
인덱스란?
인덱스는 데이터베이스 테이블의 조회 속도를 높이기 위해 고안된 자료구조이다.
쉽게 말해서 사전에서의 색인, 목차라고 생각하면 된다.
색인에는 [내용 : 페이지 번호]가 저장 되어있다. 인덱스도 마찬가지다. [컬럼 데이터 : 메모리 위치]가 인덱스에 저장된다.
인덱스 자료구조인덱스 자료구조
MySQL 기준 인덱스 자료구조는 B-Tree이다.
이진탐색트리(Binary Search Tree)
우선 이진탐색트리를 알아야하는데,
이진탐색트리는 이진탐색과 연결리스트를 결합한 자료구조이다.
이진탐색의 빠른 탐색 속도와 연결리스트의 빈번한 자료 입력, 삭제가 가능하게끔 고안되었다.

사진 출처 (https://ahribori.com/article/5948bf09b24df70e383033e8)
이진탐색트리의 특징
- 내부적으로, 왼쪽 노드는 루트보다 작고 오른쪽 노드는 루트보다 크게 정렬되어있다.
- 중복데이터 허용 안함
- 왼쪽 서브트리, 오른쪽 서브트리 또한 이진탐색트리
- 노드 검색 / 삽입 / 삭제 시간복잡도 O(logN)
그런데

사진 출저(https://lgphone.tistory.com/90)
위의 사진처럼 한 쪽으로 편향된 트리 모양이 된다면 연결 리스트랑 모양이 같아지므로 최악의 경우 시간복잡도가 O(N)이된다.
개선해야함을 느끼고 균형 이진탐색트리가 나왔고 그 중에 B-Tree를 설명하겠다.
B-Tree
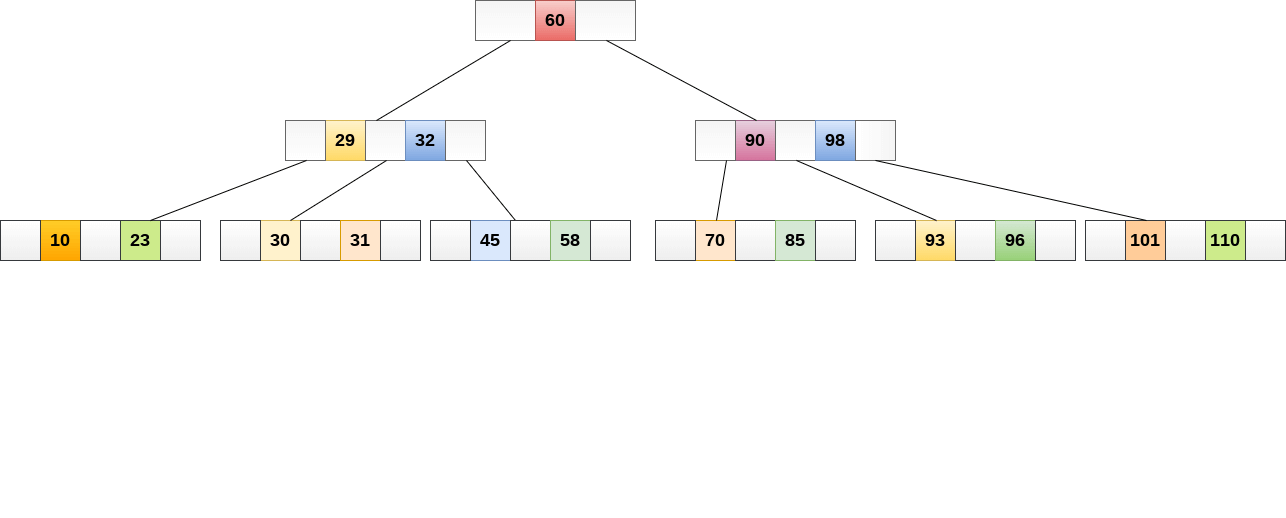
사진 출처(https://velog.io/@jewelrykim/Binary-Search-Tree에서-BTree까지Database-Index-추가)
탐색 성능을 높이기 위해 균형 있게 높이를 유지하는 Balanced Tree의 일종이다.
