
미분
-
미분이란?
변수의 움직임에 따른 함수값의 변화를 측정하기 위한 도구로 최적화에서 가장 많이 사용하는 기법 -
수치 미분
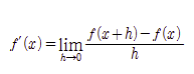
-
전방 차분
def func(f,x):
h = 10e-50
return (f(x + h) - f(x)) / h이렇게 구현을 하게 되면 h가 아무리 작은 수라도 오차가 생길 수 있다.
- 수치 미분의 오차를 줄이기 위해 중심차분(중앙차분)을 사용
def func(f,x):
h = 10e-50
return (f(x + h) - f(x - h)) / h-
미분은 한 점에서 접선의 기울기를 구하면 어느 방향으로 점을 움직여야 함수값이 증가 혹은 감소하는지 알 수 있다.
-
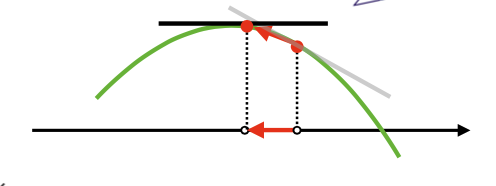
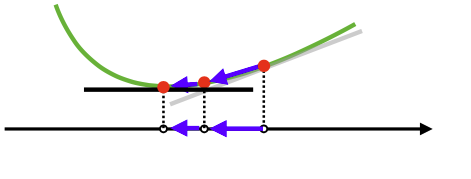
해당 지점에서 미분값을 더하면 경사상승법(gradient ascent)이고 극대값을 찾을 때 사용한다.
-
해당 지점에서 미분값을 빼면 경사하강법(gradient descent)이고 극소값을 찾을 때 사용한다.
-
경사 상승, 경사하강 방법은 극값에 도달하면 움직임을 멈춘다.
출처
Naver BoostCamp AI Tech - edwith 강의 -
궁극적으로 딥러닝에서는 경사하강법을 이용해 손실함수(loss)최소화 하여 모델을 최적화 한다.
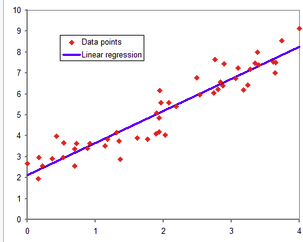
선형회귀 분석
-
데이터들을 총합적으로 고려하여 가장 가까운 직선 도출
출처
https://ko.wikipedia.org/wiki/%EC%84%A0%ED%98%95_%ED%9A%8C%EA%B7%80 -
역행렬을 이용한 선형회귀 식 구하기
import numpy as np
import matplotlib.pyplot as plt
x = np.array([[2],[3],[3],[2],[1]])
y = np.array([4,2,5,1,7]).reshape(-1,1)
plt.plot(x, y, 'ro')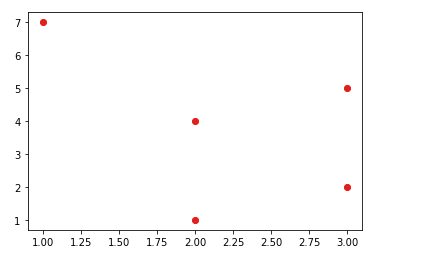
sklearn모듈을 이용한 beta값 도출
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x,y)
print(model.coef_)
print(model.intercept_)
유사역행렬을 이용한 beta값 도출
x_ = np.array([np.append(x1,[1]) for x1 in x])
print(x_)
beta = np.linalg.pinv(x_) @ y
2가지 방법을 통해서 직선에 대한 정보를 얻을 수 있는데 유사 역행렬 사용시 beta를 x_에 다시 곱할 때 y가 도출이 안되는데 그 이유는 다음과 같다.
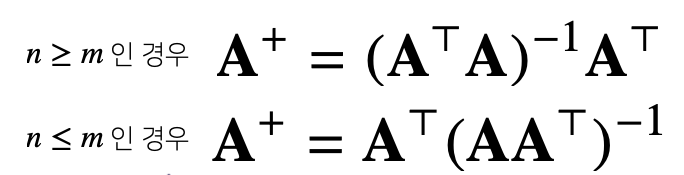
출처
Naver BoostCamp AI Tech - edwith 강의
는 유사 역행렬, n은 행의 갯수, m은 열의 갯수를 뜻하고

출처
Naver BoostCamp AI Tech - edwith 강의
를 만족하게 되는데 위의 코드 상으로는 beta = x^+y가 되므로 x_x^+y에서 xx^+는 항등행렬(I)가 아니므로 y가 아닌 다른 값으로 도출이 될 수 있다.
