네이버 뉴스 스크래핑
네이버 뉴스 스크래핑하는 중 에러 발생
에러 : 현재 연결은 원격 호스트에 의해 강제로 끊겼습니다
코드가 아닌 것을 속이기 위해 headers를 사용함
- headers
웹서버 요청을 대신 해 준다.
나 코드아니고 크롬이야~
headers = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebkit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
import requests
from bs4 import BeautifulSoup
url = "https://news.naver.com/main/list.naver?mode=LPOD&mid=sec&sid1=001&sid2=140&oid=001&isYeonhapFlash=Y"
headers = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebkit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.content, "html.parser")
soup<!DOCTYPE HTML>
<html lang="ko">
<head>
<meta charset="utf-8"/>
<meta content="IE=edge" http-equiv="X-UA-Compatible"/>
<meta contents="always" name="referrer"/>
<meta content="600" http-equiv="refresh">
<meta content="width=1106" name="viewport">
<meta content="네이버 뉴스" property="og:title"/>
<meta content="website" property="og:type"/>
<meta content="https://news.naver.com/main/list.naver?mode=LPOD&mid=sec&sid1=001&sid2=140&oid=001&isYeonhapFlash=Y" property="og:url"/>
<meta content="https://ssl.pstatic.net/static.news/image/news/ogtag/navernews_800x420_20221201.png" property="og:image">
<meta content="다양한 기사 정보를 제공합니다." property="og:description"/> 생략-
NLP: Natural Language Processing - Depp LEARNING
-
RNN(LSTN,GRU)
-
Seqseq(문장to문장, 변역, 챗봇, 요약) -> Transformer(RNN->Attention)
-
pre-trained(fine-tuning) : BERT, GPT
speech 4~6days
elastic search (elk stack in AWS)
AWS cloud(4days)
mini project(4days)
final project(6주이상)
text = """저 별을 따다가 니 귀에 걸어주고파
저 달 따다가 니 목에 걸어주고파
세상 모든 좋은 것만 해주고 싶은
이런 내 맘을 그댄 아나요"""import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
tok = Tokenizer()
tok.fit_on_texts([text])
tok.word_index{'저': 1,
'따다가': 2,
'니': 3,
'걸어주고파': 4,
'별을': 5,
'귀에': 6,
'달': 7,
'목에': 8,
'세상': 9,
'모든': 10,
'좋은': 11,
'것만': 12,
'해주고': 13,
'싶은': 14,
'이런': 15,
'내': 16,
'맘을': 17,
'그댄': 18,
'아나요': 19}vocab_size = len(tok.word_index) + 1 #1 = zero padding#단어를 숫자로 바꿈
"""저 별을 따다가 니 귀에 걸어주고파
저 달 따다가 니 목에 걸어주고파
세상 모든 좋은 것만 해주고 싶은
이런 내 맘을 그댄 아나요"""
"""
저 별을? -> 따다가
저 별을 따다가 ? -> 니
저 별을 따가가 니 귀에 ? -> 걸어주고피
"""
seq_list=[]
for sentence in text.split("\n"):
res = tok.texts_to_sequences([sentence])[0]
print(res, '/')
[1, 5, 2, 3, 6, 4] /
[1, 7, 2, 3, 8, 4] /
[9, 10, 11, 12, 13, 14] /
[15, 16, 17, 18, 19] /"""
저 별을? -> 따다가
저 별을 따다가 ? -> 니
저 별을 따가가 니 귀에 ? -> 걸어주고피
"""
#예측 , 한 단어씩 확장하면서 예측
seq_list=[]
for sentence in text.split("\n"):
res = tok.texts_to_sequences([sentence])[0]
for i in range(1, len(res)):
seq = res[:i+1]
seq_list.append(seq)
seq_list
[[1, 5],
[1, 5, 2],
[1, 5, 2, 3],
[1, 5, 2, 3, 6],
[1, 5, 2, 3, 6, 4],
[1, 7],
[1, 7, 2],
[1, 7, 2, 3],
[1, 7, 2, 3, 8],
[1, 7, 2, 3, 8, 4],
[9, 10],
[9, 10, 11],
[9, 10, 11, 12],
[9, 10, 11, 12, 13],
[9, 10, 11, 12, 13, 14],
[15, 16],
[15, 16, 17],
[15, 16, 17, 18],
[15, 16, 17, 18, 19]]max_len = max(len(sent) for sent in seq_list)
max_len6#zero padding함
seq_padded = pad_sequences(seq_list, maxlen=max_len)
seq_paddedarray([[ 0, 0, 0, 0, 1, 5],
[ 0, 0, 0, 1, 5, 2],
