최적화와 관련된 주요한 용어와 다양한 Gradient Descent 기법들을 배웁니다.
주요한 용어: Generalization,Overfitting, Cross-validation 등 다양한 용어가 있습니다. 각 용어들의 의미에 대해 배웁니다.
다양한 Gradient Descent 기법: 기존 SGD(Stochastic gradient descent)를 넘어서 최적화(학습)가 더 잘될 수 있도록 하는 다양한 기법들에 대해 배웁니다.
Gradient Descent
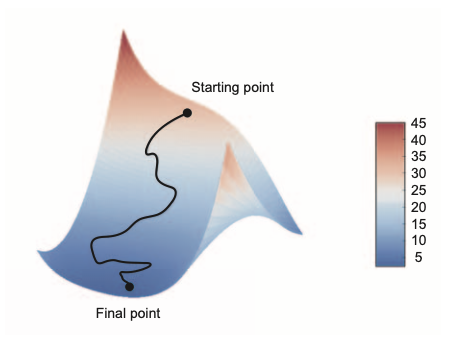
First-order iterative optimization algorithm for finding a local minimum of a differentiable function
gradient descent down a 2D loss surface (two learnable parameters)
Important Concepts in Optimization
- Generalization
- Under-fitting vs. over-fitting
- Cross validation
- Bias-variance tradeoff
- Bootstrapping
- Bagging and boosting
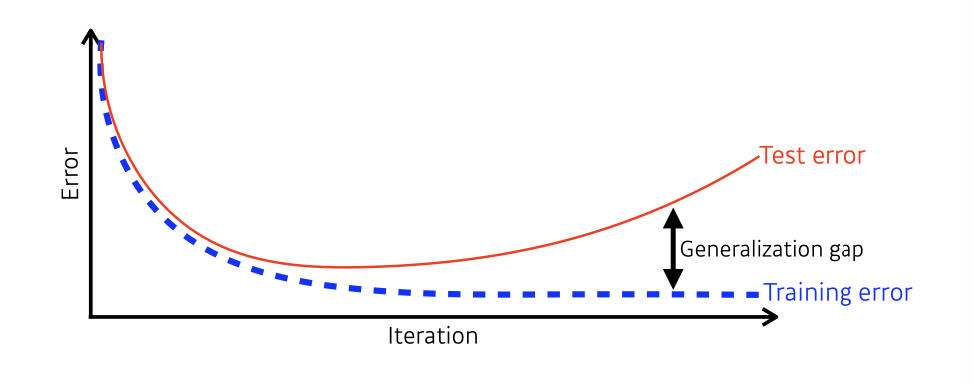
Generalization
How well the learned model will behave on unseen data
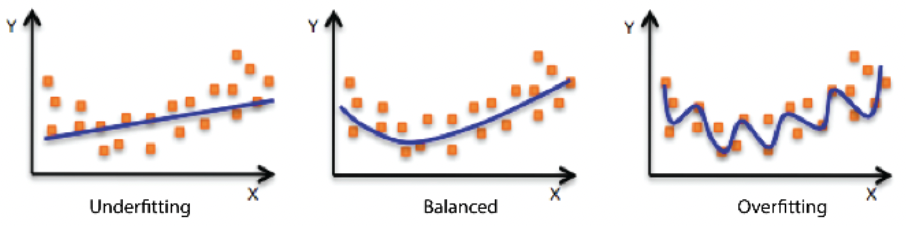
Underfitting vs Overfitting
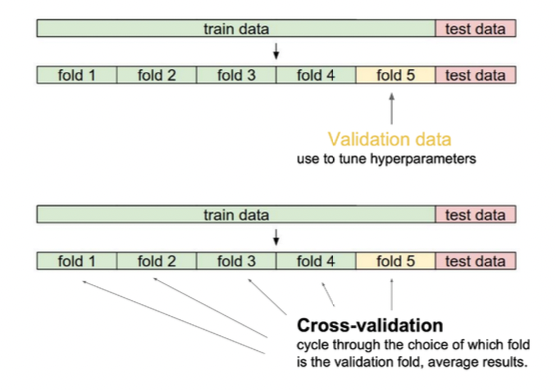
Cross-validation
Cross-validation is a model validation technique for assessing how the model will generalize to an independent (test) data set
Bias and Variance
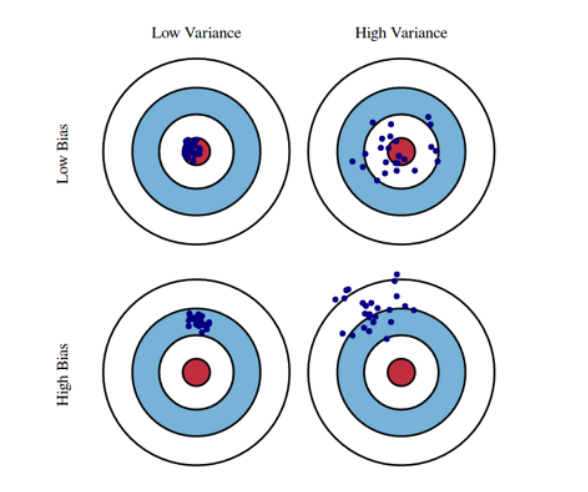
Bias and Variance Tradeoff

Bootstrapping
