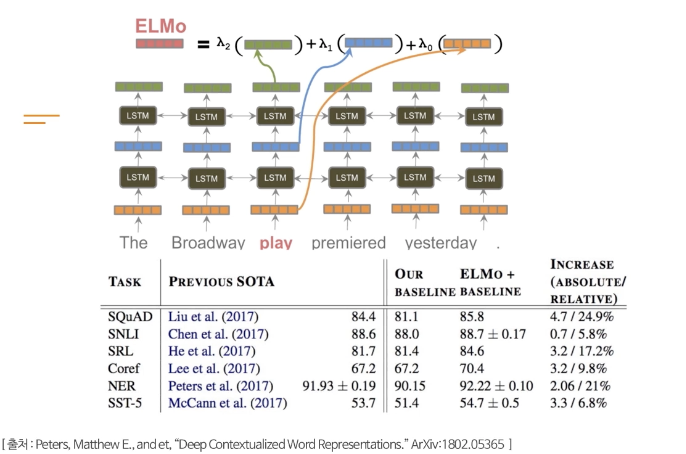
ELMo
LM pre-training using deep bidirectional LSTM(2 layers)
Contextualized word embedding by linear combinatoin of hidden states
GPT: Transformer Decoder LM
Pretrain large 12 layer left-to-right decoder transformer
Uni-directoinal (forward) LM

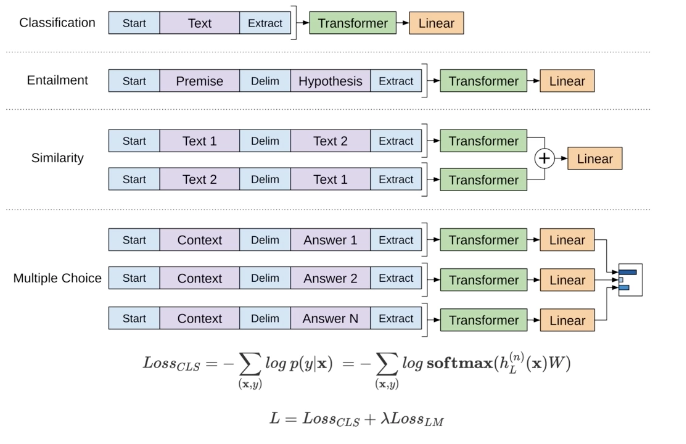
GPT: Supervised Fine Tuning
Supervised fine-tuning for each NLP tasks(classification, similarity, multiple choice)
Sentence representation from last token output of last transformer layer