사이킷런으로 머신러닝
1.2022 여름방학 머신러닝 공부하기

사회조사분석사 2급 필기필기 공부하면서 기초통계학 빵꾸난 부분 보충하기졸업 토익이번 방학에는 따야 됨..머신러닝 공부하기파이썬 머신러닝 완벽 가이드 교재 끝까지 잘 따라가보기빅데이터분석기사 실기 시험 준비해보니까 확실히 직접 코드 짜고 실습을 해봐야 흥미도 생겨서 더
2.[ML] Intro - scikit-learn, XGBoost, LightGBM 설치

Anaconda를 기반으로 진행함윈도우: Anaconda Prompt를 관리자 권한으로 실행맥: 터미널에서 진행앞으로 'ML' 이라는 가상환경에서 진행함예제를 그대로 따라가기 위해 버전을 고정한 설치 방법예전에는 pip install이 잘 안 됐는데 요즘은 잘 된다고
3.[ML] Intro - 머신러닝을 위한 NumPy 기본
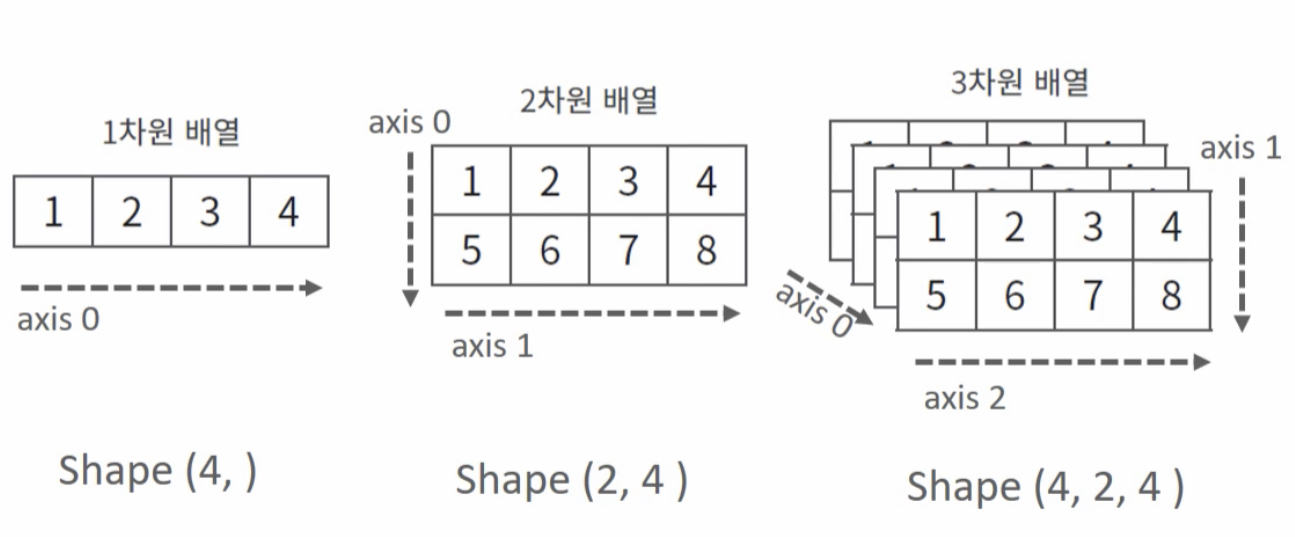
ndarray: N 차원 (Dimension) 배열 (Array) 객체파이썬 기본 list도 있는데 이걸 안 쓰고 왜 굳이 ndarray?파이썬 list로는 대용량 데이터를 처리하기 힘듦, ndarray는 훨씬 빠르게 처리scikit-learn도 ndarray 기반으로
4.[ML] Intro - 머신러닝을 위한 Pandas 기본
Pandas는 빅데이터분석기사 실기 준비하면서 꽤 익숙해진 상태라 헷갈리는 것들 위주로 정리
5.[ML] Intro - iris 품종 예측하기 - 개요

scikit-learn 왜 scikit-learn을 사용하지? > 파이썬에서 정형데이터로 머신러닝을 구현하는 것은 대부분 scikit-learn으로 함 사용하기 쉽고 가장 파이썬스러운 API 오랜 기간 실전 환경에서 검증됐으며, 매우 많은 환경에서 사용되는 성숙한 라이
6.[ML] Intro - iris 품종 예측하기 - 최소한의 머신러닝
여기서는 최소한의 코드만 사용해서 파이썬에서 scikit-learn으로 iris 품종을 어떻게 예측하는지를 본다.sklearn은 iris 데이터세트를 내장하고 있다.여기서 사용할 모델은 DecisionTreeClassifier이다.train/test 데이터를 나누는 기
7.[ML] Intro - iris 품종 예측하기 - 교차 검증
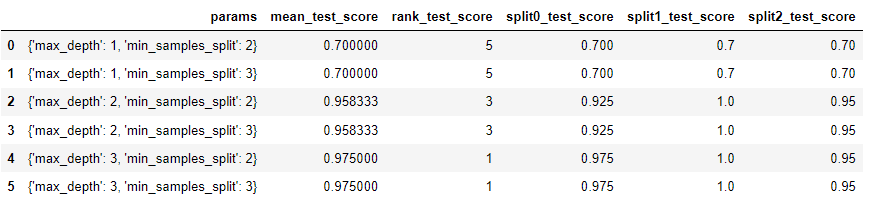
교차 검증 개요 학습 데이터세트를 다시 학습 데이터세트 / 검증 데이터세트로 나눔 학습(train) 데이터세트: 학습을 위한 데이터 검증(validation) 데이터세트: 학습된 모델의 성능을 일차 평가 평가(test) 데이터세트: 모든 학습/검증 과정이 완료된 후
8.[ML] Intro - iris 품종 예측하기 - 데이터 전처리
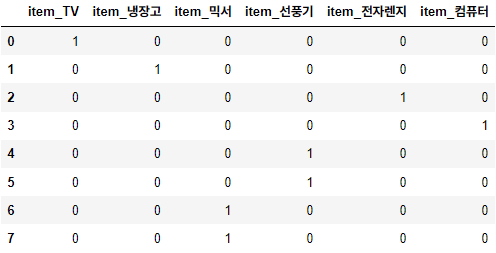
데이터 전처리 개요 데이터 전처리의 종류 데이터 클린징 결손값 처리 (Null/NaN 처리) 데이터 인코딩(레이블, 원-핫 인코딩) 데이터 스케일링 이상치 제거 Feature 선택, 추출 및 가공 데이터 인코딩 머신러닝 모델은 문자열 값을 허용하지 않음 문자열 값을
9.[ML] Intro - 타이타닉 생존자 예측하기