이진탐색트리와 비슷하게 왼쪽은 루트보다 작은 값, 오른쪽은 루트보다 큰 값 으로 정렬되어있다.
대표적인 특징으로는,
- 자식 노드의 개수가 2개 이상이다.
- 노드 내 key가 1개 이상일 수 있다.
- 모든 leaf 노드가 같은 level로 유지되도록 자동으로 밸런스를 맞춘다.
그래서 시간복잡도가 최악의 경우에도 O(logN)을 보장한다.
허나 B-Tree도 아쉬운게 있다.
- 트리 균형을 위해서 복잡한 연산이 필요하다.
- 중위순회를 하기 때문에, 순차탐색 시 비효율적이다.
개선해야함을 느끼고 B+Tree가 나왔다.
B+Tree

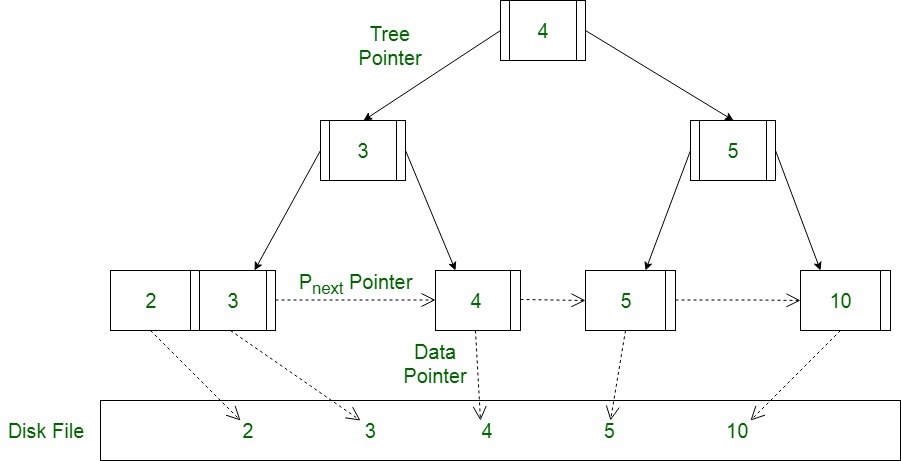
B+Tree는 오직 leaf노드에만 데이터를 저장하고 leaf 노드가 아닌 노드에서는 자식 포인터만 저장한다. leaf 노드 외에는 데이터에 빠른 접근을 위한 인덱스 역할만 수행한다.
대표적인 특징으로는,
- leaf 노드들은 연결리스트 형태로 서로 연결되어있으며 오름차순 정렬되어있다.
따라서 순차 탐색, 범위 탐색에 매우 유리하다. - leaf 노드를 제외하고는 데이터를 저장안하기 때문에 메모리 더 확보된다. 따라서 하나의 노드에 더 많은 포인터를 가질 수 있어서 트리의 높이가 낮아지고 검색속도를 높일 수 있다.
- 무조건 leaf노드까지 가야 데이터가 있다. 최악의 시간복잡도는 logN이다.
인덱스 사용시 장단점
장점
- 빠른 검색/조회 속도 향상
실제 서비스에서 요청되는 메소드중에 80퍼센트 가량이 조회 메소드라고 한다. 즉 데이터를 조회하고 검색하는 작업이 가장 많이 일어난다는 뜻. 인덱스를 이용해서 조회/검색 속도를 빠르게 할 수 있다.
단점
-
인덱스 데이터를 담을 추가 저장공간이 필요 (DB의 10%정도 해당하는 공간이 필요)
-
조회속도가 빨라지는 반면, INSERT, DELETE, UPDATE의 작업의 성능을 다소 희생해야함. INSERT, DELETE, UPDATE 과정시 인덱스의 B-Tree구조를 변경하는 리소스가 듦
-
무엇보다 인덱스는 잘 써야지 좋은거다. 못쓰면 오히려 성능이 떨어질수도 있다.
