팀명: DBDB DEEP
팀원: 김규민, 박준형, 오현식
지도교수: 박희민 교수님
작성일: 2023년 06월 22일
프로젝트명
- 내가 본 영화와 유사한 영화 추천 프로그램
프로젝트 기간
23년 3월 13일 ~ 23년 6월 12일 (3개월간 진행)
보고서
우리가 평소 쉽게 접할 수 있는 여러 가지 OTT서비스에는 방대한 영화들이 존재한다. 매번 OTT 서비스를 이용할때면 방대한 양의 영화들 중 어떤영화를 봐야하는지 항상 고민에 빠지곤 한다. 때문에 영화를 고르다 못해 OTT서비스를 종료하는 경우가 대부분이다. 또한 OTT서비스를 이용해 영화를 볼 때 내가 최근에 봤던 장르의 영화들만 추천해준다는 문제점이 있다. 추가적으로 이러한 추천기능은 각 OTT 플렛폼에 등재되어있는 영화만 추천하기 때문에 더 넓은 폭에서 영화선택이 불가능하다. 이러한 문제점을 바탕으로 OTT서비스를 둘러보다 버리는 시간을 절약하기 위해 이 주제를 선정하게 되었다.
위의 목표가 우리가 이 프로젝트를 선택하게 된 이유들이지만, 프로젝트를 진행하며 현실적으로 불가능한 부분까지 파고들고자 했다는걸 알게되었다. 약간의 타협을 보며 진행한 프로젝트이지만, 머신러닝과 전체적인 서버-클라이언트 구조를 구축할 수 있었던 가장 기억에 남을 첫 번째 프로젝트였다.
FrontEnd + 데이터 수집
-
kofic과 tmdb를 활용한 영화 데이터 수집
데이터 수집은 파이썬을 활용하여 진행하였다. 데이터 수집에 사용된 사이트는 총 2개로 kofic과 tmdb이다. 먼저 tmdb는 각 영화마다 포스터와 줄거리, 평점 데이터, 배우 정보 등 우리 팀에게 필요한 정보를 가지고 있었지만 영화 제목을 넘겨줘야 해서 단독으로 사용하기 어려웠다. 그래서 생각한 게 kofic과 같이 사용하는 것이었다. kofic은 시작연도와 끝연도(2005~2023같은)를 지정해주면 그 사이에 개봉한 영화들의 데이터를 수집할 수 있었는데 거기서 수집한 영화 제목을 tmdb로 보내서 tmdb의 데이터를 수집할 수 있었다. 이렇게 수집한 데이터를 json파일로 만들어 프로젝트에 사용하였다. -
검색창 기능
검색창은 사용자들이 우리 사이트를 이용할 때 가장 많이 사용할 것 같아서 포털 사이트의 검색창 기능처럼 구현하려고 노력했다. 먼저 현재 검색하고 있는 검색창안에 값이 포함되는 영화 제목을 검색어 추천으로 띄어 주었다. 그리고 키보드의 위 아래 방향키로 추천 검색어를 이동하며 선택할 수 있게 하였다. 이동을 할 때 마다 해당 위치에 있는 영화 제목이 검색창안

에 값으로 변하게 하여 엔터를 누르면 해당 영화가 검색되게 해주었다.
-
장르, 키워드, 제작사 별 검색 기능
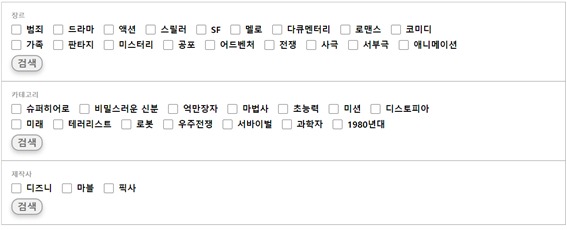
장르는 다중 선택이 가능하여 선택한 장르가 포함되는 영화가 검색되고 키워드는 단일 선택으로 구현하였는데 그 이유는 키워드가 너무 방대하여 다중 선택 시 겹치는 영화가 없는 경우가 있어서 단일 선택으로 구현하였다. 14개의 키워드는 평점과 추천수 상위 영화의 키워드를 추출하여 보여주었다. 제작사는 각 제작사의 특색이 강한 3개의 제작사의 영화들을 보여주었다.
-
페이지 분할
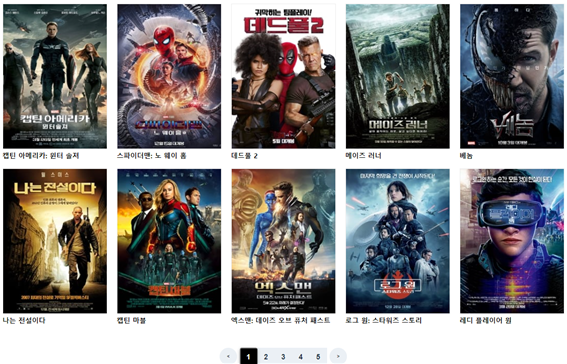
장르 선택으로 영화를 검색하면 많은 양의 영화가 한 화면에 담기게 되어서 사용자가 영화를 찾을 때 화면을 계속 스크롤 해야 하는 문제점을 발견하여 한 페이지 당 30개의 영화만 보여주었다. 만약 330개의 영화가 있다면 1~5 페이지 버튼이 보이고 5에서 다음 페이지 버튼을 누르면 6~10 페이지 버튼이 보이도록 하였다. 페이지 버튼을 누르면 해당 페이지로 바로 이동이 가능하다.
