-
rnn내부구조
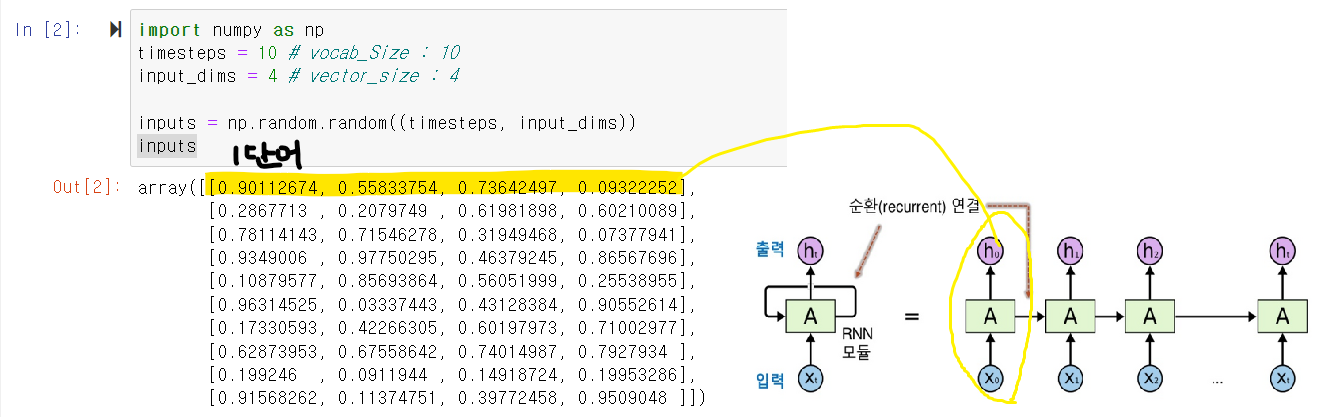
-
return_Sequences=True
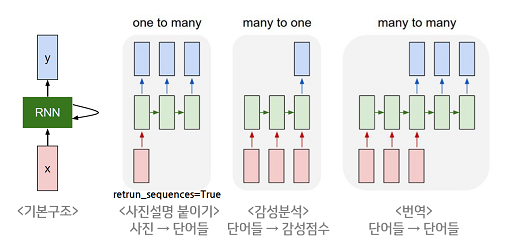 출처:
출처:
https://brunch.co.kr/@linecard/324
https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
RNN 내부 이해
하나의 input이 있을 때 여러개 output이 있을 수 있다.
ht = tanh(Wx Xt + Wh h(t-1) + bias)
Xt : 가상 입력 데이터
embedding을 했음
import numpy as np
timesteps = 10 # vocab_Size : 10
input_dims = 4 # vector_size : 4
inputs = np.random.random((timesteps, input_dims))
inputsarray([[0.19093102, 0.46330531, 0.73710614, 0.75053189],
[0.15380386, 0.37371035, 0.60822087, 0.30212406],
[0.57354832, 0.56882249, 0.27344565, 0.28325112],
[0.47652602, 0.07965003, 0.04707211, 0.807744 ],
[0.27385387, 0.33608652, 0.10539779, 0.74653977],
[0.07139212, 0.03497438, 0.84326877, 0.7219065 ],
[0.54223106, 0.26822572, 0.31839833, 0.3472377 ],
[0.15519828, 0.84729487, 0.01589498, 0.95549488],
[0.13123711, 0.05083824, 0.78304752, 0.85053066],
[0.06622686, 0.51280097, 0.68751053, 0.19184749]])hidden_units = 8
hidden_state = np.zeros((hidden_units,))
hidden_statearray([0., 0., 0., 0., 0., 0., 0., 0.])keras가 하는 일
ht = tanh(Wx Xt + Wh h(t-1) + bias)
8행 4열 (8,4)(4,1) + (8,8)(8,1)+(8,1)
(8,1) + (8,1) +(8,1) = (8,1)
Wx = np.random.random((hidden_units, input_dims)) #(8,4)
Wh = np.random.random((hidden_units, hidden_units))#(8,8)
b = np.random.random((hidden_units,))#(8,1)
Wx.shape, Wh.shape, b.shape((8, 4), (8, 8), (8,))hidden_state_list=[]
for input_one in inputs: #10번 반복(10단어)
#ht = tanh(Wx * Xt + Wh * h(t-1) + bias)
ht_res = np.tanh(np.dot(Wx, input_one) + np.dot(Wh, hidden_state) + b) #현재 출력
hidden_state_list.append([ht_res])
hidden_state = ht_res
hidden_state_list ---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_16024\1400609434.py in <module>
2 for input_one in inputs: #10번 반복(10단어)
3 #ht = tanh(Wx * Xt + Wh * h(t-1) + bias)
----> 4 ht_res = np.tanh(np.dot(Wx, input_one) + np.dot(Wh, hidden_state) + b) #현재 출력
5 hidden_state_list.append([ht_res])
6 hidden_state = ht_res
<__array_function__ internals> in dot(*args, **kwargs)
ValueError: shapes (8,8) and (1,4,3) not aligned: 8 (dim 1) != 4 (dim 1)from tensorflow.keras.layers import SimpleRNN