지금까지 배운 것을 종합해서 타이타닉 데이터를 이용한 생존자 예측하기 >변수 설명 PassengerId : 각 승객의 고유 번호 Survived : 생존 여부 0 = 사망 1 = 생존 Pclass : 객실 등급 - 승객의 사회적, 경제적 지위 1 = Upper 2 =
10.[ML] Intro - Wine 품질 예측하기
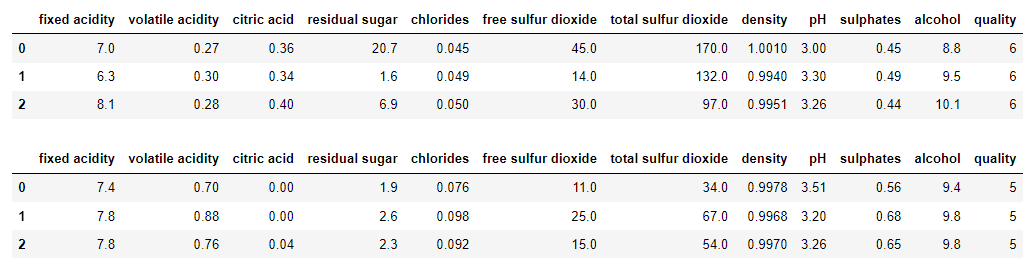
강의에서는 다루지 않은 데이터 처음부터 혼자 짜보기 지난 학기에 나를 괴롭혔던 Wine 데이터를 활용하기로 했다. 데이터 출처: https://archive.ics.uci.edu/ml/datasets/wine+quality 사전 작업 >레드 와인, 화이트 와인으
11.[ML] 평가 - 분류 성능 평가지표 개요와 정확도 (Acurracy)

지금부터는 분류에 대한 성능 평가지표를 소개한다. 분류의 성능 평가 지표 개요 정확도 (Acurracy) 오차행렬 (Confusion Matrix) 정밀도 (Precision) 재현율 (Recall) F1 스코어 ROC AUC 정확도는 한계를 가지고 있어서 이진 분
12.[ML] 평가 - 오차 행렬 (Confusion Matrix), 정밀도 (Precision), 재현율 (Recall)
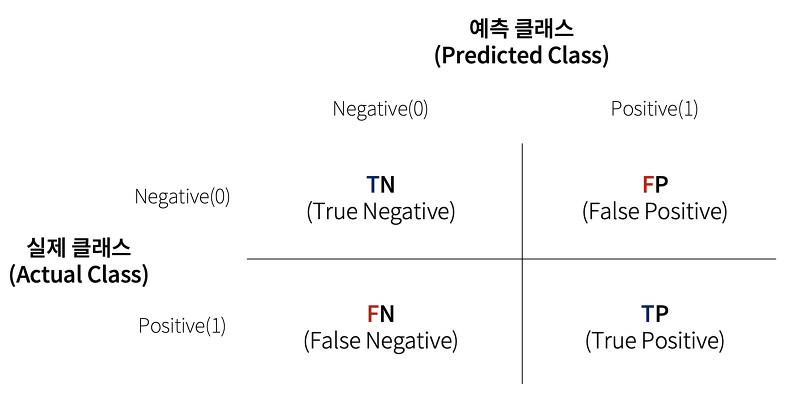
앞에서 확인한 것처럼 정확도에는 한계가 존재한다.다른 성능 평가지표들도 알아보자.오차 행렬, 혼동 행렬, 오분류표, Confusion Matrix학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지 함께 보여주는 지표뒤에 붙은 N, P가 예측이고, 앞에 붙은 T
13.[ML] 평가 - 정밀도 (Precision)와 재현율 (Recall)의 Trade-off
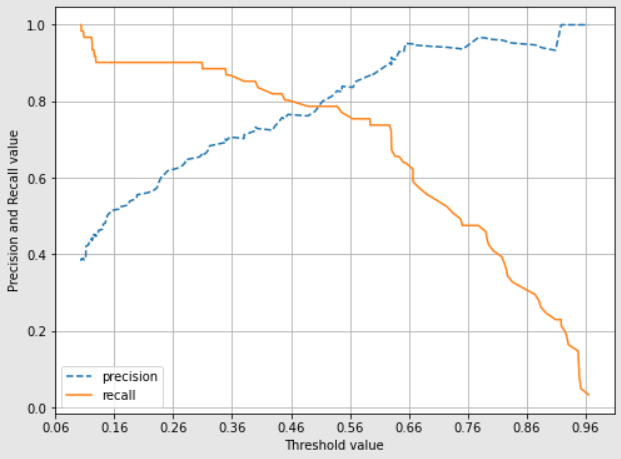
정밀도와 재현율의 Trade-off 개요 Trade-off: 한 쪽이 높아지면 한 쪽이 낮아짐 정밀도와 재현율이 이런 관계를 가지고 있음 >정밀도가 더 중요한 경우 실제 Negative 음성인 데이터 예측을 Positive 양성으로 잘못 판단하게 되면 업무 상
14.[ML] 평가 - F1 Score와 ROC-AUC
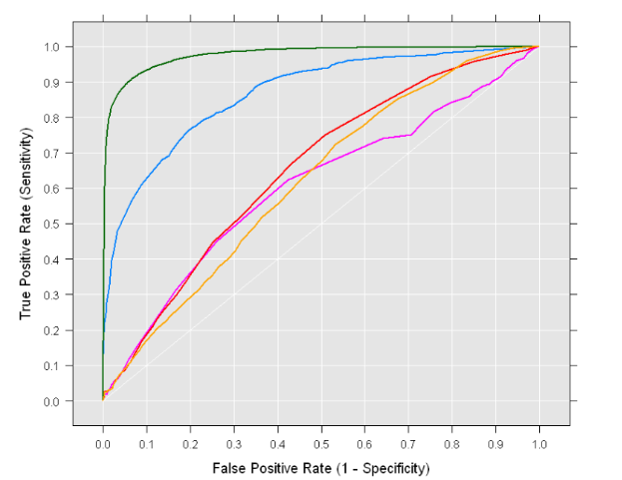
F1 Score는 재현율과 정밀도에 밀접한 관련이 있음관련 내용을 먼저 살펴보자$$Precision = \\frac{TP}{FP+TP}$$$$Recall = \\frac{TP}{FN+TP} $$정밀도를 100%로 만드는 법확실한 기준이 되는 경우만 Positive로 예
15.[ML] 평가 - 피마 인디언 당뇨병 예측

이번엔 피마 인디언 당뇨병 데이터를 이용한 분류 예측을 한다. 지난 학기 데이터마이닝에서 교수님이 활용한 데이터인데, 다시 보니까 반갑다. 데이터 출처: https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-dat
16.[ML] 분류 - 분류 (Classification) 개요

이제부터 분류 (Classification) 에 대해서 알아보자지도학습은 크게 분류와 회귀로 나눠짐참고로 앞에서 한 평가지표들은 모두 분류에 적용되는 것!회귀의 평가지표(MSE, RMSE, MAE, R-Square, ...)는 회귀 파트에서 다루겠음...