Bootstrapping is any test or metric that uses random sampling with replacement
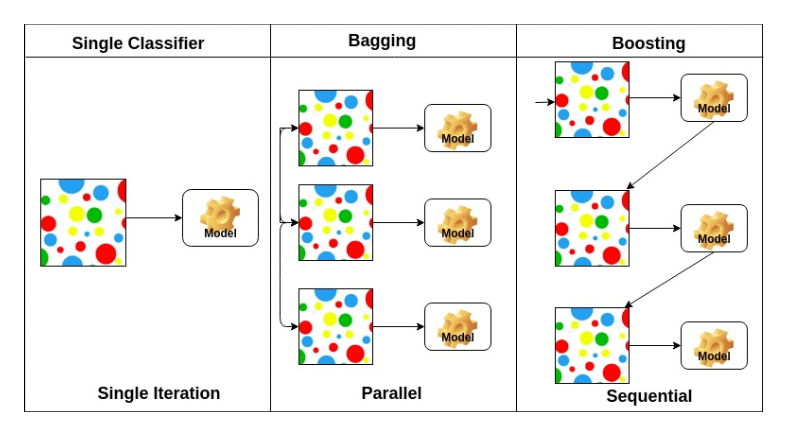
Bagging vs Boosting
- Bagging (Bootstrapping aggregating)
Multiple models are being trained with bootstrapping.
ex) Base classifiers are fitted on random subset where individual predictions are aggregated (voting or averaging).
- Boosting
It focuses on those specific training samples that are hard to classify.
A strong model is built by combining weak learners in sequence where each learner learns from the mistakes of the previous weak learner.
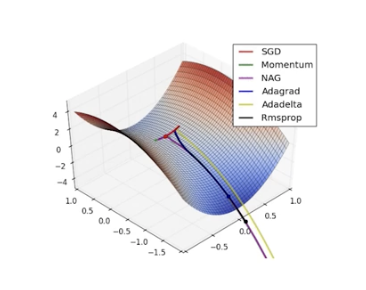
Practical Gradient Descent Methods
Gradient Descent Methods
- Stochastic gradient descent
The term stochastic refers to the fact that each batch of data is drawn at random (stochastic is a scientific synonym of random)
Update with the gradient computed from a single sample
- Mini-batch gradient descent
Update with the gradient computed from a subset of data
-
Batch gradient descent
Update with the gradient computed from the whole data -
Stochastic gradient descent
-
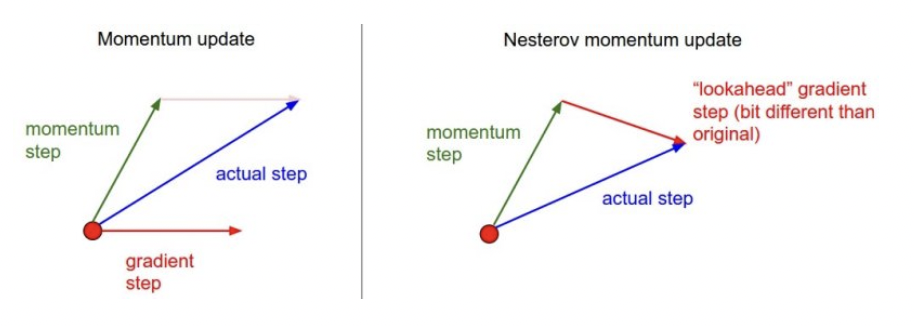