-
영화 세부정보 + 평점/댓글 + 관련 트레일러
영화의 포스터나 제목을 누르면 해당 영화의 세부정보를 볼 수 있는 창으로 이동한다. 해당 창에는 영화 포스터, 영화 제목, 영화 영문 제목, 장르, 줄거리, 배우 3명의 정보를 볼 수 있다.

세부정보 창 하단에 해당 영화의 평점과 댓글을 작성할 수 있게 해주었다. 여기서 회원들이 평가한 영화의 평점은 데이터 베이스에 저장되고 머신러닝의 협업 필터링에 활용된다.
영상 탭에서는 해당 영화 관련 트레일러 영상들을 볼 수 있도록 해주어서 사용자가 영화를 선택할 때 도움이 되도록 해주었다.
BackEnd
백엔드는 Srping Boot로 구현했다. 우리나라에서는 Java 개발자도 많고 Java로 된 프로젝트들이 많기 때문에 자료가 많을 것 같아 판단하여, 일단 Java의 Spring Boot로 프레임워크를 채택했다.
백엔드는 크게 4가지의 기능이 있다.
1. 로그인
- Spring Security + JWT를 사용한 권한을 확인
- 회원가입
- 회원가입 성공 시, DB에 User정보 저장
- 게시판 및 평점
- 댓글 및 평점 불러오기
- 댓글 및 평점 받아서 DB에 저장
- 영화추천
- 내용, 키워드 기반 추천 MovieId값을 플라스크와 통신
- 영화데이터(평점) 기반으로 플라스크와 협업필터링 MovieId값 통신
- 회원가입
로그인을 구현할려면, 우선 회원의 정보를 데이터베이스에 저장을 해야된다. 클라이언트에서 서버로 전송할 때 받는 데이터의 틀을 Data Transfer Object(DTO)를 입력했다.
다음 사진은 UserForm 이라는 클래스다. 유저 정보를 클라이언트에서 서버로 받는 형식인 DTO다.
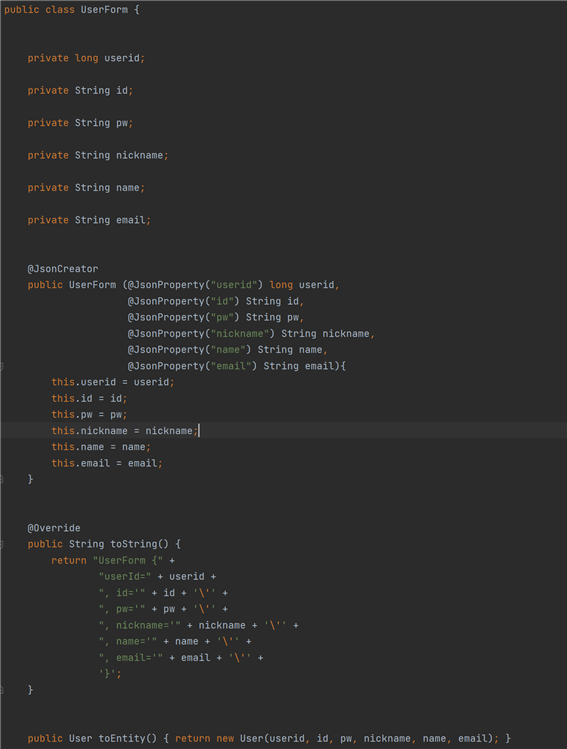
UserFrom 이라는 DTO는 클라이언트가 서버에게 회원가입을 할 때 회원가입에 필요한 사용자의 데이터 정보의 틀이다.
이 형식에 맞춰 서버는 클라이언트에게 요청을 하게 된다. 만약 UerForm 객체로 정보가 클라이언트에서 서버로 넘어오게 되면
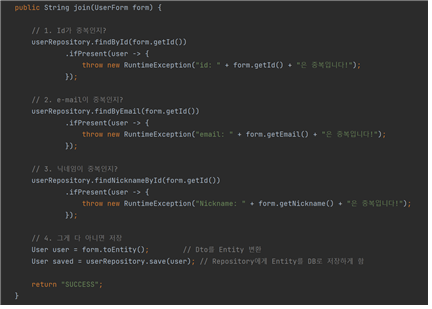
UserService 클래스의 join 메서드로 User DTO가 넘어가게 된다. 이 메서드에서는 id가 중복이 아닌지, 이메일이 중복이 아닌지, 닉네임이 중복이 아닌지 검사를 한다. 중복일 경우, 그에 맞는 에러 메세지가 클라이언트에게 응답하게 된다.
