
이번 포스팅에서는 넷플릭스 첼린지에서 성능향상에 핵심적인 역활을 한 기본 잠재 모형과 고급 잠재 모형에 대한 내용을 정리해 보았습니다. 현재까지도 이 모형들은 성능을 인정받아 추천시스템에서 널리 사용되어지고 있습니다.
추천시스템 기본내용 링크 https://velog.io/@ganta/%EC%B6%94%EC%B2%9C%EC%8B%9C%EC%8A%A4%ED%85%9C-%EA%B8%B0%EB%B3%B8
기본 잠재 인수 모형
✔️ 잠재 인수 모형의 핵심은 사용자와 상품을 벡터로 표현하는 것이다.
✔️ 사용자와 영화를 임베딩한 예시
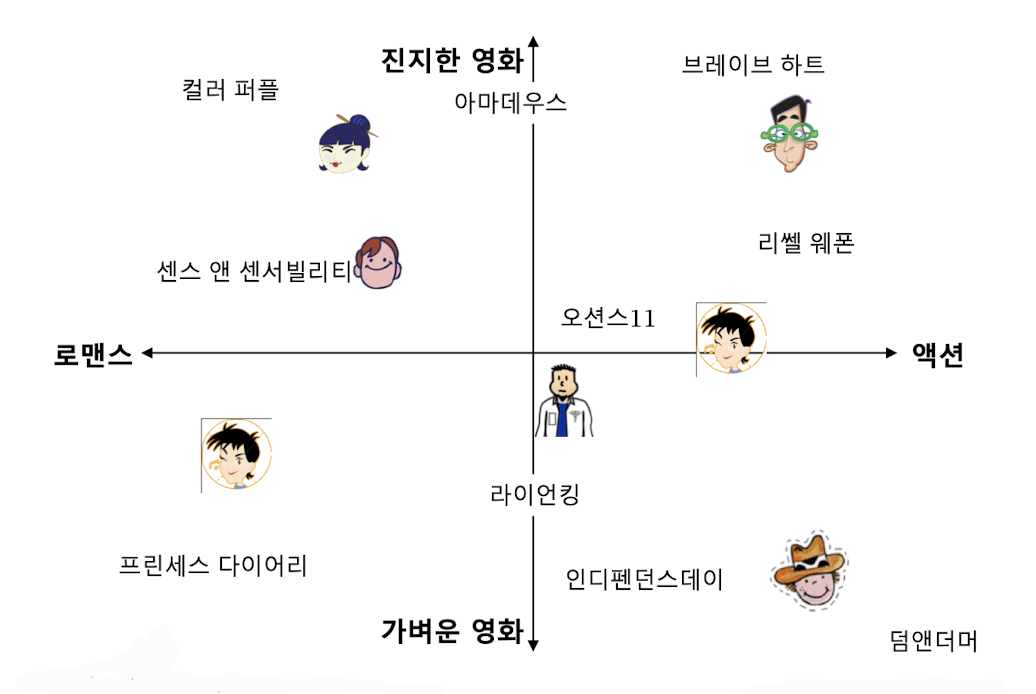
출처
Naver BoostCamp AI Tech - edwith 강의
http://www.mmds.org/mmds/v2.1/ch09-recsys2.pdf
❗️ 이때, 구체적으로 사용자나 상품이 어느정도의 성향을 가지고 있는지 구체적으로 수치를 매기는 일은 쉽지 않은 일이다. 따라서, 잠재 인수 모형에서는 고정된 인수 대신 효과적인 인수를 학습하는 것을 목표로 하고 학습한 인수를 잠재 인수(Latent Factor)라 부른다.