SimpleRNN(32) # hidden_units, Conv2D(64), Dense(10)
SimpleRNN(32, input_shape, input_shape = (timesteps, input_dim))
SimpleRNN(32, input_shape, input_length = timesteps, input_dim = input_dim)
SimpleRNN(32, input_shape, return_sequences=True, input_shape = (timesteps, input_dim)) # return_sequences=False가 기본값
SimpleRNN(32, input_shape, return_sequences=True, return_state=True, input_shape = (timesteps, input_dim))---------------------------------------------------------------------------
NameError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_16024\1386081663.py in <module>
2 SimpleRNN(32) # hidden_units, Conv2D(64), Dense(10)
3
----> 4 SimpleRNN(32, input_shape, input_shape = (timesteps, input_dim))
5
6 SimpleRNN(32, input_shape, input_length = timesteps, input_dim = input_dim)
NameError: name 'input_shape' is not definedfrom tensorflow.keras.models import Sequentialmodel = Sequential([SimpleRNN(3, input_shape=(10,4))])
model.summary()
#Wx:3*4, Wh:3*3Model: "sequential_21"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_31 (SimpleRNN) (None, 3) 24
=================================================================
Total params: 24
Trainable params: 24
Non-trainable params: 0
_________________________________________________________________model = Sequential([SimpleRNN(3, batch_input_shape=(5,10,4))])
model.summary()Model: "sequential_22"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_32 (SimpleRNN) (5, 3) 24
=================================================================
Total params: 24
Trainable params: 24
Non-trainable params: 0
_________________________________________________________________model = Sequential([SimpleRNN(3, batch_input_shape=(5,10,4), return_sequences=True)])
model.summary()
#Wx:3*4 Wh:3*3 b:3 => 12+9+3=24Model: "sequential_23"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_33 (SimpleRNN) (5, 10, 3) 24
=================================================================
Total params: 24
Trainable params: 24
Non-trainable params: 0
_________________________________________________________________#rnn2번 = Deep RNN(심층rnn)
#return_sequences=True 을 통해 RNN을 쌓기위해서, 하지만 복잡도가 높다고 해서 항상 좋은 건 아니기에 해봐야 알 수 있다.