3가지 전부 다 중복이 아니라면, UserForm의 toEntity 라는 메서드가 실행이 되며, 이 메서드는 UserForm에서 User 클래스로 변환되는 메소드다.
유저 메소드는
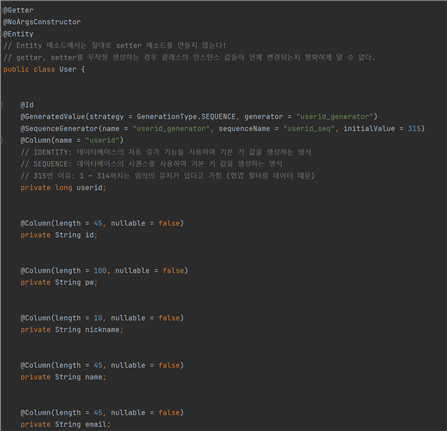
서버에서 DB로 넘기기 위한 데이터 형식이다. 현재 이 프로젝트에서는 JPA를 통해 서버와 DB를 연결하고 SQL 쿼리문을 작성했다. DTO에서 repository로 변환하고, 이 변환된 객체를 UserRepository의 save 메소드로 저장이 된다. JPA는 기본적으로 save 메소드가 내장되어 있다. 이 메소드를 통해 서버와 연결된 DB에 데이터가 저장이 된다.
-
로그인
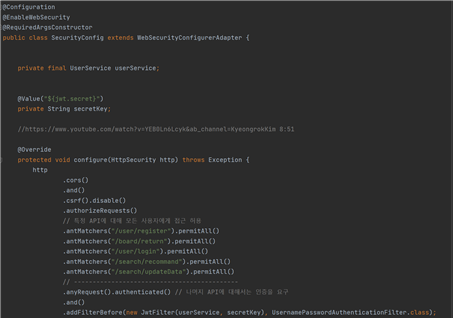
BackEnd의 꽃이라고 하는 로그인 기능이다. 로그인을 구현하는 방식은 여러가지지만, 이번 프로젝트에서는 Spring Security + JWT를 사용한 사용자와 그 사용자의 권한을 확인했다.Spring Security를 의존성에 추가하게 된다면 추가적으로 설정을 하지 않는 이상, 기본적으로 모든 API는 토큰이 없으면 401 오류를 발생시킨다. 이는 프런트가 백에게 토큰값과 함께 요청을 하면 정상적으로 응답을 한다.

Spring Security는 JWT(Json Web Token)라는 토큰을 이용해 권한을 부여한다, 이 토큰 안에는 어떤 사용자의 고유 id 혹은 사용자 이름과 토큰의 유효시간 등이 담겨져 있다. 클라이언트가 ID와 PW를 맞게 입력하게 되면, 스프링에서는 토큰을 응답하게 되고 클라이언트가 응답받은 토큰은 쿠키 혹은 세션 방식으로 브라우저에 저장하게 된다. 엑시오스 혹은 에이잭 등 프런트에서 API 통신을 할 때 HTTP 헤더에 토큰값과 함께 담아서 요청을 하게 된다. 그럼 백엔드에서 이 토큰값이 유효한지 혹은 시간이 지나지 않았는지 백엔드의 포트로 요청이 들어올때마다 JwtFilter.java에서 토큰을 확인한다.
다음 사진은 JwtFilter.java 파일이다. 토큰이 옳바른 토큰인지, 혹은 유효기간이 남아있는지를 판단해서 에러값으로 응답하거나, 정상적인 토큰값이면 정상적으로 API에 접근할 수 있도록 권한을 응답한다.
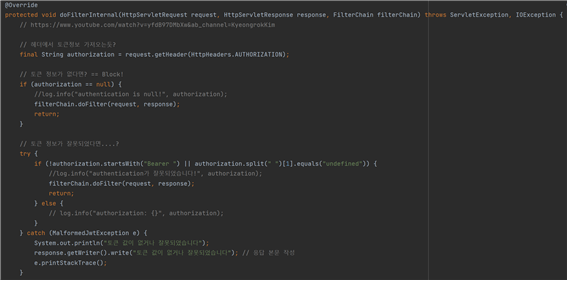
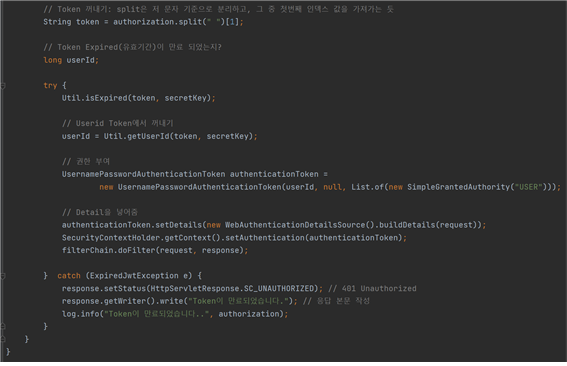
SecurityConfig.java에서 Security의 전반적인 설정을 담당한다. API가 꼭 로그인을 해야만 사용할 수 있는 것도 있고 (댓글 작성, 협업필터링 등) 또는 로그인을 하지 않아도 사용을 해야만 하는 API도 있다 (댓글 목록 불러오기, 로그인API, 회원가입 등) 그래서 SecurityConfig.java에서 어떤 API는 토큰 없이도 허용을 하고, 토큰이 있어야만 사용할 수 있는 설정들을 이 java 코드에서 코드를 작성할 수 있다.
