
optimizaton
-
뉴럴 네트워크 결과와 실제 정답 레이블의 차이를 어떠한 형식으로 표현하고(loss function) 이 차이를 줄이고자 hyperparameter의 값을 조정하는 다양한 방법(optimization)들이 있다.
-
loss function의 종류
MSE(Mean Squared Error)
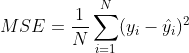
RMSE(Root Mean Squared Error)
MSE에 루트를 씌워준 거으로 MSE와 기본적으로 동일 하나 MSE는 오류의 제곱을 구하기 때문에 실제 오류 평균보다 더 커지기에 값의 외곡이 생기게 된다.왜 MSE를 사용할까?
(계산의 용이성)
https://velog.io/@ganta/3-%EA%B8%B0%EC%B4%88-%EC%88%98%ED%95%99-%EA%B2%BD%EC%82%AC%ED%95%98%EA%B0%95%EB%B2%95
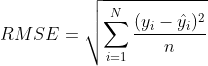
CrossEntropy

(y는 신경망의 출려 , t는 정답 레이블)
이 외에도 다양한 loss function들이 존재
Optimization을 이해하기 위한 개념
-
Genealization
- 학습 데이터를 과도하게 학습을 시키면 오히려 테스트 데이터에서 성능이 떨어지는 현상이 발생하게 된다.(overfitting 현상)
- Generalization performance가 좋다 : 학습 데이터의 결과와 테스트 데이터의 Error가 비슷하게 나온다.
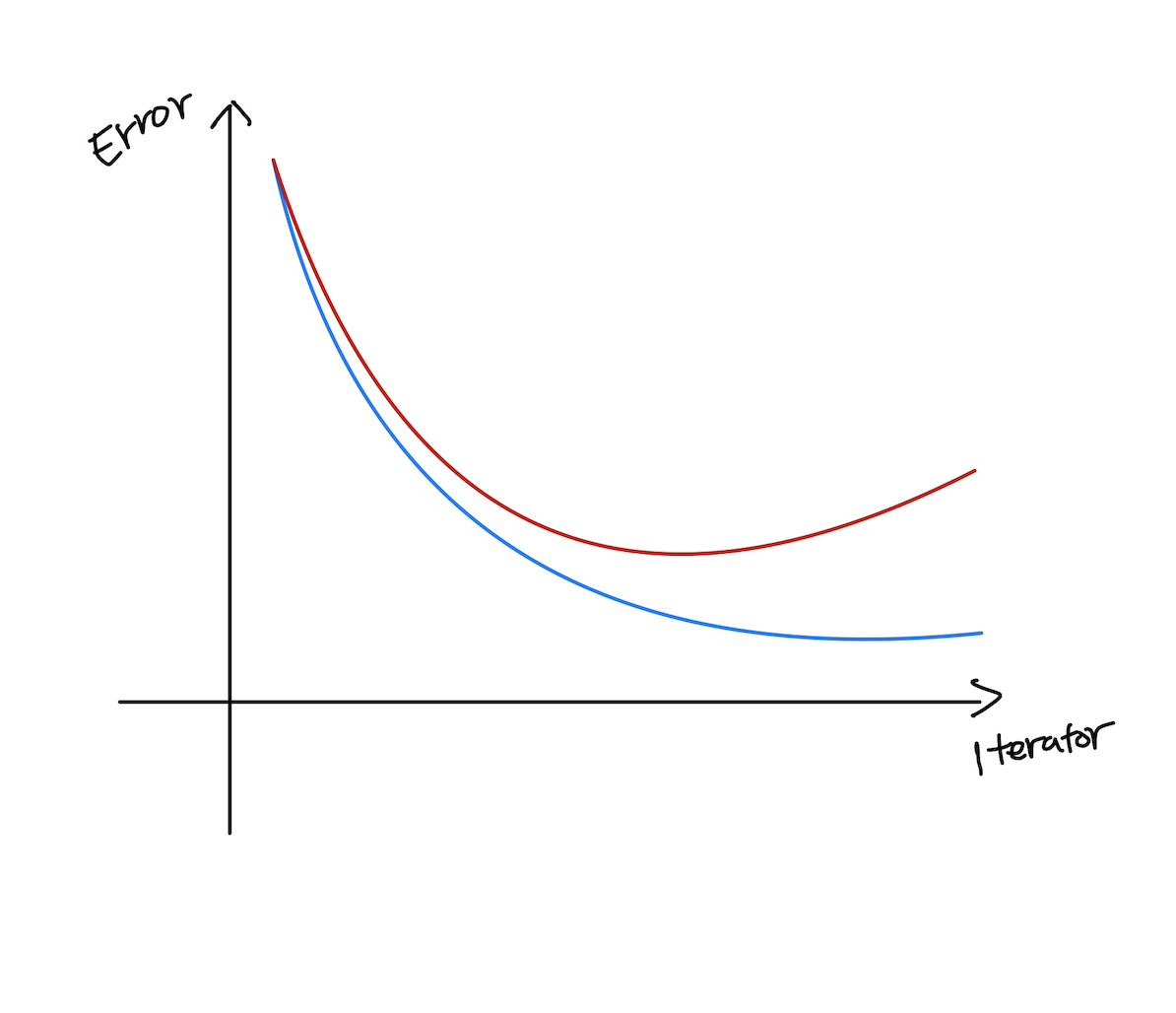
(파란색 - Test error / 빨간색 - Training error)
-
under-fitting / over-fitting
- underfitting : 학습 데이터를 잘 못마추는 형태
- Balanced : 적절하게 학습 된 형태
- overfitting : 과도하게 학습 데이터에 대하여 맞춰진 형태
