[논문 리뷰] Deep Fuzzy Clustering—A Representation Learning Approach
Abstract
이 글에서는, 고차원 데이터와 복잡한 잠재 분포를 가진 데이터를 처리하는데 있어 퍼지 클러스터링이 가지는 어려움을 해결하기 위해 신경망을 통해 데이터를 표현하는 새로운 퍼지 클러스터링 방법을 제안합니다. 이 방법은 데이터의 표현 학습 관점에서 세 가지 제약 또는 목표를 신경망에 부과합니다. 첫째, 데이터의 좋은 표현은 새로운 특성 공간에서 매핑된 데이터가 원래 데이터의 재구성을 지원해야 하므로, 인코딩된 표현을 다른 신경망을 사용하여 디코딩함으로써 원래 데이터를 복구할 수 있도록 자동인코더 구조를 적용합니다. 둘째, 클러스터링 문제를 효율적으로 해결하기 위해 새로운 특성 공간에서 클러스터 내의 밀집도를 최소화하고 클러스터 간의 분리도를 최대화합니다. 마지막으로, 동일한 클래스의 데이터는 서로 가까워야 하므로, 새로운 표현들 사이의 친밀도는 차별적인 정보에 따라 조정됩니다. 이 모든 요소를 종합하여, 표현 학습과 부드러운 클러스터링을 동시에 수행하는 그래프 정규화된 깊은 정규화된 퍼지 밀집도와 분리 클러스터링 모델을 설계합니다. 이 모델을 위한 확률적 경사 하강법 기반의 학습 알고리즘이 제안되며, 기준 클러스터링 알고리즘과의 비교 연구도 수행됩니다.
Introduction
이 글에서는 데이터 마이닝, 지식 발견, 이미지 처리 및 패턴 인식과 같은 분야에 중요한 기여를 한 클러스터링, 특히 퍼지 클러스터링에 대해 논의합니다. 퍼지 클러스터링은 데이터를 클러스터에 부드럽고 유연하게 할당하는 것으로 유명합니다. 이 기술의 발전은 자데(Zadeh)의 퍼지 집합과 퍼지 논리 개념에서 시작되었습니다. 이후 러스피니(Ruspini)가 퍼지 클러스터링 알고리즘을 개발했고, 던(Dunn)과 베즈덱(Bezdek)은 퍼지 c-평균 (FCM)을 발전시켰습니다. FCM에서 가능성 c-평균, Ying-Yang FCM, 타입-2 퍼지 집합 및 클러스터링, 퍼지 가중 c-평균, 퍼지 밀집도 및 분리(FCS)와 같은 다양한 변형들이 개발되었습니다.
빅 데이터 시대에는 고차원 데이터(텍스트, 이미지, 비디오 등)의 클러스터링이 중요한 도전 과제가 되었습니다. 이를 해결하기 위한 두 가지 접근 방법이 제안되었습니다. 첫 번째는 커널 방법을 사용하여 더 표현력 있는 특성을 간접적으로 얻는 것이고, 두 번째는 원래 데이터의 명시적 변환입니다. 최근에는 딥러닝을 통해 데이터의 좋은 표현을 발견하는 것이 활발히 연구되고 있습니다. 이 글에서는 딥러닝의 성공에 동기를 얻어, 신경망을 통해 생성된 특성 공간에서 데이터를 표현하는 깊은 퍼지 클러스터링 모델을 제안합니다. 이 모델은 자동인코더(AE) 아키텍처를 적용하여 퍼지 클러스터링과 깊은 표현 학습을 동시에 수행합니다.
신경망에 의해 생성된 새로운 특성 공간에서 클러스터링 문제를 효율적으로 해결하기 위한 두 번째 제약 조건으로 클러스터 내의 밀집도를 최소화하고 클러스터 간의 분리도를 최대화하는 것을 제안합니다. 퍼지 c-평균(FCM)의 변형 중 하나인 FCS 알고리즘은 클러스터링의 정확도를 향상시키기 위해 데이터의 클래스 간 거리와 클래스 내 거리를 사용하여 퍼지 멤버십을 얻는 것을 권장합니다. 이러한 방법에서 영감을 받아, 이 글에서는 신경망의 목표를 위한 새로운 FCS 기반 제약 조건을 제안합니다.
