35회
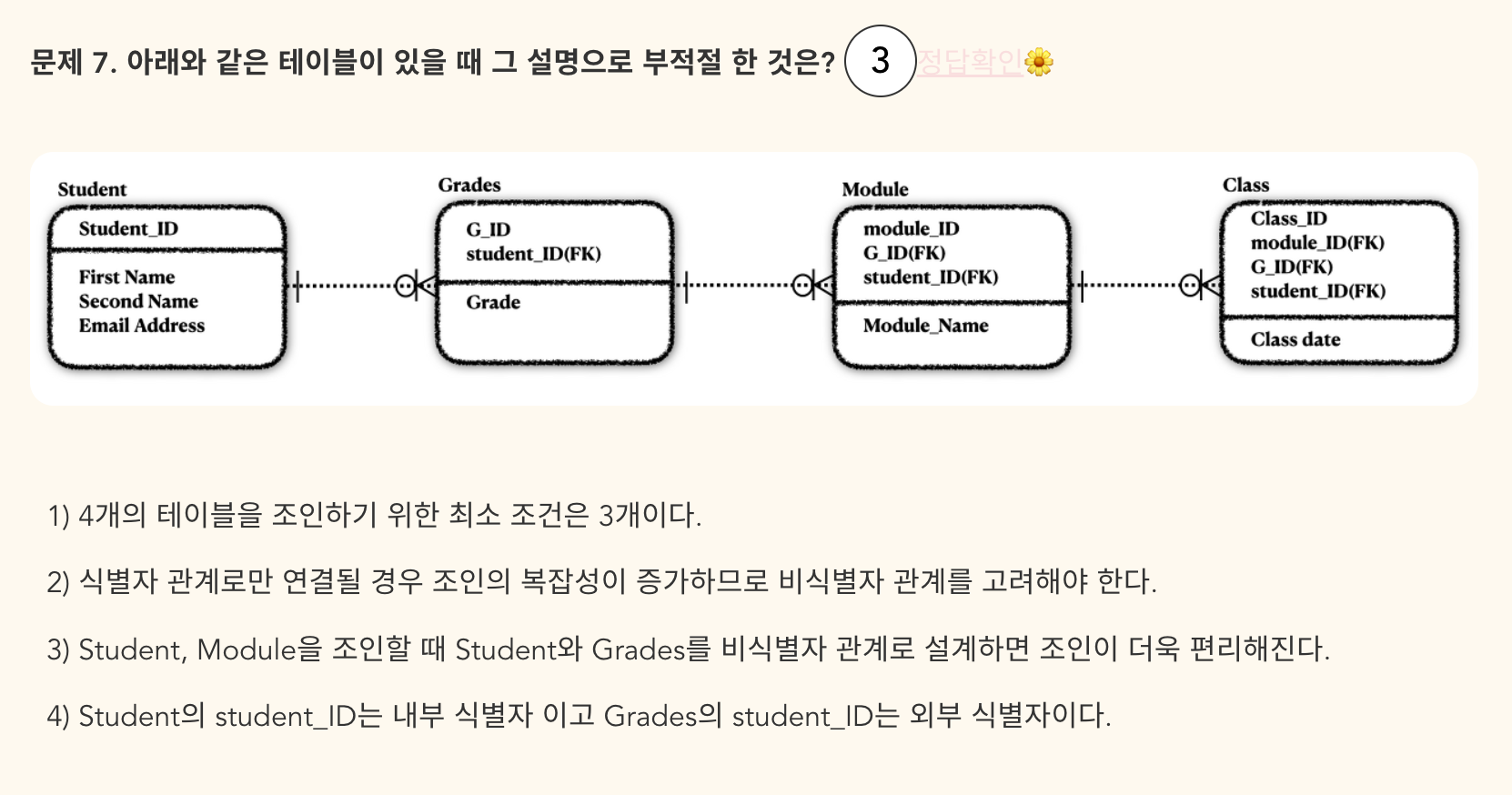
- 정답: 3 - Student, Grade를 비식별자 관계로 설계하면 Grade, Module은 식별자 관계이므로 오히려 조인의 복잡성이 커질 수 있다.

- 정답: 4 - 말장난 문제. 문제를 자세히 끝까지 읽을 것.

- 정답: 2 - NATURAL JOIN에서는 OWNER명 사용 불가

- 정답: 3. Lock - 자주 나오는 문제. Lock은 병행성 제어 기법, 무결성을 보장하기 위한 방법은 아님
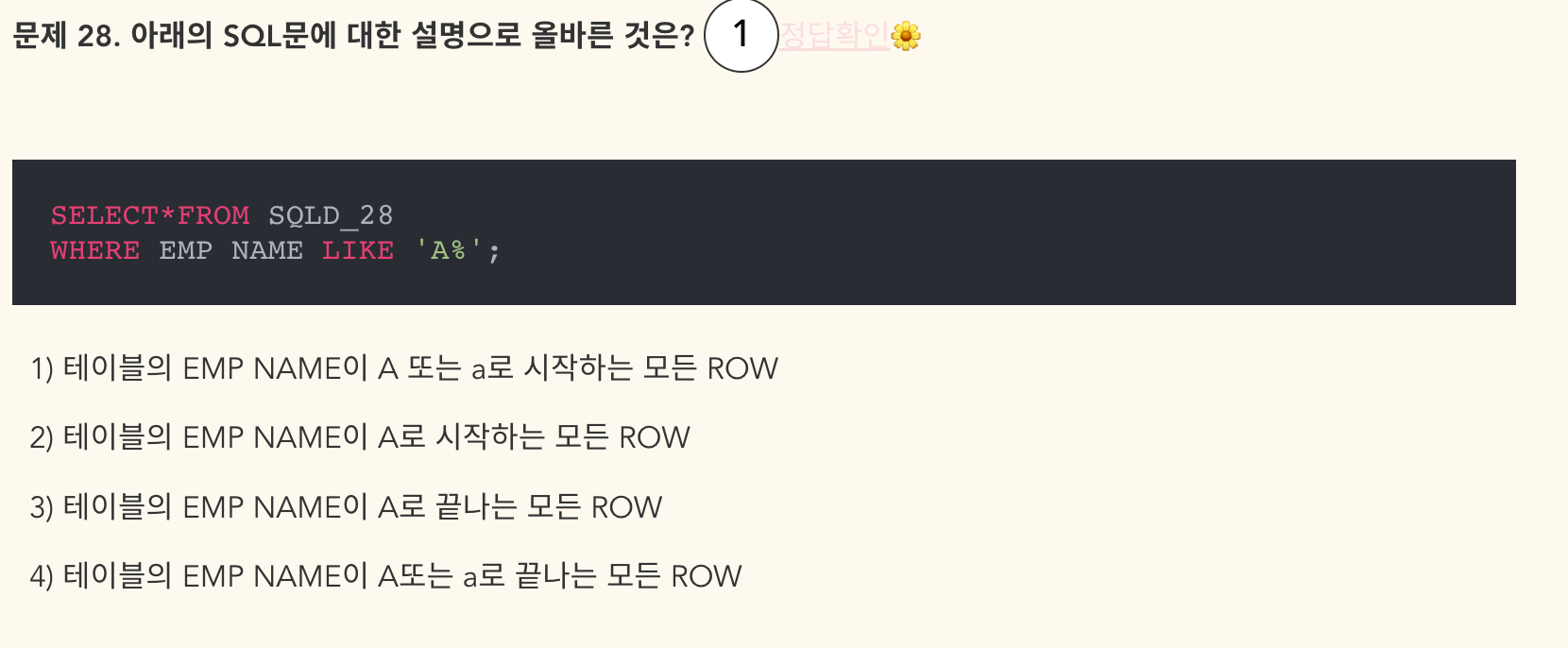
- 정답: 2 A로 시작하는 모든 ROW - 대문자, 소문자 모두 나오는 것이 아님 주의!
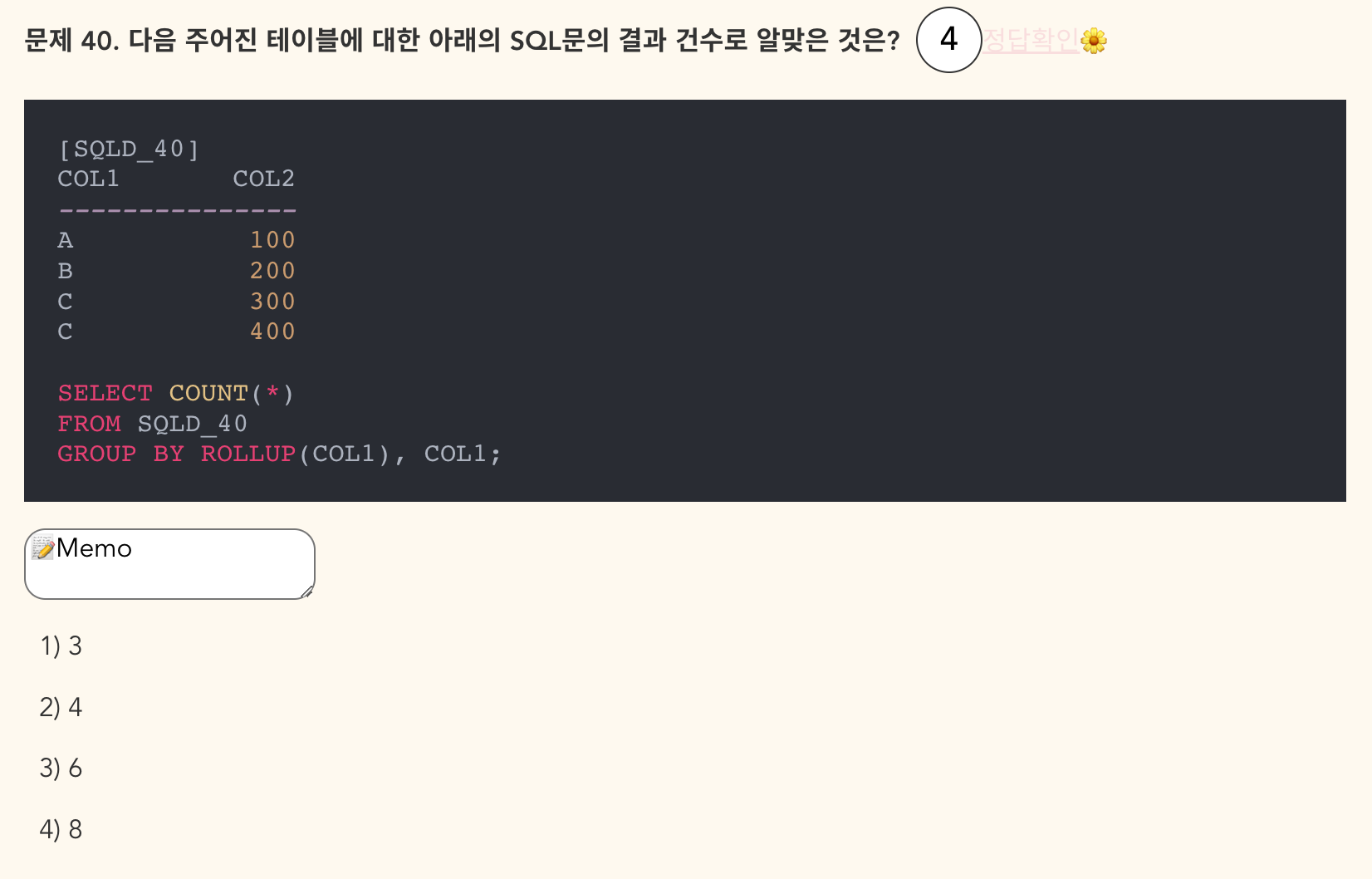
-
정답: 3) 6개
- ROLLUP(a), a
- (a), a 집계
- (), a 집계
- ROLLUP (a, b)
- (a, b) 합계
- (a) 합계
- () 합계
즉, (COL1)과 COL1 집계 3개, ()와 COL1집계로 3개, 총 6개가 나온다. 사실 이 문제는 잘 모르겠다...
- ROLLUP(a), a
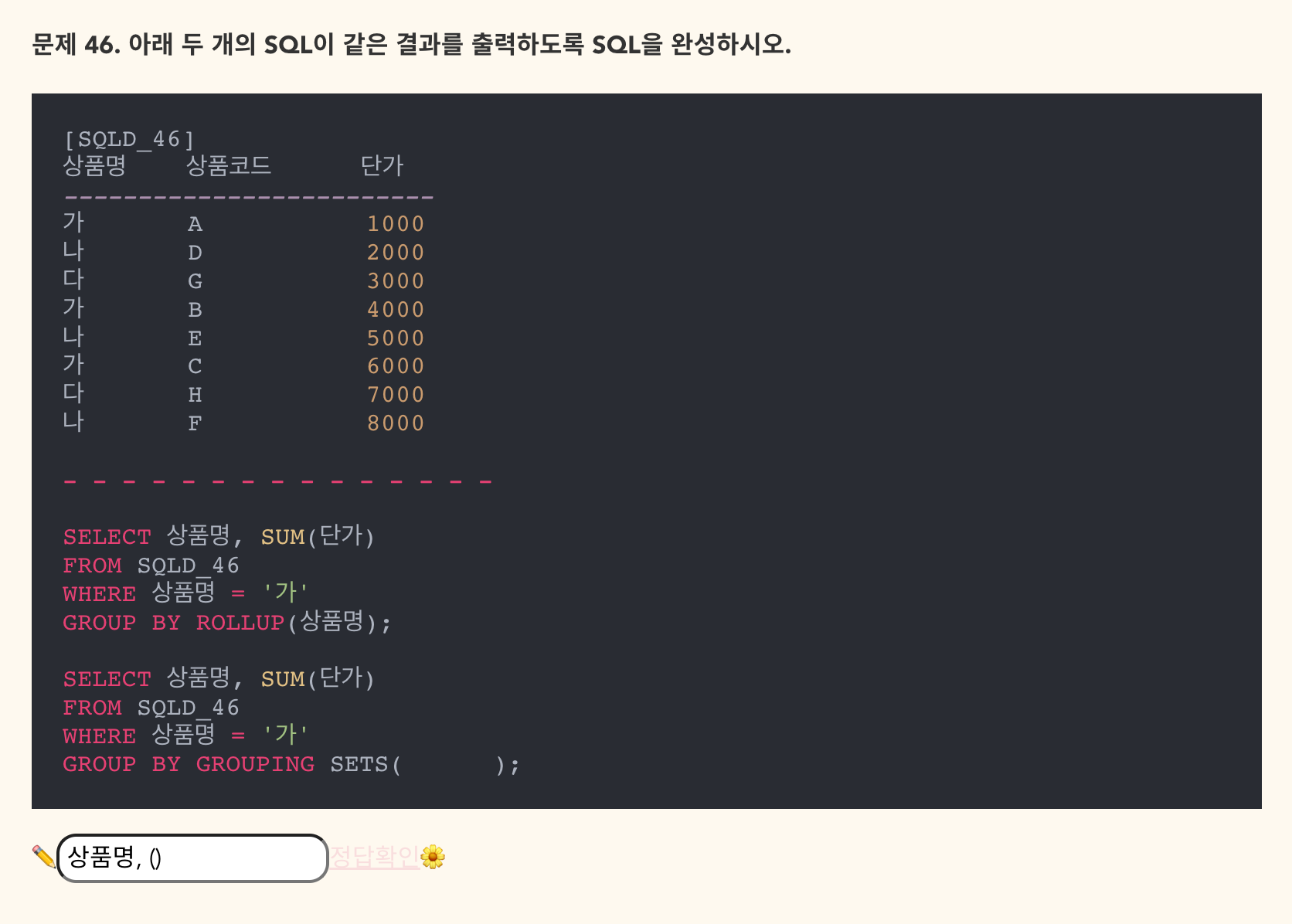
- 맞힌 문제이긴 하지만 헷갈리기 때문에 오답 노트 작성
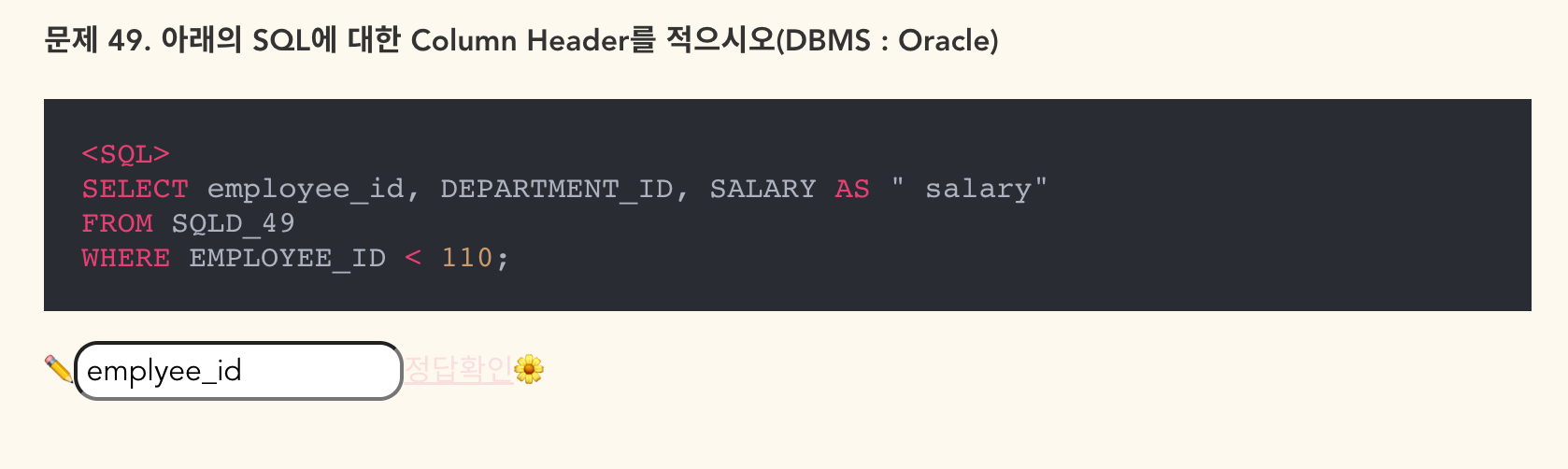
- 정답: EMPLYEE_ID, DEPARTMENT_ID, salary - 별칭이 없는 칼럼은 대문자로 바뀌고 별칭이 있는 칼럼은 그대로 사용.
37회

