새싹 인공지능 응용sw 개발자 양성 교육 프로그램 심선조 강사님 수업 정리 글입니다.
import pandas as pd
import matplotlib.pyplot as pltpd.read_csv('05_machine_learning/human/human_activity/features.txt',
sep='\s+', header=None,
names=['column_index', 'column_name'])
# ParserError : read_csv 구분자가 , 가 아니면 다른 에러가 뜸
# pd.read_csv('human_activity/features.txt', sep='\s+')| column_index | column_name | |
|---|---|---|
| 0 | 1 | tBodyAcc-mean()-X |
| 1 | 2 | tBodyAcc-mean()-Y |
| 2 | 3 | tBodyAcc-mean()-Z |
| 3 | 4 | tBodyAcc-std()-X |
| 4 | 5 | tBodyAcc-std()-Y |
| ... | ... | ... |
| 556 | 557 | angle(tBodyGyroMean,gravityMean) |
| 557 | 558 | angle(tBodyGyroJerkMean,gravityMean) |
| 558 | 559 | angle(X,gravityMean) |
| 559 | 560 | angle(Y,gravityMean) |
| 560 | 561 | angle(Z,gravityMean) |
561 rows × 2 columns
feature_name_df = pd.read_csv('05_machine_learning/human/human_activity/features.txt',
sep='\s+', header=None,
names=['column_index', 'column_name'])feature_name = feature_name_df.iloc[:, 1].values.tolist()
# values : ndarray로 나오게 되어있음feature_name[:10]['tBodyAcc-mean()-X',
'tBodyAcc-mean()-Y',
'tBodyAcc-mean()-Z',
'tBodyAcc-std()-X',
'tBodyAcc-std()-Y',
'tBodyAcc-std()-Z',
'tBodyAcc-mad()-X',
'tBodyAcc-mad()-Y',
'tBodyAcc-mad()-Z',
'tBodyAcc-max()-X']feature_dup_df = feature_name_df.groupby('column_name').count()
feature_dup_df.head(2)| column_index | |
|---|---|
| column_name | |
| angle(X,gravityMean) | 1 |
| angle(Y,gravityMean) | 1 |
feature_dup_df[feature_dup_df['column_index']>1].count()column_index 42
dtype: int64def get_new_df(old_df):
dup_df = pd.DataFrame(data=old_df.groupby('column_name').cumcount(), columns=['dup_cnt'])
dup_df = dup_df.reset_index()
new_df = pd.merge(old_df.reset_index(), dup_df, how='outer')
new_df['column_name'] = new_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1]) if x[1]>0 else x[0], axis = 1)
# if x[1]>0 이면 람다식 진행하고, else x[0]이면 x[0]을 출력하라!
new_df.drop(columns=['index'], inplace=True)
return new_df
# 컬럼 이름이 중복되면 데이터프레임을 못 만듦df = get_new_df(feature_name_df)
df.head(2)| column_index | column_name | dup_cnt | |
|---|---|---|---|
| 0 | 1 | tBodyAcc-mean()-X | 0 |
| 1 | 2 | tBodyAcc-mean()-Y | 0 |
df[df['dup_cnt']>0]| column_index | column_name | dup_cnt | |
|---|---|---|---|
| 316 | 317 | fBodyAcc-bandsEnergy()-1,8_1 | 1 |
| 317 | 318 | fBodyAcc-bandsEnergy()-9,16_1 | 1 |
| 318 | 319 | fBodyAcc-bandsEnergy()-17,24_1 | 1 |
| 319 | 320 | fBodyAcc-bandsEnergy()-25,32_1 | 1 |
| 320 | 321 | fBodyAcc-bandsEnergy()-33,40_1 | 1 |
| ... | ... | ... | ... |
| 497 | 498 | fBodyGyro-bandsEnergy()-17,32_2 | 2 |
| 498 | 499 | fBodyGyro-bandsEnergy()-33,48_2 | 2 |
| 499 | 500 | fBodyGyro-bandsEnergy()-49,64_2 | 2 |
| 500 | 501 | fBodyGyro-bandsEnergy()-1,24_2 | 2 |
| 501 | 502 | fBodyGyro-bandsEnergy()-25,48_2 | 2 |
84 rows × 3 columns
def get_human_dataset():
feature_name_df = pd.read_csv('05_machine_learning/human/human_activity/features.txt',
sep='\s+', header=None,
names=['column_index', 'column_name'])
name_df = get_new_df(feature_name_df)
feature_name = name_df.iloc[:, 1].values.tolist()
X_train = pd.read_csv('05_machine_learning/human/human_activity/train/X_train.txt', sep='\s+', names=feature_name)
X_test = pd.read_csv('05_machine_learning/human/human_activity/test/X_test.txt', sep='\s+', names=feature_name)
y_train = pd.read_csv('05_machine_learning/human/human_activity/train/y_train.txt', sep='\s+', names=['action'])
y_test = pd.read_csv('05_machine_learning/human/human_activity/test/y_test.txt', sep='\s+', names=['action'])
return X_train, X_test, y_train, y_testX_train, X_test, y_train, y_test = get_human_dataset()X_train.head(2)| tBodyAcc-mean()-X | tBodyAcc-mean()-Y | tBodyAcc-mean()-Z | tBodyAcc-std()-X | tBodyAcc-std()-Y | tBodyAcc-std()-Z | tBodyAcc-mad()-X | tBodyAcc-mad()-Y | tBodyAcc-mad()-Z | tBodyAcc-max()-X | ... | fBodyBodyGyroJerkMag-meanFreq() | fBodyBodyGyroJerkMag-skewness() | fBodyBodyGyroJerkMag-kurtosis() | angle(tBodyAccMean,gravity) | angle(tBodyAccJerkMean),gravityMean) | angle(tBodyGyroMean,gravityMean) | angle(tBodyGyroJerkMean,gravityMean) | angle(X,gravityMean) | angle(Y,gravityMean) | angle(Z,gravityMean) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.288585 | -0.020294 | -0.132905 | -0.995279 | -0.983111 | -0.913526 | -0.995112 | -0.983185 | -0.923527 | -0.934724 | ... | -0.074323 | -0.298676 | -0.710304 | -0.112754 | 0.030400 | -0.464761 | -0.018446 | -0.841247 | 0.179941 | -0.058627 |
| 1 | 0.278419 | -0.016411 | -0.123520 | -0.998245 | -0.975300 | -0.960322 | -0.998807 | -0.974914 | -0.957686 | -0.943068 | ... | 0.158075 | -0.595051 | -0.861499 | 0.053477 | -0.007435 | -0.732626 | 0.703511 | -0.844788 | 0.180289 | -0.054317 |
2 rows × 561 columns
X_train.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7352 entries, 0 to 7351
Columns: 561 entries, tBodyAcc-mean()-X to angle(Z,gravityMean)
dtypes: float64(561)
memory usage: 31.5 MBy_train['action'].value_counts()6 1407
5 1374
4 1286
1 1226
2 1073
3 986
Name: action, dtype: int64from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_scoredt_clf = DecisionTreeClassifier(random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy_score(y_test, pred)0.8547675602307431dt_clf.get_params()
# 어떤 파라미터를 돌렸는지 알 수 있음
# 여기서 튜닝해서 성능을 높여볼 수 있음{'ccp_alpha': 0.0,
'class_weight': None,
'criterion': 'gini',
'max_depth': None,
'max_features': None,
'max_leaf_nodes': None,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'random_state': 156,
'splitter': 'best'}from sklearn.model_selection import GridSearchCV%%time # 시간을 알려주는 것
params = {
'max_depth': [6, 8, 10, 12, 16, 20, 24],
'min_samples_split': [16],
}
# 하나의 값 범위에 대해서 차례차례 진행하면 됨
grid_cv = GridSearchCV(dt_clf, params, scoring = 'accuracy', cv = 5, verbose = 1)