17.[ML] 분류 - 결정 트리 (Decision Tree)
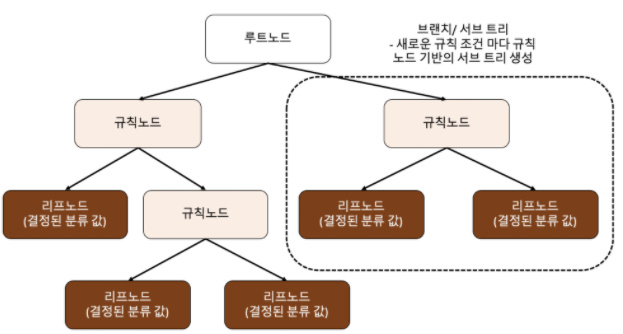
머신러닝 분류 알고리즘 중 하나인 결정 트리 (Decision Tree)를 알아보자학교에서 배울 땐 '의사결정나무'로 배운 것 같음대충 스무고개를 생각하면 됨if-else를 자동으로 찾아내 예측을 위한 규칙을 만드는 알고리즘!루트 노드: 최상위에 있는 노드규칙 노드:
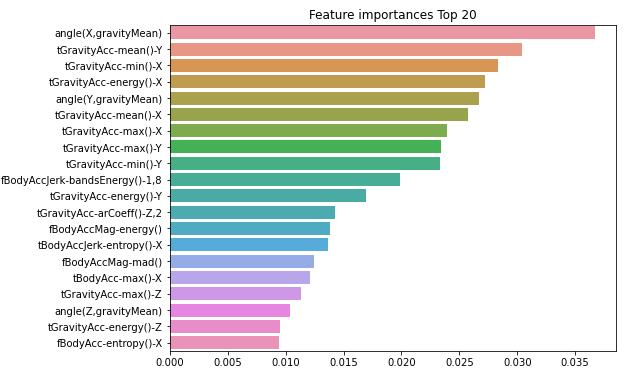
18.[ML] 분류 - 사용자 행동 인식 데이터를 이용한 결정 트리 실습
데이터 출처: https://archive.ics.uci.edu/ml/datasets/human+activity+recognition+using+smartphones사용자 행동 인식 데이터를 이용해서 결정 트리를 실습해보자이 데이터는 30명에게 스마트폰 센서를
19.[ML] 분류 - 앙상블 학습 (Ensemble Learning)과 보팅 (Voting)
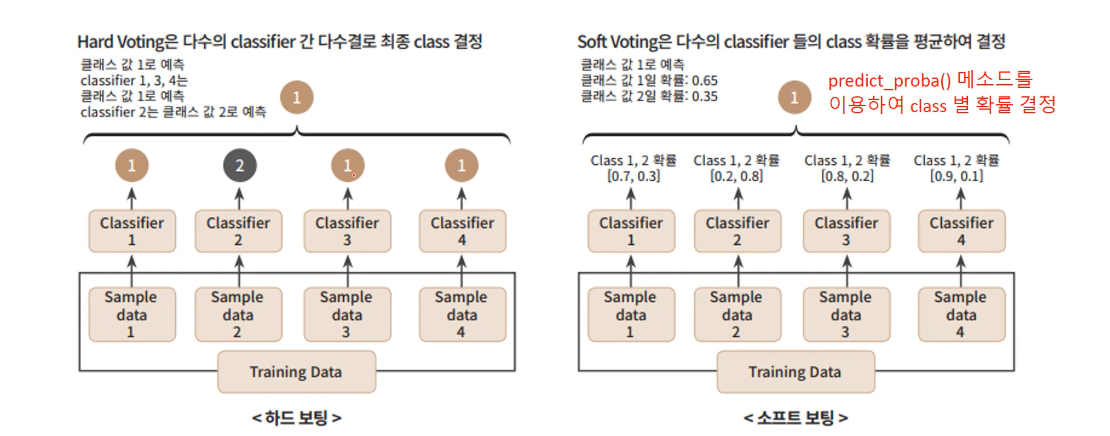
앙상블 학습: 분류를 할 때 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법앙상블 학습의 유형으로는 여러 가지 종류가 있음전통적인 세 가지 방법보팅 (Voting)배깅 (Bagging)부스팅 (Boosti
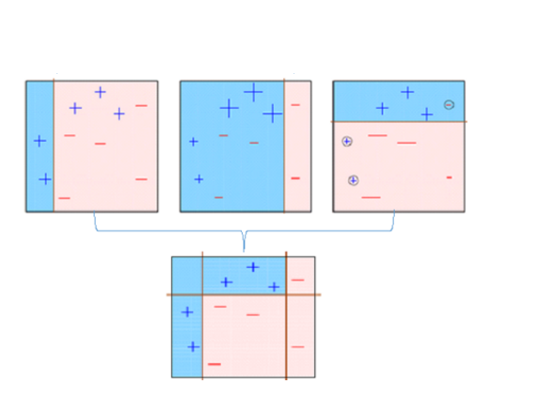
20.[ML] 분류 - 배깅 (Bagging)과 랜덤 포레스트 (Random Forest)
배깅 개요 배깅 (Bagging)은 Bootstrap aggregating의 줄인말이다. 앙상블 학습의 유형 중 하나로 부트스트랩 방식으로 데이터에서 샘플링을 해서 하나의 분류기로 소프트 보팅을 하는 것! 보팅은 같은 데이터로 서로 다른 분류기로 예측을 하고 제일
21.[ML] 분류 - 부스팅과 AdaBoost, GBM 계열
부스팅: 여러 개의 약한 학습기 (weak learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터나 학습 트리에 가중치 부여를 통해 오류를 개선하면서 학습하는 방식부스팅의 구현 종류AdaBoost (Adaptive Boosting)Gradient BoostGr