#결과값을 여러 개 나올 수 있어서 X,y train 여러개 할 수 있다.
model = Sequential([SimpleRNN(3, batch_input_shape=(5,10,4), return_sequences=True),
SimpleRNN(3, return_sequences=True)
])
model.summary()
Model: "sequential_24"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_34 (SimpleRNN) (5, 10, 3) 24
simple_rnn_35 (SimpleRNN) (5, 10, 3) 21
=================================================================
Total params: 45
Trainable params: 45
Non-trainable params: 0
_________________________________________________________________from tensorflow.keras.layers import Bidirectionalmodel = Sequential([
Bidirectional(SimpleRNN(3, return_sequences=True), input_shape=(10,5))
])
model.summary()
#3*3 + 3*5 + 3 = 9+15+3 = 27 * 2 = 54
# 나는 오늘 [치킨] 먹고 싶다Model: "sequential_25"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bidirectional_1 (Bidirectio (None, 10, 6) 54
nal)
=================================================================
Total params: 54
Trainable params: 54
Non-trainable params: 0
_________________________________________________________________train_X=np.random.random((4,5))
train_Xarray([[0.72086586, 0.22345077, 0.69338963, 0.91736445, 0.0108463 ],
[0.08564687, 0.87114107, 0.48255117, 0.27699769, 0.3550196 ],
[0.87874899, 0.99494361, 0.02386441, 0.45135215, 0.87288311],
[0.99672176, 0.94006783, 0.98806925, 0.28386568, 0.34482131]])train_X = train_X.reshape((-1,4,5))
train_Xarray([[[0.72086586, 0.22345077, 0.69338963, 0.91736445, 0.0108463 ],
[0.08564687, 0.87114107, 0.48255117, 0.27699769, 0.3550196 ],
[0.87874899, 0.99494361, 0.02386441, 0.45135215, 0.87288311],
[0.99672176, 0.94006783, 0.98806925, 0.28386568, 0.34482131]]])train_X.shape(1, 4, 5)rnn = SimpleRNN(3, return_sequences=True)
hidden_state = rnn(train_X)
hidden_state.shape, hidden_state(TensorShape([1, 4, 3]),
<tf.Tensor: shape=(1, 4, 3), dtype=float32, numpy=
array([[[-0.01488839, -0.3331584 , -0.5038846 ],
[-0.600117 , -0.6700086 , -0.9101974 ],
[ 0.31104553, -0.9478841 , -0.73979986],
[ 0.08852138, -0.9020153 , -0.94455254]]], dtype=float32)>)rnn = SimpleRNN(3, return_sequences=True,return_state=True)
hidden_state, last_state = rnn(train_X)
hidden_state.shape, hidden_state, last_state.shape,last_state(TensorShape([1, 4, 3]),
<tf.Tensor: shape=(1, 4, 3), dtype=float32, numpy=
array([[[ 0.5367813 , 0.42327297, 0.44304246],
[-0.2182088 , -0.65690875, -0.6705875 ],
[-0.10877639, 0.7939693 , -0.05944298],
[ 0.41017136, -0.63257456, 0.34562686]]], dtype=float32)>,
TensorShape([1, 3]),
<tf.Tensor: shape=(1, 3), dtype=float32, numpy=array([[ 0.41017136, -0.63257456, 0.34562686]], dtype=float32)>)rnn = SimpleRNN(3, from tensorflow.keras.layers )
hidden_state, last_state = rnn(train_X)
hidden_state.shape, hidden_state, last_state.shape,last_state File "C:\Users\user\AppData\Local\Temp\ipykernel_16024\2656467335.py", line 1
rnn = SimpleRNN(3, from tensorflow.keras.layers )
^
SyntaxError: invalid syntax#error나는 이유는 lstm에는 은닉층이랑 cell상태도 있기 때문이다.
from tensorflow.keras.layers import LSTM
lstm = LSTM(3, return_sequences=False,return_state=True)
hidden_state, last_hidden_state, last_cell_state = lstm(train_X)
hidden_state.shape, hidden_state, last_state.shape,last_state, last_cell_state.shape, last_cell_state#lstm 은 rnn과 다르게 cell state도 출력된다.
