
CNN의 기초 개념
👉 https://velog.io/@ganta/7-%EA%B8%B0%EC%B4%88-%EC%88%98%ED%95%99-CNN
Computer vision 처리
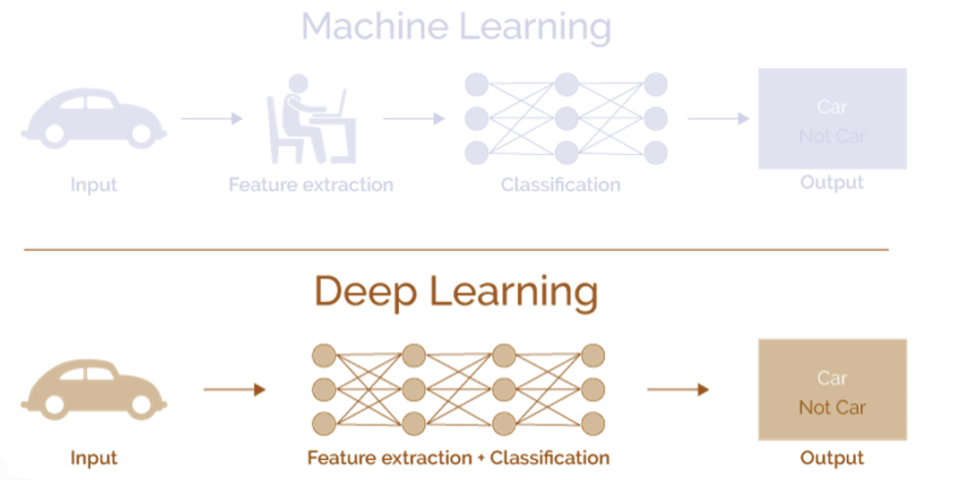
출처 : Naver BoostCamp AI Tech - edwith 강의
👉 Machine Learning적 처리 : 특징을 사람이 추출 한 다음 분류를 프로그램이 학습하여 하는 방향으로 이뤄진다.
👉 Depp Learning적 처리 : 기계가 특징 추출과 분류를 학습하여 진행을 한다.
Image Classification
✔️ Classifier(분류기) : input 데이터와 output 데이터를 매칭시켜 주는 것이다.
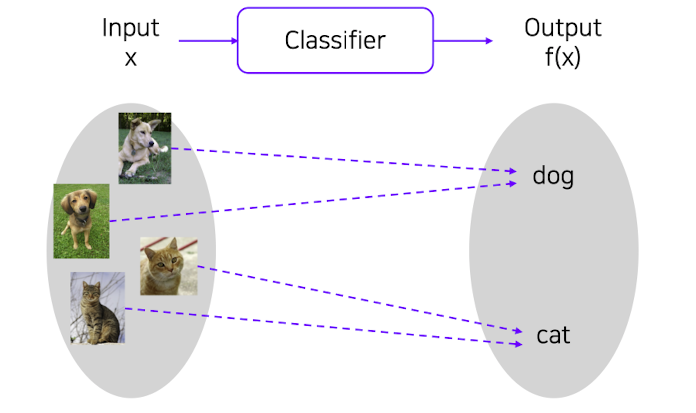
출처 : Naver BoostCamp AI Tech - edwith 강의
❗️ 그러면 세상의 모든 데이터를 기억한 다음 분류를 수행하면되지 않을까?
➡️ k Nearest Neighbors(k-NN)
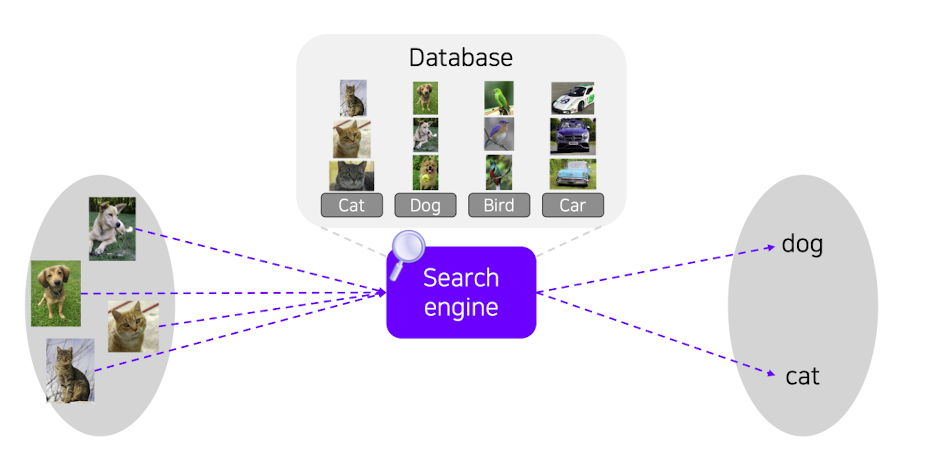
출처 : Naver BoostCamp AI Tech - edwith 강의
k Nearest Neighbors(k-NN)는 최근접 알고리즘으로써 query data(새로 들어온 데이터)를 주변 point를 보아 분류를 해 주는 알고리즘이다.
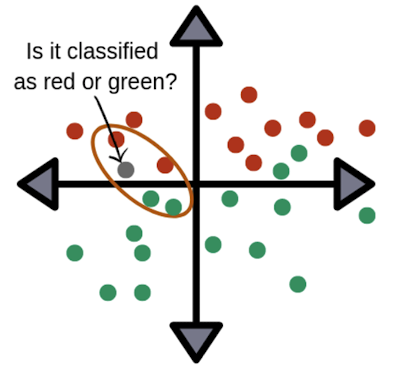
출처 : Naver BoostCamp AI Tech - edwith 강의
❗️ 이 알고리즘의 문제점은 기억할 데이터가 커지면 커질수록 시간복잡도와 공간복잡도가 무한이 늘어나는 단점이 있다.
⭐️ 이에 따라서 모든 데이터를 neural network에 압축하여 분류를 수행하는 CNN같은 기법들이 나오게 되었다.
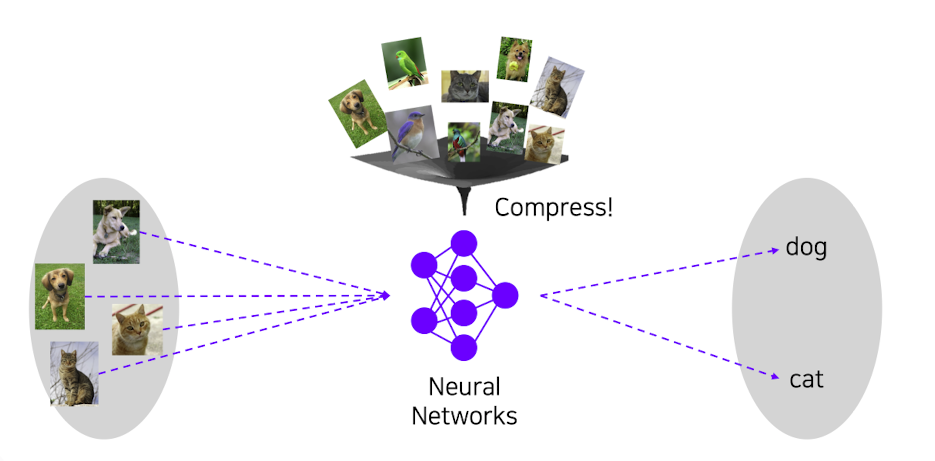
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ CNN 아이디어의 변천사
1️⃣ 처음에는 픽셀별로 fully connected layer를 통해서 분류를 시도해 보고자 하였다.
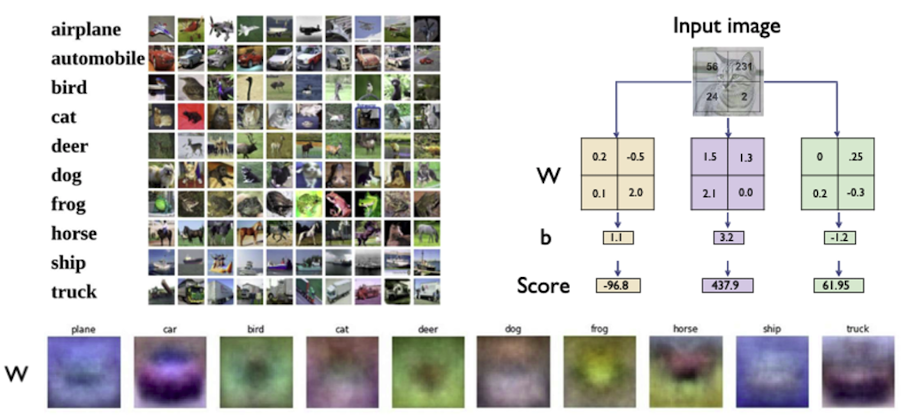
출처 : Naver BoostCamp AI Tech - edwith 강의
이미지에서 아래 부분(W)에는 라벨에 대한 평균적인 이미지의 특성을 볼 수 있다.
이러한 방식의 단점은 첫번째로 layer가 1층이라 단순해서 평균 이미지 같은거 외에 표현이 안되고 두번째로는 test time의 문제인데 학습시에는 물체가 가득찬 하나의 이미지에 대하여 학습을 하나 테스트시에는 여러 경우(이미지가 잘렸다거나)에 대하여 대비를 할 수 없게 된다.
⭐️ 이에 따라, CNN에서는 locally connected neural network를 사용하여지 지역적인 특징들을 이용함으로써 유연하게 이미지 분류를 수행한다.
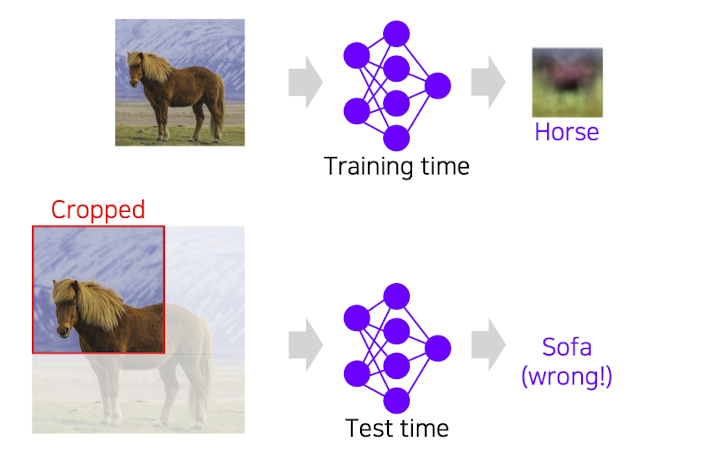 출처 : Naver BoostCamp AI Tech - edwith 강의
출처 : Naver BoostCamp AI Tech - edwith 강의
⭐️ CNN은 많은 CV수행과정에서 backbone역활로써 사용되어지고 있다.(Image-level classification, Classification + Regression, Pixel-level classification)
CNN의 구성
✔️ CNN은 convolution layer, pooling layer, fully connected layer(dense layer)로 이뤄져 있다.(최근에는 fully connected layer를 convolution layer처럼 연산해서 사용하는 추세이다.)
