컴퓨터 구조 기초
-
이 구조에 보기에 앞서 일반적으로 hello.c 소스 프로그램을 만들면 Compliation System을 통해서 실행가능한 object 파일로써 저장됨
-
이 실행가능한 파일을 Shell이라는 곳에서 명령어 입력을 해석해서 해당 명령을 수행하고 처리할 수 있게함, 리눅스 기준으로
./hello를 하면 실행가능한 파일로 보고 load가 되고 run이 됨 -
그러면 hello 프로그램은 실행이 되서
hello, world를 출력하고 사라짐, 그리고 shell은 사라질때까지 기다리고 다음 명령어 입력을 기다리는 식으로 진행이 됨
Compliation System?
Compliation System
Compliation System은 소스파일이 어떻게 컴파일러로 번역되어서 실행이 되어지는지 그 과정을 거치는 나타내는 시스템이라고 볼 수 있음
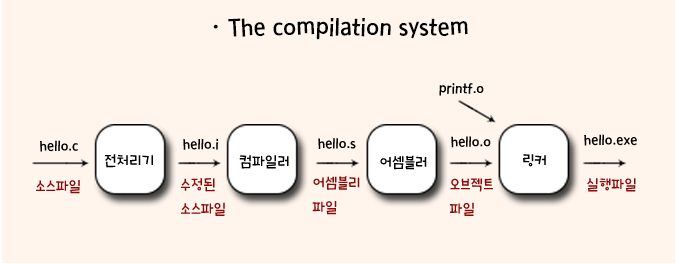
시스템 하드웨어 구성
- 위와 같이 기본적으로 시스템 하드웨어가 구성됨, 여기서 하나씩 알아보자면
Buses
-
시스템에서 실행시 buses라는 집합체를 통해서 정보의 bytes가 컴포넌트 사이에서 주고받아짐
-
버스는 words라고 불리는 bytes의 고정된 사이즈의 묶음을 전송하게끔 디자인되어 있음, 이 word의 bytes는 시스템마다 다양하게 구성됨
-
일반적으로 오늘날은 word의 크기는 4 bytes 혹은 8 bytes임(다른 사이즈도 존재함)
I/O Devices
-
I/O Devices는 외부와 연결할 수 있는 장치를 말함
-
일반적으로 입력을 받는 마우스와 키보드, 출력을 보여주는 디스플레이, 디스크 드라이브가 데이터와 프로그램을 저장하고 있음, hello 프로그램의 경우 디스크에 있는 것임
-
이 I/O Devices는 I/O bus에 controller와 adapter로 연결되어 있음, controller의 경우 그 자체 기기의 칩셋 혹은 시스템의 마더보드에 있는 것이고, adapter는 마더보드에 연결되어 있는 것임, 이 2개의 역할은 I/O bus와 I/O Device 간의 정보전달을 목표로 함
Main Memory
-
Main Memory는 프로세스가 프로그램을 실행하고 있는 동안 프로그램과 데이터를 가지고 있는 임시 저장소임
-
물리적으로 DRAM 칩의 집합체로 구성되어 있고 논리적으로는 0부터 시작하는 각각의 고유한 주소가 있는 linear array of bytes로 이루어짐
-
일반적으로 이런 machine instructions은 다양한 bytes로 구성할 수 있는 프로그램으로 구성되어 있음 즉, 이러한 데이터의 경우 프로그램의 타입에 따라서 매우 다양함
Processor
-
CPU혹은 Processor라고 부르는데 주로 Main memory에 저장되어 있는 명령을 해석하고 실행하는 엔진임
-
내부에는 word-size 저장소(레지스터)인 Program Counter(PC)가 있음
-
어떤 상황이든 PC는 main memory에 있는 기계어 명령을 가르킴(주소로 구성된)
-
전원이 켜지고 꺼질 때까지 프로세스는 PC가 가르키고 있는 명령을 반복적으로 수행하고 PC가 다음 명령을 가르키도록 업데이트를 함
-
PC가 메모리로부터 가르킨 명령을 읽고 명령어의 비트를 해석하며 명령어에 의해 쓰여진 단순한 실행을 수행하고 PC를 다음 명령어로 업데이트를 함
-
이러한 실행은 Main Memory, Register File, Arithmetic/Login Unit(ALU)를 계속 돌면서 수행이 됨
-
Register File은 각각의 고유한 값이 있는 word-size register의 집합체로 구성된 작은 저장 장치임, ALU는 새로운 데이터와 주소 값을 계산함
-
현대의 Processor는 더 복잡한 로직으로 돌아감
Word?