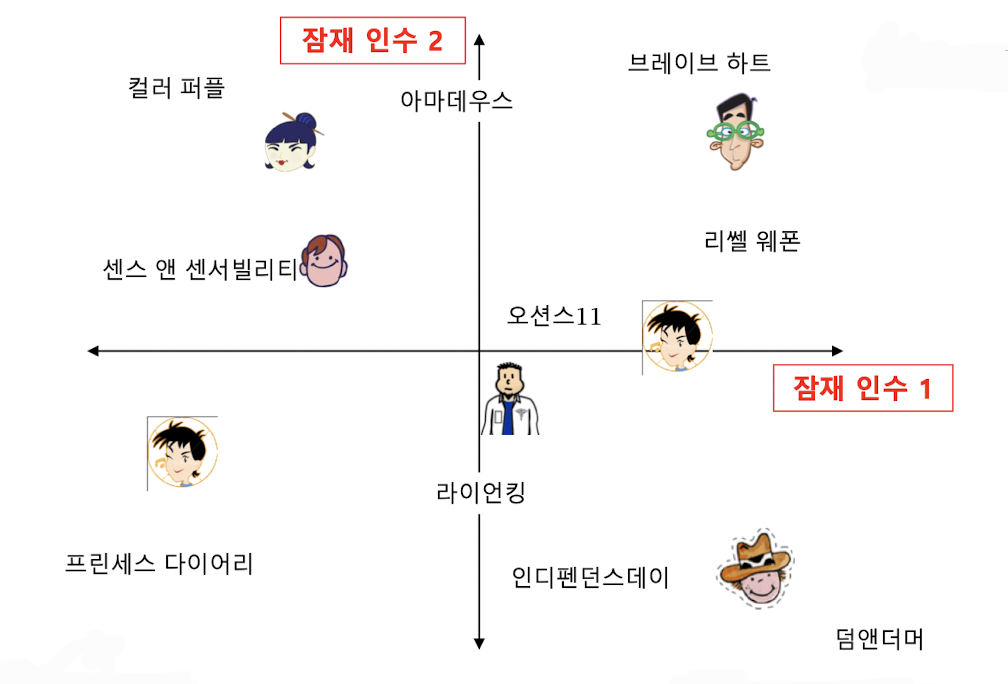
출처
Naver BoostCamp AI Tech - edwith 강의
http://www.mmds.org/mmds/v2.1/ch09-recsys2.pdf
✔️ 사용자와 상품을 임베딩하는 기준?
👉 사용자와 상품의 임베딩의 내적(Inner Product)이 평점과 최대한 유사하도록 하는 것
예시
사용자 의 임베딩을 , 상품 의 임베딩을 , 사용자 의 상품 에 대한 평점을 라고 하였을 때, 임베딩의 목표는 이 와 유사하도록 하는 것이다.
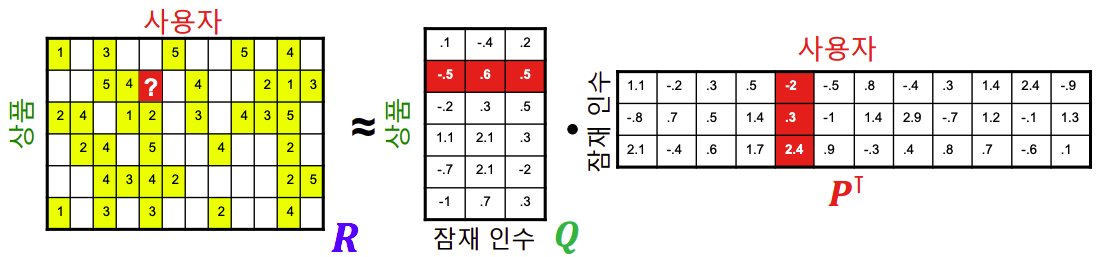
출처
Naver BoostCamp AI Tech - edwith 강의
http://www.mmds.org/mmds/v2.1/ch09-recsys2.pdf
평점 행렬 : 사용자 수의 열과 상품 수의 행을 가짐
사용자 행렬 : 사용자들의 임베딩(벡터)을 쌓아서 만듬
상품 행렬 : 영화들의 임베딩(벡터)을 쌓아서 만듬
❗️ 즉, 잠재인수라는 것은 어느정도 성향을 가지고 있는지를 파라미터 식으로 보는 것이고 기본 잠재 인수 모형은 이를 학습 하게 된다.
👉 잠재 인수 모형은 다음 손실함수를 최소화하는 와 를 찾는 것을 목표로 학습을 하게 된다.
➡️ (훈련 데이터에 있는 평점에 대해서만 계산)
❗️ 위의 손실함수를 그대로 사용할 경우 과적합(Overfitting)이 발생할 수 있다. 과적합이란 기계학습 모형이 훈련 데이터의 잡음(Noise)까지 학습하여, 평가 성능이 오히려까지 감소하는 현상을 의미한다.
⭐️ 이로 인해, 과적합을 방지하기 위해 정규화 항을 손실 함수에 더해주워 손실함수를 사용하게 된다.
➡️ ( => 모형 복잡도 / lambda : 정규화의 세기<하이퍼파라미터>)
즉, 절댓값이 너무 큰 임베딩을 방지하는 효과가 있다.
