
개념
TF-IDF
-
DTM과 같은 단순 빈도수 기반 방법론의 문제는 중요한 단어와 불필요한 단어를 구분하지 못한다는 것이다
-
예를 어 the, this, is 같은 stopwords(불용어)들은 어떤 문서이든 빈도수가 높지만 해당 문서를 대변하는 단어라고 볼 수 없다
-
문서를 대변하는 단어에 가중치를 더 부여하는 방법이 TF-IDF이다
-
TF-IDF = TF * IDF 이다
IDF, DF
-
DF (Document Frequency)는 특정 단어가 등장한 문서의 수를 뜻한다
-
IDF (Inverse Document Frequency)는 DF를 역수 취해준 값으로 흔하지 않은 단어일수록 해당 문서를 대변한다고 가정하며 식은 다음과 같다
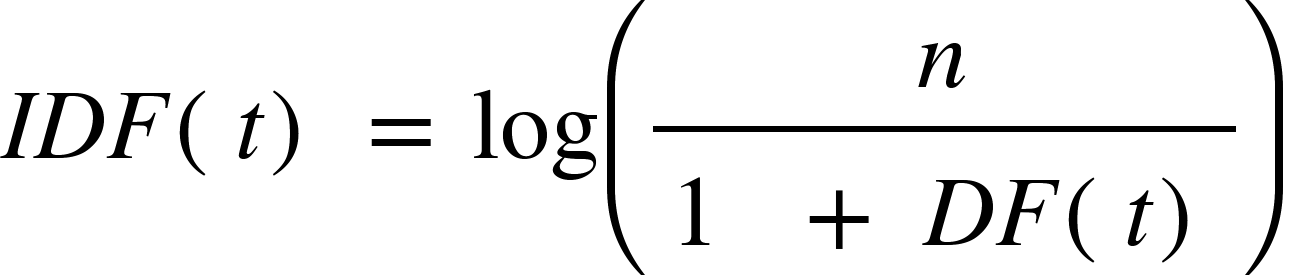
분모에 1을 더해준 것은 0으로 나누는 것을 막기 위해서이다
log를 씌우는 이유는 흔하지 않은 단어에 부여하는 가중치가 너무 커지기 때문이다
-
로그를 씌웠을 때
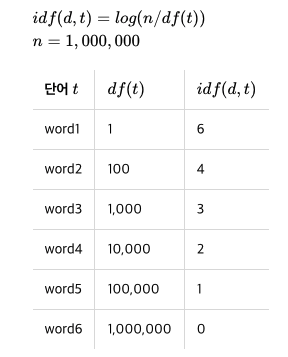
-
로그를 씌우지 않았을 때
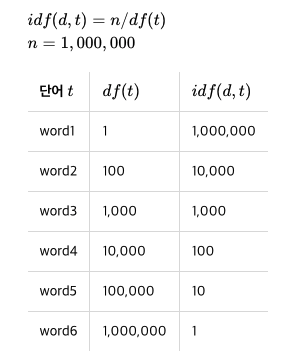
결론
TF-IDF의 값은 TF와 IDF에 비례하며 이는 흔하지 않은 단어이면서(불용어가 아니면서) 해당 문서에 유독 많이 출현한다면 TF-IDF가 높아지는 것을 의미한다
TF-IDF 파이썬 구현
- 라이브러리
# install & import the libraries needed
!pip3 install pandas
!pip3 install scikit-learn
from typing import List
from math import log
import numpy as np
import pandas as pd
import random
from sklearn.metrics.pairwise import cosine_similarity
# for printing out all the columns of a pandas dataframe https://towardsdatascience.com/how-to-show-all-columns-rows-of-a-pandas-dataframe-c49d4507fcf
pd.set_option('display.max_columns', None)- corpus
# The corpus
CORPUS = [
'this is the first document',
'the first document is this',
'this is the second document',
'and this is the third document',
'is this the first document'
]- DTM, DF 함수 구현
def tf(term: str, doc: str) -> int:
tf = sum([
word == term
for word in doc.split(" ") # word count
])
return tf
def build_dtm(corpus: List[str]) -> pd.DataFrame:
words = [
word
for doc in corpus
for word in doc.split(" ")
]
vocab = list(set(words))
dtm = [
[tf(term, doc) for term in vocab] # row
for doc in corpus
]
dtm = pd.DataFrame(data=dtm, columns=vocab)
return dtm- IDF 구현
# complete this function
def idf(term: str, corpus: List[str]) -> float:
n = len(corpus)
df = sum([ term in doc.split(" ") for doc in corpus])
idf = log (n / (1 + df))
return idf- TF-IDF 구현
def build_dtm_with_tfidf(corpus: List[str]) -> pd.DataFrame:
dtm = build_dtm(corpus) # tf
idfs: List[float] = [
idf(term, corpus)
for term in dtm.columns
]
dtm_tfidf: np.array = dtm.to_numpy() * np.array(idfs) # 리스트, 혹은 넘파이 배열
return pd.DataFrame(data=dtm_tfidf, columns=dtm.columns)- TF-IDF와 DTM 비교
# build dtm, and one with
dtm = build_dtm(CORPUS)
dtm_tfidf = build_dtm_with_tfidf(CORPUS)
print(dtm)
print(dtm_tfidf)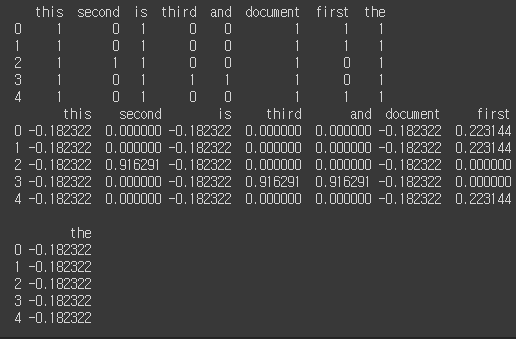
- TF-IDF와 DTM cosine 유사도 비교
# compare the two
print(cosine_similarity(dtm.to_numpy(), dtm.to_numpy()))
print(cosine_similarity(dtm_tfidf.to_numpy(), dtm_tfidf.to_numpy()))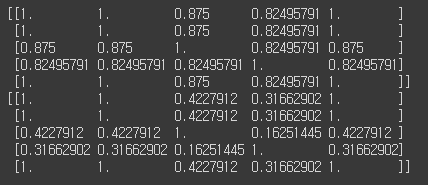
출처
광주 인공지능사관학교 - 김유빈 강사님

정리가 엄청 깔끔하네용
2편은 언제 업로드 해주시져?