인덱스 사용시 고려할 점
3가지 기준을 고려해야한다.
- 카디널리티 (Cardinality)
중복이 없는 정도를 나타내는 값인데, 높을수록 한 컬럼이 갖고있는 데이터에 중복이 없다는 뜻 - 선택도 (Selectivity)
특정값을 얼마나 잘 골라낼 수 있는지에 대한 지표로 (카디널리티 / 총 레코드수) * 100
쉽게말하면, 전체 레코드와 조건절에 의해 선택될 예상 레코드 수의 비율이다. 5~10% 비율이 적당하다고 한다. - 활용도
카디널리티나 선택도가 별로 좋지 않더라도, 데이터가 빈번하게 호출되고 인덱스를 써서 조금이라도 개선됨이 보이면 쓰는거다.
외에도 ORDER BY, GROUP BY 작업을 위해 인덱스를 사용하기도 한다.
그럼 인덱스 한 번 써보자!
Tool : MySQL workbench 8.0.31
우선 더미데이터 부터 만들어보자
파이썬에 더미데이터를 만들때 쓰는 Faker 라이브러리를 사용했다.
import random
from faker import Faker
fake = Faker()
with open('index10000.txt', 'w') as f:
for i in range(1, 10001):
country = fake.country()
city = fake.city()
name = fake.name()
email = fake.unique.email()
phone_number = fake.unique.phone_number()
age = random.randint(9, 85)
gender = random.choice(['Female', 'Male'])
date = fake.date()
new_str = f"{i}\t{country}\t{city}\t{name}\t{email}\t{phone_number}\t{age}\t{gender}\t{date}\n"
f.write(new_str)txt 파일로 출력되며,
번호, Country, City, Name, Email, Phone, Age, gender, Date
9가지 정보의 더미데이터를 만들어주었고 각각 데이터들은 ‘\t’을 기준으로 구분되게 했다.
Email과 Phone데이터는 중복이 없을테니 unique옵션을 주었다.
1 Falkland Islands (Malvinas) North Tylerborough Dana Mills drewwalton@example.org 001-013-846-1564x839 18 Male 1998-05-24
2 Papua New Guinea Hortonhaven Cynthia Weiss frances86@example.com +1-397-376-5730x87029 61 Male 2007-10-28
3 Niger Port Tiffanyberg Sandra Miranda christinaenglish@example.org 364-723-0969x9546 36 Female 1981-11-07
4 Israel Michelleberg Maria Graham mstewart@example.com (353)592-9201x59263 13 Male 1985-04-23
5 Netherlands West Tanya Tonya Miller towens@example.net 505-282-6047 62 Male 2006-10-19
6 Paraguay Connerview Paul Johnson wendylawson@example.org 788.232.2633x4366 27 Male 2008-06-09
7 Mauritania Taraview Ann Frye edwardgardner@example.net 243.574.7589 68 Female 2001-12-04
...데이터는 100개, 1,000개, 10,000개, 100,000개, 1,000,000개 총 5가지의 더미데이터로 이루어져있다.
(천 만까지 하려했는데 Faker가 이메일 데이터에서 유니크하게 뽑을 수 있는 경우의 수가 천 만을 넘기지 못했다…)
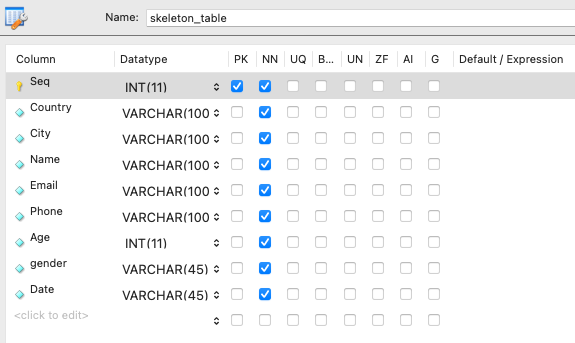
workbench에서, 데이터가 저장될 테이블 뼈대코드를 만들어주었다.