- 정답: 1 - 슈퍼/서브타입 데이터 모델에 대해 정확히 알지 못해 틀린 문제. 자주 나오는 유형이니 외워둘 것.
- One To One Type
- 슈퍼타입과 서브타입을 개별 테이블로 도출
- 테이블의 수가 많아서 조인이 많이 발생. 관리 어려움
- Plus Type
- 슈퍼타입과 서브타입 테이블로 도출
- 조인이 발생하고 관리 어려움
- Single Type
- 슈퍼타입과 서브타입을 하나의 데이터로 도출
- 조인 성능이 좋고 관리 편함. I/O 성능 나쁨
보기 1) One To One은 개별 테이블 O
보기 2) Plus Type이 아닌 Single Type이 하나의 테이블을 생성함
보기 3, 4) 조인 성능이 우수한 건 Single Type
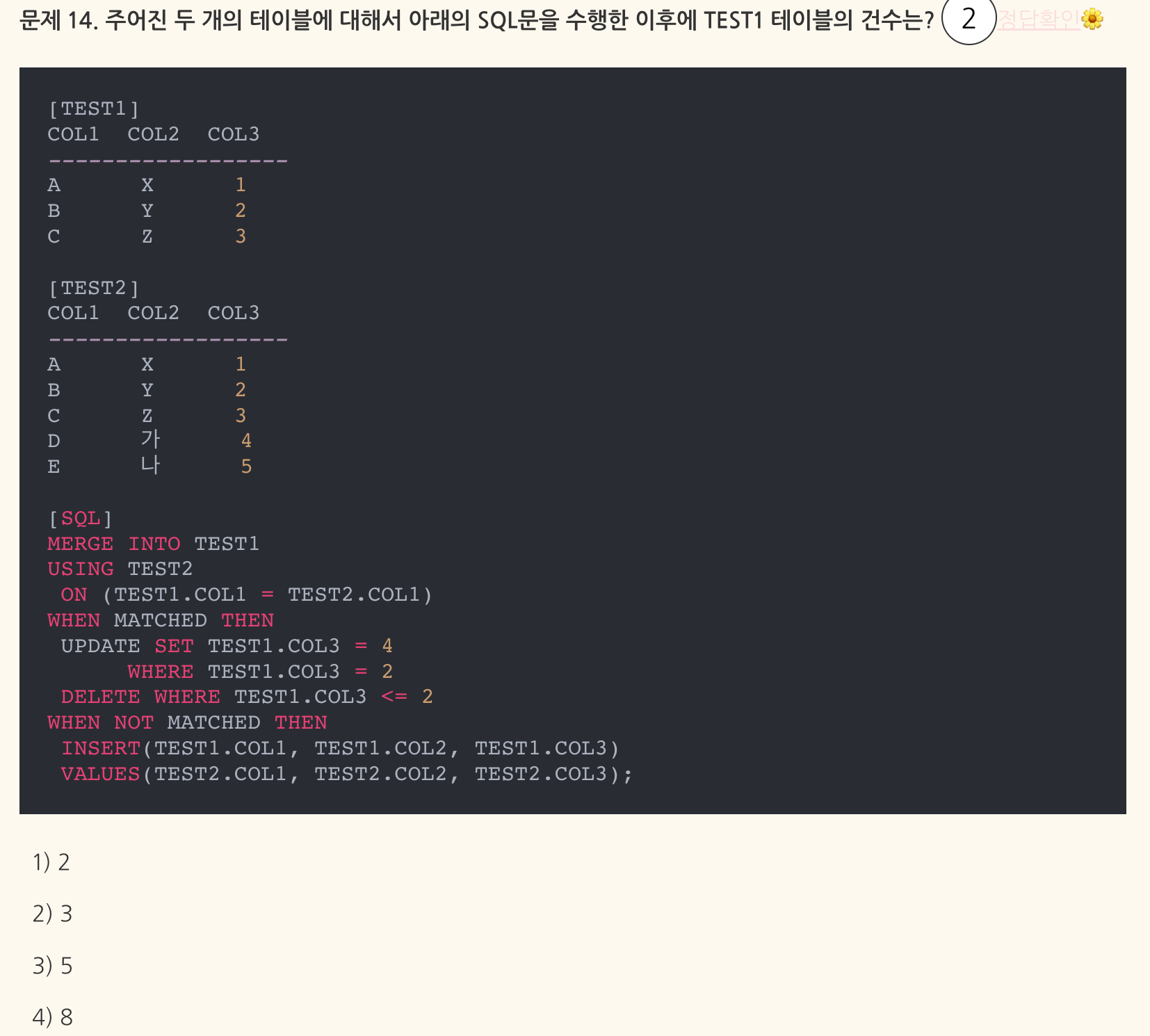
- 정답: 3 - MERGE: INSERT + UPDATE
레코드가 있을 때에 UPDATE, 없을 때 INSERT
위 문제에선 3개의 행이 Insert되고, Insert 되지 않은 2개의 행은 Update된다.
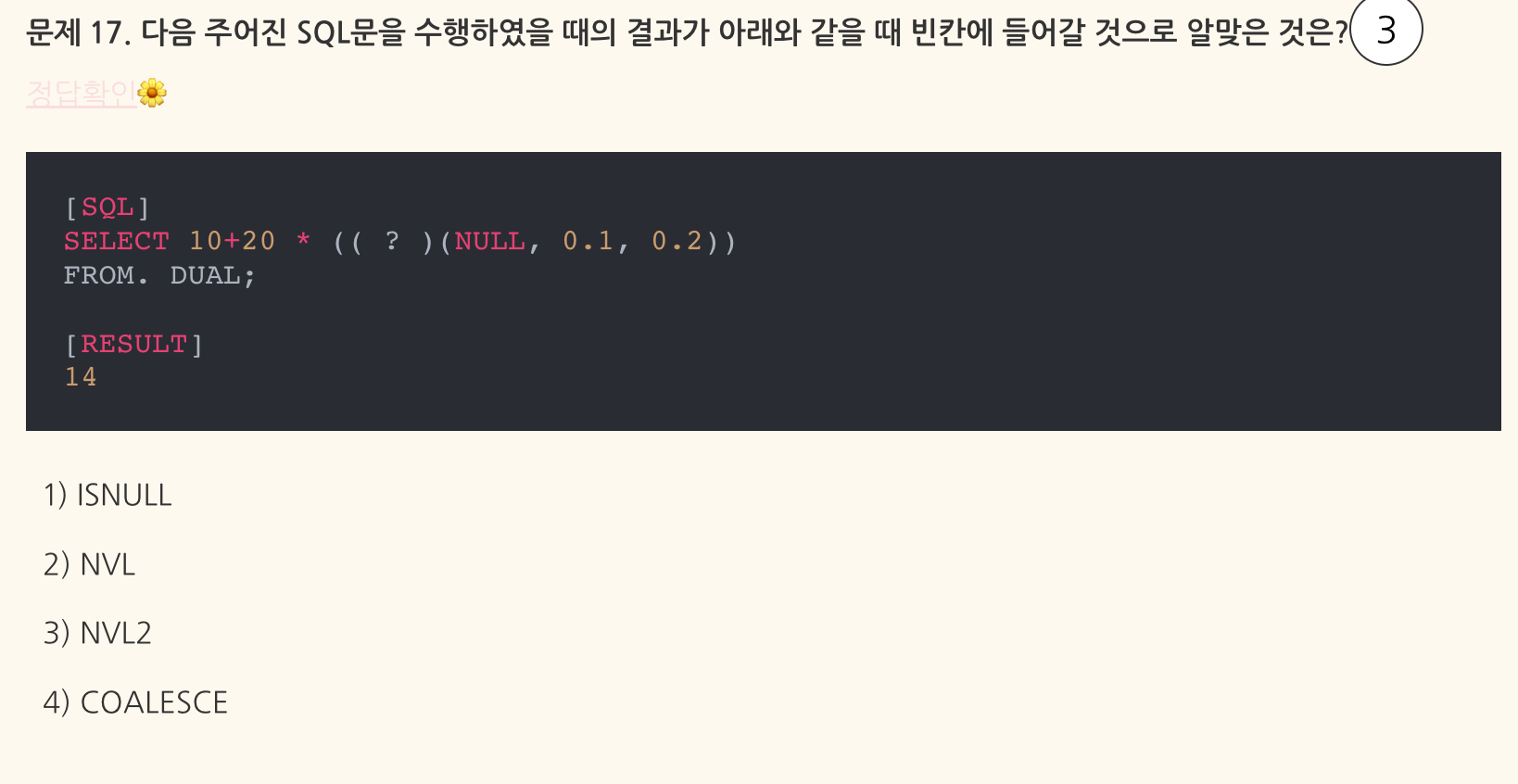
- 맞힌 문제이지만 순간 헷갈렸으니 오답 노트 작성
(?)(NULL, 0.1, 0.2)가 0.2가 되어야 함.
따라서(?)는 NVL2.

