새싹 인공지능 응용sw 개발자 양성 교육 프로그램 김기희 강사님 수업 정리 글입니다.
목차
1. sub query(서브쿼리)
2. view
3. transaction(트랜젝션)
4. 데이터베이스 모델링
1. sub query(서브쿼리)
서브 쿼리는 하나의 쿼리 구문 내에서 또 다른 쿼리를 사용하는 구문을 말한다. 이때 쿼리 문 내에 포함된 쿼리 문을 서브 쿼리라고 한다. 쿼리 안에 쿼리가 존재하는 것을 서브쿼리다
보통 join이랑 같이 쓰임. 제일 많이 사용하고 제일 어려움
=물리스키마 → db에 적용하면 바로 table생성된다.
첫 번째 규칙. () 묶어줘야 한다
두 번째 규칙. alias를 해야 한다.
select 절에서의 서브 쿼리
select를 column으로 넣겠다
→ 분류별 제품 수 , part_id 별 레코드 수, 분류별 제품 수
select part_id, part_name from part;
= part테이블로부터 part_id와 part_name을 가져옴
select part_id, part_name,
(select part_id, count(*) from product
group by part_id having part_id = part_id)
from part;
→ 오류나서
→ having part_id = part.part_id)로 바꿈
select part_id, part_name,
(select product_name from product
where part_id = part.part_id limit 1) product_name
from part;
-> 하나만 출력가능 해야 한다. → limit 1써줘야 함
- 전제조권
- 하나만 출력 가능해야 한다.
- alias 필수가 아니다. 하지만 안 하면 지저분해서 써주는 것이 좋음.
→ 특정조건에서만 사용하기(사실 웬만하면 안 쓰는 것이 좋음)
part의 record마다 서브 쿼리가 실행된다는 것이다.
from 절에서의 서브 쿼리
꼭 alias를 해야 한다.
select part.part_tag, 'sub'part_name
from
(select * from part) sub
part 와 sub 때문에 alias를 해야 한다.?
예제1) 가장 비싼 제품을 출력해라
select * from product
where
product_price =
(select max(product_price) from product)
- 단 조건이 있다.
- 하나의 column 또는 record가 출력되는 sql문
- in (a, b, c)
서브 쿼리를 실행했을 때 결과는 여러개가 나오면 안 된다. 컬럼 또는 레코드가 여러개면 비교연산이 불가하다. 연산자에 따라서 반드시 하나의 컬럼 또는 레코드가 출력되는 sql문이거나
여러개의 레코드가 오는 select문이 올 수 있다 =
select product_name from product where product_name like '%프레즐';
또는 in (a, b, c)
예제2) 평균가 이상의 제품목록을 출력하세요
select * from product
where product_price <=
(select max(product_price) from product );
- 중첩된 서브쿼리
select * from prodcut where product_price =
(select max(product_price) from prodcut
where
product_price < (select max(product_price) from product))
서브쿼리 간에 조인, 서브쿼리와 테이블과 조인 가능할 수 있음
하나의 테이블에서 통계내는 방법 = sum
select * from order; order = 예약어
select * from order ;
select ordered_date, sum(pay_price)
from order group by ordered_date;
- WHERE
- SUM , GROUP
→ pay result
select * from order ;
select ordered_date, pay_result, sum(pay_price)
from order where pay_result = 'y'group by ordered_date;
=
select * from order ;
select ordered_date, pay_result, sum(pay_price)
from order group by ordered_date, pay_result
having pay_result = 'y';
다른 table과 join, 서브쿼리 이용
두 테이블간의 관계가 orerid로 관계가 되어 있다.