ALTER TABLE `indextest`.`skeleton_table`
ADD INDEX `ageAndName_index` (`Age` ASC, `Name` ASC) VISIBLE,
ADD INDEX `email_index` (`Email` ASC) VISIBLE,
ADD INDEX `phone_index` (`Phone` ASC) VISIBLE,
ADD INDEX `gender_index` (`gender` ASC) VISIBLE,
ADD INDEX `date_index` (`Date` ASC) VISIBLE;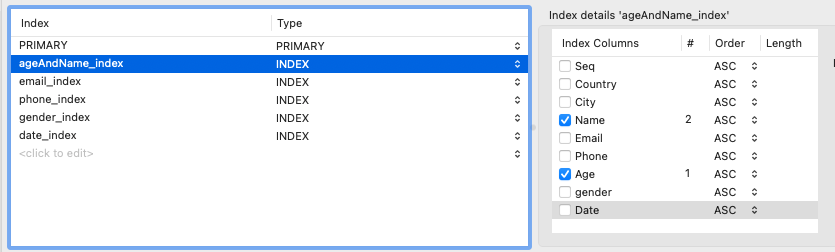
인덱스도 추가해주었다. 특히 오른쪽 ageAndName_index 에서 인덱스 컬럼을 선택해줄 때는 순서를 잘 정해야한다. 첫 번째 키가 정렬되고 두 번째 키는 첫 번째 키에 의존하여 정렬하기 때문이다.
SHOW INDEX FROM index100000;
인덱스가 잘 들어간것을 확인할 수 있다.
CREATE TABLE `만들 테이블` LIKE `복사 될 테이블`;
EX)
CREATE TABLE `index1000` LIKE `skeleton_table`;
테이블 복사 SQL로 위와 같이 테이블들을 생성해주었다.
이제 txt파일에 담긴 내용들을 테이블에 넣어주자!
LOAD DATA INFILE '/절대경로/index1000000.txt' INTO TABLE index1000000
CHARACTER SET 'utf8'
FIELDS TERMINATED BY '\t'
ENCLOSED BY "" LINES TERMINATED BY '\n';위의 SQL을 통해서 테이블에 데이터를 넣어주었다.
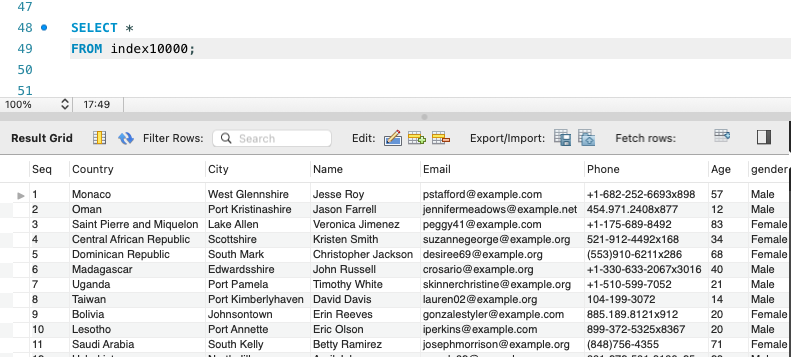
데이터가 잘 들어간걸 확인할 수 있다.
인덱스 재생성 해준다.
ANALYZE TABLE index10000핵심 포인트
- 데이터 개수가 적을 때, 많을 때 인덱스 사용 효과 비교
- 인덱스를 사용했을 때와 안했을 때의 비교
위 두 가지를 큰 틀로 하여 실험을 진행할 것이다.