- 정답: 3: 앞의 한 건, 현재 행, 뒤의 한 건 사이의 평균이 아닌 앞의 한 건, 뒤의 한 건 사이의 급여 평균

- 맞힌 문제이지만 자주 나오는 유형이기 때문에 오답노트 작성
PL/SQL
- Block 구조
- 변수, 상수 선언 가능
- 절차형 언어 사용
- 응용 프로그램의 성능 향상
- DECLARE, BEGIN~END는 필수, EXCEPTION은 선택
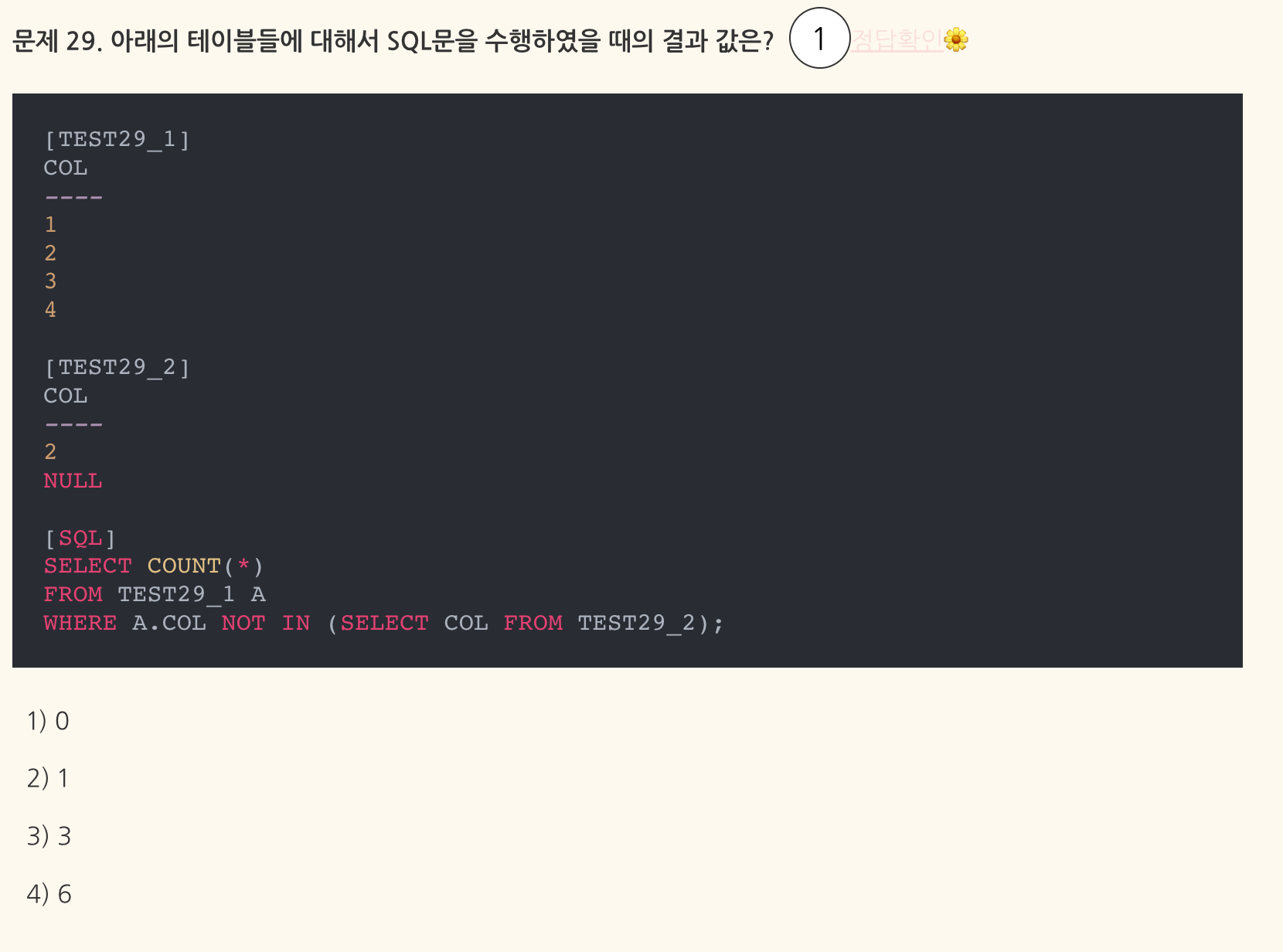
- 맞힌 문제이지만 다음 문제인 30번과 묶어서 외워둘 것.
- NOT IN문 서브쿼리의 결과 중에 NULL이 포함되는 경우 데이터가 출력되지 않음.
- IN 문은 OR 조건, NOT IN 문은 AND 조건
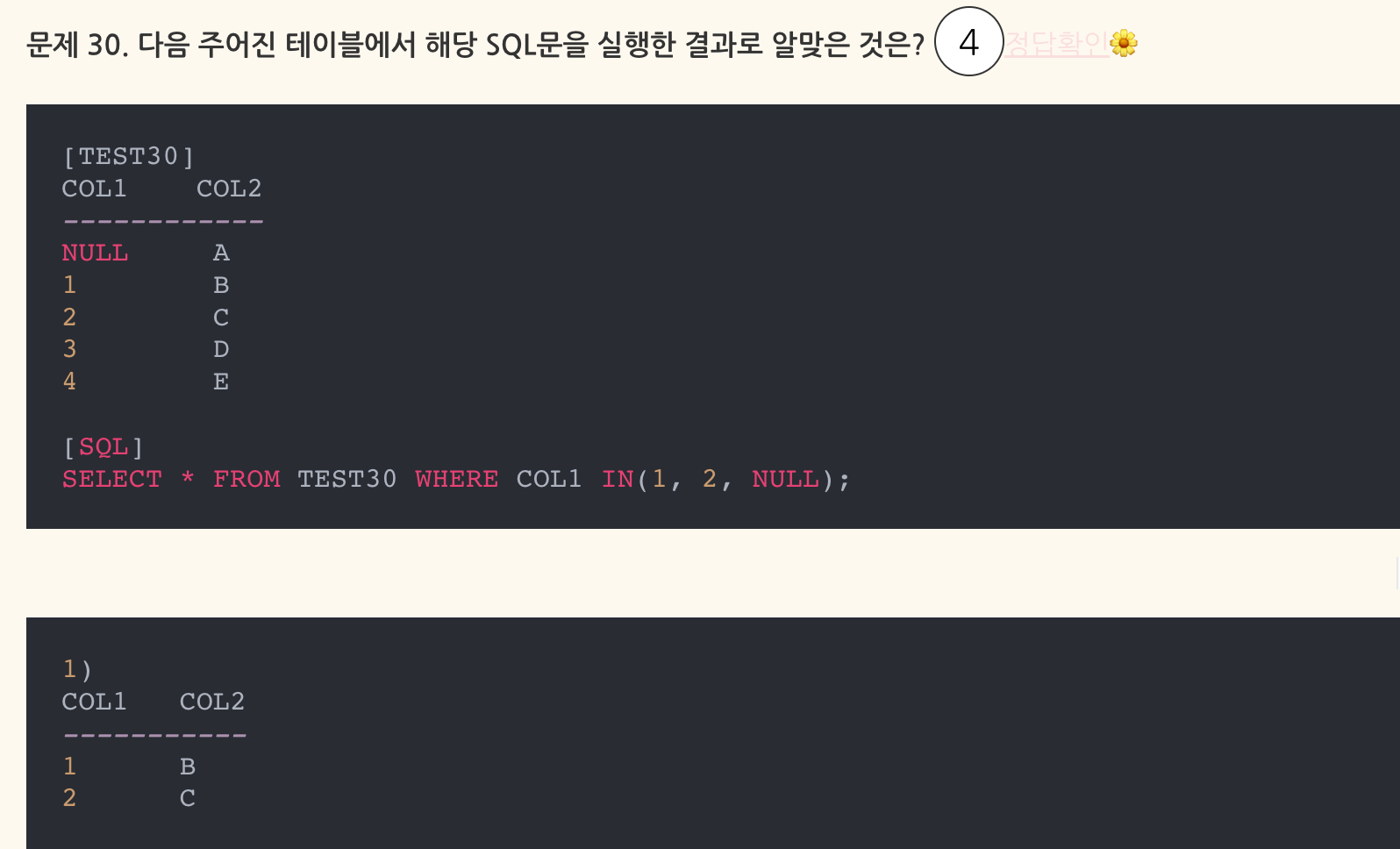
- 정답: 1
- NULL은 비교에서 제외됨. IN 문은 OR 조건
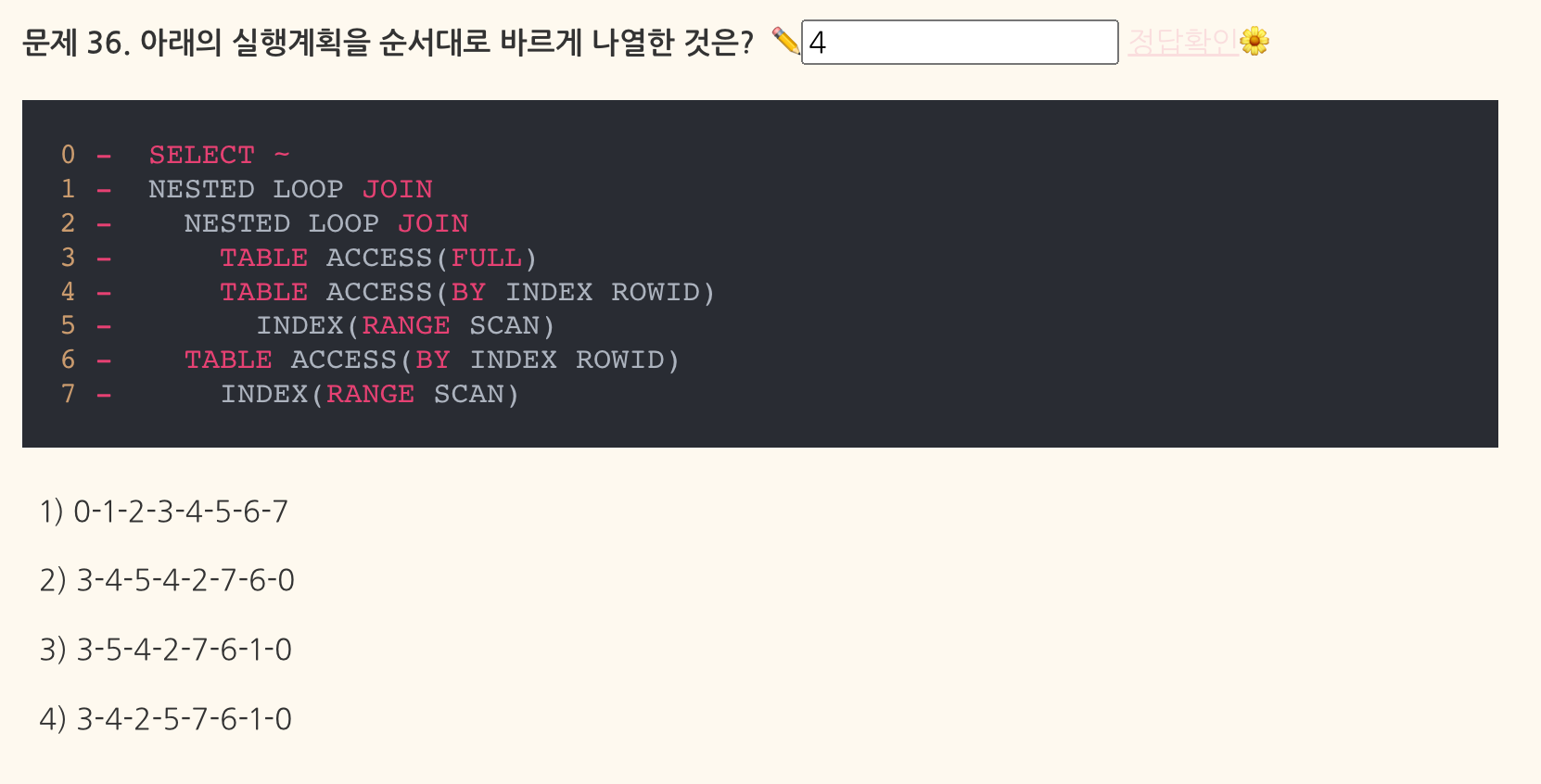
