[논문리뷰] Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
0
논문리뷰
목록 보기
5/5
모든 이미지 출처 : 논문 원문
모델 종류
- Phi-4-Mini
- 3.8B 파라미터를 가진 소형 언어 모델
- Phi-3.5-Mini와 비교해 어휘 크기를 200K 토큰으로 확장 + 다국어 지원 강화
- 논문에 reasoning-enhanced Phi-4-Mini에 대한 실험 결과가 나와있지만 모델은 아직 공개하지 않았다고 함 (지금은 공개됨)
- Phi-4-Multimodal
- Phi-4-Mini에 비전, 오디오 인코더 결합한 통합 멀티모달 모델
- 비전-언어 벤치마크에서 기존 모델보다 향상된 성능
- 높은 성능의 다국어 음성 인식, 번역, 요약
- 음성인식 리더보드(OpenASR)에서 1위 달성
- 30분 이상의 음성에 대한 요약 기능을 갖춘 최초의 오픈소스 모델
Phi-4-Mini 주요 특징
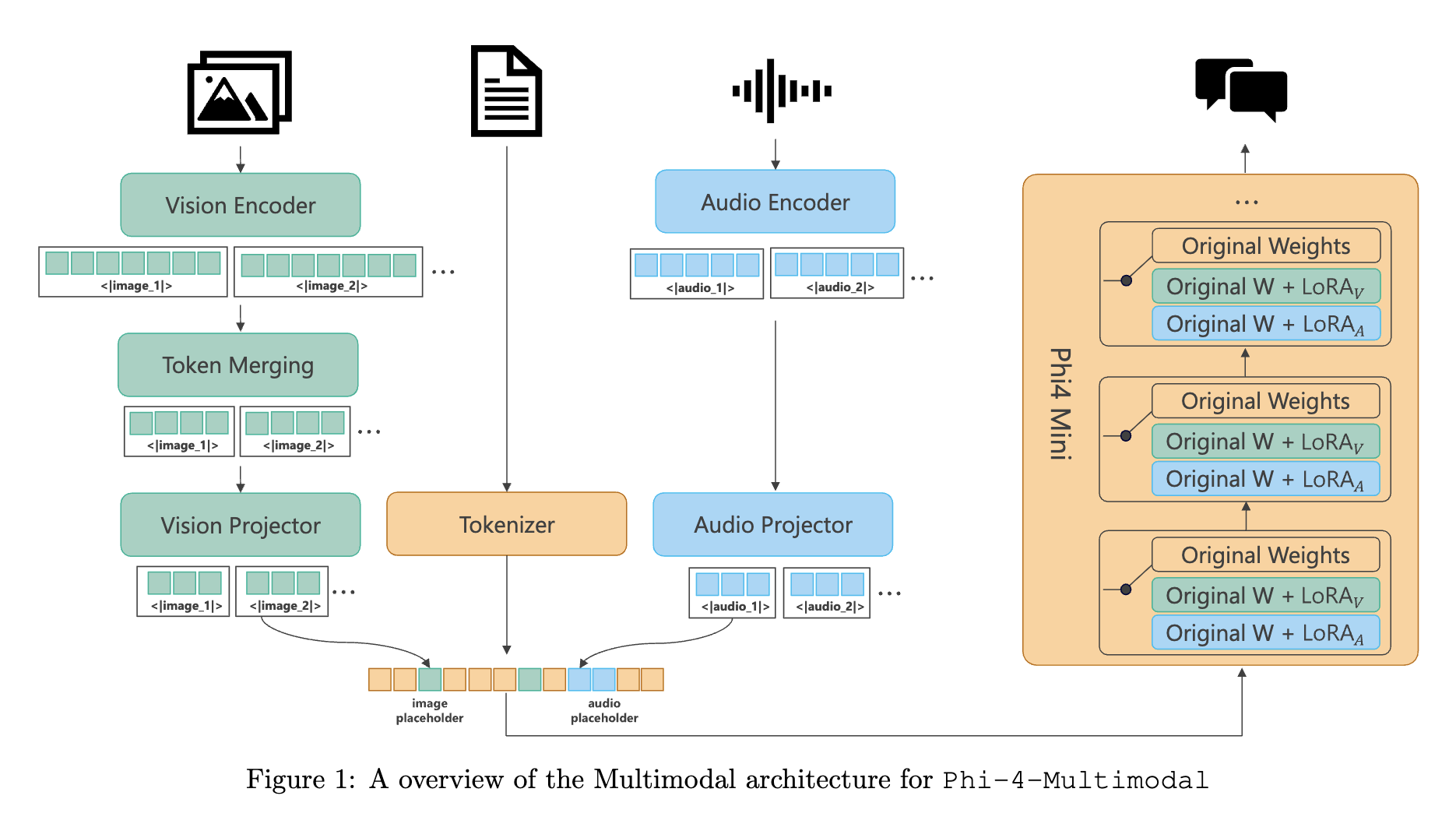
- Mixture-of-LoRAs
- 언어 모델을 완전히 동결한 상태에서 모달리티를 LoRA 어댑터로 연결
- 모달리티 간 간섭 최소화
- 언어 모델을 완전히 동결한 상태에서 모달리티를 LoRA 어댑터로 연결
- Group Query Attention
- 장문 생성을 위한 KV 캐시 사용을 최적화
- 128K 컨텍스트 길이
- LongRoPE 기반의 긴 컨텍스트 학습
Phi-4-Mini 학습
model architecture
- 32개의 transformer layer, 3072 dimension hidden state
- tied input / output embedding (가중치 공유 - 메모리 소비 감소)
- GQA(Group Query Attention) 사용: 24개 query 헤드, 8개 key/value 헤드
