
군집 구조와 군집 탐색 문제
-
군집이란?
다음을 만족하는 정점들의 집합이다.
✔️ 집합에 속하는 정점 사이에는 많은 간선이 존재
✔️ 집합에 속하는 정점과 그렇지 않은 정점 사이에는 적은 수의 간선이 존재
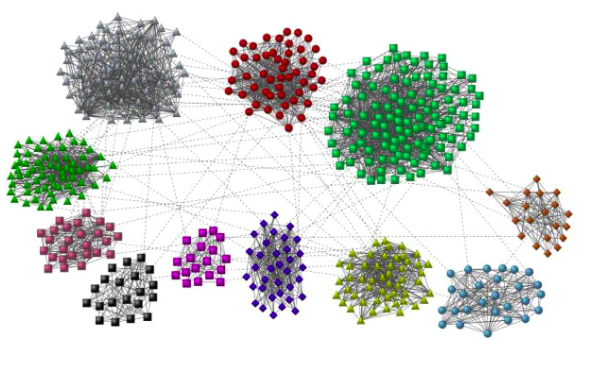
출처: Naver BoostCamp AI Tech - edwith 강의 -
군집 탐색 문제란?
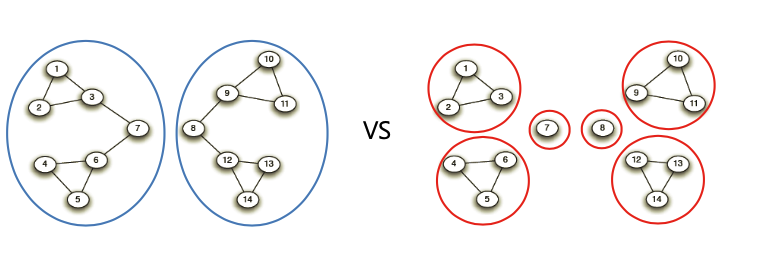
그래프를 여러 군집으로 잘 나누는 문제를 군집 탐색(community Detection)문제라 한다.
(비지도 머신러닝 문제인 Clustering과 다소 유사하다.)
군집 구조의 통계적 유의성과 군집성
-
배치 모형이란?
각 정점의 연결성(Degree)을 보존한 상태에서 간선들을 무작위로 재배치하여서 얻은 그래프를 의미
➡️ 배치 모형에서 임의의 두 정점 와 사이에 간선이 존재할 확률은 두 정점의 연결성에 비례
(연결성이란 정점과 연결된 간선의 수를 의미) -
군집성의 정의
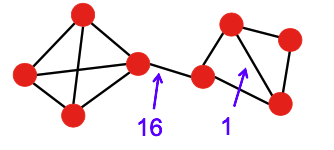
그래프와 군집들의 집합 S가 주워졌을 때 각 군집 가 군집의 성질을 잘 만족하는지 보기 위해 군집 내부의 간선의 수를 그래프와 배치 모형에서 비교한다.
✔️ 구체적인 군집성의 수식
(그래프에서 군집내부 간선의 수 - 배치 모형에서 군집내부 간선의 수의 기댓값)
➡️ 배치 모형과 비교시 그래프에서 군집 내부의 간선의 수가 월등히 많을 수록 성공한 군집 탐색이다!
❗️이때, 헷갈렸던 점이 배치 모형과 기존 그래프의 차이점이 무엇인가 헷갈렸었다. 정리해 게 되면 차이가 나는 이유를 두가지를 들 수 있는데 다음과 같은 이유이다.
➡️ imple graph(두 정점을 연결하는 간선이 한 개만 있는 그래프)와 multi graph(두 정점을 연결하는 간선이 여러 개 있는 그래프)
➡️ Edge의 수와 연결성(Degree)은 차이가 날 수 있다.(Edge가 자기 자신으로 다시 들어가는 경우 Edge - 1, Degree - 2)
👉 이를 통해 배치 모형과 기존 그래프의 차이점이 발생을 하게 된다.
✔️ 군집성은 항상 -1과 +1 사이의 값을 가진다.
✔️ 보통 군집성이 0.3 ~ 0.7정도의 값을 가질 때, 그래프에 존재하는 통계적으로 유의미한 군집들을 찾아냈다고 할 수 있다.