주로 사용할 쿼리는
-- 쿼리 캐시 초기화 코드인데 이 부분은 좀 더 알아봐야함
SHOW GLOBAL STATUS LIKE 'Qc%';
SET GLOBAL query_cache_size = 1024 * 1024 * 1000;
-- 현재 테이블의 인덱스 정보 보기
SHOW INDEX FROM index100;
-- 단 건 조회 인덱스 미사용
EXPLAIN
SELECT *
FROM index100 IGNORE INDEX(email_index)
WHERE Email = 'gdiaz@example.org';
-- 단 건 조회 인덱스 사용
EXPLAIN
SELECT *
FROM index100 FORCE INDEX(email_index)
WHERE Email = 'gdiaz@example.org';
-- =======================================
-- range 조회 인덱스 미사용
EXPLAIN
SELECT *
FROM index100 IGNORE INDEX(date_index)
WHERE Date BETWEEN '2002-09-01' AND '2019-08-14';
-- range 조회 인덱스 사용
EXPLAIN
SELECT *
FROM index100 FORCE INDEX(date_index)
WHERE Date BETWEEN '2002-09-01' AND '2019-08-14';
-- =======================================
-- 다중 컬럼 인덱스 미사용
EXPLAIN
SELECT *
FROM index100 IGNORE INDEX(ageAndName_index)
WHERE Age = '42' AND Name = 'Mary Kaiser';
-- 다중 컬럼 인덱스 사용
EXPLAIN
SELECT *
FROM index100 FORCE INDEX(ageAndName_index)
WHERE Age = '42' AND Name = 'Mary Kaiser';
SHOW profiles;힌트를 주어서 인덱스를 사용했을때와 안했을 때를 구분해줄것이다.
100건 데이터
SHOW INDEX FROM index100;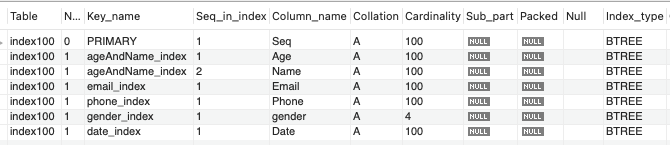
100건의 데이터에서는 성별을 제외하고 카디널리티가 전부 100이 나왔는데, 아무래도 데이터 크기가 작아서인듯 하다.
단 건 조회 인덱스 X
EXPLAIN
SELECT *
FROM index100 IGNORE INDEX(email_index)
WHERE Email = 'gdiaz@example.org';
type이 ALL이다. rows 100으로 풀 테이블 스캔하였다.
단 건 조회 인덱스 O
EXPLAIN
SELECT *
FROM index100 FORCE INDEX(email_index)
WHERE Email = 'gdiaz@example.org';
type이 ref 이며 rows 는 1이다. email_index를 사용했다.
range 조회 인덱스 사용 X
EXPLAIN
SELECT *
FROM index100 IGNORE INDEX(date_index)
WHERE Date BETWEEN '2002-09-01' AND '2019-08-14';
풀 테이블 스캔한것을 알 수 있다.
range 조회 인덱스 사용 O
EXPLAIN
SELECT *
FROM index100 FORCE INDEX(date_index)
WHERE Date BETWEEN '2002-09-01' AND '2019-08-14';
type이 range로 되어있고 rows가 35이다. '2002-09-01' AND '2019-08-14' 사이에 데이터가 35개가 있나보다.
다중 컬럼 인덱스 사용 X
EXPLAIN
SELECT *
FROM index100 IGNORE INDEX(ageAndName_index)
WHERE Age = '42' AND Name = 'Mary Kaiser';
풀 테이블 스캔 확인
다중 컬럼 인덱스 사용 O
EXPLAIN
SELECT *
FROM index100 FORCE INDEX(ageAndName_index)
WHERE Age = '42' AND Name = 'Mary Kaiser';
type이 ref이며 인덱스를 사용했다.
SET PROFILING=1;
SHOW PRIFILES;
위의 SQL을 실행하면 시간이 나오는데 사실 별 차이가 없다. 데이터 개수가 작아서 그런것 같다.
range 탐색의 경우 힌트 없이 사용했을 때 옵티마이저는 풀 스캔을 택했다.