현재 회원가입, 댓글목록 보기, 로그인, 영화 추천 기능들은 권한이 없어도 접근을 해야하는 API여서 토큰 없이도 권한을 줄 수 있도록 설정된 상태다.
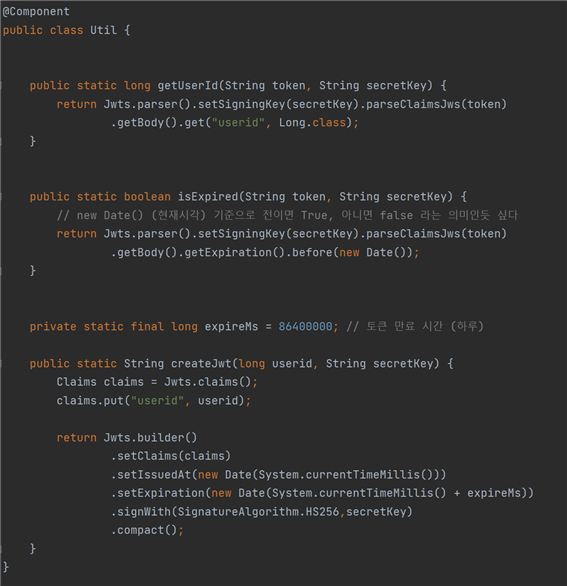
Util.java에서는 로그인을 성공 했을 때, 토큰을 생성하는 역할을 담당한다. ID와 PW가 프런트에서 백으로 넘어오면, 백에서 ID와 PW가 DB에서 일치하는 값이 있는지 확인 후, 만약 둘 다 일치한다면 Util.java에서 “String createJwt(long userid, String secretKey)” 이라는 메소드를 실행하게 된다. 여기서 secretKey는 하나의 백엔드 서버의 고유 키 값이다. 이 키 값을 통해 토큰을 만들거나 디코딩을 시도한다.
- 게시판 및 평점
게시판 기능에는 크게 두가지 기능이 있다. 댓글입력과 댓글목록을 불러와야 한다.
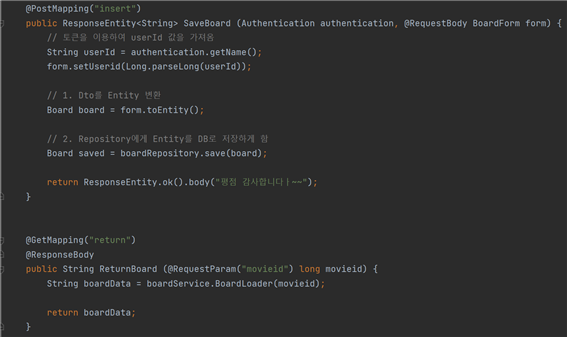
SaveBoard는 댓글목록을 저장하는 API다. 일단 토큰 값에서 UserId를 디코딩한다. 그럼 이 토큰을 보유한 사용자가 댓글을 입력하고 저장해달라고 요청을 했을 때, BoardFrom이라는 DTO클래스가 클라이언트에서 서버로 넘어오게 되고, BoardForm의 UserId는 토큰값에서 디코딩한 값을 넣어준다.
회원가입과 마찬가지로 DTO에서 Repository로 변환하는 toEntity 메소드를 실행해서 변환하고, 역시 JPA에 기본적으로 내장된 save를 통해 DB에 Board값이 저장이 된다.
ReturnBoard는 각 MovieId의 댓글 목록을 가져오는 API다. boardService의 BoardLoader 메소드를 통해 댓글 목록들을 반환해 온다. 다음 사진은 boardService 클래스의 코드다.
