SemiVL: Semi-Supervised Semantic Segmentation with Vision-Language Guidance 논문리뷰
간략한 배경지식
-
Semi-Supervised learning
- 준지도 학습
- 라벨링된 적은 양의 데이터와 라벨링이 안된 많은 데이터가 있을 경우
라벨링된 데이터는 지도학습, 안된 데이터는 비지도 학습하는 방법 - 총 loss = 지도학습 loss + 비지도학습 loss
- 예측 결과를 다음 학습의 데이터로 사용함
-
Contrastive learning
- 비지도 학습의 한 분야인 자기 주도 학습(모델 자체에서 데이터의 라벨을 생성하여 학습 - nlp에서 언어 마스킹, vision에서 이미지 회전 및 뒤집기 등) 모델이 학습에서 사용되는 방법론 중에 하나
- 학습된 표현 공간상에 비슷한 데이터는 가까이, 다른 데이터는 멀리 학습하는 것
-
Consistency regularization (Consistency training)
- Semi-Supervised를 하기 위한 여러 방법론 들중 하나
- 라벨링 되지 않은 데이터 point에 작은 변화(perturbation)을 주어도 예측의 결과에는 일관성이 있을 것이라 가정함
- 애매한 데이터들에 대해 유연한 예측을 함
-
VLM (비전-언어 모델)
- 이미지와 언어를 모두 학습해, 더 나은 의미적 추론을 하려는 모델
- 비젼 모듈과 언어 모듈이 합쳐진 구조를 가짐
- 이미지에 대한 설명 캡션을 생성하거나,
텍스트를 통한 이미지 생성,
텍스트를 통한 이미지 검색 및 시각 탐색(언어로 로봇 작업 수행)
등이 진행됨
Abstract
- 문제
- Semi-Supervised Semantic Segmentation 분야의 이전 연구 들은 라벨링 비용을 낮추며 좋은 세그멘테이션 경계를 학습할 수 있지만, 비슷해 보이는 데이터는 클래스를 혼동하기 쉬움