lstm = LSTM(3, return_sequences=True,return_state=True)
hidden_state, last_hidden_state, last_cell_state = lstm(train_X)
hidden_state.shape, hidden_state, last_state.shape,last_state, last_cell_state.shape, last_cell_state
#TensorShape([1, 4, 3] : 차원=4(TensorShape([1, 4, 3]),
<tf.Tensor: shape=(1, 4, 3), dtype=float32, numpy=
array([[[-0.01518249, -0.1621133 , -0.0144873 ],
[-0.12557061, -0.2426117 , -0.02431121],
[-0.17863382, -0.37962332, -0.07366271],
[-0.16617344, -0.45549923, -0.08902212]]], dtype=float32)>,
TensorShape([1, 3]),
<tf.Tensor: shape=(1, 3), dtype=float32, numpy=array([[ 0.41017136, -0.63257456, 0.34562686]], dtype=float32)>,
TensorShape([1, 3]),
<tf.Tensor: shape=(1, 3), dtype=float32, numpy=array([[-0.26270822, -0.78616345, -0.21555428]], dtype=float32)>)#error남 마지막 꺼를 안 보겠다고 해놓고 마지막꺼 출력해서
lstm = LSTM(3, return_sequences=True,return_state=False)
hidden_state, last_hidden_state, last_cell_state = lstm(train_X)
hidden_state.shape, hidden_state, last_state.shape,last_state, last_cell_state.shape, last_cell_state---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_16024\1442534190.py in <module>
1 #error남 마지막 꺼를 안 보겠다고 해놓고 마지막꺼 출력해서
2 lstm = LSTM(3, return_sequences=True,return_state=False)
----> 3 hidden_state, last_hidden_state, last_cell_state = lstm(train_X)
4 hidden_state.shape, hidden_state, last_state.shape,last_state, last_cell_state.shape, last_cell_state
ValueError: not enough values to unpack (expected 3, got 1)lstm = LSTM(3, return_sequences=True,return_state=False)
hidden_state= lstm(train_X)
hidden_state.shape, hidden_state(TensorShape([1, 4, 3]),
<tf.Tensor: shape=(1, 4, 3), dtype=float32, numpy=
array([[[-0.01190256, -0.0126974 , 0.12204829],
[ 0.07283699, 0.06875242, 0.178883 ],
[-0.0131071 , 0.06586495, 0.16148917],
[ 0.06033057, 0.11212185, 0.21860315]]], dtype=float32)>)from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical#가사 일부를 제시하면 여러 단어를 출력하도록 학습(생성형)
text = """저 별을 따다가 니 귀에 걸어주고파
저 달 따다가 니 목에 걸어주고파
세상 모든 좋은 것만 해주고 싶은
이런 내 맘을 그댄 아나요
걸어주고파 난 어떻게든 할거야"""tok = Tokenizer()
tok.fit_on_texts([text])
vocab_size = len(tok.word_index)+1
vocab_size23from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense, SimpleRNN
for sentence in text.split("\n"):
res = tok.texts_to_sequences([sentence])[0]
seq_list=[]
for sentence in text.split("\n"):
res = tok.texts_to_sequences([sentence])[0]
for i in range(1, len(res)):
seq = res[:i+1]
seq_list.append(seq)
max_len = max(len(sent) for sent in seq_list)
seq_padded = pad_sequences(seq_list, maxlen=max_len)
X = seq_padded[:, :-1]
y = seq_padded[:, -1]
y_hot = to_categorical(y, num_classes = vocab_size)
model = Sequential([
Embedding(vocab_size,10),
SimpleRNN(32),
Dense(vocab_size, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=['accuracy'])
history = model.fit(X, y, epochs=200, verbose=1)Epoch 1/200
1/1 [==============================] - 1s 593ms/step - loss: 3.1316 - accuracy: 0.0455
Epoch 2/200
1/1 [==============================] - 0s 4ms/step - loss: 3.1229 - accuracy: 0.0455
Epoch 3/200
1/1 [==============================] - 0s 4ms/step - loss: 3.1142 - accuracy: 0.0909
Epoch 4/200
1/1 [==============================] - 0s 4ms/step - loss: 3.1054 - accuracy: 0.1364
Epoch 5/200
1/1 [==============================] - 0s 4ms/step - loss: 3.0965 - accuracy: 0.1818 생략def generate_sentence(model, starting_word, tok, n):
init_word = starting_word
sentence=""
#단어 preict를 n번 반복, 문장을 만들 것이다.
