

=> 2일차에 데이터분석 방법론 : ADSP / 시각화 라이브러리 += seaborn
Ch1. 분석을 위한 데이터 구조
앞에 챕터에 정리함
Ch2. 데이터프레임 변경
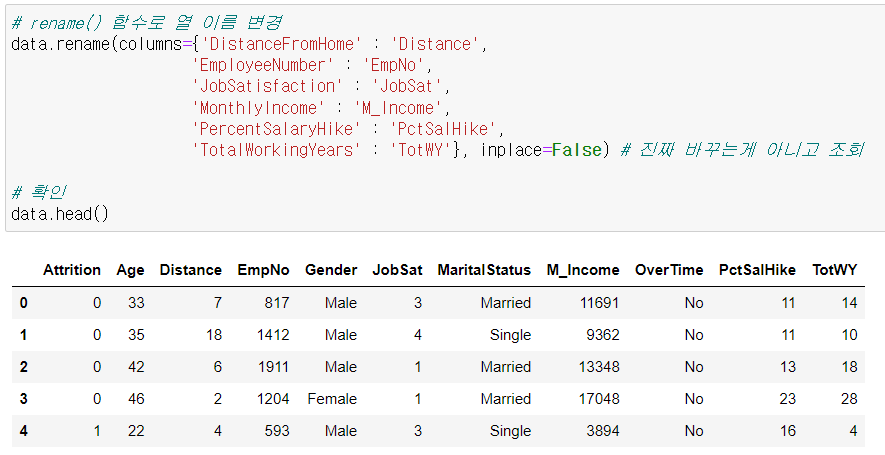
▫️ .rename() 메소드
- 기본값 : inplace = False => 진짜 바꾸는게 아니고 조회
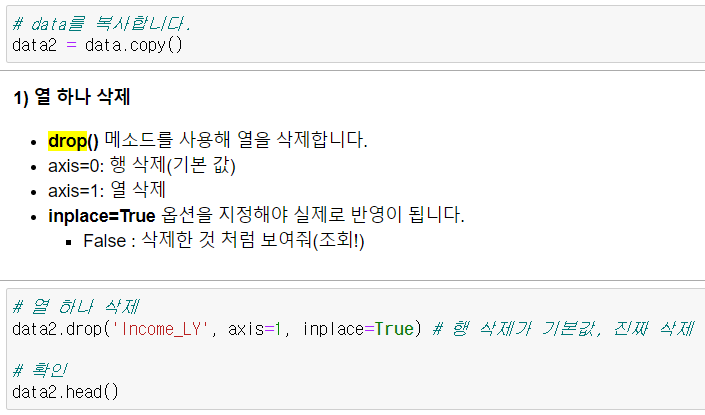
▫️ .drop()
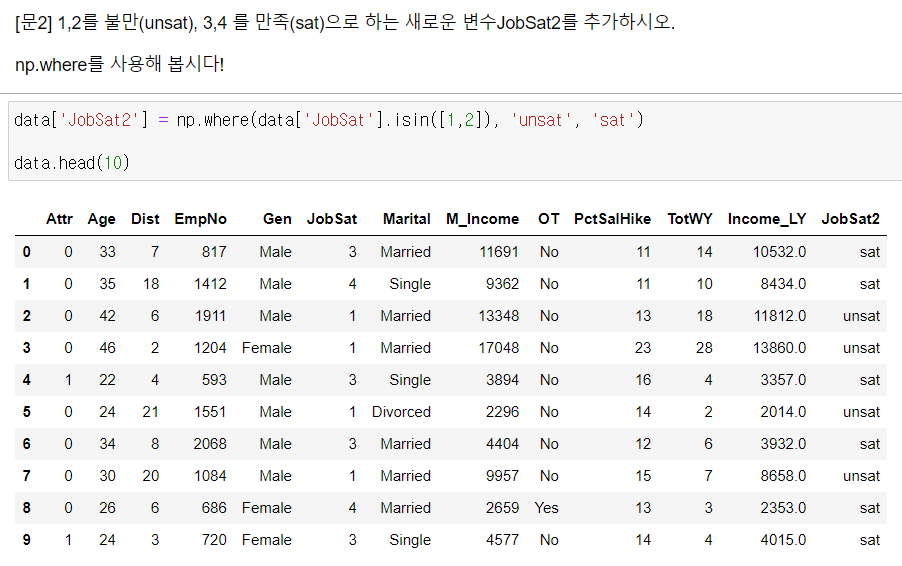
▫️ np.where( )
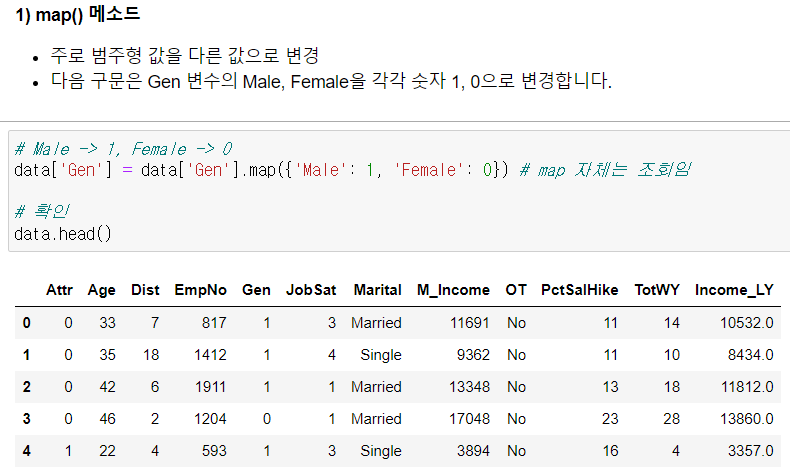
▫️ .map( )
- 주로 범주형 값을 변경할 때
▫️ pd.cut(해당 열, 몇 등분 or bins = [ , , ], label = [' ', ' '])
- 숫자 => 범주

