import warnings
warnings.filterwarnings('ignore')
import pandas as pd- 데이터 내용 파악
data = pd.read_csv('202208_202208_주민등록인구및세대현황_월간.csv',encoding='cp949')
data.head(2)| 행정구역 | 2022년08월_총인구수 | 2022년08월_세대수 | 2022년08월_세대당 인구 | 2022년08월_남자 인구수 | 2022년08월_여자 인구수 | 2022년08월_남여 비율 | |
|---|---|---|---|---|---|---|---|
| 0 | 서울특별시 (1100000000) | 9,488,454 | 4,472,975 | 2.12 | 4,601,295 | 4,887,159 | 0.94 |
| 1 | 서울특별시 종로구 (1111000000) | 143,499 | 73,866 | 1.94 | 69,408 | 74,091 | 0.94 |
data.info() #object라고 들어오면 int, float으로 들어오는 데 문제가 있다.라는 뜻으로 해석할 수 있다.<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3865 entries, 0 to 3864
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 행정구역 3865 non-null object
1 2022년08월_총인구수 3865 non-null object
2 2022년08월_세대수 3865 non-null object
3 2022년08월_세대당 인구 3865 non-null float64
4 2022년08월_남자 인구수 3865 non-null object
5 2022년08월_여자 인구수 3865 non-null object
6 2022년08월_남여 비율 3865 non-null float64
dtypes: float64(2), object(5)
memory usage: 211.5+ KB#2. 컬럼 이름 수정
data.columns #컬럼 내용 확인Index(['행정구역', '2022년08월_총인구수', '2022년08월_세대수', '2022년08월_세대당 인구',
'2022년08월_남자 인구수', '2022년08월_여자 인구수', '2022년08월_남여 비율'],
dtype='object')data.columns = ['행정구역', '총인구수', '세대수', '세대당인구', '남자', '여자', '남여비율']data.columnsIndex(['행정구역', '총인구수', '세대수', '세대당인구', '남자', '여자', '남여비율'], dtype='object')# 필요없는 컬럼 제거 - 남여제거
data.drop(columns=['남여비율'],inplace=True)data.columnsIndex(['행정구역', '총인구수', '세대수', '세대당인구', '남자', '여자'], dtype='object')# 4. geojson과 연결할 키를 확인
data.head(3)| 행정구역 | 총인구수 | 세대수 | 세대당인구 | 남자 | 여자 | |
|---|---|---|---|---|---|---|
| 0 | 서울특별시 (1100000000) | 9,488,454 | 4,472,975 | 2.12 | 4,601,295 | 4,887,159 |
| 1 | 서울특별시 종로구 (1111000000) | 143,499 | 73,866 | 1.94 | 69,408 | 74,091 |
| 2 | 서울특별시 종로구 청운효자동(1111051500) | 11,766 | 5,198 | 2.26 | 5,392 | 6,374 |
데이터 정보 확인 - 대분류, 중분류 같이 있으면 안 된다. 개별 데이터만 있어야 한다.
첫 번째 줄은 서울 전체 (서울특별시)
두 번째 줄은 해당 구별 (서울특별시 종로구)
세 번쨰 줄은 해당 동별 (서울특별시 종로구 청운효자동)
-> 데이터 분리하는 작업 필요
4. geojson과 연결할 키를 확인
행정구역을 이용해서 시, 구, 동 컬럼을 만들어 준다.
개별 데이터는 남기고 대분류, 중분류에 해당하는 값을 제거해 준다.
부산 지역의 데이터만 가지고 와서 인덱스는 새로 부여한다.
data['행정구역'].str.split() #내용확인0 [서울특별시, (1100000000)]
1 [서울특별시, 종로구, (1111000000)]
2 [서울특별시, 종로구, 청운효자동(1111051500)]
3 [서울특별시, 종로구, 사직동(1111053000)]
4 [서울특별시, 종로구, 삼청동(1111054000)]
...