- 우선 join
select * from order inner join orderlist using (order_id)
→ 이것을 하나의 테이블로 보기
- 서브쿼리 이용
select ordered_date, pay_result, sum(pay_price)
from
(select * from order inner join orderlist using (order_id)) as sub
group by ordered_date, pay_result
having pay_result = 'y'
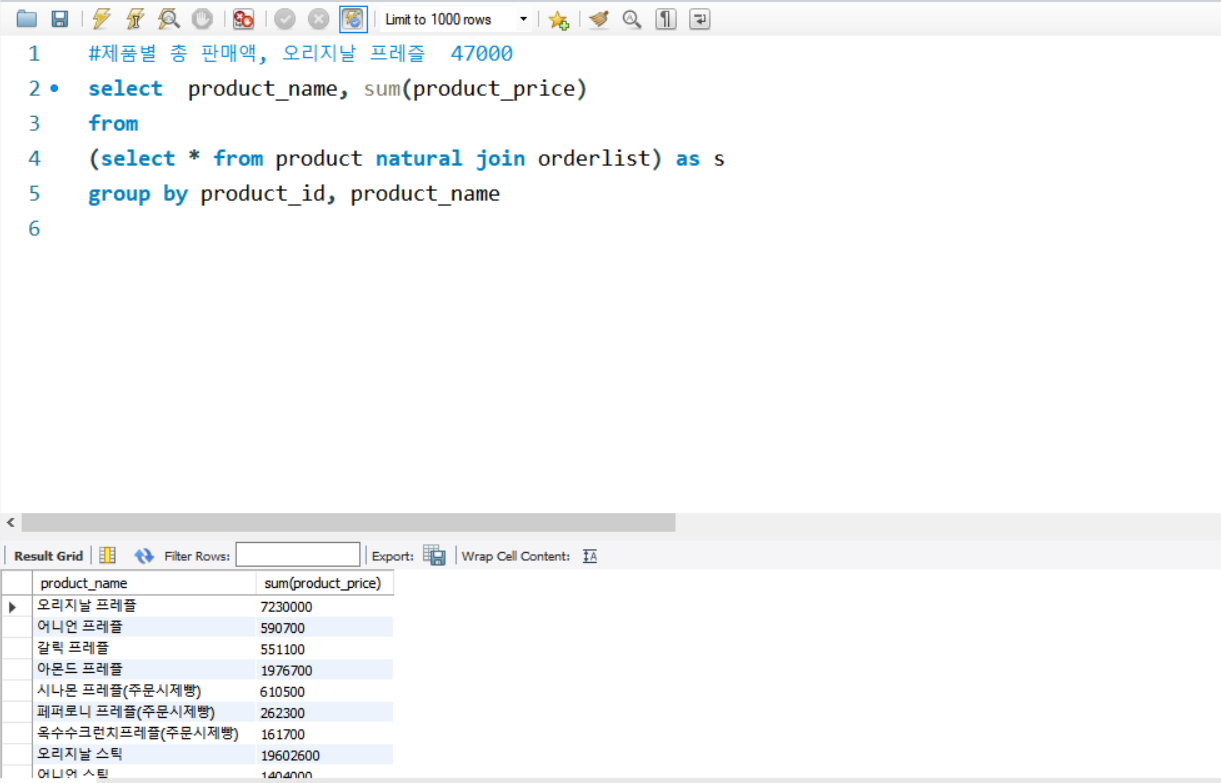
예제3)제품별 총 판매액
- select * from product natural join orderlist
개별 컬럼은 혼자서 쓸 수 없어서 grop by 필요
꼭 개별 컬럼은 그룹핑할 필요는 없다. select 절에 없는 것으로 그룹핑가능하다. → product_id 생략가능
select product_id , product_name, sum(product_price)
from
(select * from product natural join orderlist) as s
group by product_id, product_name
2.VIEW
VIEW= TABLE
TABLE은 실제 데이터 저장
VIEW는 실제 테이블이 아닌 SELECT문을 이용해서 실행하게 되면 화면에 결과출력한 가상테이블을 그대로 테이블구조로 만든 것을 VIEW 라고한다.
VIEW = 창, 마치 하나의 table처럼 결과를 보여준다.
사용할 때 주의점: 실제 정보가 저장되는 table이 아닌 select문을 통해 만들어진 가상테이블,
view는 select 전용이다.
table 삭제는 drop
view 삭제는 drop
통계나 복잡한 코드를 생성할 때는 view를 생성하라.
insert into select 구문을 이용한 데이터의 입력
create table auth_copy as select * from auth
-> select의 결과를 table로 만들어라
view 는 실시간을 table로부터 정보를 끌어온다.
table은 고유한 데이터라 안 바뀜
create table auth2 as
select * from auth where auth_id = 0
-> 구조만 복사, 제약은 안 가져옴
as뒤의 select문을 수행해서 성공하면 select에 명시한 column을 동일한 자료형으로 만든다. select된 데이터들을 insert한다.