- 정답: 3 (3-5-4-2-7-6-1-0)
- (3-4-2-5-7-6-1-0)이 아님!!!!!
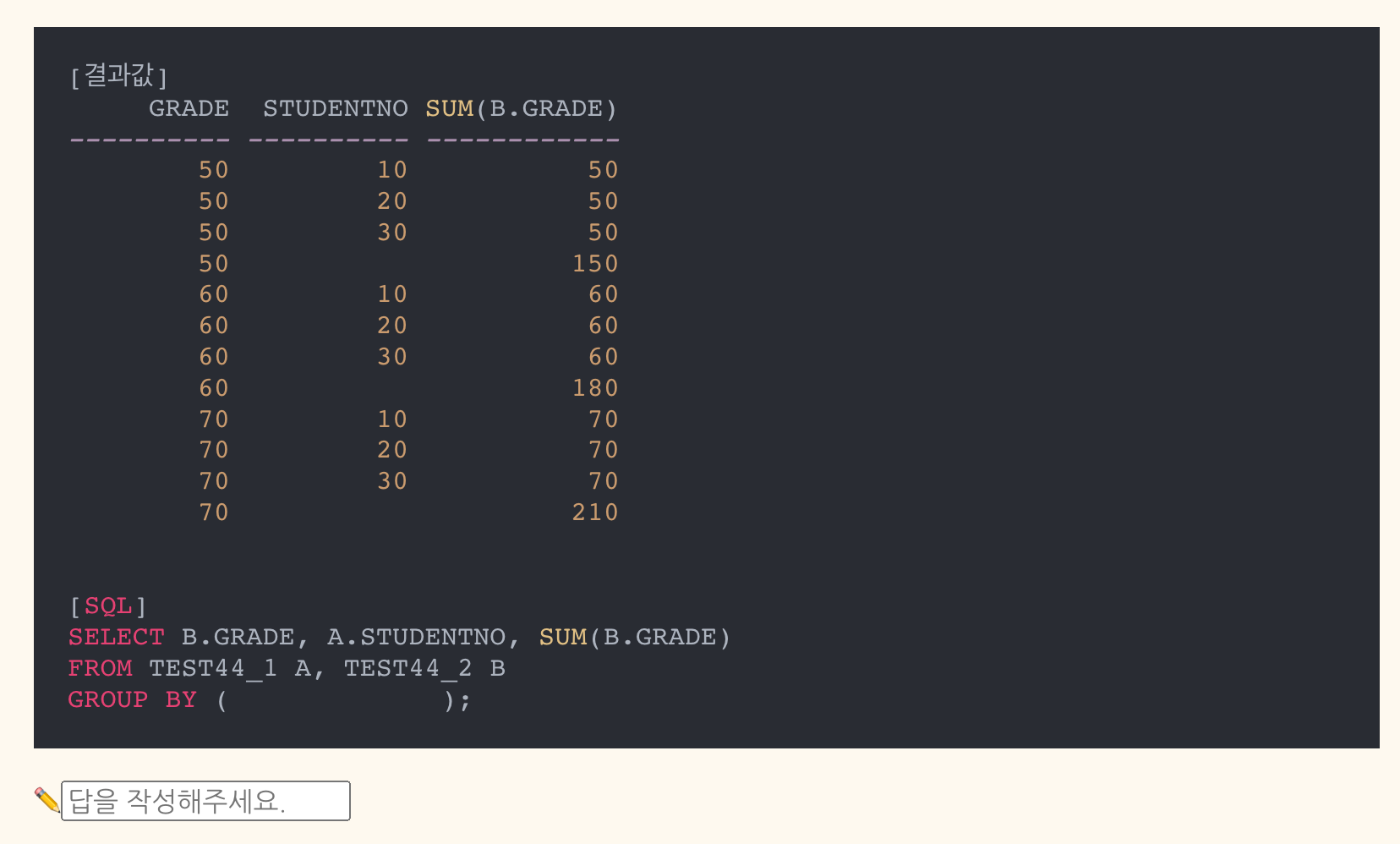
- 정답: GROUPING SETS(B.GRADE, (B.GRADE, A.STUDENTNO))
- 자주 틀리는 유형.
- B.GRADE로 그룹핑 / B.GRADE, A.STUDENTNO로 그룹핑 / 전체 집계는 없음 -> GROUPING SETS(B.GRADE, (B.GRADE, A.STUDENTNO)
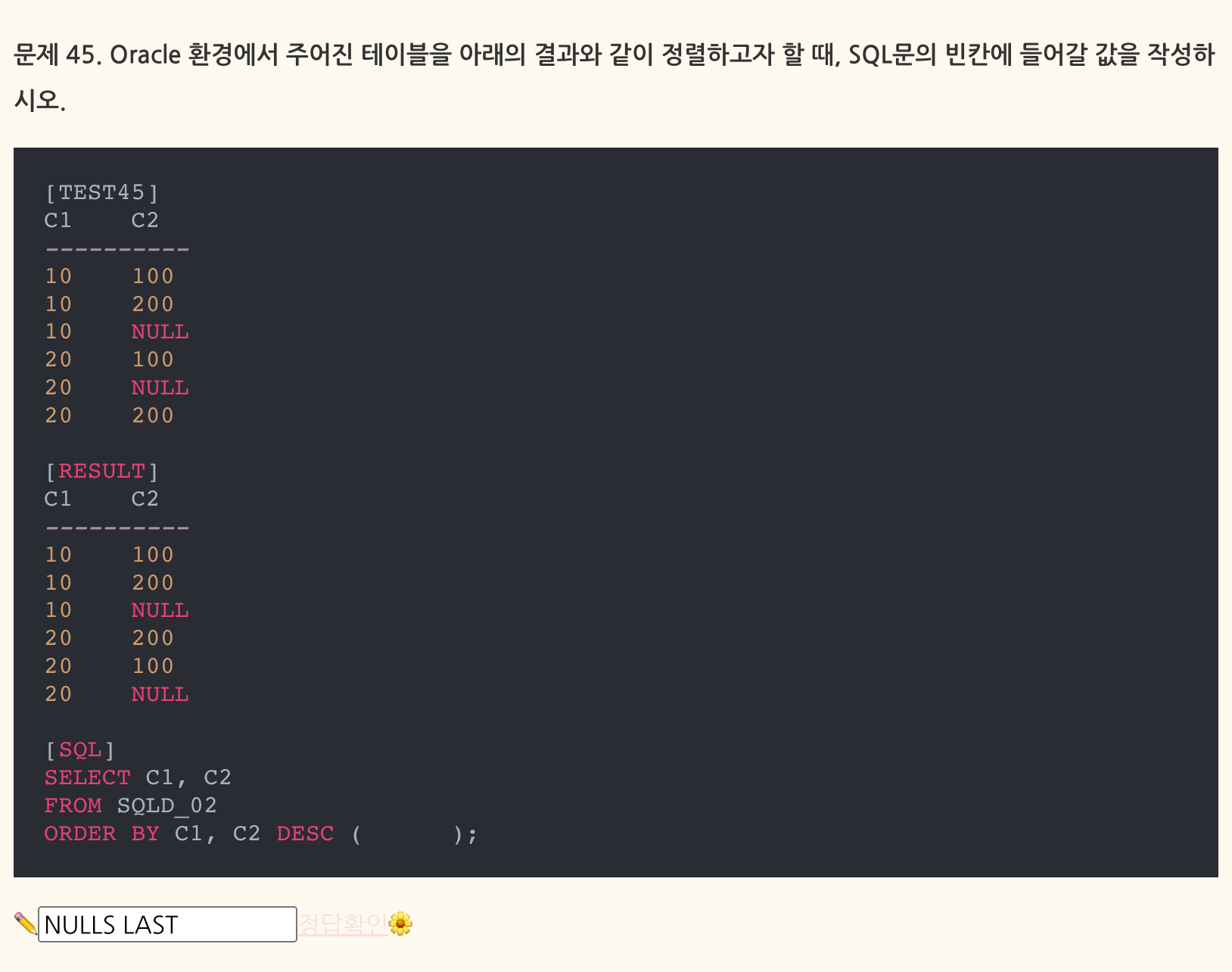
- 맞힌 문제, 하지만 순간 헷갈린 답. 자주 접해본 게 아니라 당황했음
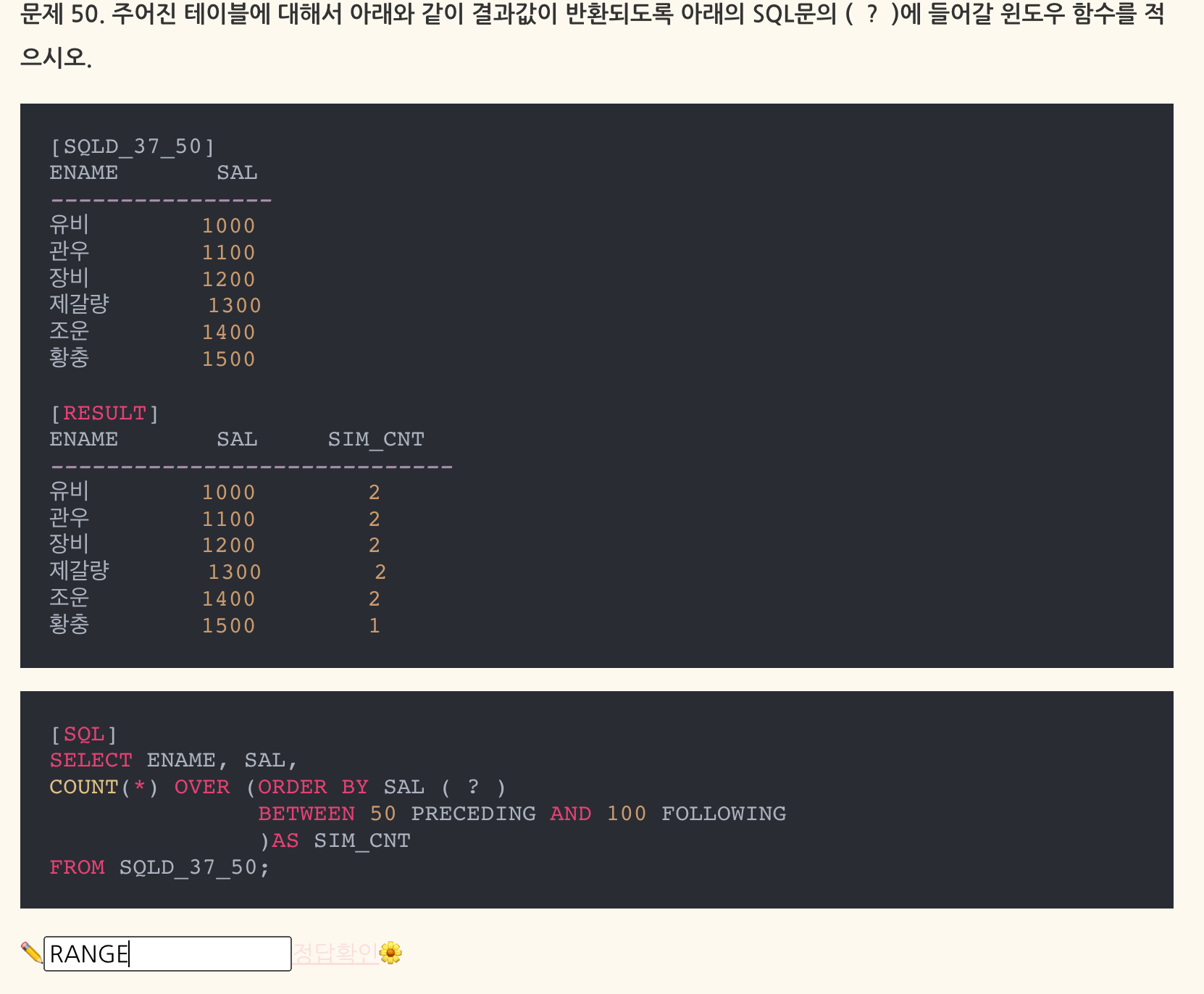
- RANGE는 현재 행의 데이터 값을 기준으로 앞뒤 데이터 값의 범위를 표시하는 것
38회