이 글에서는 또한 표현 학습을 위한 신경망에 부과된 마지막 제약 조건으로 차별적 정보에 대해 논의합니다. 동일한 클래스의 데이터는 서로 가까워야 하므로 새로운 표현의 친밀도는 차별적 정보에 따라 미세 조정됩니다. 이를 위해, 이 글에서는 일시적 클러스터링 결과에서 파생된 가짜 라벨을 사용하여 차별 기반 친밀도를 계산하는 것을 제안합니다.
이 글에서 제안하는 깊은 퍼지 클러스터링 모델은 AE 복구 오류, 클래스 간 및 클래스 내 산포 행렬 기반 KL 발산, 그리고 차별적 정보와 관련된 친밀도의 일관성을 포함하는 세 가지 목표를 공동으로 최적화하는 심층 매개변수화된 퍼지 클러스터링 신경망입니다.
이 네트워크는 고차원 실제 세계 데이터셋의 클러스터링에서 기존 알고리즘과 비교하여 현저한 성능 향상을 보여줍니다.
이 글의 주요 기여는 다음과 같이 요약됩니다:
1) 심층 신경망의 표현 학습 능력을 퍼지 클러스터링과 결합한 것
2) 새로운 특성 공간에서 효율적인 클러스터링을 위한 새로운 정규화된 FCS 알고리즘 제안
3) 제안된 깊은 클러스터링 모델에서 숨겨진 특성 공간을 규제하기 위한 차별적 그래프 적용
4) 깊은 퍼지 클러스터링 모델을 위한 최적화 알고리즘 제안 및 실제 고차원 데이터에 대한 실험 결과 제시. 이 글은 관련 작업 검토, 제안된 모델 및 학습 알고리즘 소개, 기준 클러스터링 방법과 비교한 실험 결과, 그리고 결론으로 구성되어 있습니다.
Related Work
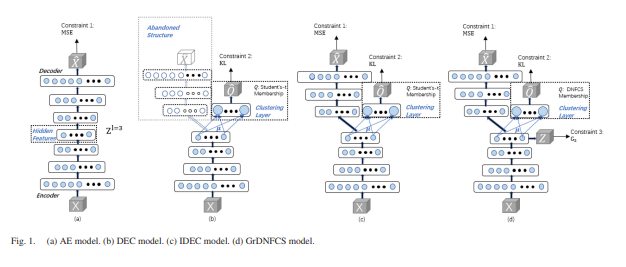
A. FCM
퍼지 c-평균(FCM) 클러스터링은 데이터를 클러스터에 부드럽게 할당함으로써 비감독 클러스터링 성능을 향상시키는 것을 목표로 합니다. FCM은 데이터가 속할 클러스터 중심과의 거리를 기반으로 멤버십을 계산합니다. 클러스터 중심과 멤버십은 반복적으로 업데이트되며, 이 과정은 데이터가 클러스터에 효과적으로 할당될 때까지 계속됩니다.
B. AE
AE는 데이터를 압축하고 복원하는 데 사용되는 중요한 비감독 신경망 모델입니다. 인코더는 데이터를 낮은 차원의 비선형 특성으로 압축하고, 디코더는 이 인코딩된 특성을 바탕으로 원본 데이터를 복원합니다. AE의 목표 함수는 입력 데이터와 복원된 데이터 사이의 차이를 최소화하도록 설계되었습니다.
C. Deep Clustering Based on Student’s-t Distribution
DEC(Deep Embedding Clustering) 모델과 IDEC(Improved Deep Embedding Clustering) 모델은 AE와 클러스터링을 동시에 최적화하는 효과적인 깊은 클러스터링 모델입니다. 이들은 t-분포를 기반으로 한 클러스터링 레이어를 통해 클러스터링을 수행합니다. 이 글에서는 GrDNFCS(그래프-정규화된 깊은 정규화된 퍼지 밀집도와 분리) 클러스터링 모델을 제안하여 깊은 표현 학습과 퍼지 클러스터링을 동시에 수행합니다.