Ch3. 데이터프레임 결합
▫️ pd.concat( [ , ], axis = , join = 'inner' or 'outer')
▫️ pd.merge( , , how = 'inner' or 'left' or 'right', on = ' ' )

▫️ pivot( 인덱스, 열 제목, 값 )
- 집계된 데이터를 재구성
Ch4. 시계열 데이터 처리
▫️ pd.datetime( ).옵션 붙일 수 있음
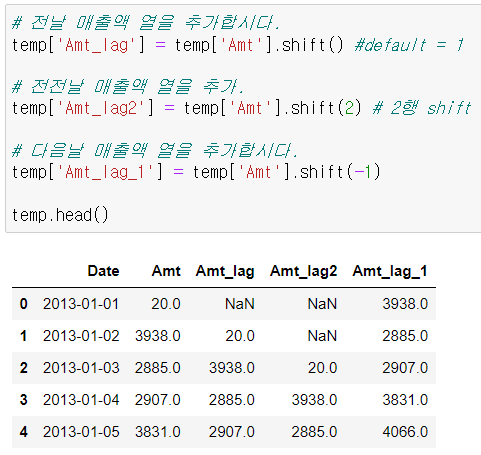
▫️ .shift(얼마나 이동시킬 건지 숫자)
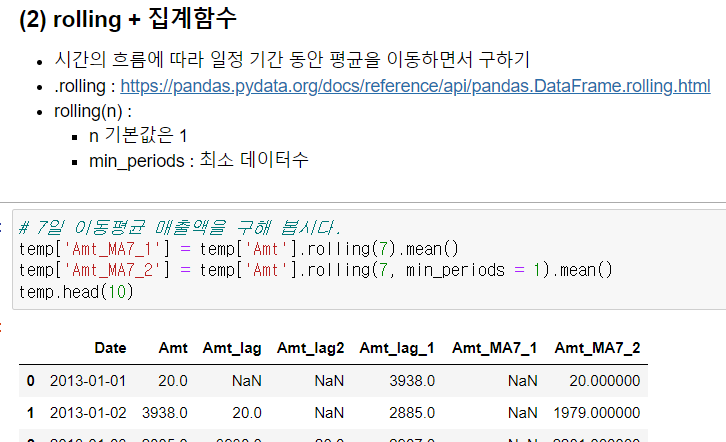
▫️ .rolling().집계함수
Ch5. 데이터분석 방법론
앞에 챕터에 정리함
Ch6. 시각화 라이브러리
▫️ matplotlib과 seaborn 패키지
- plt 옵션 : plt.xticks(rotation = 각도) / .xlabel(' ') / .ylabel(' ') / .title(' ') / .plot(color = , linestlye = , marker = ) / .legend() => 범례추가, 위치 조절 가능 / .grid()
Ch7. 개별 변수 분석 도구 (단변량 분석)
▫️ 숫자형 변수
- 평균, 중위수, 최빈값(mode), 사분위수
- 기초 통계량 : .describe()
▫️ 시각화
- 히스토그램 : plt.hist( , bins = )
- 밀도 함수 : sns.kdeplot(data[' '])
- 박스 플롯 - 반드시 NaN 제거 (sns는 알아서 빼고 그려줌): plt.boxplot( , vert = False or True(세로))
▫️ 범주형 변수
- 범주별 빈도수 : value_counts()
- 범주별 비율 : value_counts() / .shape[0] => 데이터 프레임의 행, 열 수로 나눠줌
▫️ 시각화
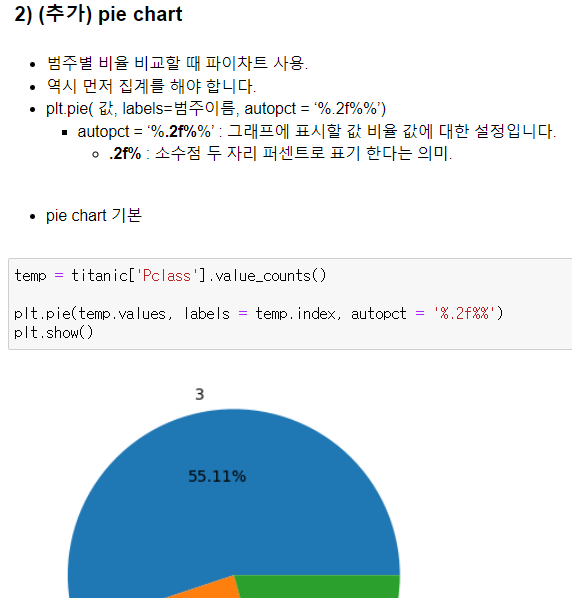
- 바 플롯 : sns.countplot - 범주별 빈도수 계산해서 바플롯으로 나타냄,
plt.bar - 빈도수를 계산한 결과를 입력해야 범주별 빈도가 그려짐
sns.countplot(x = ) - 집계와 barplot을 한번에 그려줌