Word
여기서 워드 단위가 살짝 생소할 수 있는데 이는 그냥 컴퓨터 데이터 단위를 의미함, 데이터 크기 자체가 CPU나 레지스터나 크지 않기 때문에 워드 단위를 쓰는 것
bit < byte < word로 볼 수 있는데 이는 컴퓨터 설계시 정해지는 메모리 기본 단위라 컴퓨터마다 다름 애플의 경우 8비트 컴픁터는 1바이트가 1워드고 IBM 컴퓨터에선 16비트 2바이트가 1워드였음
캐시
-
시스템은 많은 시간을 정보를 하나의 곳에서 다른 곳으로 옮기는데 씀
-
hello program의 명령어는 원래 disk에 저장되어 있지만, 프로그램이 load될 때, main memory로 복사됨, processor가 프로그램을 실행하면 명령어는 main memory에서 processor로 복사가 됨
-
hello,world\n데이터는 처음엔 disk에 있었지만 main memory로 복사되고 그리고 display device까지 복사됨 -
하지만 이런 복사가 실제 프로그램 작업을 늦춰지는 것을 야기할 수 있음, 시스템 디자이너는 이러한 복사를 가능한 빨리 수행하도록 설계를 함
-
물리적인 이유로 크기가 큰 저장장치는 작은 저장장치보다 느리고 빠른 장치들은 느린 장치보다 설계비용이 더 들어감(disk drive의 경우 main memory보다 1000배 가량 크지만, processor가 memory보다 word를 읽어 오는 것보다 10000000배 더 길게 걸린다고 함)
-
register file은 main memory보다 훨씬 적은 바이트를 가지고 있지만 processor는 register file로부터 memory보다 100배 정도 빠르게 읽어올 수 있음
-
이러한 processor-memory의 차이는 지속적으로 증가하였고 main memory를 빠르게 만드는 것보다 processor를 빠르게 만드는게 더 쉽고 비용을 저렴하게 할 수 있음
-
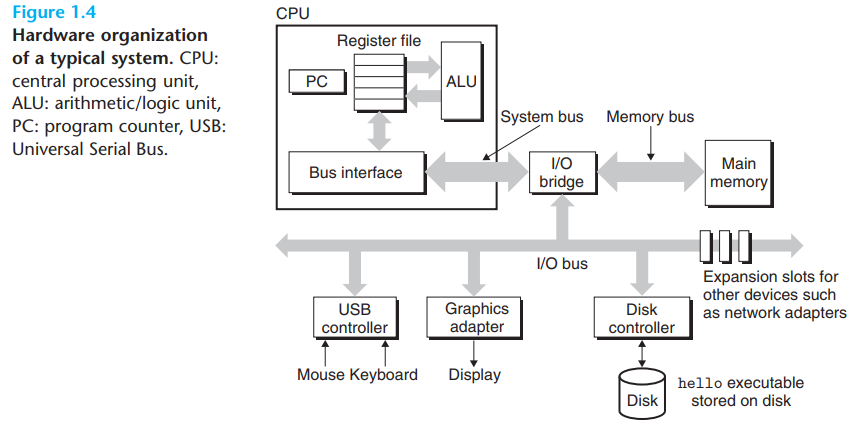
이런 문제를 처리하기 위해서 더 작고 빠른 저장장치인 cache memories를 통해 processor가 가까운 시간안에 정보를 필요로하는 상황에서 임시적으로 저장하는 곳을 만듬
