이번 포스팅에서는 Meta에서 10월에 공개한 SpiritLM 논문에 대해서 리뷰해보도록 하겠습니다. 게시글의 모든 이미지 출처는 원문에 있습니다.
원문 : https://arxiv.org/abs/2402.05755
데모 페이지 : https://speechbot.github.io/spiritlm/
SpiritLM은 쉽게 말하면 음성과 텍스트를 동일한 tokenizer로 구현한 모델입니다. 그래서 논문 제목처럼 ‘interleaved’ model인거죠. ASR, TTS, LLM이 동시에 되는 단일 모델이라기보다 단일 토크나이저로 이해해주시면 좋을 것 같습니다.
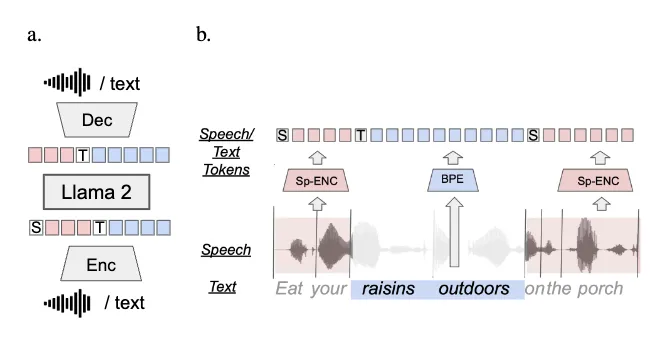
SpiritLM에서는 음성과 텍스트 데이터를 단어 단위로 교차하는 방법(word-level interleaving method)을 활용하여 모델을 학습한 것인데요, 음성 토큰과 텍스트 토큰을 하나의 sequence로 연결하여 LLM에서 처리한다는 점이 이 모델의 핵심입니다. 이전 포스팅에서 여러 audio-LLM 모델(혹은 툴킷)을 소개드렸었는데요, 이전에 소개드린 모델과 어떤 점이 다른지 차차 설명드리겠습니다.
Background
음성 모델
모델을 설명하기 위해 음성인식 기술 배경에 대해 간단하게 설명드리겠습니다. SSL(Self-supervised learning)의 등장으로 라벨링된 텍스트 없이도 raw audio에서 바로 speech representation을 학습할 수 있게 되었습니다. SSL이 등장하기 전에는 무조건 음성 unit과 텍스트를 쌍으로 만들어서 모델을 학습시켜야 했는데요, SSL을 통해 음성을 pseudo-text의 모양을 띄는 discrete token으로 나눌 수 있게 된 것입니다. 또한 SSL 방식은 음성의 언어적 특성뿐만 아니라 음율, 감정 등 다양한 정보를 추출할 수 있어 감정 등을 인식하거나 분류하는 모델을 쉽게 구축할 수 있게 되었습니다. 대표적인 SSL 기반의 음성 모델로는 Wav2vec2.0과 HuBERT가 있습니다. 참고로 많은 분들이 알고 계시는 OpenAI의 whisper는 SSL이 아니라 그냥 supervised learning 기법을 사용했습니다. 대신 다른 음성인식 모델들과 차원이 다른 양의 라벨링된 학습 데이터를 사용하여 엄청난 성능을 자랑하는 것이죠.
audio-LLM
하지만 음성 모델을 LLM과 연결하기 위해서는 별도의 adapter가 필요했습니다. 음성 모델에서 음성을 처리하는 tokenizing 방법과 LLM에서 텍스트를 처리하는 tokenizing 방법이 달랐기 때문입니다. 따라서 저희가 흔히 알고 있는 audio-LLM 모델은 음성 모델의 encoder에서 임베딩된 음성이 차원을 조정해주는 audio adapter를 거쳐 LLM의 인풋으로 들어가게 됩니다. LLM은 ‘음성’ 자체를 학습한다기보다 어떠한 규칙에 의해 변환된 벡터들을 텍스트 문맥을 참고하여 문맥으로서 이해하게 되는 것이죠.
SpiritLM
이러한 제약을 극복하기 위해 제안된 모델이 SpiritLM입니다. 모델은 기본적으로 Llama2-7B 기반으로 Continuously pretraining한 모델입니다. SpiritLM은 음성을 음성 단위(phonetic unit)로만 인코딩한 BASE 모델과 음운 단위에 피치(pitch)와 스타일(style) 단위를 추가한 EXPRESSIVE 모델 두 종류가 있습니다.