(사실 이것은 애매한 표현이다. 어느 경우에는 조금은 과도하게 맞춰진 형태가 사실은 잘 분류된 형태일 수도 있기 때문이다.)
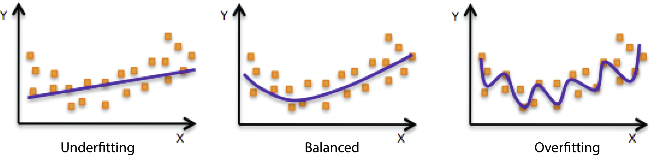
출처
https://docs.aws.amazon.com/machine-learning/latest/dg/model-fit-underfitting-vs-overfitting.html
-
Cross validation
- 학습 데이터를 여러개로 나눈 후 하나의 fold를 제외한 다른 fold를 이용하고 학습을 진행 후 결과들을 저장
- k-1개의 fold로 학습을 시키고 나머지 1개의 fold로 test(validation)을 함
- 최적의 hyper parameter의 set을 찾고 hyper parameter를 고정시키고 학습시킬 때는 모든 데이터를 사용하여 학습을 시킴
- 위와 같은 방법을 사용하는 이유는 테스트 데이터는 학습을 시키는 데 있어서 무조건 사용을 하면 안되기 때문이다.
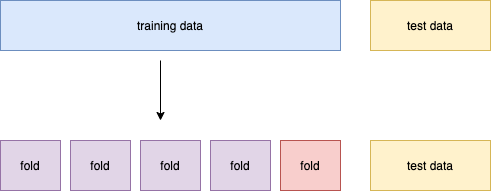
(각각의 round마다 다른 fold를 선택하고 나머지 fold에 대하여 학습을 진행 한 후 하나의 fold에 대하여 확인을 진행한다.)
참고 링크 - https://specialscene.tistory.com/109
-
Bias-variance tradeoff
-
variance : 데이터 내에 있는 에러나 노이즈까지 잘 잡아내는 모델에(highly flexible models) 데이터를 fitting시킴으로써, 실제 현과 관계 없는 랜덤한 데이터들까지 학습하는 알고리즘의 경향
-
bias : 데이터 내에 있는 모든 정보를 고려하지 않고 지속적으로 잘못된 것으 학습하는 경향
-
bias는 트레이닝 데이터를 바꿈으로써 알고리즘의 평균 정확도가 얼마나 바뀌는지 보여주고, variance는 특정 입력 데이터에 대해 알고리즘이 얼마나 민감한지 나타냄
-
high variance일수록 overfitting될 가능성이 높아진다.