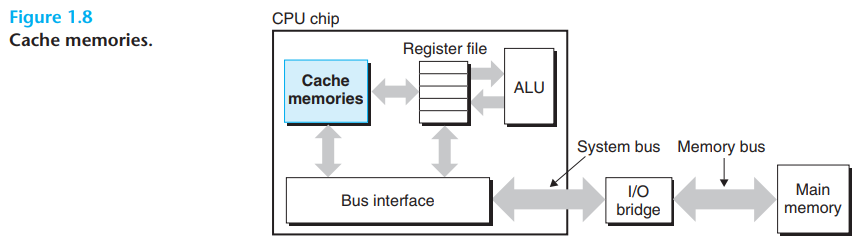
메모리 계층 구조
- 메모리는 아래와 같이 계층적 구조를 가짐
-
밑으로 갈수록 느려지고 커지고 비용이 줄고 위로 가면 그 반대가 됨
-
각각의 계층이 서로의 cache가 되고 접근 속도에 있어서 보완을 해줄 수 있음
-
이런식으로 localized 된 곳에서 데이터와 코드를 접근하게 할 수 있어서 큰 memory와 빠른 속도에 대한 특징을 동시에 효과를 볼 수 있음
-
cache가 자주 접근해서 data를 가지고 있으면 빠른 cache를 활용해서 memory 기능을 더 확실하게 활용할 수 있음, 이를 통해서 프로그램의 성능을 더 끌어올릴 수 있음
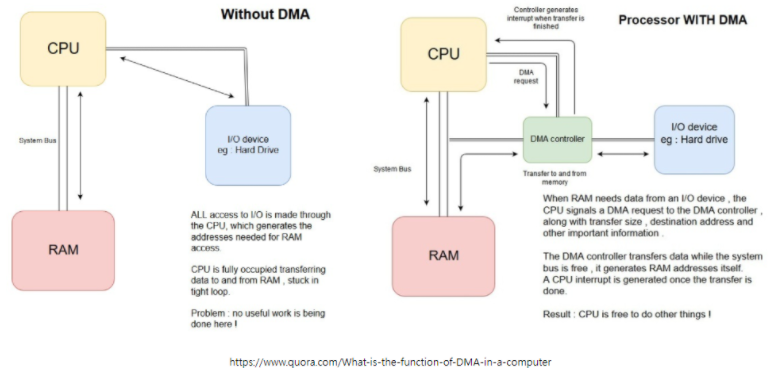
추가 : DMA(Direct Memory Access)
DMA
여기서 Cache도 큰 역할을 하지만 내부적으로 DMA라는 기술도 활용을 할 수 있음
이는 메모리에 직접 접근하여 읽거나 쓸 수 있도록 하는 것을 의미하는데 이는 CPU 개입 없이 I/O 장치와 기억장치 사이의 데이터를 전송하는 접근 방법이라는 것임
CPU가 해야할 일을 DMA 장치가 해줌으로써 그만큼의 CPU 효율을 늘릴 수 있음
운영체제
- 예시로써 계속 언급하는 hello program이 load 되고 실행되는 과정에서 운영체제가 제공하는 서비스에 의존함

-
위와 같이 운영체제(Operating System)의 경우 Application Program과 Hardware사이에 위치해 있음, 이는 Application Program이 Hardware를 조작하는 모든 시도는 운영체제(Opearting System)을 거친다는 것을 의미함
-
운영체제(Opearting System)는 실행중인 Application이 Hardware를 오용하는 것을 보호하고 저수준의 hardware를 다룰 때 복잡하고 완전히 다른 것을 조작을 할 때 간단하고 규겨고하된 매커니즘을 Application에 제공하는 두 가지 목표가 있음
-
이런 목표를 위해서 아래와 같이 추상화(Abstraction)을 이룸
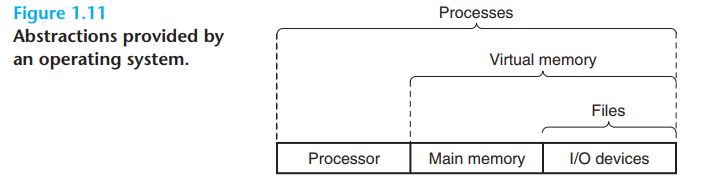
추상화(Abstraction)?
