이번 게시물에서는 최근에 뜨거운 관심을 받았던 dialogue모델인 Moshi를 소개해보려고 합니다. Technical report가 워낙 분량이 많아서 전부 다루기는 어려웠고, 3.Model, 4.Training 파트 위주로 다뤄보려고 합니다. Moshi는 데모 페이지에 로그인해서 직접 사용해볼 수도 있고, 깃헙에서 관련 스크립트도 확인할 수 있습니다.
Moshi는 음성 대 음성으로 실시간으로 대화가 가능한 대화 시스템입니다. 간단하게 이야기하면 사용자의 음성으로 Moshi에게 말을 걸면 Moshi가 적절한 응답을 제공합니다. 이 때, Moshi는 신기하게도 생각하는 시간 없이 사용자의 말이 끝나자마자 대답을 하기도 하고, 심지어는 사용자가 말하는 데에 끼어들기까지 합니다. 반대로 Moshi가 말하는 도중에 사용자가 끼어들어도 사용자의 음성을 듣고 대답을 할 수 있습니다. 보통 저희가 알고 있는 dialogue모델은 사용자의 말이 끝나야만 그 말에 대한 적절한 응답을 생성할 수 있었습니다. Moshi는 어떻게 답이 끝나자마자 응답을 생성하는 시간 없이도 대답을 이어나갈 수 있는 걸까요?
결론부터 말씀드리면 Moshi는 신속한 대화가 가능하도록 모든 방면에서 다양한 기술을 활용하였습니다. 논문을 읽는 내내 모델 네트워크, 모델 학습에 사용한 데이터, 경량화 기법, 스트리밍 방식 등 신경쓰지 않은 파트가 없어 보였습니다. 이론도 자세하게 기술되어 있었지만 난이도 있는 내용을 깊이 다루고 있어 전체적인 흐름 위주로 이해하고 정리해보았습니다.
본 게시물의 이미지는 전부 논문에서 가져왔습니다:)
모델 구조
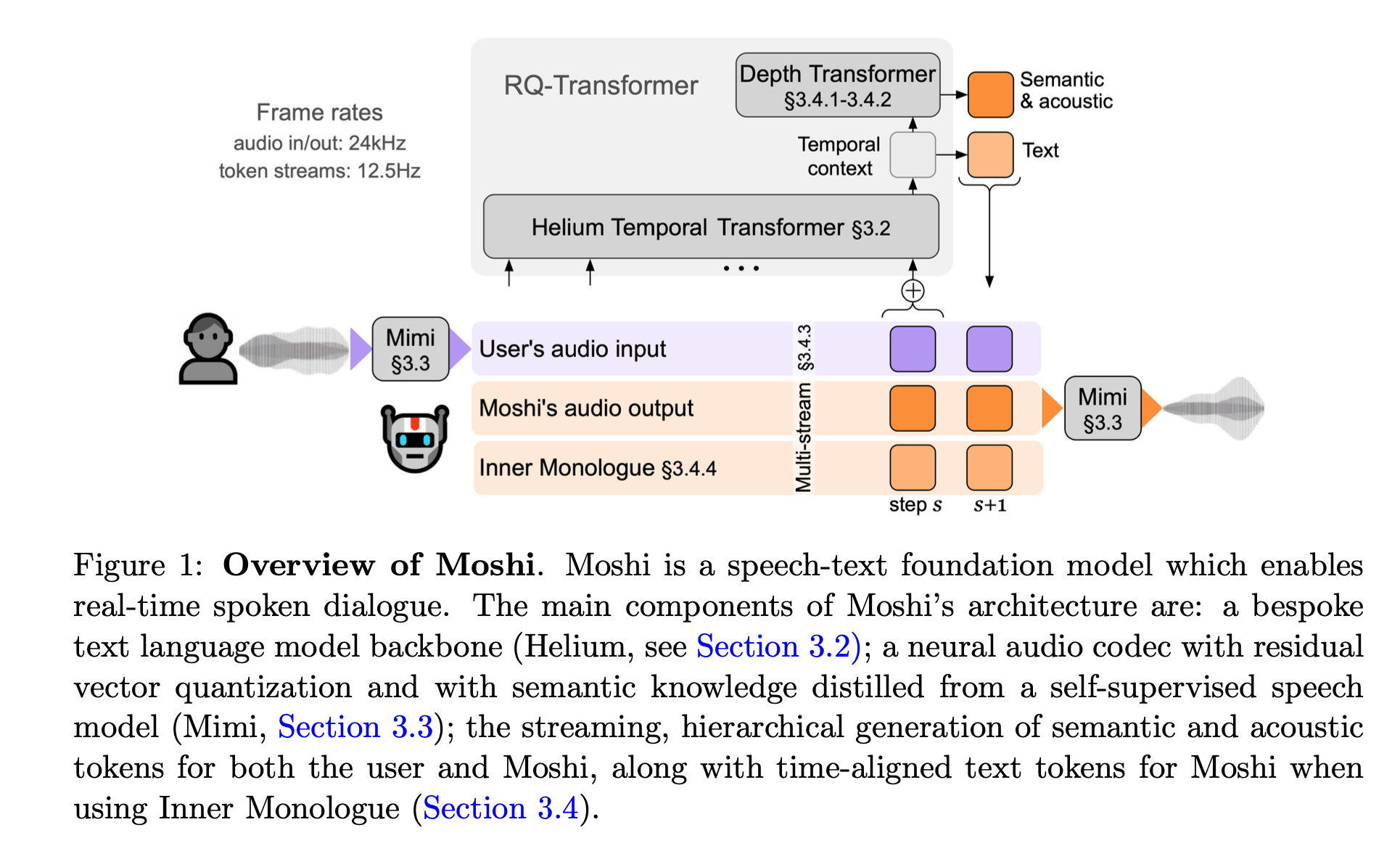
Moshi는 Mimi 라는 neural audio codec과 Helium이라는 7B의 Text Language Model이 연결된 모델입니다.
