
시퀀스(Sequence) 데이터
-
시퀀스 데이터란?
시퀀스 데이터는 연관된 연속의 데이터를 지칭하며 소리, 문자열, 주가 등의 데이터를 나타낸다. -
시퀀스 데이터는 연속된 데이터이므로 순서가 매우 중요하게 작용한다.(CNN에서 활용하는 이미지 데이터는 시퀀스 데이터와는 거리가 멀다.)
-
과거의 영향을 받기 때문에 과거 정보의 맥락을 고려하는 새로운 모델이 필요 하였다.(CNN은 과거의 데이터의 영향을 고려하지 않는 모델)
- 시퀀스 정보를 활용하여 앞으로 발생할 데이터의 확률분포를 다룰 때 조건부 확률로써 고려 할 수 있다.(t개의 데이터를 고려해 볼 경우)
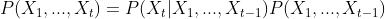
베이즈 정리를 활용한 식이고 유도 과정은 다음과 같다.
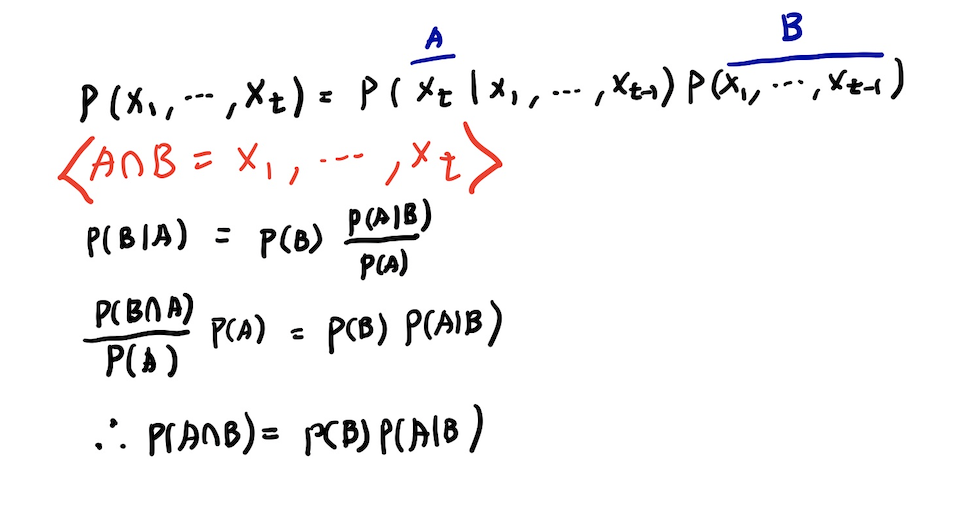
위와 같은 정리로 식을 일반화 한 결과는 다음과 같다.
RNN
-
RNN(Recurrent Neural Network)이란?
순환 신경망이라고도 하며 입력과 출력을 시퀀스 단위로 처리하는 모델 -
RNN은 과거의 데이터의 영향을 판단하여 새로운 예측을 하는 모델이다.
-
모델링의 식
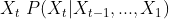
-
시퀀스 데이터를 다루기 위해서는 가변적인 데이터를 다룰 수 있는 모델이 필요 - 조건부에 들어가는 데이터의 길이가 가변적이기 때문
.gif)
이때, 과거의 모든 데이터를 다룰 필요가 없는 경우가 종종 있다.
예를 들어, 어느 회사의 주가를 예측하는 모델을 고려 할 때, 창립 시점부터의 데이터까지 고려 할 필요는 없기 때문이다.
따라서 이전의 데이터 중 가장 최근 데이터부터 τ개의 시퀀스만 사용하는 경우를 AR(τ) - Autoregressive Model(자가회귀모델) 이라고 한다. -
RNN에서 이전 데이터의 정보를 담기 위해 H라는 잠재 변수를 사용한다.
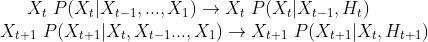
-
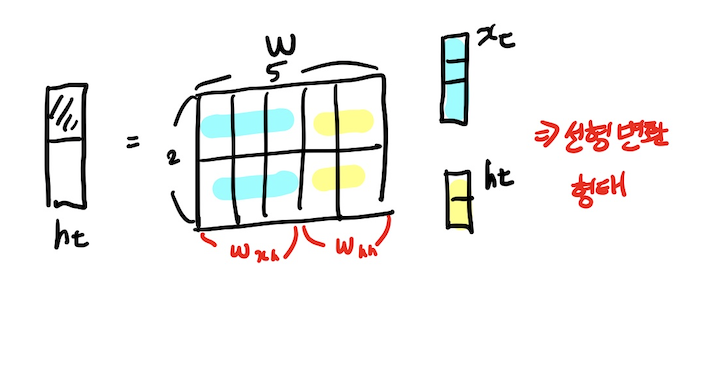
가장 기본적인 RNN모형은 MLP와 유사하며 잠재변수는 활성화 함수와 가중치 행렬을 통해 잠재변수(H)를 도출하고 이 잠재변수를 통하여 output(O)을 도출해 낸다.
