
개념
NLP?
-
NLP는 단어 or 문서의 의미를 나타내는 표현을 얻는 것부터 시작한다
-
가장 간단한 단어의 의미 표현 방법으로 one-hot vector가 있다
-
이 one-hot vector의 문제점은 각각의 vector가 모두 직교(orthogonal)하기 때문에 내적하면 0이되는데 이는 유사성 개념이 존재하지 않는 것을 의미한다
-
이러한 문제를 해결하기 위해 벡터 자체에 단어의 의미를 담는 방법을 고안한다
-
단어의 의미(semantics)는 단어 자체가 아닌 단어가 쓰이는 맥락에 걸쳐 배분(distributed across contexts)되어 있다고 가정한다
Count-based: DTM
-
맥락에 걸쳐 의미가 배분되어있다고 가정하에 벡터 자체에 단어의 의미를 담는 방법 중 하나이다
-
Document-Term Matrix(DTM)을 구축하고 벡터를 추출한다
-
One-hot vector와 달리 두 문서 사이의 유사도를 정량적으로 측정할 수 있다는 점에 의의를 가진다
-
문제점으로 sparsity가 있다
Prediction based: Language Models
-
의미를 담는 규칙을 사람이 정하지 않고 모델이 단어의 의미를 벡터에 담는 규칙을 스스로 학습하도록 하여 dense vector를 얻는 것
-
P(next|context)를 최대화 하는 방향으로 모델의 가중치를 최적화
DTM 파이썬 구현
- DTM, tf(term frequency) 구현
# A mini corpus to play with
CORPUS = [
'this is the first document',
'this is the second document',
'and this is the third document',
'is this the first document'
]
# 단어 term이 문장 doc에 얼마나 있는지 카운트하여 출력한다
def tf(term: str, doc: str) -> int:
tf = sum([
term == word # True (1) or False (0)
for word in doc.split(" ")
])
return tf
def build_dtm(corpus: List[str]) -> pd.DataFrame:
words = [
word
for doc in corpus
for word in doc.split(" ")
]
vocab = list(set(words)) # 어휘(vocabulary)
dtm = [
[tf(term, doc) for term in vocab]
for doc in corpus
]
dtm = pd.DataFrame(data=dtm, columns=vocab)
return dtm- DTM 출력 결과
# build a dtm from the corpus, and have a look at it
dtm = build_dtm(CORPUS)
print(dtm)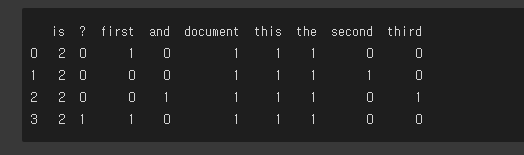
- 유사도 행렬 계산 결과
# this will print out the similarities of the documents to each other
sim_matrix = cosine_similarity(dtm.to_numpy(), dtm.to_numpy())
print(sim_matrix)
