들어가며
지난 글에서는 Vector DB와 임베딩을 다뤘다. 텍스트를 숫자 배열로 변환해서 의미 기반 유사도 검색을 할 수 있다는 것, 그리고 기존 LIKE 검색이 왜 의미 파악에 한계가 있는지를 살펴봤다.
이번 글에서는 그 Vector DB를 실제로 활용하는 패턴인 RAG를 다룬다. 글을 읽으면서 다음 세 가지 질문에 답할 수 있게 된다.
- LLM은 왜 혼자 두면 위험한가?
- RAG는 내부에서 어떤 순서로 동작하는가?
- Threshold와 프롬프트 설계가 왜 답변 품질을 결정하는가?
1. LLM의 한계 — 왜 RAG가 필요한가
LLM은 학습 데이터를 기반으로 답변한다. 여기에 세 가지 태생적 약점이 있다.
Knowledge Cutoff: 모델이 학습을 마친 시점 이후의 정보는 모른다.
Private Data: 기업 내부 문서, 사내 규정처럼 공개되지 않은 데이터는 학습 데이터에 포함되지 않는다.
Hallucination: 모르는 내용에 대해 아는 척 그럴듯하게 지어내는 현상이다.
사용자: "우리 회사 연차는 몇 일이에요?"
LLM: "죄송하지만 귀사의 내부 정책은 알 수 없습니다."RAG는 이 문제를 정면으로 해결한다. LLM에게 오픈북 테스트를 허용하는 것이다.
머릿속 기억에만 의존하지 않고, 옆에 놓인 참고서를 보고 답하게 만든다.
2. RAG 동작 흐름
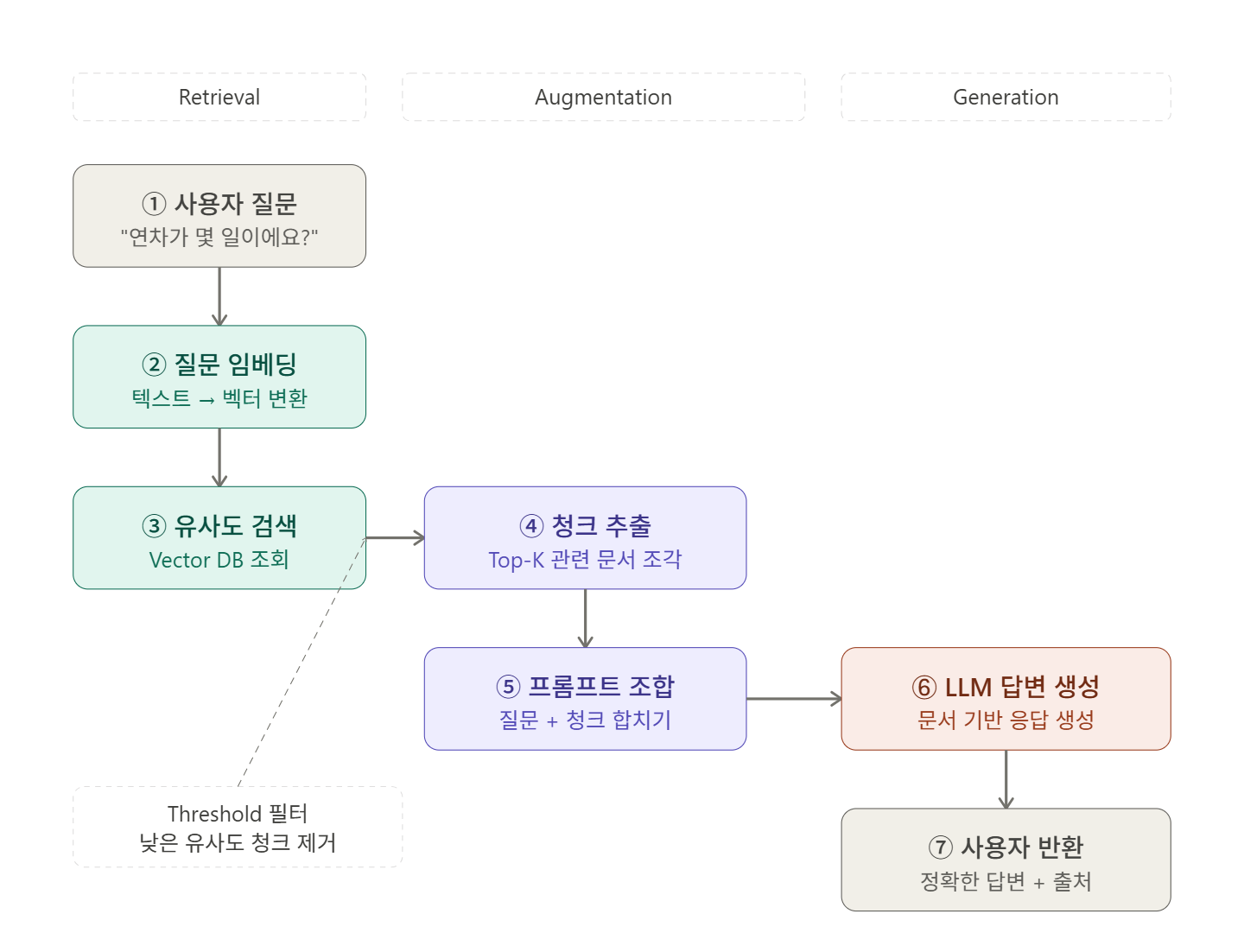
RAG는 이름 그대로 세 단계로 나뉜다.