# verbose : 돌아가면서 로그 내용이 찍히는지 안 찍히는지 나오게 하는 것
# verbose = 0이면 아무것도 안 찍힘
grid_cv.fit(X_train, y_train)UsageError: Can't use statement directly after '%%time'!grid_cv.best_score_
# 가장 좋은 점수0.8548794147162603grid_cv.best_params_{'max_depth': 8, 'min_samples_split': 16}# 제일 좋았던 파라미터 다시 학습함 best_estimator
# cv_results : 결과값이 다 저장됨
cv_result = pd.DataFrame(grid_cv.cv_results_)cv_result[['param_max_depth', 'mean_test_score']]
# max_depth가 8인 경우만 제일 잘 나옴| param_max_depth | mean_test_score | |
|---|---|---|
| 0 | 8 | 0.852023 |
| 1 | 8 | 0.852566 |
| 2 | 8 | 0.854879 |
| 3 | 8 | 0.852567 |
| 4 | 8 | 0.851342 |
%%time
params = {
'max_depth': [8, 12, 16, 20],
'min_samples_split': [16, 24]
}
grid_cv = GridSearchCV(dt_clf, params, scoring = 'accuracy', cv = 5, verbose = 1)
grid_cv.fit(X_train, y_train)Fitting 5 folds for each of 8 candidates, totalling 40 fits
Wall time: 2min
GridSearchCV(cv=5, estimator=DecisionTreeClassifier(random_state=156),
param_grid={'max_depth': [8, 12, 16, 20],
'min_samples_split': [16, 24]},
scoring='accuracy', verbose=1)grid_cv.best_params_{'max_depth': 8, 'min_samples_split': 16}grid_cv.best_score_0.8548794147162603%%time
params = {
'max_depth': [8],
'min_samples_split': [8, 12, 16, 20, 24]
}
grid_cv = GridSearchCV(dt_clf, params, scoring = 'accuracy', cv = 5, verbose = 1)
grid_cv.fit(X_train, y_train)Fitting 5 folds for each of 5 candidates, totalling 25 fits
Wall time: 1min
GridSearchCV(cv=5, estimator=DecisionTreeClassifier(random_state=156),
param_grid={'max_depth': [8],
'min_samples_split': [8, 12, 16, 20, 24]},
scoring='accuracy', verbose=1)grid_cv.best_params_{'max_depth': 8, 'min_samples_split': 16}grid_cv.best_score_0.8548794147162603pred = grid_cv.best_estimator_.predict(X_test)
accuracy_score(y_test, pred)
# 예측 정확도 확인! 테스트 데이터로 하면 교차검증에서 높게 나올수도 낮게 나올수도 있음!0.8717339667458432grid_cv.best_estimator_.feature_importances_array([0. , 0. , 0. , 0. , 0.00175182,
0. , 0. , 0. , 0. , 0.00217984,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.00034009, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0.00997154, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.00122902,
0.00629033, 0. , 0.2533544 , 0.002077 , 0.00291231,
0. , 0. , 0.02047009, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0.0024461 , 0. , 0. ,
0. , 0.00302454, 0. , 0. , 0.10188539,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.00124463,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.0011924 , 0. , 0. , 0. ,
0. , 0. , 0.00065083, 0. , 0. ,
0. , 0.00034211, 0. , 0. , 0. ,
0. , 0. , 0.00396674, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.00854963,
0. , 0. , 0.00437287, 0. , 0. ,
0. , 0. , 0. , 0. , 0.00264146,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.0005292 ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0.00233647, 0. , 0.01651344,
0. , 0. , 0. , 0. , 0. ,
0. , 0.00033559, 0. , 0. , 0.0034711 ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.00124472, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.0003379 , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0.01574123, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.00041491, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0.00882456, 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0.00233064, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.00066434, 0. ,
0. , 0. , 0. , 0. , 0.21258352,
0. , 0. , 0. , 0.00145481, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.00142006,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.00220174, 0. ,
0.00118853, 0. , 0. , 0. , 0. ,
0.0017426 , 0. , 0. , 0. , 0. ,
0. , 0. , 0.00524676, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.00283466, 0. ,
0. , 0. , 0. , 0.02397088, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.00259031, 0. ,
0. , 0. , 0. , 0.11547846, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.00138302, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.00129082, 0. , 0.00098939, 0.1390006 ,
0.00298663])data = pd.Series(grid_cv.best_estimator_.feature_importances_, index=X_train.columns)top10 = data.sort_values(ascending=False)[:10]import seaborn as snssns.barplot(x=top10, y=top10.index)<AxesSubplot:>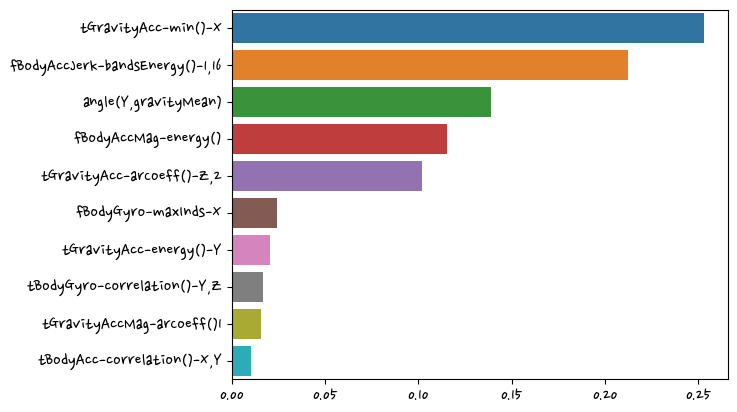
랜덤포레스트 -
bagging : 전체 데이터에서 샘플 데이터를 추출해서 (중복 추출 가능) decision tree의 각각 예측값이 나오는데 이를 합쳐서 최종 예측값 측정
중복데이터 추출 가능 부트스트래핑 분할 방식
이진분류를 나누는 형태
sklearn에 load를 제공하는 보편적인 방법
보팅분류기를 만들어서 test해봄
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
#voing안에 logi랑 kn 모델 사용
#데이터셋에서 데이터 가져오는 것
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scorecancer = load_breast_cancer(as_frame=True) #Dimensionality = 컬럼수cancer.data.head(2)| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst radius | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.8 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 25.38 | 17.33 | 184.6 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 |
| 1 | 20.57 | 17.77 | 132.9 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 24.99 | 23.41 | 158.8 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 |
2 rows × 30 columns
cancer.target.head(2)0 0
1 0
Name: target, dtype: int32cancer.target_names #악성 = 0, 양성 = 1array(['malignant', 'benign'], dtype='<U9')lr_clf = LogisticRegression(solver='liblinear') #모델만듦
knn_clf = KNeighborsClassifier(n_neighbors=8) #n_neighbors=5 : 점 5개를 잡고 지점에서 가까운 것끼리 분류
vo_clf = VotingClassifier([('lr',lr_clf),('knn',knn_clf)],voting='soft') #튜플로 만듦
X_train,X_test,y_train,y_test = train_test_split(cancer.data,
cancer.target,
test_size=0.2,
random_state=156)
vo_clf.fit(X_train,y_train) #보팅분류기
pred = vo_clf.predict(X_test)
accuracy_score(y_test,pred) #묶어서 하는 것이 개별하는 것보다는 좋다. 뭐가 좋음?0.956140350877193#n_neighbors=5 : 점 5개를 잡고 지점에서 가까운 것끼리 분류, 점들의 데이터들의 거리를 계산해서, 데이터를 하나가 있으면 데이터들과 점들의 거리를 계산을 해서 거리를
데이터 들의 중심점으로 계산해서 더 이상 이동이 없을 때가지 계속 작업을 한다.