- 쿼리(Q) 헤드 수와 키/값(K/V) 헤드 수를 다르게 설정
- 여러 쿼리 헤드가 같은 키/값 헤드를 공유 (캐시 크기 감소)
- 128K 컨텍스트 길이 지원 (LongRoPE 기반)
- 200,064 어휘 크기의 o200k_base tiktoken 토크나이저 사용
method
- Pre-training
- Phi-3.5-Mini에서 지향한 퀄리티 높은 사전학습 데이터 관점과 동일하게 5조 토큰 데이터 제작

- Post-training
- 함수 호출, 요약, 지시 따르기, 코드 완성 등의 데이터셋으로 미세 조정 (데이터 크기를 공유하진 않음)
- Chain-of-Thought(COT) 스타일의 reasoning 데이터를 만들었지만 공개한 체크포인트에는 사용하지 않았다.
Phi-4-Multimodal 학습
Mixture-of-LoRAs method
- 기본 언어 모델(Phi-4-Mini)을 완전히 동결
- 모달리티별 인코더를 각각 사용 (비전 인코더, 오디오 인코더)
- encoder : raw 입력을 벡터 시퀀스 형태로 변환
- 모달리티별 프로젝터로 각 모달리티의 임베딩을 언어 모델의 임베딩 공간으로 매핑
- projector : 벡터 시퀀스를 LLM 임베딩과 동일하게 변환
- 모달리티별 LoRA 어댑터를 언어 모델에 적용하여 각 모달리티 처리 최적화
- adapter : 모달리티를 이해하기 위해 LLM 내부 모든 linear layer에 추가되는 파라미터
1. 비전 학습
1-1. model architecture
- 비전 인코더
- LLM2CLIP으로 파인튜닝한 SigLIP-400M(구글 모델) 기반 이미지 인코더
- 해상도 448×448로 학습
- dynamic multi-crop strategy 사용해서 다양한 해상도 이미지 처리