- 비전-언어 모델(VLMs)은 이미지-캡션 데이터셋에 대해서 의미를 학습할 수 있지만, 이미지 수준(이미지 전체에 대한)의 훈련으로 인해 노이즈가 있는 세그멘테이션을 생성할 수 있음
- SemiVL의 제안
- VLM + Semi-Supervised Semantic Segmentation
사전 학습된 VLM 통해 풍부한 이미지 정보로 더 나은 시멘틱(의미적) 결정 경계(semantic decision boundary)를 만들고자 함 - VLM을 global에서 local 추론으로 조정하기 위해(전체적인 이미지 수준이 아닌, 각 라벨별 추론을 하기 위해) 공간적 미세 조정 전략(fine-tuning)을 도입
- 비전과 언어를 함께 고려하는 언어 안내 디코더를 설계
-> 해당 디코더로 class의 라벨에 대한 언어 안내를 모델에 제공
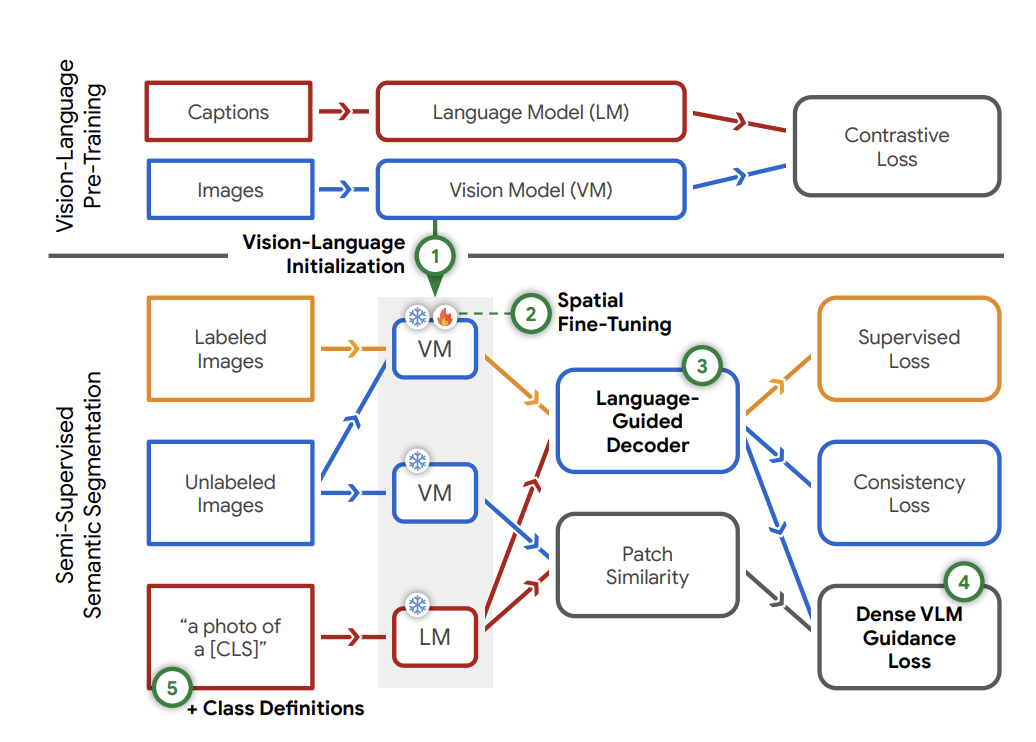
- VLM + Semi-Supervised Semantic Segmentation
- 성과 : 4개의 시맨틱 세그멘테이션 데이터셋에서 평가
- 232개의 주석이 지정된 COCO에서 +13.5 mIoUfh SOTA
- 92개의 레이블이 있는 Pascal VOC에서 +6.1 mIoU
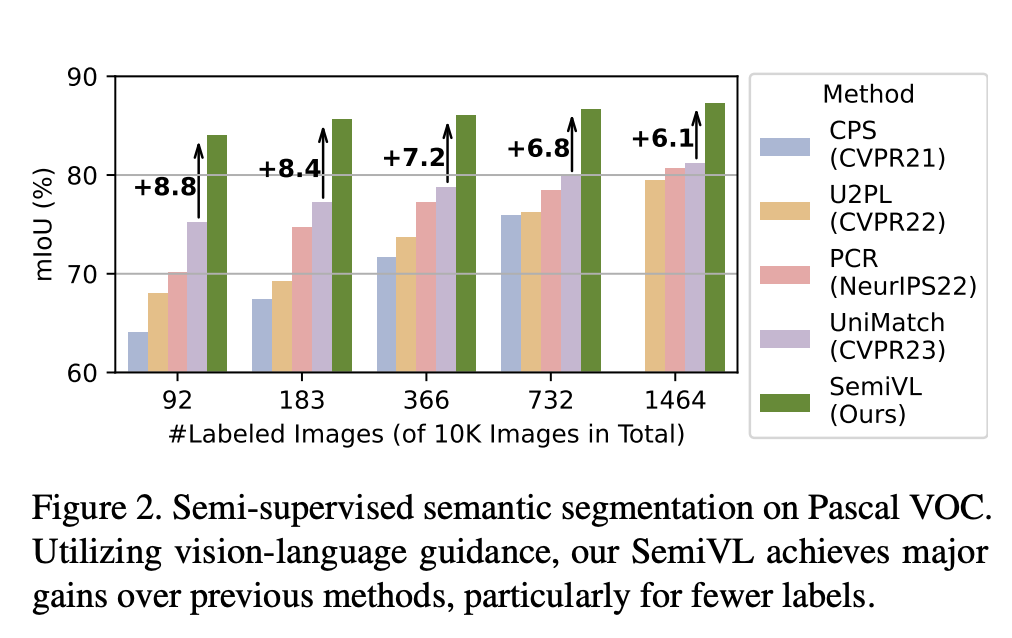
Introduction
semantic segmentation 모델은 학습에 대규모 라벨링된 데이터에 의존성이 커서, 사람에 의한 라벨링이 필요함
semi semantic segmentation은 라벨링 안된 이미지 데이터도 효과적으로 학습하고자 함
이러한 노력으로 적대적 신경망 모델, 자기 훈련 모델이 존재함
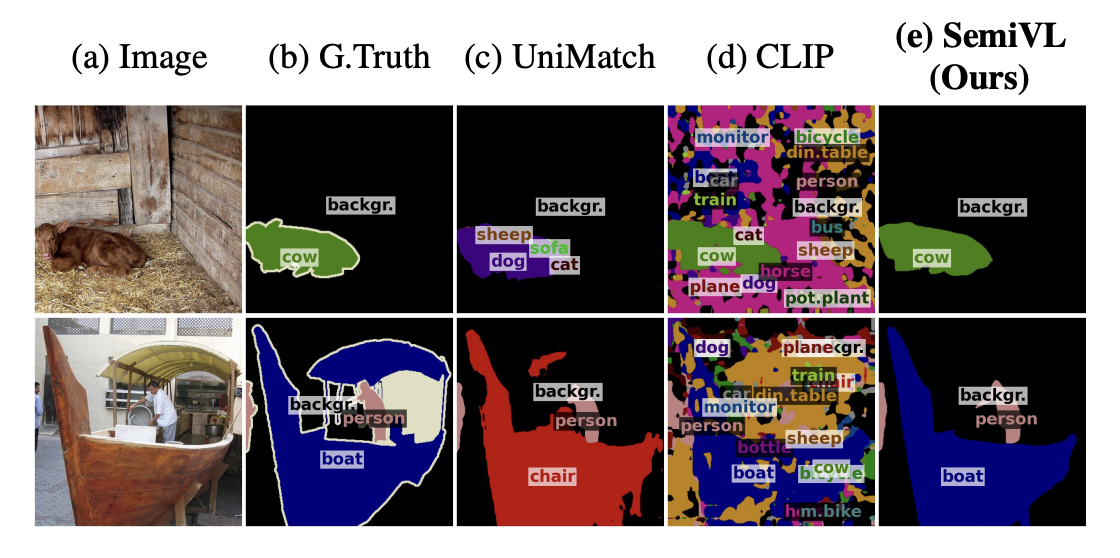
- 현재 sota인 UniMatch 모델은 세그멘테이션 마스크는 잘 학습했으나, 비슷한 시각적 특징을 가진 세그먼트는 정확한 시맨틱 결정 경계를 학습하기 어려움.