- convolution, pooling layer : 특징들을 추출(feature extraction)
- connected layer : 분류기능(classification)
- 학습시켜야 하는 파라미터(hyper parameter)갯수가 너무 많아질수록 학습하는 시간이 많이 걸리고 generalize performance가 줄어들기 때문에 적절한 파라미터 수를 가지는 것이 중요하다.
- dense layer는 파라미터 숫자에 dependent하기 때문에 최근 연구 동향 방향은 convolution을 늘리고 dense layer를 줄이는 방향으로 연구가 진행이 되고 있다.
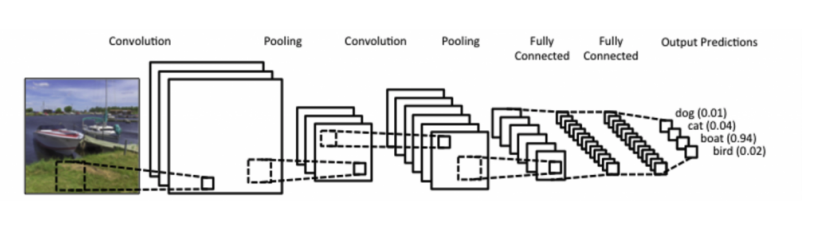
출처
Naver BoostCamp AI Tech - edwith 강의
https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
Convolution, Fully connected, Pooling
✔️ convolution layer
-
각 픽셀을 그대로 feature로 사용하도 괜찮지만 감당해야 하는 비용이 너무나도 크다.
-
예를 들어, 가로 48 , 세로 48, RGB 이미지 데이터를 생각 해 보았을 때 이미지의 각각의 픽셀을 MLP(multi layer perceptron)에 적용한다고 고려 하였을 시 뉴럴 네트워크가 감당해야 하는 feature의 차원 수는 48 * 48 * 3 = 6912이므로 작은 픽셀(저해상도)의 이미지임에도 불구라고 feature 차원이 매우 큰 것을 볼 수 있다.
-
이에 따라 컴퓨팅 속도, 오버피팅 면에서 매주 좋지 않다.
또한, MLP의 경우에는 각 샘플이 등장한 순서가 그렇게 중요하게 다뤄지지 않는다. 하지만 이미지 분석 시에는 데이터의 순서(문맥) 또한 중요한 요소로 다뤄지기 때문에 MLP로는 한계가 있었다. -
위와 같은 요인으로 인해 이미지로부터 독특한 특성만 뽑아내어 feature로 사용하는 기법이 convolution layer의 특징이고 이를 feature extraction이라 한다.
-
convolution layer의 전제조건
1, Local connectivity : 이전 레이어의 모든 뉴런 중 일부와 커널이 연결되어 special feature을 추출한다.(dense layer와 차이)
2, spatial invariance : 이미지의 한 부분의 데이터 분포는 다른 부분에서의 데이터 분포와 다르지 않다는 특징
MLP에서는 입력 샘플을 1차원의 벡터로 보았다면 convolution layer는 입력 샘플을 3차원의 tensor로 인식하고 커널 역시 3텐서로 인식하게 되고 출력의 크기는 커널의 수와 커널의 크기에 따라 결정이 된다.
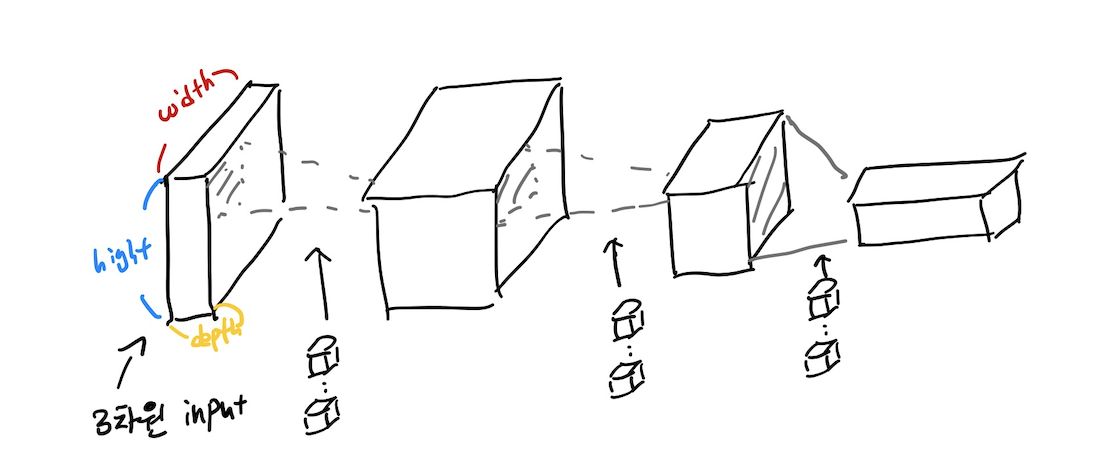
(이때, 참고적으로 1 x 1크기의 커널을 사용하여 convolution연산을 진행하는 경우가 있는데크기를 그대로 두고 채널의 수만 줄이거나 늘리는 테크닉 또한 가능하다.) -
convolution 연산에 대한 output 크기에 영향을 미치는 요인
1, 커널의 크기 및 갯수에 따라 변화
ex - 입력 크기를(H,W), 커널 크기를(K(H), K(W)), 출력 크기를(O(H), O(W))라 하였을 때 출력의 크기는 다음과 같다.
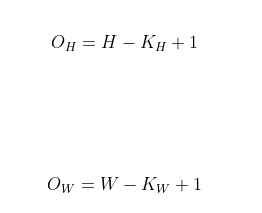
2, stride
커널을 이동 시킬 때 얼마만큼 이동시키는 지에 따라 output크기에 영향을 미친다.
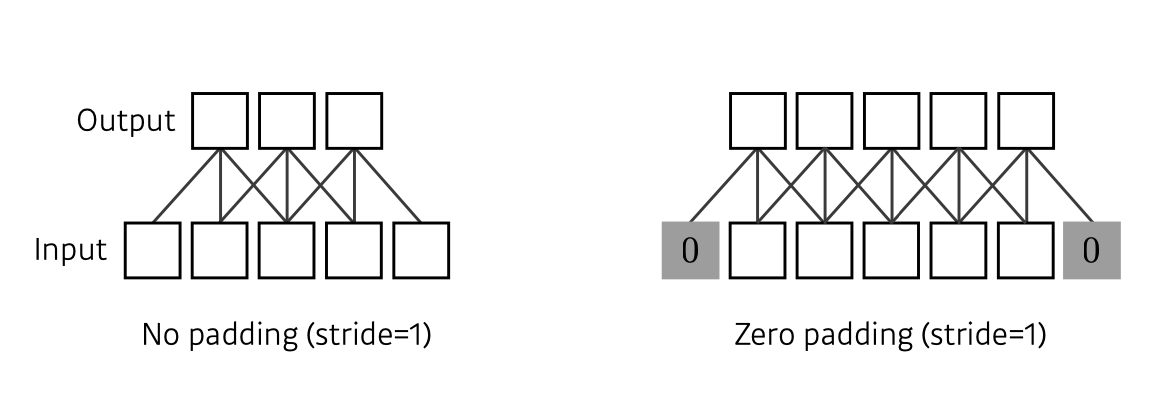
출처 : Naver BoostCamp AI Tech - edwith 강의3, output의 크기가 input에 비하여 크기가 줄어드는 현상이 발생하는데 이를 보완하기 위하여 padding을 사용하기도 한다.
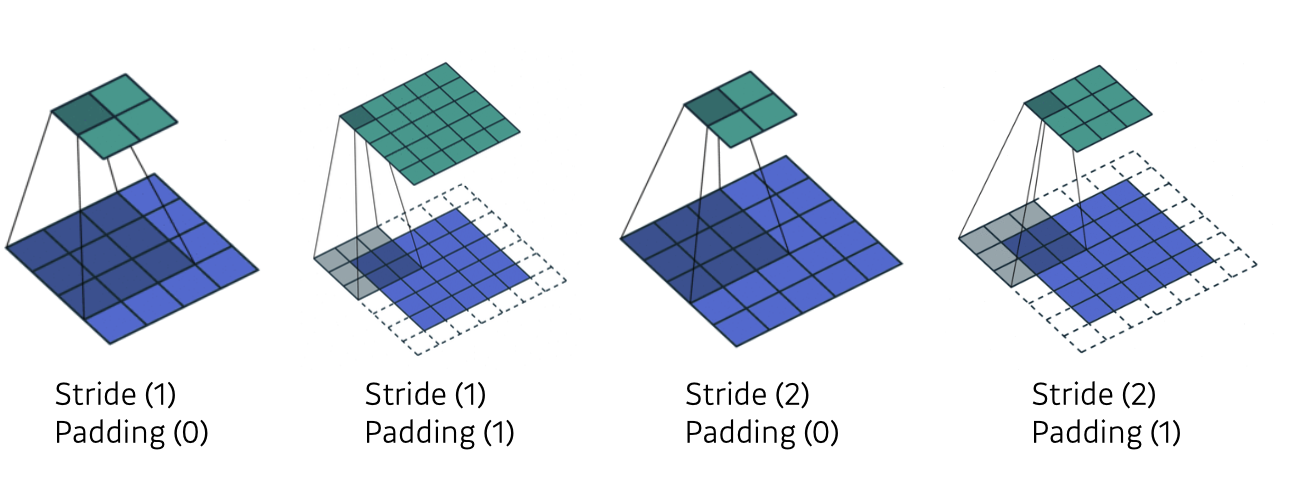
출처 : Naver BoostCamp AI Tech - edwith 강의이때, 보통 통상적으로 필터의 가로, 세로 길이를 홀수로 사용하는 경우가 있는데 첫번째 이유로는 필터 길이를 2로 나눈 몫 만큼 패딩을 붙혀주게 되면 input사이즈와 output사이즈가 같게 된다. (만약 짝수 길이면 하나의 길이를 고려했을 시 padding의 갯수는 홀수가 되어야 한다.) 두번째로는 컴퓨터 비전 문제에서 중앙값을 가지는 것이 중요하게 고려되어와서 전통적으로 쓰이는 것등의 이유가 있다.