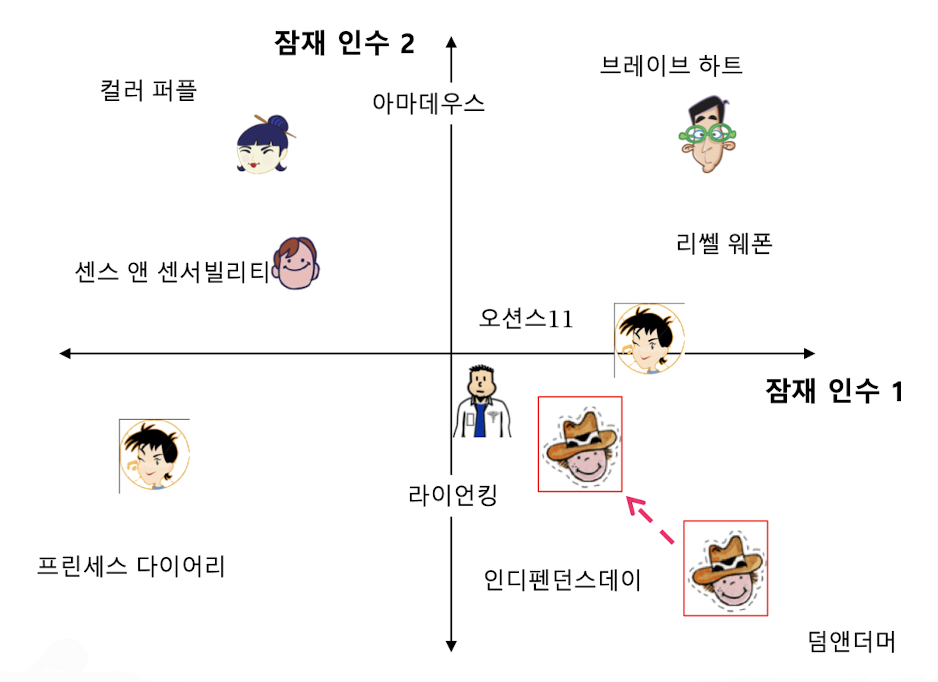
출처
Naver BoostCamp AI Tech - edwith 강의
http://www.mmds.org/mmds/v2.1/ch09-recsys2.pdf
또한, 손실함수를 최소화하는 와 를 찾기 위해서는 (확률적) 경사하강법을 사용한다.
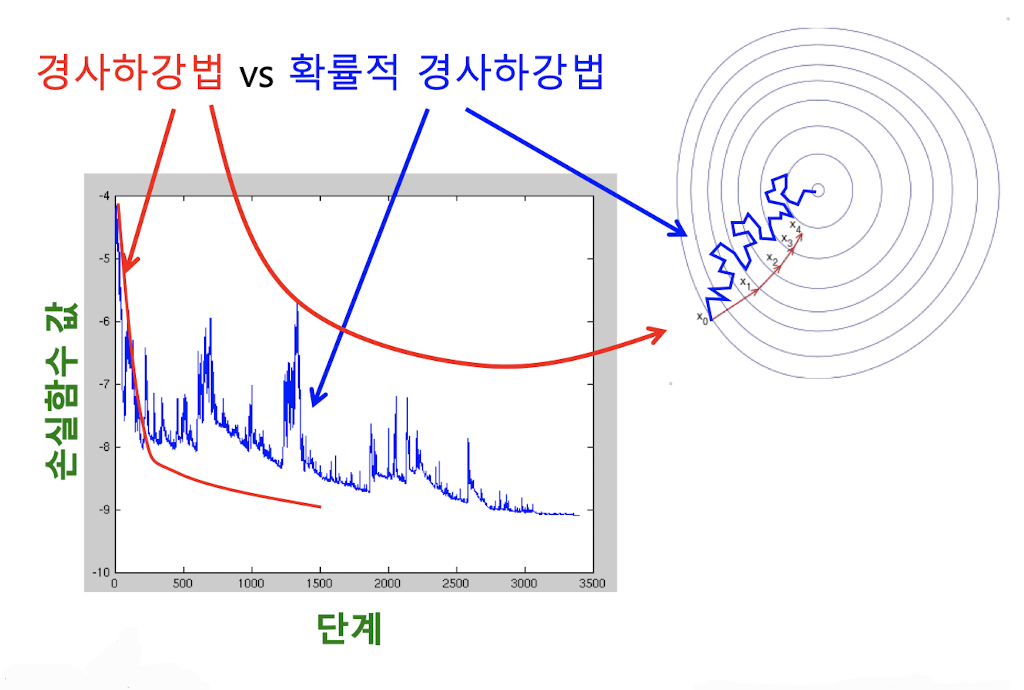
출처
Naver BoostCamp AI Tech - edwith 강의
http://www.mmds.org/mmds/v2.1/ch09-recsys2.pdf
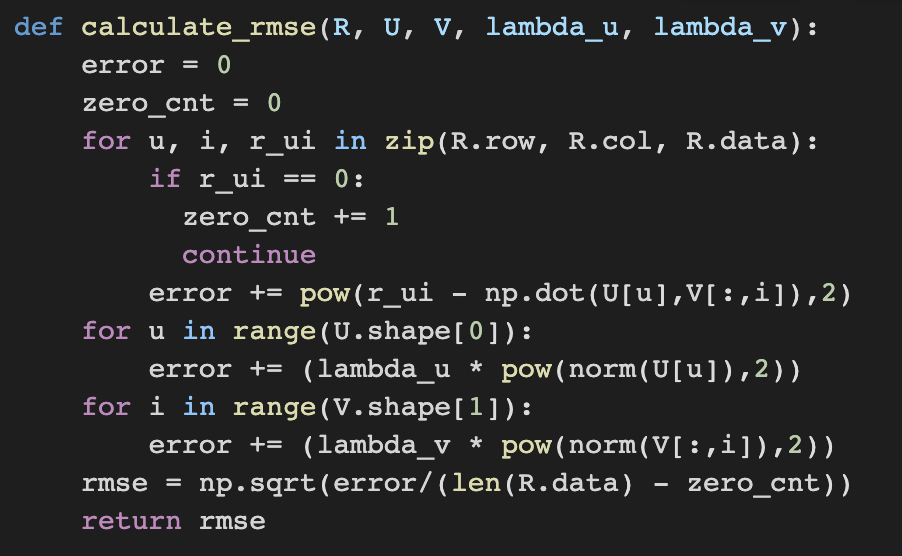
✔️ 기본 잠재 인수 모형 중 가장 기본적인 형태인 'UV 분해(UV decomposition)'의 pseudo-code코드와 간단한 구현 코드는 다음과 같다.



출처 : Naver BoostCamp AI Tech - edwith 강의
고급 잠재 인수 모형
1️⃣ 사용자와 상품의 편향을 고려한 잠재 인수 모형
2️⃣ 시간에 따른 편향을 고려한 잠재 인수 모형
1️⃣ 모형
✔️ 사용자의 편향은 해당 사용자의 평점 평균과 전체 평점 평균의 차이다.
예시
A가 매긴 평점의 평균 : 4.0
B가 매긴 평점의 평균 : 3.5
