Computer Vision - 2) CNN (with Pytorch ex.)
합성곱 신경망(Convolutional Neural Network, CNN)은 이미지 처리에 자주 사용되는 신경망입니다.
주로 " 합성곱(CONV) + 활성화 함수(ReLU) + 풀링(POOL) " 로 이뤄진 합성곱 layer와 Fully Connected Layer(FC) 를 조합해서 이미지 처리 신경망을 구성합니다.
각각의 layer에 대한 설명과 MNIST 예제를 이용한 이미지 분류까지 이 글에서 다뤄보겠습니다.
합성곱 연산
다층퍼셉트론(MLP)를 이용해서 이미지 처리 신경망을 구성할수도 있지만, 이 경우 2차원 이미지를 1차원인 벡터로 변환하여 처리하기때문에 공간적인 구조정보가 유실되며, 픽셀이 조금만 이동해도 완전히 다른 벡터가 된다는 단점이 있습니다.
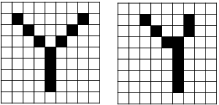
위의 두 그림 모두 알파벳 Y를 나타내지만, 픽셀단위로 보면 두 그림에서 모두 검정인 픽셀은 2개밖에 존재하지 않습니다. 즉 기계 입장에서는 완전히 다른값을 가지는 벡터입니다. 이미지에서는 이렇게 약간 휘어지거나, 이동되거나, 돌아가거나 하는 등 약간의 변형으로 벡터값이 완전히 바뀌게 됩니다.
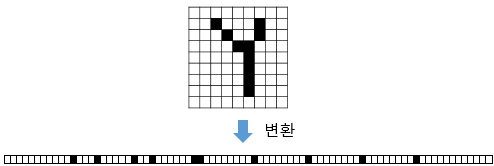
위 그림과 같이 이미지를 벡터로 변환하게되면 사람도 이미지를 구분하기 어렵게 되며, 픽셀간 상하좌우 관계가 대부분 유실되게 됩니다. 이 문제를 해결하기위해 공간적인 구조정보를 보존하는 합성곱 신경망을 사용하게 되었습니다.
합성곱 연산에는 다양한 개념이 존재합니다.
Kernel, Stride, Padding, Feature Map 의 개념을 알아보도록 하겠습니다.
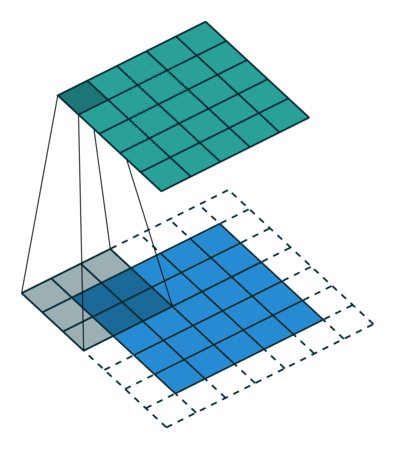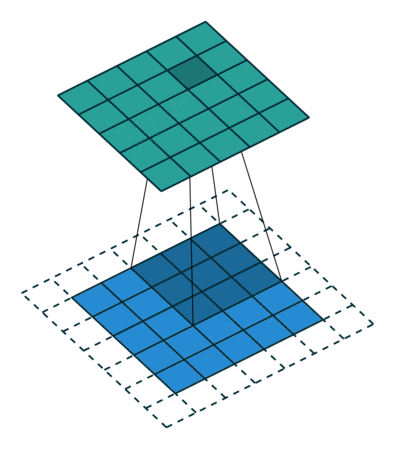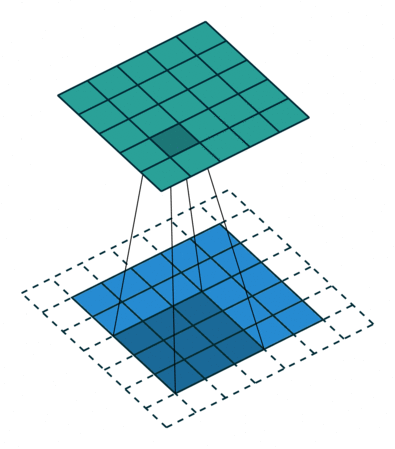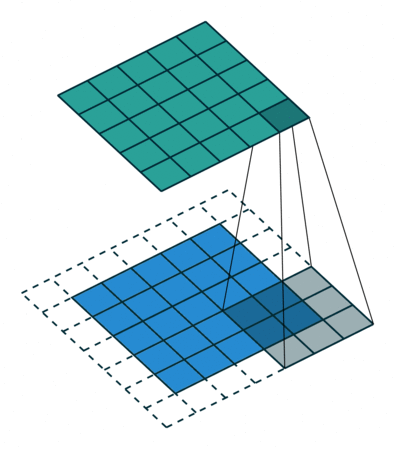
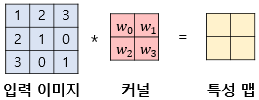
합성곱 연산은 이미지의 특징을 추출하는 역할을 합니다. Kernel(또는 filter)라는 nxm 크기의 행렬로 높이(h) x 너비(w) 크기의 이미지를 처음부터 끝까지 훑으면서 겹쳐지는 부분의 이미지와 Kernel의 원소의 값을 곱해서 모두 더한값을 출력하는 연산을 말합니다. Kernel은 일반적으로 3x3 이나 5x5 크기를 사용합니다.