-
필요한 파라미터 수의 계산
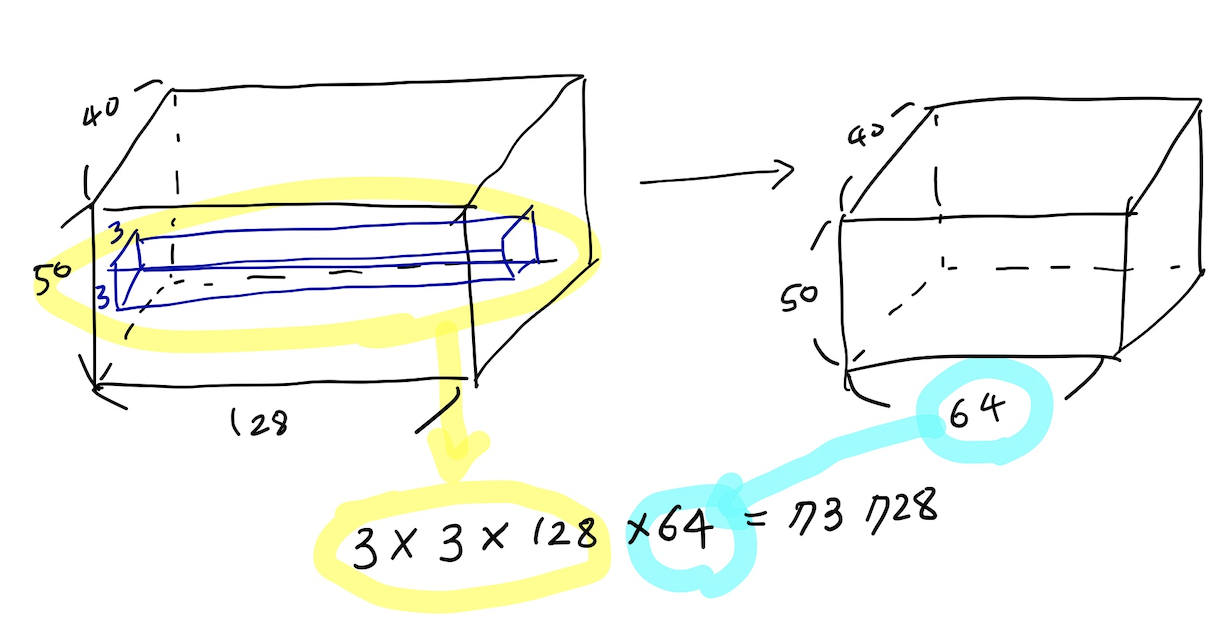
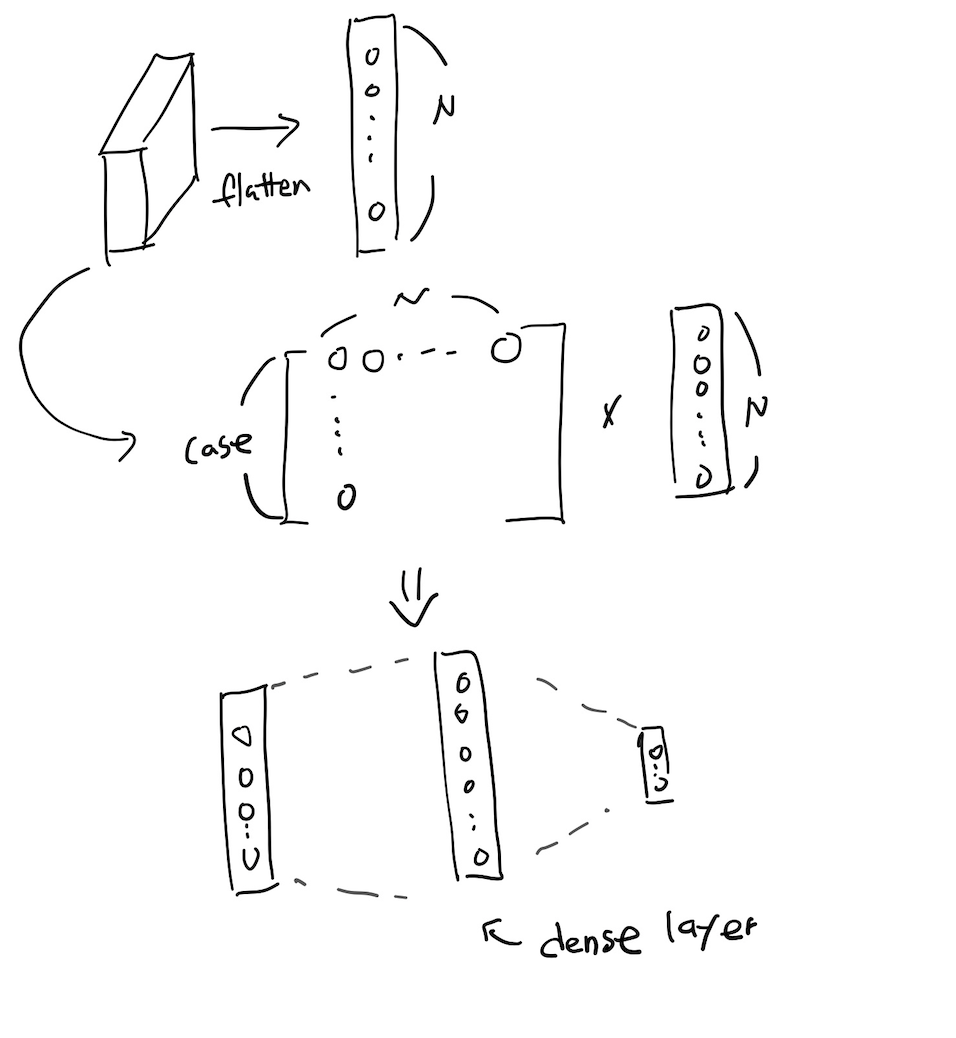
✔️ fully connected layer(dense layer)
- MLP와 같은 개념으로써 1차원 벡터에 대하여 다룸으로써 3차원 tensor를 벡터를 1차원 배열로 바꿔주고 계산을 구행하여 분류 문제를 해결한다.
- 필요한 파라미터 수의 계산
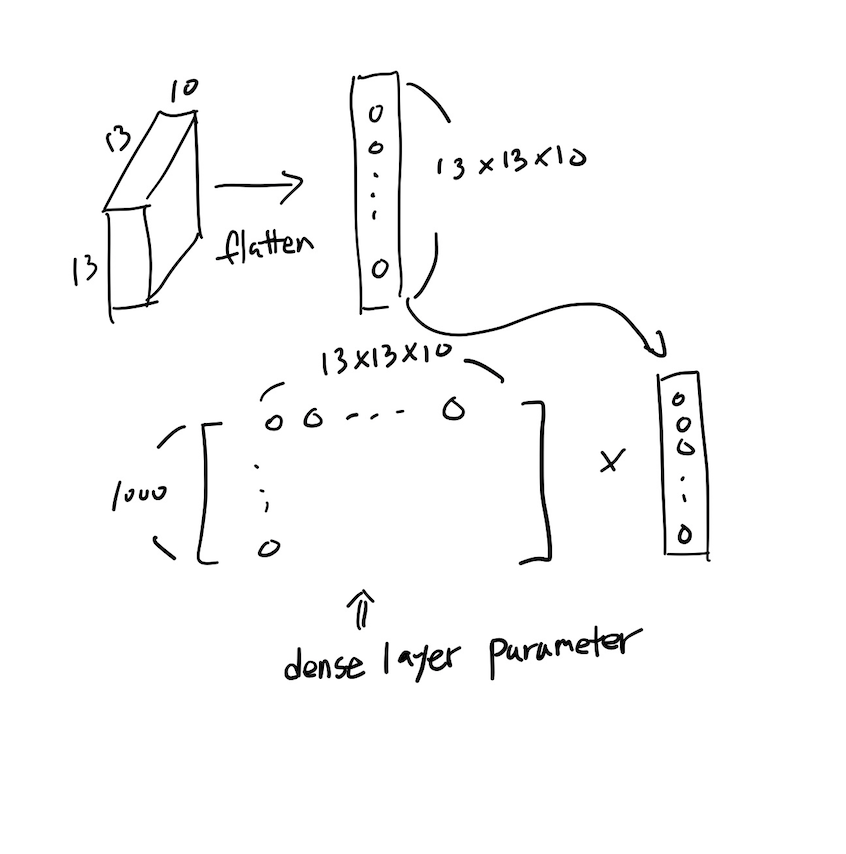
이때, 모든 노드에 대한 파라미터가 필요하기 때문에 convolution연산보다 훨씬 많은 파라미터 갯수가 필요한 것을 확인 할 수 있다.