외부파일로 내보낼 때
select * into outfile 'C:\Temp\data.txt' from auth
-> mysql은 보안상 막아둠, mariadb는 가능
3. transaction(트랜젝션)
일련의 절차를 가지는 작업의 단위
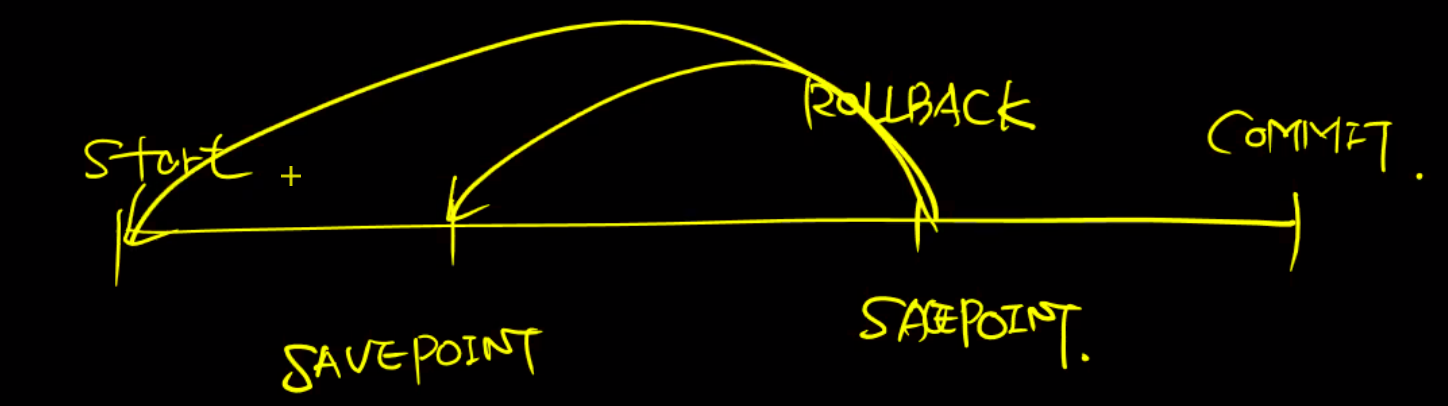
savepoint를 만드는 것은 취소를 할 때 포인트까지만 취소할 수 있다.
예) tera term 이용
mysql> start transaction;
-> 트랜젝션 시작
commit;
-> 커밋을 하면 새로운 트랜젝션 시작
mysql 에서 innodb 엔진을 사용하여 테이블 에서 트랜젝션을 시작하면 로그장치를 이용.
사용자가 명령을 실행하면, 실행의 로그를 기록하게 된다. 결과를 출력하게 되면 실제 테이블의 테이블의 결과를 출력하는 것이 아닌 로그의 반영된 결과를 보여준다. 즉 실제 테이블에 저장이 안 됬었다는 말. 작업을 하면 또 기록한다. 또 결과를 출력해라 하면 실제 테이블을 출력하는 것이 아닌 로그를 반영하는 결과를 보여준다.
commit을 하면 로그기록을 하면 실제 테이블에 반영한다.
autocommit을 하면 바로 테이블에 반영해서 트랜젝션을 사용할 수 없다.
한 사용자가 트랜젝션을 시작해서 데이터를 변경하게 되면 commit을 하기 전까지는 이전데이터가 보인다.
commit을 안 해도 바뀐 값을 볼 수 있게금 최종적으로는 일치가 되어야 한다. -> 더티체크(dirty checking)
부모와 자식이 관계를 형성하면 서로 영향을 미친다.
자식은 입력받을 때 영향을 받는다. insert은 부모만 제약, update는 둘다 제약, delete는 부모만 제약
테이블(스키마)를 만들 때 부모와 자식간에 테이블을 만들 때. 자식의 외래키와 cascade를 넣게 되면 트랜젝션이 필요없다. 너무 위험해서 트리거 안된다 . 부모지우려면 부모를 참조하는 자식테이블의 정보를 다 지우고 그 다음에 부모를 제워야 한다. 자식이 삭제되고 부모가 삭제되는 것을 적용된다. 삭제를 못 시키면 rollback을 해야하고 이 때 트랜젝션이 필요하다. 제약이라는 것은 관계설정 할 떄 트리거를 어떻게 설정하냐에 따라 다르다. 트리거를 삭제 못 시키면 트랜젝션이 필요하다.
입력할 때도 트랜젝션 필요할 수도 있다.