PSEUDOLABEL-BASED AFFINITY GRAPH-REGULARIZED DEEP FUZZY CLUSTERING MODEL
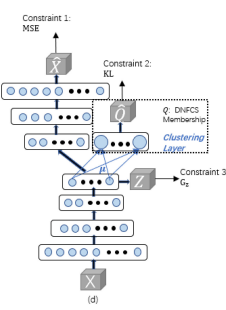
섹션 I에서 언급된 바와 같이, 실제 고차원 데이터의 클러스터링은 어려운 문제입니다. FensiVAT [36]과 같은 성공적인 솔루션은 일반적으로 클러스터링 전에 낮은 차원의 좋은 표현을 생성합니다. 이 섹션에서는 깊은 표현을 발견하고 그 새로운 표현에 퍼지 클러스터링을 동시에 수행하는 새로운 깊은 퍼지 클러스터링 모델을 제안합니다. 고차원 실제 세계 데이터셋에서 퍼지 클러스터링의 성능을 향상시키기 위해 제안된 모델에는 세 가지 제약 조건이 부과됩니다 [그림 1(d) 참조].
첫 번째 제약 조건은 숨겨진 표현을 정규화하여 원본 데이터를 재구성하는 MSE 항입니다. 이러한 종류의 AE 기반 제약 조건은 섹션 II-B에서 논의되었습니다. 두 번째 제약 조건은 깊은 퍼지 클러스터링 모델에 클러스터 간 분리를 내장하는 것이며, 세부 사항은 섹션 III-A에서 제공됩니다. 깊은 퍼지 클러스터링에서 적절한 퍼지화자 m을 찾는 방법은 섹션 III-B에서 보여집니다. 제안된 모델의 마지막 제약 조건은 섹션 III-C에서 제시된 바와 같이, 가짜 라벨 기반 친밀도를 사용하여 학습된 표현을 정규화하는 것입니다. 종합하면, 제안된 모델의 최종 손실 함수와 훈련 알고리즘은 섹션 III-D에서 제시됩니다.
Normalized FCS-Based Membership and KL-Divergence-Based Objective
깊은 퍼지 클러스터링 모델의 두 번째 제약 조건은 FCM의 클러스터링 효과를 향상시키는 것을 목표로 합니다. 많은 클러스터링 방법들, 특히 FCM과 학생의 t-분포 기반 접근법은 클러스터 내의 밀집도를 멤버십을 유도하는 데 사용합니다. 반면에 FCS는 클러스터 내외의 거리를 사용하여 데이터의 퍼지 멤버십을 추정하는 효과적인 퍼지 클러스터링 방법입니다. FCS 알고리즘의 우수성에 동기를 얻어, 우리는 제안된 모델의 두 번째 제약 조건을 설계하기 위한 수단으로 깊은 정규화된 퍼지 밀집도와 분리 클러스터링(DNFCS)을 제시합니다.
1) 퍼지 밀집도와 분리(FCS): FCS에서 데이터는 c개의 카테고리로 분리됩니다. 이 알고리즘에서의 퍼지 멤버십은 두 클러스터 행렬을 고려합니다: 퍼지 클러스터 간 산포 행렬 Sfb와 퍼지 클러스터 내 산포 행렬 Sfw입니다. 이들은 각각 데이터와 평균 지점 간 거리를 확장하고 같은 클래스 내 데이터 간 거리를 줄이는 것을 목표로 합니다. 이 목표 함수에서 ηj는 퍼지 멤버십 qij를 L(qij, μj)에 대해 미분 가능하게 하는 매개변수입니다.