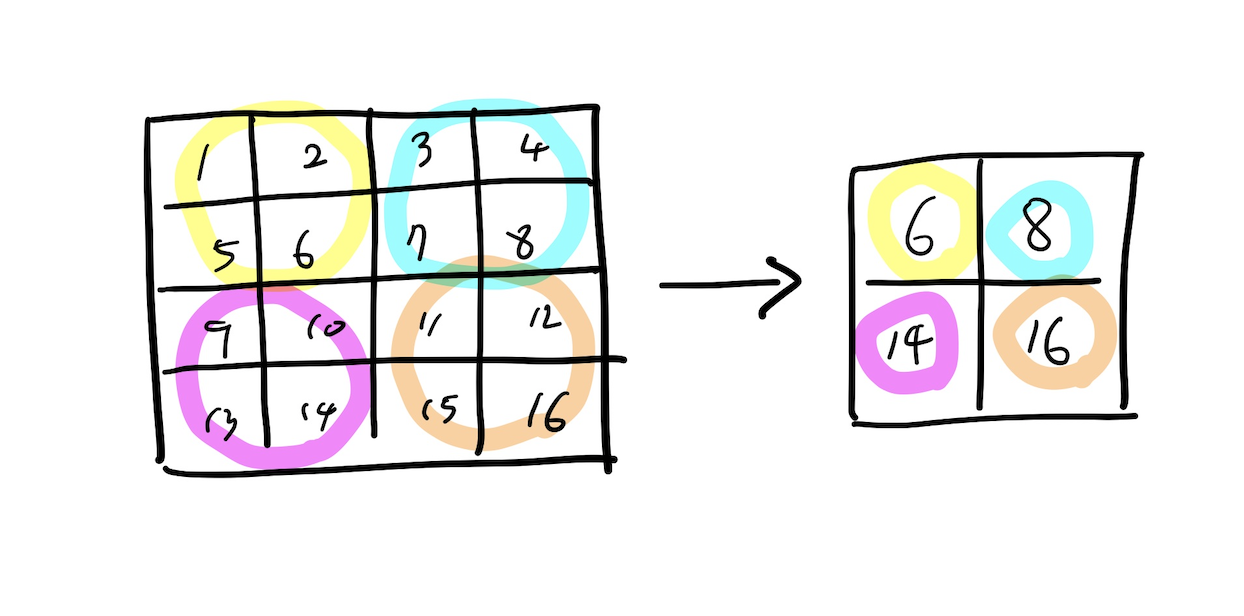
✔️ pooling
- 특징을 뽑아내는 과정으로써 convolution layer의 계산 결과를 이용하여 특징들만 뽑아와서 가져오는 기법이다.
- 정해진 크기 안에서 가장 큰 값을 가져오는 Max Pooling, 평균을 가져오는 Average Pooling등이 이용된다.
- pooling 중 대게 max pooling을 많이 사용하게 되는데 그 이유는 convolution 계산결과인 feature maps에서 filter마다 특징을 찾아내는 것인데 큰 숫자는 filter가 찾아내고자 하는 특징에 가깝기 때문이다.
- max pooling
Modern CNN
이때까지 나온 유명한 네트워크 중 몇가지에 대하여 간단하게 소개하는 식으로 정리를 해 보았습니다.
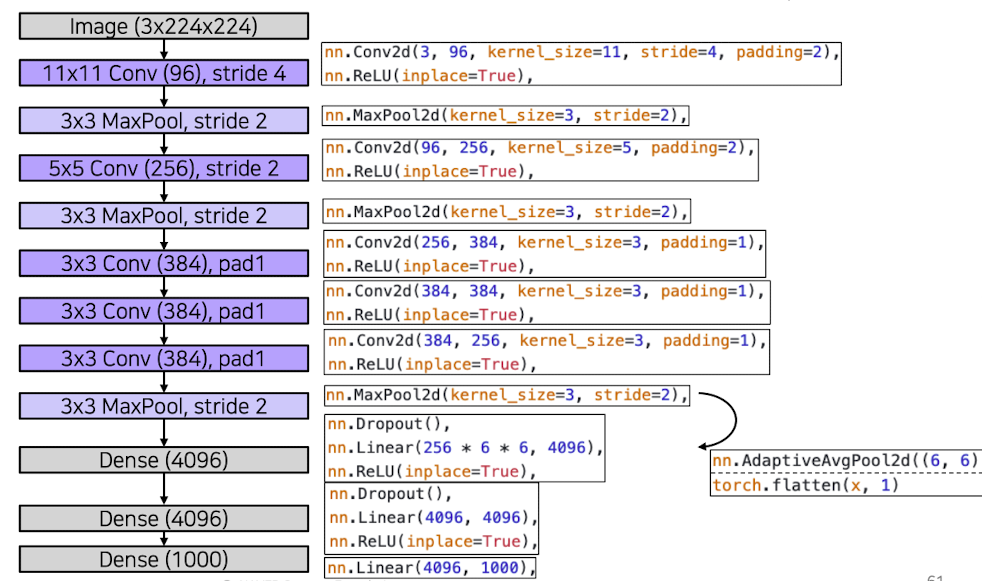
✔️ AlexNet(2012)
출처 : Naver BoostCamp AI Tech - edwith 강의
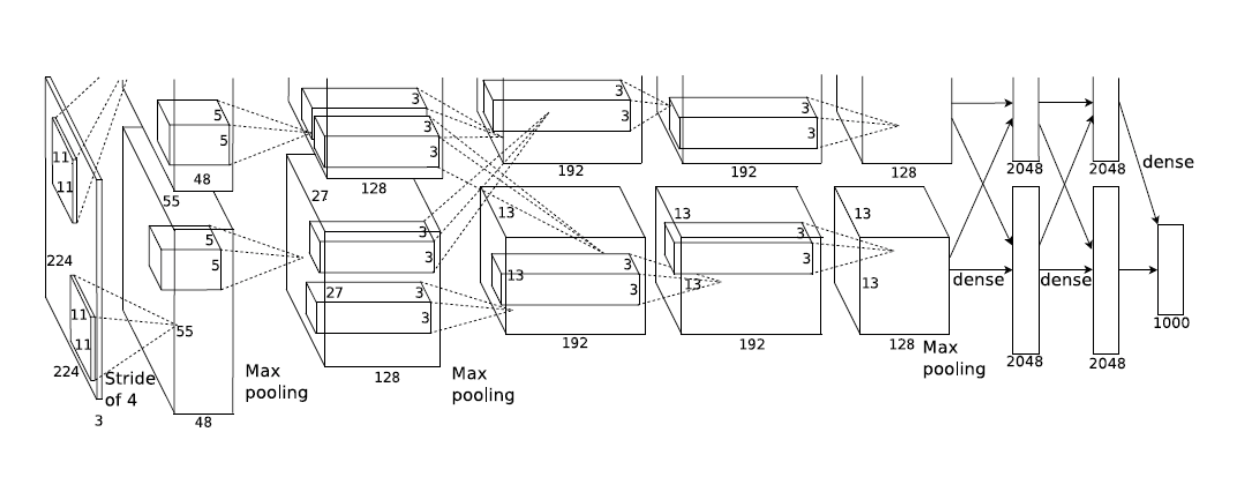
출처 : Naver BoostCamp AI Tech - edwith 강의
이때, layer수행 시(예 - fully connected layer 4096 = 2048 * 2048)데이터를 분리하여 작업을 수행 한 이유는 당시 GPU메모리 한계 때문에 다음과 같이 수행했다.
출처 : Naver BoostCamp AI Tech - edwith 강의
(LRN과정은 제외된 순서 나열)
💡 Overall architecture
Conv - Pool - LRN - Conv - Pool - LRN - Conv - Conv - Conv - Pool - FC - FC - FC
❗️Local Response Normalization(LRN) : 현재는 잘 사용되어 지지 않고 Batch normallization이 사용이 된다.
사용되어 지지 않는 이유는 다음과 같다.
1️⃣ Lateral inhibition : the capacity of an excited neuron to subdue its neighbors
2️⃣ LRN normalizes around the local neighborhood of the excited neuron
3️⃣ Excited neuron becomes even more sensitive as compared to its neighbors
💡 기본 핵심 아이디어
1, ReLU 활성함수의 사용 -> non Linear
2, GPU의 도입
3, Data Augmentation의 사용
4, Dropout 사용 -> overfitting 방지
5, local response normalization, overlapping pooling
6, Convolution : 5 X 5 filters with stride 1
7, Pooling : 2 X 2 max pooling with stride 2
💡 ReLu함수는 왜 사용 하였을까?
1, 비선형 모델 생성
2, 좋은 generalization
3, 경사하강도 최적하
4, 역전파 수행 시 미분값의 손실 방지
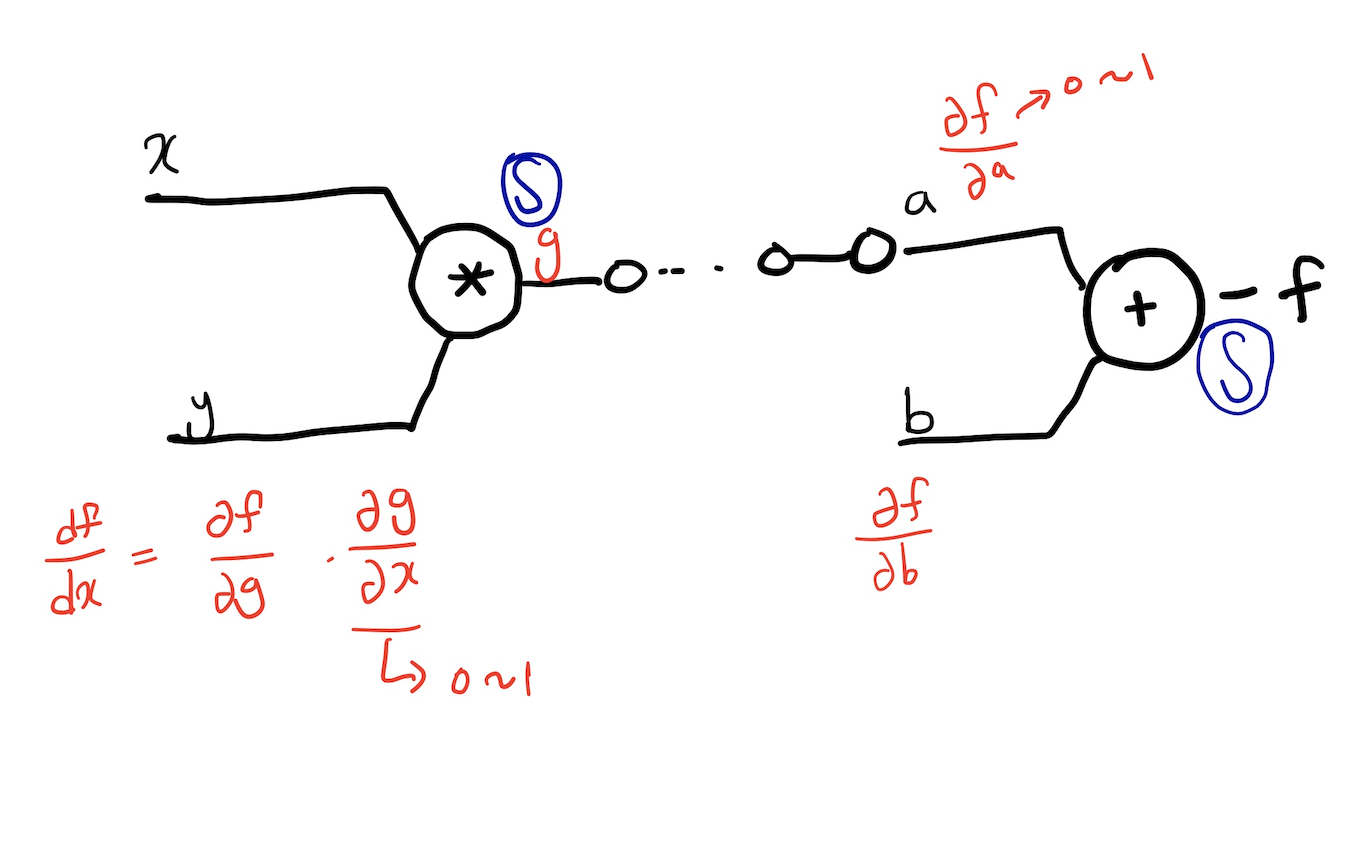
기존의 sigmoid함수는 기울기가 0~1의 값을 가지게 되는데 chain rule을 이용하여 미분값을 구하다 보면 뒤의 값들은 계속해서 작은 수가 곱해져서 아주 작은 수가 나오게 된다.(이때, 위의 연산뒤에 활성함수는 sigmoid함수가 왔다고 생각하였다.) => 이는 위의 값들이 결과값에 거의 영향을 안 주는 현상으로 이해 할 수 있다.