22.[ML] 분류 - 베이지안 최적화 (Bayesian Optimization)
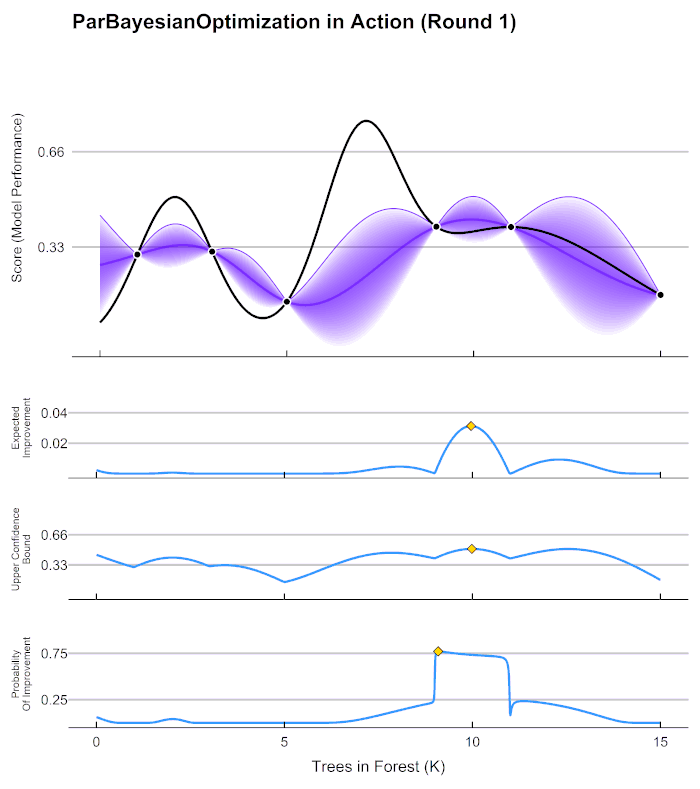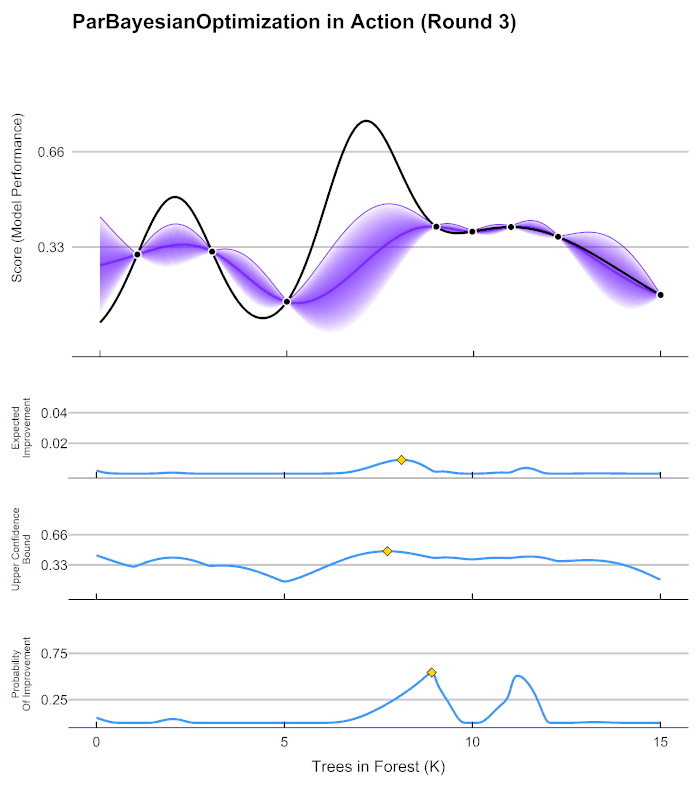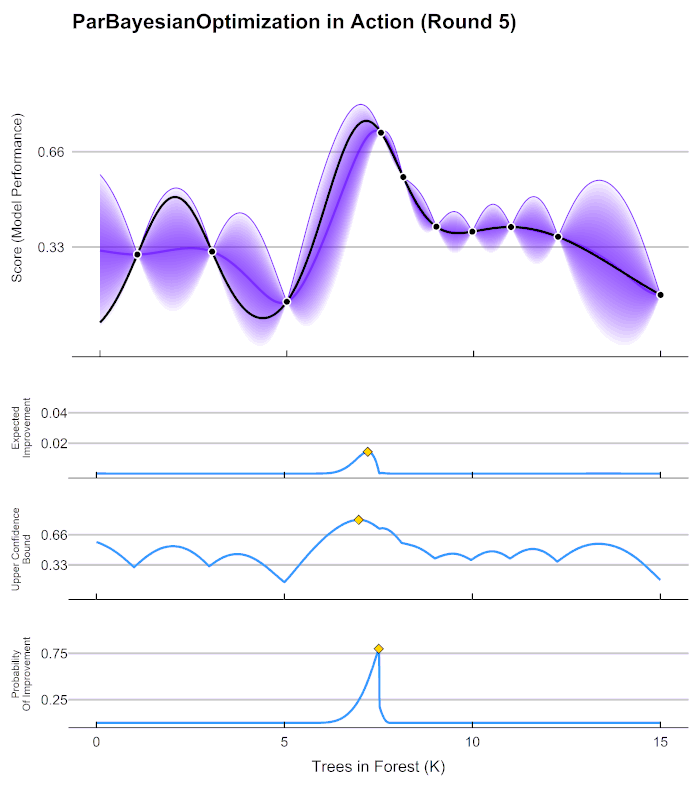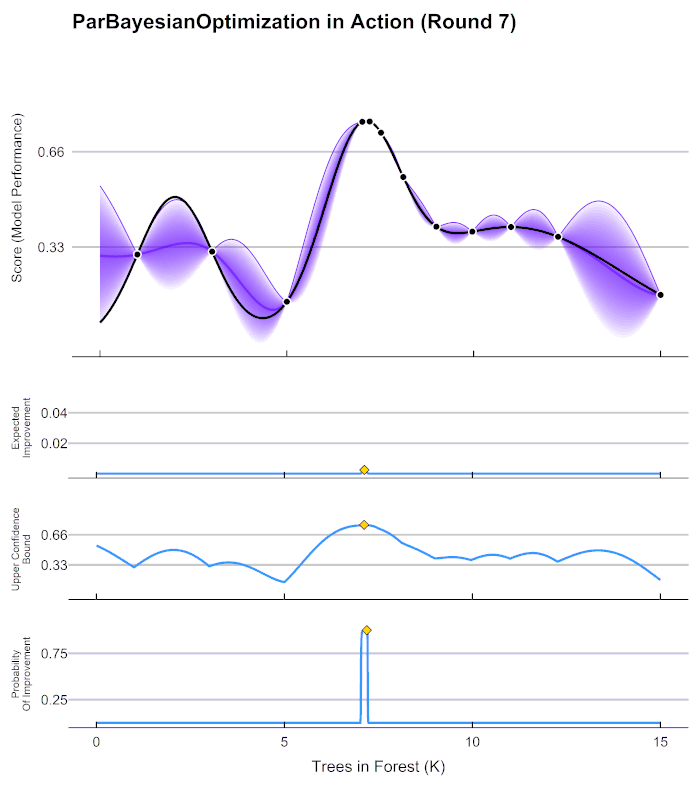
베이지안 최적화? -> 그리드 서치처럼 하이퍼 파라미터 최적화를 수행하는 방법 중 하나그리드 서치가 있는데 굳이 이걸 왜 배울까?하이퍼 파라미터 튜닝 수행 방법1\. 그리드 서치2\. 랜덤 서치 (그리드 서치를 랜덤하게 해주는 것)3\. 베이지안 최적화4\. 수동
23.[ML] 분류 - 산탄데르 고객 만족 예측
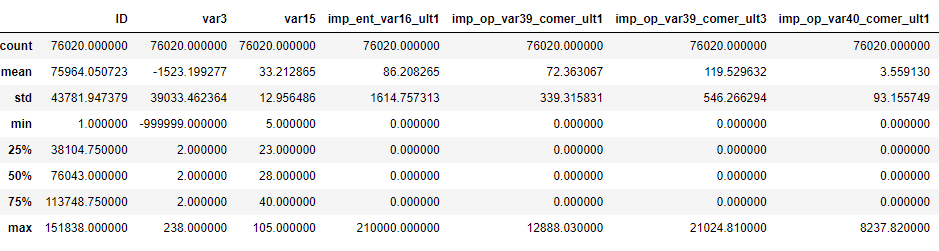
XGBoost/LightGBM 사용해서 분류 예측 진행Early Stopping과 베이지안 최적화를 이용한 하이퍼 파라미터 튜닝을 중점으로 진행데이터 출처: https://www.kaggle.com/competitions/santander-customer-sa
24.[ML] 분류 - 신용카드 사기 예측
신용카드 사기 예측 데이터2013년 European Card 사용 트랜잭션을 가공하여 생성불균형 되어 있는 데이터 셋. 284,807건의 데이터 중 492건이 Fraud (전체의 0.172%)데이터 출처: https://www.kaggle.com/dataset
25.[ML] 분류 - Feature Selection
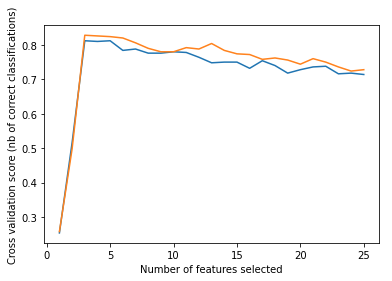
모델을 구성하는 주요 Feature 선택불필요한 다수의 피처들로 인해 모델 성능을 떨어뜨릴 가능성 제거이해할 수 있는 설명 가능한 모델이 될 수 있도록 피처들을 선별Feature Selection 유형Feature값의 분포, NULL, Feature간 높은 상관도, 결
26.[ML] 회귀 - 회귀 (Regression) 개요