- vo_clf = VotingClassifier()
estimators : list of (str, estimator) tuples
models = [lr_clf,knn_clf]
for model in models:
model.fit(X_train,y_train)
pred = model.predict(X_test)
model_name = model.__class__.__name__
print(f'{model_name} 정확도 : {accuracy_score(y_test,pred)}')LogisticRegression 정확도 : 0.9473684210526315
KNeighborsClassifier 정확도 : 0.9385964912280702
C:\anaconda\lib\site-packages\sklearn\neighbors\_classification.py:228: FutureWarning: Unlike other reduction functions (e.g. `skew`, `kurtosis`), the default behavior of `mode` typically preserves the axis it acts along. In SciPy 1.11.0, this behavior will change: the default value of `keepdims` will become False, the `axis` over which the statistic is taken will be eliminated, and the value None will no longer be accepted. Set `keepdims` to True or False to avoid this warning.
mode, _ = stats.mode(_y[neigh_ind, k], axis=1)- 교재 215p
보팅 분류기가 정확도가 조금 높게 나타남.
결정트리알고리즘을 기반으로 한다.
앙상블 학습에서 이 같은 결정 트리 알고리즘의 단점을 많은 분류기를 결합해 단점을 극복하고 있다.
랜덤포레스트
- 배깅
대표적으로 램덤 포레스트
소프트부팅사용
#랜덤포레스트
from sklearn.ensemble import RandomForestClassifierdef get_new_df(old_df):
dup_df = pd.DataFrame(data=old_df.groupby('column_name').cumcount(), columns=['dup_cnt'])
dup_df = dup_df.reset_index()
new_df = pd.merge(old_df.reset_index(), dup_df, how='outer')
new_df['column_name'] = new_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1]) if x[1]>0 else x[0], axis = 1)
# if x[1]>0 이면 람다식 진행하고, else x[0]이면 x[0]을 출력하라!
new_df.drop(columns=['index'], inplace=True)
return new_df
def get_human_dataset():
feature_name_df = pd.read_csv('human/human_activity/features.txt',
sep='\s+',
header=None,
names=['column_index','column_name'])
name_df = get_new_df(feature_name_df)
#fBodyAcc-bandsEnergy()-1,8_1을 추출해서 column으로 사용
feature_name = name_df.iloc[:,1].values.tolist()
X_train = pd.read_csv('human/human_activity/train/X_train.txt',sep='\s+',names=feature_name) #sep='\s+' : 공백으로 구분
X_test = pd.read_csv('human/human_activity/test/X_test.txt',sep='\s+',names=feature_name)
y_train = pd.read_csv('human/human_activity/train/y_train.txt',sep='\s+',names=['action'])
y_test = pd.read_csv('human/human_activity/test/y_test.txt',sep='\s+',names=['action'])
return X_train, X_test, y_train, y_testX_train, X_test, y_train, y_test = get_human_dataset()rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(X_train,y_train)
pred = rf_clf.predict(X_test)
accuracy_score(y_test,pred)C:\Users\user\AppData\Local\Temp\ipykernel_11632\1442801055.py:2: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
rf_clf.fit(X_train,y_train)
0.9253478113335596- 교재 218p 오타
디폴트는 10개 -> 100개
from sklearn.model_selection import GridSearchCVparams = {
'max_depth':[8,16,24],
'min_samples_split':[2,8,16],
'min_samples_leaf':[1, 6, 12], #딕셔너리라서 :사용
}%%time
rf_clf = RandomForestClassifier(random_state=0,n_jobs=-1) #n_jobs=-1 : 전부다 쓰겠다
grid_cv = GridSearchCV(rf_clf,params,cv=2,n_jobs=-1)
grid_cv.fit(X_train,y_train)C:\anaconda\lib\site-packages\sklearn\model_selection\_search.py:926: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
self.best_estimator_.fit(X, y, **fit_params)
Wall time: 33.9 s
GridSearchCV(cv=2, estimator=RandomForestClassifier(n_jobs=-1, random_state=0),
n_jobs=-1,
param_grid={'max_depth': [8, 16, 24],
'min_samples_leaf': [1, 6, 12],
'min_samples_split': [2, 8, 16]})grid_cv.best_params_
{'max_depth': 16, 'min_samples_leaf': 6, 'min_samples_split': 2}grid_cv.best_score_0.9164853101196953rf_clf = RandomForestClassifier(random_state=0,max_depth=16,min_samples_leaf=6,min_samples_split=2)
rf_clf.fit(X_train,y_train)
pred = rf_clf.predict(X_test)
accuracy_score(y_test,pred)C:\Users\user\AppData\Local\Temp\ipykernel_11632\795056095.py:2: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
rf_clf.fit(X_train,y_train)
0.9260264675941635-교재 210p 피처 중요도 그래프
-교재 221p 그래프
GBM(Gradient Boosting Machine)
순차적으로 처리하기 때문에 병렬처리를 해줘야 한다.
앞쪽에서 학습하고 잘못 학습된
데이터에 가중치를 부여하면서 오류를 개선해 나가면서 학습하는 방식이다.
-
에이다 부스트는
오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘이다. -
교재 222p
-
피처 데이터 세트
+,-기호를 분류하고자 한다.
잘못 분류된 데이터에 가중치를 부여한다.
더 크게 그려진 이유는 가중치가 부여되서
순차적으로 진행한다.
gbm도 에이다부스트와 유사하다. 가중치 업데이트를 경사 하강법을 이용한다.
from sklearn.ensemble import GradientBoostingClassifier
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
from sklearn.metrics import accuracy_scoredef get_new_df(old_df):
dup_df = pd.DataFrame(data=old_df.groupby('column_name').cumcount(), columns=['dup_cnt'])
dup_df = dup_df.reset_index()
new_df = pd.merge(old_df.reset_index(), dup_df, how='outer')
new_df['column_name'] = new_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1]) if x[1]>0 else x[0], axis = 1)
# if x[1]>0 이면 람다식 진행하고, else x[0]이면 x[0]을 출력하라!
new_df.drop(columns=['index'], inplace=True)
return new_df
def get_human_dataset():
feature_name_df = pd.read_csv('human/human_activity/features.txt',
sep='\s+',
header=None,
names=['column_index','column_name'])
name_df = get_new_df(feature_name_df)
#fBodyAcc-bandsEnergy()-1,8_1을 추출해서 column으로 사용
feature_name = name_df.iloc[:,1].values.tolist()
X_train = pd.read_csv('human/human_activity/train/X_train.txt',sep='\s+',names=feature_name) #sep='\s+' : 공백으로 구분
X_test = pd.read_csv('human/human_activity/test/X_test.txt',sep='\s+',names=feature_name)
y_train = pd.read_csv('human/human_activity/train/y_train.txt',sep='\s+',names=['action'])
y_test = pd.read_csv('human/human_activity/test/y_test.txt',sep='\s+',names=['action'])
return X_train, X_test, y_train, y_testX_train, X_test, y_train, y_test = get_human_dataset()%%time
gb_clf = GradientBoostingClassifier(random_state=0) # learning_rate=0.1 : 학습률(=얼마큼씩 이동할 지 정하는 값)
gb_clf.fit(X_train,y_train)
pred = gb_clf.predict(X_test)
accuracy_score(y_test,pred)Wall time: 12min 8s
0.9389209365456397min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_depth=3,
-> dicisiontree기반이라는 것을 알 수 있다.XGBoost
트리 기반의 앙상블 학습에서 가장 각광
가적합을 방지하기위한 규제가 가능하다.
◐특징
- 뛰어난 예측 성능
- BGM보다 빠르다.
- 과적합 규제
- TREE PRUNING
- 자체 내장된 교차 검증 : 조기 중단 기능
- 결손값(NA) 자체 처리
파이썬 래퍼 XGBoost 하이퍼 파라미터
파이썬 래퍼 XGBoost 모듈과 시이킷런 래퍼 XGBoost 모듈의 일부 하이퍼 파라미터는 약간 다르므로 주의가 필요하다.