추상화(Abstraction)
정의를 말하면 복잡한 자료, 모듈, 시스템 등으로부터 핵심적인 개념 또는 기능을 간추려 내는 것을 말함
즉 Hardware의 접근과 처리를 Files, Processes, Virtual Memory등의 추상화를 통해서 활용을 함을 의미함, 정의 그 자체를 생각하면 됨 위의 구조도에 맞게 각각 추상화를 한 것
Processes
-
예시로 든 hello program을 실행을 하면 운영체제가 마치 program이 시스템에서 오직 하나만 돌아가는 것처럼 보여줌 즉, processor, main memory, I/O devices를 독점적으로 사용하게끔 하는것처럼 보이게 함
-
이렇게 보이는 이유가 process라는 개념에 의해서 그렇게 된 것임, 이 process는 실행되는 프로그램에 대한 운영체제의 추상화임
-
여러 개의 process들은 같은 시스템에서 동시에 실행될 수 있고 각각의 process는 하드웨어의 사용을 독점적으로 쓰는 것처럼 보임
-
Concurrently 동시성은 하나의 process에서의 명령이 다른 process의 명령에 interleave하는 것을 의미함
-
대부분의 시스템에서는 CPU가 그들을 실행시키는 것보다 더 많은 process들이 실행되고 있음
-
전통적인 시스템에서는 오직 한 번에 하나의 프로그램을 실행시켰지만, 새로운 multi-core processors는 여러개의 프로그램을 동시에 실행시킬 수 있음
-
단일 CPU는 processor가 switch함으로써 여러개의 processes들이 동시에 실행되는 것처럼 보임
-
운영체제가 이러한 interleaving한 기법을 Context Switching이라고 함
-
운영체제은 process가 실행시키기 위해서 정보의 모든 상태를 추적을 함, 이 상태를 Context라고 함
-
Context에서는 현재 PC(Program Counter)의 상태값, register file, main memory의 구성상태를 포함함
-
이 Context Switch와 과정을 본다면 단일 process를 위해서 code를 실행하면, 운영체제가 현재 process에서 새로운 process로 바꾸려고 결정했을 때, 현재 process의 context를 저장하고 새로운 process의 context를 가지고 오는 context switch를 실행함, 그리고 새로운 process에 control을 넘겨줌
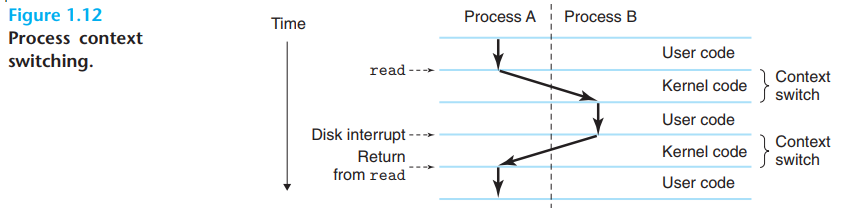
-
이 과정을 hello program의 실행과정과 관련해 생각해본다면 shell process와 hello process가 존재하는데 처음엔 shell process가 혼자서 실행이 되고 명령어 입력을 기다림, hello program 실행을 요청하면 shell은 요청을 수행받아 system call이라는 특별한 함수를 불러일으켜 운영체제의 control을 넘김
-
운영체제는 shell context를 저장하고 hello process와 context를 생성함, 그리고 control을 hello process에 넘김, 그리고 hello가 끝났을 때 shell process의 context를 다시 불러와 control을 넘기고 다음 명령어를 기다림
-
이 process간의 변환은 운영체제에서 kernel이 그 역할을 함, kernel은 운영체제 code의 일부로 memory에 항상 상주해 있음
-
Application Program의 action이 파일을 읽거나 쓰는 것 같이 운영체제를 필요로 한다면 특별한 system call 명령어가 실행되어 kernel로 control을 넘김, 그러면 kernel은 요청된 실행을 수행하고 Application Program을 return함
-
Kernel은 분리된 process가 아님, 대신 code와 data 구조의 집합체로 시스템이 모든 processes를 관리하는데 사용함
Concurrency? 멀티 프로세스? 멀티코어? 병렬?