경사하강법
- 경사하강법 알고리즘(단일 변수)
var = init #입력값
grad = gradient(var) #입력값에 대한 기울기
#기울기에 따라 값을 갱신(lr: learning rate)
while(abs(grad) > eps):
var = var -lr * grad
grad= gradient(var)-
변수가 벡터일 경우에는 편미분을 사용
-
편미분이란?
변수가 여럿인 함수에 대한 미분
하나의 변수에 대한 변화를 판단(나머지 변수는 상수로 취급)
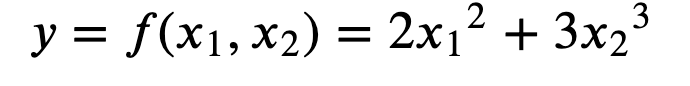
-
x1에 대한 y의 변화
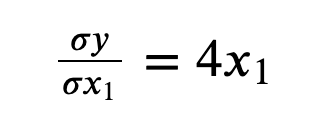
-
x2에 대한 y의 변화
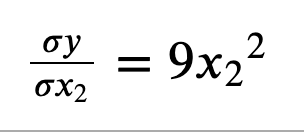
-
tip : 왜 편미분을 사용하는가?
편미분이란 어느 특정한 한 변수에 대하여 결과값의 변화율을 보자는 것인데 기준을 현재 판단하고자 하는 값에만 집중하여 값을 조정하는 효과를 낸다. -
를 그래프로 그려보면 다음과 같고 하나의 최소값을 가지는 것을 볼 수 있다.
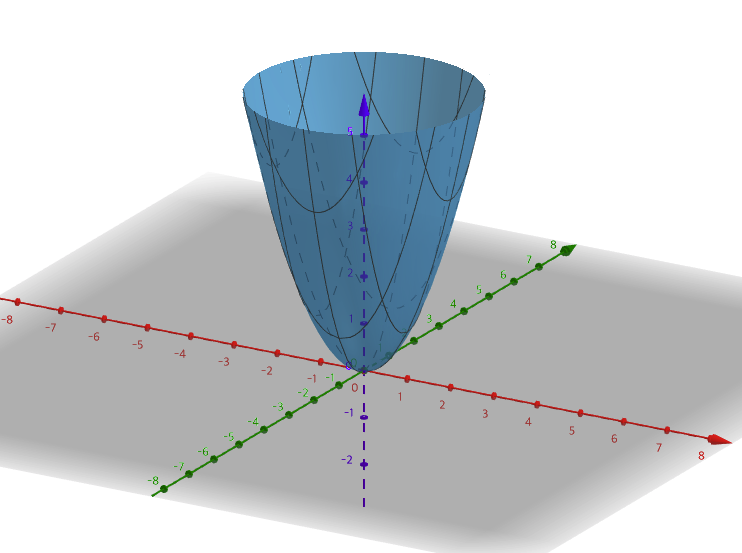
-
이 외에도 볼록한 모양의 함수에 대하여 경사하강법을 이용하여 극솟값을 찾을 수 있다.

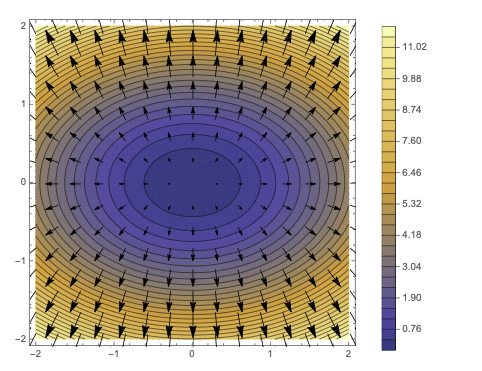
출처
Naver BoostCamp AI Tech - edwith 강의 -
경사하강법 알고리즘(벡터 변수)
-
var = init #입력값
grad = gradient(var) #입력값에 대한 기울기
#기울기에 따라 값을 갱신(lr: learning rate)
#차이! : 벡터는 절대값 대신 norm을 이용
while(norm(grad) > eps):
var = var -lr * grad
grad= gradient(var)-
경사하강법으로 선형회귀 계수 구하기(데이터가 여러개 - X의 행이 여러개의 경우)
- 표현 식( 는 L2 norm을 지칭)
다음 식은 그레디언트 벡터(기울기 벡터)를 나타낸다.

출처
Naver BoostCamp AI Tech - edwith 강의 - Beta에 따라 편미분의 값을 구하는데 Beta의 k번째 원소에 대한 그레디언트 벡터 값과 이에 대한 식과 유도 과정은 다음과 같다.