통계학에서의 회귀분석: 데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계 기법머신러닝에서의 회귀: 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법을 통칭$Y$: 종속변수$X_1, X_2, ..., X_n$: 독립변수$W_1,
27.[ML] 회귀 - 경사 하강법 (Gradient Descent)
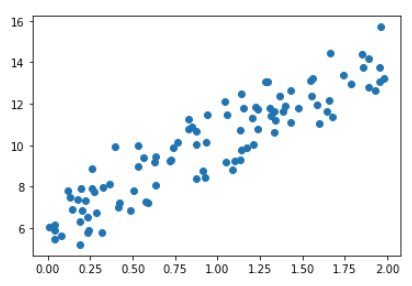
단순 선형 회귀 (Simple Linear Regression)에 대한 경사 하강법 실습NumPy로 구현해보기$$Y = W_0 + W_1X_1$$$$W0 = W_0 - \\eta \\frac{dLoss(W)}{dW_0} = W_0+\\eta(\\frac{2}{N}\\s
28.[ML] 회귀 - 선형 회귀 (Linear Regression)
scikit-learn의 LinearRegression 클래스를 알아보자LinearRegression 클래스예측값과 실제값의 RSS를 최소화하는 OLS 추정 방식으로 구현한 클래스fit() 으로 X, y 배열을 입력 받음회귀 계수인 $W$를 coef\_에 저장절편(bi
29.[ML] 회귀 - 다항 회귀 (Polynomial Regression)
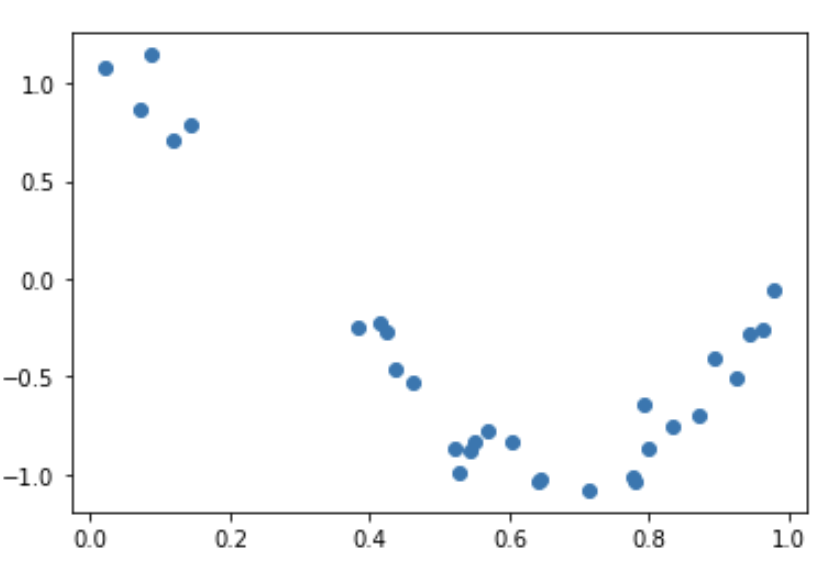
다항 회귀란?\-> 회귀식의 독립변수가 2차, 3차 방정식 같은 다항식으로 표현되는 것예: $y = w_0 + w_1x_1 + w_2x_2 + w_3x_1x_2 + w4\*x_1^2$비선형 회귀와 헷갈리지 말자!비선형 회귀 예: $y = w_1x^{w2}$sicikit
30.[ML] 회귀 - 규제 선형 회귀 (Regularized Linear Regression)
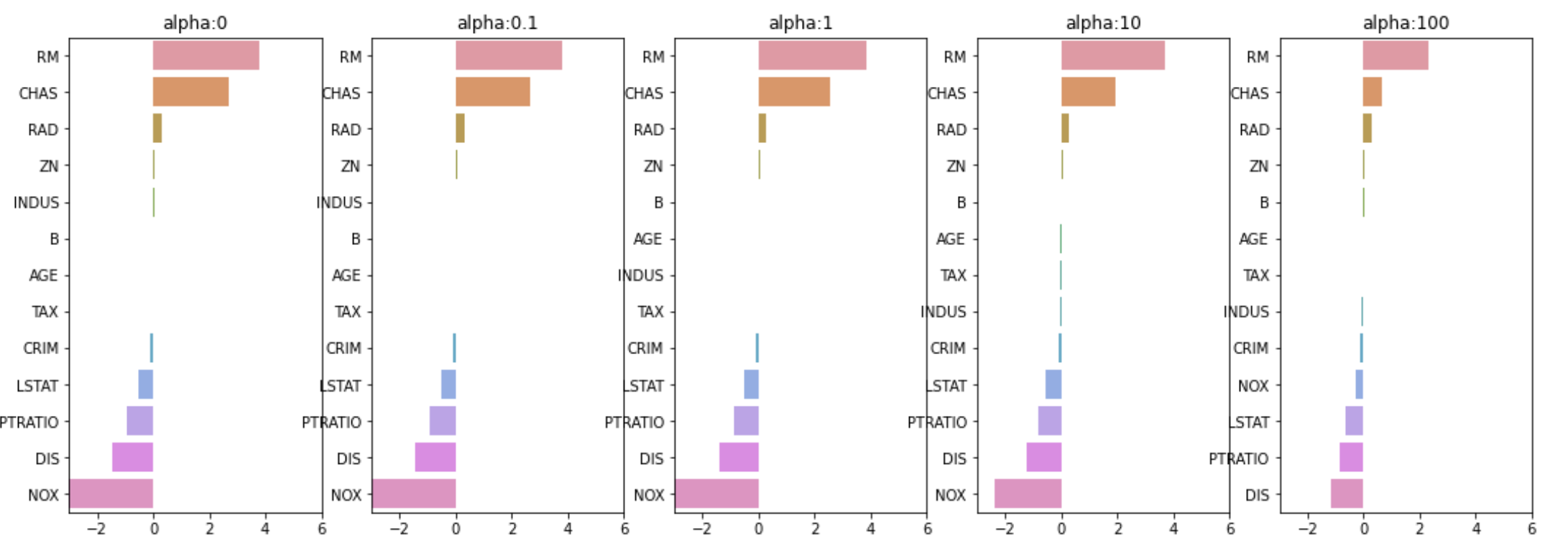
우리가 지금까지 다룬 회귀 모델들은 결국 Loss 값인 RSS를 최소화 하는 것이었음$$Min(\\,RSS(W)\\,)$$그런데, 앞에 다항 회귀의 차수가 15일 때를 보면 회귀계수가 매우 크게 설정됨\-> 과적합 발생\-> 형편없는 평가 데이터 예측 성능따라서, 데이
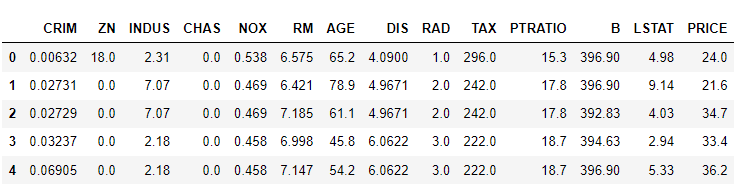
31.[ML] 회귀 - 선형 회귀를 위한 데이터 변환