-
Bias and Variance Tradeoff
Error(X) = noise(X) + bias(X) + variance(X)
내 학습 데이터에 noise가 껴있다고 가정을 한 경우 Error(cost)는 일정하고 보통 bias를 줄이려 하면 variance가 늘어나고 variance를 줄이려 하면 bias를 늘리려는 현상이 일어나게 되고 이를 tradeoff 라고 한다.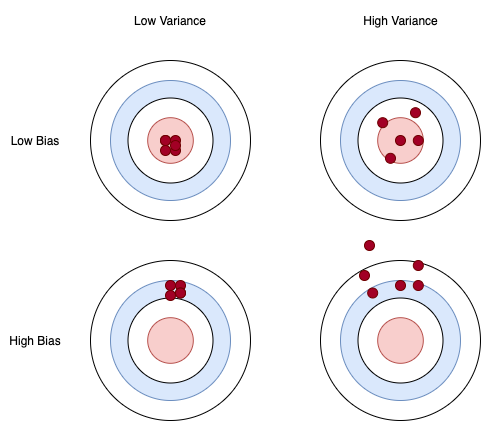
출처
https://www.quora.com/What-is-an-intuitive-explanation-for-bias-variance-tradeoff -
underfitting
1 - 데이터의 모든 정보를 고려하지 못한다.(High Bias)
2 - 새로운 데이터가 들어오더라도 모형이 크게 변하지는 않는다.(Low Variance) -
overfitting
1 - 주어진 데이더를 잘 설명한다.(Low Bias)
2 - 새로운 데이터가 들어오면 모델 변형이 크게 일어난다.(High Variance)
-
-
Bootstrapping
- training data를 늘리는 방법의 일종
- 학습 데이터를 random sampling(몇개의 데이터를 중복을 허용하여 뽑아옴)하여 여러개의 데이터 셋을 만듬. 즉, 훈련 데이터 셋에서 중복을 허용하여 원래 데이터 셋과 같은 크기의 데이터 셋을 만듬
-
Bagging and Boosting
- Bagging : bootstrap을 통해 조금씩 다른 훈련을 통해 나온 모델들의 평균을 내어 결합(전통적인 앙상블)
- Boosting : 학습 데이터에 대하여 간단한 model을 만들고 몇개의 데이터에 대하여 원하는 결과가 안 나올시 안되는 데이터 셋에 대하여만 모델을 새롭게 정의하여 만들고 이러한 model(weak leaner)들을 합쳐 새로운 model(strong model)을 만든다.
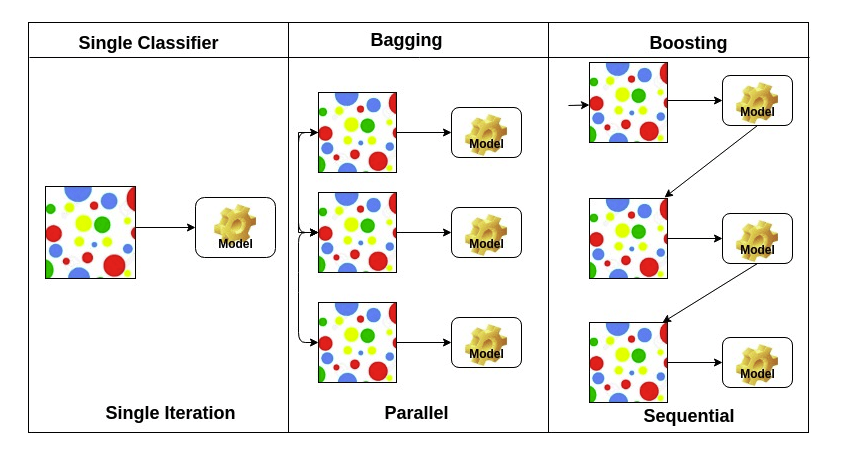
출처
https://www.datacamp.com/community/tutorials/adaboost-classifier-python
Gradient Descent Methods (Optimization)
-
Gradient Descent Method의 큰 3가지 분류 종류
1, Stochastic gradient descent
통계적 경사하강법이자 원칙적으로는 한번에 하나의 데이터만 사용하여 파라미터 업데이트를 수행하는 것을 말한다.
