
Ch1. 데이터 구조
▫️ CRISP-DM : Cross-Industry Stansdard Process for Data Mining
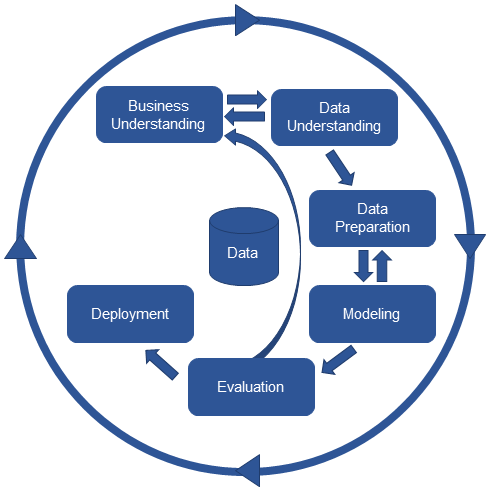
- Business Understanding : 무엇이 문제인가?
- 문제 정의 (평가 지표)
- 분석 목표
- 가설 수립, X -> Y
- Data Understanding : 어디? => 원본 식별 / 가설이 진짜? => 목적(해석)이 중요해
-
EDA : 탐색적 데이터 분석 (그래프, 통계량)
-
CDA : 확증적 데이터 분석 (가설검정, 실험)
-
개별 변수
그래프 통계량 숫자 히스토그램, 박스 플롯, kde plot min, max, mean, std, 사분위수 범주 bar plot 범주별 빈도수 비율 -
가설 X -> Y
-
X1 vs X2
-
-
- Data Preparation : 모델링 하려면 어떤 구조?
- 모든 셀은 값이 있어야/그 값은 숫자/경우에 따라 범위 일치
- Evaluation : 문제 해결된거야?
▫️ 분석할 수 있는 데이터
- 범주형, 질적, 정성적 데이터
- 명목형 데이터
- 순서형 데이터
- 수치형, 양적, 정량적 데이터
- 이산형 데이터
- 연속형 데이터
- 기본이 2차원 (Table, 2차원 Array, Data Frame)
- 행 하나하나가 개별적인 분석 단위, 데이터 한 건, 한 건
- 열은 변수, 요인 (x), 결과 (y)
Ch2. 넘파이 (Numpy)
- 배열에 대한 이해
ex) 3차원 배열 : shape : (2, 3, 5) => 3 x 5 배열이 2개 있다! - Axis 0의 의미 : 분석 단위, 데이터가 몇 개인지
-a.ndim
-a.shape
-a.dtype
-a.reshape(3,4) / a.reshape(m, -1)
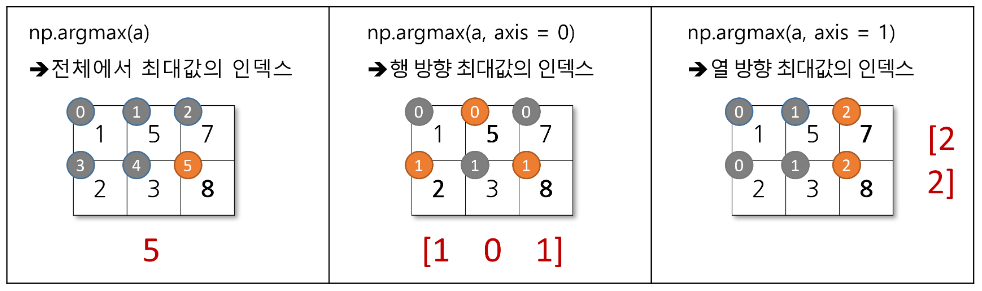
- np.argmax(), np.argmin()
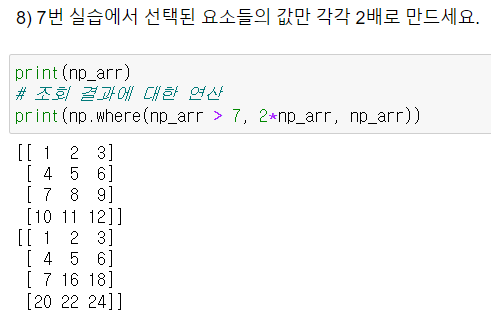
- 조건 걸어서 변경

-열별(axis = 0), 행별(axis = 1) 평균

- arr[ 행, 열 ] => 열은 생략 가능
- 값, 단일 인덱스 arr[2, 3]
- 값, 여러 인덱스 arr[ [ ], [ ] ] => 리스트
- 범위 슬라이싱 2:7 => 2, 3, 4, 5, 6
Ch3. 판다스 (Pandas)
- 데이터프레임 : 2차원 구조
- 시리즈 : 1차원, 열을 떼어낸 것 (하나의 정보를 떼어낸 것)
- csv 파일에서 읽어와 데이터 프레임을 만듦 => 실습
▫️ 자주 사용할 만한 메서드들 - head(): 상위 데이터 확인
- tail(): 하위 데이터 확인

- shape: 데이터프레임 크기 (행, 열 크기) = > 읽는 법 사진 첨부!