Momentum
-
Nesterov accelerated gradient
-
Adagrad
-
Adadelta
-
RMSprop
-
Adam
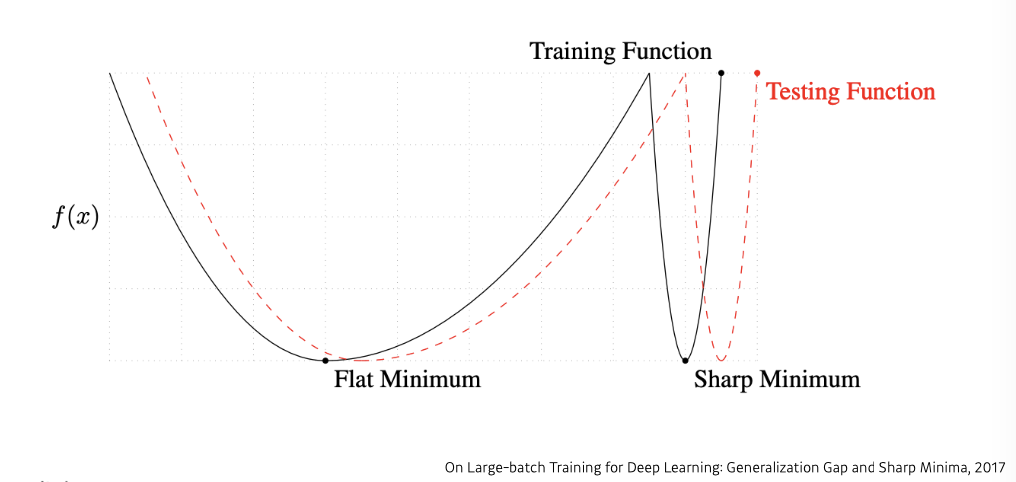
Batch-size Matters
"It has been observed in practice that when using a larger batch there is a degradation in the quality of the model, as measured by its ability to generalize."
"We ... present numerical evidence that supports the view that large batch methods tend to converge to sharp minimizers of the training and testing functions. In contrast, small-batch methods consistently converge to flat minimizers... this is due to the inherent noise in the gradient estimation."
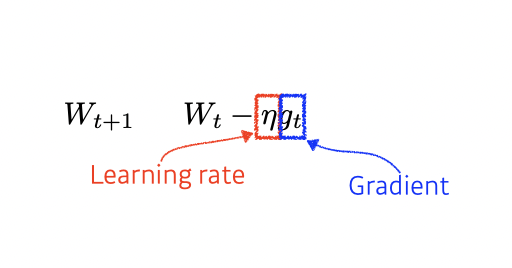
Gradient Descent
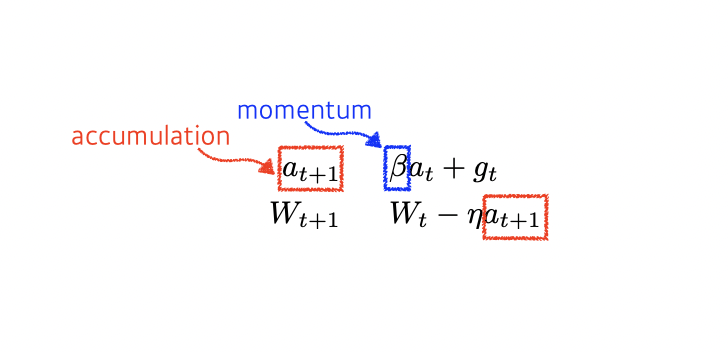
Momentum
hyperparameter로 베타 적용(모멘텀)
모멘텀이 포함된 gradient로 update
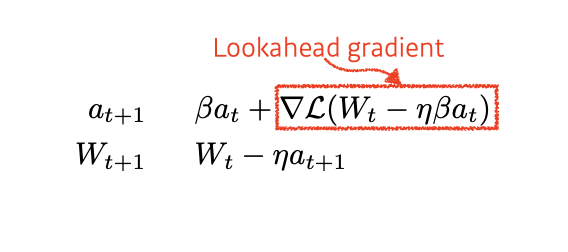
Nesterov Accelerated Gradient
Adagrad
Adagrad adapts the learning rate, performing larger updates for infrequent and smaller updates for frequent parameters
Gt : Sum of gradient squares
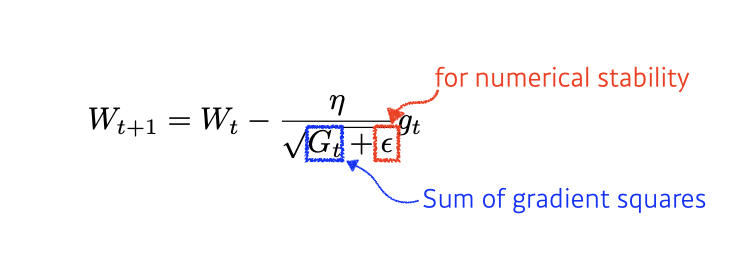
What will happen if the training occurs for a long period?