[ 0, 0, 1, 5, 2, 3],
[ 0, 1, 5, 2, 3, 6],
[ 1, 5, 2, 3, 6, 4],
[ 0, 0, 0, 0, 1, 7],
[ 0, 0, 0, 1, 7, 2],
[ 0, 0, 1, 7, 2, 3],
[ 0, 1, 7, 2, 3, 8],
[ 1, 7, 2, 3, 8, 4],
[ 0, 0, 0, 0, 9, 10],
[ 0, 0, 0, 9, 10, 11],
[ 0, 0, 9, 10, 11, 12],
[ 0, 9, 10, 11, 12, 13],
[ 9, 10, 11, 12, 13, 14],
[ 0, 0, 0, 0, 15, 16],
[ 0, 0, 0, 15, 16, 17],
[ 0, 0, 15, 16, 17, 18],
[ 0, 15, 16, 17, 18, 19]])X = seq_padded[:, :-1]
y = seq_padded[:, -1]
X, y(array([[ 0, 0, 0, 0, 1],
[ 0, 0, 0, 1, 5],
[ 0, 0, 1, 5, 2],
[ 0, 1, 5, 2, 3],
[ 1, 5, 2, 3, 6],
[ 0, 0, 0, 0, 1],
[ 0, 0, 0, 1, 7],
[ 0, 0, 1, 7, 2],
[ 0, 1, 7, 2, 3],
[ 1, 7, 2, 3, 8],
[ 0, 0, 0, 0, 9],
[ 0, 0, 0, 9, 10],
[ 0, 0, 9, 10, 11],
[ 0, 9, 10, 11, 12],
[ 9, 10, 11, 12, 13],
[ 0, 0, 0, 0, 15],
[ 0, 0, 0, 15, 16],
[ 0, 0, 15, 16, 17],
[ 0, 15, 16, 17, 18]]),
array([ 5, 2, 3, 6, 4, 7, 2, 3, 8, 4, 10, 11, 12, 13, 14, 16, 17,
18, 19]))y_hot = to_categorical(y, num_classes = vocab_size)
y_hotarray([[0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 1.]], dtype=float32)from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense, SimpleRNNmodel = Sequential([
Embedding(vocab_size,10),
SimpleRNN(32),
Dense(vocab_size, activation="softmax")
])
#model.summary()import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])---------------------------------------------------------------------------
NameError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_15828\2442704613.py in <module>
1 import matplotlib.pyplot as plt
----> 2 plt.plot(history.history['accuracy'])
NameError: name 'history' is not definedmodel.compile(loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=['accuracy'])
history = model.fit(X, y, epochs=200, verbose=1)Epoch 1/200
1/1 [==============================] - 1s 1s/step - loss: 2.9986 - accuracy: 0.1053
Epoch 2/200
1/1 [==============================] - 0s 4ms/step - loss: 2.9900 - accuracy: 0.1579
Epoch 3/200
1/1 [==============================] - 0s 4ms/step - loss: 2.9814 - accuracy: 0.1579
Epoch 4/200
1/1 [==============================] - 0s 4ms/step - loss: 2.9729 - accuracy: 0.1579
Epoch 5/200
1/1 [==============================] - 0s 3ms/step - loss: 2.9643 - accuracy: 0.2105생략start_text = "이런 내 맘을 그댄"
encoded = tok.texts_to_sequences([start_text])[0]
encoded[15, 16, 17, 18]#padding추가
padded = pad_sequences([encoded], maxlen=max_len)
paddedarray([[ 0, 0, 15, 16, 17, 18]])#model에 시켜보기 , 15,16,17,18하면 뭐라고 할래
res = model.predict(padded, verbose=1)
res1/1 [==============================] - 0s 223ms/step
array([[1.3786000e-03, 1.8889316e-03, 1.1288294e-03, 1.1301618e-04,
3.6843794e-05, 1.9032428e-02, 1.6038929e-03, 1.6891779e-02,
4.6042008e-03, 1.9088124e-03, 4.9405266e-03, 1.0474561e-04,
7.7498420e-03, 5.1799063e-03, 1.6398039e-03, 3.2488962e-03,
1.6680386e-02, 3.9386280e-02, 8.6205201e-03, 8.6386180e-01]],
dtype=float32)res_softmax = np.argmax(res, axis=1)
res_softmax
# array([19], dtype=int64) # array([19] 아나요array([19], dtype=int64)
시계열 알고리즘을 통해 주식 가격 예측을 할 수 있다.
