

Ch1. 단변량 분석 종합실습
- 주피터 노트북
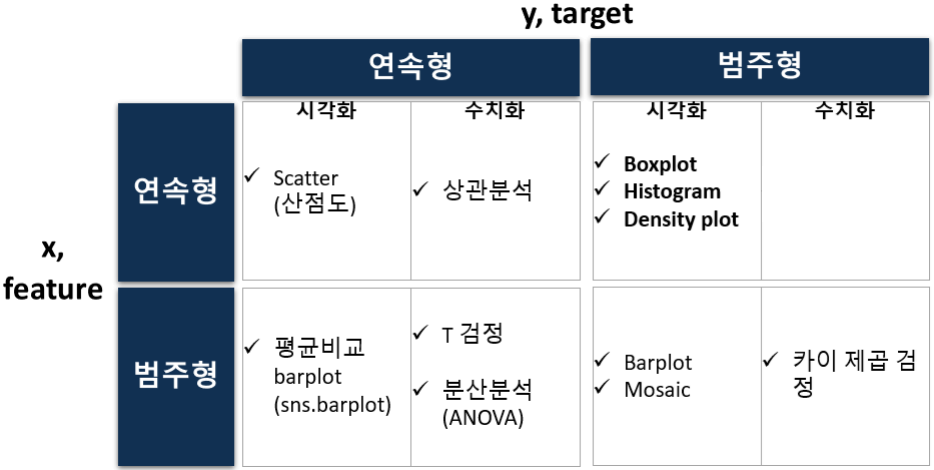
| 숫자 - 1일차 | 1일차 | 범주 | ||
|---|---|---|---|---|
| 그래프 | 통계량 | 그래프 | 통계량 | |
| 도구 | 산점도 | <직선> 상관분석 상관계수, P-value | --- | --- |
| sns.barplot | <평균비교> 2개 - t-test, 3개 - 분산분석(ANOVA) | 모자익플롯 | 기대빈도로부터의 차이 : 카이제곱검정 |
Ch2. 숫자 -> 숫자
▫️ 시각화 - 산점도 :
- sns.sctterplot(x = ,y = ,data = )
- plt.scatter(, , ), sns.partplot() <- 한꺼번에 다 그려주는데 시간 너무 오래걸려서 별로 안씀
- sns.joinplot(,, ) <- 산점도랑 히스토그램을 한번에 보여줌, - sns.replot(,, ) <- 산점도와 직선을 같이 그려줌
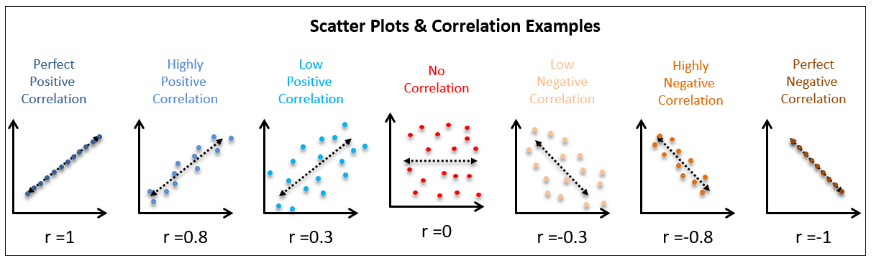


▫️ 수치화 - 상관분석 : .corr() <- 데이터프레임 전체를 한번에 상관계수 구할 수 있음
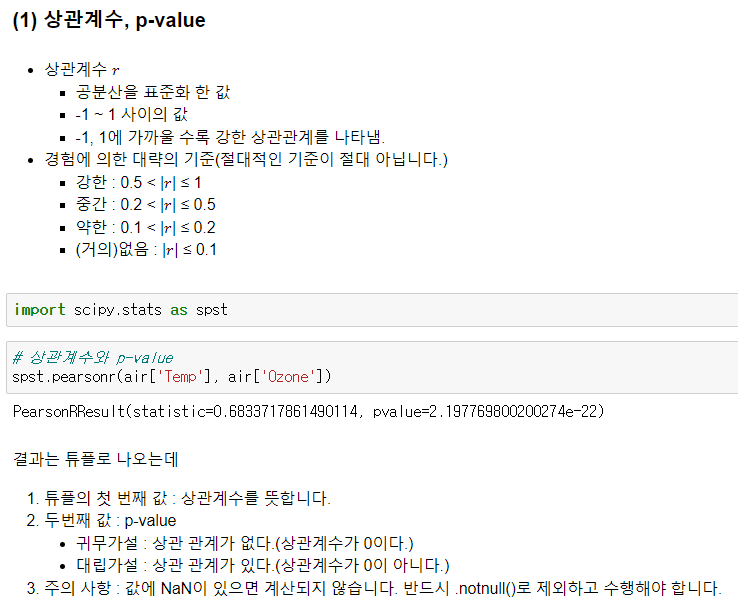