3860 [제주특별자치도, 서귀포시, 서홍동(5013058000)]
3861 [제주특별자치도, 서귀포시, 대륜동(5013059000)]
3862 [제주특별자치도, 서귀포시, 대천동(5013060000)]
3863 [제주특별자치도, 서귀포시, 중문동(5013061000)]
3864 [제주특별자치도, 서귀포시, 예래동(5013062000)]
Name: 행정구역, Length: 3865, dtype: objectdata['행정구역'] = data['행정구역'].str.split('(').str.get(0)
data['시'] = data['행정구역'].str.split().str.get(0)
data['구'] = data['행정구역'].str.split().str.get(1)
data['동'] = data['행정구역'].str.split().str.get(2).str.split('(').str.get(0)
#null 값이면 NaN으로 나와야 하는데 아무 것도 안 나오면 빈 문자열이 들어갔다라는 의미이다.data.head(3)| 행정구역 | 총인구수 | 세대수 | 세대당인구 | 남자 | 여자 | 시 | 구 | 동 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 서울특별시 | 9,488,454 | 4,472,975 | 2.12 | 4,601,295 | 4,887,159 | 서울특별시 | NaN | NaN |
| 1 | 서울특별시 종로구 | 143,499 | 73,866 | 1.94 | 69,408 | 74,091 | 서울특별시 | 종로구 | NaN |
| 2 | 서울특별시 종로구 청운효자동 | 11,766 | 5,198 | 2.26 | 5,392 | 6,374 | 서울특별시 | 종로구 | 청운효자동 |
#4-2. 대분류, 중분류 제거
data.dropna(inplace=True) #nan가 있는 해당 행을 제거(axis = 0), axis = 1이면 column을 제거
data.head(3)| 행정구역 | 총인구수 | 세대수 | 세대당인구 | 남자 | 여자 | 시 | 구 | 동 | |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 서울특별시 종로구 청운효자동 | 11,766 | 5,198 | 2.26 | 5,392 | 6,374 | 서울특별시 | 종로구 | 청운효자동 |
| 3 | 서울특별시 종로구 사직동 | 9,278 | 4,668 | 1.99 | 4,124 | 5,154 | 서울특별시 | 종로구 | 사직동 |
| 4 | 서울특별시 종로구 삼청동 | 2,384 | 1,188 | 2.01 | 1,130 | 1,254 | 서울특별시 | 종로구 | 삼청동 |
busan = data[data['시'] == '부산광역시']
busan| 행정구역 | 총인구수 | 세대수 | 세대당인구 | 남자 | 여자 | 시 | 구 | 동 | |
|---|---|---|---|---|---|---|---|---|---|
| 454 | 부산광역시 중구 중앙동 | 3,139 | 2,435 | 1.29 | 1,475 | 1,664 | 부산광역시 | 중구 | 중앙동 |
| 455 | 부산광역시 중구 동광동 | 2,590 | 1,703 | 1.52 | 1,323 | 1,267 | 부산광역시 | 중구 | 동광동 |
| 456 | 부산광역시 중구 대청동 | 6,185 | 3,562 | 1.74 | 2,877 | 3,308 | 부산광역시 | 중구 | 대청동 |
| 457 | 부산광역시 중구 보수동 | 10,464 | 6,029 | 1.74 | 5,052 | 5,412 | 부산광역시 | 중구 | 보수동 |