- 비전 프로젝터
- 2-layer MLP
- 비전 인코더와 프로젝터는 440M 파라미터, 비전 어댑터 LoRA는 추가로 370M 파라미터
1-2. dataset
- 이미지-텍스트 문서, 이미지-텍스트 쌍, 이미지 그라운딩 데이터(바운딩 박스)
- PDF 및 실제 이미지의 OCR 합성 데이터셋
- 차트 이해를 위한 합성 데이터셋
- 사전 학습에 0.5T 토큰, SFT에 0.3T 토큰 사용
1-3. method (4단계)
- Projector Alignment
- 캡션 데이터를 사용하여 프로젝터만 학습
- 비전 인코더의 사전 학습된 표현 보존하면서 비전과 텍스트 임베딩을 정렬
- Joint Vision Training
- 프로젝터와 비전 인코더를 함께 학습
- OCR 등 정밀한 이해 필요로 하는 테스크 성능 개선
- Generative Vision-Language Training
- 언어 디코더에 LoRA 적용 및 학습
- 단일 프레임(단일 이미지) SFT 데이터로 비전 인코더 및 프로젝터와 함께 훈련
- Multi-Frame Training
- 비전 인코더는 동결하고 다중 프레임 SFT 데이터로 학습
- 컨텍스트 길이를 64K까지 확장하고 다중 이미지 및 시간적 이해 가능
- 긴 컨텍스트, 여러 이미지 간의 관계 이해, 시간적 순서나 변화
2. 음성 및 오디오 학습

2-1. model architecture
- 오디오 인코더
- 10ms 프레임 속도를 가진 80차원 log-mel filterbank
- 3개의 convolution layer와 24개의 conformer 블록으로 구성된 오디오 인코더
- 음성 토큰 속도는 80ms, 1분에 750 토큰
- 오디오 프로젝터
- 1024차원 음성 특징을 3072차원의 텍스트 임베딩 공간으로 매핑하는 2-layer MLP