전체 평점 평균 : 3.7
➡️ A의 사용자 편향 : 4.0 - 3.7 = 0.3, B의 사용자 편향 : 3.5 - 3.7 = -0.2
✔️ 상품의 편향은 해당 상품에 대한 평점 평균과 전체 평점 평균의 차이다.
예시
a상품의 평점 평균 : 4.5
b상품의 평점 평균 : 3.0
전체 평점 평균 : 3.7
➡️ a상품의 상품 편향 : 4.5 - 3.7 = 0.8, b상품의 상품 편향: 3.0 - 3.7 = -0.7
✔️ 개선된 잠재 인수 모형에서는 평점을 전체 평균, 사용자 편향, 상품 편향, 상호작용으로 분리한다.
➡️ ( : 전체 평균, : 사용자 편향, : 상품 편향, : 상호 작용) => 기존에는 상호작용 부분만 고려했다면 개선된 잠재 인수 모형에서는 편향까지 고려
이때, 손실함수는 다음과 같다.
이때도 마찬가지로 (확률적)경사하강법을 통해 손실 함수를 최소화하는 잠재 인수와 편향을 찾아낸다.
2️⃣ 모형
위의 개선된 잠재 모형을 더욱 성능을 개선 시키고자 하는 노력을 하면서 데이터 분석을 한 결과 넷플릭스 시스템의 변화로 평균 평점이 크게 상승하는 사건, 영화의 평점은 출시일 이후 시간이 지남에 따라 상승하는 경향 등 시간의 영향또한 중요한 요소임을 확인 할 수 있었고 이를 모형에 반영하도록 개선된 모형을 만들게 되었다.