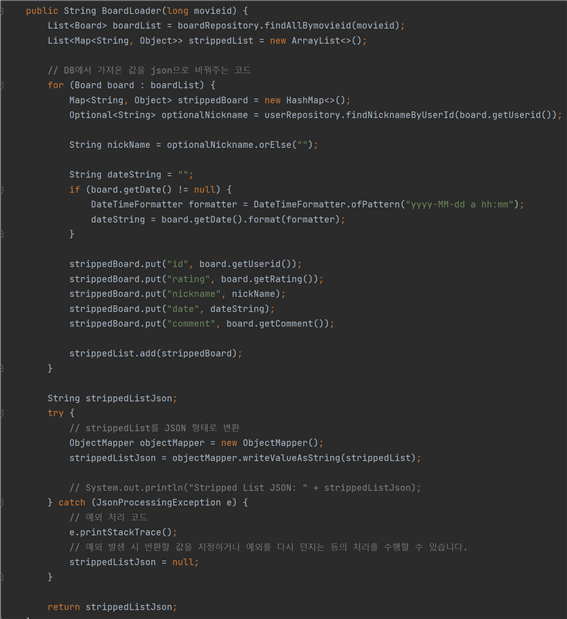
DB에서 MovieId 값을 기준으로 댓글 목록을 가져오고, 사용자에겐 UserId가 아닌 UserId의 nickname을 가져와야 된다. 그래서 각 댓글 목록의 UserId를 기점으로 닉네임을 가져오는 쿼리문을 한번 더 DB로 보낸다. Nickname과 평점, 댓글 내용, 작성시간을 json 형태로 만들어서 반환하게 된다. 이 값을 RetrunBoard API로 반환하게 된다.
- 영화추천
머신러닝은 파이썬의 플라스크 API 서버를 통해 Spring Boot와 통신한다.
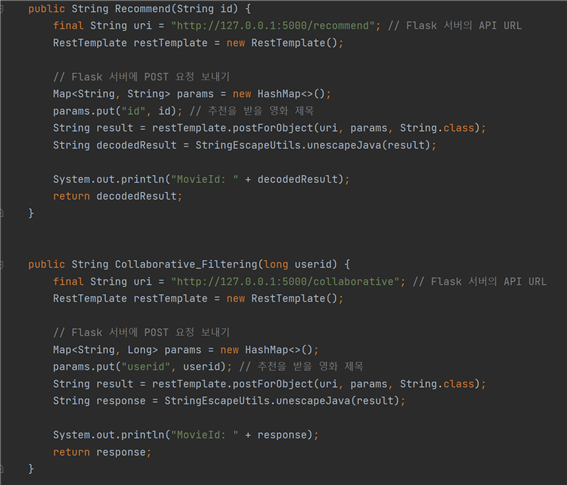
첫번째 메소드인 Recommand 메소드는 한 MovieId를 기준으로 내용기반 추천 Id 10개, 키워드기반 추천 Id 10개, 총 20개의 MovieId를 플라스크 서버에서 Spring Boot로 응답하라고 요청하는 메소드다.
두번째 메소드 Collaborative_Filtering 메소드는 협업필터링 메소드다. 한 사용자가 로그인을 하고, 메인페이지에 접속하게 되면 메인페이지에서 서버로 토큰값을 전송하고, 이 토큰 값의 유저 평점 데이터를 기반으로 영화를 추천해달라고 요청하는 API가 있다.
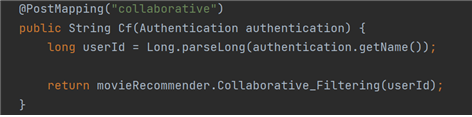
이 API가 저 메소드를 통해 추천된 MovieId값 3개를 플라스크 서버에서 응답받아서 JSON 형태로 반환받고, 그럼 반환받은 값을 클라이언트에게 응답하게 된다.
ML
이번 프로젝트에 사용하게된 머신러닝은 총 2가지 이다.
1. 키워드 기반, 내용 기반 영화추천
- “재미있게 본 영화”를 입력하면 그 영화의 키워드와 내용의 유사도를 통해 영화 추천.
2. 협업필터링(SVD + 피어슨 유사도)
- 개인 맞춤형 서비스로, 영화의 평가 진행 시 다른 유저들의 평가 내용을 기반으로 영화 추천.
1. 키워드 기반, 내용 기반 영화추천
먼저 키워드 기반과 내용 기반 영화추천을 위해 사용하게된 알고리즘은, TF-IDF와 코사인 유사도이다. TF-IDF의 경우 각 문장의 단어 빈도라고 생각하면 쉽다.
예를들어
“나는 바나나를 엄청 좋아한다. 왜냐하면 바나나는 맛있기 때문이다.”
라는 문장이 있을 때 “바나나”라는 단어의 빈도수가 2회이기 때문에 저 문장에서는 바나나에 높은 가중치를 부여하게 된다.
이렇게 TF-IDF를 이용해 각 문장에서 각 단어마다의 가중치를 구해주었다. 이 후 코사인 유사도를 통해 또 다른 문장과의 유사도를 검사했다. 여기서 TF-IDF를 활용해 구한 가중치 단어들로 코사인 유사도를 계산하게 된다. TF-IDF의 가중치가 높은 단어가 일치할시 더 높은 가중치를 부여하도록 구현했다.