삼각함수를 통해 예측할 수 있을까
# 하나의 사이클에 20개의 스텝이 있을 것이다
steps_per_cycle = 20
number_of_cycles = 176
noise_factor = 0.5
plot_num_cycles = 20
seq_len = steps_per_cycle * number_of_cycles
t = np.arange(seq_len)
sin_t_noisy = np.sin(2*np.pi/steps_per_cycle*t +
noise_factor * np.random.uniform(-1.0, 1.0, seq_len))
sin_t_clean = np.sin(2*np.pi/steps_per_cycle*t)
upto = plot_num_cycles * steps_per_cycle
fig = plt.figure(figsize=(15,4))
plt.plot(t[:upto], sin_t_noisy[:upto], label = "noisy")
plt.plot(t[:upto], sin_t_clean[:upto], label = "clean")
plt.legend()
plt.show()C:\anaconda\lib\site-packages\IPython\core\pylabtools.py:151: UserWarning: Glyph 8722 (\N{MINUS SIGN}) missing from current font.
fig.canvas.print_figure(bytes_io, **kw)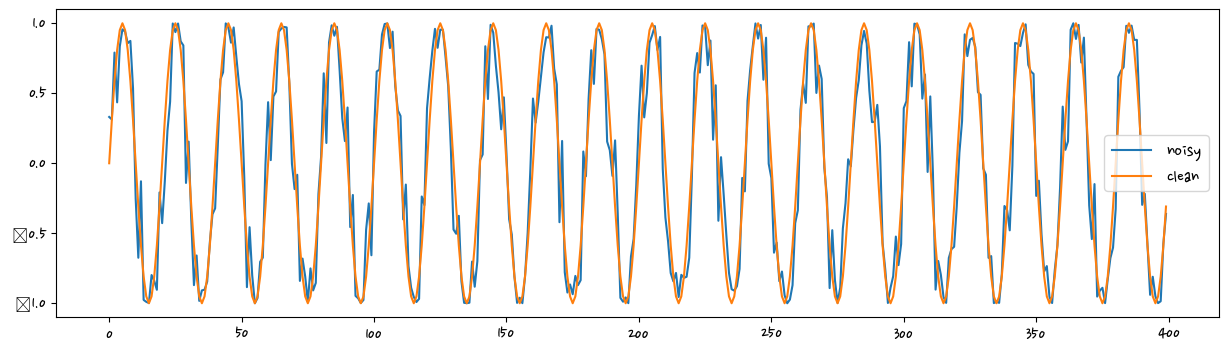
def pack_truncated_data(data, num_prev = 100):
X, y = [], []
for i in range(len(data)-num_prev):
X.append(data[i:i+num_prev])
y.append(data[i+num_prev])
X = np.array(X)[:,:,np.newaxis]
y = np.array(y)[:,np.newaxis] # np.newaxis 괄호 하나 더 적어줌 [[4]] #keras가 이런 형태를 요구함
return X, y#분류에서는 train, test는 랜덤하게 나누고 랜덤(골고루)하게 예측하는 게 좋음
#시계열에서 train은 앞의 것(옛날), test은 뒤에 것(최신)으로 하는 것이 좋다.
#시계열데이터를 어떻게 윈도윙하는가
truncated_seq_len = 10
test_split = 0.25 #테스트 비율 0.25, 트레인 비율 0.75
data = sin_t_noisy#sin_t_clean
data_len = data.shape[0]
num_train = int(data_len*(1-test_split))
train_data = data[:num_train]
test_data = data[num_train:]
X_train, y_train = pack_truncated_data(train_data,truncated_seq_len)
X_test, y_test = pack_truncated_data(test_data,truncated_seq_len)
data_len, X_train.shape, y_train.shape, X_test.shape, y_test.shape #shape확인(3520, (2630, 10, 1), (2630, 1), (870, 10, 1), (870, 1))# RNN, 지난 10개의 1번마다 데이터 1개
import tensorflow as tf
def define_model(truncated_seq_len):
input_dimension = 1
output_dimension = 1
hidden_dimension = 1
model = Sequential()
model.add(SimpleRNN(input_shape=(truncated_seq_len, input_dimension),
units= hidden_dimension,#유닛의 개수
return_sequences=False,name="hidden_layer"))
model.add(Dense(output_dimension, name="output_layer"))
my_adam=tf.keras.optimizers.Adam(learning_rate=1e-3)
model.compile(loss="mse",
optimizer=my_adam)
return modelmodel = define_model(X_train.shape[1]) #10개
model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hidden_layer (SimpleRNN) (None, 1) 3
output_layer (Dense) (None, 1) 2