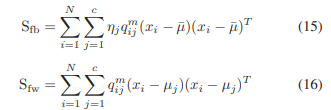
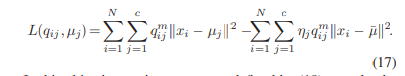

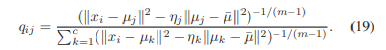
2) 정규화된 FCS 멤버십: 실제로, FCS의 퍼지 멤버십은 ηj가 항상 양수를 보장하지 않습니다. 이를 보장하기 위해 DNFCS를 제안합니다. DNFCS에서는 숨겨진 표현 zi를 입력으로 받아 퍼지 멤버십 qij를 출력합니다. 이 퍼지 멤버십은 클러스터 내 거리와 클러스터 간 거리의 균형을 맞추는 데 사용되는 할당된 하이퍼파라미터 β에 의해 정의됩니다. DNFCS에서의 목표 함수는 클러스터 내 산포 행렬을 최소화하고 클러스터 간 행렬을 동시에 최대화하는 것입니다.
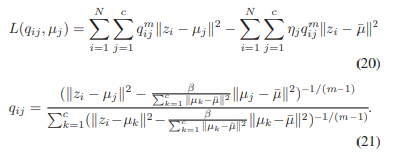
3) KL 발산 기반 목표 항: 클러스터링 레이어의 출력 qij가 관찰되고, KL 발산을 최소화하는 것에 의해 동기 부여된 이 목표는 qij를 표적 pij에 근접하게 만듭니다. KL 발산 기반의 손실이 수렴되면, 숨겨진 뉴런과 퍼지 클러스터링 뉴런을 연결하는 가중치 μij는 j번째 클러스터에 대한 중심이 됩니다. DNFCS 멤버십 qij를 사용함으로써, 제안된 두 번째 제약 조건은 클러스터 내 거리의 밀집도와 클러스터 간 거리의 분리를 동시에 달성합니다.
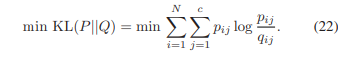
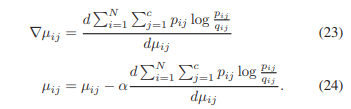
Pseudolabel-Based Affinity Graph Regularization
이 부분은 인코딩 신경망에 의해 생성된 표현에 대한 세 번째 제약 조건으로서, 새로운 의사 라벨(pseudolabel) 기반의 친밀도 정규화를 제안합니다. 이는 동일 클러스터에 속하는 특성들이 서로 가까이 있어야 하며, 차별적 정보의 중요성을 고려하는 것을 목적으로 합니다.
1) 그래프 기반 정규화 (Graph-Based Regularization)
정규화의 기본 아이디어는 입력 데이터 간의 친밀도가 새로운 표현 간의 친밀도와 일치해야 한다는 것입니다.
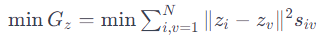
2) 의사 라벨 가이드 친밀도 행렬 (Pseudolabel-Guided Affinity Matrix):
친밀도 s iv는 중요하며, 전통적으로 원본 데이터에 대한 KNN 알고리즘을 통해 얻어집니다.
그러나 KNN은 시간이 많이 소요되므로, 깊은 학습 모델에 직접 적용하기 어렵습니다.
이 문제를 해결하기 위해, 클러스터링 레이어에서 예측된 퍼지 멤버십으로부터 차별적 정보를 얻는 의사 라벨 기반 접근법을 제안합니다.
의사 라벨 기반 그래프 정규화 방법이 KNN 기반 친밀도 정규화보다 더 효율적임을 섹션 IV-E에서 입증합니다.
3) 의사 라벨 기반 친밀도의 업데이트 방법 (Update Method):
친밀도 행렬의 품질을 향상시키기 위해, T번째 학습 에포크에서 얻은 숨겨진 특성과 의사 라벨을 사용하여 친밀도 s_iv를 업데이트합니다.
전통적인 친밀도 기반 접근법과 달리, 제안된 의사 라벨 기반 친밀도는 학습 과정 중에 업데이트될 수 있으며, 업데이트 에포크는 1보다 클 수 있습니다.