선형 회귀 모델은 일반적으로 Feature와 Target 간 선형 관계가 있다고 가정선형 회귀 모델은 Feature와 Target의 분포가 정규분포인 것을 선호 (특히 Target)앞에서 한 보스톤 데이터 그대로 사용하자Ridge Regression에 대해 다양한 데이
32.[ML] 회귀 - 로지스틱 회귀 (Logistic Regression)
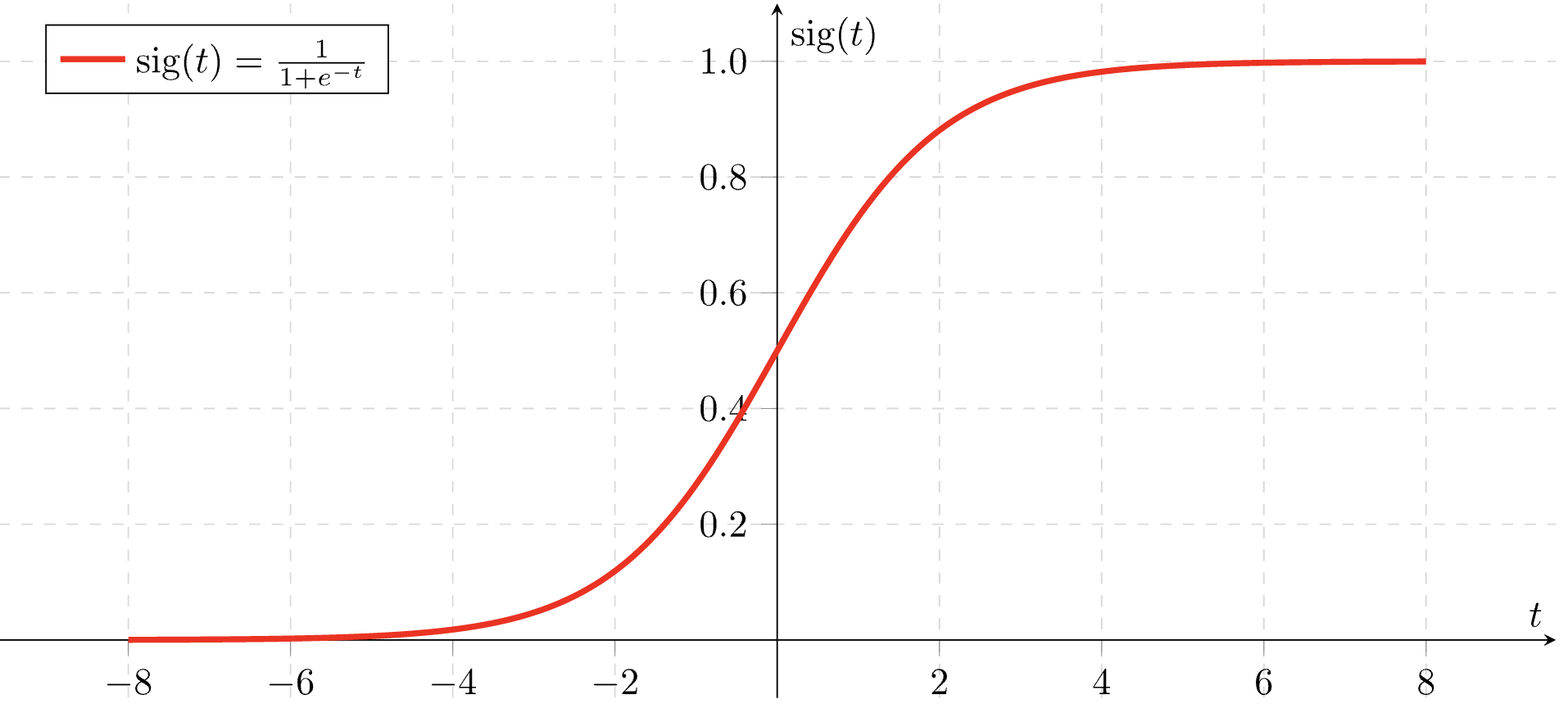
로지스틱 회귀 개요 로지스틱 회귀 개요 로지스틱 회귀는 이름은 회귀인데, 분류에 사용됨 종속변수가 범주형 변수일 때 사용하는 것이 로지스틱 회귀 시그모이드 함수 우선 시그모이드 함수를 먼저 알아보자 (로지스틱 함수라고도 함) $$ Sigmoid(x) = \fr
33.[ML] 회귀 - 회귀 트리 (Regression Tree)
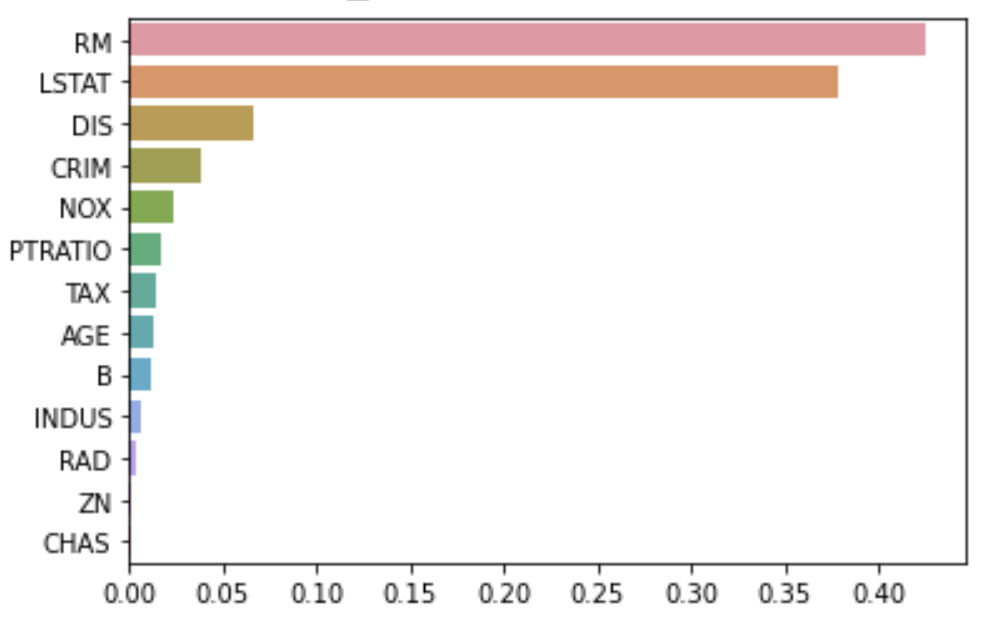
scikit-learn의 결정 트리와 결정 트리 기반의 앙상블 알고리즘은 분류 말고 회귀도 가능함트리가 CART (Classification and Regression Tree)를 기반으로 만들어졌기 때문CART 회귀 트리는 분류와 유사하게 분할, 최종 분할이 완료된
34.[ML] 회귀 - 자전거 대여 수요 예측
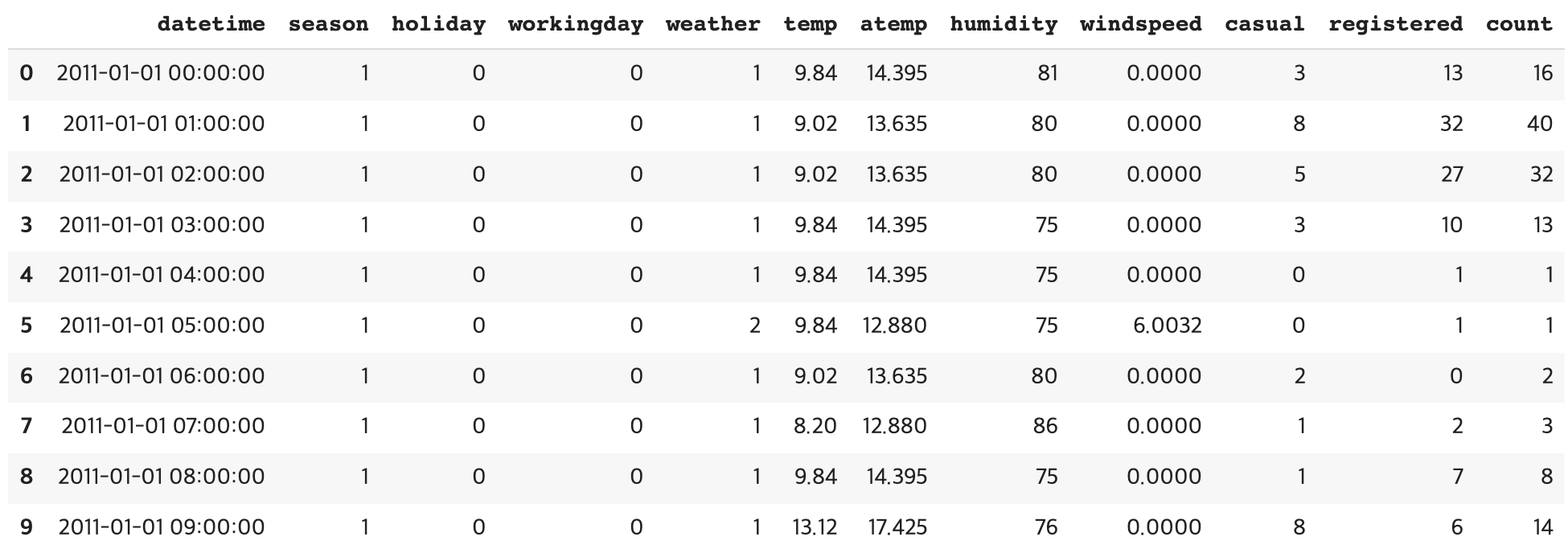
Bike Sharing Demand 데이터 데이터 출처: https://www.kaggle.com/c/bike-sharing-demand 데이터 가공과 사전 작업 >칼럼 설명 datetime: hourly date + timestamp season: 1 = 봄,
35.[ML] 회귀 - 캐글 경연 주택 가격 예측

평가지표로는 RMSLE를 사용하자. $$ RMSLE = \sqrt{\frac{1}{n}\sum{i=1}^N(log(Yi+1)-log(\hat{Y_i}+1))^2} $$ 데이터 전처리 > 데이터 탐색 후 전처리를 진행하자 여러가지 전처리를 해보기 위해 원본 데이터는
36.[ML] 차원 축소 - 차원 축소 (Dimensionality reduction) 개요
차원의 저주 차원이 커질수록 데이터 포인트간 거리가 크게 늘어나고 데이터가 희소화됨 -> Feature가 많으면 ML 알고리즘 무력화 가능성 있음 -> Feature가 많으면 개별 Feature간 상관관계가 높기 때문에, 선형 회귀 같은 모델에서는 다중 공선성 문제로