이에 따라 기울기가 0또는 1이면서 nonlinear한 함수인 ReLU가 현재에도 많이 사용되고 있다.
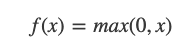
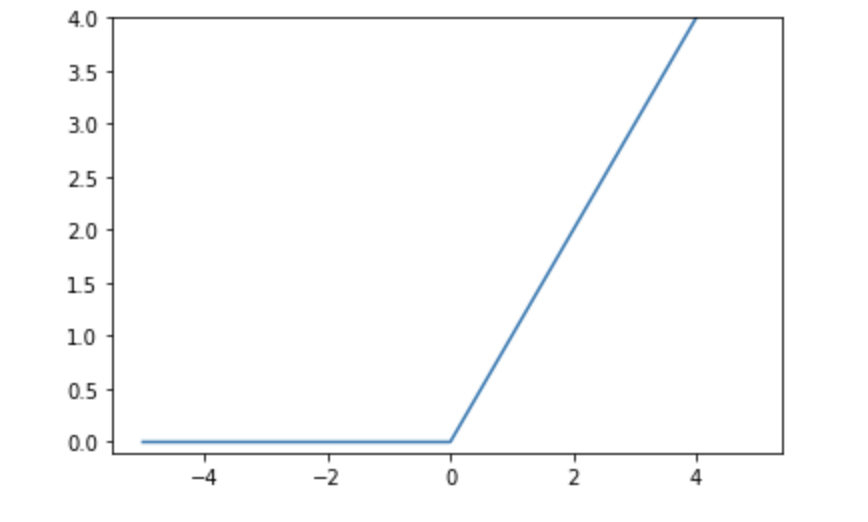
✔️ VGGNet(2015)
출처 : Naver BoostCamp AI Tech - edwith 강의
💡 기본 핵심 아이디어
1, 3 x 3 convolution filter를 사용(stride = 1)(Simpler architecture)
2, 2 X 2 max pooling(Simpler architecture)
➡️ 크기가 작아도 층을 깊게 쌓으면 넓은 receptive field 커버 가능
3, full connected layer에서의 1 X 1 convolution 연산의 사용
4, Dropout
5, VGG16(16층을 쌓음), VGG19(19층을 쌓음) -> (Deeper architecture)
6, 층을 통과한 후의 normalization과정이 존재하지 않는다.
7, input data에 대해서 224 X 224 이미지를 사용하고 RGB의 값에서 평균을 빼줌 -> normalization
8, 3개의 Fully-connected 층들이 있고 ReLu활성함수를 사용한다.
➡️ AlexNet보다 좋은 성능을 얻을 수 있었음(Better performance)
➡️ 다른 task에 대해서도 fine-tuning이 없어도 좋은 성능을 보임(Better generalization)
💡 AlexNet와 비교해 보았을 때
1, Deeper architecture
2, Simpler architecture
3, Better performance
4, Better generalization
💡 왜 3 x 3 convolution filter를 사용하였을까?
결론적으로 생각해 보면 parameter의 갯수를 줄이기 위해서다.
- receptive field : 하나의 뉴런이 원본 이미지에서 담당하는 범위
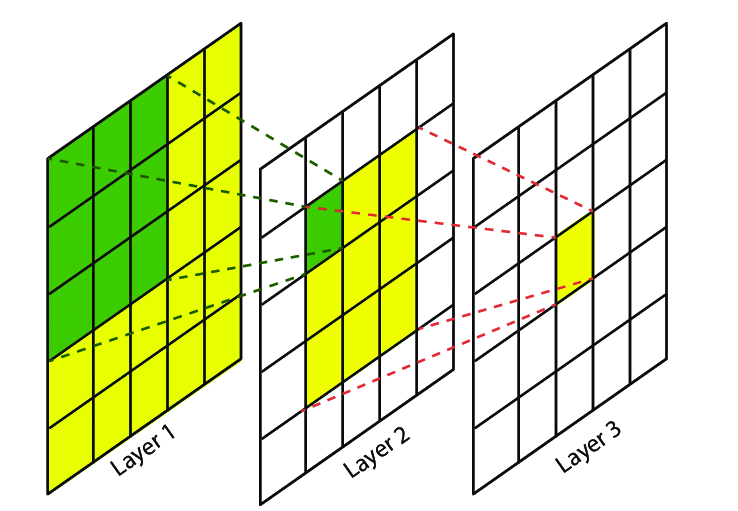
출처 : https://theaisummer.com/receptive-field/
만약, K x K convolution filter(stride = 1)와 P x P pooling layer를 거쳤다고 했을 시 하나의 데이터에 대한 receptive field는 (P + K -1) X (P + K -1)이다.
이때, 같은 receptive field를 가지기 위해 필터링을 하는 방법은 여러가지 이다.
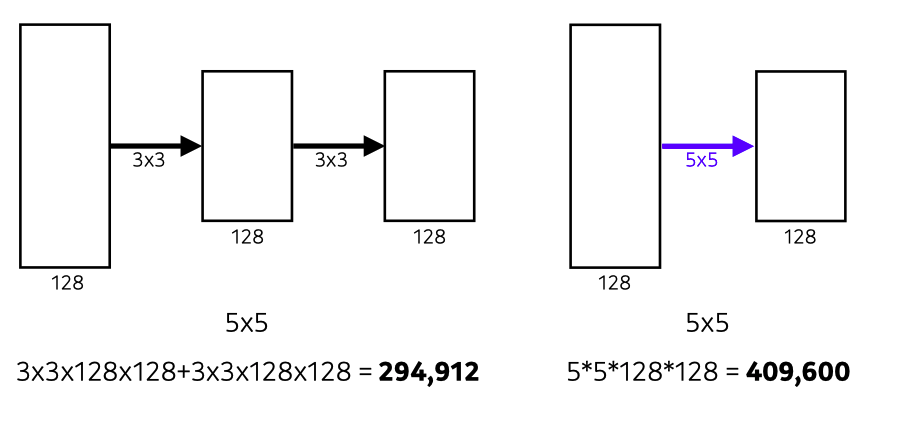
출처 : Naver BoostCamp AI Tech - edwith 강의
이때, 같은 receptive field를 가지기 위해 필터링을 해 주더라도 작은 filter크기를 depth를 깊게 하는 경우가 필요한 파라미터 수가 훨씬 적음을 알 수 있다.
❗️이렇게 층을 더욱 깊게 쌓으면 성능 향상이 일어날 것이라 예측을 하였으나 다양한 문제에 직면하여 성능향상이 더욱 되지는 않았다.
👉 Gradient vanishing / exploding
👉 Computationally complex
👉 Degradation problem<Gradient vanishing / exploding을 지칭>(Overfitiing Problem) => 이유는 weight들은 분포가 균등하지 않고 역전파가 제대로 이뤄지지 않음
⭐️ 이러한 문제를 해결하기 위해 googleNet, ResNet등 다양한 아키텍쳐들이 나오게 되었다.
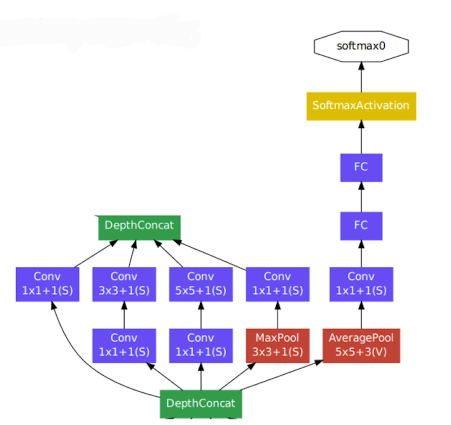
✔️ GoogleNet(2015)
- 총 22개의 층으로 구성되어 있으며 network 안에 network가 있는 형태이다.
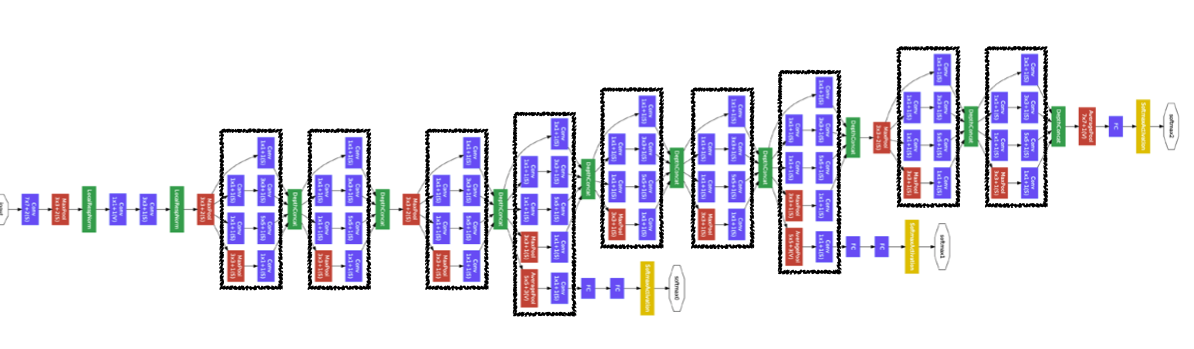
출처 : Naver BoostCamp AI Tech - edwith 강의 - 어떠한 입력이 들어왔을 때 펴졌다 다시 합쳐지는 형태
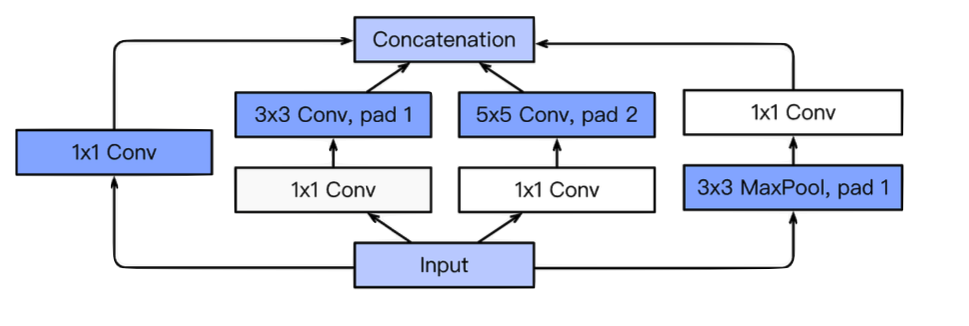
출처 : Naver BoostCamp AI Tech - edwith 강의
- 1 x 1 convolution 연산을 진행 함으로써 채널 갯수를 줄일 수 있다.