학습 에포크가 증가함에 따라 손실이 점차 감소하고, 의사 라벨의 정확도가 향상됩니다.
이를 통해 친밀도 정보가 더 정확해지고, 표현이 데이터의 실제 분포와 더 일치하도록 유도됩니다.
Objective and Training Algorithm
EXPERIMENTS
A. 데이터셋 및 실험 설정
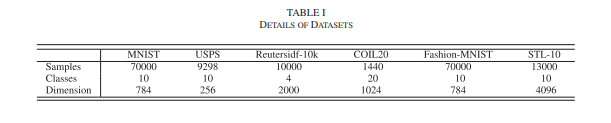
실제 세계 데이터셋인 MNIST, USPS, Reutersidf-10k, COIL20, Fashion-MNIST, STL-10이 GrDNFCS의 클러스터링 성능을 평가하는 데 사용되었습니다. 이들은 머신 러닝 알고리즘과 모델의 성능 및 강건성을 테스트하는 데 자주 사용되는 고차원 벤치마크 데이터셋입니다. 실험에서 사용된 실제 세계 데이터셋에 대한 자세한 내용은 표 I에 나열되어 있습니다.
Van Der Maaten의 추천에 따라, GrDNFCS의 AE 구조와 클러스터링 레이어의 차원은 일반적으로 사용되는 d-500-500-2000-c-2000-500-500-d와 c로 설정되었습니다. 모델의 사전 학습 단계에서 오버피팅을 방지하기 위해, 숨겨진 레이어와 출력 레이어에 드롭아웃이 사용되었습니다. K-means, 스펙트럼 임베딩 클러스터링(SEC), FCM, 미니배치 K-means(MBKM)에 대해 주성분 분석(PCA)가 저차원 특성 추출에 적용되었습니다. 기준선 방법의 모든 하이퍼파라미터는 비교 실험에서 미세 조정된 최적의 값입니다.
B. 비교 알고리즘
다음 중요한 클러스터링 방법들은 제안된 GrDNFCS와 비교할 기준선 알고리즘입니다:
K-means: 데이터가 하나의 클러스터에만 속하는 하드 클러스터링 알고리즘.
FCM: 소프트 클러스터링 알고리즘.
SEC [76]: 매니폴드 학습 기반 클러스터링 알고리즘.
MBKM [77]: K-means의 계산 복잡성을 줄이기 위해 미니배치를 사용하는 알고리즘.
DEC [48]: 디코더를 버리고 학생의 t-분포를 기반으로 하는 딥 클러스터링 모델.
IDEC 모델 [49]: 학생의 t-분포를 기반으로 하며 AE의 디코더를 유지하고 AE를 정규화하는 재구성 항을 사용하는 딥 클러스터링 모델.
C. 평가 지표
클러스터링 성능을 평가하기 위해 정확도(ACC), 정규화된 상호 정보(NMI), 조정된 랜드 인덱스(ARI)를 사용합니다.
D. 하이퍼파라미터 민감도 분석
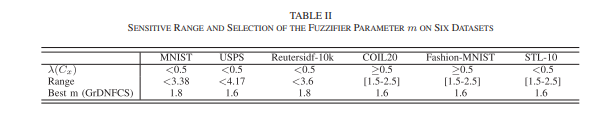

GrDNFCS 모델에는 다섯 가지 하이퍼파라미터가 있으며, 이들은 정규화 파라미터 α1, α2, 친밀도 파라미터 t, 할당 파라미터 β, 퍼지화자 m입니다. 광범위하게 설계된 범위와 그리드 검색 방법을 사용하여 하이퍼파라미터의 민감도 영역을 찾았습니다. USPS와 Reutersidf-10k 데이터셋에서 이 다섯 하이퍼파라미터의 클러스터링 정확도 곡선은 그림 2(a)–(j)에 나타나 있습니다. 또한, 교차 검증을 사용하여 하이퍼파라미터의 최적값을 찾을 수 있습니다.