1,000건 데이터
SHOW INDEX FROM index1000;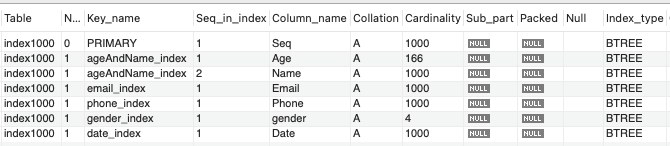
age 속성에서 카디널리티가 낮아졌다. 다른 부분에서는 아직 중복이 없다.
단 건 조회 인덱스 X
EXPLAIN
SELECT *
FROM index1000 IGNORE INDEX(email_index)
WHERE Email = 'samantha27@example.net';
단 건 조회 인덱스 O
EXPLAIN
SELECT *
FROM index1000 IGNORE INDEX(email_index)
WHERE Email = 'samantha27@example.net';
힌트 없이 쿼리문을 돌려도 옵티마이저가 알아서 인덱스를 사용한다.
range 조회 인덱스 사용 X
EXPLAIN
SELECT *
FROM index1000 IGNORE INDEX(date_index)
WHERE Date BETWEEN '1990-06-10' AND '2006-06-18';
range 조회 인덱스 사용 O
EXPLAIN
SELECT *
FROM index1000 FORCE INDEX(date_index)
WHERE Date BETWEEN '1990-06-10' AND '2006-06-18';
힌트 없이 돌린 결과, 옵티마이저는 풀 테이블 스캔을 택했다.
'1990-06-10' AND '2006-06-18' 의 범위가 레코드의 20~25% 를 넘어서 옵티마이저가 풀 테이블 스캔을 선택한것이라 추측한다.
다중 컬럼 인덱스 사용 X
EXPLAIN
SELECT *
FROM index1000 IGNORE INDEX(ageAndName_index)
WHERE Age = '23' AND Name = 'Christopher Jordan';
다중 컬럼 인덱스 사용 O
EXPLAIN
SELECT *
FROM index1000 FORCE INDEX(ageAndName_index)
WHERE Age = '23' AND Name = 'Christopher Jordan';
힌트 없이 실행한 결과 옵티마이저는 다중 컬럼 인덱스를 택했다.
사실 카디널리티가 매우 높기에 당연한 결과 일 것 같다.
SET PROFILING=1;
SHOW PRIFILES;
인덱스를 사용한 쿼리가 좀 더 빠르긴하다. 그러나 엄청 뛰어나게 빠르다고 볼 수는 없다.
10,000건 데이터
SHOW INDEX FROM index10000;
카디널리티가 10077로 나와서 무언가 이상함을 느꼈다.
그래서 직접 개수를 세어 보았다.
SELECT
Count(DISTINCT Name) `Name 개수`,
COUNT(DISTINCT Email) `Email 개수`,
COUNT(DISTINCT Phone) `Phone 개수`,
COUNT(DISTINCT Age) `Age 개수`,
COUNT(DISTINCT Date) `Date 개수`
FROM index10000;
10000줄 짜리 데이터 그리고 Age가 77인데 무언가 관련 있을것 같다. 카디널리티를 어떻게 계산하는지 좀 더 찾아봐야겠다.
단 건 조회 인덱스 X
EXPLAIN
SELECT *
FROM index10000 IGNORE INDEX(email_index)
WHERE Email = 'goodmanwendy@example.net';
단 건 조회 인덱스 O
EXPLAIN
SELECT *
FROM index10000 IGNORE INDEX(email_index)
WHERE Email = 'goodmanwendy@example.net';
range 조회 인덱스 사용 X
EXPLAIN
SELECT *
FROM index10000 IGNORE INDEX(date_index)
WHERE Date BETWEEN '2016-10-25' AND '2022-07-06';
range 조회 인덱스 사용 O
EXPLAIN
SELECT *
FROM index10000 FORCE INDEX(date_index)
WHERE Date BETWEEN '2016-10-25' AND '2022-07-06';
다중 컬럼 인덱스 사용 X
EXPLAIN
SELECT *
FROM index10000 IGNORE INDEX(ageAndName_index)
WHERE Age = '50' AND Name = 'Karen Conrad';
다중 컬럼 인덱스 사용 O
EXPLAIN
SELECT *
FROM index10000 FORCE INDEX(ageAndName_index)
WHERE Age = '50' AND Name = 'Karen Conrad';
SET PROFILING=1;
SHOW PRIFILES;
range 탐색을 제외 하고는 10배 정도 속도 차이가 발생한다.