Mimi
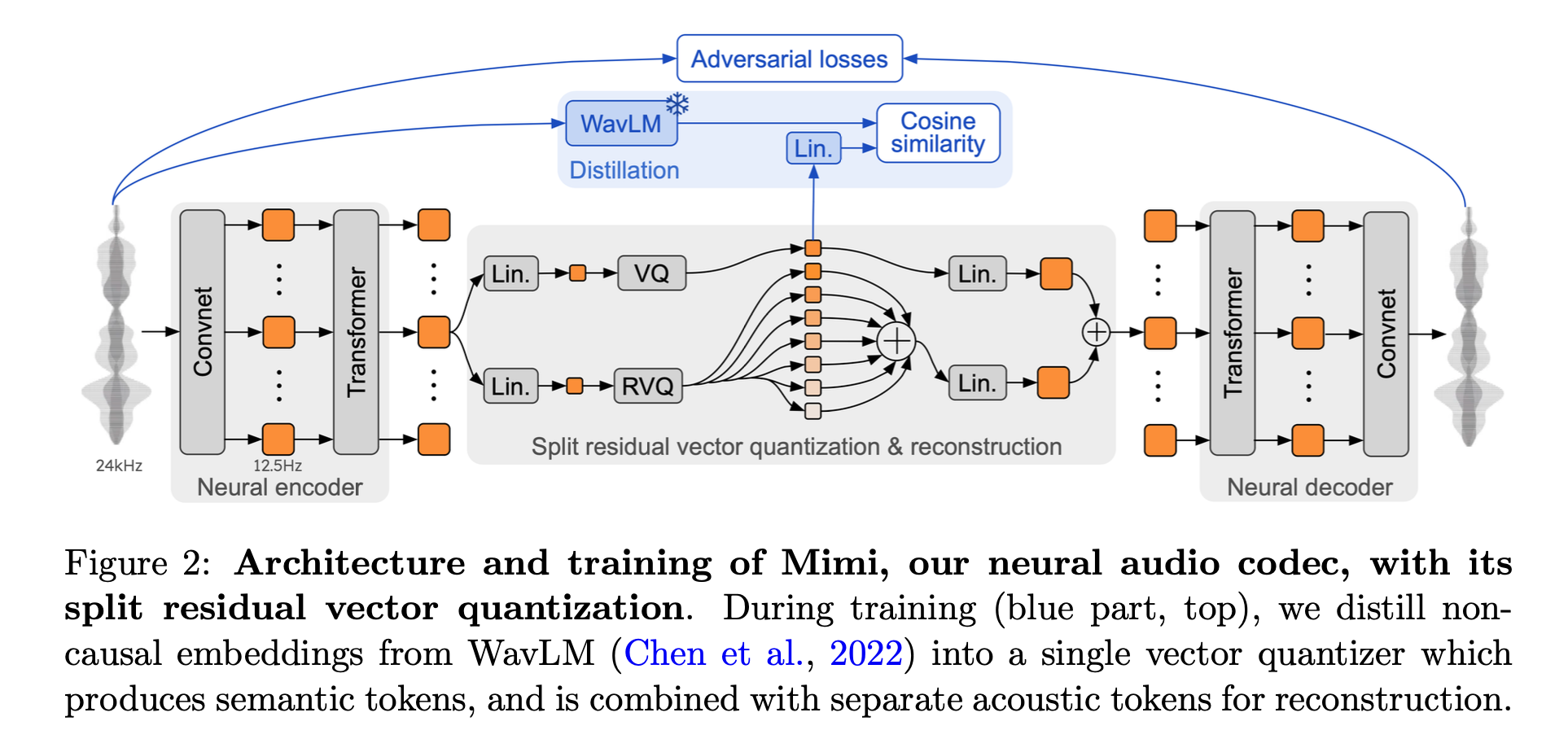
Mimi는 오디오의 semantic token(음성의 내용이나 의미적 정보)과 acoustic token(음질과 같은 음향적 특성 정보)를 하나의 tokenizer로 합친 neural audio codec입니다. 24kHz의 waveform을 12.5Hz로 변환하여 아주 가벼운 차원으로 처리하는데요, 여기서 오디오의 퀄리티를 유지하기 위해 residual vector quantization(RVQ)과 knowledge distillation 방식을 활용하고, adversarial-only training 사용해서 오디오의 품질을 향상시켰습니다.
RVQ(residual vector quantization)
RVQ(residual vector quantization)는 글자 그대로 음성 신호를 양자화하는 방식입니다. 코드북(Codebook) 을 사용하여 음성 신호의 연속된 벡터를 압축된 벡터로 변환하는데요, 코드북은 쉽게 말하면 오디오 정보를 알맞은 벡터 값으로 변환할 수 있는 사전입니다. LLM에서 vocab과 비슷한 역할을 한다고 생각하시면 됩니다. 이 코드북은 음성 처리 작업의 성능을 유지하면서도 연산 비용을 줄여서 추론 속도를 감소시키고, 음성 인식에서 사용한 코드북을 음성 합성 단계에도 동일하게 사용하여 음성 합성 성능을 높이는 역할을 합니다.
knowledge distillation
음성의 semantic 정보는 음성의 앞뒤 맥락을 모두 참고하여 계산해야 하는데 real-time generation 모델인 Moshi에는 적합하지 않습니다. 또한 semantic token과 acoustic token을 각각 독립적인 tokenizer로 사용하면 계산량이 늘어나기 때문에 모델 추론 속도가 느려질 수도 있습니다. 