여기엔 강의에 나오는 내용 위주로 정리하고 수학적인 내용은 따로 봐야겠다..
결정 트리 개요
머신러닝 분류 알고리즘 중 하나인 결정 트리 (Decision Tree)를 알아보자
학교에서 배울 땐 '의사결정나무'로 배운 것 같음
대충 스무고개를 생각하면 됨
if-else를 자동으로 찾아내 예측을 위한 규칙을 만드는 알고리즘!
- 루트 노드: 최상위에 있는 노드
- 규칙 노드: 중간에 있는 노드로
규칙이 들어있음- 리프 노드: 마지막 노드로
최종적으로 결정된 분류값이 들어있음
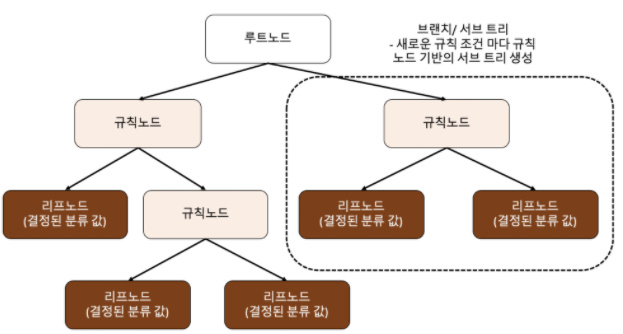
최종적으로 최대한 균일한 데이터 세트를 구성할 수 있도록 해야함!
균일한 게 뭔데? -> 최대한 같은 데이터(Label)끼리만 들어있는 것!
균일도 측정
균일도를 어떻게 측정하는데?
정보 이득 (Information Gain)
Entropy 개념을 기반으로 함
Entropy: 무질서도
- 서로 다른 값이 섞여있으면 Entropy가 높음
- 서로 같은 값이 섞여있으면 Entropy가 낮음
정보이득 지수 = 1 - Entropy 지수
서로 같은 값이 섞여있으면 Entropy가 낮으니까 정보 이득은 높을 것임
따라서 정보 이득 지수는 높을수록 좋음!
지니 계수 (Gini Index)
원래 경제학에서 불평등 지수를 나타낼 때 사용하는 계수
지니 계수가 낮을수록 데이터의 균일도가 높음
따라서 지니 계수는 낮을수록 좋음!
데이터 집합의 모든 아이템이 같은 분류에 속하는지 확인
If True: 리프 노드로 만들어서 분류 최종 결정
else: 데이터를 분할하는 데 가장 좋은 속성과 분할 기준 찾음 (정보 이득 or 지니 계수 이용)
-> 해당 속성과 분할 기준으로 데이터 분할하여 Branch 노드 생성
-> Branch 노드에 대해 처음으로 돌아가서 재귀적으로 모든 데이터의 집합의 분류가 결정될 때 까지 수행
결정 트리 모델의 특징
균일도라는 룰을 기반으로 해서 알고리즘이 쉽고 직관적
균일도만 신경쓰면 되니까 특별한 경우를 제외하면 Feature의 스케일링과 정규화 같은 전처리 필요 없음
단, 과적합 발생 위험이 높아서 정확도가 떨어짐!
과적합을 어떻게 극복할까? -> 파라미터 튜닝!
결정 트리의 파라미터와 과적합
결정 트리 파라미터를 알아보자
파라미터 조정은 거의 과적합 제어를 위해서 하는 것임
| 파라미터 | 설명 |
|---|---|
| min_samples_split | 노드를 분할하기 위한 최소한의 샘플 데이터 수 과적합을 제어하는 데 사용됨 계속 분할하다가 데이터 수가 지정한 값에 도달하면 멈추는 것! 기본 값은 2 |
| min_samples_leaf | 리프 노드가 되기 위한 최소한의 샘플 데이터 수 과적합을 제어하는데 사용됨 분할할 때 최종적으로 데이터 수가 지정한 값에 도달하도록 조건을 설정해주는 것! 비대칭 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있어서 이 경우는 작게 설정 |
| max_features | 최적의 분할을 위해 고려할 최대 Feature 개수 기본 값은 None으로 모든 Feature에 대해 진행함 iris 데이터 같이 Feature가 적으면 상관 없는데 너무 많으면 조절 필요 int형으로 지정하면 대상 Feature의 개수 float형으로 지정하면 전체 피처 중 대상 피처의 비율 sqrt (또는 auto): 전체 Feature 수의 제곱근 만큼 선정 log: 전체 feature의 log2 만큼 선정 |
| max_depth | 트리의 최대 깊이 지정 안 하면 완벽하게 균일하게 될 때까지 분할 (모두 같은 Label만 있을 때 까지) |
| max_leaf_nodes | 리프 노드의 최대 개수 |
글로만 보면 이해가 잘 안 된다.