이로 인해 파라미터의 갯수를 줄여 줄 수 있음
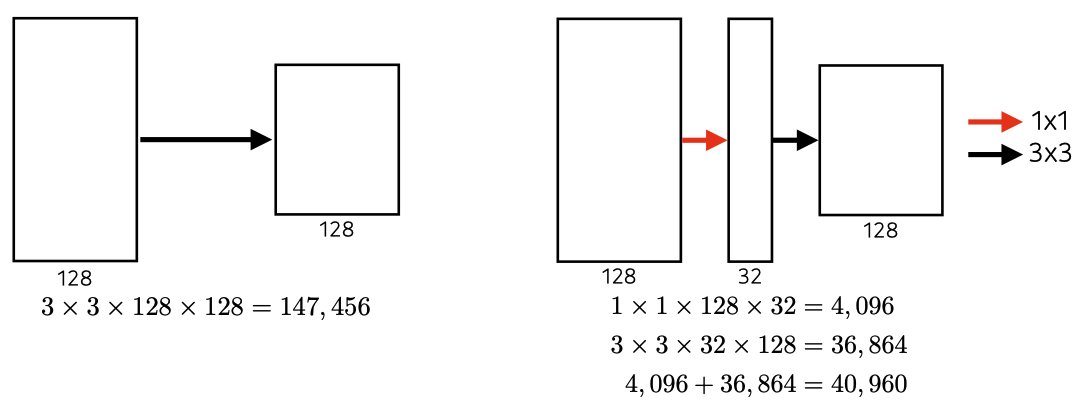
출처 : Naver BoostCamp AI Tech - edwith 강의
이때, 크기의 표현은(kernel row, kernel col, in_channel, out_channel순으로 이뤄져 있다.)
- GoogleNet에서는 gradient vanishing 문제를 해결하기 위해 추가적인 처리를 수행하였다.
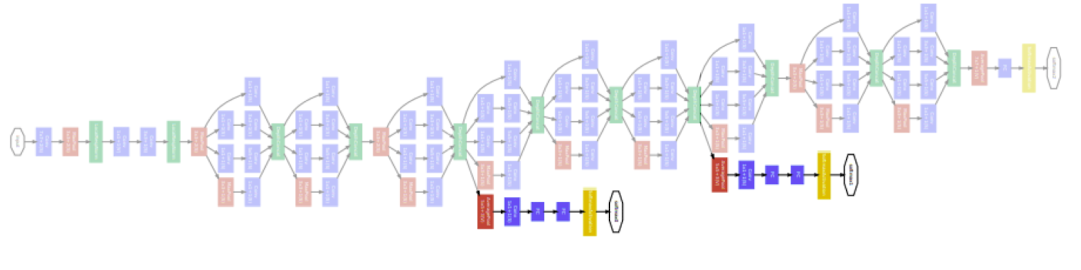
Auxiliary classifier을 넣음으로써 기울기 손실에 대하여 방지하고자 만들게 되었고 해당 부분은 학습 시에만 이뤄져 있고 실제 테스트때에는 사용하지 않는다.
⭐️ GoogleNet이 가장 효과적인 CNN모델로써 알려져 있지만 사용하기 복잡하기 때문에 VGGNet, ResNet이 backbone 모델로써 많이 사용되어 진다.

출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ ResNet(2015)
-
일정수준 층이 많아지면 학습이 더 이상 일어나지 않는 현상이 발생하게 됨
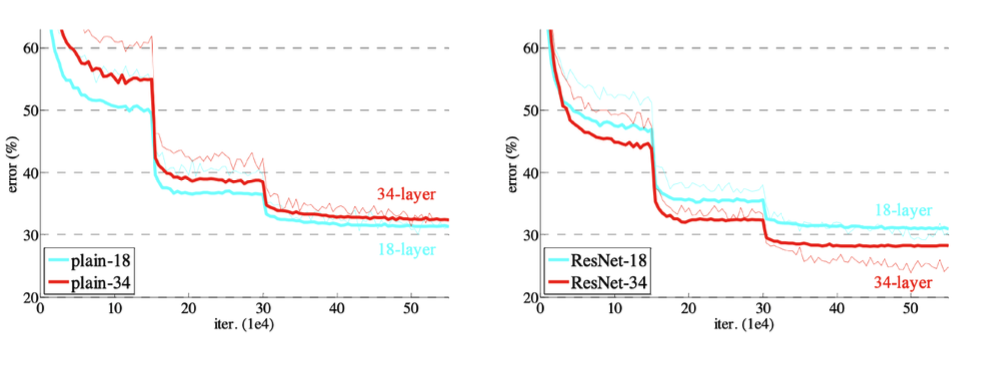
출처 : Naver BoostCamp AI Tech - edwith 강의 -
identity map을 추가(skip connection)함으로써 층이 깊어지더라도 좋은 generalization을 보이게 해 줌
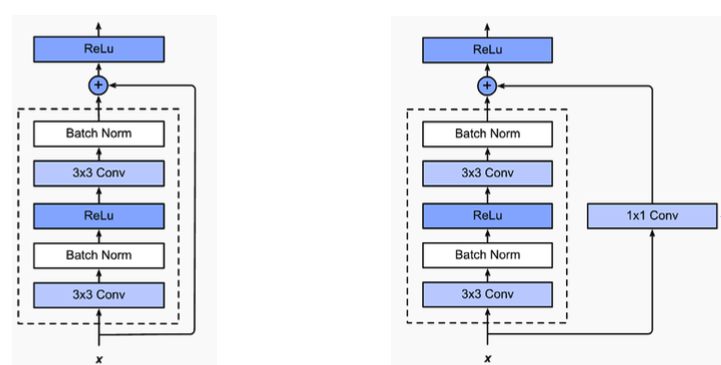
출처 : Naver BoostCamp AI Tech - edwith 강의점선 층을 거친 값을 F(X)라 하고 최종 결과를 H(X)라 한다면 H(X) = F(X) + x이다. 원래 이전에는 H(X) = F(X)로써 H(X)를 얻기 위한 학습을 했다면 ResNet은 F(X)가 0가 되는 방향으로 학습을 하고 이 관점에서 나머지(residual)를 학습한다고 보아 ResNet이라고 이름이 붙혀졌다.
이 Network로 인해 층을 깊게 쌓는 것에 대한 한계를 극복 할 수 있었다.
-
를 에 대하여 미분하게 되면 이 되는데 는 층이 깊어질수록 작은 값이 되지만 의 부분으로 인해 gradient vanishing문제를 방지 할 수 있다.
-
skip connection을 이용함으로써 굉장히 복잡한 mapping의 표현이 가능하다.
만약 개의 mapping이 존재한다면 표현할 수 있는 path의 갯수는 이 되게 된다.
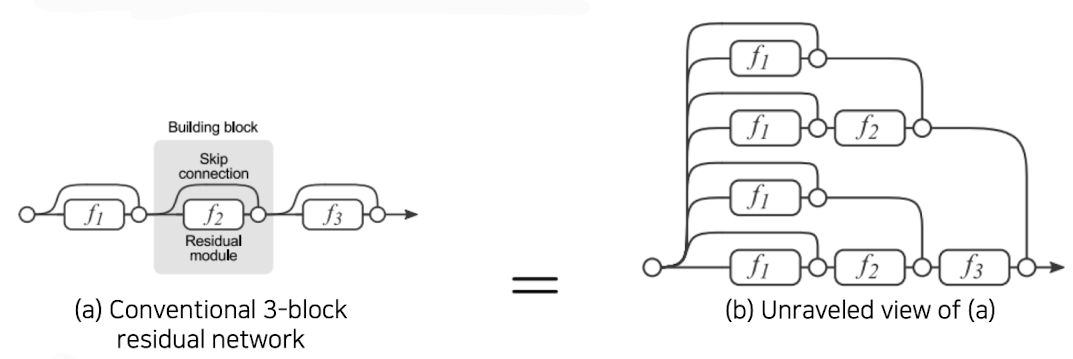
출처 : Naver BoostCamp AI Tech - edwith 강의
❗️또한, 계속 값이 더해지면 값이 커지는 현상이 발생하기 떄문에 이에 맞게 initialize방법도 같이 제시가 되었다.
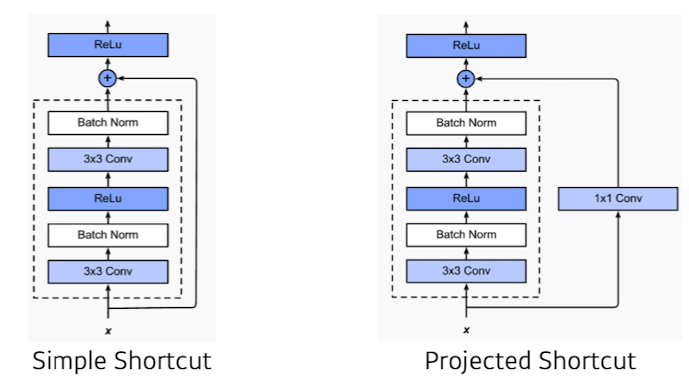
출처 : Naver BoostCamp AI Tech - edwith 강의
추가적으로 과정 곳곳에 stride를 2로 주워 공간이 줄어들게 하는 부분 또한 추가를 해 주워 모델 아키텍쳐를 설계하였다.