예시를 통해 설명해보겠습니다. 아래는 3x3 크기의 Kernel로 5x5 크기의 이미지에 합성곱 연산을 수행하는 예시입니다.
- 합성곱 연산을 수행할때 이미지의 좌상단부터 우하단까지 순차적으로 진행합니다.
- Kernel이 한번에 이동하는 거리를 Stride라고 합니다.
1st Step
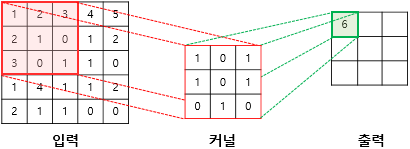
(1x1)+(2x0)+(3x1)+(2x1)+(1x0)+(0x1)+(3x0)+(0x1)+(1x0) = 6
2nd Step
( Stride = 1 이므로 오른쪽으로 1px만큼 이동하여 계산합니다. )
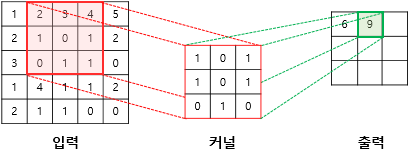
(2x1)+(3x0)+(4x1)+(1x1)+(0x0)+(1x1)+(0x0)+(1x1)+(1x0) = 9
3rd Step
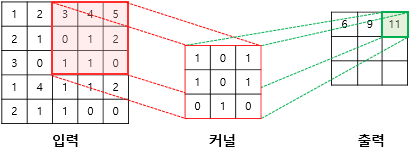
(3x1)+(4x0)+(5x1)+(0x1)+(1x0)+(2x1)+(1x0)+(1x1)+(0x0) = 11
4th Step
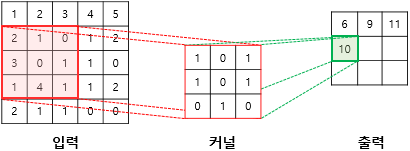
(2x1)+(1x0)+(0x1)+(3x1)+(0x0)+(1x1)+(1x0)+(4x1)+(1x0) = 10
이렇게 9th step까지 진행하면 최종결과로 다음과 같은 행렬을 얻을 수 있습니다.
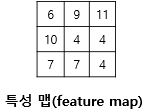
이렇게 합성곱 연산을 통해 나온 결과를 특성 맵(Feature Map)이라고 합니다.
Feature Map의 크기는 Image의 크기와 Kernel의 크기, Stride에 따라서 달라지게 됩니다.
그런데, 위 연산처럼 5x5 이미지에 3x3 Kernel을 사용해 합성곱 연산을 하면, Feature map의
크기는 입력보다 작아지게 됩니다. 만약, 합성곱 층을 여러개 쌓았다면 최종적으로 얻은 결과값은 초기 입력보다 매우 작아진 상태가 되어버립니다. 합성곱 연산 이후에도 입력과 특성맵의 크기를 동일하게 유지되도록 하고 싶다면 패딩(Padding)을 사용하면 됩니다.
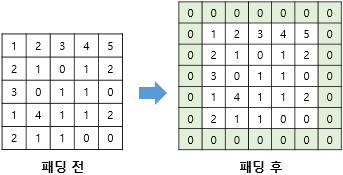
패딩은 합성곱 연산 전, 입력의 가장자리에 지정된 폭만큼 행과 열을 추가하는것을 말합니다. 주로 값을 0으로 채우는 제로 패딩(zero padding)을 사용합니다. 위 그림은 5x5 입력에 폭 1짜리 제로 패딩을 적용한 결과입니다. 이렇게 패딩을 적용하고 합성곱 연산을 하면 입력과 특성맵의 크기를 같도록 조절할 수 있습니다.