-
주요파라미터
booster
silent
nthread (n_jobs와 비슷) -
주요 부스터 파라미터
eta
num_boost_rounds(n_estimators와 비슷, 학습기 몇 개를 쓸 것이냐)
sub_sample(1이면 100%를 쓰겠다.)
lambda(L2 Regularization)
aplha(L1 Regularization)
-교재 231p
import xgboost as xgb
from xgboost import XGBClassifier
from xgboost import plot_importance
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_splitxgb.__version__'1.5.0'dataset = load_breast_cancer(as_frame= True)
dataset.data| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst radius | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.30010 | 0.14710 | 0.2419 | 0.07871 | ... | 25.380 | 17.33 | 184.60 | 2019.0 | 0.16220 | 0.66560 | 0.7119 | 0.2654 | 0.4601 | 0.11890 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.08690 | 0.07017 | 0.1812 | 0.05667 | ... | 24.990 | 23.41 | 158.80 | 1956.0 | 0.12380 | 0.18660 | 0.2416 | 0.1860 | 0.2750 | 0.08902 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.19740 | 0.12790 | 0.2069 | 0.05999 | ... | 23.570 | 25.53 | 152.50 | 1709.0 | 0.14440 | 0.42450 | 0.4504 | 0.2430 | 0.3613 | 0.08758 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.24140 | 0.10520 | 0.2597 | 0.09744 | ... | 14.910 | 26.50 | 98.87 | 567.7 | 0.20980 | 0.86630 | 0.6869 | 0.2575 | 0.6638 | 0.17300 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.19800 | 0.10430 | 0.1809 | 0.05883 | ... | 22.540 | 16.67 | 152.20 | 1575.0 | 0.13740 | 0.20500 | 0.4000 | 0.1625 | 0.2364 | 0.07678 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 564 | 21.56 | 22.39 | 142.00 | 1479.0 | 0.11100 | 0.11590 | 0.24390 | 0.13890 | 0.1726 | 0.05623 | ... | 25.450 | 26.40 | 166.10 | 2027.0 | 0.14100 | 0.21130 | 0.4107 | 0.2216 | 0.2060 | 0.07115 |
| 565 | 20.13 | 28.25 | 131.20 | 1261.0 | 0.09780 | 0.10340 | 0.14400 | 0.09791 | 0.1752 | 0.05533 | ... | 23.690 | 38.25 | 155.00 | 1731.0 | 0.11660 | 0.19220 | 0.3215 | 0.1628 | 0.2572 | 0.06637 |
| 566 | 16.60 | 28.08 | 108.30 | 858.1 | 0.08455 | 0.10230 | 0.09251 | 0.05302 | 0.1590 | 0.05648 | ... | 18.980 | 34.12 | 126.70 | 1124.0 | 0.11390 | 0.30940 | 0.3403 | 0.1418 | 0.2218 | 0.07820 |
| 567 | 20.60 | 29.33 | 140.10 | 1265.0 | 0.11780 | 0.27700 | 0.35140 | 0.15200 | 0.2397 | 0.07016 | ... | 25.740 | 39.42 | 184.60 | 1821.0 | 0.16500 | 0.86810 | 0.9387 | 0.2650 | 0.4087 | 0.12400 |
| 568 | 7.76 | 24.54 | 47.92 | 181.0 | 0.05263 | 0.04362 | 0.00000 | 0.00000 | 0.1587 | 0.05884 | ... | 9.456 | 30.37 | 59.16 | 268.6 | 0.08996 | 0.06444 | 0.0000 | 0.0000 | 0.2871 | 0.07039 |
569 rows × 30 columns
dataset.target_names #'malignant'=악성, 'benign'=양성array(['malignant', 'benign'], dtype='<U9')dataset.target.value_counts()1 357
0 212
Name: target, dtype: int64X_train,X_test,y_train,y_test = train_test_split(dataset.data,dataset.target,test_size=0.2,random_state=156) #학습, 테스트에 쓸 것을 나눔 #stratify=None : 비율설정해서 나눔
X_tr,X_val,y_tr,y_val = train_test_split(X_train,y_train,test_size=0.1,random_state=156)X_train.shape,X_test.shape((455, 30), (114, 30))X_tr.shape,X_val.shape((409, 30), (46, 30))y_train.value_counts()1 280
0 175
Name: target, dtype: int64dtr = xgb.DMatrix(data=X_tr,label=y_tr)
dval =xgb.DMatrix(data=X_val,label=y_val)
dtest= xgb.DMatrix(data=X_test,label=y_test)XGBClassifier() # **kwargs: Any : kwargs = key word args#하이퍼파라미터를 딕셔너리로 지정
params = {
'max_depth' :3,
'eta' : 0.05,
'objective':'binary:logistic',
'eval_metric':'logloss'
}
num_rounds = 500 #num_rounds = esimator, 400개 사용하겠다.
eval_list=[(dtr,'train'),(dval,'eval')] #dtr을'train'으로 하겠다.model = xgb.train(params,dtr,num_rounds,evals=eval_list,early_stopping_rounds=50)#eval = 평가, early_stopping_rounds=None : 조기종료(기간동안 변화가 없을 때 멈춰리)
#train-logloss 점점 줄어든다. eval-logloss는 학습에 사용하지 않아서 줄어들지는 않는다. -> 이 기간을 넘으면 가적합이 됨, 가적합이 되면 오히려 못 맞춘다.[0] train-logloss:0.65016 eval-logloss:0.66183
[1] train-logloss:0.61131 eval-logloss:0.63609
[2] train-logloss:0.57563 eval-logloss:0.61144
[3] train-logloss:0.54310 eval-logloss:0.59204
[4] train-logloss:0.51323 eval-logloss:0.57329
[5] train-logloss:0.48447 eval-logloss:0.55037
[6] train-logloss:0.45796 eval-logloss:0.52929
[7] train-logloss:0.43436 eval-logloss:0.51534
[8] train-logloss:0.41150 eval-logloss:0.49718
[9] train-logloss:0.39027 eval-logloss:0.48154
[10] train-logloss:0.37128 eval-logloss:0.46990
[11] train-logloss:0.35254 eval-logloss:0.45474
[12] train-logloss:0.33528 eval-logloss:0.44229
[13] train-logloss:0.31893 eval-logloss:0.42961
[14] train-logloss:0.30439 eval-logloss:0.42065
[15] train-logloss:0.29000 eval-logloss:0.40958
[16] train-logloss:0.27651 eval-logloss:0.39887
[17] train-logloss:0.26389 eval-logloss:0.39050
[18] train-logloss:0.25210 eval-logloss:0.38254
[19] train-logloss:0.24123 eval-logloss:0.37393
[20] train-logloss:0.23076 eval-logloss:0.36789
[21] train-logloss:0.22091 eval-logloss:0.36017
[22] train-logloss:0.21155 eval-logloss:0.35421
[23] train-logloss:0.20263 eval-logloss:0.34683
[24] train-logloss:0.19434 eval-logloss:0.34111
[25] train-logloss:0.18637 eval-logloss:0.33634
[26] train-logloss:0.17875 eval-logloss:0.33082
[27] train-logloss:0.17167 eval-logloss:0.32675
[28] train-logloss:0.16481 eval-logloss:0.32099
[29] train-logloss:0.15835 eval-logloss:0.31671
[30] train-logloss:0.15225 eval-logloss:0.31277
[31] train-logloss:0.14650 eval-logloss:0.30882
[32] train-logloss:0.14102 eval-logloss:0.30437
[33] train-logloss:0.13590 eval-logloss:0.30103
[34] train-logloss:0.13109 eval-logloss:0.29794
[35] train-logloss:0.12647 eval-logloss:0.29499
[36] train-logloss:0.12197 eval-logloss:0.29295
[37] train-logloss:0.11784 eval-logloss:0.29043
[38] train-logloss:0.11379 eval-logloss:0.28927
[39] train-logloss:0.10994 eval-logloss:0.28578
[40] train-logloss:0.10638 eval-logloss:0.28364
[41] train-logloss:0.10302 eval-logloss:0.28183
[42] train-logloss:0.09963 eval-logloss:0.28005
[43] train-logloss:0.09649 eval-logloss:0.27972
[44] train-logloss:0.09359 eval-logloss:0.27744
[45] train-logloss:0.09080 eval-logloss:0.27542
[46] train-logloss:0.08807 eval-logloss:0.27504
[47] train-logloss:0.08541 eval-logloss:0.27458
[48] train-logloss:0.08299 eval-logloss:0.27348
[49] train-logloss:0.08035 eval-logloss:0.27247
[50] train-logloss:0.07786 eval-logloss:0.27163
[51] train-logloss:0.07550 eval-logloss:0.27094
[52] train-logloss:0.07344 eval-logloss:0.26967
[53] train-logloss:0.07147 eval-logloss:0.27008
[54] train-logloss:0.06964 eval-logloss:0.26890
[55] train-logloss:0.06766 eval-logloss:0.26854
[56] train-logloss:0.06592 eval-logloss:0.26900
[57] train-logloss:0.06433 eval-logloss:0.26790
[58] train-logloss:0.06259 eval-logloss:0.26663