예제4) 소설로 분류되는 늑대와 춤을 2만원으로 바꾸시오
- natural join
mysql> UPDATE category natural join book set book.b_price = 20000 where c_name = '소설' and b_name = '늑대와 춤을 ';
Query OK, 1 row affected (0.03 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from book where b_name like '늑대와 춤을';
+--------+------------------+---------+--------+
| b_code | b_name | b_price | c_code |
+--------+------------------+---------+--------+
| FT0001 | 늑대와 춤을 | 20000 | FT |
+--------+------------------+---------+--------+
1 row in set (0.00 sec)
-
set join
mysql> update category A, book B set b_price = 15000
-> where A.c_code = B.c_code and A.c_name = '소설'
-> and B.b_name = '늑대와 춤을 ';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0 -
inner join
mysql> UPDATE category inner join book using(c_code) set book.b_price = 20
000 where b_name='늑대와 춤을 '; -
삭제트리거
on delete cascade on update cascade
= 외래키도 같이 삭제 하겠다
- truncate 구문에 의한 삭제
table 데이터를 삭제
쓰지않은 존재 유무까지만 알아두기
delete 는 대상 table을 선택적으로 삭제
truncate는 table자체를 삭제하고 다시 만듦
- delete문에서의 join
sql)0
delete table_name(실제로 삭제할 레코드를 포함하는 테이블
from table_references(join할 구문)
where
ex)
delete book from category natural join book where category.c_name ='소설' and book.b_name = '늑대와 춤을 ';
4. 데이터베이스 모델링
업무분석 -> 개념적 데이터베이스 모델링
도메인 = 값의 범위
선택성 = 의무
차수 = 일대일, 일대다
논리적 데이터베이스 모델링
- 논리적 데이터베이스 모델링의 단계
- 맵핑 규칙을 이용한 관계형 데이터 모델로의 변환
- 정규화 과정
-> 논리스키마를 만든다 = 테이블은 뭘 쓸 것이고, 제약사항을 뭘 줄 것인지
물리적 데이터베이스 모델링
업무분석 -> 개념설계 -> 논리스키마 -> 물리스키마
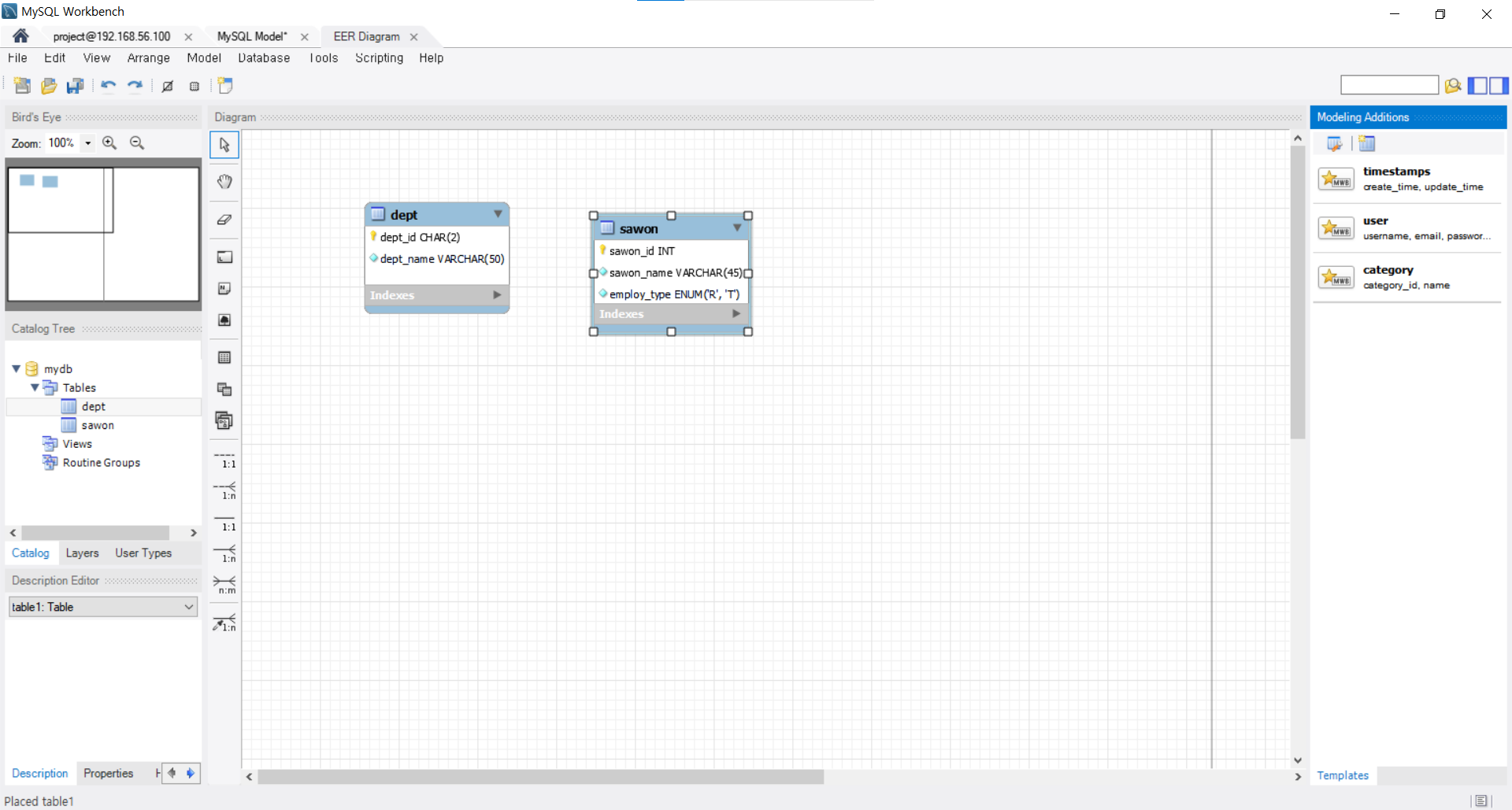
-> table생성
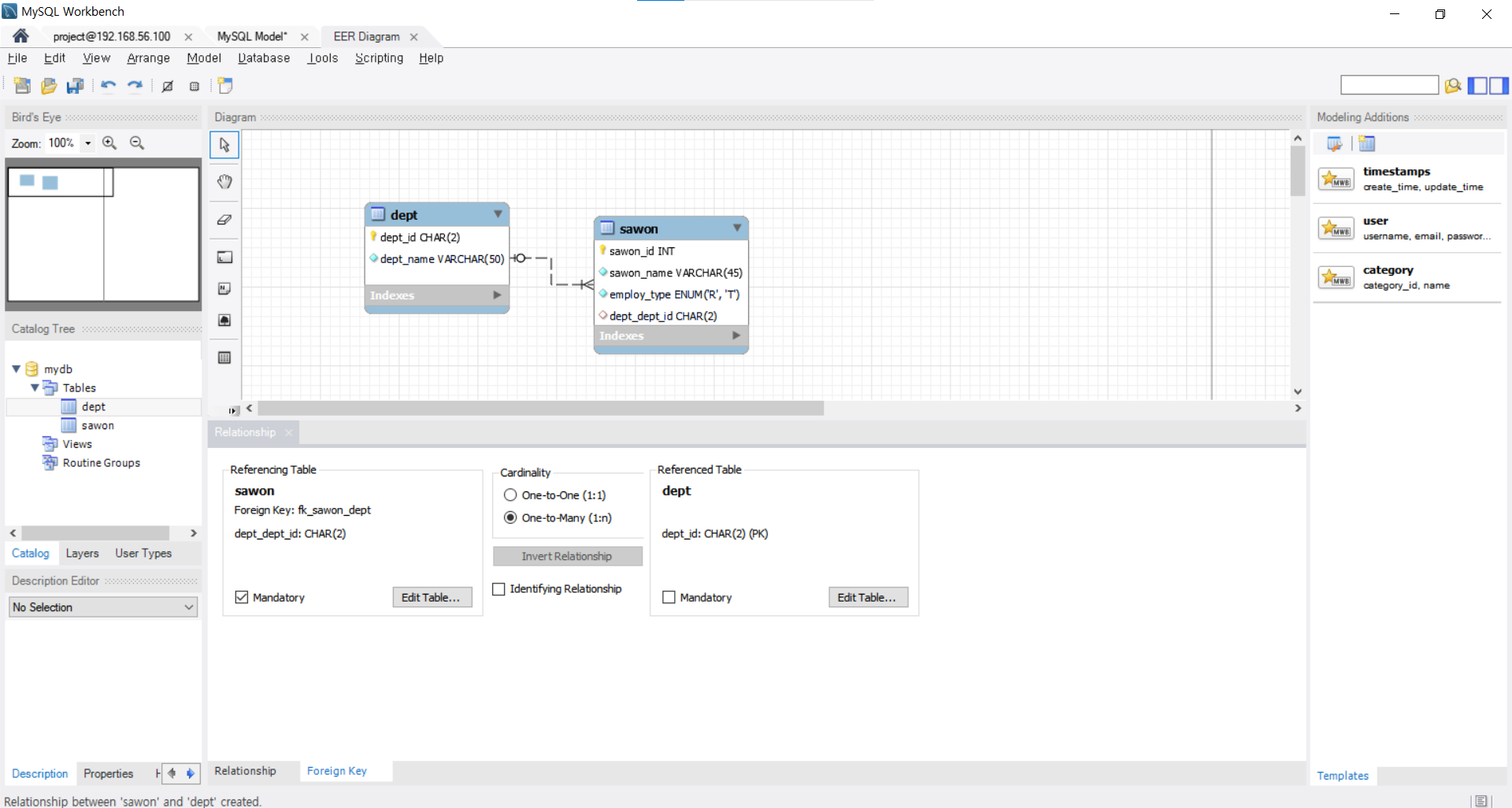
-> 관계설정