Concurrency
Concurrency의 사전적 의미는 병행, 동시에 처리하는 것을 말함
이게 자칫 병렬적, 병렬도 동시에 하는거라고 생각해서 헷갈릴 수 있는데 위에서 말한 Concurrency는 단일 CPU 환경에선 하나의 프로세스가 아래와 같이 여러 가지 task를 동시에 수행하는 것임
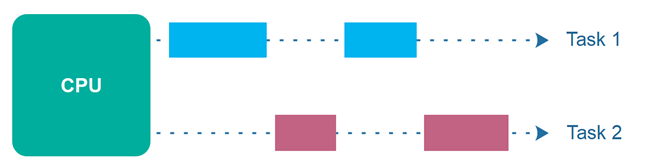
여기서 병렬적 Parallel은 아래와 같이 볼 수 있음
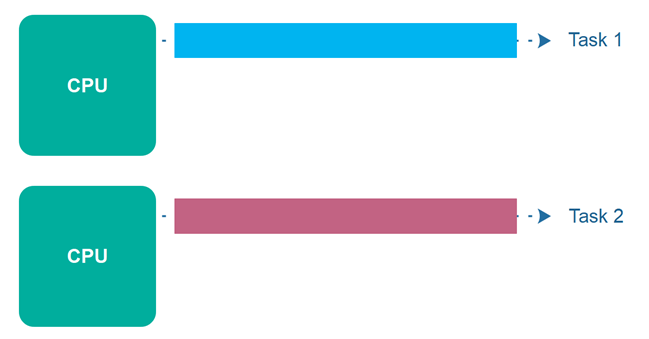
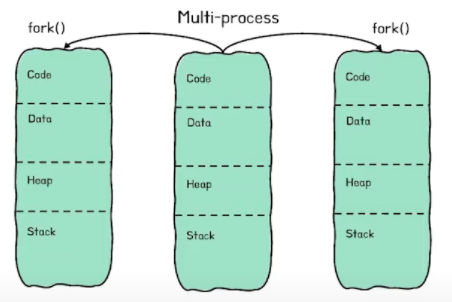
멀티 프로세스, 멀티코어 프로세서
여기서 멀티 프로세스는 아래와 같이 여러개의 프로세스가 이루어져서 일을 하는 것을 의미함
그리고 멀티코어 프로세서는 다른 의미인데 여기서 프로세스(Process)는 위에서 본 바와 같이 일을 처리하는 Process를 의미하는 것이고
프로세서(Processor)의 경우 프로세스(Process)가 동작하도록 하는 하드웨어를 뜻하는 것임 즉, 멀티코어 프로세서는 우리가 생각하는 CPU를 흔히 통치하는 것임, CPU가 종류에 따라서 듀얼코어, 쿼드코어, 옥타코어라고 사양을 말할때 말하듯이
그럼 멀티코어 즉, 그런 코어가 여러개여서 이러한 멀티 프로세스 작업을 더 수월하게 할 수 있는 것임
Thread
-
Process가 단일한 control flow를 가지고 있다고 생각하지만 현대 시스템에서는 process는 threads라고 불리는 다양한 실행 유닛으로 구성되게 할 수 있음
-
Threads는 각각 process의 context를 실행시킬 수 있고 같은 코드와 global data를 공유할 수 있음
-
Threads는 각각 Network servers에서 동시성을 필요로 하기 때문에 중요한 프로그래밍 모델 중 하나임
-
여러개의 processes보다 여러개의 threads 사이의 데이터를 공유하는 것이 더 쉽기 때문임(그리고 threads가 processes보다 더 효율적임)
-
Multiple Processor가 이용 가능할 때 Multi-threading은 프로그램을 더 빠르게 할 수 있는 방법 중에 하나임