37.[ML] 차원 축소 - PCA (Principal Component Analysis)
PCA 개요 PCA, Principal Component Analysis, 주성분 분석 >고차원의 원본 데이터를 저차원의 부분 공간으로 투영하여 데이터 축소 예시: 10차원의 데이터를 2차원의 부분 공간으로 투영하여 데이터 축소 PCA는 원본 데이터가 가지는 데이터 변동성을 가장 중요한 정보로 간주하고 이 변동성에 기반한 원본 데이터 투영으로 차원 축...
38.[ML] 차원 축소 - PCA 실습
scikit-learn은 sklearn.decomposition.PCA 클래스 제공n_componets: PCA 축의 개수 (변환 차원)PCA 이전에 입력 데이터의 개별 Feature에 대해 스케일링 필수! PCA는 여러 Feature들의 값을 연산해야 하므로, Fea
39.[ML] 차원 축소 - LDA (Linear Discriminant Analysis)
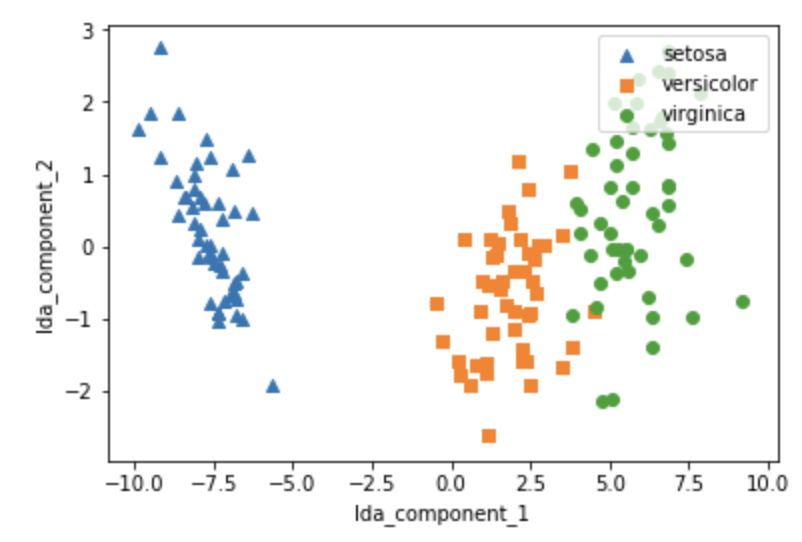
LDA, Linear Discriminant Analysis, 선형 판별 분석PCA와 매우 유사함PCA처럼 입력 데이터 세트를 저차원 공간에 투영해 차원을 축소하는 기법중요한 차이는 LDA는 지도학습의 분류에서 사용하기 쉽도록 개별 클래스를 분별할 수 있는 기준을 최대
40.[ML] 차원 축소 - SVD (Singular Value Decomposition)
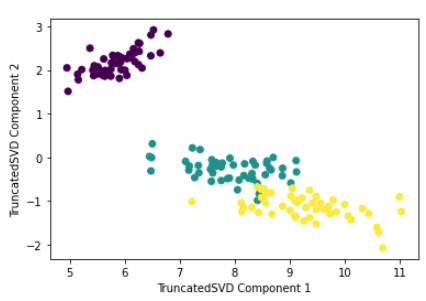
SVD, Singular Value Decomposition, 특이값 분해앞에서 배운 고윳값 분해와 비교해보자고윳값 분해$$C = P\\Sigma P^T $$$$C = \\left\\begin{matrix} e_1 & e_2 & ... & e_n\\end{matrix}
41.[ML] 군집화 - K-Means Clustering
군집화 개요 Clustering 데이터 포인트들을 별개의 군집으로 그룹화 하는 것을 의미 유사성이 높은 데이터들을 동일한 그룹으로 분류하고 서로 다른 군집들이 상이하게 그룹화 군집화 활용 분야 고객, 마켓, 브랜드, 사회 경제 활동 세분화 이미지 검출, 세분화,