시각화하면서 파라미터를 다시 한번 봐보자
시각화에는 Graphviz 패키지를 사용한다. 설치 과정이 좀 있는데 그건 생략함
scikit-learn에서 DecisionTreeClassifier Estimator를 쓰는 건 앞에서 많이 해봤음
iris 데이터로 파라미터 지정 없이 fit()까지 진행
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 붓꽃 데이터를 로딩하고, 학습과 테스트 데이터 셋으로 분리
iris_data = load_iris()
X_train , X_test , y_train , y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=11)
# DecisionTreeClassifer 학습.
dt_clf.fit(X_train , y_train)skelarn.tree의
export_graphviz를 사용하면 tree가 어떤 구조로 이루어져 있는지 확인할 수 있음
구조에 대한 파일을 생성함
from sklearn.tree import export_graphviz
# tree가 어떤 구조로 이루어져 있는지 확인할 수 있게 해줌
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names , \
feature_names = iris_data.feature_names, impurity=True, filled=True)
graphviz를 통해서 시각화 진행
import graphviz
# 위에서 생성된 tree.dot 파일을 Graphviz 읽어서 Jupyter Notebook상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)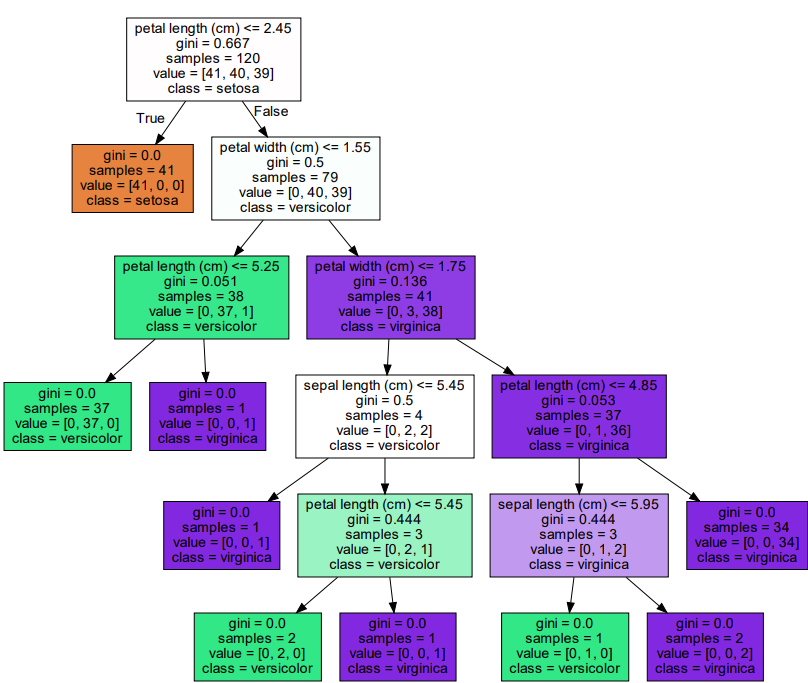
- 'petal length(cm) <= 2.45' 같이 feature의 조건이 있는 것은 자식 노드를 만들기 위한 규칙 조건
- 위 같은 조건이 없으면
리프 노드- samples는 현재 규칙에 해당하는 데이터 건수
- value는 Label 기반의 데이터 건수, [40, 40, 39] -> 0 Label 40개, 1 Label 40개, 2 Label 39개
param: max_depth
max_depth (결정 트리의 최대 깊이)를 3으로 해보자
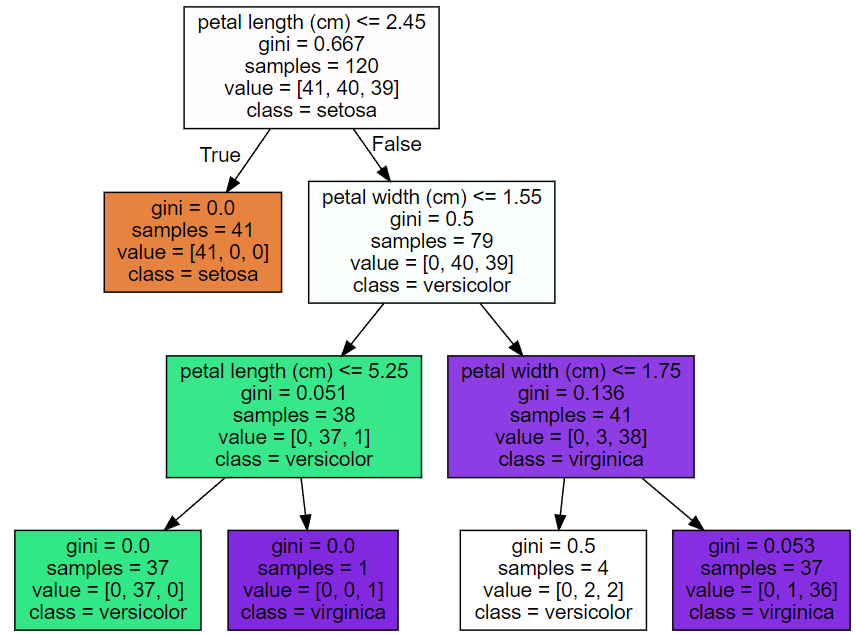
제약이 없을 때는 전부다 균일하게 될 때까지 분할했는데
지금은 value가 [0, 2, 2], [0, 1, 36] 같은 것들이 있어도 설정한 depth에 도달하면 멈춤!
마지막에 있는 노드들이리프 노드가 된다.
param: min_samples_split
min_samples_split을 4로 해보자
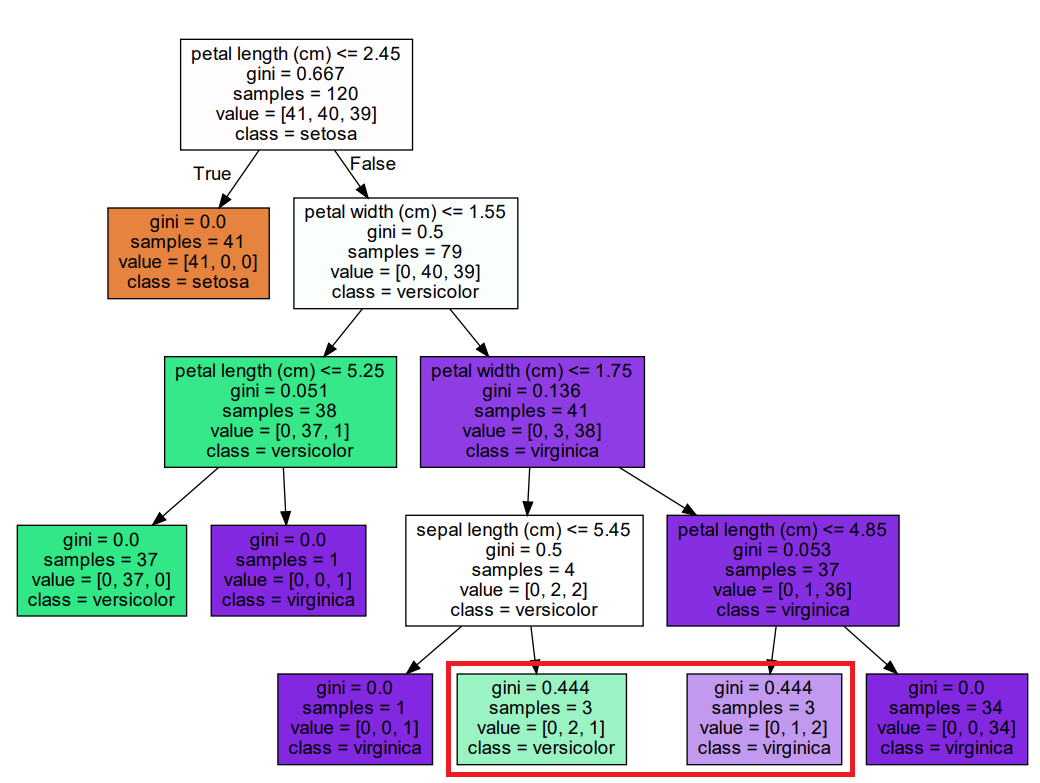
빨간 네모를 보자
아직 균일하지 못하지만 samples가 우리가 설정한 4보다 작아져
분할을 멈추고 리프 노드가 되었다!