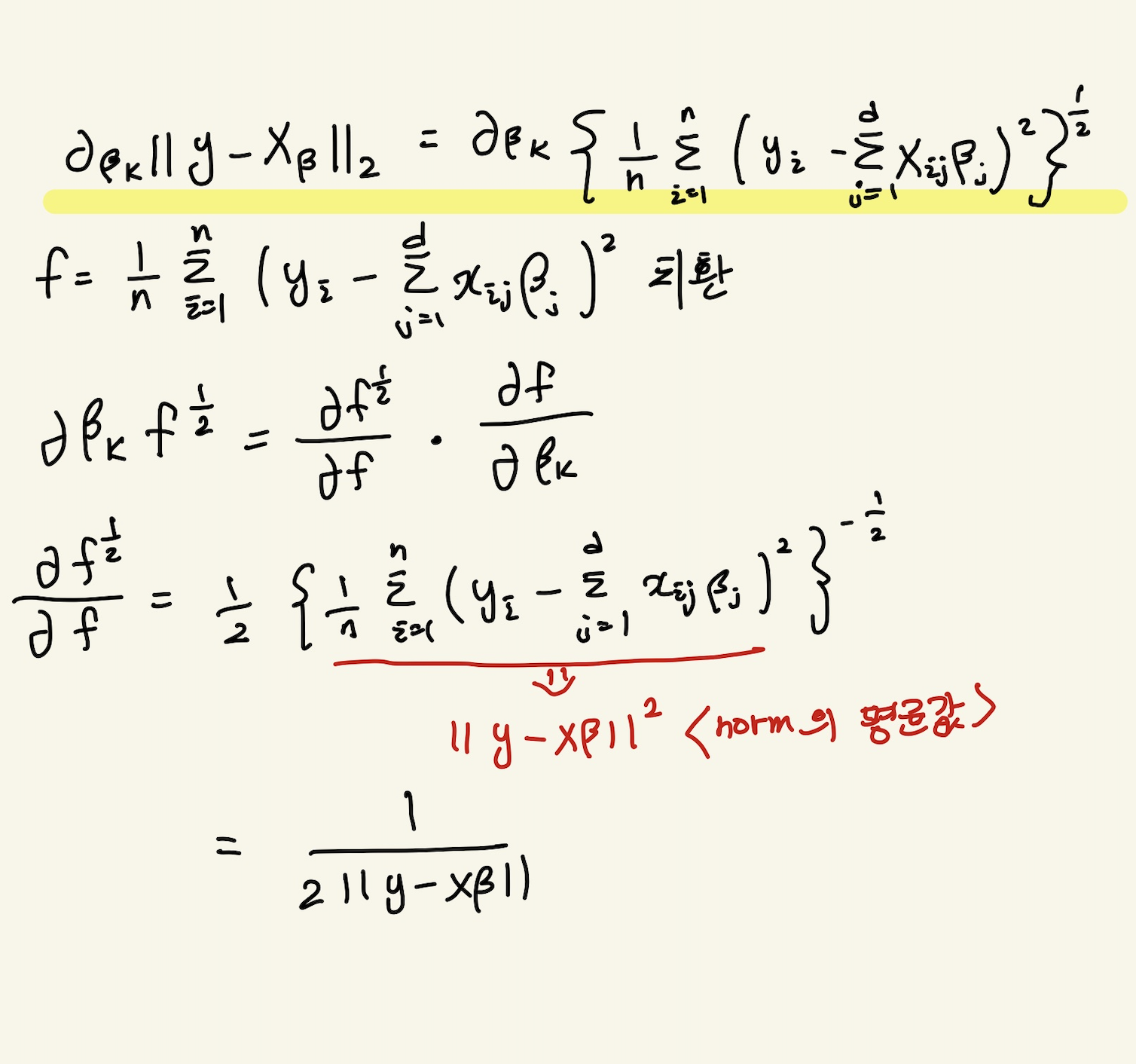
-16.jpg)
- 표현 식( 는 L2 norm을 지칭)
-
선형회귀의 목적식
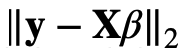
출처
Naver BoostCamp AI Tech - edwith 강의
이를 최소화 하는 Beta를 찾아내야 한다.
-
경사하강법 선형회귀 알고리즘

출처
Naver BoostCamp AI Tech - edwith 강의 -
그레디언트 벡터를 구할 때 y와 x*beta의 값을 제곱을 해 주워도 의미는 같고 식이 간편하기 때문에 제곱 방법을 사용한다.