Adadelta
Adadelta extends Adagrad to reduce its monotonically decreasing the learning rate by restricting the accumulation window
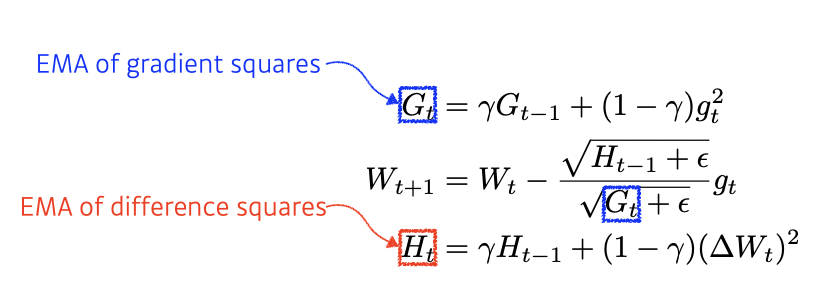
There is no learning rate in Adadelta
-> 바꿀 수 있는 요소가 많지 않은 이유로 잘 활용되지는 않음
RMSprop
RMSprop is an unpublished, adaptive learning rate method proposed by Geoff Hinton in his lecture
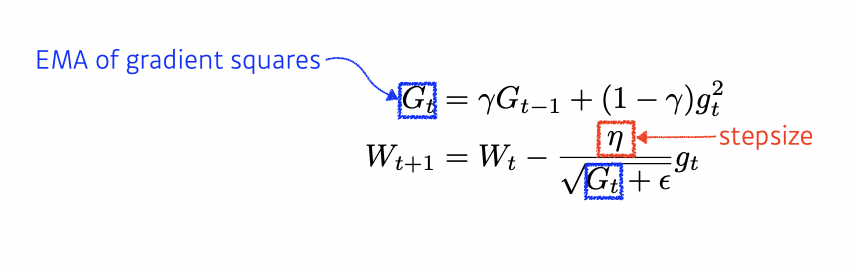
Adam
Adaptive Moment Estimation (Adam) leverages both past gradients and squared gradients
opt = tf.keras.optimizers.Adam(learning_rate=0.1)Adam effectively combines momentum with adaptive learning rate approach
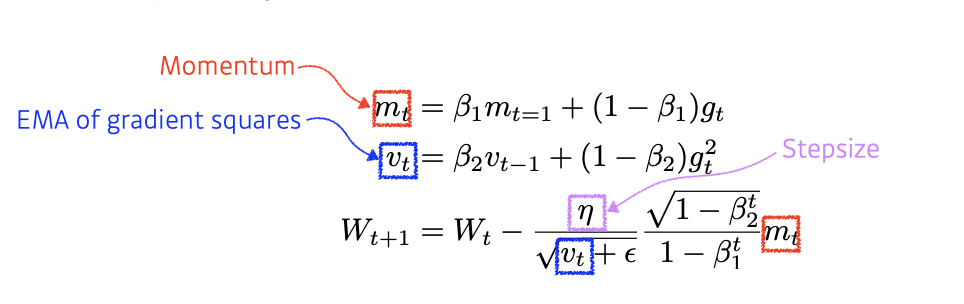
Regularization
- Early stopping
- Parameter norm penalty
- Data augmentation
- Noise robustness
- Label smoothing
- Dropout
- Batch normalization
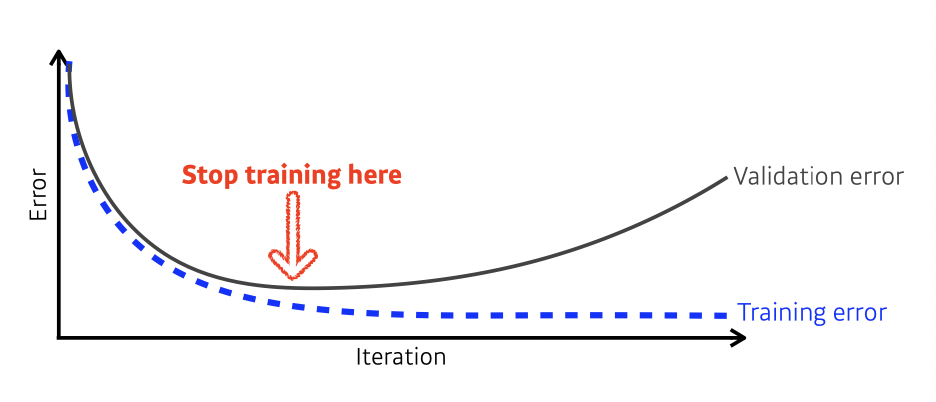
Early Stopping
Interrupting training when the validation loss is no longer improving (and of course, saving the best model obtained during training)