- 정답: 3
보기 1) NL Join: 랜덤 액세스 O
보기 2) Sort Merge Join: 정렬 유발 O
보기 3) 후행 테이블에 인덱스가 없는 경우 NL Join 사용 불가!!!!!
보기 4) Hash Join은 정렬 작업이 없어 정렬이 부담되는 대량 배치 작업에 유리 O
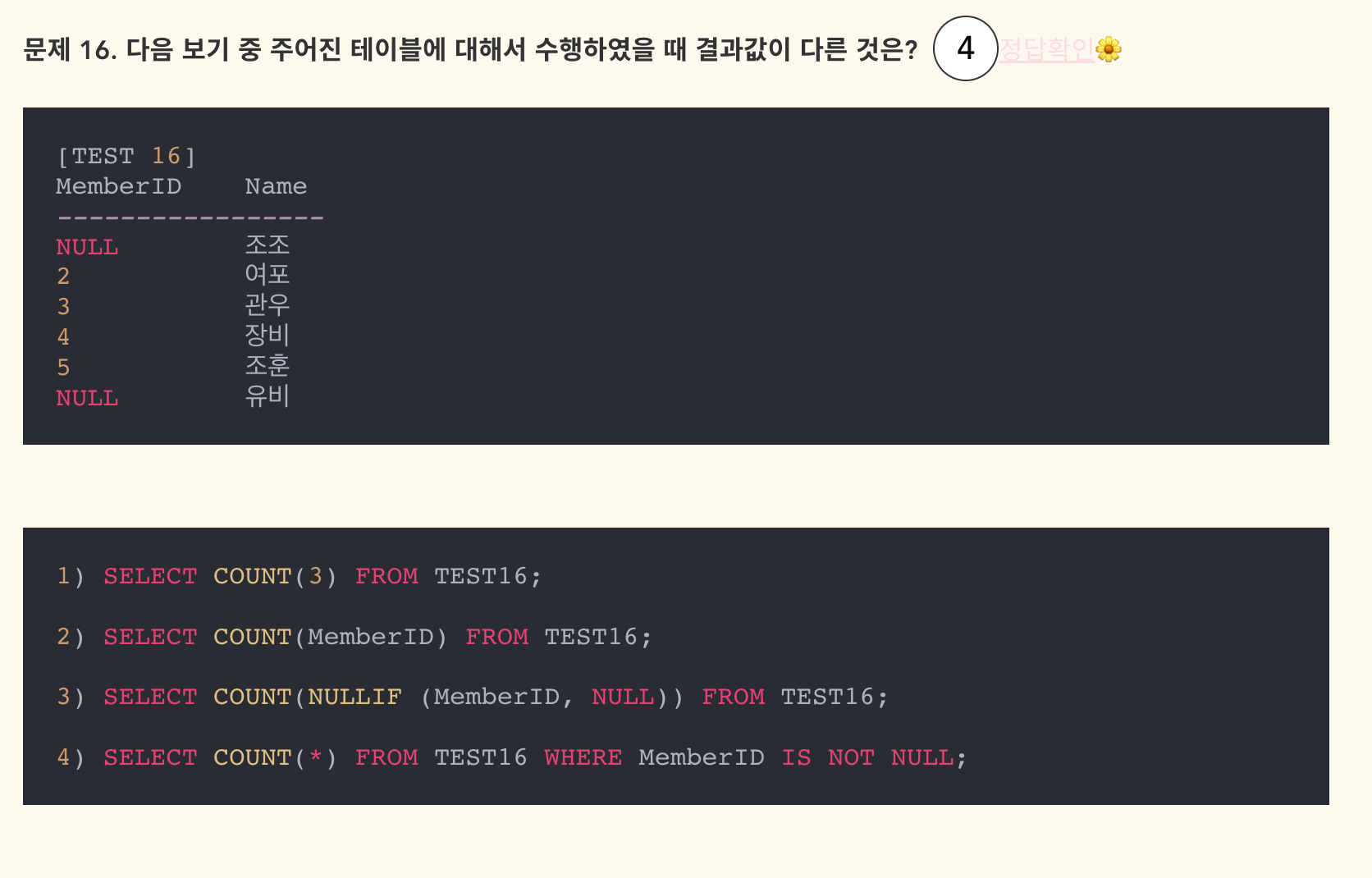
- 정답: 1
보기 1은 6개를 반환하며, 나머지는 모두 4개를 반환함

- 정답: 1 - NULL은 비교에서 제외되어 IN() 연산자 안에 NULL이 있어도 비교연산을 수행하지 않는다.

- 정답: 2 - WHERE 1 = 2 의 값은 False이다. 집계 함수에서 COUNT(*)함수는 조건절이 거짓일 때 0을 반환한다.