군집 탐색 알고리즘
- Girvan-Newman 알고리즘
✔️ Girvan-Newman 알고리즘은 대표적인 하향식(Top-Down) 군집 탐색 알고리즘이다.
✔️ 동작과정
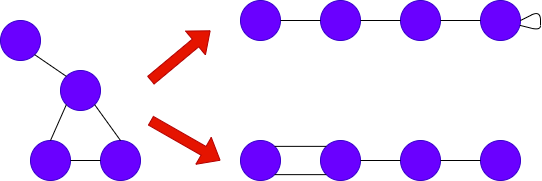
1️⃣ 전체 그래프에서 탐색을 시작하면서 군집들어 서로 분리되도록 간선을 순차적으로 제거(서로 다른 군집을 연결하는 다리(Birdge) 역할의 간선을 제거)
2️⃣ 매개 중심성이 높은 간선을 순차적으로 제거(간선의 제거 정도에 따라 다른 입도(Granularity)의 군집 구조가 나타난다.)
출처: Naver BoostCamp AI Tech - edwith 강의
3️⃣ 간선이 제거될 때 마다, 매개 중심성을 다시 계산한다.
4️⃣ 간선은 군집성이 최대가 되는 지점까지 간선을 제거한다.
✔️ 다리 역할을 하는 간선은 간선의 매개 중심성(Betweenness Centrality)를 사용한다.(간선의 매개 중심성이라 해당 간선이 정점 간에 최단 경로에 놓이는 횟수를 의미)
✔️ 매개 중심성의 수식 표현
정점 로 부터 로의 최단 경로 수를 라고 하고 그 중 간선 를 포함한 것을 라고 하면 간선 의 매개 중심성은 다음 수식과 같이 표현이 가능하다.
출처: Naver BoostCamp AI Tech - edwith 강의
- Louvain 알고리즘
✔️ Louvain 알고리즘은 대표적인 상향식(Bottom-Up) 군집 탐색 알고리즘이다.
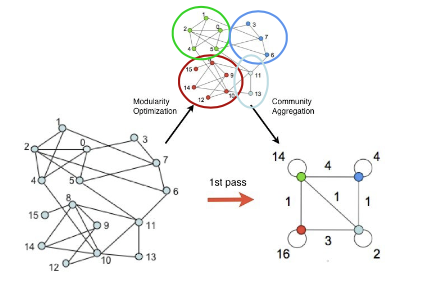
출처: Naver BoostCamp AI Tech - edwith 강의
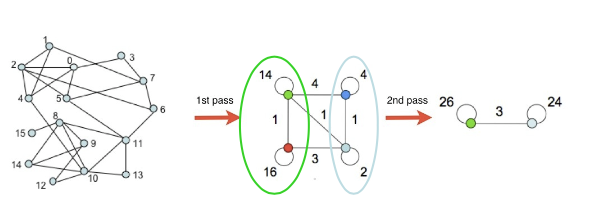
출처: Naver BoostCamp AI Tech - edwith 강의
(이때, 간선에 있는 수는 연결되어 있는 간선의 수를 의미하고 군집마다 자기 자신으로 들어가는 간선은 군집 내에 있는 간선 수 * 2이다.)
✔️ 동작의 과정
1️⃣ Louvain알고리즘은 개별 정점으로 구성된 크기 1의 군집들로부터 시작한다.
2️⃣ 각 정점 를 기존 혹은 새로운 군집으로 이동한다. 이 때, 군집성이 최대화되도록 군집을 결정한다.
3️⃣ 더 이상 군집성이 증가하지 않을 때 까지 2️⃣를 반복한다.
4️⃣ 각 군집을 하나의 정점으로하는 군집 레벨의 그래프를 얻은 후 3️⃣을 수행한다.
5️⃣ 한개의 정점이 남을 때까지 4️⃣를 반복한다.