keras.callbacks.EarlyStopping
or
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)we need additional validation data to do early stopping
Parameter Norm Penalty
It adds smoothness to the function space
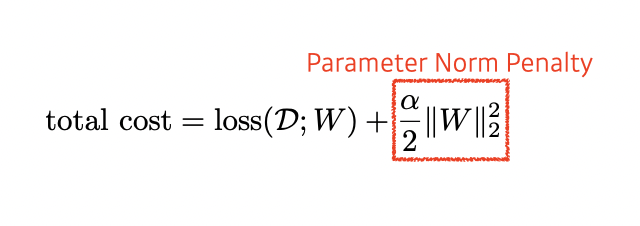
Data Augmentation
a powerful technique for mitigating overfitting in computer vision
More data are always welcomed
data_augmentation = tf.keras.Sequential([
layers.experimental.preprocessing.RandomFlip("horizontal_and_vertical"),
layers.experimental.preprocessing.RandomRotation(0.2),
])
However, in most cases, training data are given in advance
In such cases, we need data augmentation
Noise Robustness
Add random noises inputs or weights

Label Smoothing
Mix-up constructs augmented training examples by mixing both input and output of two randomly selected training data
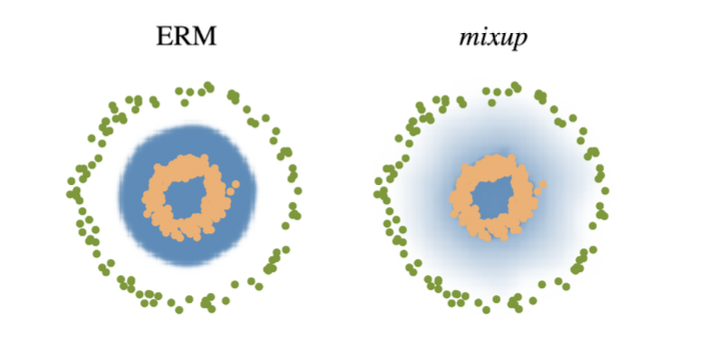