따라서 Mimi는 SpeechTokenizer (Zhang et al., 2024b) 방식을 차용하여 non-casual model인 WavLM에서 distillation을 통해 semantic 정보를 가져오는 방식을 사용하여 성능을 높이면서 계산량 문제를 해결하였습니다.
Helium
Helium은 웹 데이터를 가공해서 자체적으로 학습한 Pretrained 언어 모델입니다. Moshi는 이 언어 모델을 기반으로 음성 대화에 적합한 모델로 만들기 위해 RQ-Transformer 구조로 변형하여 음성 데이터로 추가 학습을 진행합니다.
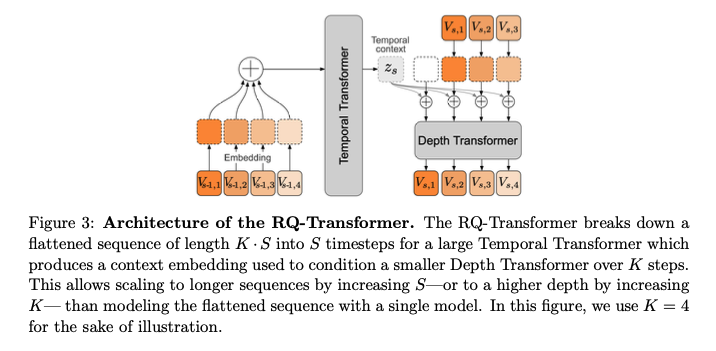
RQ-Transformer는 Temporal Transformer와 Depth Transformer로 구성되어 있습니다. Temporal Transformer는 Helium과 결합하여 음성의 시간적 흐름(순서)을 처리하는 역할을 수행합니다. 앞서 Mimi에서 이야기한 Semantic Token을 바탕으로 발화를 이해하고 응답을 생성합니다. Depth Transformer는 Acoustic Token과 Semantic Token 간의 관계를 학습하는데요, 쉽게 말하면 음성의 음향적 특징을 이해하고 음성 합성을 진행하는 역할을 수행합니다. 이러한 방식은 그림과 같이 음성을 학습할 때 Temporal Transformer에서 얻은 context를 참고할 수 있도록 합니다. 이 방식을 논문에서는 Inner Monologue라고 표현했는데요. 두 Transformer가 연결된 구조상 음성 토큰을 예측하고 생성할 때 textual representation을 참고할 수 있도록 하여 음성 대화의 언어적 성능을 높일 수 있었다고 주장합니다.