- index: 인덱스 정보 확인
- values: 값 정보 확인
- columns: 열 정보 확인
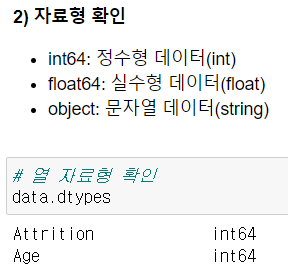
- dtypes: 열 자료형 확인
- info(): 열에 대한 상세한 정보 확인 (열 자료형, 값 개수 확인)
- describe(): 기초통계정보 확인
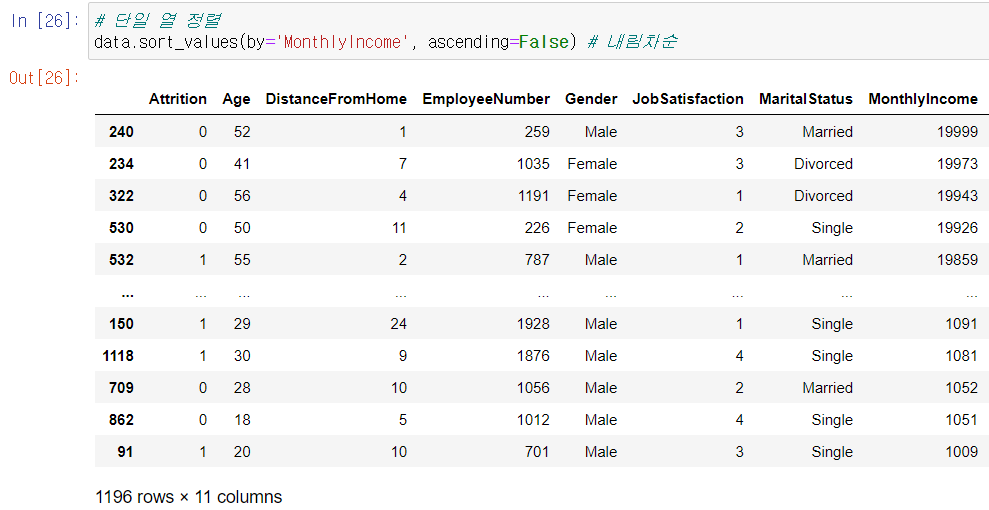
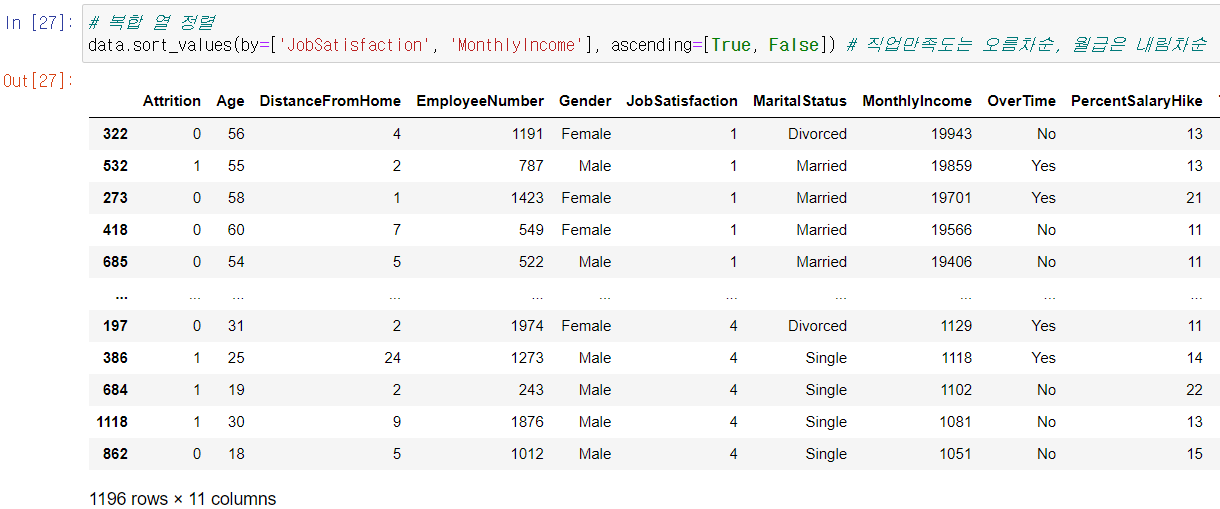