Tokenizing (Encoder)
모델의 토크나이저는 음성(phonetic), 피치, 스타일, 텍스트 토큰을 한 번에 처리할 수 있습니다.
-
phonetic token (음성 토큰)
음성 토큰은 Hubert라는 음성 모델에서 501개의 phonetic speech token 을 추출하였습니다. Hubert는 encoder에서 raw audio를 clustering하는데요. 이 clustering 정보를 기반으로 입력한 음성에 대해서 501개의 음성 토큰으로 변환하였습니다. 이렇게 생성되는 음성 토큰을 spirit LM 학습에 사용하게 되었습니다. 모델에서 음성 토큰은 1초 음성 기준으로 25개의 토큰으로 변환됩니다.
-
Pitch and Style token
HuBERT는 피치나 스타일 토큰 추출에는 성능이 좋지 않았기 때문에, 다른 모델을 사용하여 토큰을 추출했다고 합니다. 우선 Pitch 토큰은 VQ-VAE를 사용하여 생성하였습니다. 음성의 F0(기본 주파수) 정보를 추출한 뒤, 이를 K-means 클러스터링하여 총 64개의 토큰으로 음성의 피치를 분류했다고 합니다. 피치 토큰은 1초에 12.5개의 토큰으로 변환됩니다.
Style 토큰은 Sonar expressive라는 모델에서 추출하였습니다. Sonar expressive는 입력한 음성의 스타일을 캡쳐하는 모델인데요. 쉽게 이야기하면 분노, 기쁨 등의 감정이 하나의 스타일이라고 보시면 됩니다. 모델을 통해 100개의 token으로 스타일 토큰으로 클러스터링하였습니다. 그리고 학습 음성을 1초 단위로 나눠서 평균 값으로 추출하여, 1초에 1개의 토큰으로 변환되도록 하였습니다. 스타일을 인식할 때에는 speaker 정보가 영향을 줄 수 있기 때문에 음성의 speaker 정보는 normalization 통해 제거하였다고 합니다.
-
text token
텍스트 토큰은 원 모델인 Llama2의 tokenizer를 그대로 사용하였다고 합니다.
입력한 음성과 텍스트는 결과적으로 아래와 같은 형태로 LLM의 인풋으로 입력되고, 동일한 형식으로 생성되어 출력됩니다. 음성과 텍스트를 구분하기 위해 음성이 시작될 때에는 [SPEECH] 토큰이 붙고, 텍스트가 시작될 때에는 [TEXT] 토큰이 붙습니다.

Decoder
모델은 입력 토큰을 기반으로 텍스트 토큰과 음성 토큰 생성합니다. STT를 할지, Speech to speech를 할지 등의 테스크는 앞서 말한 [SPEECH], [TEXT] 토큰 등과 함께 프롬프트로 지시합니다.
음성 출력은 HuBERT의 스피치 토큰으로 음성 합성 모델인 HifiGAN을 학습하여 구축하였습니다. 학습 시 deduplicated된 토큰을 사용했지만 음성 길이를 학습하기 위해 duration prediction module을 함께 훈련하였습니다. 따라서 실제 음성이 생성될 때에는 deduplicated된 토큰이 음성 길이에 맞게 반복되어 출력된다고 합니다.
Dataset
학습 데이터는 텍스트 전용 시퀀스, 음성 전용 시퀀스, 음성-텍스트 혼합 시퀀스로 나누어 학습을 진행하였다고 합니다. 음성은 총 570k 시간을 사용했다고 합니다. (참고로 whisper는 680k 시간의 음성 데이터를 사용하였습니다.)
Deduplicate 방식을 적용하여 동일한 토큰이 연속적으로 나올 때에는 중복 제거를 진행하여 학습을 진행했다고 합니다. 또한 음성-텍스트 혼합 데이터에서는 두 모달리티가 균일하게 훈련되도록 비율을 조정했다고 합니다.
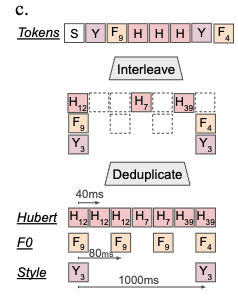
Training
음성-텍스트 혼합 데이터를 학습할 때에는 음성과 텍스트를 단일 스트림으로 결합하여 단어 단위로 교차(interleaving)하는 방법을 사용하여 학습을 진행했다고 합니다. 학습 중에는 모달리티 변경이 단어 경계를 기준으로 무작위로 발생시켜서 텍스트와 음성을 하나의 시퀀스로 자연스럽게 이해하도록 했다고 하네요.