- 정답: (COL1, COL2),(COL1),()
- 자주 틀리는 유형.....
- ROLLUP(A, B)
- A, B 그룹핑
- A 그룹핑
- 총 합계
- GROUPING SETS((A, B), A, ())
- A, B 그룹핑
- A 그룹핑
- 총 합계
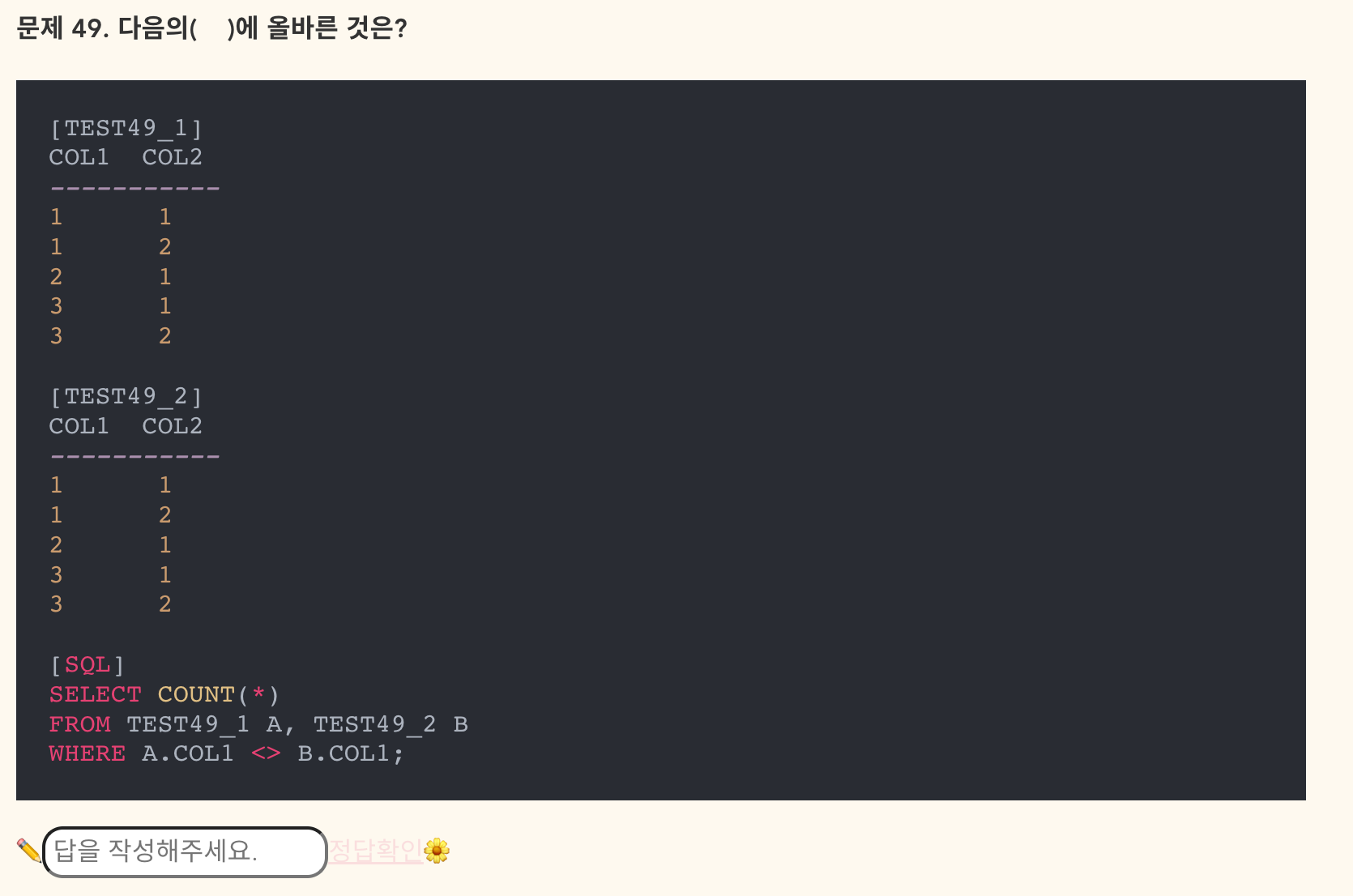
- 정답: 16
- 답을 보고 가장 당황했던 문제.
- 한 행씩 비교해야 한다.
- 첫 번째 행 A.COL1 의 경우(1): B.COL1(1)과 다른 수는 2, 3, 3으로 3개
- 두 번째 행 A.COL1 의 경우(1): B.COL1(1)과 다른 수는 2, 3, 3으로 3개
- 세 번째 행 A.COL1 의 경우(2): B.COL1(2)와 다른 수는 1, 1, 3, 3으로 4개
- 네 번째 행 A.COL1 의 경우(3): B.COL1(3)과 다른 수는 1, 1, 2으로 3개
- 다섯 번째 행 A.COL1 의 경우(3): B.COL1(3)과 다른 수는 1, 1, 2으로 3개
- 따라서 3 + 3 + 4 + 3 + 3 = 16개
39회
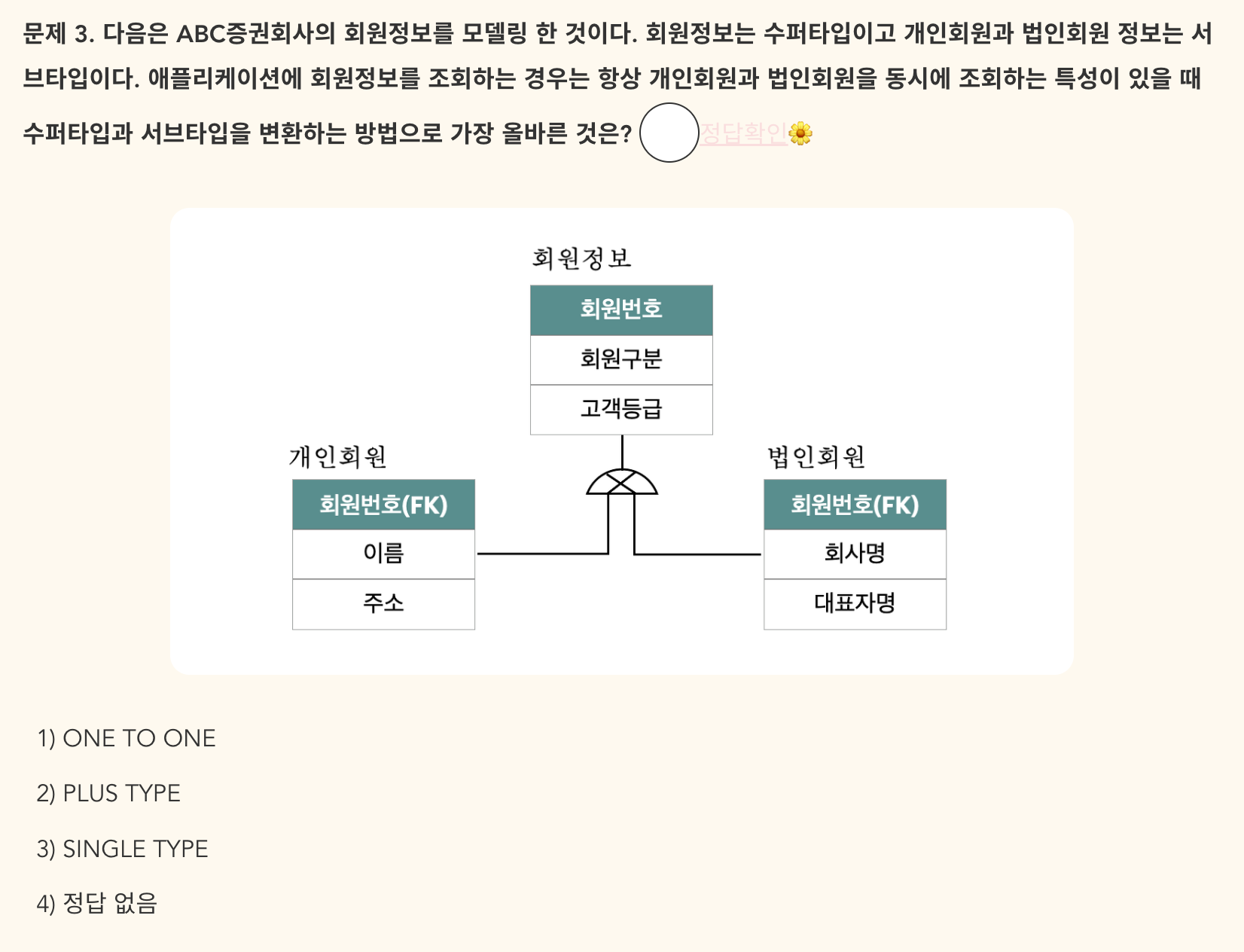
- 정답: 3) SINGLE TYPE - 항상 동시에 조회하는 특성이기 때문에 SINGLE TYPE이 가장 올바른 방법.
- 37회의 문제 3번과 유사한 문제
- One To One Type
- 슈퍼타입과 서브타입을 개별 테이블로 도출
- 테이블의 수가 많아서 조인이 많이 발생. 관리 어려움
- Plus Type
- 슈퍼타입과 서브타입 테이블로 도출
- 조인이 발생하고 관리 어려움
- Single Type
- 슈퍼타입과 서브타입을 하나의 데이터로 도출
- 조인 성능이 좋고 관리 편함. I/O 성능 나쁨

- 헷갈렸던 문제. 제 3정규화는 주식별자를 제외한 칼럼 간에 종속성을 확인해서 종속성이 있으면 분할하는 과정임.

- 정답: 1) 본질 식별자 - 비즈니스 프로세스에 의하여 만들어지는 식별자
- 대체 여부로 분리되는 식별자: 본질 식별자 / 인조 식별자
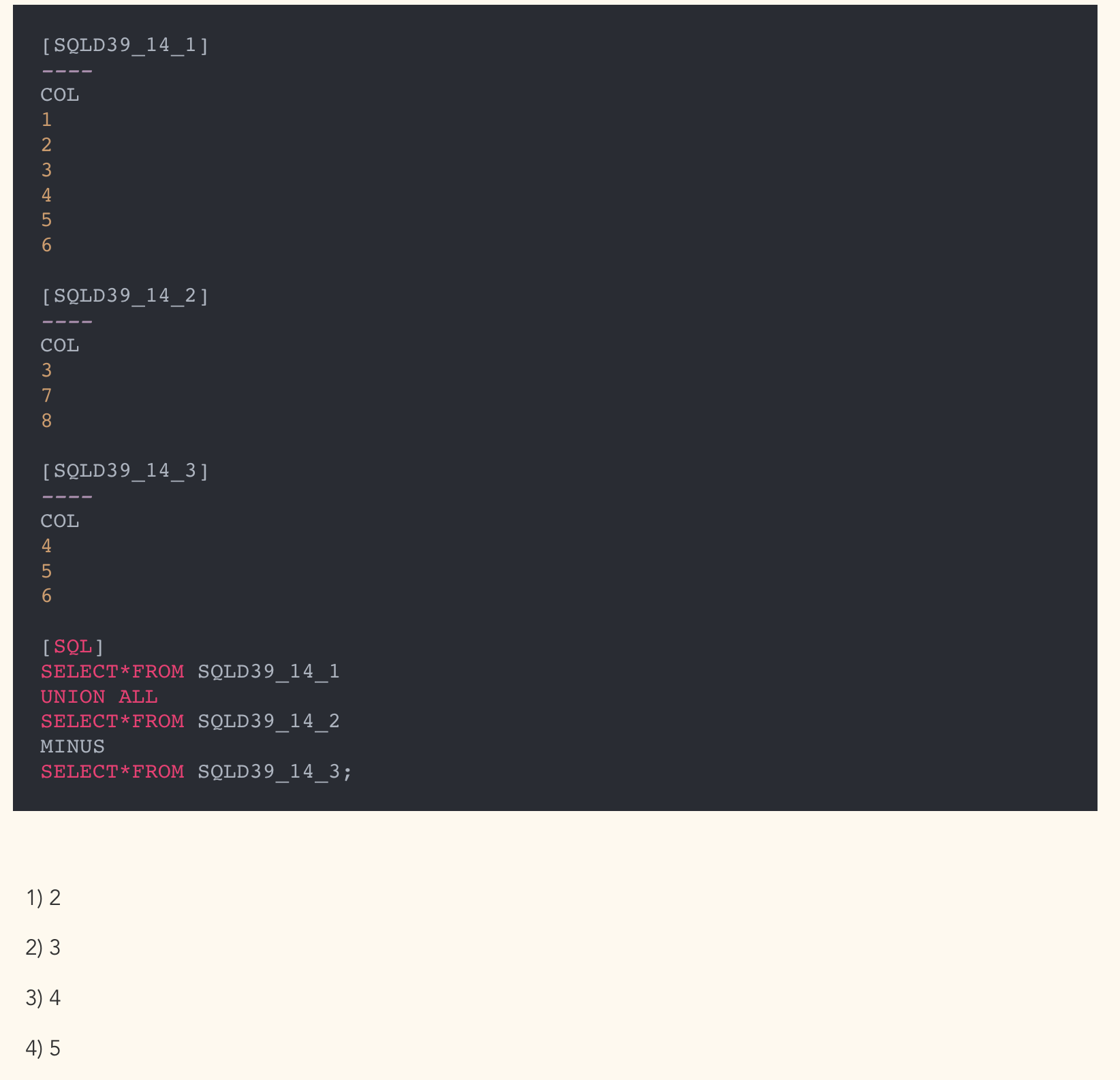
- 정답: 4) 5개
- 처음 문제를 풀었을 땐 6개로 답이 나왔음.
- UNION ALL -> 1, 2, 3, 4, 5, 6, 3, 7, 8 (9개)
- MINUS -> 1, 2, 3, 7, 8 (5개)
- 차집합에서 중복 제외됨.