Virtual Memory
-
Virtual Memory는 각각의 process가 main memory를 독점적으로 사용하는 것처럼 보이게 함
-
각각의 process는 Virtual Address Space라고 알려진 같은 표준의 memory를 가지고 있음
-
Linux기준 아래와 같이 Virtual Address Space를 가짐
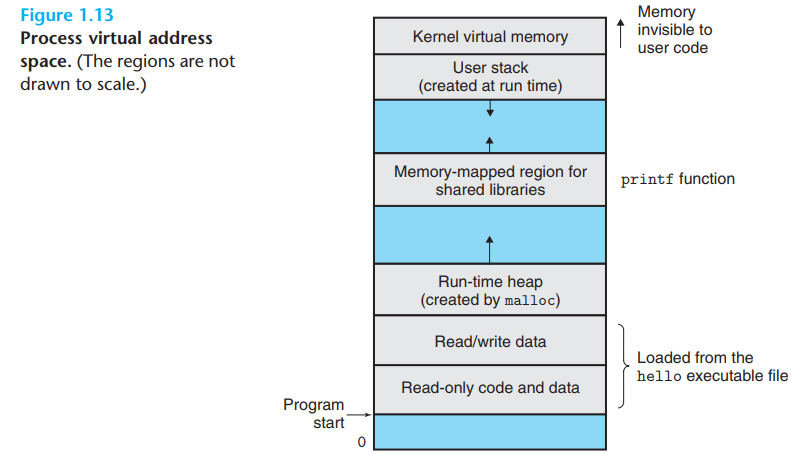
-
최상단에는 모든 process가 공통인 opearting system에서의 data와 code가 있음, 아래로 갈수록 user process에 의해 정의된 code와 data를 가지고 있음, addresses는 위로 올라가는 구조임
-
이 Virtual Address Space 각각 process가 잘 정의된 구역의 집합체로 각각이 특정 목적을 가짐
Program code and data
- code와 data는 실행가능한 파일의 contents로부터 직접적으로 초기화 됨
Heap
-
위의 code와 data는 바로 run-time heap으로 넘어감, 이 영역은 process가 시작되면 사이즈가 고정이 됨
-
이 영역은 run time 시점에서 다이나믹하게 늘리고 줄일 수 있는 영역임
Shared libraries
- 중간에서 code와 data를 shared libraries를 위해서 잡아둔 곳임(표준 C 라이브러리와 같이)
Stack
-
Compiler가 함수 호출을 실행하기 위해서 사용을 하는 곳임
-
heap과 같이 프로그램이 실행되는 동안 다이나믹하게 늘리고 줄일 수 있는 영역임
-
특별하게 함수를 호출하는 순간마다 stack이 늘어나고 함수가 return 될 때마다 줄어듬
Kernel Virtual Memory
- Application Program은 직접적으로 접근을 할 수 없고 kernel을 통해서만 이쪽에 대한 작업을 수행할 수 있음
과정
-
이런식으로 Virtual Memory가 작업을 위해서는 Hardware와 Operating System Software 그리고 Processor가 생성한 모든 주소를 hardware가 변환하는 작업을 포함하여 복잡한 상호작용을 필요로 함