| 458 | 부산광역시 중구 부평동 | 4,430 | 2,748 | 1.61 | 2,103 | 2,327 | 부산광역시 | 중구 | 부평동 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 669 | 부산광역시 기장군 기장읍 | 52,213 | 25,757 | 2.03 | 25,411 | 26,802 | 부산광역시 | 기장군 | 기장읍 |
| 670 | 부산광역시 기장군 장안읍 | 8,453 | 4,709 | 1.80 | 4,568 | 3,885 | 부산광역시 | 기장군 | 장안읍 |
| 671 | 부산광역시 기장군 정관읍 | 81,242 | 32,042 | 2.54 | 40,196 | 41,046 | 부산광역시 | 기장군 | 정관읍 |
| 672 | 부산광역시 기장군 일광읍 | 28,012 | 11,772 | 2.38 | 13,840 | 14,172 | 부산광역시 | 기장군 | 일광읍 |
| 673 | 부산광역시 기장군 철마면 | 7,808 | 3,889 | 2.01 | 3,987 | 3,821 | 부산광역시 | 기장군 | 철마면 |
205 rows × 9 columns
busan.reset_index()| index | 행정구역 | 총인구수 | 세대수 | 세대당인구 | 남자 | 여자 | 시 | 구 | 동 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 454 | 부산광역시 중구 중앙동 | 3,139 | 2,435 | 1.29 | 1,475 | 1,664 | 부산광역시 | 중구 | 중앙동 |
| 1 | 455 | 부산광역시 중구 동광동 | 2,590 | 1,703 | 1.52 | 1,323 | 1,267 | 부산광역시 | 중구 | 동광동 |
| 2 | 456 | 부산광역시 중구 대청동 | 6,185 | 3,562 | 1.74 | 2,877 | 3,308 | 부산광역시 | 중구 | 대청동 |
| 3 | 457 | 부산광역시 중구 보수동 | 10,464 | 6,029 | 1.74 | 5,052 | 5,412 | 부산광역시 | 중구 | 보수동 |
| 4 | 458 | 부산광역시 중구 부평동 | 4,430 | 2,748 | 1.61 | 2,103 | 2,327 | 부산광역시 | 중구 | 부평동 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 200 | 669 | 부산광역시 기장군 기장읍 | 52,213 | 25,757 | 2.03 | 25,411 | 26,802 | 부산광역시 | 기장군 | 기장읍 |
| 201 | 670 | 부산광역시 기장군 장안읍 | 8,453 | 4,709 | 1.80 | 4,568 | 3,885 | 부산광역시 | 기장군 | 장안읍 |
| 202 | 671 | 부산광역시 기장군 정관읍 | 81,242 | 32,042 | 2.54 | 40,196 | 41,046 | 부산광역시 | 기장군 | 정관읍 |
| 203 | 672 | 부산광역시 기장군 일광읍 | 28,012 | 11,772 | 2.38 | 13,840 | 14,172 | 부산광역시 | 기장군 | 일광읍 |
| 204 | 673 | 부산광역시 기장군 철마면 | 7,808 | 3,889 | 2.01 | 3,987 | 3,821 | 부산광역시 | 기장군 | 철마면 |
205 rows × 10 columns
busan.reset_index(drop=True, inplace=True) #index 컬럼 제거
busan.head(2)| 행정구역 | 총인구수 | 세대수 | 세대당인구 | 남자 | 여자 | 시 | 구 | 동 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 부산광역시 중구 중앙동 | 3,139 | 2,435 | 1.29 | 1,475 | 1,664 | 부산광역시 | 중구 | 중앙동 |