[59] train-logloss:0.06107 eval-logloss:0.26743
[60] train-logloss:0.05957 eval-logloss:0.26610
[61] train-logloss:0.05817 eval-logloss:0.26644
[62] train-logloss:0.05691 eval-logloss:0.26673
[63] train-logloss:0.05550 eval-logloss:0.26550
[64] train-logloss:0.05422 eval-logloss:0.26443
[65] train-logloss:0.05311 eval-logloss:0.26500
[66] train-logloss:0.05207 eval-logloss:0.26591
[67] train-logloss:0.05093 eval-logloss:0.26501
[68] train-logloss:0.04976 eval-logloss:0.26435
[69] train-logloss:0.04872 eval-logloss:0.26360
[70] train-logloss:0.04776 eval-logloss:0.26319
[71] train-logloss:0.04680 eval-logloss:0.26255
[72] train-logloss:0.04580 eval-logloss:0.26204
[73] train-logloss:0.04484 eval-logloss:0.26254
[74] train-logloss:0.04388 eval-logloss:0.26289
[75] train-logloss:0.04309 eval-logloss:0.26249
[76] train-logloss:0.04224 eval-logloss:0.26217
[77] train-logloss:0.04133 eval-logloss:0.26166
[78] train-logloss:0.04050 eval-logloss:0.26179
[79] train-logloss:0.03967 eval-logloss:0.26103
[80] train-logloss:0.03877 eval-logloss:0.26094
[81] train-logloss:0.03806 eval-logloss:0.26148
[82] train-logloss:0.03740 eval-logloss:0.26054
[83] train-logloss:0.03676 eval-logloss:0.25967
[84] train-logloss:0.03605 eval-logloss:0.25905
[85] train-logloss:0.03545 eval-logloss:0.26007
[86] train-logloss:0.03488 eval-logloss:0.25984
[87] train-logloss:0.03425 eval-logloss:0.25933
[88] train-logloss:0.03361 eval-logloss:0.25932
[89] train-logloss:0.03311 eval-logloss:0.26002
[90] train-logloss:0.03260 eval-logloss:0.25936
[91] train-logloss:0.03202 eval-logloss:0.25886
[92] train-logloss:0.03152 eval-logloss:0.25918
[93] train-logloss:0.03107 eval-logloss:0.25865
[94] train-logloss:0.03049 eval-logloss:0.25951
[95] train-logloss:0.03007 eval-logloss:0.26091
[96] train-logloss:0.02963 eval-logloss:0.26014
[97] train-logloss:0.02913 eval-logloss:0.25974
[98] train-logloss:0.02866 eval-logloss:0.25937
[99] train-logloss:0.02829 eval-logloss:0.25893
[100] train-logloss:0.02789 eval-logloss:0.25928
[101] train-logloss:0.02751 eval-logloss:0.25955
[102] train-logloss:0.02714 eval-logloss:0.25901
[103] train-logloss:0.02668 eval-logloss:0.25991
[104] train-logloss:0.02634 eval-logloss:0.25950
[105] train-logloss:0.02594 eval-logloss:0.25924
[106] train-logloss:0.02556 eval-logloss:0.25901
[107] train-logloss:0.02522 eval-logloss:0.25738
[108] train-logloss:0.02492 eval-logloss:0.25702
[109] train-logloss:0.02453 eval-logloss:0.25789
[110] train-logloss:0.02418 eval-logloss:0.25770
[111] train-logloss:0.02384 eval-logloss:0.25842
[112] train-logloss:0.02356 eval-logloss:0.25810
[113] train-logloss:0.02322 eval-logloss:0.25848
[114] train-logloss:0.02290 eval-logloss:0.25833
[115] train-logloss:0.02260 eval-logloss:0.25820
[116] train-logloss:0.02229 eval-logloss:0.25905
[117] train-logloss:0.02204 eval-logloss:0.25878
[118] train-logloss:0.02176 eval-logloss:0.25728
[119] train-logloss:0.02149 eval-logloss:0.25722
[120] train-logloss:0.02119 eval-logloss:0.25764
[121] train-logloss:0.02095 eval-logloss:0.25761
[122] train-logloss:0.02067 eval-logloss:0.25832
[123] train-logloss:0.02045 eval-logloss:0.25808
[124] train-logloss:0.02023 eval-logloss:0.25855
[125] train-logloss:0.01998 eval-logloss:0.25714
[126] train-logloss:0.01973 eval-logloss:0.25587
[127] train-logloss:0.01946 eval-logloss:0.25640
[128] train-logloss:0.01927 eval-logloss:0.25685
[129] train-logloss:0.01908 eval-logloss:0.25665
[130] train-logloss:0.01886 eval-logloss:0.25712
[131] train-logloss:0.01863 eval-logloss:0.25609
[132] train-logloss:0.01839 eval-logloss:0.25649
[133] train-logloss:0.01816 eval-logloss:0.25789
[134] train-logloss:0.01802 eval-logloss:0.25811
[135] train-logloss:0.01785 eval-logloss:0.25794
[136] train-logloss:0.01763 eval-logloss:0.25876
[137] train-logloss:0.01748 eval-logloss:0.25884
[138] train-logloss:0.01732 eval-logloss:0.25867
[139] train-logloss:0.01719 eval-logloss:0.25876
[140] train-logloss:0.01696 eval-logloss:0.25987
[141] train-logloss:0.01681 eval-logloss:0.25960
[142] train-logloss:0.01669 eval-logloss:0.25982
[143] train-logloss:0.01656 eval-logloss:0.25992
[144] train-logloss:0.01638 eval-logloss:0.26035
[145] train-logloss:0.01623 eval-logloss:0.26055
[146] train-logloss:0.01606 eval-logloss:0.26092
[147] train-logloss:0.01589 eval-logloss:0.26137
[148] train-logloss:0.01572 eval-logloss:0.25999
[149] train-logloss:0.01557 eval-logloss:0.26028
[150] train-logloss:0.01546 eval-logloss:0.26048
[151] train-logloss:0.01531 eval-logloss:0.26142
[152] train-logloss:0.01515 eval-logloss:0.26188
[153] train-logloss:0.01501 eval-logloss:0.26227
[154] train-logloss:0.01486 eval-logloss:0.26287
[155] train-logloss:0.01476 eval-logloss:0.26299
[156] train-logloss:0.01461 eval-logloss:0.26346
[157] train-logloss:0.01448 eval-logloss:0.26379
[158] train-logloss:0.01434 eval-logloss:0.26306
[159] train-logloss:0.01424 eval-logloss:0.26237
[160] train-logloss:0.01410 eval-logloss:0.26251
[161] train-logloss:0.01401 eval-logloss:0.26265
[162] train-logloss:0.01392 eval-logloss:0.26264
[163] train-logloss:0.01380 eval-logloss:0.26250
[164] train-logloss:0.01372 eval-logloss:0.26264
[165] train-logloss:0.01359 eval-logloss:0.26255
[166] train-logloss:0.01350 eval-logloss:0.26188
[167] train-logloss:0.01342 eval-logloss:0.26203
[168] train-logloss:0.01331 eval-logloss:0.26190
[169] train-logloss:0.01319 eval-logloss:0.26184
[170] train-logloss:0.01312 eval-logloss:0.26133
[171] train-logloss:0.01304 eval-logloss:0.26148
[172] train-logloss:0.01297 eval-logloss:0.26157
[173] train-logloss:0.01285 eval-logloss:0.26253
[174] train-logloss:0.01278 eval-logloss:0.26229
[175] train-logloss:0.01267 eval-logloss:0.26086
[176] train-logloss:0.01258 eval-logloss:0.26103pred_probs = model.predict(dtest)np.round(pred_probs[:10],3) #1이될 확률array([0.845, 0.008, 0.68 , 0.081, 0.975, 0.999, 0.998, 0.998, 0.996,
0.001], dtype=float32)predict = 확률값, predict_proba = 0,1이 될 확률값이 나온다
pred = [1 if x >0.5 else 0 for x in pred_probs]pred #결정값[1,
0,
1,
0,
1,
1,
1,
1,
1,
0,
0,
0,
1,
1,
1,
1,
1,
1,
1,
1,
0,
0,
0,
1,
0,
1,
0,
0,
1,
0,
1,
0,
1,
1,
0,
0,
1,
1,
0,
1,
0,
1,
1,
1,
1,
1,
0,
1,
1,
1,
1,
0,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
0,
0,
1,
1,
0,
1,
1,
1,
0,
1,
0,
1,
1,
0,
1,
1,
1,
0,
0,
1,
1,
1,
1,
1,
1,
1,
1,
0,
0,
1,
0,
0,
1,
0,
0,
1,
0,
1,
0,
0,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1]def get_clf_eval(y_test,pred,pred_proba_1): #(y_test,pred) 지역변수 pred = 결정값,pred_proba_1=확률값?