- 맞힌 문제이지만 헷갈려서 작성.
- 순위 함수 사용 시 ORDER BY 절 입력 가능
- 보기 1, 2, 3이 너무나도 정확하므로 4로 찍었음

- 맞힌 문제지만 헷갈려서 작성.
- CUBE(A, B)
- A, B로 그룹핑
- A로 그룹핑
- B로 그룹핑
- 총합계
- GROUPING SETS(A, B, (A, B), ())
- A로 그룹핑
- B로 그룹핑
- A, B로 그룹핑
- 총합계
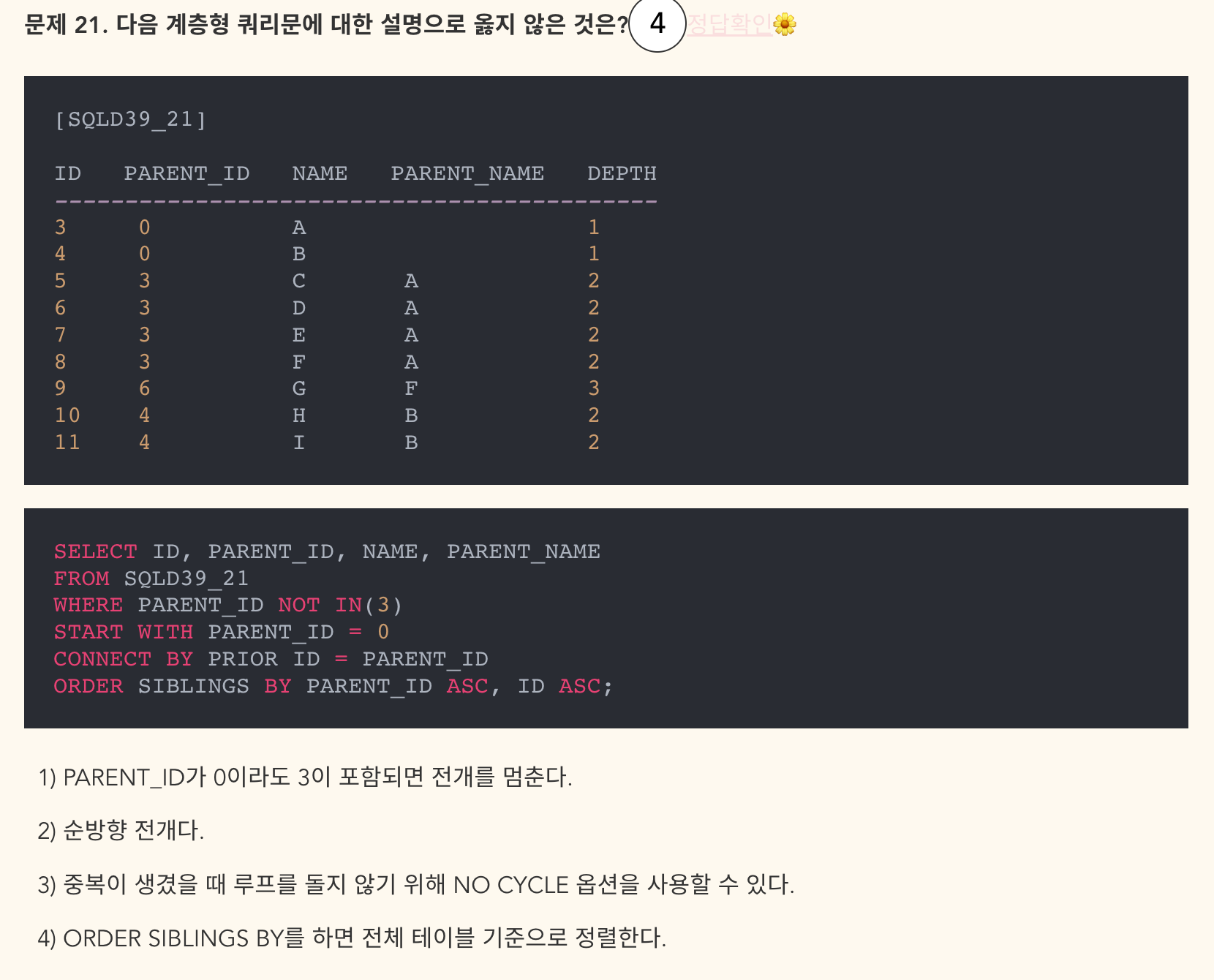
- 맞힌 문제지만 헷갈려서 작성.
- 보기1) NOT IN(3)이므로 3이 포함되면 전개 멈춤.
- 보기2) 부모 ID를 기준으로 자식 ID를 검색하므로 순방향 O
- 보기3) NO CYCLE 옵션 사용 가능
- 보기4) ORDER SIBLING BY를 수행하면 계층형으로 된 데이터 값을 기준으로 정렬함. 전체 테이블 기준이 아님.
ORDER SIBLINGS BY 를 수행하면 전체 테이블이 아니라 계층형으로 된 데이터값(특정 칼럼) 기준으로 정렬된다.

- 맞힌 답이지만 헷갈려서 작성.
- 보기 2) CHAR는 길이가 서로 다르면 짧은 쪽에 스페이스를 추가하여 같은 값으로 판단함

- 맞힌 문제지만 혹시나 해서 작성.
- SELECT절에는 GROUP BY절에 있는 칼럼이 나와야 한다.
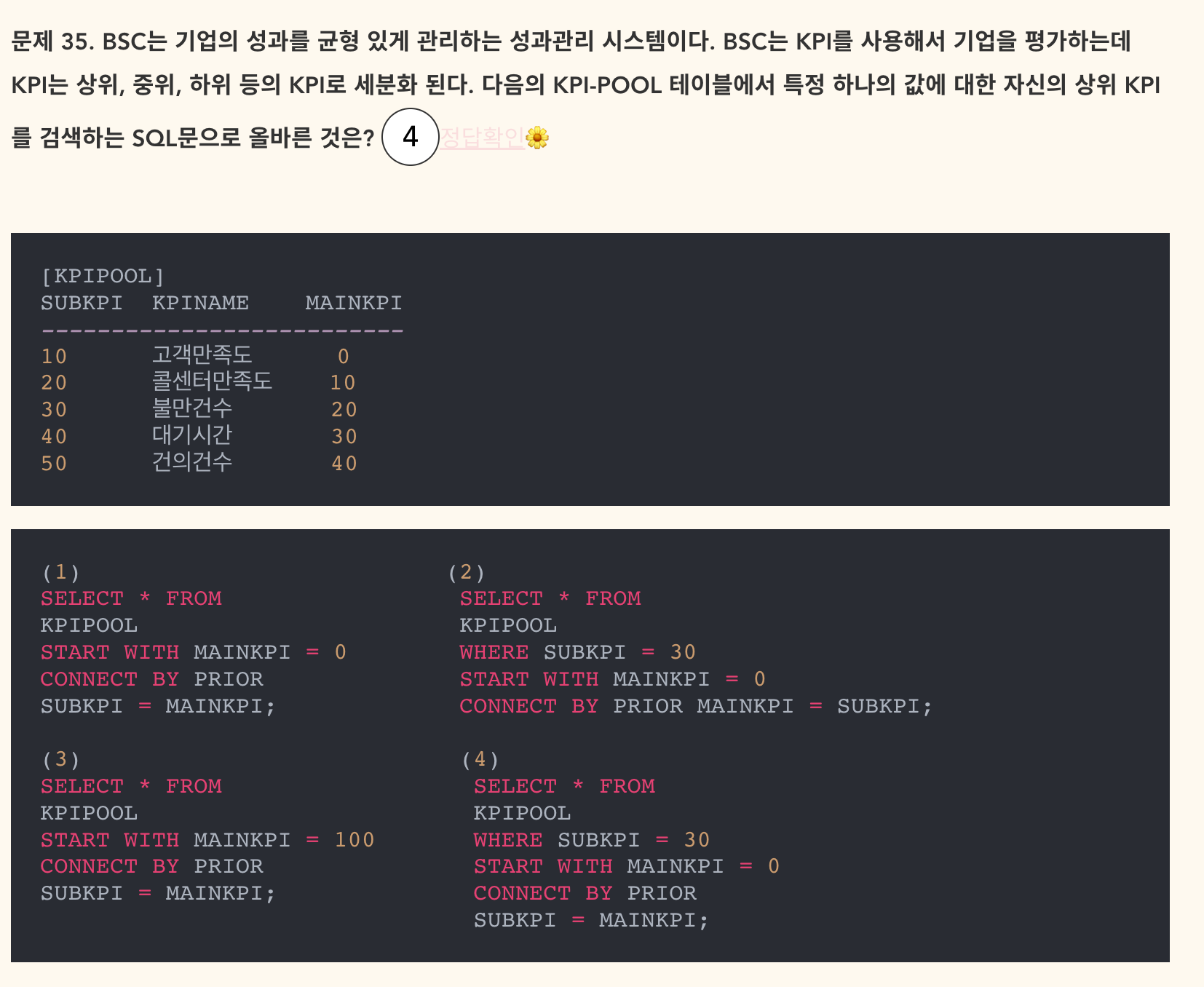
- 정답: 4
- 문제를 제대로 읽기. 특정 하나 값에 대한 자신의 상위 KPI를 검색하는 SQL문을 묻고 있음. 따라서 2, 4로 답이 압축됨.
- SUBKPI가 30일 때, 상위 KPI는 MINEKPI=20임. 순방향 전개.
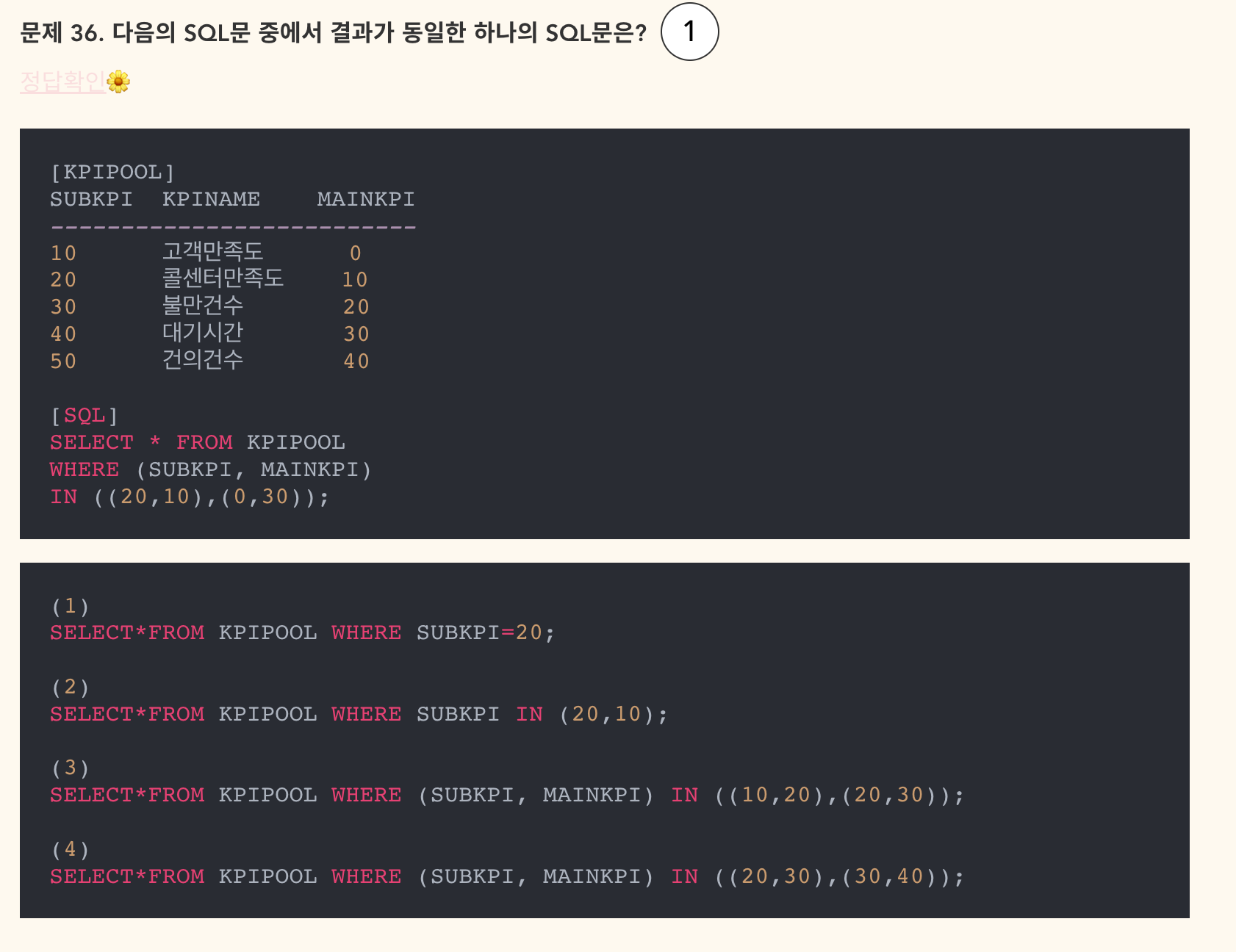
- 정답: 1
WEHRE (SUBKPI, MAINKPI) IN ((20, 10), (0, 30))은 (SUBKPI = 20 AND MAINKPI = 10) OR (SUBKPI = 0 AND MAINKPI = 30)이라는 뜻이다.