- 오디오 인코더와 프로젝터는 460M 파라미터, 어댑터는 또 다른 460M 파라미터 추가
2-2. dataset
- Pre-training: 8개 언어(중국어, 영어, 프랑스어, 독일어, 이탈리아어, 일본어, 포르투갈어, 스페인어)로 구성된 2M 시간의 음성-텍스트 쌍
- Post-training: 다양한 태스크별 데이터셋
- 음성 인식: 약 40k 시간의 공개(20k) 및 사내(20k) 데이터 (8개국어)
- 음성 번역: 약 30K 시간의 번역 데이터 (eng→7 languages, 7 languages→ eng)
- 음성 요약: 1M weighted SFT examples with English speech only
- 최대 30분 길이의 회의 녹음 데이터
- 오디오 이해: 17M weighted SFT examples
- SQQA, SQA : 26M weighted SFT examples
2-3. method (2단계)
-
Pre-training:
- 대규모 자동 음성 인식 데이터로 오디오 인코더와 Phi-4-Mini를 정렬
- 오디오 인코더와 프로젝터만 업데이트
- LLM은 동결 상태 유지
-
Post-training:
<∣user∣><audio>{task prompt}<∣end∣><∣assistant∣>{label}<∣end∣>- 약 100M개의 큐레이션된 음성 및 오디오 SFT 샘플로 학습
- 오디오 인코더는 동결하고 오디오 프로젝터와 LoRA만 업데이트
- 다양한 음성/오디오 테스크 학습 (ASR, 음성 번역, 음성 QA, 음성 요약 등)
- 최대 30분 길이 오디오(22.5k 토큰)까지 처리 가능
3. 비전-음성 공동 학습 (Vision-Speech Joint Training)
dataset
- 비전-텍스트 SFT 데이터 일부 재사용