42.[ML] 군집화 - Mean Shift Clustering
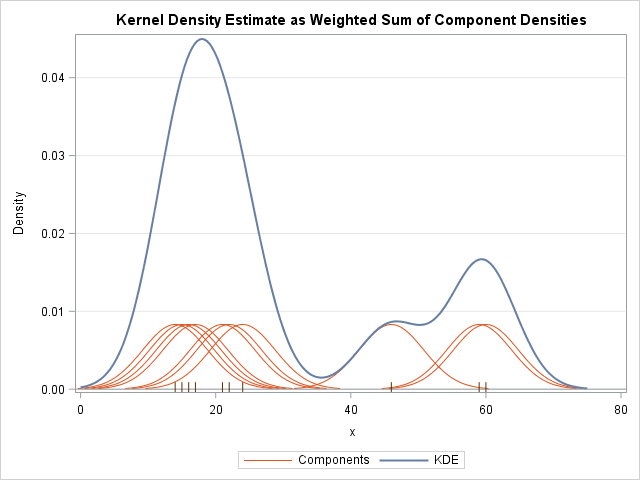
Mean Shift Clustering 개요 K-Means랑 유사한데 차이점은 K-means는 중심에 소속된 데이터의 평균 거리 중심으로 이동하는 데 반해, Mean Shift는 중심을 데이터가 모여있는 밀도가 가장 높은 곳으로 이동 시킴 특징 KDE (Kernel
43.[ML] 군집화 - Gaussian Mixture Model
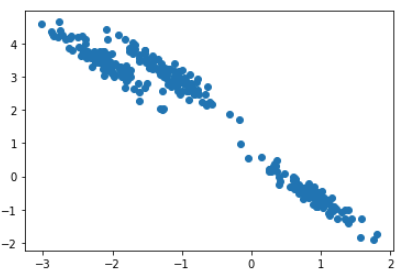
Gaussian Mixture Model, Mixture of Gaussian, GMM, MoG거리기반 K-Means의 문제점\-> K-Means는 특정 중심점을 기반으로 거리적으로 퍼져있는 데이터 세트에 군집화를 적용하면 효율적인데 그 반대는 비효율적이다.예를 들어보
44.[ML] 군집화 - DBSCAN
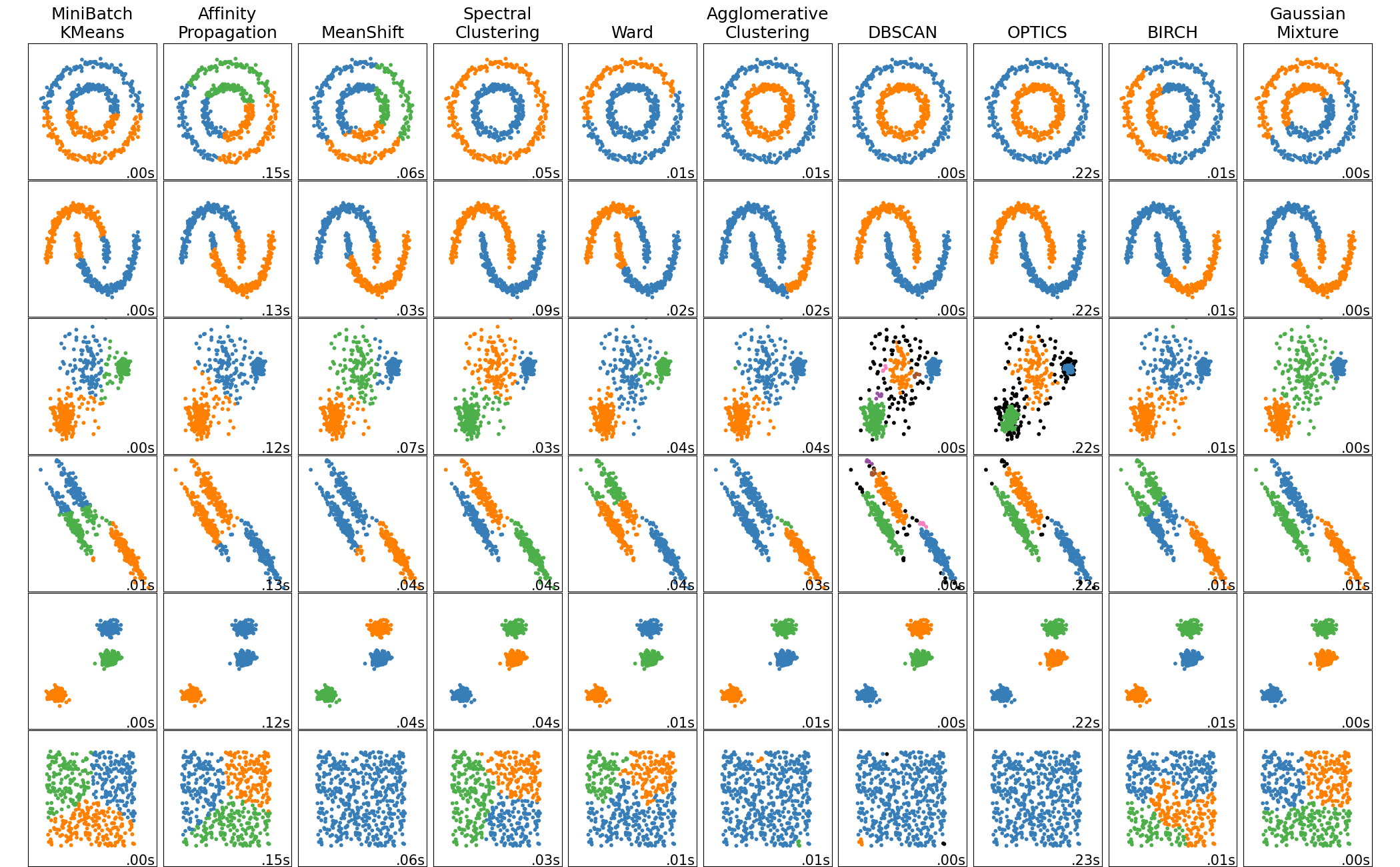
DBSCAN, Density Based Spatial Clustering of Applications with Noise특정 공간 내에 데이터 밀도 차이 기반 알고리즘으로 하고 있어서 복잡한 기하학적 분포도를 가진 데이터 세트에 대해서도 군집화를 잘 수행여러 데이터에
45.[ML] 군집화 - 실루엣 분석 (Silhouette Analysis)
실루엣 분석: 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타내는 것 다른 방법으로는 Elbow Method가 있음 (Inertia)실루엣 계수 (Silhouette Coefficient)각각의 샘플마다 계산$a$: 나와 나와 같은 군집에 속한 샘플들 사이
46.[ML] 군집화 - 고객 세그먼테이션 구현 실습

데이터 출처: https://archive.ics.uci.edu/ml/datasets/online+retail고객 세그먼테이션: 다양한 기준으로 고객을 분류하는 기법사는 지역, 결혼 여부, 성별, 소득, 직업, 월별 사용액, 최근 구매 상품, 구매 주기,