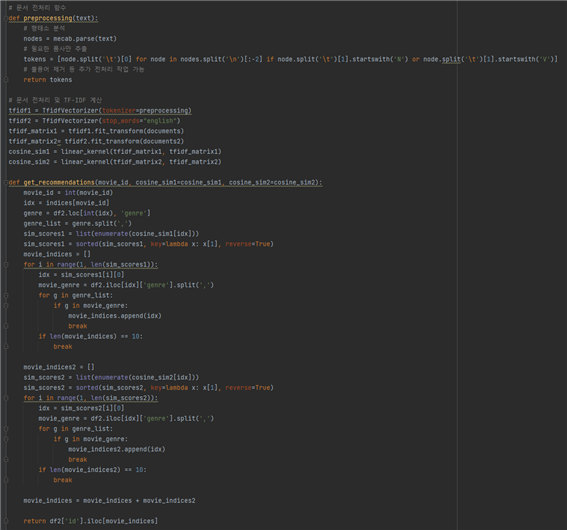
하지만 여기서 가장 중요한 것은, 각 단어별로 조사가 다르면 다른 단어로 취급되기 때문에, 형태소를 분석하고 불용어를 처리해 주었어야한다. 형태소 분석은 직접 진행해 보려했으나, 너무나 많은 데이터의 양으로 KoNLPy를 이용하도록 계획했다.
윈도우의 오류인지 어떤 부분의 오류인지는 잘 모르겠으나, KoNLPy에서 제공하는 Hannanum, kkma, Komoran, Okt를 모두 사용해봤고 모두 실패했다. Mecab이라는 일본어 형태소 분리기만 제대로 작동했다. Mecab을 한국어 형태소로 사용하기 위해선, 한글버전의 라이브러리를 깔아 사용해야했다.
위의 블로그를 이용해 Mecab Ko를 설치하게 되었다. 그리고 필요한 품사만 추출하기 위해 불필요한 부분을 split하고 제거해주었다. 이렇게 완성된 단어들을 가지고, 코사인 유사도를 구해주었다. 유사도 가중치 상위 10개의 영화를 Back-end로 보내주고 이 값을 front-end에서 띄워주도록 구현했다. 아래의 사진이 결과물이다.
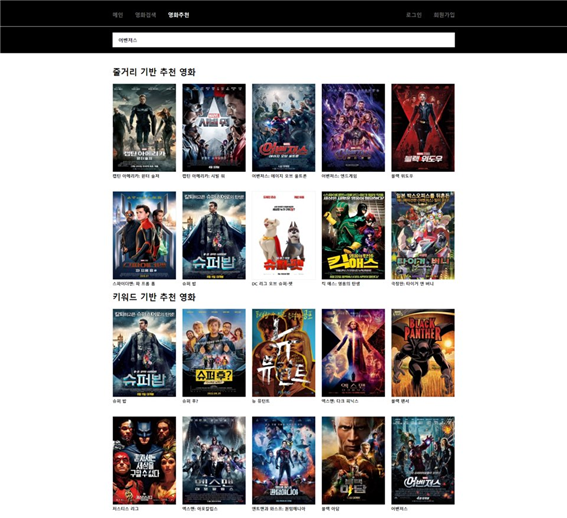
사진에서 보이듯이 전체적으로 나쁘지 않은 성능을 보인다는걸 알 수 있다. 이런 성능을 보이기 위해 우리는 수많은 노력을 거쳐왔다. 초반에는 토이 스토리3 영화를 쳤을 때, 내용은 비슷하지만 장르가 너무 다른 처키가 추천되었다. 이러한 부분을 방지하기위해 우리는 2가지 생각을 하게되었다.
1. 하나이상의 장르가 유사하면 추천
2. 모든 장르가 유사해야 추천
이렇게 두가지 방법을 고안해냈고, 영화의 다양성과 성능향상이라는 두 마리 토끼를 모두 잡기위해 하나 이상의 장르가 유사하면 추천하도록 구현하게되었다. 모든 장르가 유사할 때 추처하는 부분은 시리즈물의 부재도 문제였고, 실제로 나는 판타지 영화를 좋아하지만, 실사 판타지와 애니메이션 판타지 모두를 좋아한다는 생각 때문에 1번으로 진행하게되었다.
그 후 우리의 기준으로 ML 성능평가를 진행해 보았다. 성능평가는 10개의 영화중 1개의 영화가 조금이라도 연관이 없다고 생각하면 정확도 90%, 2개의 영화가 연관이 없다고 생각하면 80% 와 같은 방법으로 성능평가를 진행했고, 18개의 영화를 기분으로 평균을 냈을 때, 키워드기반은 51%, 내용기반은 91%라는 성능을 가지게 되었다. 키워드 기반은 추천 서비스 중에서도 가장 낮은레벨의 추천서비스이자, 독특한 키워드를 가지고있는게 아니라면 추천에있어 어려움이있다. 예를들어 상어, 수녀 와 같은 키워드를 가진다면 정확도가 대폭 상승하지만, 일반 로맨스와 같은 영화에선 정확도가 많이 낮아진다. 그래도 평균적으로 10개의 영화중에 5~6개의 영화는 제대로 추천한다는 소리이다.