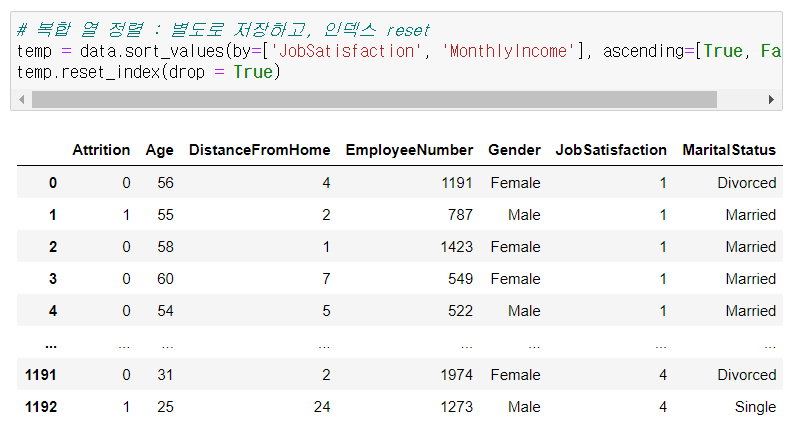
▫️ 정렬
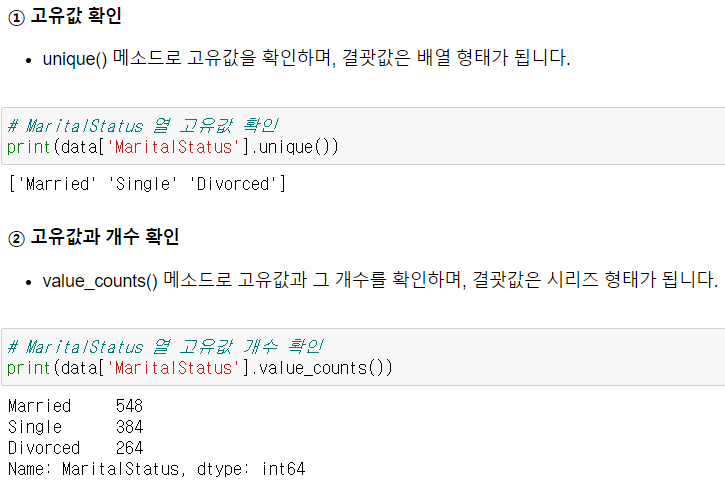
▫️ 기본 집계 - .unique(), .sum(), .max(), mean.(), median.()
Ch4. 데이터프레임 조회 ⭐
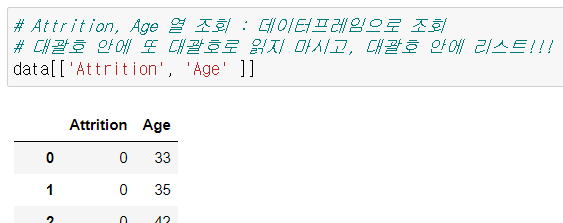
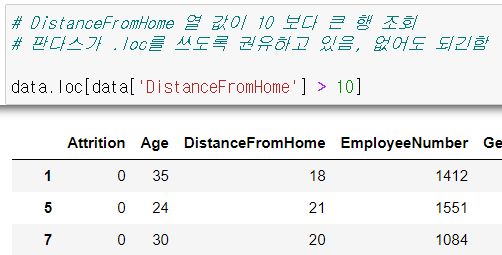