| 1 | 부산광역시 중구 동광동 | 2,590 | 1,703 | 1.52 | 1,323 | 1,267 | 부산광역시 | 중구 | 동광동 |
숫자형으로 바꾸기
5. 총인구수, 남자, 여자 컬럼의 데이터 타입을 정수형으로 변경
data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 3584 entries, 2 to 3864
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 행정구역 3584 non-null object
1 총인구수 3584 non-null object
2 세대수 3584 non-null object
3 세대당인구 3584 non-null float64
4 남자 3584 non-null object
5 여자 3584 non-null object
6 시 3584 non-null object
7 구 3584 non-null object
8 동 3584 non-null object
dtypes: float64(1), object(8)
memory usage: 280.0+ KB#busan['총인구수'].astype('int') #.는 숫자로 인식하지만 ,는 숫자로 인식 하지 않아서 오류남 -> ,제거해야 함
busan['총인구수'] = busan['총인구수'].str.replace(',','').astype('int')
busan['남자'] = busan['남자'].str.replace(',','').astype('int')
busan['여자'] = busan['여자'].str.replace(',','').astype('int')
#nan값으로 대체하는 것은 원본 값을 지워버려서 원본을 지워도 괜찮을 때 사용busan.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 205 entries, 0 to 204
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 행정구역 205 non-null object
1 총인구수 205 non-null int32
2 세대수 205 non-null object
3 세대당인구 205 non-null float64
4 남자 205 non-null int32
5 여자 205 non-null int32
6 시 205 non-null object
7 구 205 non-null object
8 동 205 non-null object
dtypes: float64(1), int32(3), object(5)
memory usage: 12.1+ KB#동별, 구별 부산 인구를 차트로 표시(인구순으로 5개 항목만 출력) #seaborn사용할 때 index가 있으면 불편해서 reset시킴
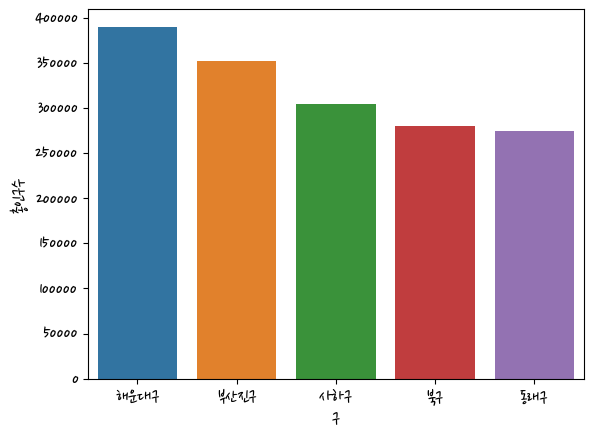
gu = busan.groupby(['구'])['총인구수'].sum().sort_values(ascending=False).head().reset_index()import seaborn as sns
sns.barplot(data=gu,x='구',y='총인구수')<AxesSubplot:xlabel='구', ylabel='총인구수'>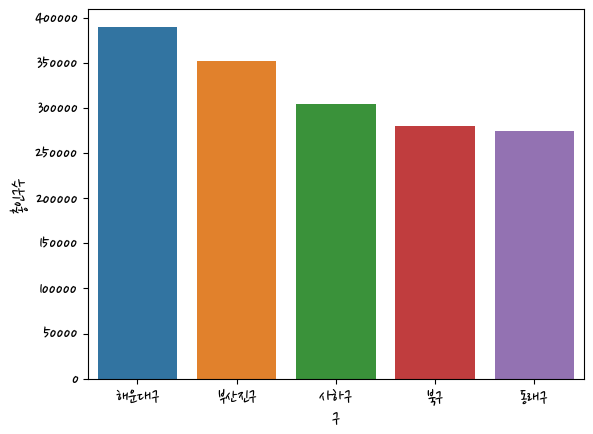
dong = busan.sort_values(by='총인구수',ascending=False).head(5)
sns.barplot(data=dong,x='동',y='총인구수')<AxesSubplot:xlabel='동', ylabel='총인구수'>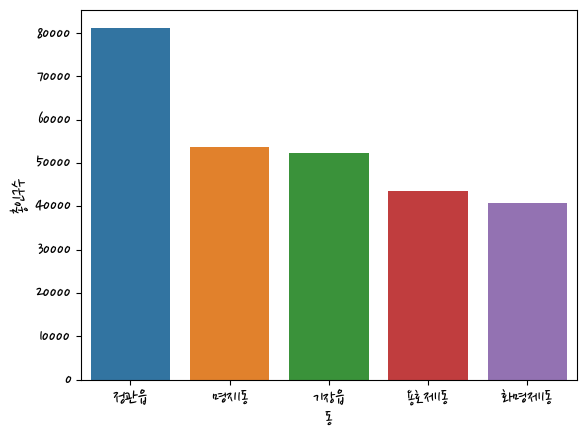
json파일 정리
파이썬에서는 리스트가 딕셔너리이다.