2. 협업필터링(SVD + 피어슨 유사도)
우리는 첫 번째 추천시스템보다 협업필터링에 더 많은 노력을 쏟아부었다. 먼저 협업필터링은 사용자가 보지않은 영화의 평점을 예측하는 추천시스템으로 영화의 개수가 많으면 많을수록 계산속도가 느려진다. 때문에 우리는 로딩속도를 대폭 상승시키기 위해 4가지 방법을 고안해냈다.
1. API 통신
- API 통신때마다 학습을 진행하게된다. 사용자의 평점이 실시간으로 반영된다는 장점이 있지만, 매 API통신때마다 학습을 진행하기 때문에 실질적으로 서비스하지 못한다.
2. pickle파일
- pickle파일에 학습된 데이터셋을 저장해두고 API통신때마다 그 회원에 해당하는 값을 넘겨주도록 진행했다. 하지만 이 방법은 학습된 데이터셋을 만들 때 사용되었던 데이터가 하나라도 변화가 있으면, pickle파일이 손상되는 점으로인해 실패했다.
3. Flask DB연결
- Flask에 DB를 연결하고자 하였으나, 이미 spring boot에서 DB를 연결했기 때문에 이중연결은 보안상의 문제로 진행하지 않았다.
4. spring boot 실행
-
spring boot가 실행되면 바로 데이터셋을 넘겨주고 flask에서 데이터셋을 학습하는 방법이다. 이 방법이 가장 효율적이고 안정적이였다.
이렇게 4번방법을 이용해 spring boot가 실행되면 데이터셋을 받아 학습을 진행하도록 구현했다. spring boot에 연결되어있는 DB값에 영화 평가가 담기기 때문에, 그 DB값을 리스트화 하고 Flask로 보내주도록 구현하게되었다. 이방법은 주기적으로 업데이트 버튼을 눌러 업데이트를 진행하거나 서버를 다시껏다켜야한다는 단점이 존재하지만, 가장 안정적이고 효율적인 방법이다.
구현 방법의 틀을 만들고, surprise 패키지의 SVD를 이용해 예측평점을 구하게되었다. SVD는 사용자 – 아이템간 잠재요인을 분석하고 평점을 예측하는 알고리즘이다. 하지만 우리는 잠재요인이라는 문제점을 발견하게되었다. 사용자들간의 유사도 보다는 평가가 많거나 평점이 높은 영화에 더 높은 예측 평점을 부여하게 된다는 것이다. 개인 맞춤형 서비스인 협업필터링에서 우리는 사용자들간의 유사도에 더 많은 가중치를 부여하고 싶었지만, 잠재요인이라는 문제점이 발생하고 말았다.
인터넷을 찾아보니 SVD와 함께 접목해 여러 가지 알고리즘을 함께 사용한다는 것을 알게되었고, 우리는 그 중 피어슨 유사도를 선택하게 되었다. 피어슨 유사도는 비슷한 평점, 취향을 가진 사용자에게 높은 가중치를 부여하는 알고리즘으로 –1~1점의 가중치를 가지고 있다. 비슷한 취향을 가진 사용자끼리는 +의 가중치를 그렇지 않은 사용자에게는 –가중치를 부여하게된다는 것이다. SVD로 예측한 평점에 사용자들의 유사도 가중치인 피어슨 유사도를 더하면 자동적으로 사용자들간의 유사도 가중치를 높일 수 있을것이라 생각했다. 이렇게 나와 다른 사용자들의 피어슨 유사도를 저장해 각 사용자들과 나의 취향 차이를 가중치로 만들게되었다. 그리고 각 영화를 추천한 사용자들의 유사도 가중치 평균을 구해 SVD로 구한 예측 평점에 모두 더해주었다. 이렇게 SVD로 구한 예측평점과 피어슨 유사도를 이용해 사용자의 유사도 가중치도 합치며 보다 더 높은 정확도를 가지게 되었다.
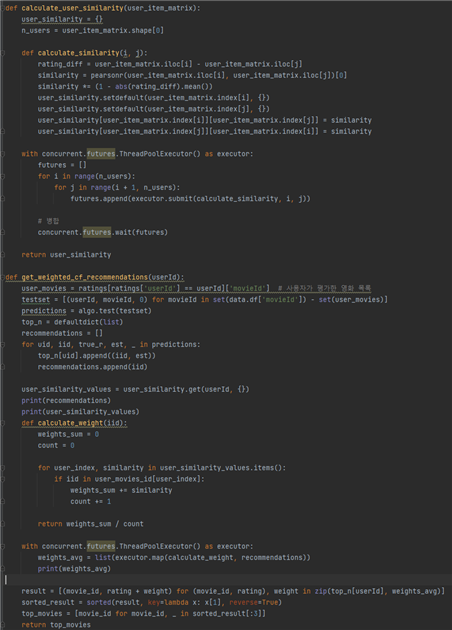

이런식으로 직접 엑셀로 그려 계산을통해 예측영화를 계산했고, 실제로 추천한 3개의 영화 중 1개라도 오류가 있으면 실패, 모두 맞으면 성공으로 간주해 정확도를 구하게되었다. 총 50번 진행했고, 그중 49번을 성공해 정확도는 98%라고 할 수 있다.