CutMix constructs augmented training examples by mixing inputs with cut and paste and outputs with soft labels of two randomly selected training data

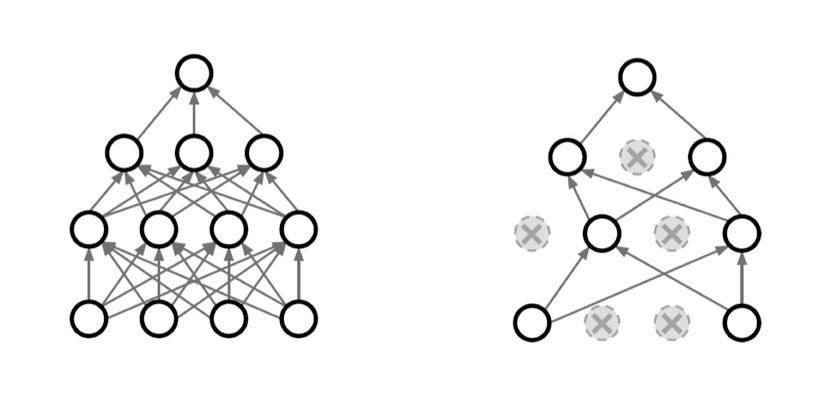
Dropout
In each forward pass, randomly set some neurons to zero
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))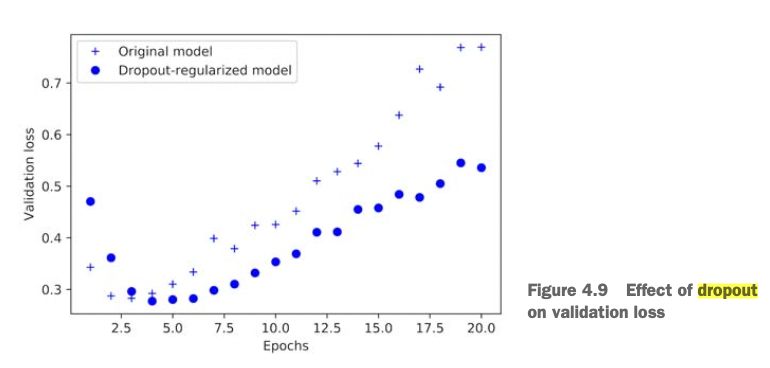
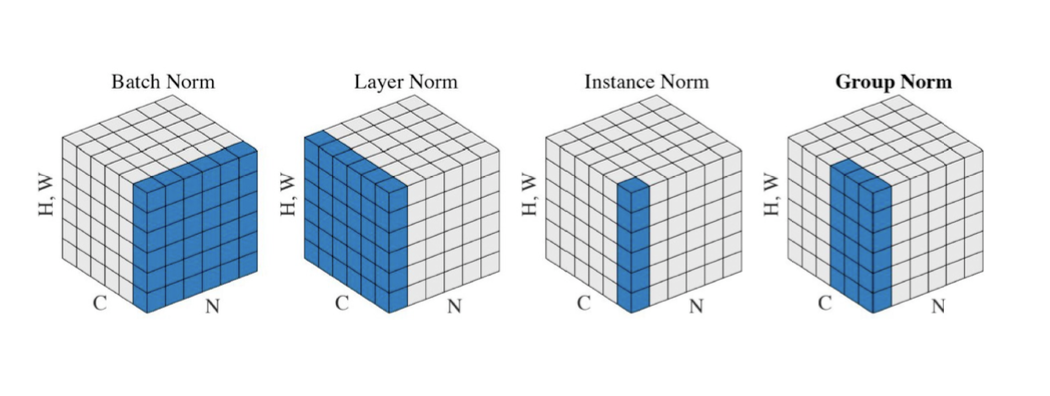
Batch Normalization
Batch normalization compute the empirical mean and variance independently for each dimension (layers) and normalize
BatchNormalization layer is typically used after a convolutional or densely
connected layer
conv_model.add(layers.Conv2D(32, 3, activation='relu')) #After a Conv layer
conv_model.add(layers.BatchNormalization())
dense_model.add(layers.Dense(32, activation='relu')) #After a Dense layer
dense_model.add(layers.BatchNormalization())
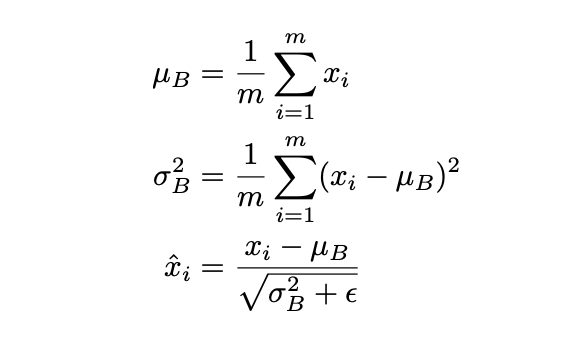
There are different variances of normalizations