for dummy in range(n): # dummy = _
start_text = "별을 따다가 니"
encoded = tok.texts_to_sequences([start_text])[0]
padded = pad_sequences([encoded], maxlen=max_len)
res = model.predict(padded, verbose=0) #verbose=0 :과정출력x
res_softmax = np.argmax(res, axis=1)
for word, index in tok.word_index.items():
if res_softmax == index:
break
starting_word = sentence + " " + word
sentence = sentence + " " + word
sentence = init_word + sentence
return sentencegenerate_sentence(model, "저", tok, 2)'저 니 니'generate_sentence(model, "저 별을", tok, 20)'저 별을 니 니 니 니 니 니 니 니 니 니 니 니 니 니 니 니 니 니 니 니'spam
import pandas as pddata = pd.read_csv('datasets/spam.csv', encoding="latin1")
data = data[["v1","v2"]]
data| v1 | v2 | |
|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... |
| 1 | ham | Ok lar... Joking wif u oni... |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... |
| 3 | ham | U dun say so early hor... U c already then say... |
| 4 | ham | Nah I don't think he goes to usf, he lives aro... |
| ... | ... | ... |
| 5567 | spam | This is the 2nd time we have tried 2 contact u... |
| 5568 | ham | Will Ì_ b going to esplanade fr home? |
| 5569 | ham | Pity, * was in mood for that. So...any other s... |
| 5570 | ham | The guy did some bitching but I acted like i'd... |
| 5571 | ham | Rofl. Its true to its name |
5572 rows × 2 columns
data['v1'] = data['v1'].replace(["ham","spam"],[0, 1]) #ham=0, spam=1
data[:5]| v1 | v2 | |
|---|---|---|
| 0 | 0 | Go until jurong point, crazy.. Available only ... |
| 1 | 0 | Ok lar... Joking wif u oni... |
| 2 | 1 | Free entry in 2 a wkly comp to win FA Cup fina... |
| 3 | 0 | U dun say so early hor... U c already then say... |
| 4 | 0 | Nah I don't think he goes to usf, he lives aro... |
data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5572 entries, 0 to 5571
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 v1 5572 non-null int64
1 v2 5572 non-null object
dtypes: int64(1), object(1)
memory usage: 87.2+ KB#중복확인
data["v2"].nunique()51695572-5169403#중복제거
data = data.drop_duplicates(subset=["v2"])data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 5169 entries, 0 to 5571
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 v1 5169 non-null int64
1 v2 5169 non-null object
dtypes: int64(1), object(1)
memory usage: 121.1+ KBdata["v2"].nunique()5169data["v1"].value_counts()0 4516
1 653
Name: v1, dtype: int64from sklearn.model_selection import train_test_split
X_data = data['v2']
y_data = data['v1']
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=0, stratify=y_data)X_train.shape, X_test.shape, y_train.shape, y_test.shape((4135,), (1034,), (4135,), (1034,))tok = Tokenizer()
tok.fit_on_texts(X_train)