from sklearn.metrics import accuracy_score,precision_score,recall_score,confusion_matrix,f1_score,roc_auc_score
confusion = confusion_matrix(y_test,pred)
accuracy = accuracy_score(y_test,pred)
precision = precision_score(y_test,pred)
recall = recall_score(y_test,pred)
f1 = f1_score(y_test,pred)
auc = roc_auc_score(y_test,pred_proba_1)
print('오차행렬')
print(confusion)
print(f'정확도:{accuracy:.4f}, 정밀도:{precision:.4f}, 재현율:{recall:.4f}, F1:{f1:.4f}, AUC:{auc:.4f}')
get_clf_eval(y_test,pred,pred_probs)오차행렬
[[34 3]
[ 2 75]]
정확도:0.9561, 정밀도:0.9615, 재현율:0.9740, F1:0.9677, AUC:0.9937plot_importance(model)<AxesSubplot:title={'center':'Feature importance'}, xlabel='F score', ylabel='Features'>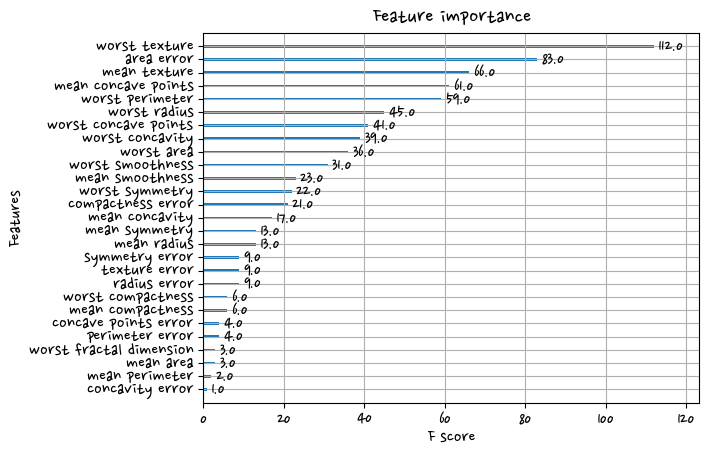
xgb.to_graphviz(model,'xgb.dot')---------------------------------------------------------------------------
XGBoostError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_9144\3641375644.py in <module>
----> 1 xgb.to_graphviz(model,'xgb.dot')
C:\anaconda\lib\site-packages\xgboost\plotting.py in to_graphviz(booster, fmap, num_trees, rankdir, yes_color, no_color, condition_node_params, leaf_node_params, **kwargs)
206 parameters += ':'
207 parameters += json.dumps(kwargs)
--> 208 tree = booster.get_dump(
209 fmap=fmap,
210 dump_format=parameters)[num_trees]
C:\anaconda\lib\site-packages\xgboost\core.py in get_dump(self, fmap, with_stats, dump_format)
2250 length = c_bst_ulong()
2251 sarr = ctypes.POINTER(ctypes.c_char_p)()
-> 2252 _check_call(_LIB.XGBoosterDumpModelEx(self.handle,
2253 c_str(fmap),
2254 ctypes.c_int(with_stats),
C:\anaconda\lib\site-packages\xgboost\core.py in _check_call(ret)
216 """
217 if ret != 0:
--> 218 raise XGBoostError(py_str(_LIB.XGBGetLastError()))
219
220
XGBoostError: [15:32:50] ..\dmlc-core\src\io\local_filesys.cc:209: Check failed: allow_null: LocalFileSystem::Open "xgb.dot": No such file or directory사이킷 래퍼 XGBoost의 개요 및 적용
from xgboost import to_graphviz
to_graphviz(model)
from xgboost import XGBClassifiermodel = XGBClassifier(n_estimators=500,learning_rate=0.05,max_depth=3,eval_metric='logloss')model.fit(X_train,y_train,verbose=True)XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, enable_categorical=False,
eval_metric='logloss', gamma=0, gpu_id=-1, importance_type=None,
interaction_constraints='', learning_rate=0.05, max_delta_step=0,
max_depth=3, min_child_weight=1, missing=nan,
monotone_constraints='()', n_estimators=500, n_jobs=8,
num_parallel_tree=1, predictor='auto', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)pred = model.predict(X_test)pred #결정값으로 나온다.array([1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1,
0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1,
0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1])pred_proba = model.predict_proba(X_test)pred_proba[:,1]array([9.12188411e-01, 3.26777250e-03, 9.18584466e-01, 1.12425499e-01,
9.91267264e-01, 9.99935985e-01, 9.99622345e-01, 9.99181807e-01,
9.95988905e-01, 1.21930876e-04, 3.26498965e-04, 2.35663480e-04,
9.99827325e-01, 9.99892950e-01, 9.98326719e-01, 9.92636442e-01,
9.93933976e-01, 9.99863386e-01, 9.99317884e-01, 9.99371588e-01,
7.17270304e-04, 6.14884675e-01, 2.00337556e-04, 9.99950290e-01,
2.73418846e-04, 8.82554293e-01, 3.71223688e-03, 3.85174004e-04,
9.98981297e-01, 4.70896214e-02, 9.98191297e-01, 4.11191548e-04,
9.89034534e-01, 7.66591251e-01, 3.31286481e-03, 1.45611324e-04,
9.98210073e-01, 9.98775661e-01, 2.10140735e-01, 9.99862194e-01,
2.12053820e-01, 9.97596204e-01, 9.99571860e-01, 9.99598920e-01,
9.99083996e-01, 9.84561980e-01, 1.25431782e-02, 9.99352515e-01,
9.98489738e-01, 9.99605715e-01, 9.97448742e-01, 4.12069174e-04,
9.99003828e-01, 9.99744356e-01, 9.99462426e-01, 9.99344289e-01,
9.99861002e-01, 9.91916835e-01, 9.99539137e-01, 9.61040139e-01,
9.98758674e-01, 9.77937937e-01, 8.05007468e-04, 4.46018035e-04,
9.99605358e-01, 9.99295592e-01, 9.03019914e-04, 9.89207387e-01,
9.99782741e-01, 9.99626398e-01, 4.78562928e-04, 9.98247385e-01,
2.28664241e-04, 9.98528004e-01, 9.98889625e-01, 1.68968734e-04,
9.99672890e-01, 9.99839902e-01, 9.99839544e-01, 1.16767813e-04,
1.85251178e-04, 9.83601868e-01, 9.99406099e-01, 9.99420047e-01,
9.99271572e-01, 9.93693352e-01, 9.98360932e-01, 9.99571860e-01,
9.89574730e-01, 2.23127907e-04, 1.61858186e-01, 9.99864578e-01,
7.57402275e-04, 1.90093089e-03, 9.99784172e-01, 4.20990912e-03,
8.70510284e-03, 9.97238755e-01, 3.27697693e-04, 7.22961247e-01,
4.12358483e-03, 7.13363173e-04, 9.98041272e-01, 9.96626973e-01,
5.29846489e-01, 9.99231815e-01, 9.99245286e-01, 9.91033375e-01,
9.98749495e-01, 9.99877691e-01, 6.45176947e-01, 9.99190748e-01,
9.98065531e-01, 9.98803973e-01], dtype=float32) get_clf_eval(y_test,pred,pred_proba[:,1])오차행렬
[[34 3]
[ 1 76]]
정확도:0.9649, 정밀도:0.9620, 재현율:0.9870, F1:0.9744, AUC:0.9951-교재 242p
eval - 검증셋?