멋대로 생각해보자면 range 탐색은 '2016-10-25' 데이터 부터 선형적으로 탐색하는 시간때문에 다른 인덱스 보다 조금 느린이유가 되지 않을까 싶다.
100,000건 데이터 (십만)
SHOW INDEX FROM index100000;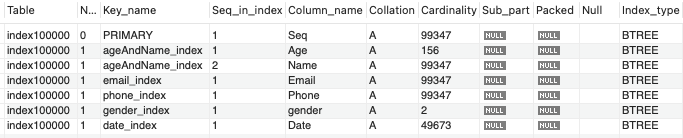
SELECT
Count(DISTINCT Name) `Name 개수`,
COUNT(DISTINCT Email) `Email 개수`,
COUNT(DISTINCT Phone) `Phone 개수`,
COUNT(DISTINCT Age) `Age 개수`,
COUNT(DISTINCT Date) `Date 개수`
FROM index10000;
이메일과 전화번호를 제외한 정보들은 중복이 꽤 있다.
단 건 조회 인덱스 X
EXPLAIN
SELECT *
FROM index100000 IGNORE INDEX(email_index)
WHERE Email = 'cardenasmichelle@example.net';
단 건 조회 인덱스 O
EXPLAIN
SELECT *
FROM index100000 FORCE INDEX(email_index)
WHERE Email = 'cardenasmichelle@example.net';
range 조회 인덱스 사용 X
EXPLAIN
SELECT *
FROM index100000 IGNORE INDEX(date_index)
WHERE Date BETWEEN '2015-09-24' AND '2019-05-09';
range 조회 인덱스 사용 O
EXPLAIN
SELECT *
FROM index100000 FORCE INDEX(date_index)
WHERE Date BETWEEN '2015-09-24' AND '2019-05-09';
다중 컬럼 인덱스 사용 X
EXPLAIN
SELECT *
FROM index100000 IGNORE INDEX(ageAndName_index)
WHERE Age = '70' AND Name = 'Anthony Abbott';
다중 컬럼 인덱스 사용 O
EXPLAIN
SELECT *
FROM index100000 FORCE INDEX(ageAndName_index)
WHERE Age = '70' AND Name = 'Anthony Abbott';
SET PROFILING=1;
SHOW PRIFILES;
range 조회를 제외 하고는 약 200배 정도 차이가 나는것을 볼 수 있다. 데이터 개수가 많아질수록 인덱스의 효과가 커짐을 알 수 있었다.
range 조회는 왜 차이가 많이 없을까 이유를 생각해봤더니, 현재 Data 컬럼의 카디널리티가 좋지 못하다!!

10만건 중에서 19334건이 Unique하다는 뜻이므로 데이터의 중복도가 꽤 높다고 생각된다.

힌트 없이 실행했을 때도 옵티마이저가 인덱스를 활용하는 것을 보면, 탐색한 row수가 13802줄로, 전체 레코드의 20~25%를 넘지 않고 일단 실행속도가 풀테이블 스캔보다는 빠르기 때문이 아닐까 싶다.
그래서 Date의 기간을 더 넓게 줘봤다.
EXPLAIN
SELECT *
FROM index100000 FORCE INDEX(date_index)
WHERE Date BETWEEN '1970-09-06' AND '2022-11-15';
rows가 약 5만건이므로 힌트 없이 실행해보면
EXPLAIN
SELECT *
FROM index100000
WHERE Date BETWEEN '1970-09-06' AND '2022-11-15';
옵티마이저는 인덱스 풀 스캔을 하는 것을 볼 수 있다.