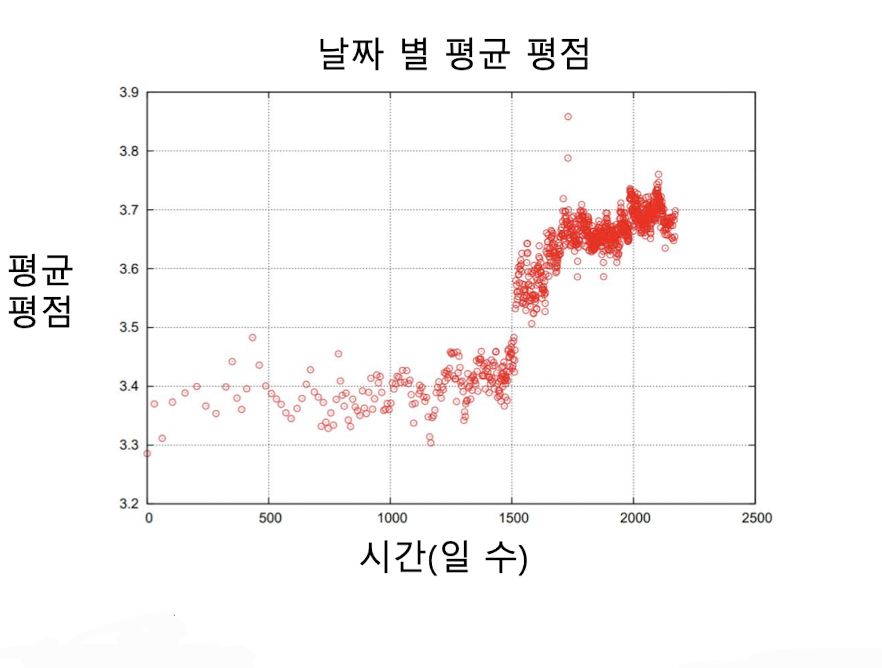
출처
Naver BoostCamp AI Tech - edwith 강의
http://www.mmds.org/mmds/v2.1/ch09-recsys2.pdf
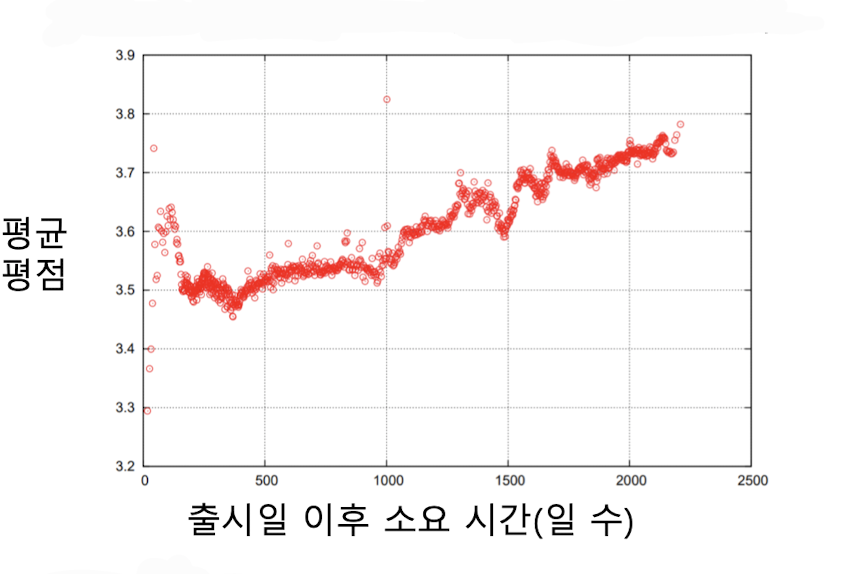
출처
Naver BoostCamp AI Tech - edwith 강의
http://www.mmds.org/mmds/v2.1/ch09-recsys2.pdf
이때, 출시일에 따른 평균평점 변화는 초반에는 간절히 영화를 기다렸던 사람이 보고 그 이후에는 평점이 점차 줄었지만 오래될 수록 굳이 찾아 볼 정도로 관심이 있는 사람들이 보게 됨으로 차이가 난다.
⭐️ 따라서, 기존 편향은 전체적인 평균을 고려하였다면 구체적으로 사용자 편향과 상품 편향을 시간에 따른 함수로 가정을 하여 좀 더 세분화를 시켜 평점을 구하도록 설계하였고 더욱 성능을 올릴 수 있었다.
➡️ ( : 전체 평균, : 사용자 편향, : 상품 편향, : 상호 작용, : 시간에 따른 함수 표현)
Reference
Naver BoostCamp AI Tech - edwith 강의