모델 학습
Moshi Training
1. Pre-training
- Moshi는 7백만 시간의 unsupervised(전사 텍스트가 없는) 오디오 테이터셋에 대해서 Whisper를 사용하여 전사 텍스트를 생성하여 제작한 음성-텍스트 데이터셋으로 pre-traning을 진행합니다.
2. Post Training
- Pre-training 이후 multi-stream ability를 훈련하기 위해 PyAnnote (Bredin, 2023)라는 화자분리 패키지를 사용하여 Pre-training에 사용했던 unsupervised dataset 음성의 화자를 분리합니다. Main 화자를 랜덤으로 정하고, 해당 화자의 waveform만 마스킹해서 훈련합니다. 마스킹된 waveform과 그렇지 않은 waveform을 multi stream으로 동시에 훈련하는데요, 이 단계는 moshi의 화자는 일정하고, user의 음성은 다양할 수 있는 음성 환경을 학습합니다.
3. Fine-tuning
- Fisher dataset이라는 2000시간의 통화 데이터를 사용해서 모델을 학습시킵니다.
- Speech-Text Instruct Data를 사용해서 모델을 학습시킵니다. 처음엔 Open Hermes 데이터셋을 사용하려고 했으나, 해당 데이터셋이 bullet point 등 TTS에 입력하기엔 적합하지 않았다고 합니다. 따라서 Open Hermes와 real conversation 텍스트 데이터로 미세조정한 Helium 모델로 적합한 텍스트 데이터를 만들어 TTS에 입력하여 음성 합성을 진행했습니다. 여기서 Moshi stream에게는 single 화자의 음성으로, user stream에는 다양한 화자에 robust하게 학습하도록 데이터를 제공했습니다.

TTS Training
TTS는 별도의 훈련 과정을 거쳤는데, 직접 수집한 170시간의 대화 데이터(supervised multi-stream dataset)를 사용하여 훈련했다고 합니다. Moshi 훈련에는 해당 데이터셋의 전사 텍스트만 사용하고, 음성 데이터는 multi-stream TTS 모델 훈련에만 사용되었다고 합니다.

TTS 훈련 과정에서 multi-stream처리를 위한 방식을 적용하는데요. 오디오 스트림은 매칭되는 텍스트와 비교해서 약 2초 정도의 딜레이를 가지고 훈련됩니다. 이러한 훈련 방식은 모델이 텍스트가 먼저 예측되고 2초 후에 음성이 생성되는 방식으로 동작할 수 있게 됩니다. 이는 Moshi의 음성 생성의 품질을 높이고, 대화가 자연스럽게 이어질 수 있도록 합니다.