출처 : Naver BoostCamp AI Tech - edwith 강의 -
googleNet의 이점과 동일하게 1 x 1 convolution 연산을 진행 함으로써 채널 갯수를 줄여 큰 채널의 연산을 적은 수의 채널로 연산을 수행하였고
이를 "Bottleneck architecture"라고 한다.
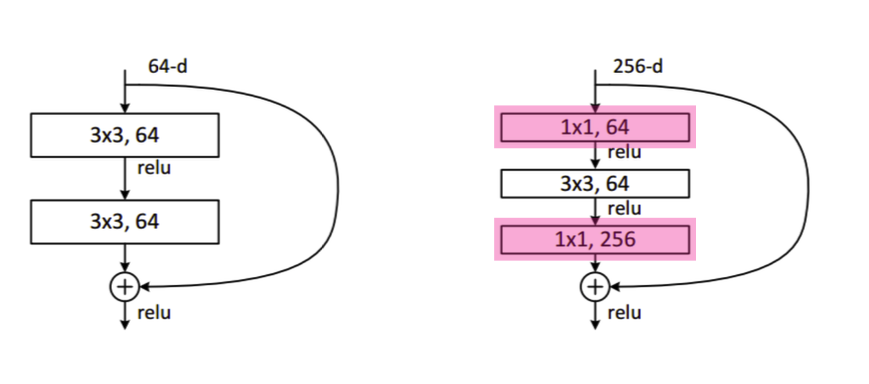
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ DenseNet(2017)
- ResNet에서의 단점은 값을 더해줌으로써 두 값이 섞이니 이를 따로 보관하자는 데에서 출발하였다. => 훨씬 이전의 layer의 정보를 넘겨줌(상위 층이 하위 층의 정보를 일일하 가지고 있음)
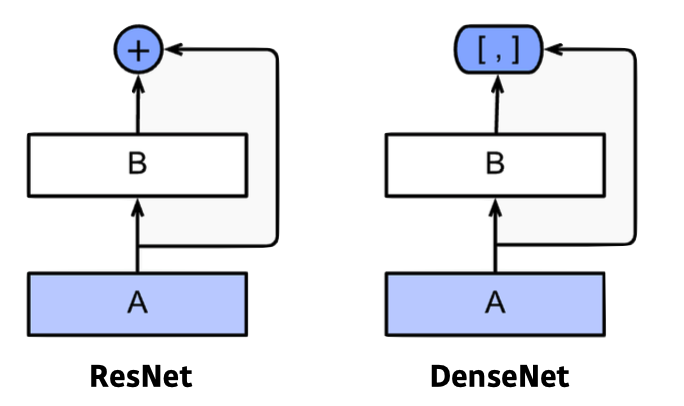
출처 : Naver BoostCamp AI Tech - edwith 강의 - 하지만, 이로 인해 값이 늘어나 파라미터의 갯수가 기하급수적으로 늘어나는 현상이 발생하게 된다.
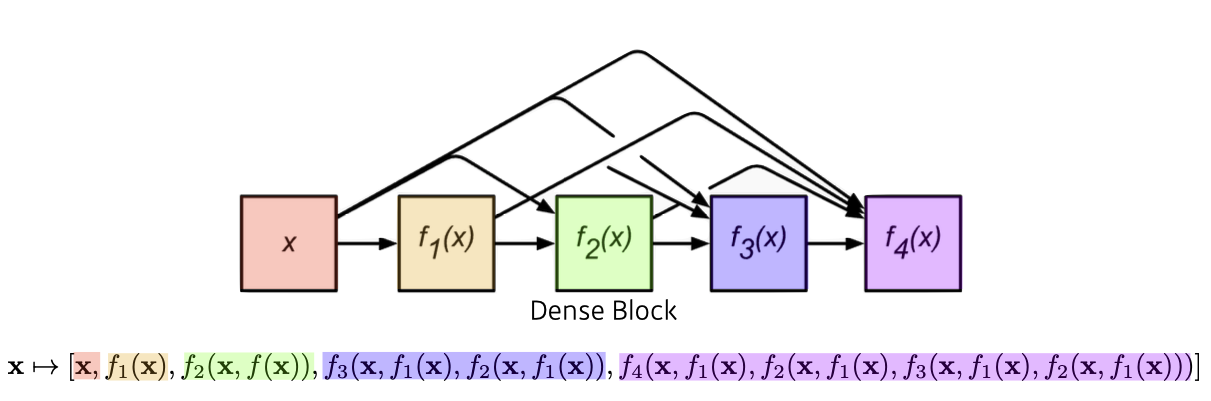
출처 : Naver BoostCamp AI Tech - edwith 강의
- 문제점을 해결하기 위해 Dense Block과 Transition Block 개념을 이용하여 해결하였다.
Dense Block : 기하급수적으로 채널의 수를 늘림
Transition Block : BatchNorm -> 1 x 1 conV -> 2 x 2 AvgPooling 즉, 1 x 1 convolution 계산을 통해 채널의 수를 줄여 문제점을 해결하였다.

출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ SENet(2018)
- 채널 간 관계, 중요도(Attention)를 파악함
- Squeeze와 Exteraction의 기법을 사용
Squeeze : 전역적인 평균 풀링을 통해 채널 응답 방식의 분포를 캡처(아래 그림에서 부분)
Extraction : FC를 통해 얻은 채널들의 Attention들의 gating channel(채널간의 연관성을 고려, 아래 그림에서 부분)
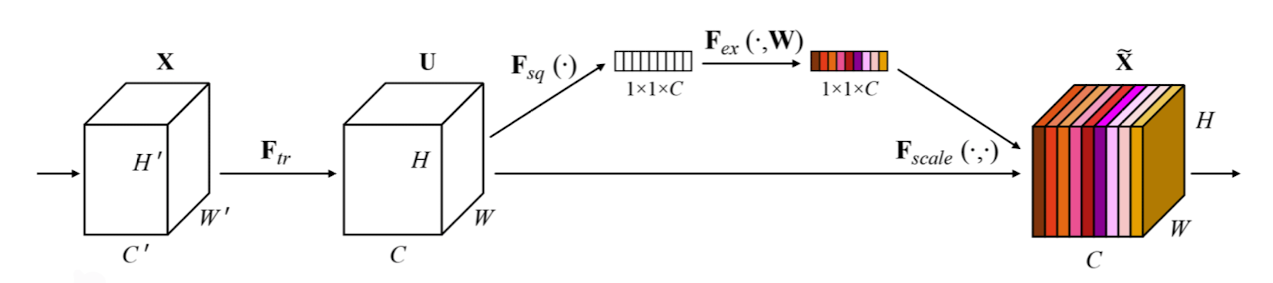
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ EfficientNet(2018)
- 여러 성능을 높히기 위한 기법들 합쳐서 좀 더 좋은 성능을 나게 하도록 설계된 아키텍처
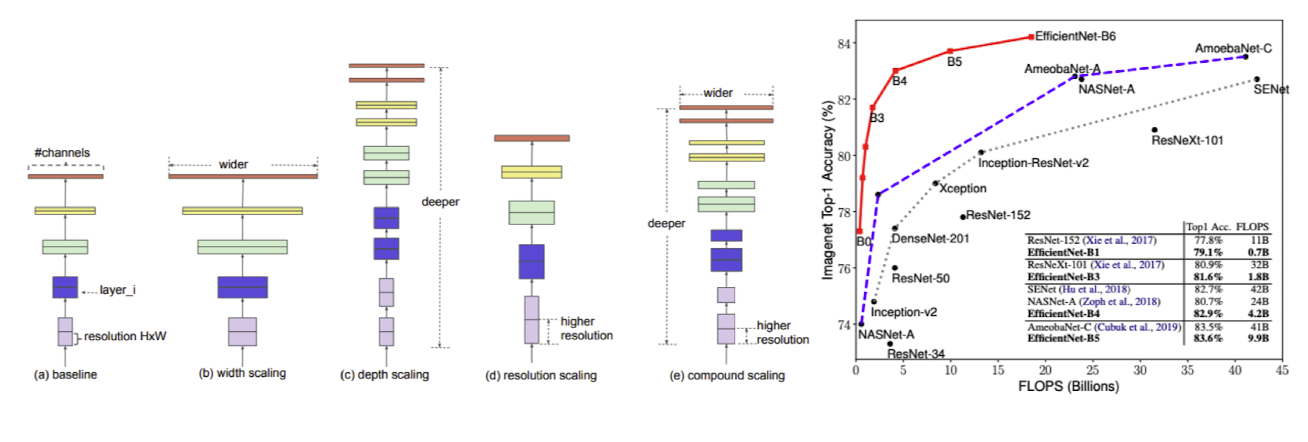
출처 : Naver BoostCamp AI Tech - edwith 강의
(b) - 채널축을 넓게(gooleNet, DenseNet)
(c) - 층을 깊게(ResNet)
✔️ Deformable convolution
-
사람이나 종물 팔다리가 변하는 등 형식적이지 않은(deformable)모양 detection을 어떻게 하면 잘할 수 있을까? 하여 나온 아키텍쳐
-
convolution에 해당하는 weight들은 따로 존재하고 offsets를 통해 weight를 늘림 => irregular한 샘플링을 통해서 activation과 irregular한 필터를 내적하여 한가지 값을 도출함
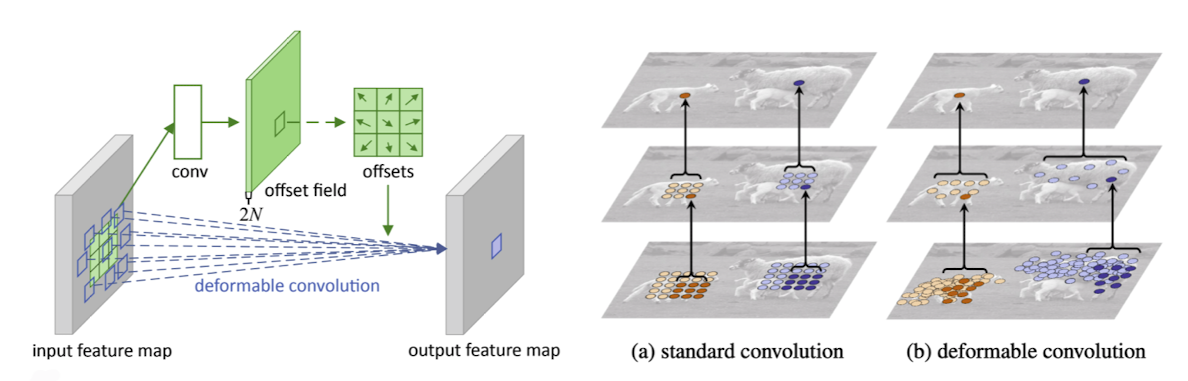
출처 : Naver BoostCamp AI Tech - edwith 강의
Segmantic Segmentation
✔️ 전제 사진을 보고 하나의 사물을 분류하는 것이 아닌 각각의 라벨에 해당하는 물건을 감지하고 분류하는 것을 말한다
✔️ Fully Convolution Network
- 보통 convolution 연산을 한 다음 dense layer(MLP)연산을 하게 되지만 Fully Convolution Network은 마지막 라벨을 구하는 과정 또한 Convolution 연산을 사용하게 된다.(즉, MLP연산을 하지 않는다.)