이렇게 피어슨 유사도를 통해 각 사용자의 유사도와 영화별 사용자 유사도 평균을 구하다 보니 연산이 늘어나게 되었고, 우리는 멀티 쓰레드 방식으로 병렬처리를 진행하게되었다. 컴퓨터의 성능마다 다르지만, 인텔 i5 맥북으로 돌렸을 때 5분정도 걸리던 연산이 10초로 줄어들게 되었다. 이렇게 수많은 과정을 거쳐 협업필터링을 완성하게 되었다.

실제로 애니메이션들의 평점을 좋게 남겼던 내 아이디의 협업필터링 부분이다.
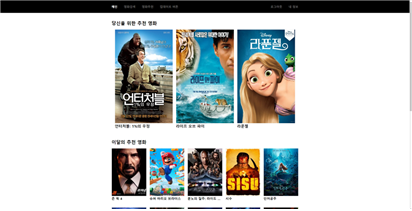
위의 사진은 전체 메인페이지의 사진이다.
느낀점
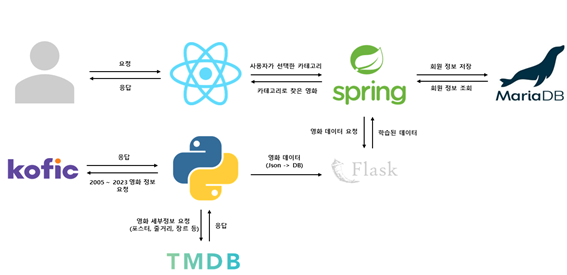
최종적으로 이러한 기술들을 사용해 프로젝트를 완료했다. 생각보다 많은 프레임워크와 기술들을 사용했다고 생각한다. 이 프로젝트에서 목표는 최대한 많은 기술을 사용해보고 익히는것이였는데, 그 목표를 이뤄 뜻깊은 프로젝트였다. 처음에는 너무 많은 프레임워크와 기술을 사용하는 것이 아닌가라는 걱정이 있었지만, 팀원들과함께 해낼 수 있었다.
머신러닝에 대해 한번도 배운적이 없어 정확한 방법은 아니지만, 첫 프로젝트에 이정도의 머신러닝을 썻다는거에 이의를 두고 있다.
받은 평가목록
-
로딩 속도를 향상시키기위해 병렬처리를 활용하였다는점이 인상적이었다.
-
완성도 높은 작품인것 같습니다. UI의 완성도가 조금만 더 높았다면 완벽했을것 같습니다.
-
중간발표보다 더 많은 성능향상과 기술적인 부분에서 굉장히 많은 부분이 들어가서 놀랬다. 여러가지 문제점을 닥친게 이해가 되고 문제점을 어떻게 해결했는지 기승전결로 이야기해줬다.
-
사용한 기술 하나하나가 다 높은 수준의 기술들이라 배울점이 많은것같다.
-
많이 잘했고 고생했다ㅠ
-
여러가지 AI기준을 가지고 비교 후 가장 성능이 적합한 모델을 선택 한점은 좋다.
-
내용 기반 성능이 눈으로 봤을 때 좋아보인다.
-
로그인, 협업 등 여러 항목에서 최선의 방법을 찾아나가는 모습이 좋다
-
가중치 방식으로 점수를 매기는 방식을 사용한점
-
자연어 처리 및 머신러닝 과정이 쉽지 않았을 것으로 예상되는데 결과에서 높은 퍼센트를 보인것이 인상적입니다. 보안에 신경 쓴 부분도 좋았습니다. 로딩 속도 향상을 위해 여러 가지 시행착오를 거친 것으로 보이는데 적당한 수준에서 타협하지 않고 성능 향상을 위해 노력하신 부분이 돋보여 좋았습니다. 기술적인 부분은 최대한 풀어서 설명해주신 점 좋았습니다.
-
수치로 한눈에 보기좋게 성능을 나타내 주어서 보기 편했습니다.
-
매끄러운 ppt 자료가 몰입하기에 좋았습니다.
-
자신의 문제점을 어떻게 보완하였는지 설명이 잘됨, 다른팀은 모를만한 기술 사용들을 쉽게 풀어 설명함
-
전체적으로 잘 만들었는데 좀 만 더 채워졌으면 좋겠어요.
전체적으로 PPT에 대한 내용이 많은데 PPT를 3시간이라는 시간을 들여 열심히 만들었다........... 가장 재미있었고 가장 힘들었던 내 첫번째 토이 프로젝트이다!