- .loc[조건]
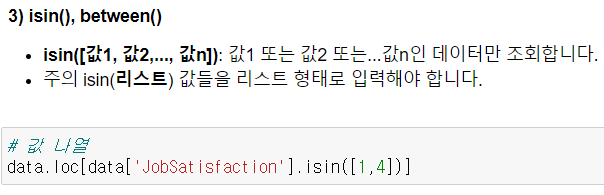

✔ 다음날 수업시간 복습
- 다음 날 복습하는데 예외가 있길래...
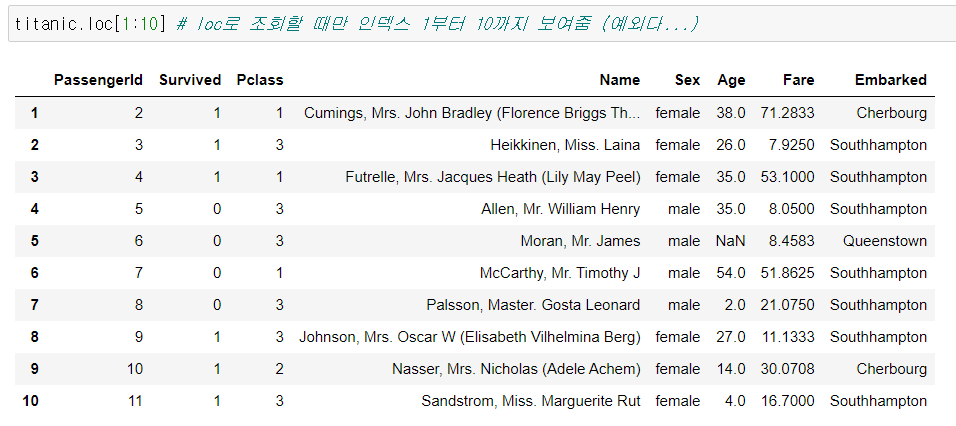
- between 공식 문서 찾아보니...inclusive

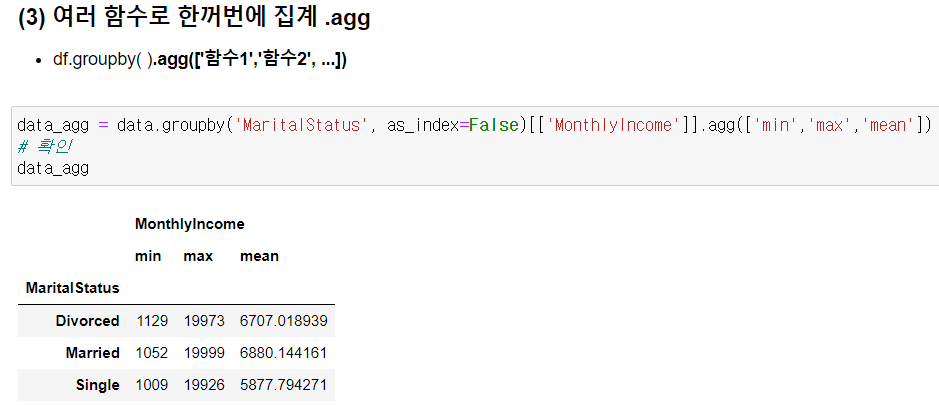
Ch5. 데이터프레임 집계 (2/7 아침 강의)

❄️