2, Mini-batch gradient descent
batch size 만큼의 데이터를 사용하여 파라미터 업데이트를 수행하는 것을 말한다.
3, Batch gradient descent
한번에 데이터를 다 사용하여 파라미터 업데이트를 수행한다. -
Batch-size Matter
배치 사이즈가 너무 크면 generalize performance가 오히려 더 낮아지는 현상을 말한다.
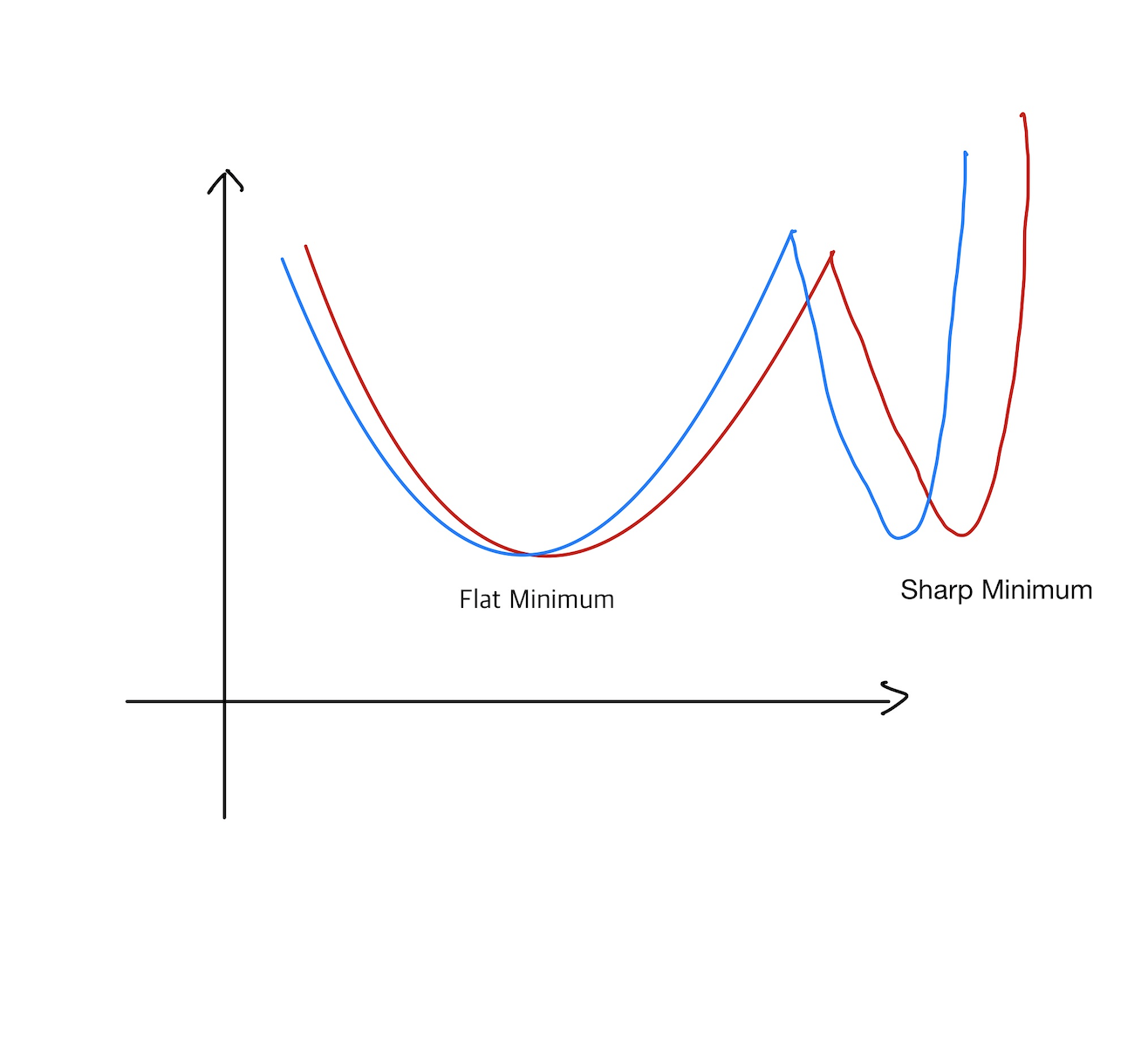
출처:
On Large-batch Training for Deep Learning: Generalization Gap and Sharp Minima, 2017
Flat Minimum - generalize performance 좋음
Sharp Minimum - generalize performance 나쁨 -
Stochastic gradient descent
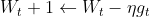
SGD라고 하며 기울기를 이용한 파라미터 조정이 수행되고 learnng rate에 따라서 모델의 성능이 많이 좌지우기 때문에 잘 설정을 해 주워야 함(예 - 너무 클 시 발산) -
Momentum
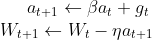
다음번 grad가 다르게 흘러도 이전 grad가 영향을 미치는 성질(관성)
단점 : 관성때문에 local minimum converging(극소값을 찾아감)을 찾아가지 못하고 계속 왔다갔다 하는 현상이 일어날 수 있음 -
Nesterov Accelerated Gradient
.gif)
.gif)
Momentum의 단점을 고려하여 먼저 이동 후 그 자리에서 기울기값을 고려하여 관성처럼 움직임
즉, momentum은 이전의 움직임의 관성이였다면 Nesterov Accelerated Gradient는 다음번의 움직임의 관성
-
Adagrad
.gif)