MLP와 CNN은 어떻게 다를까요?
다층퍼셉트론도 이미지처리에 사용할 순 있습니다. 하지만 앞에서 언급했듯이 공간적 정보가 유실되어 성능이 좋진 않습니다.
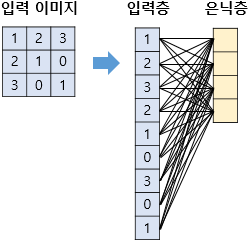
위 그림과 같이 이미지는 벡터로 변환되고 모든 픽셀이 은닉층 각각의 계산값으로 들어가게 됩니다. 총 가중치 개수는 9x4 = 36개가 필요하게되고 학습에 있어서도 36개의 parameter를 학습하게 됩니다. 그러면 합성곱연산에서는 어떻게 될까요?
똑같이 3x3 이미지를 처리한다고 가정하고, 2x2 Kernel, Stride = 1로 계산하면 2x2의 특성맵을 얻게 됩니다. MLP처럼 그림으로 표현하면 다음과 같게 됩니다.
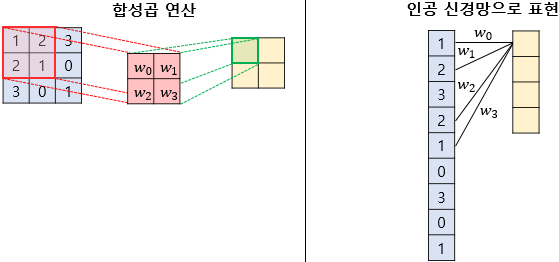
하나의 값을 얻기위해 9개 픽셀 모두가 필요한것이 아니라 4개의 픽셀값만 필요하고, 공간적 정보도 보존할 수 있게 되었습니다. 총 가중치 개수는 4x4 = 16개가 필요하게 되어 기존보다 학습할 parameter 개수가 줄어들게 됩니다.
RGB image는 어떻게 처리할까요?
컬러 이미지는 주로 Red, Green, Blue의 3가지 채널을 가지게 됩니다. 이 경우 각 채널마다 따로따로 합성곱 연산을 진행하고 특성맵을 전부 더해서 하나의 Feature Map을 얻게 됩니다.
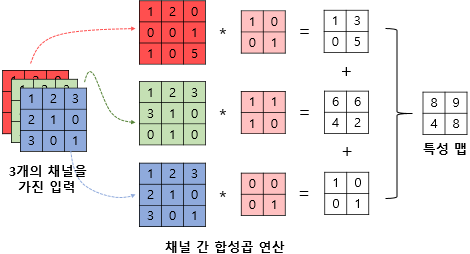
커널이 하나일때는 특성맵 1개를 얻게됩니다. CNN에서는 주로 같은 크기의 커널을 여러개 학습시킵니다. 커널이 N개 일때는 N개의 특성맵을 얻게 됩니다.
풀링 연산
합성곱 연산을 진행한 뒤, 주로 풀링(Pooling)연산을 진행해줍니다. Feature map의 차원을 줄여 계산량을 줄이는 용도입니다. 풀링연산을 진행한 뒤 Fully Connected Layer와 연결해 최종적으로 분류를 진행하게 됩니다.
풀링연산은 주로 Max Pooling과 Average Pooling을 사용합니다. 초기에는 주로 Max Pooling을 사용했지만 최근에는 Pooling 대신 합성곱 연산에서 Stride를 증가시키는 식으로 차원축소를 진행합니다. ( Deep한 신경망일수록 미세한 정보들이 중요한데, Max Pooling은 이런 미세한 feature들이 유실되기 때문 )
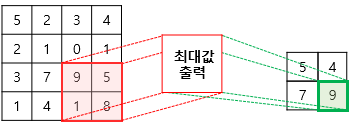
풀링 연산에서도 Kernel과 Stride의 개념을 가집니다. 위 그림은 Max Pooling에 2x2 Kernel과 Stride=2인 연산을 표현한 것입니다. 특성맵의 크기가 줄어든것을 볼 수 있습니다.
Reference
https://wikidocs.net/62306