- CLIP [51]과 같은 VLM은 웹 규모의 이미지 캡션 데이터셋에서 훈련됨
데이터의 다양성과 고정된 클래스 라벨이 아닌 자연어 캡션은 VLM이 더 풍부한 의미 표현을 캡처할 수 있음.
그러나 이미지 수준에서 훈련되어 그들의 특징이 잘 localize 되지 못함(각 세그먼트 마다 가지는 특징을 잘 훈련되지 못함) - SimVL은 더 풍부한 의미를 캡처하기 위해, 우리는 Vision Language Models (VLM)의 가이드를 활용하여 Semi-Supervised Semantic Segmentation을 보완하는 것을 제안
이 연구에서는 세미-지도 훈련의 좋은 로컬라이제이션과 VLM(Vision-Language Models)의 풍부한 의미 이해를 어떻게 결합할지를 연구했습니다. 이를 기반으로, 우리는 세미VL(SemiVL)을 제안합니다. 이는 두 가지 강점을 결합하여 좋은 세그멘테이션 품질과 미세한 의미적 식별력을 달성합니다. 예를 들어, SemiVL은 그림 1e에서 소와 보트를 올바르게 세그멘트하고 분류합니다. 우리의 최고 지식으로는, SemiVL은 밀집 레이블의 부족 문제를 완화하기 위해 비전-언어 안내를 사용한 세미-지도 시맨틱 세그멘테이션에 대한 최초의 작업입니다. 이전의 VLM 시맨틱 세그멘테이션 작업(2.2절 참조)은 밀집 레이블이 없이 운영되거나[5, 63, 73] 성능을 제한하는 큰 비용이 드는 주석이 달린 세그멘테이션 데이터셋을 사용하였습니다[12, 65, 76]. 그 대신에, SemiVL은 몇 개의 레이블만 사용하여 세미-지도 환경에서 고품질 시맨틱 세그멘테이션을 학습할 수 있습니다.
Conclusion
참고
https://sanghyu.tistory.com/177
https://jimmy-ai.tistory.com/129
https://daebaq27.tistory.com/97
https://blog.est.ai/2020/11/ssl/