json의 역할은 파이썬에서 사용할 수 있는 형태로 바꿔줌 (리스트, 딕셔너리) -> index, key값으로 사용 가능
import json
jsonfile = open('HangJeongDong_ver20220701.geojson','r',encoding='utf8').read()
jsonfile #시작이 { 면 문자열이라는 뜻
type(jsonfile)strjsondata = json.loads(jsonfile)
type(jsondata)dictjson_busan = {"type" : "FeatureCollection"} #기본틀
json_pick = [] #확인하는 용도
json_dong = []
#리스트안에 딕셔너리값
for item in jsondata['features']:
#print(item['properties']['sidonm'])
if item['properties']['sidonm'] == '부산광역시':
#print(item['properties']['sidonm'])
dong = item['properties']['adm_nm'].split()[-1].strip() #딕셔너리라서 .str 안 붙힘, strip() = 공백제거
item['id'] = dong
json_pick.append(item) #id값이 없어서 연결이 안 된다.
json_dong.append(dong)
json_busan['features']=json_pick
id값이 있어야 한다.
#dong정보를 id값으로 넣어놔서 데이터프레임에 id값을 확인해야 한다?
import folium
loc = [35.1795543,129.0756416]
m = folium.Map(loc,zoom_start=11)
folium.Choropleth(geo_data=json_busan,data=busan,columns=['동','총인구수'],key_on='feature.id').add_to(m)
mfor i, item in enumerate(zip(df_dong,json_dong)): #enumerate() = index를 같이 return해준다.
print(i, item) json_busan = {"type" : "FeaureCollection"} #기본틀
json_pick = [] #확인하는 용도
json_dong = []
#리스트안에 딕셔너리값
for item in jsondata['features']:
#print(item['properties']['sidonm'])
if item['properties']['sidonm'] == '부산광역시':
#print(item['properties']['sidonm'])
dong = item['properties']['adm_nm'].split()[-1].strip()
if dong == '가야제1동':
dong = '가야1동'
item['id'] = dong
json_pick.append(item)
json_dong.append(dong)
json_busan['features']=json_pickjson_dong = sorted(json_dong)
df_dong = sorted(busan['동'])
for i, item in enumerate(zip(df_dong,json_dong)):
print(i, item)busan['동'] = busan['동'].str.replace('제','').to_list() #to_list() = 리스트로 보여줘라busan['동'].replace(['거1동','거2동','거3동','거4동'],['거제1동','거제2동','거제3동','거제4동']) #str.replace() - 부분일치, .replace() - 전체일치 0 중앙동
1 동광동
2 대청동
3 보수동
4 부평동
...
200 기장읍
201 장안읍
202 정관읍
203 일광읍
204 철마면
Name: 동, Length: 205, dtype: objectjson_dong = sorted(json_dong)
df_dong = sorted(busan['동'])
for i, item in enumerate(zip(df_dong,json_dong)):
print(i, item)json_busan = {"type" : "FeatureCollection"} #기본틀
json_pick = [] #확인하는 용도
json_dong = []
#리스트안에 딕셔너리값
for item in jsondata['features']:
#print(item['properties']['sidonm'])
if item['properties']['sidonm'] == '부산광역시':
#print(item['properties']['sidonm'])
dong = item['properties']['adm_nm'].split()[-1].strip() #딕셔너리라서 .str 안 붙힘, strip() = 공백제거
if dong == '가야제1동':
dong = '가야1동'
item['id'] = dong
json_pick.append(item) #id값이 없어서 연결이 안 된다.
json_dong.append(dong)
json_busan['features']=json_pick
loc = [35.1795543,129.0756416]
m = folium.Map(loc,zoom_start=11)
folium.Choropleth(geo_data=json_busan,
data=busan,
columns=['동','총인구수'],
fill_color='OrRd',
fill_opacity=0.8,
key_on='feature.id').add_to(m)
m
DL 공부중