X_train_encoded = tok.texts_to_sequences(X_train)
X_train_encoded[:2][[102, 1, 210, 230, 3, 17, 39], [1, 59, 8, 427, 17, 5, 137, 2, 2326]]print(tok.word_index){'i': 1, 'to': 2, 'you': 3, 'a': 4, 'the': 5, 'u': 6, 'and': 7, 'in': 8, 'is': 9, 'me': 10, 'my': 11, 'for': 12, 'your': 13, 'it': 14, 'of': 15, 'have': 16, 'on': 17, 'call': 18, 'that': 19, 'are': 20, '2': 21, 'now': 22, 'so': 23, 'but': 24, 'not': 25, 'can': 26, 'or': 27, "i'm": 28, 'get': 29, 'at': 30, 'do': 31, 'if': 32, 'be': 33, 'will': 34, 'just': 35, 'with': 36, 'we': 37, 'no': 38, 'this': 39, 'ur': 40, 'up': 41, '4': 42, 'how': 43, 'gt': 44, 'lt': 45, 'go': 46, 'when': 47, 'from': 48, 'what': 49, 'ok': 50, 'out': 51, 'know': 52, 'free': 53, 'all': 54, 'like': 55} 생략total_cnt = len(tok.word_index)
vocab_size = len(tok.word_index) + 1
vocab_size7822import matplotlib.pyplot as plt
plt.hist([len(sample) for sample in X_data], bins=100)
plt.show()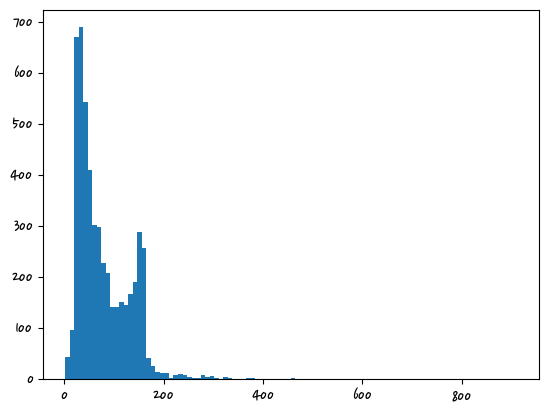
#4135 : 훈련해야 할 것
max_len = 200
X_train_padded = pad_sequences(X_train_encoded, maxlen=max_len)
X_train_padded.shape(4135, 200)vocab_size7822model = Sequential([
Embedding(vocab_size, 30),
SimpleRNN(32),
Dense(1, activation="sigmoid")
])
model.summary()Model: "sequential_29"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_12 (Embedding) (None, None, 30) 234660
simple_rnn_42 (SimpleRNN) (None, 32) 2016
dense_12 (Dense) (None, 1) 33
=================================================================
Total params: 236,709
Trainable params: 236,709
Non-trainable params: 0
_________________________________________________________________model.compile(optimizer='rmsprop',loss="binary_crossentropy",metrics=['acc'])
history=model.fit(X_train_padded, y_train, epochs=5, batch_size=64, validation_split=0.2)Epoch 1/5
52/52 [==============================] - 2s 26ms/step - loss: 0.5070 - acc: 0.7860 - val_loss: 0.3538 - val_acc: 0.8984
Epoch 2/5
52/52 [==============================] - 1s 23ms/step - loss: 0.1911 - acc: 0.9501 - val_loss: 0.1450 - val_acc: 0.9528
Epoch 3/5
52/52 [==============================] - 1s 24ms/step - loss: 0.0820 - acc: 0.9791 - val_loss: 0.1325 - val_acc: 0.9541
Epoch 4/5
52/52 [==============================] - 1s 23ms/step - loss: 0.0638 - acc: 0.9791 - val_loss: 0.0666 - val_acc: 0.9807
Epoch 5/5
52/52 [==============================] - 1s 23ms/step - loss: 0.0251 - acc: 0.9940 - val_loss: 0.0627 - val_acc: 0.9831X_test_enc = tok.texts_to_sequences(X_test)
X_test_pad = pad_sequences(X_test_enc, maxlen=max_len)
model.evaluate(X_test_pad, y_test)33/33 [==============================] - 0s 5ms/step - loss: 0.0825 - acc: 0.9797
[0.08245593309402466, 0.9796905517578125]
DL 공부중