Retrieval → Vector DB에서 관련 청크 검색
Augmented → 질문 + 청크를 합쳐서 프롬프트 강화
Generation → LLM이 강화된 프롬프트로 답변 생성전체 흐름을 순서대로 따라가면 아래와 같다.
① 사용자 질문 입력
② 질문을 벡터로 변환 (임베딩)
③ Vector DB에서 유사도 검색
④ 관련 청크 Top-K 추출
⑤ 질문 + 청크를 합쳐 프롬프트 구성
⑥ LLM이 프롬프트 기반으로 답변 생성
⑦ 사용자에게 답변 반환여기서 핵심은 ⑤번이다. 질문만 달랑 보내는 게 아니라,
"이 문서들을 참고해서 답해줘" 라고 컨텍스트를 함께 붙여서 LLM에 전달한다.
이것이 Augmentation의 본질이다.
3. 코드로 보는 RAG 구현
3-1. 유사도 검색과 Threshold
public AnswerResponse ask(String question) {
// threshold 0.0 → 필터링 없음 (유사도와 무관하게 전부 가져옴)
List<Document> relevantDocs = searchDocuments(question, 5, 0.0);
if (relevantDocs.isEmpty()) {
throw new DomainException(DomainExceptionCode.NOT_FOUND_CONVERSATION);
}
return AnswerResponse.builder()
.answer(generateAnswer(question, relevantDocs))
.build();
}
public RagResponse askWithSource(String question) {
// threshold 0.7 → 유사도 70% 이상 청크만 선별
List<Document> docs = searchDocuments(question, 5, 0.7);
...
}ask()와 askWithSource()의 차이는 Threshold에 있다.
| 메서드 | Threshold | 이유 |
|---|---|---|
ask() | 0.0 | 답변만 반환 → 출처 신뢰도가 덜 중요 |
askWithSource() | 0.7 | 출처를 명시 → 엉뚱한 근거를 보여주면 신뢰도가 무너짐 |
Threshold는 LLM 앞단에서 작동하는 필터다.
Vector DB 검색 시점에 낮은 유사도의 청크를 걸러내어,
품질 낮은 컨텍스트가 LLM에 전달되는 것을 막는다.
3-2. 프롬프트 설계 — Hallucination 방지
private static final String RAG_PROMPT_TEMPLATE = """
다음 문서들을 참고하여 질문에 답변해주세요.
문서에 없는 내용은 답변하지 마세요. ← 핵심
답변은 한국어로 작성해주세요.
[참고 문서]
%s
[질문]
%s
""";"문서에 없는 내용은 답변하지 마세요" 이 한 줄이 없으면
LLM은 문서에 없는 내용을 자신의 사전 학습 지식으로 채워 넣는다.
Hallucination이 발생하는 지점이 바로 여기다.
프롬프트로 명시적 제약을 걸어야 LLM의 상상력을 차단할 수 있다.
3-3. 출처 포함 응답
public RagResponse askWithSource(String question) {
List<Document> docs = searchDocuments(question, 5, 0.7);
String answer = generateAnswer(question, docs);
List<RagResponse.DocumentSource> sources = docs.stream()
.map(doc -> RagResponse.DocumentSource.builder()
.filename((String) doc.getMetadata().get("filename"))
.documentId(doc.getId())
.preview(doc.getText().substring(0, Math.min(doc.getText().length(), 100)))
.build())
.toList();
return RagResponse.builder()
.answer(answer)
.sources(sources)
.build();
}출처를 함께 반환하면 사용자는 "이 답변이 어느 문서에서 왔는지" 확인할 수 있다.
Threshold를 높게 잡는 이유도 여기 있다.
출처가 틀리면 LLM 전체에 대한 신뢰가 무너지기 때문이다.
4. RAG vs Fine-tuning
RAG와 자주 비교되는 것이 Fine-tuning이다.
- RAG: 참고서를 찾아보는 것
- Fine-tuning: 머릿속에 외우는 것
| 항목 | RAG | Fine-tuning |
|---|---|---|
| 업데이트 | 문서만 추가하면 즉시 반영 | 재학습 필요 (고비용) |
| 신뢰도 | 출처 제공 가능 | 블랙박스 |
| 비용 | 저렴 | 고성능 GPU 필요 |
| 적합한 경우 | 최신 정보, 사내 문서 | 말투 변경, 도메인 특화 스타일 |
사내 규정 챗봇, 최신 문서 기반 QA 시스템이라면 RAG가 압도적으로 유리하다.
마치며
RAG는 LLM에게 오픈북 테스트를 허용하는 패턴이다.
질문을 벡터화 → 유사도 검색 → 청크 추출 → 프롬프트 증강 → 답변 생성의 흐름으로,
문서 기반의 정확하고 신뢰할 수 있는 답변을 이끌어낸다.
