Spring AI
1.[Spring AI] 시작하기

지금까지 IoC/DI, Bean, Spring MVC 흐름을 익히면서 Spring이 "복잡한 것을 추상화해서 개발자가 비즈니스 로직에 집중하게 해준다"는 철학을 반복해서 봐왔다. 오늘은 그 철학이 AI 영역에서 어떻게 적용되는지를 다룬다.이번 글을 읽으면서 스스로에게
2.[Spring AI] LLM과 제대로 대화하기: Context, History, Token, Streaming
지난 글에서 Spring AI의 기본 구조와 ChatClient를 통해 LLM에 질문을 던지는 방법을 살펴봤다.그런데 막상 챗봇을 만들려고 하면 이런 의문이 생긴다.AI는 내가 아까 뭐라고 했는지 기억하는가?대화가 길어질수록 비용이 얼마나 늘어나는가?어떻게 해야 AI가
3.[Spring AI] LLM 컨텍스트 관리와 멀티모달
지난 글에서는 LLM과 대화를 설계하는 방법을 다뤘다. System / User / Assistant 세 가지 메시지 타입을 이해하고, 히스토리를 어떻게 구성해야 AI가 맥락을 잘 이해하는지 살펴봤다.그런데 히스토리를 쌓다 보면 자연스럽게 이런 의문이 생긴다.대화가 1
4.[Spring AI] 로컬에서 AI 모델 돌리기 — Spring AI + Ollama 연동
지금까지 Spring AI로 Gemini와 OpenAI 같은 클라우드 API를 연동해봤다.ChatClient 하나로 다양한 모델을 추상화해서 쓸 수 있다는 것도 확인했다.그런데 이런 의문이 생길 수 있다.클라우드 API를 쓰면 데이터가 외부 서버로 나가는데, 민감한 정
5.[Spring AI] Vector DB와 Spring AI
10단계에서 LLM은 Stateless하기 때문에 매 요청마다 컨텍스트를 직접 전달해야 한다고 배웠다. 그런데 컨텍스트가 길어질수록 토큰 비용이 폭증하고, 필요한 정보만 골라서 전달해야 한다는 문제가 남아 있었다.이번 글에서는 그 해결책의 핵심인 Vector DB를 다
6.[Spring AI] Spring AI와 RAG — LLM에게 참고서를 쥐어주는 법
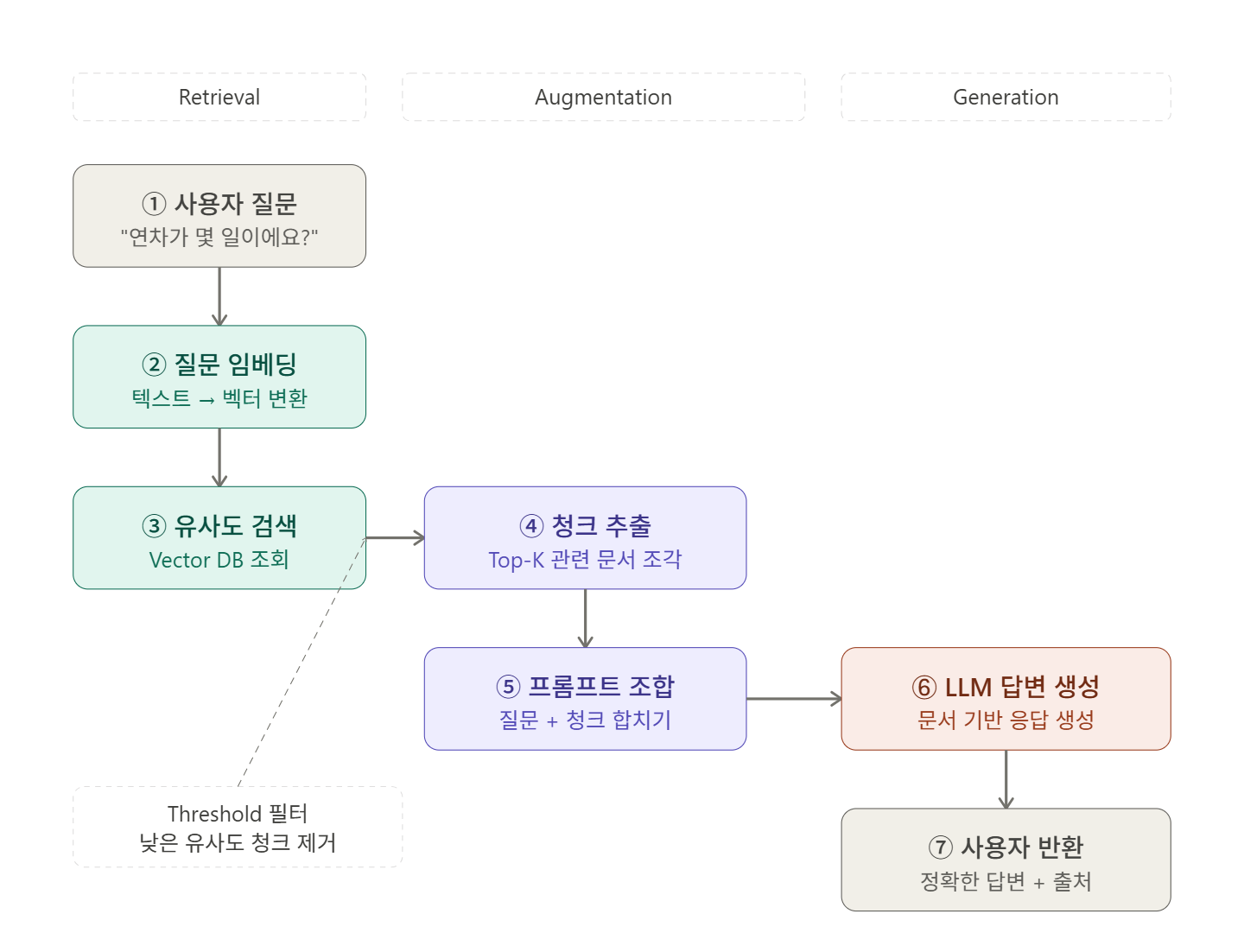
지난 글에서는 Vector DB와 임베딩을 다뤘다. 텍스트를 숫자 배열로 변환해서 의미 기반 유사도 검색을 할 수 있다는 것, 그리고 기존 LIKE 검색이 왜 의미 파악에 한계가 있는지를 살펴봤다.이번 글에서는 그 Vector DB를 실제로 활용하는 패턴인 RAG를 다
7.[Spring AI] Spring AI Advisor 패턴과 Function Calling
지난 글에서는 RAG(Retrieval-Augmented Generation)를 통해 LLM이 외부 문서를 참조해서 답변하는 방법을 배웠다. 이번 글에서는 한 단계 더 나아간다.이런 질문들을 생각해보자.대화 기록 저장, 욕설 필터링 같은 공통 로직을 매번 Service
8.[Spring AI] Agentic Workflow — AI가 스스로 생각하고 행동하는 방법
지난 글에서는 Spring AI의 Advisor 패턴과 Function Calling을 통해 LLM이 외부 도구를 활용하는 방법을 살펴봤다. 그런데 도구를 쓸 수 있다고 해서 에이전트가 되는 건 아니다.이번 글에서는 다음 질문들을 중심으로 Agentic Workflow