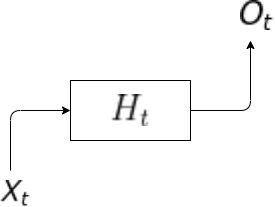
1, 과거의 정보를 다룰 수 없는 경우
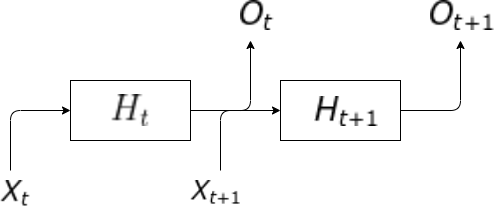
2, 과거의 정보를 다루는 경우
행렬의 곱셈으로써 연산을 표현 해 본 예시는 다음과 같다.
(위와 같은 모델을 Vanilla RNN 이라고 한다.)
- RNN의 타입
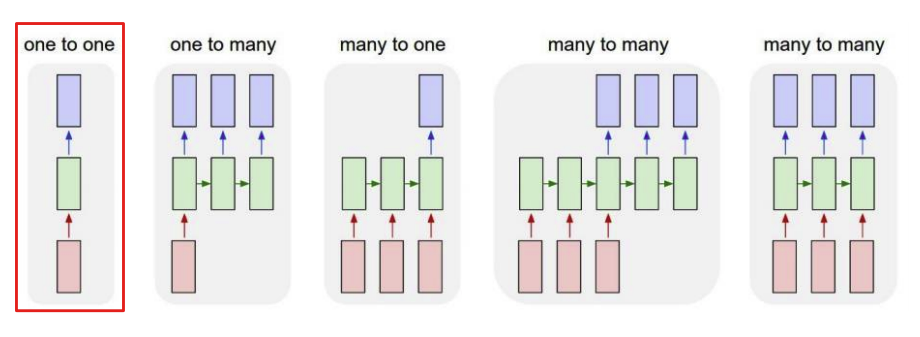
1, one to one : 입출력 데이터가 sequence데이터가 아닌 경우
예) 사람의 키, 몸무게, 나이 -> 저혈압?, 고혈압?, 정상?
2, ont to many : 입력은 하나이나 출력은 sequence데이터인 경우
예) 이미지 -> 이미지에 대한 설명글 예측 혹은 생성
이때, 입력의 빈칸에는 벡터가 들어가야 하기 때문에 이때는 0벡터를 넣어주어 해결한다.
3, many to one : sequence데이터가 입력값으로 들어가고 하나의 output이 나옴
예) 어느 문장 -> positive or negative?
4, many to many : 입출력이 전부 sequence데이터
예) 문장 -> 문장
5, many to many : 입출력이 전부 sequence데이터이며 입력이 주어질 때 마다 데이터를 출력
예) 여러개의 이미지 프레임(각각의 영화 이미지 프레임) -> 여러개의 설명이나 번역 형태 결과
출처
Naver BoostCamp AI Tech - edwith 강의
- character level language model의 예시
1, hello라는 단어를 학습 할 시 단어 사전은 (h,e,l,o)이고 이를 one hot 벡터로 표현한다.
2, hidden state의 값은 다음과 같이 정의한다.
3, 각각의 output은 다음과 같다.
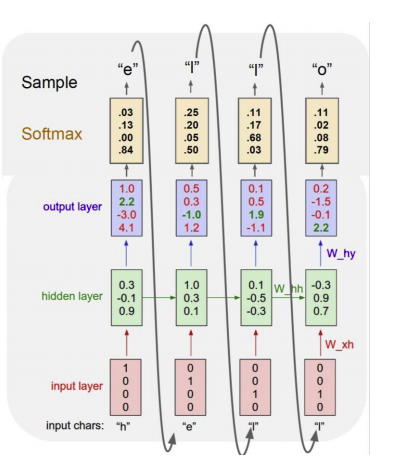
위의 그림은 hello라는 단어를 학습하는 과정이고 핵심적으로 눈여겨 볼 부분은 1)과거의 데이터를 사용하여 결과를 도출함으로 같은 "l"값 이더라도 다른 output을 도출하는 것을 볼 수 있고 2) 실제로 예측값을 도출 할 때 output으로 나온 결과를 재귀적으로 input값으로 넣어 줌으로써 계속해서 결과를 도출 해 낼 수도 있다.(예시 - 회사의 과거 주식 -> 다음날의 주식 가격 -> 예측값을 입력 값으로 넣어서 계속해서 예측을 할 수 있다.)
RNN의 역전파
-
RNN의 역전파는 잠재변수의 연결그래프에 따라 순차적으로 계산을 하여 구한다.
.png)
위의 논리로 각각의 결과값에 대한 가중치의 영향도를 Chain rule에 의해 구할 수 있다.
위와 같은 방법을 Backpropagation Through Time(BPTT)라고 하며 RNN의 역전파 방법이다.