Neural Network의 파라미터가 얼만큼 지금까지 변화해왔는지를 도려하여 파라미터가 많이 변한 부분은 좀 적게 변화시키고 많이 변하지 않은 파라미터는 많이 변화 시키는 방식
G : 지금가지 얼마나 변했는지 제곱하여 누적해서 더한 값(이 값이 무한대로 갈 수록 학습이 멈춰지는 현상이 나옴)
ε : for numerical stability(0으로 나누는 것을 방지하기 위한 수) -
RMSProp
.gif)
Adagrad의 단점을 보완한 방법으로 지수 이동 평균을 이용하여 G가 무한히 커지는 점을 막는다.
= 으로써 은 업데이트 횟수이고 학습이 진행이 될 수록 이전의 값의 효력이 줄어드는 효과가 나오게 된다. -
Adadelta
.gif)
RMSProp과 마찬가지로 지수평균을 사용하고 learning rate를 사용하는 대신 H를 이용하여 W변화값을 가지고 있는 변수이기 때문에 learning rate없이도 업데이트가 가능하도록 해 준다. -
Adam
지수평균과 momentum 방식을 동시에 사용하고 있음
β1 : momentum 얼마나 유지?
β2 : EMA of gradient squares(지수 평균시 사용)
η : learning rate
ε : for numerical stability(0으로 나누는 것을 방지하기 위한 수)
=> 이러한 파리미터의 설정이 매우 중요
Regularization
-
Early Stopping
(파란색 - Test error / 빨간색 - Training error)
적절한 시점에서 학습을 멈추기 위해서는 추가적인 데이터가 필요하다. -
Parameter Norm Penalty

- neaural network의 파라미터의 값이 너무 커지지 않게(절댓값의 크기) 조절
- 네크워크의 숫자들이 작으면 작을수록 좋다.(크기 관점에서)
- function space => 최대한 부드러운 함수를 만들자!(generalization performance가 높을 것이다.)