- 헷갈렸던 문제.
- 메인쿼리는 서브쿼리에 있는 칼럼을 자유롭게 사용할 수 없다.
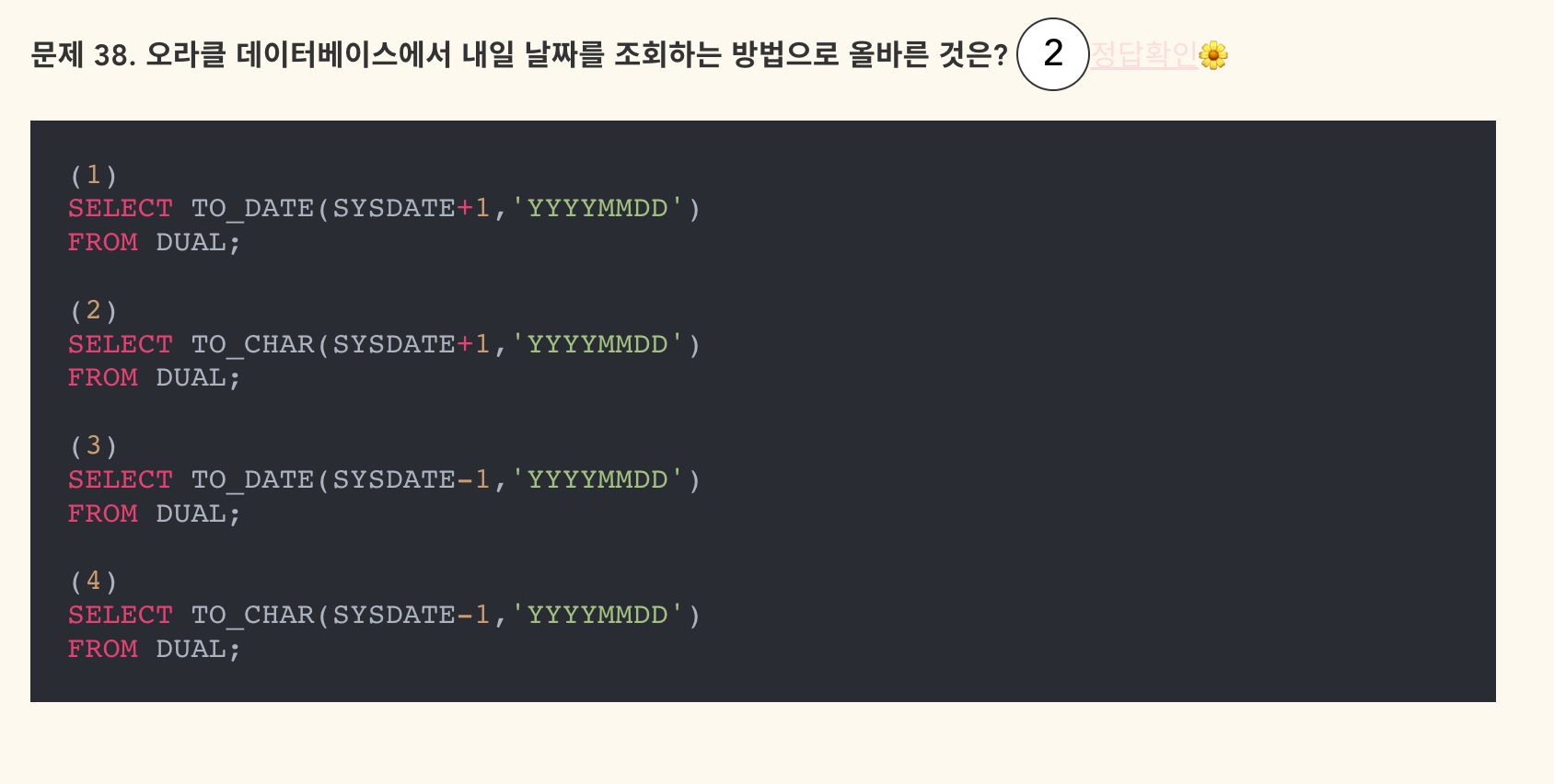
- 정답: 2
- 보기1과 헷갈렸다. 데이트 타입을 문자열 TO_CHAR로 변환해주어야 한다.

- 정답: 2
- 정말.. 처음 보는 문제....
- CURSOR 순서: 선언 - OPEN - FETCH - CLOSE
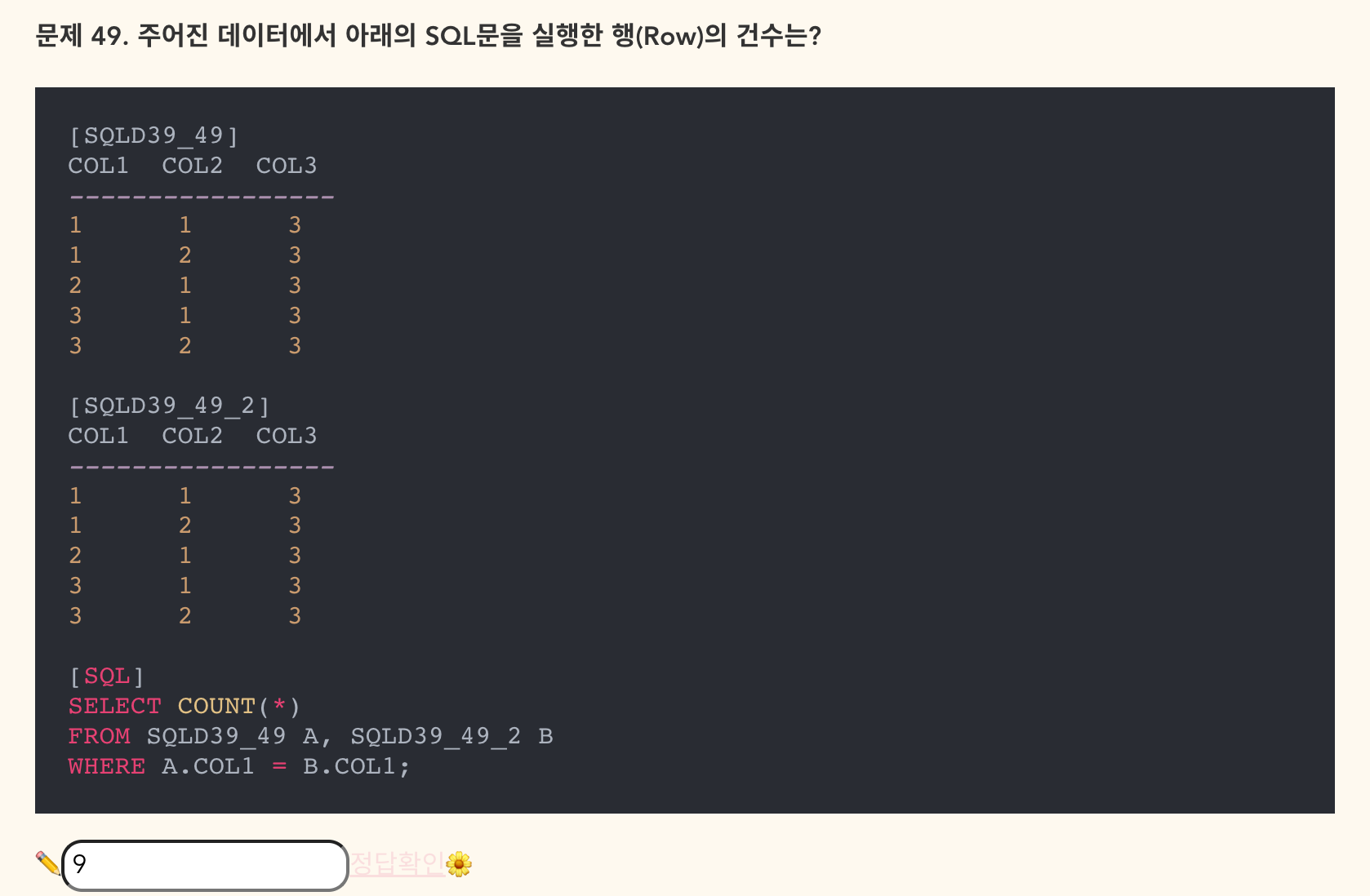
- 정답: 9
- 38회 49번과 비슷한 문제
- 한 행씩 비교해야 한다.
- 첫 번째 행의 A.COL1의 경우(1): B.COL1(1)과 같은 레코드는 2개
- 두 번째 행의 A.COL1의 경우(1): B.COL1(1)과 같은 레코드는 2개
- 세 번째 행의 A.COL1의 경우(2): B.COL1(2)와 같은 레코드는 1개
- 네 번째 행의 A.COL1의 경우(2): B.COL1(3)와 같은 레코드는 2개
- 다섯 번째 행의 A.COL1의 경우(2): B.COL1(3)와 같은 레코드는 2개
- 즉 2 + 2 + 1 + 2 + 2로 9가 답이 된다.
자료 출처: Study with yana 티스토리

🌱 새싹 개발자의 고군분투 코딩 일기