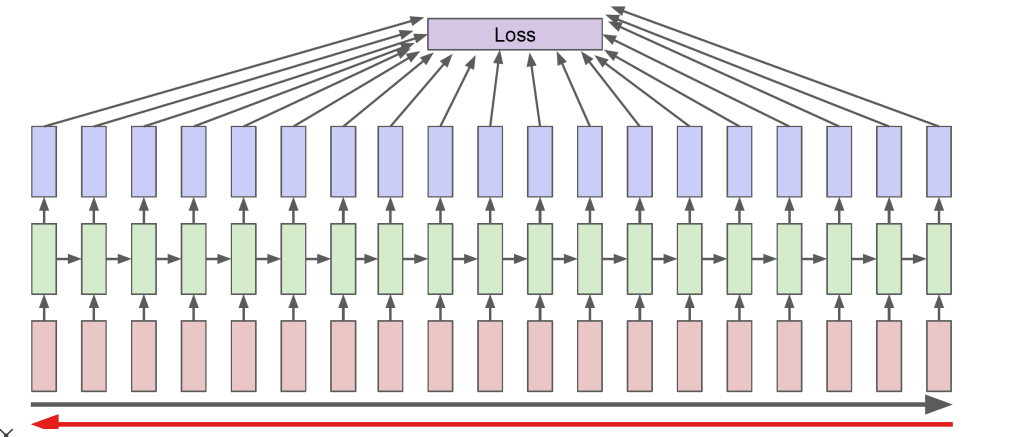
-
RNN의 역전파의 방법을 이용하면 Chain Rule에 의해 계속해서 편미분 값이 곱해지기 때문에 1보다 큰 수 혹은 1보다 작은 수가 많이 곱해지게 되면 Gradient 증폭 혹은 손실이 발생하게 된다. 즉, 과거 시점에에서의 데이터의 영향도가 굉장히 불안정해 지는 현상이 발생하게 된다.
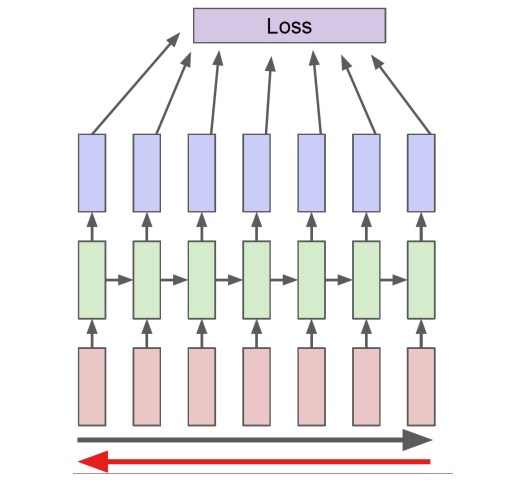
왜 불안정해 질까?
이유는 식에서 그 해답을 찾을 수 있다.
예시를 들어보면 다음과 같다.
이때, 의 식에서 을 편미분 했을 때 계속해서 3이 곱해지는 현상을 볼 수 있다.(값이 게속해서 곱해지는 현상) 이에 따라, 역전파가 수행 될 때, 너무나도 값이 불안정하게 커지거나 작아지는 현상을 볼 수 있다.
참고
개인적으로 MLP에서도 그러면 위와 같은 현상이 일어나야 하지 않는가 고민을 해 보았는데 역전파 수행 시 편미분의 값 곱하기 이전 미분의 값이 수행이 되어지게 되는데 이때, 이전 미분의 값은 ReLU같은 활성함수를 이용하게 되어짐으로 이를 방지하는 역활을 하게 해 준다.(즉, 게속해서 곱해주게 되는 것은 ReLu같은 활성함수의 미분값이라고 볼 수 있다.)
역전파의 개념은 이전에 정리 한 것이 있으니 참고하자
=> https://velog.io/@ganta/4-%EA%B8%B0%EC%B4%88-%EC%88%98%ED%95%99-%EB%94%A5%EB%9F%AC%EB%8B%9D-%ED%95%99%EC%8A%B5%EB%B0%A9%EB%B2%95
그러면 왜 RNN은 ReLU함수로 극복을 못하는 것인가?
RNN은 계속 같은 layer를 MLP보다 여러번 반복하는 성질을 가지고 있어 1보다 큰 값이 들어오게 되면 반복하면서 값이 너무 커지게 된다.
따라서, 오히려 성능이 너무 안 좋게 되는 현상이 발생함으로 RNN에서는 ReLU대신 활성함수로써 sigmoid나 tanh를 사용하게 된다. -
이를 해결하기 위해 장기적으로 긴 길이를 쪼개어 역전파를 수행하는 truncated BPTT아이디어가 나오기도 하였다.
-
이에 따라 적정한 길이의 시퀀스 데이터 길이를 끊는 것이 중요하고 여러 문제로 인해 최근에는 LSTM, GRU 네트워크가 등장이 되어지고 사용되어 진다.
Reference
Naver BoostCamp AI Tech - edwith 강의
https://wikidocs.net/22886
https://gruuuuu.github.io/machine-learning/lstm-doc/#