- 위의 예시를 보면 loss에 추가적인 값(Patameter Norm Penalty)를 부여하여 값을 키우지 않음
-
Data Augmentation
- 딥러닝은 데이터 셋이 많아야 학습 효과가 나타남(데이터 셋이 적으면 오히려 Neural Network나 전통 ML보다 성능이 낮다)
- 어떤식으로든 내가 가진 데이터를 활용하여 새로운 DataSet을 만듬 - 변화를 가했을 시 Label이 변하지 않는 경우(예를 들어 동물의 사진의 경우 흔들거나 뒤집어도 분류 기준이 변하지 않으나 숫자의 경우 6,9의 경우 뒤집으면 분류 기준이 달라지기에 이 경우는 변화를 가하면 안된다.)
-
Noise Robustness
입력 데이터 혹은 Weightdp noise를 주워 학습 데이터를 늘리거나 모델에 변화를 가함 -
Label Smoothing
mix up : decision boundary를 설정하여 분류를 하게 해 주는데 이 경계를 몇개의 선택된 데이터의 input과 output을 섞어 training해 줌으로써 경계를 부드럽게 하는 개념이다.
cutmix : 실제로 사용하여 성능이 좋은 방법으로써 학습 데이터를 막 섞어(Blending, 일부 영역의 교체) 및 일부를 제거한 input을 넣어 학습을 시킴
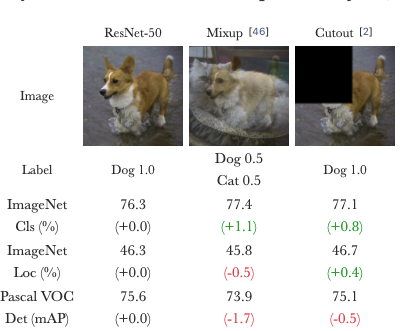
-
Dropout
Neural Network의 weight의 일부분을 0으로 만들너 주워 overfitting현상을 제어 - 각각의 뉴런들이 robust한 데이터를 잡을 수 있다. -
Batch Normalization
- 내가 적용하고자 하는 layer의 수치적 통계의 정규화
.gif)
- Bath Normalization의 여러 종류
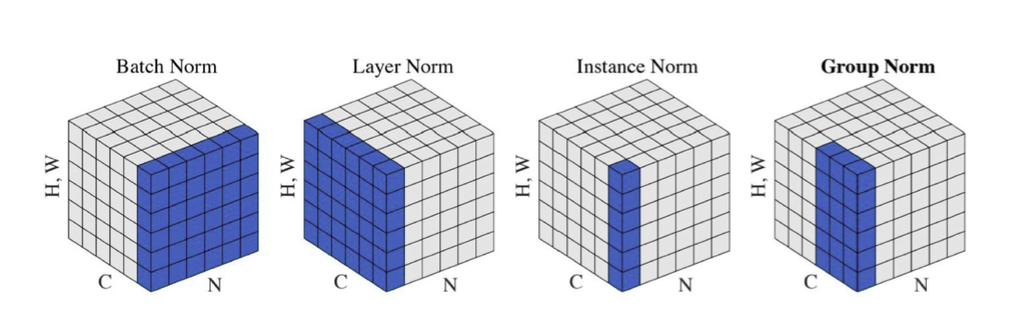
출처
Naver BoostCamp AI Tech - edwith 강의
Group Normalization, 2018
- 내가 적용하고자 하는 layer의 수치적 통계의 정규화
Reference
Naver BoostCamp AI Tech - edwith 강의
https://bywords.tistory.com/entry/%EB%B2%88%EC%97%AD-%EC%9C%A0%EC%B9%98%EC%9B%90%EC%83%9D%EB%8F%84-%EC%9D%B4%ED%95%B4%ED%95%A0-%EC%88%98-%EC%9E%88%EB%8A%94-biasvariance-tradeoff
https://learningcarrot.wordpress.com/2015/11/12/%EB%B6%80%ED%8A%B8%EC%8A%A4%ED%8A%B8%EB%9E%A9%EC%97%90-%EB%8C%80%ED%95%98%EC%97%AC-bootstrapping/
https://hororolol.tistory.com/246
http://shuuki4.github.io/deep%20learning/2016/05/20/Gradient-Descent-Algorithm-Overview.html
https://twinw.tistory.com/247