=================================================================
Total params: 5
Trainable params: 5
Non-trainable params: 0
_________________________________________________________________history = model.fit(X_train, y_train, batch_size=600,
epochs = 1000, verbose = 1, validation_split = 0.05)Epoch 1/1000
5/5 [==============================] - 1s 50ms/step - loss: 0.5906 - val_loss: 0.5703
Epoch 2/1000
5/5 [==============================] - 0s 8ms/step - loss: 0.5738 - val_loss: 0.5557
Epoch 3/1000
5/5 [==============================] - 0s 9ms/step - loss: 0.5591 - val_loss: 0.5415
Epoch 4/1000
5/5 [==============================] - 0s 8ms/step - loss: 0.5455 - val_loss: 0.5285
Epoch 5/1000
5/5 [==============================] - 0s 7ms/step - loss: 0.5346 - val_loss: 0.5179
Epoch 6/1000
5/5 [==============================] - 0s 8ms/step - loss: 0.5253 - val_loss: 0.5103
Epoch 7/1000
5/5 [==============================] - 0s 7ms/step - loss: 0.5175 - val_loss: 0.5051
Epoch 8/1000
5/5 [==============================] - 0s 9ms/step - loss: 0.5118 - val_loss: 0.5012
Epoch 9/1000
5/5 [==============================] - 0s 9ms/step - loss: 0.5070 - val_loss: 0.4978
Epoch 10/1000
5/5 [==============================] - 0s 9ms/step - loss: 0.5041 - val_loss: 0.4948 생략plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.legend()
plt.show()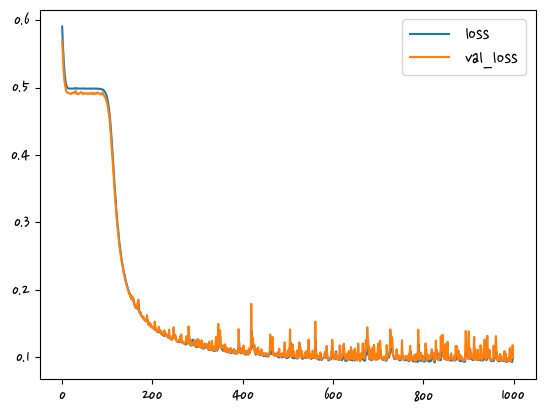
y_pred = model.predict(X_test[:100])
plt.figure(figsize=(20,4))
plt.plot(y_test[:100], label="y_real")
plt.plot(y_pred, label="y_pred")
plt.legend()
plt.show()4/4 [==============================] - 0s 3ms/step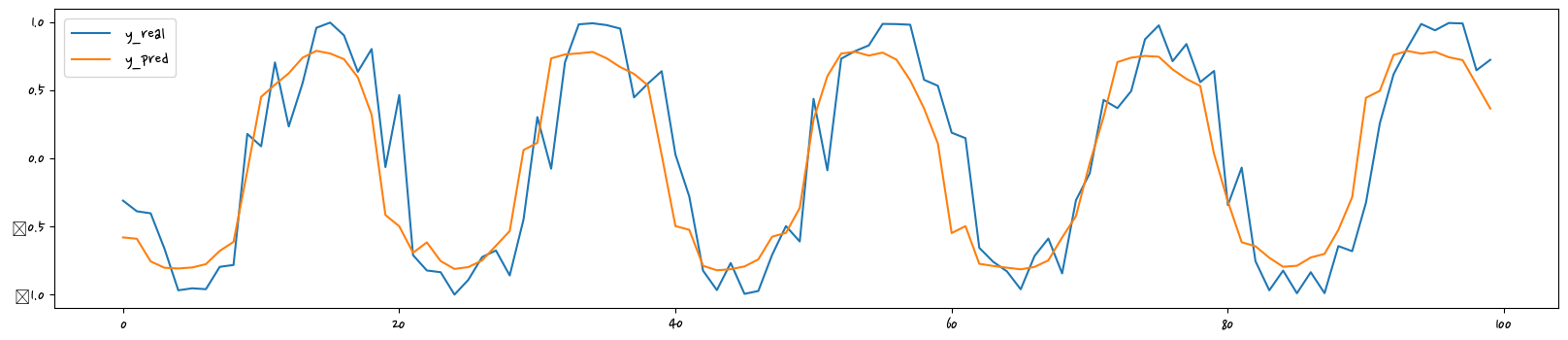
for layer in model.layers: #output_layer: dense
print(f"model name{layer.name}, layer_weight:{layer.get_weights()}")model namehidden_layer, layer_weight:[array([[-0.00111269]], dtype=float32), array([[2.0733]], dtype=float32), array([-6.4700405e-05], dtype=float32)]
model nameoutput_layer, layer_weight:[array([[0.9707168]], dtype=float32), array([0.00466661], dtype=float32)]PERCEPTRON

output은 히든 층 또는 input으로 될 수 있다.
output이 input이 들어오면 tanh에 넣고 그 것이 output으로 나간다.
RNN(Recurrent Neural Network)
시간의 흐름을 펼쳐서 표현. 유닛은 1개이지만 시간에 따라 상태가 여러개가 된다.
일반 네트워크 종류 : mlp(뇌세포따라서 만듦)-> cnn, rnn
LSTM :좀 더 긴 버전, input()으로 돌아온 것 일부는 output()으로 나가고 현재의 것과 합치기도 한다. rnn을 썼을 때 성능이 낮아졌을 때 lstm사용. 길게 가져갈 떄는 rnn