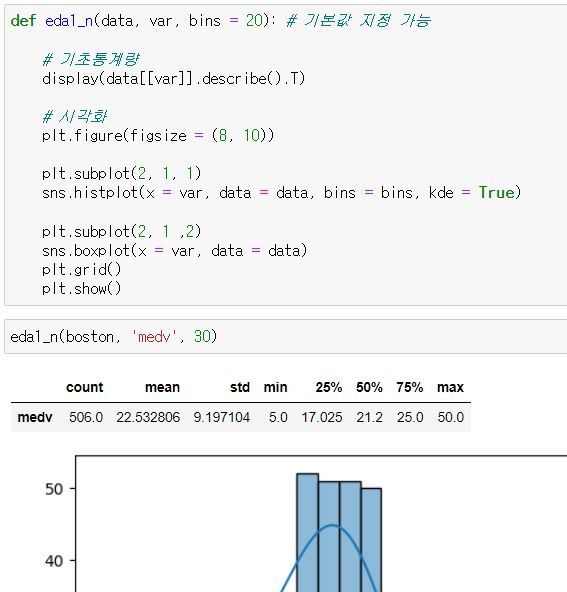
▫️ 단변량 분석, 함수로 한번에
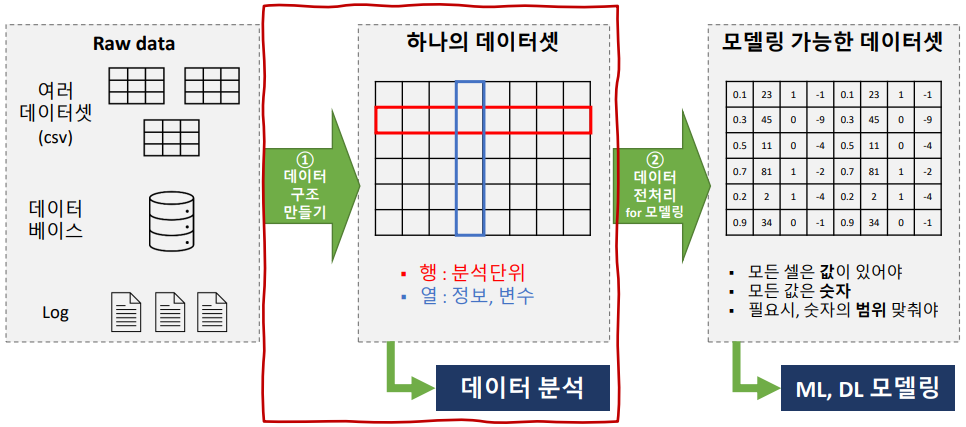
추가자료. 모델링을 위한 데이터 전처리
- 모델링을 위한 최소한의 데이터 전처리 3가지 요건
- 모든 셀에 값이 있어야함
- 모든 값은 숫자이어야함
- 옵션 값의 범위를 일치 시켜야함
- 방법
- 결측치(NaN) 조치
- 범주를 숫자로 변환하는 가변수화
- 범위를 일치시키는 스케일링



❄️