Model performance
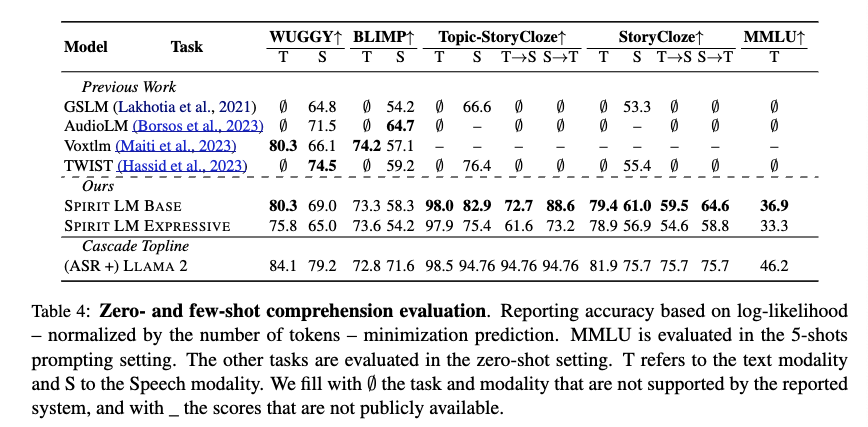
모델을 평가할 때에는 S→T, T→S를 수행할 수 있는 다른 모델이 없기 때문에 Whisper-medium과 Llama2-7B, MMS-TTS를 cascade models로 사용하여 비교했다고 합니다. S→T, T→S의 성능을 평가할 수 있는 비교군이 없어 ‘좋은 성능’을 가지고 있는지 확인할 수 없다고 생각하기 때문에 자세히 다루지 않고 넘어가겠습니다. Cascade 모델보다는 성능이 낮은 걸 확인할 수 있습니다.
STSP(Speech-Text Sentiment Preservation) benchmark
논문에서는 새롭게 구축한 벤치마크를 소개하는데요. 감정을 포함한 텍스트와 음성을 생성하였을 때 주어진 입력의 감정을 정확히 보존하는지 평가하는 벤치마크입니다. Wav2Vec2 모델을 fine-tuning한 감정 분류기를 사용하여 모델의 성능을 평가한다고 합니다. 논문에서는 해당 벤치마크를 제시하면서 SpiritLM이 감정 표현을 잡아낼 수 있는 첫 번째 언어 모델이라는 점을 강조하였습니다.
Contribution & Limitation
자세히 다루진 않지만, 논문은 ablation을 통해 interleaving 학습이 텍스트와 음성 간의 자연스러운 상호작용을 학습하는 데에 큰 영향을 끼쳤다고 이야기합니다. 이런 실험을 통해 논문은 텍스트와 음성을 하나의 sequence에서 자유자재로 모달리티를 변경할 수 있는 모델을 제시했다는 점에서 멀티모달 모델에 큰 인사이트를 제시했다고 생각합니다. 하지만 모델은 영어 데이터 기반으로 학습해서 non-English에 대한 수행 능력을 측정하지 못했고, 학습한 모델의 텍스트 작업의 수행 능력이 기존 Llama2 모델보다 떨어졌다는 점에서 한계가 있다는 점을 제시했습니다. 또한 Pitch와 Style 토큰의 추가는 일부 테스크(특히 음성 이해 테스크에서)에서 성능 저하를 발생시켰다고 하네요. 이러한 한계가 있지만 앞으로의 음성 언어모델 발전이 기대가 되는 논문이었습니다.
Reference
-
Baevski et al. (2020) present wav2vec 2.0, a self-supervised framework for learning speech representations by masking latent speech inputs and solving a contrastive task over quantized representations, achieving state-of-the-art results in speech recognition with limited labeled data.
-
Hsu et al. (2021) introduce HuBERT, a self-supervised speech representation learning model that predicts hidden unit representations of masked audio segments, utilizing offline clustering to generate target labels for a BERT-like prediction loss, achieving state-of-the-art performance in speech recognition tasks.
-
Nguyen et al. (2024) introduce SPIRIT LM, a multimodal language model that integrates text and speech, enabling tasks like ASR, TTS, and speech classification through interleaved training on both modalities.