- TTS 엔진으로 텍스트 쿼리를 오디오로 변환
- 생성된 TTS 음성을 자사 ASR로 전사 후 WER 측정하여 품질 체크
method
- 비전 Post-training과 음성 Post-training 이후에 진행
- LLM, 오디오 인코더, 오디오 프로젝터는 동결
- 비전 어댑터 LoRA, 비전 인코더, 비전 프로젝터만 fine-tuning
- 비전-음성 SFT 데이터와 언어 및 비전 Post-training 데이터를 혼합해서 학습
모델 성능
1. LLM
- Llama-3.1-8B랑 비슷함
- coding performance : Qwen2.5-Ins 7B보단 낮고 Gemma2-It 9B보단 높음
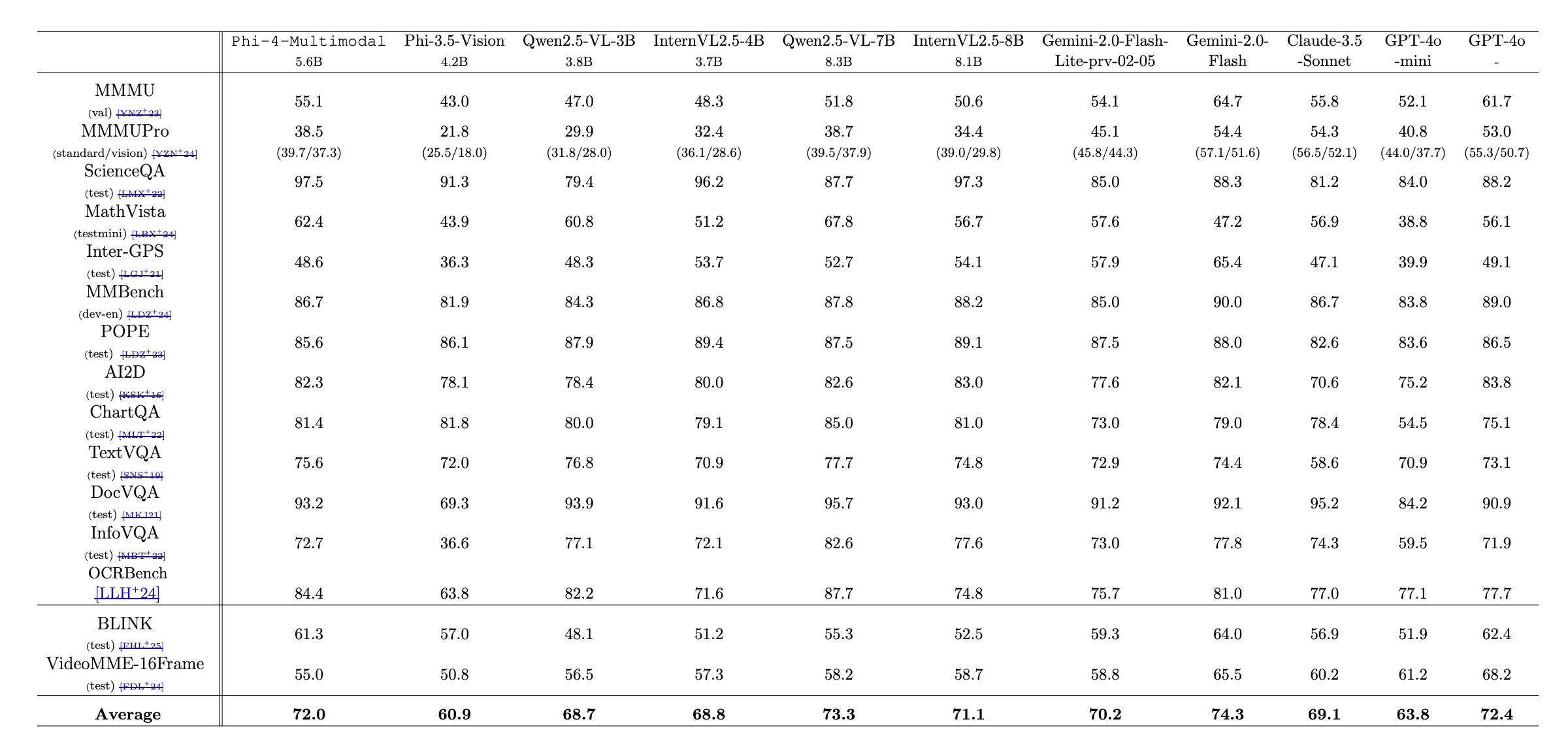
2. vision-language
- GPT-4o와 평균은 비슷하지만 분포는 다른 것 같다
- 와중에 qwen2.5-VL-7B랑 Gemini2.0-Flash 점수가 높다
3. speech
- ASR 성능은 가장 높지만 요약이랑 오디오 대화는 gpt-4o가 성능이 더 좋음 (특히 오디오 대화)
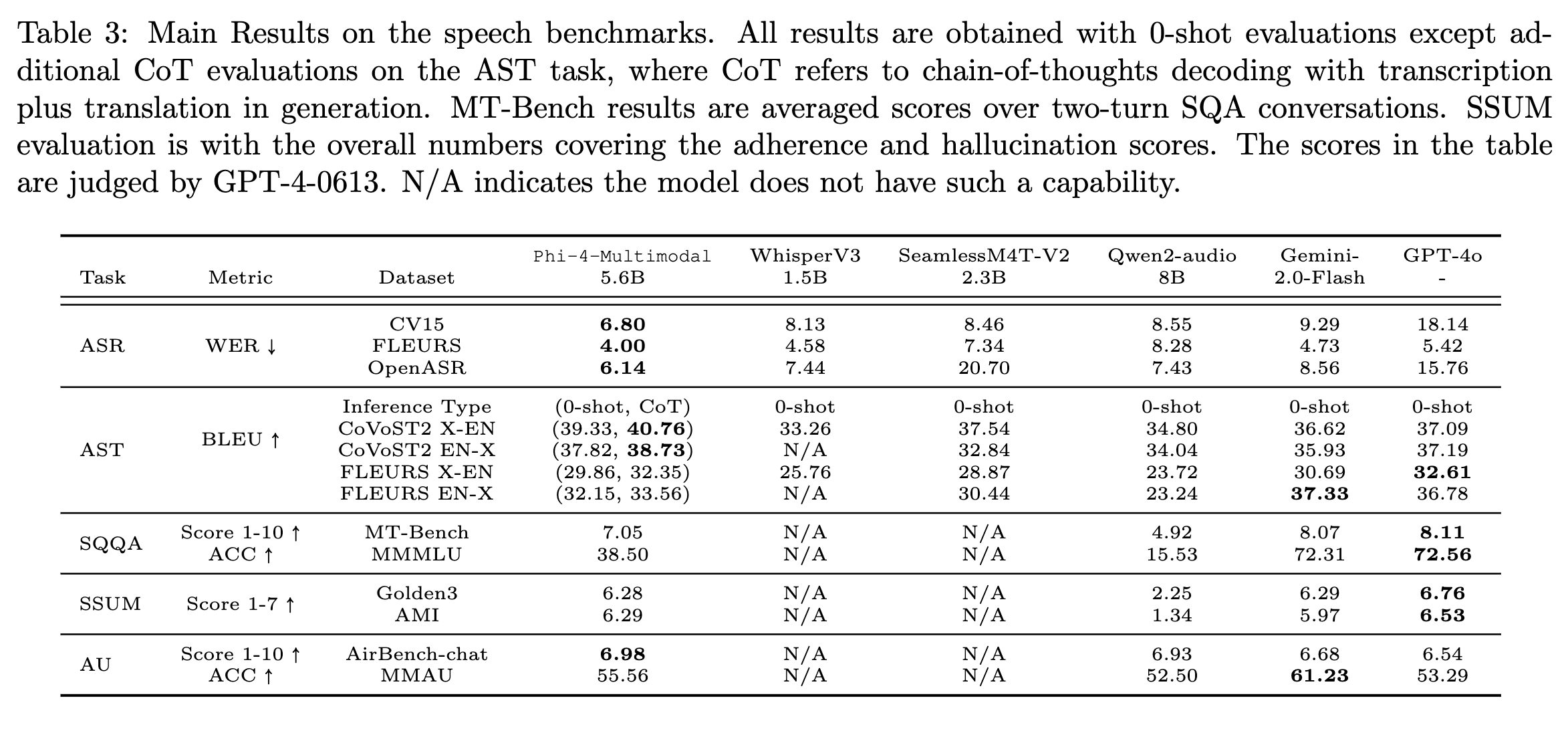
- ASR : automatic speech recognition
- AST : automatic speech translation
- SQA : speech question answering
- SQQA : spoken query question answering
- SSUM : speech summarization
- AU : audio understanding
4. vision-speech
- 아직 많이 연구가 안 되어서 비교 모델이 별로 없음
- 얼마전에 카이스트에서 vision(영상)-speech 관련 논문을 냈다(daily paper에 올라옴)

정리좋아휴먼의 기록