이밍
HOL 블로킹 문제의 해결책으로 등장한 HTTP/2는 각 메시지를 작은 프레임으로 나누고, 같은 TCP 연결에서의 요청과 응답메시지를 인터리빙한다. 이를 이해하기 위해 앞서 언급한 하나의 큰 비디오클립과 8개의 작은 객체로 이루어진 웹페이지 예시를 다시보자. 결국 서버는 이 웹페이지를 확인하기 위해 브라우저를 통해 9개의 병렬요청을 받게된다. 각 요청마다 서버는 9개의 경쟁적인 HTTP 응답메시지를 브라우저로 보내야 한다. 모든 프레임은 고정된 길이를 갖고, 비디오클립은 1000개의 프레임으로 구성되며, 작은 객체들은 2개의 프레임으로 구성된다고 가정하자. 비디오클립으로부터 하나의 프레임을 전송한 이후 프레임 인터리빙을 이용하여 각 소형객체의 첫 번째 프레임을 보낸다. 이후 두 번째 비디오클립 프레임을 보내고나서 각 소형 객체의 마지막 프레임을 전송한다. 따라서 모든 소형객체는 18개의 프레임을 보낸 후에 전송된다. 만약 인터리빙이 사용되지 않는다면 소형객체들은 1016개의 프레임이 보내진 후에야 전송될 것이다. 따라서 HTTP/2 프레이밍 메커니즘을 사용함으로써 사용자가 인지하는 지연 시간은 상당히 줄어들 수 있다.
HTTP 메시지를 독립된 프레임들로 쪼개고 인터리빙하고 반대편 사이트에서 재조립하는 것이야말로 HTTP/2의 가장 중요한 개선점이다. 프레이밍은 HTTP/2 프로토콜의 프레임으로 구현된 다른 프레이밍 서브계층에 의해 이루어진다. 서버가 HTTP 응답을 보내고자 할 때, 응답은 프레이밍 서브계층에 의해 처리되며 프레임들로 나눠진다. 응답의 헤더필드는 하나의 프레임이 되며 메시지 본문은 하나의 프레임으로 쪼개진다. 응답프레임들은 서버의 프레이밍 서브계층에 의해 인터리빙된 후 하나의 지속적인 TCP 연결상에서 전송된다. 프레임들이 클라이언트에 도착하면 프레이밍 서브계층에서 처음 응답메시지로 재조립되며 브라우저에 의해 처리된다. 마찬가지로, 클라이언트의 HTTP 요청은 프레임으로 쪼개지고 인터리빙된다.
각 HTTP 메시지를 독립적인 프레임으로 쪼개는 것 외에도 프레이밍 서브계층은 프레임을 바이너리 인코딩한다. 바이너리 프로토콜은 파싱하기에 더 효율적이며, 좀 더 작은 프레임 크기를 갖고, 에러에 더 강건하다.
메시지 우선순위화 및 서버 푸싱
메시지 우선순위화(message prioritization)는 개발자들로 하여금 요청들의 상대적 우선순위를 조정할 수 있게 함으로써 애플리케이션의 성능을 최적화할 수 있게 해준다. 프레이밍 서브계층은 같은 요청자로 향하는 메시지들을 병렬적인 데이터 스트림으로 쪼개준다. 클라이언트가 하나의 특정 서버로 동시에 여러개의 요청을 할 때, 각 메시지에 1에서 256 사이의 가중치를 부여함으로써 요청에 우선순위를 매길 수 있다. 높은 수치일수록 높은 우선순의를 의미한다. 이러한 가중치를 이용하여 서버는 가장 높은 우선순위의 요청을 위한 프레임을 제일 먼저 보낼 수 있다. 클라이언트 역시 각 의존도에 따라 메시지의 ID를 지정함으로써 서로 다른 메시지들 간의 의존성을 나타낼 수 있다.
HTTP/2의 또 다른 특징은 서버로 하여금 특정 클라이언트 요청에 대해 여러개의 응답을 보낼 수 있게 해주는데 있다. 처음 요청에 대한 응답 외에도, 서버는 클라이언트의 요청 없이도 추가적인 객체를 클라이언트에게 푸시하여 보낼 수 있다. 이는 HTML 기반페이지가 웹페이지를 완벽하게 구동시킬 필요가 있는 객체들을 가리킬 수 있기에 가능하다. 이러한 객체에 대한 HTTP 요청을 기다리는 대신 서버는 HTML 페이지를 분석할 수 있으며, 필요한 객체들을 식별할 수 있고, 해당 객체들에 대한 요청이 도착하기도 전에 해당 객체들을 클라이언트로 보낸다. 서버는 해당 요청들을 기다리는 데 소요되는 추가 지연을 없앤다.
HTTP/3
3장에서 다룰 새로운 트랜스포트 프로토콜인 QUIC는 UDP 프로토콜 위에 위치하는 애플리케이션 계층에 구현되어 있다. QUIC는 메시지 멀티플렉싱(인터리빙), 스트림별 흐름 제어, 저지연 ㅇ녀결 확립과 같은 HTTP에 의미 있는 여러 특징을 갖는다. HTTP/3은 QUIC 위에서 작동하도록 설계된 새로운 HTTP 프로토콜로서, 2020년 현재 인터넷 드래프트로 나와 있으나 완전히 표준화된 상태는 아니다. 메시지 인터리빙과 같은 HTTP/2 특징들은 QUIC에 의해 포함되며 HTTP/3을 위한 훨씬 더 간단한 설계를 가능하게 할것이다.