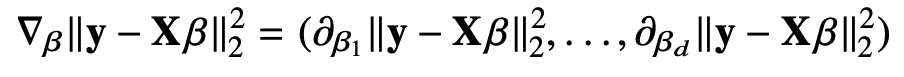
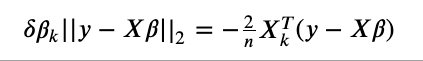
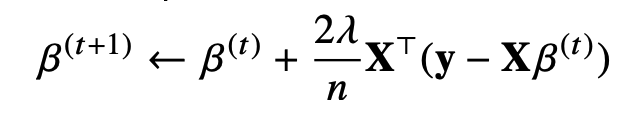
출처
Naver BoostCamp AI Tech - edwith 강의
for t in range(T):
error = y - X @ beta
grad = -transpose(X) @ error
beta = beta - lr * grad- 이론적으로 경사하강법은 1)미분가능하고 2)볼록(convex)한 함수에 대하여 적절한 learning rate화 학습횟수를 선택했을 때 수렴이 보장
확률적 경사하강법(SGD - stochastic gradient descent)
-
선형회귀 목적식은 회귀계수 beta에대해 볼록함수이기 때문에 경사하강법 알고리즘을 돌리면 수렴이 보장(최솟값을 찾을 수 있다.)
-
비선형회귀 문제의 경우 목적식이 볼록하지 않을 수 있으므로 수렴이 항상 보장되지는 않는다.
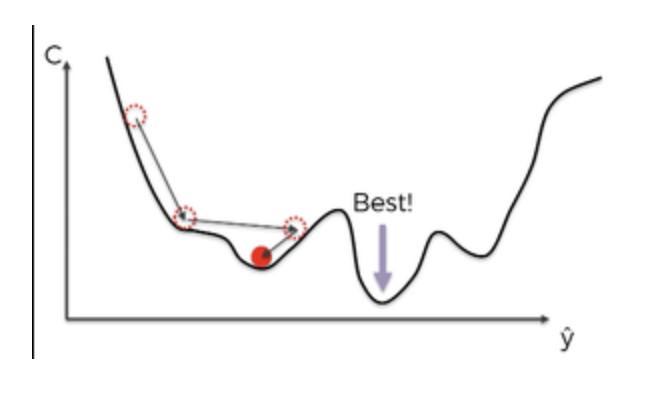
출처 https://librewiki.net/wiki/%EA%B2%BD%EC%82%AC%ED%95%98%EA%B0%95%EB%B2%95 -
확률적 경사하강법은 모든 데이터대신 데이터 한개 또는 일부 활용<미니배치>하여 업데이트를 함
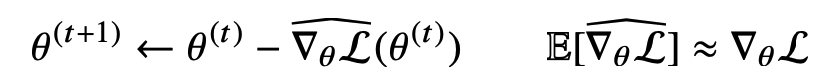
(SGD가 만능은 아니지만 딥러닝의 경우 SGD가 경사하강법보다 실증적으로 더 낫다)

gd - 경사하강법, SGD = 한개의 데이터씩 사용, batch size - 데이터 100개씩 사용출처
Naver BoostCamp AI Tech - edwith 강의
Dive into Deep Learning -
볼록이 아닌 목적식은 SGD를 통해 최적화가 가능
이유: 전체 데이터가 아닌 일부데이터를 가지고 최적화를 시키기에 동일한 상황에서만 파라미터 업데이트가 아니라 여러가지 상황에서 업데이트가 일어나 한곳에 머무는 일을 막을 수 있음
SGD는 미니배치를 가지고 그레디언트 벡터를 계산하고 미니배치는 확률적으로 선택함으로 목적식 모양이 바뀌게 됨(점들의 분포가 달라져 선형회귀 식이 각각 다름)
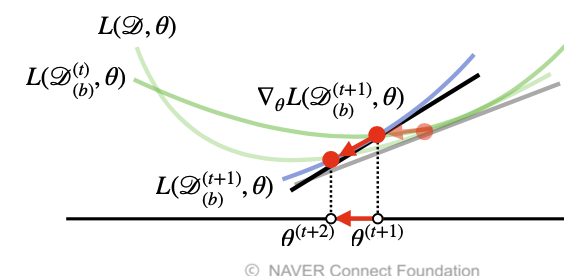
출처
Naver BoostCamp AI Tech - edwith 강의 -
최솟값을 찾는 과정이 일정하지 않으나 각각의 화살표가 생길 때 경사하강법보다 빠르다.(데이터 갯수가 적음)
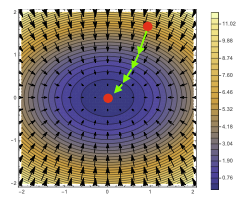
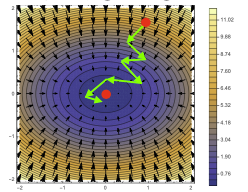
경사하강법 (위), 확률적 경사하강법(아래) -
메모리 측면에서도 효율이 좋다.
- 경사하강법은 모든 데이터를 업로드하여 메모리가 부족해 질 수 있지만 SGD는 GPU에서 행렬 연산과 모델 파라미터를 업데이트 하면서 CPU에서는 전처리와 GPU에서 업로드 할 데이터를 준비함으로 효율이 좋다.
Reference
Naver BoostCamp AI Tech - edwith 강의
https://bhsmath.tistory.com/172