중첩이 있는 군집 탐색
-
군집 탐색 알고리즘에서 했던 것 처럼 실생활의 그래프는 군집들이 나뉘어지지 않고 중첩되어 있는 경우가 많다.(하나의 정점이 려어 군집에 속해있는 경우)
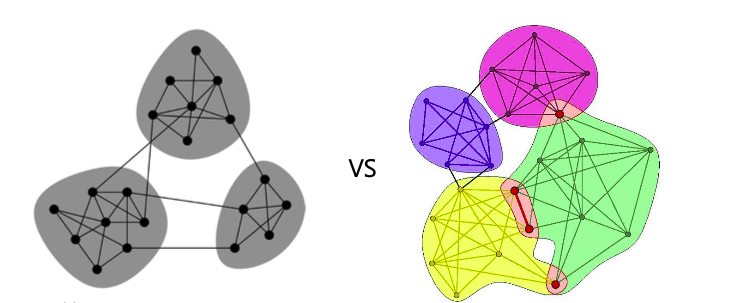
출처: Naver BoostCamp AI Tech - edwith 강의 -
이러한 상황을 위해 중첩 군집 모형을 사용한다.
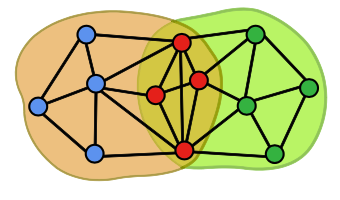
출처: Naver BoostCamp AI Tech - edwith 강의
가정 상황은 다음과 같다.
✔️ 각 정점은 여러 개의 군집에 속할 수 있다.
✔️ 각 군집 에 대하여, 같은 군집에 속하는 두 정점은 확률로 간선으로 직접 연결된다.
✔️ 두 정점이 여러 군집에 동시에 속할 경우 간선 확률은 서로 독립적이다.(두 정점이 군집 와 에 동시에 속할 경우 두 정점이 간선으로 직접 연결될 확률은 1 - (1 - )(1 - )이다.
✔️ 어느 군집에도 함꼐 속하지 않는 두 정점은 낮은 확률 으로 직접 연결된다.
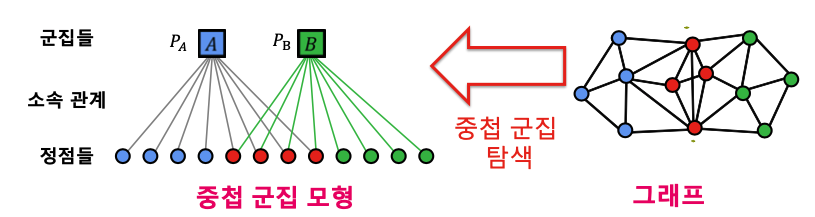
출처: Naver BoostCamp AI Tech - edwith 강의
✔️ 군집 모형이 주어지면 그래프의 확률을 구할 수 있다.(그래프의 확률은 1️⃣ 그래프의 각 간선의 두 정점이 (모형에 의해) 직접 연결될 확률과 2️⃣ 그래프에서 직접 연결되지 않은 각 정점 쌍이(모형에 의해) 직접 연결되지 않을 확률들의 곱이다.)
❗️ 중첩 군집 탐색은 주어진 그래프의 확률을 최대화하는 중첩 군집 모형을 찾는 과정이다.(최우도 추정치(Maximum Likelihood Estimate)를 찾는 과정)
⭐️ 이때, 연속확률 변수가 아니기 때문에 Maximum Likelihood Estimate를 수행하기가 어려운 점이 있는데 이를 해결하기 위해 완화된 중첩 군집 모형을 사용한다.
완화된 중첩 군집 모형에서는 각 정점이 각 군집에 속해 있는 정도를 실숫값으로 표현 ➡️ 각 정점이 포함이 되어있나 안 되어있나 이분법적으로 판단하는 것이 아닌 정도의 표현으로써 중간 상태를 표현하였다.
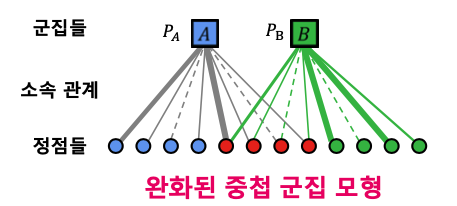
출처: Naver BoostCamp AI Tech - edwith 강의
최적화 관점에서 모형의 매개변수들이 실수 앖을 가져 익숙한 최적화 도구(경사하강법 등)를 사용하여 모형을 탐색하는 것이 가능하게 되었다.
Reference
Naver BoostCamp AI Tech - edwith 강의