실험 결과에 따르면, 평가된 데이터셋이 다르더라도 GrDNFCS의 하이퍼파라미터의 민감도 영역은 유사합니다. 이러한 민감도 영역은 GrDNFCS가 원하는 클러스터링 성능을 달성하도록 만듭니다. 또한, 그림 2(a)–(j)는 새로운 데이터셋에 제안된 모델을 적용할 때 각 하이퍼파라미터에 대한 유용한 민감도 영역을 제공합니다.
E. 시간 복잡도 분석
전체 시간 복잡도는 GrDNFCS의 각 트레이닝 에포크마다의 전방 및 후방 시간 복잡도를 포함.
KNN 기반 친밀도 그래프와 의사 라벨 기반 그래프 정규화의 시간 복잡도 비교.
COIL20 데이터셋에서 카테고리 수 증가에 따른 전체 훈련 시간 테스트.
F. 비교 클러스터링 실험 및 결과
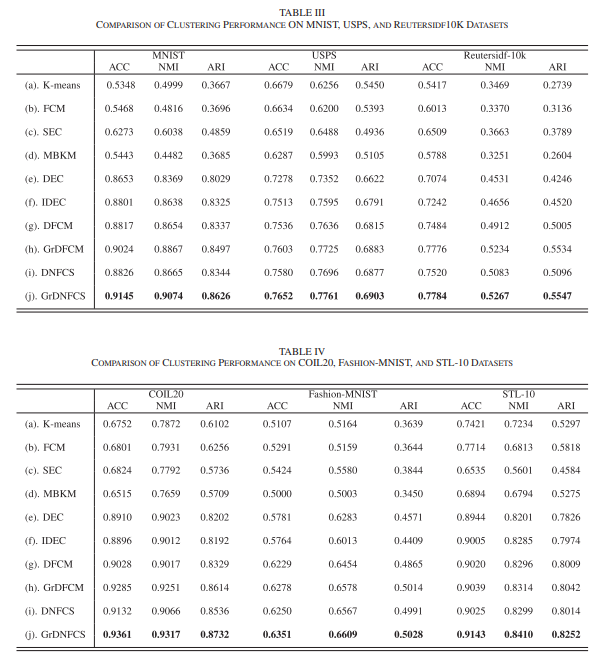
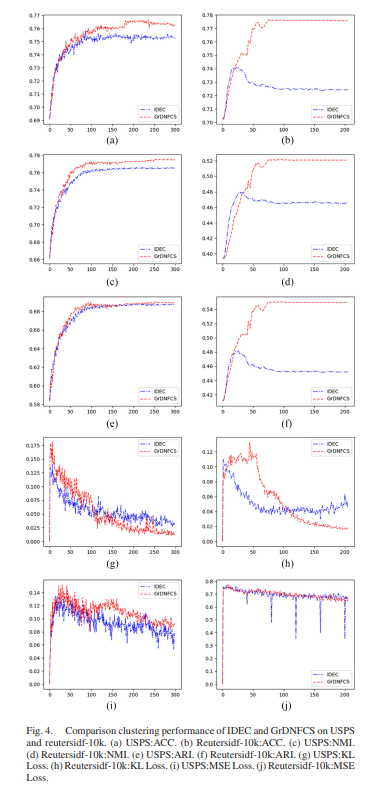
실험을 통해 GrDNFCS 모델의 클러스터링 성능 검증.
딥 표현, DNFCS 멤버십, 친밀도 정규화의 효과 검토.
정확도와 손실 곡선(USPS와 Reutersidf-10k에서) 제공.
GrDNFCS는 다른 고차원 데이터셋에서 최고의 클러스터링 성능을 달성.
실험 결과는 GrDNFCS의 강건성, 딥 표현의 효과, 퍼지화자 m의 중요성, 의사 라벨 기반 친밀도 정규화의 유용성을 입증.
IDEC와 비교하여 GrDNFCS의 우수성 확인.