model = XGBClassifier(n_estimators=500,learning_rate=0.05,max_depth=3)
evals=[(X_tr,y_tr),(X_val,y_val)]#리스트에 튜플로 구성 #검증에 쓸 것
model.fit(X_tr, #train중에 90:10 으로 나눈 것
y_tr,
verbose=True,
eval_set=evals,
early_stopping_rounds=50, #조기종료
eval_metric='logloss') #평가
pred = model.predict(X_test)
pred_proba = model.predict_proba(X_test)
get_clf_eval(y_test,pred,pred_proba[:,1])[0] validation_0-logloss:0.65016 validation_1-logloss:0.66183
[1] validation_0-logloss:0.61131 validation_1-logloss:0.63609
[2] validation_0-logloss:0.57563 validation_1-logloss:0.61144
[3] validation_0-logloss:0.54310 validation_1-logloss:0.59204
[4] validation_0-logloss:0.51323 validation_1-logloss:0.57329
[5] validation_0-logloss:0.48447 validation_1-logloss:0.55037
[6] validation_0-logloss:0.45796 validation_1-logloss:0.52929
[7] validation_0-logloss:0.43436 validation_1-logloss:0.51534
[8] validation_0-logloss:0.41150 validation_1-logloss:0.49718
[9] validation_0-logloss:0.39027 validation_1-logloss:0.48154
[10] validation_0-logloss:0.37128 validation_1-logloss:0.46990
[11] validation_0-logloss:0.35254 validation_1-logloss:0.45474
[12] validation_0-logloss:0.33528 validation_1-logloss:0.44229
[13] validation_0-logloss:0.31893 validation_1-logloss:0.42961
[14] validation_0-logloss:0.30439 validation_1-logloss:0.42065
[15] validation_0-logloss:0.29000 validation_1-logloss:0.40958
[16] validation_0-logloss:0.27651 validation_1-logloss:0.39887
[17] validation_0-logloss:0.26389 validation_1-logloss:0.39050
[18] validation_0-logloss:0.25210 validation_1-logloss:0.38254
[19] validation_0-logloss:0.24123 validation_1-logloss:0.37393
[20] validation_0-logloss:0.23076 validation_1-logloss:0.36789
[21] validation_0-logloss:0.22091 validation_1-logloss:0.36017
[22] validation_0-logloss:0.21155 validation_1-logloss:0.35421
[23] validation_0-logloss:0.20263 validation_1-logloss:0.34683
[24] validation_0-logloss:0.19434 validation_1-logloss:0.34111
[25] validation_0-logloss:0.18637 validation_1-logloss:0.33634
[26] validation_0-logloss:0.17875 validation_1-logloss:0.33082
[27] validation_0-logloss:0.17167 validation_1-logloss:0.32675
[28] validation_0-logloss:0.16481 validation_1-logloss:0.32099
[29] validation_0-logloss:0.15835 validation_1-logloss:0.31671
[30] validation_0-logloss:0.15225 validation_1-logloss:0.31277
[31] validation_0-logloss:0.14650 validation_1-logloss:0.30882
[32] validation_0-logloss:0.14102 validation_1-logloss:0.30437
[33] validation_0-logloss:0.13590 validation_1-logloss:0.30103
[34] validation_0-logloss:0.13109 validation_1-logloss:0.29794
[35] validation_0-logloss:0.12647 validation_1-logloss:0.29499
[36] validation_0-logloss:0.12197 validation_1-logloss:0.29295
[37] validation_0-logloss:0.11784 validation_1-logloss:0.29043
[38] validation_0-logloss:0.11379 validation_1-logloss:0.28927
[39] validation_0-logloss:0.10994 validation_1-logloss:0.28578
[40] validation_0-logloss:0.10638 validation_1-logloss:0.28364
[41] validation_0-logloss:0.10302 validation_1-logloss:0.28183
[42] validation_0-logloss:0.09963 validation_1-logloss:0.28005
[43] validation_0-logloss:0.09649 validation_1-logloss:0.27972
[44] validation_0-logloss:0.09359 validation_1-logloss:0.27744
[45] validation_0-logloss:0.09080 validation_1-logloss:0.27542
[46] validation_0-logloss:0.08807 validation_1-logloss:0.27504
[47] validation_0-logloss:0.08541 validation_1-logloss:0.27458
[48] validation_0-logloss:0.08299 validation_1-logloss:0.27348
[49] validation_0-logloss:0.08035 validation_1-logloss:0.27247
[50] validation_0-logloss:0.07786 validation_1-logloss:0.27163
[51] validation_0-logloss:0.07550 validation_1-logloss:0.27094
[52] validation_0-logloss:0.07344 validation_1-logloss:0.26967
[53] validation_0-logloss:0.07147 validation_1-logloss:0.27008
[54] validation_0-logloss:0.06964 validation_1-logloss:0.26890
[55] validation_0-logloss:0.06766 validation_1-logloss:0.26854
[56] validation_0-logloss:0.06592 validation_1-logloss:0.26900
[57] validation_0-logloss:0.06433 validation_1-logloss:0.26790
[58] validation_0-logloss:0.06259 validation_1-logloss:0.26663
[59] validation_0-logloss:0.06107 validation_1-logloss:0.26743
[60] validation_0-logloss:0.05957 validation_1-logloss:0.26610
[61] validation_0-logloss:0.05817 validation_1-logloss:0.26644
[62] validation_0-logloss:0.05691 validation_1-logloss:0.26673
[63] validation_0-logloss:0.05550 validation_1-logloss:0.26550
[64] validation_0-logloss:0.05422 validation_1-logloss:0.26443
[65] validation_0-logloss:0.05311 validation_1-logloss:0.26500
[66] validation_0-logloss:0.05207 validation_1-logloss:0.26591
[67] validation_0-logloss:0.05093 validation_1-logloss:0.26501
[68] validation_0-logloss:0.04976 validation_1-logloss:0.26435
[69] validation_0-logloss:0.04872 validation_1-logloss:0.26360
[70] validation_0-logloss:0.04776 validation_1-logloss:0.26319
[71] validation_0-logloss:0.04680 validation_1-logloss:0.26255
[72] validation_0-logloss:0.04580 validation_1-logloss:0.26204
[73] validation_0-logloss:0.04484 validation_1-logloss:0.26254
[74] validation_0-logloss:0.04388 validation_1-logloss:0.26289
[75] validation_0-logloss:0.04309 validation_1-logloss:0.26249
[76] validation_0-logloss:0.04224 validation_1-logloss:0.26217
[77] validation_0-logloss:0.04133 validation_1-logloss:0.26166
[78] validation_0-logloss:0.04050 validation_1-logloss:0.26179
[79] validation_0-logloss:0.03967 validation_1-logloss:0.26103
[80] validation_0-logloss:0.03877 validation_1-logloss:0.26094
[81] validation_0-logloss:0.03806 validation_1-logloss:0.26148
[82] validation_0-logloss:0.03740 validation_1-logloss:0.26054
[83] validation_0-logloss:0.03676 validation_1-logloss:0.25967
[84] validation_0-logloss:0.03605 validation_1-logloss:0.25905
[85] validation_0-logloss:0.03545 validation_1-logloss:0.26007
[86] validation_0-logloss:0.03488 validation_1-logloss:0.25984