- 질문사항

- 상관계수의 한계 : 직선의 관계(선형관계)만 수치화 해줌 / 직선의 기울기, 비선형 관계는 고려하지 X
Ch3. 범주 -> 숫자 : 범주별 평균 비교
▫️ 시각화 : 두 집단(범주) -> 숫자
- sns.barplot(x = , y = , data = ) <- 신뢰도가 같이 나옴
- sns,boxplot(x = , y = , data = )
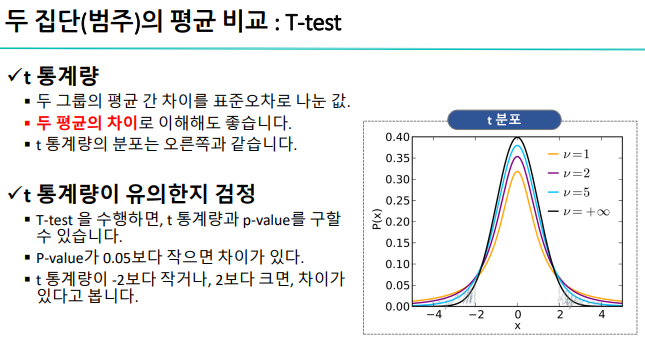
▫️ 수치화 : 두 집단(범주) -> 숫자
- t-test

- NaN이 있는지 확인 : titanic.isna().sum()
- 있으면 제거 : temp = titanic.loc[titanic['Age'].notnull()]
- 두 그룹으로 데이터 저장 :
died = temp.loc[temp['Survived']==0, 'Age']
survived = temp.loc[temp['Survived']==1, 'Age'] - t-test: ttest_ind(B, A, equal_var = False(default)<- A와 B의 분산이 같은가? 모르는 것이 기본값)

- t통계량
쉽게 설명ㅋㅋ
▫️ 시각화 : 세 개 이상의 집단(범주) -> 숫자
- sns.barplot(x = , y = , data = )
- anova : f_conway(A, B, C) <- 전체 평균 대비 각 그룹 간 차이가 있는지만 알려주고 어느 그룹 간에 차이가 있는 지는 알 수 없음, 그래서 보통 사후분석을 진행함

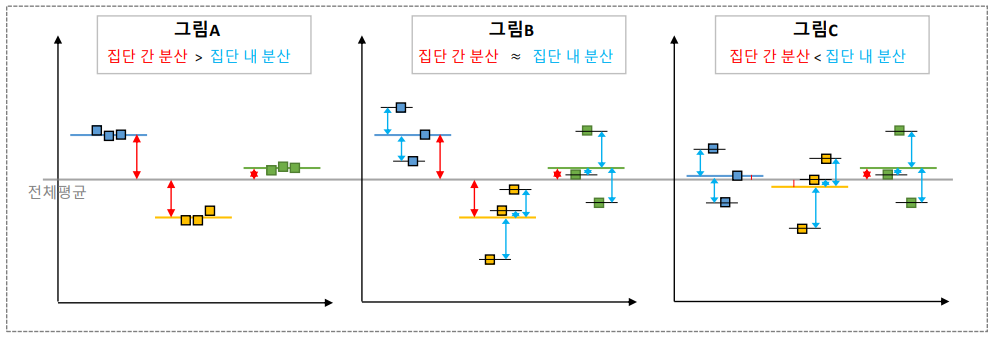
Ch4. 범주 -> 범주
▫️ 교차표
Ch5. 숫자 -> 범주
▫️
추가자료
▫️

❄️