인덱스 X > 인덱스 풀 스캔 > 인덱스 range 스캔 순으로 속도가 빠르다
속도로만 따진다면 그냥 풀 테이블 스캔하는것이 좋다고 보이나, 인덱스 풀 스캔을 하는 경우 정렬된 데이터를 받기때문에,
기간의 의미가 중요한 Date 컬럼의 경우는 인덱스 풀 스캔을 하는 것이 더 맞다고 생각한다.
1,000,000건 데이터 (백만)
SHOW INDEX FROM index1000000;

Name과 Date에서 카디널리티가 많이 떨어졌다.
단 건 조회 인덱스 X
EXPLAIN
SELECT *
FROM index1000000 IGNORE INDEX(email_index)
WHERE Email = 'connerjasmine@example.net';
단 건 조회 인덱스 O
EXPLAIN
SELECT *
FROM index1000000 FORCE INDEX(email_index)
WHERE Email = 'connerjasmine@example.net';
range 조회 인덱스 사용 X
EXPLAIN
SELECT *
FROM index1000000 IGNORE INDEX(date_index)
WHERE Date BETWEEN '1972-01-19' AND '2001-09-11';
range 조회 인덱스 사용 O
EXPLAIN
SELECT *
FROM index1000000 FORCE INDEX(date_index)
WHERE Date BETWEEN '1972-01-19' AND '2001-09-11';
다중 컬럼 인덱스 사용 X
EXPLAIN
SELECT *
FROM index1000000 IGNORE INDEX(ageAndName_index)
WHERE Age = '28' AND Name = 'Brian Medina';
다중 컬럼 인덱스 사용 O
EXPLAIN
SELECT *
FROM index1000000 FORCE INDEX(ageAndName_index)
WHERE Age = '28' AND Name = 'Brian Medina';
SET PROFILING=1;
SHOW PRIFILES;
단 건 조회의 경우 500배 정도 빨라졌으며, 멀티 컬럼의 경우 약 1000배 정도 빨라졌다.
오히려 range 조회는 인덱스를 사용한게 더 느렸다.

이번에는 인덱스 X > 인덱스 range 스캔 >= 인덱스 풀 스캔 순으로 속도가 빠르다.
EXPLAIN
SELECT *
FROM index1000000
WHERE Date BETWEEN '1972-01-19' AND '1976-06-01';

date 범위를 줄여주었으나 인덱스 풀 스캔 > 인덱스 range > 인덱스 X 순으로 속도가 빨랐으며 옵티마이저는 인덱스 풀 스캔을 택했다.
조회 rows의 수도 레코드의 20~25% 를 넘지 않았지만 인덱스 풀 스캔한 이유는 카디널리티가 낮아서 이지 않을까 싶다.
결론
- 데이터 개수가 적을 때, 많을 때 인덱스 사용 효과 비교
데이터 수가 많을수록 인덱스를 사용한 효과가 커진다.
초반 1000건 데이터에서는 4~5배 정도 속도가 빠르다가
후반 1000000건 데이터에서는 1000배까지도 속도가 빨라졌었다.
데이터의 개수가 많다면 인덱스를 활용하는것이 매우 권장될 것 같다.
- 인덱스를 사용했을 때와 안했을 때의 비교
인덱스를 잘 적용했을 때 확실히 속도가 빨라지나, 잘 적용해야한다는게 무엇보다 중요한걸 알 수 있었다.
앞으로 개발하면서 카디널리티, 선택도, 활용성 등등 세가지를 고려해보고 비교해보면서 인덱스를 활용할 것이다.
Reference
- https://ratsgo.github.io/data structure&algorithm/2017/10/22/bst/
- https://fierycoding.tistory.com/78
- https://velog.io/@jewelrykim/Binary-Search-Tree에서-BTree까지Database-Index-추가
- https://yurimkoo.github.io/db/2020/03/14/db-index.html
- https://stir.tistory.com/236#�%-D%B-�%-D%B-�%-A%A-%--�%B-%--�%B-%--�%--%--�%B-%B-
- https://velog.io/@chosj1526/DB-Index-개념-장단점-자료구조
- Real MySQL 8.0 1권