모델 추론
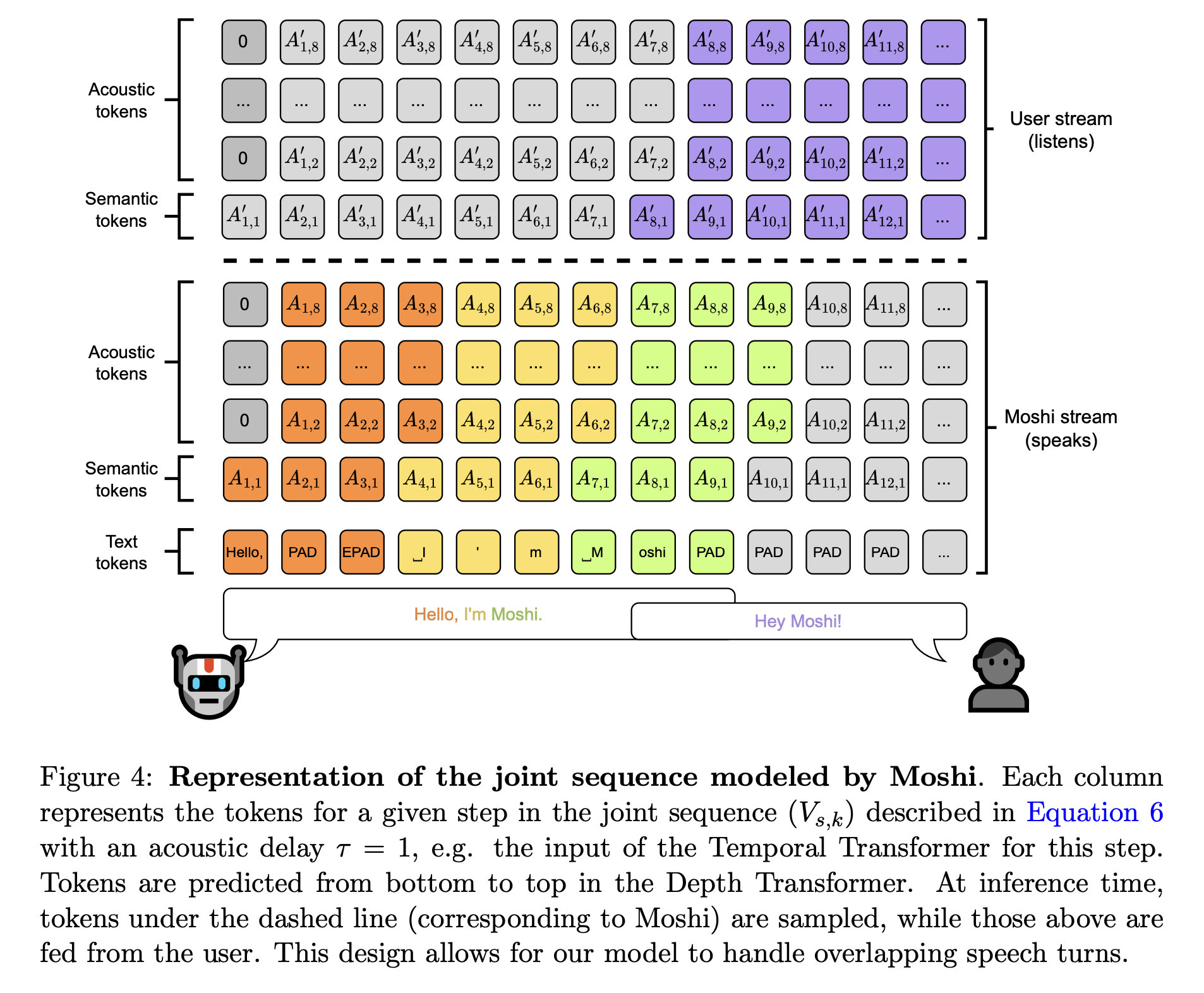
Moshi는 user와 system(moshi)가 턴을 변경하는 경계가 없습니다. 논문에선 Full-Duplex 대화 시스템이라고 부르는데요. 앞서 이야기한 multi-stream 방식으로 있도록 모델을 구축했기 때문에 user와 system(moshi)이 동시에 말하는 경우, Moshi는 두 발화를 모두 인식하고 시스템 발화와 사용자 발화를 적절히 구분하여 대화를 처리할 수 있게 됩니다. 또한 사용자가 시스템 발화 중에 끼어들어 말할 때에도, Moshi는 이를 인식하고 시스템 발화를 중단하거나 이어서 사용자와 대화할 수 있게 됩니다.
마치며
논문 전체를 읽은 것도 아닌데 내용이 상당히 방대했습니다. 하나의 코어 기술이 있다기보다는 경량화부터 화자 분리까지 대화 시스템에 필요한 다양한 고난도의 기술을 정교하게 엮어 만든 것 같다는 생각이 들었습니다. 특히 Moshi가 필요한 모델을 전부 from-scratch로 훈련한 foundation 모델이라는 사실이 놀라웠습니다. Technical Report라 내용이 순차적으로 소개되어 있지 않아서 설명 순서를 정리하는 데에 애를 꽤 먹었는데, 실시간 대화 시스템을 이해하는데 도움이 되셨으면 합니다.
참고문헌
Défossez, Alexandre, et al. "Moshi: a speech-text foundation model for real-time dialogue." arXiv preprint arXiv:2410.00037 (2024).
Zhang, Xin, et al. "Speechtokenizer: Unified speech tokenizer for speech large language models." arXiv preprint arXiv:2308.16692 (2023).