[87] validation_0-logloss:0.03425 validation_1-logloss:0.25933
[88] validation_0-logloss:0.03361 validation_1-logloss:0.25932
[89] validation_0-logloss:0.03311 validation_1-logloss:0.26002
[90] validation_0-logloss:0.03260 validation_1-logloss:0.25936
[91] validation_0-logloss:0.03202 validation_1-logloss:0.25886
[92] validation_0-logloss:0.03152 validation_1-logloss:0.25918
[93] validation_0-logloss:0.03107 validation_1-logloss:0.25865
[94] validation_0-logloss:0.03049 validation_1-logloss:0.25951
[95] validation_0-logloss:0.03007 validation_1-logloss:0.26091
[96] validation_0-logloss:0.02963 validation_1-logloss:0.26014
[97] validation_0-logloss:0.02913 validation_1-logloss:0.25974
[98] validation_0-logloss:0.02866 validation_1-logloss:0.25937
[99] validation_0-logloss:0.02829 validation_1-logloss:0.25893
[100] validation_0-logloss:0.02789 validation_1-logloss:0.25928
[101] validation_0-logloss:0.02751 validation_1-logloss:0.25955
[102] validation_0-logloss:0.02714 validation_1-logloss:0.25901
[103] validation_0-logloss:0.02668 validation_1-logloss:0.25991
[104] validation_0-logloss:0.02634 validation_1-logloss:0.25950
[105] validation_0-logloss:0.02594 validation_1-logloss:0.25924
[106] validation_0-logloss:0.02556 validation_1-logloss:0.25901
[107] validation_0-logloss:0.02522 validation_1-logloss:0.25738
[108] validation_0-logloss:0.02492 validation_1-logloss:0.25702
[109] validation_0-logloss:0.02453 validation_1-logloss:0.25789
[110] validation_0-logloss:0.02418 validation_1-logloss:0.25770
[111] validation_0-logloss:0.02384 validation_1-logloss:0.25842
[112] validation_0-logloss:0.02356 validation_1-logloss:0.25810
[113] validation_0-logloss:0.02322 validation_1-logloss:0.25848
[114] validation_0-logloss:0.02290 validation_1-logloss:0.25833
[115] validation_0-logloss:0.02260 validation_1-logloss:0.25820
[116] validation_0-logloss:0.02229 validation_1-logloss:0.25905
[117] validation_0-logloss:0.02204 validation_1-logloss:0.25878
[118] validation_0-logloss:0.02176 validation_1-logloss:0.25728
[119] validation_0-logloss:0.02149 validation_1-logloss:0.25722
[120] validation_0-logloss:0.02119 validation_1-logloss:0.25764
[121] validation_0-logloss:0.02095 validation_1-logloss:0.25761
[122] validation_0-logloss:0.02067 validation_1-logloss:0.25832
[123] validation_0-logloss:0.02045 validation_1-logloss:0.25808
[124] validation_0-logloss:0.02023 validation_1-logloss:0.25855
[125] validation_0-logloss:0.01998 validation_1-logloss:0.25714
[126] validation_0-logloss:0.01973 validation_1-logloss:0.25587
[127] validation_0-logloss:0.01946 validation_1-logloss:0.25640
[128] validation_0-logloss:0.01927 validation_1-logloss:0.25685
[129] validation_0-logloss:0.01908 validation_1-logloss:0.25665
[130] validation_0-logloss:0.01886 validation_1-logloss:0.25712
[131] validation_0-logloss:0.01863 validation_1-logloss:0.25609
[132] validation_0-logloss:0.01839 validation_1-logloss:0.25649
[133] validation_0-logloss:0.01816 validation_1-logloss:0.25789
[134] validation_0-logloss:0.01802 validation_1-logloss:0.25811
[135] validation_0-logloss:0.01785 validation_1-logloss:0.25794
[136] validation_0-logloss:0.01763 validation_1-logloss:0.25876
[137] validation_0-logloss:0.01748 validation_1-logloss:0.25884
[138] validation_0-logloss:0.01732 validation_1-logloss:0.25867
[139] validation_0-logloss:0.01719 validation_1-logloss:0.25876
[140] validation_0-logloss:0.01696 validation_1-logloss:0.25987
[141] validation_0-logloss:0.01681 validation_1-logloss:0.25960
[142] validation_0-logloss:0.01669 validation_1-logloss:0.25982
[143] validation_0-logloss:0.01656 validation_1-logloss:0.25992
[144] validation_0-logloss:0.01638 validation_1-logloss:0.26035
[145] validation_0-logloss:0.01623 validation_1-logloss:0.26055
[146] validation_0-logloss:0.01606 validation_1-logloss:0.26092
[147] validation_0-logloss:0.01589 validation_1-logloss:0.26137
[148] validation_0-logloss:0.01572 validation_1-logloss:0.25999
[149] validation_0-logloss:0.01557 validation_1-logloss:0.26028
[150] validation_0-logloss:0.01546 validation_1-logloss:0.26048
[151] validation_0-logloss:0.01531 validation_1-logloss:0.26142
[152] validation_0-logloss:0.01515 validation_1-logloss:0.26188
[153] validation_0-logloss:0.01501 validation_1-logloss:0.26227
[154] validation_0-logloss:0.01486 validation_1-logloss:0.26287
[155] validation_0-logloss:0.01476 validation_1-logloss:0.26299
[156] validation_0-logloss:0.01461 validation_1-logloss:0.26346
[157] validation_0-logloss:0.01448 validation_1-logloss:0.26379
[158] validation_0-logloss:0.01434 validation_1-logloss:0.26306
[159] validation_0-logloss:0.01424 validation_1-logloss:0.26237
[160] validation_0-logloss:0.01410 validation_1-logloss:0.26251
[161] validation_0-logloss:0.01401 validation_1-logloss:0.26265
[162] validation_0-logloss:0.01392 validation_1-logloss:0.26264
[163] validation_0-logloss:0.01380 validation_1-logloss:0.26250
[164] validation_0-logloss:0.01372 validation_1-logloss:0.26264
[165] validation_0-logloss:0.01359 validation_1-logloss:0.26255
[166] validation_0-logloss:0.01350 validation_1-logloss:0.26188
[167] validation_0-logloss:0.01342 validation_1-logloss:0.26203
[168] validation_0-logloss:0.01331 validation_1-logloss:0.26190
[169] validation_0-logloss:0.01319 validation_1-logloss:0.26184
[170] validation_0-logloss:0.01312 validation_1-logloss:0.26133
[171] validation_0-logloss:0.01304 validation_1-logloss:0.26148
[172] validation_0-logloss:0.01297 validation_1-logloss:0.26157
[173] validation_0-logloss:0.01285 validation_1-logloss:0.26253
[174] validation_0-logloss:0.01278 validation_1-logloss:0.26229
[175] validation_0-logloss:0.01267 validation_1-logloss:0.26086
[176] validation_0-logloss:0.01258 validation_1-logloss:0.26103
오차행렬
[[34 3]
[ 2 75]]
정확도:0.9561, 정밀도:0.9615, 재현율:0.9740, F1:0.9677, AUC:0.9933from xgboost import to_graphviz
to_graphviz(model)