param: min_samples_leaf
min_samples_leaf를 4로 해보자 (위에 것과 헷갈리지 말자)
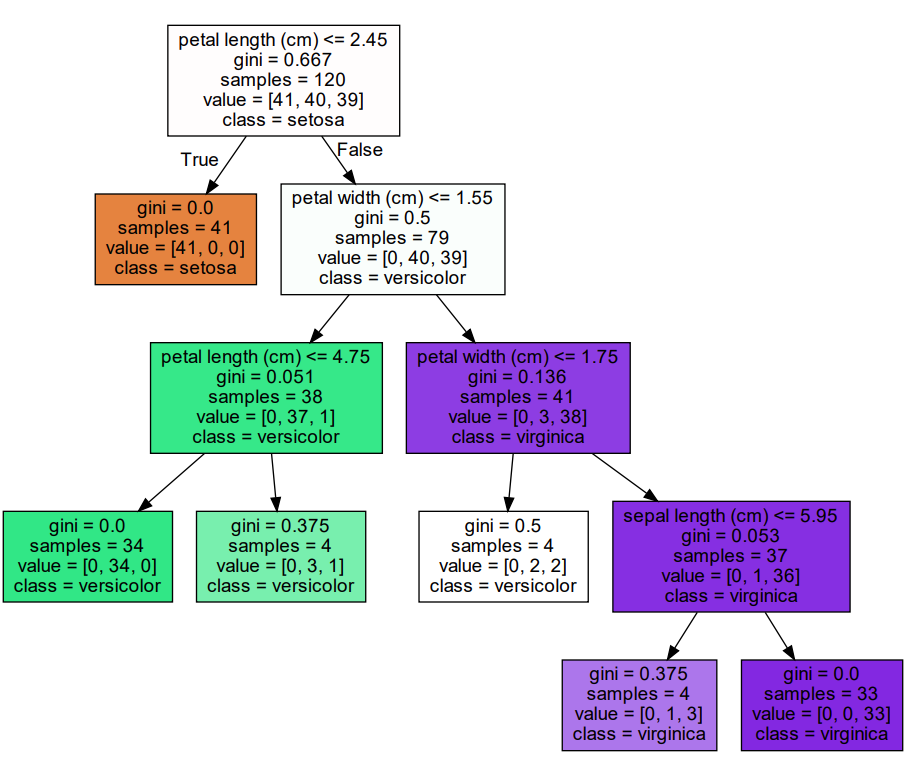
리프 노드가 될 수 있는 최솟값의 건수를 지정한 것이다.
4로 지정했으니까 리프노드가 4보다 작게 나오지 않게 분할하는 규칙을 변경한다!
( <= n ) 이런 거를 조정해준다는 듯
feature_importances
scikit-learn은 규칙을 정하는 데 있어 Feature의 중요한 역할 지표를 feature_importances_로 제공
feature_importances_는 ndarray 형태로 값을 반환하며 Feature 순서대로 값을 할당
seaborn을 이용해서 변수별 중요도를 시각화해보자
import seaborn as sns
import numpy as np
%matplotlib inline
# feature importance 추출
print("Feature importances:\n{0}".format(np.round(dt_clf.feature_importances_, 3)))
# feature별 importance 매핑
for name, value in zip(iris_data.feature_names , dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value))
# feature importance를 column 별로 시각화 하기
sns.barplot(x=dt_clf.feature_importances_ , y=iris_data.feature_names)Feature importances:
[0.006 0. 0.546 0.448]
sepal length (cm) : 0.006
sepal width (cm) : 0.000
petal length (cm) : 0.546
petal width (cm) : 0.448
그런데 이것이 Feature의 중요도에 절대적인 기준이 될 수는 없음! 그 이유는 분류 끝날 때 나온다고 함
결론
이렇게 결정 트리는 전처리에 있어서 편하지만 과적합을 잘 생각해줘야 함
적절한 파라미터 조정으로 제약을 걸지 않으면 너무 train 데이터 친화적으로 학습을 해서
막상 test 데이터에는 안 맞는 경우가 많이 생길 수 있음!
다음 글에서 실습해보고 결정트리 마무리