- 마지막 연산 시 필요한 파라미터의 갯수는 결국 동일하다.
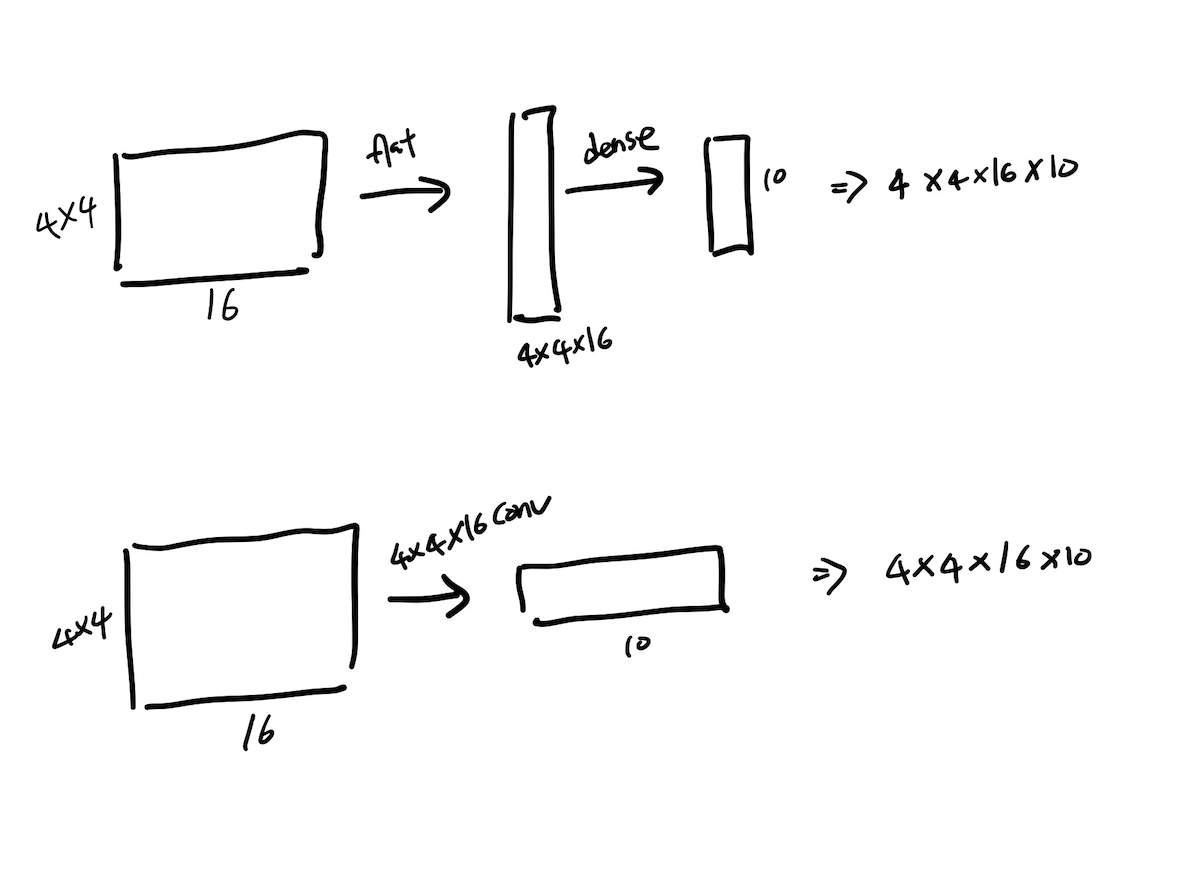
이때, 위의 10은 분류 기준의 수, 밑의 10은 커널의 갯수로 볼 수 있는데 이는 즉 커널 하나당 분류에 해당하는 값들을 도출 해 내는 하나의 filter기능인 것을 볼 수 있다. - Fully Convolution Network 를 convolution layerfh 변환하면 분류 네트워크가 heap map을 출력 할 수 있다.
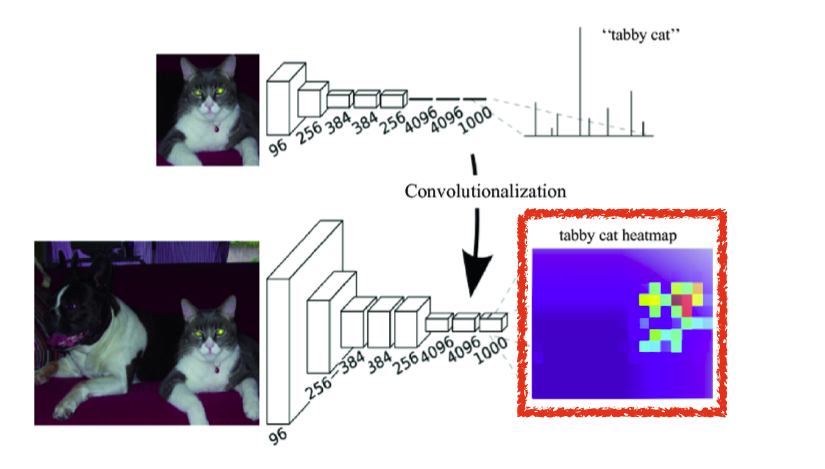
출처 : Naver BoostCamp AI Tech - edwith 강의
- Fully Convolution Network를 수행하다 보면 output의 크기(row, column의 수)가 점점 작아지게 되는데 이에따라 원래 input의 크기로 늘려주워야 한다.
이를 Deconvolution(conv transpose)라고 하는데 convolution의 역이라는 뜻이지만 이미 합을 해 준 상태이기 때문에 input값을 완전히 복원 할 수 없어 완전한 역은 아니지만 크기 관점에서 원상복귀 시켜준다는 점에서는 역의 과정이라고 생각 할 수 있다.
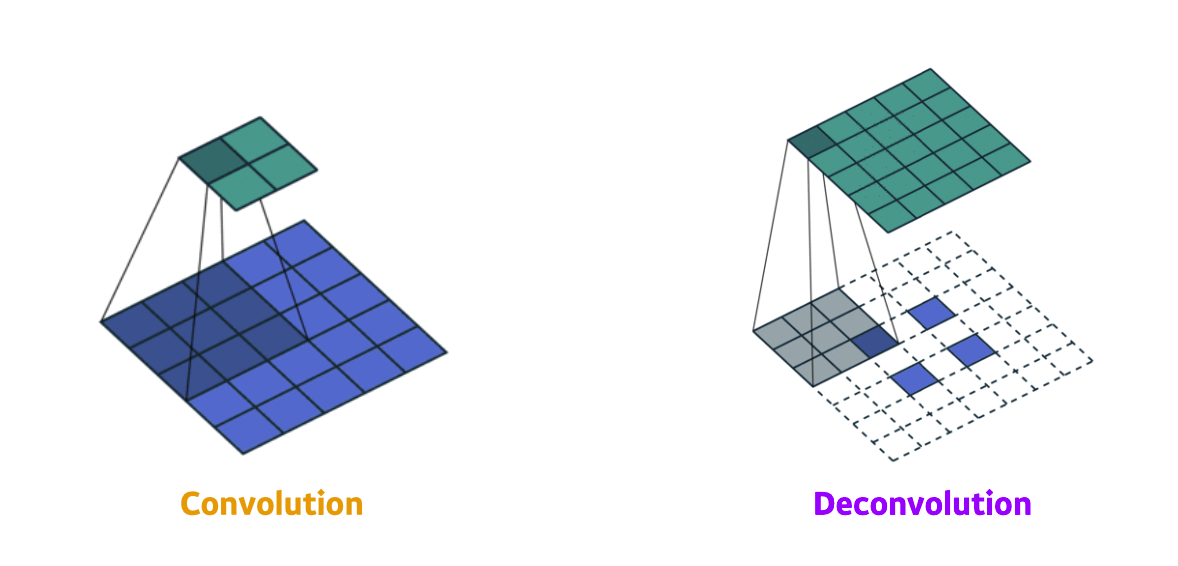
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ Detection
- R-CNN
하나의 이미지에 대하여 대략 2000개의 영역을 뽑아내고 AlexNet을 이용하여 feature을 계산 한 뒤 SVM으로 선형적으로 분리 - SPPNet
R-CNN와 달리 이미지 전체를 1번만 CNN을 수행 뒤 영역별 tensor만 가지고 와서 분류 => 결국 이 방법도 여러개의 영역에 대하여 판반을 해ㅑ 하기 때문에 속도가 느림 - Fast R-CNN
SPPNet와 분류 방법은 동일하나 Rol Feature vector(neural network 방식)층을 총하여 bounding box를 어떻게 이동하면 좋을지 분류 학습과 동시에 진행함 - Region Proposal Network
미리 bounding box의 크기를 정해 놓고 처음 물체가 있을지 없을지만 판단 후 이 판단을 이용하여 Detection유무를 판단함
- YOLO
bounding box를 따로 뽑는 로직이 없어 Faster R-CNN보다 빠르다.
여러개의 grid로 분리 한 다음 특정 수의 분류 영역으로 나눈 뒤 이미지 detection을 수행해 본다
(Detection 부분은 너무 내용이 방대 할 것 같아서 나중에 새롭게 포스팅 해봐야겠다.)
Reference
Naver BoostCamp AI Tech - edwith 강의
https://de-novo.org/2018/05/27/convnet-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0/
https://supermemi.tistory.com/16
https://www.youtube.com/watch?v=cKtg_fpw88c&list=PLlMkM4tgfjnLSOjrEJN31gZATbcj_MpUm&index=30
