스탠포드대의 CS231n 강의를 수강하고 나중에 참고할 만한 부분을 다른 자료를 참고하여 요약 정리한 내용입니다.
분류
분류의 도전적인 문제들
- 의미적 차이(Semantic Gap)
- 컴퓨터는 고양이를 픽셀 행렬로 인식해서 고양이스러움을 발견하기 어려워 함
- 시점 변화
- 보는 지점이 달라지면 컴퓨터는 완전 다르게 인식함
- 조명(Illumination)
- 형태 변화(Deformation)
- 가려짐(Occlusion)
- 꼬리만 보이는 것 등
- 배경 문제
- 배경과 객체가 비슷할 때 등
- 클래스내 변동(Intraclass Variation)
- 고양이 개체마다도 서로 서로 다르게 생긴 것
최근접 이웃 탐색(Nearest Neighbor)
- 최근접한 1개 데이터의 라벨 가져옴
- 속도 느림
- 학습 속도는 O(1), 예측 속도는 O(N)인데, 예측이 느리면 안 됨. 이 반대(예: CNN)로 되는 것은 좋음
k-최근접 이웃 탐색(k-Nearest Neighbor)
- k개의 주변 값에 대해 주된 값을 투표로 결정하여 라벨을 선택함
- 실제로 거의 안 쓰임
- k는 하이퍼파라미터
하이퍼파라미터 설정
- 학습 데이터에 잘 맞는 것? X
- 시험 데이터에 잘 맞는 것? X
- 처음 본 데이터에 대해서 시험을 해야 함. 단 한 번만!
- 데이터를 셋으로 나눠서 학습, 검증, 시험 데이터 중 검증 데이터를 이용하여 하이퍼파라미터를 튜닝
- 학습/검증 데이터 차이: 학습 데이터는 라벨 데이터를 활용해서 학습을 하지만, 검증 데이터는 라벨 데이터는 '결과가 잘 나왔는지 확인'할 때만 이용
- 교차 검증
- 효과는 좋지만 작은 데이터에 사용
거리 선택하기
- L1과 L2는 좌표계 의존성에 큰 차이가 있음
선형분류기
- 입력 x, 가중치 W, 편향 b
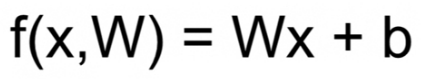
기타 키워드
- 차원의 저주
- 파라미터 접근법
참고자료:
cs231n 웹페이지
위키백과
블로그

즐겁게 새로운 것을 공부하고, 이미 배운 것들을 이리 저리 연결하며 글을 써보고, 공부한 것을 다른 분들과 공유하면서 꾸준히 발전하고자 만든 공간입니다!