-
기본 아이디어는 disk의 process's virtual memory의 contents를 저장하고 그때 disk를 위해 cache로써 main memory를 사용하는 것임
Files
-
File은 bytes의 sequence임, 모든 I/O device는 disk, keyboard, display, network마저도 File로 모델링 됨
-
시스템의 모든 입출력은 Unix I/O라고 알려진 시스템콜의 작은 집합을 사용함으로써 File을 읽고 씀
-
이 개념은 Application에 시스템이 가지고 있는 다양한 모든 I/O Devices의 표준화된 규격을 제공할 수 있음
-
이를 통해서 Application Programmer는 세부적인 사항을 알지 못하더라도 조작을 할 수 있게 되는 것임
Network
-
현대 시스템에서는 네트워크를 통해서 다른 시스템들과 연결되어 있음
-
단일 시스템의 관점에서 네트워크 역시 I/O Devices의 일부로 볼 수 있음
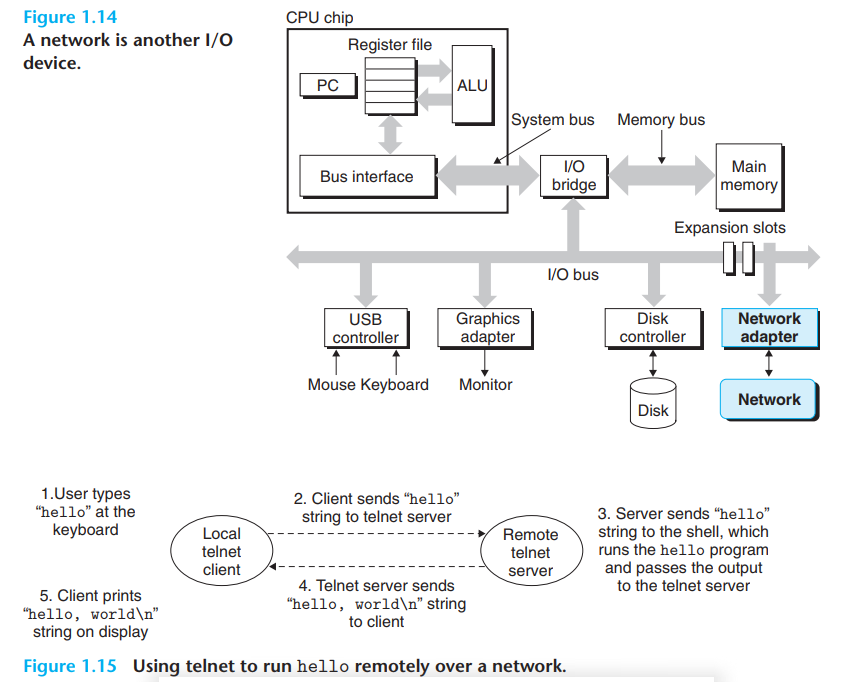
-
시스템이 main memory로부터 bytes의 연속성을 복사해 network adapter로 보낼 수 있음, 이 data 흐름을 마치 local disk drive로 보내는 것과 유사함
-
그리고 시스템은 이렇게 보내진 data를 읽고 main memory로 복사할 수 있음
-
인터넷의 발달로 인해서 이런식으로 정보를 하나의 기기에서 다른 곳으로 복사하는 것이 중요해짐, email, instant messaging, World Wide Web, FTP, telnet등이 네트워크를 통한 위에서 설명한 흐름이 다 기반이 됨
-
위의 그림은 telnet을 통한 네트워클르 기반으로 통신을 하는 예시임(Figure 1.15), Remote Shell이 hello program을 실행시키는 것임
-
이렇게 Clients와 Servers가 일반적으로 주고 받는 방식이 모든 Network Application의 기본임
